
基于Word2vec和K-Means算法的勘探开发成果文档聚类研究
2023-01-03 07:56:54沈东义姬银秀毛火明郭林袁秋霞
湖北大学学报(自然科学版) 2023年1期
沈东义,姬银秀,毛火明,郭林,袁秋霞
(中海石油(中国)有限公司天津分公司,天津 300459)
0 引言
渤海油田勘探开发阶段每年都会产生近万份研究成果文档.为进一步实现科研人员研究协同、成果共享,提高研究效率,对大数据量的研究成果进行分类整理十分有必要[1].但目前,渤海油田勘探开发研究成果入库前分类工作主要依靠传统手动方式,效率低下且无法满足成果文档及时共享的需求.
近年来随着自然语言处理技术的发展,文本聚类技术在很多领域都有应用,如电子商务网页检索聚类、网络舆情热点聚类挖掘、医药专利文本聚类研究、电商网站用户评论热点挖掘、垃圾邮件识别、情感分析、档案数据自动分类等领域[2-8],并且都取得了较好的应用效果.其中短文本聚类由于短文本所呈现的稀疏性、歧义与噪声多的特点,比普通文本聚类更具挑战性.冯靖等人[9]通过使用LDA模型对训练数据进行建模和特征扩展,从而提高了聚类效果.傅承涛等人[10]针对新闻类短文本聚类检测困难和计算量大的问题,提出使用基于密度的聚类算法CFDP对矢量化的文本数据进行聚类的方法,聚类结果F值达到89.24,效果良好.
渤海油田开发成果文档标题文本作为入库分类依据,在文本长度上类似于短文本,具有文本较短、专业化词汇占比大、特征缺失等特点.针对上述问题,为了提高成果文档分类入库效率,本研究从短文本聚类的两个关键步骤,即文本的向量化表示和聚类效果评价进行研究,提出了一种基于Word2vec再训练模型和K-Means的文本聚类方法对勘探开发阶段的成果文档进行文本聚类.
1 数据预处理
本文中收集了近7万份勘探开发成果文档,涵盖地球物理探测、地质综合研究、分析化验、测井、录井、钻完井等专业,专业分布广泛、类型齐全,有一定代表性.
1.1 文本数据获取首先将渤海油田项目知识库中近7万份勘探开发成果数据文档所有数据的详细信息以Excel表格导出,如图1所示,表中包含“DocID”、“TypeID”、“正题名”、“DocType”等字段信息,其中“DocID”为成果文档的ID信息,“正题名”为所有成果文档入库原始标题名称.
同时提取“DocID”和“正题名”两字段中所有数据作为初始数据集,最终获取原始标题共69 099条.
1.2 文本预处理获取初始数据集后,对获取数据中的“正题名”进行预处理,提取有用的文本信息.根据初始数据集特点,本文将中英文数据分别进行处理,其中,中文标题文本共33 577条,英文标题文本共35 522条.
由于标题文本中存在命名不规范、中英文不同语种以及多种特殊符号等问题,为保证数据一致性,提高原始数据质量,同时要保证文本标题清洗后仍包含关键类别信息,因此要对标题中多余的符号、数字、括号内解释性文本、修饰性文本等无关信息进行剔除.采用正则表达式[11]来预定义标题文本清洗规则.最终中文标题清洗前后对比示例如表1所示.
其中,中文标题文本数据清洗主要包含以下步骤:
1)去除括号内所包含的文本内容.如:标题“C井完井总结(80年3月改为C2井)”中括号内文无法提供有价值的判别内容,予以去除;

表1 中文标题文本清洗前与清洗后示例
2)去除文本数据中的特殊符号、数字等,保留中文文本.如标题中包含“#(a-zA-Z0-9./ )-″)(&ⅠⅡⅣⅢ&′△-"Ⅴ#;,〈s,、zn:”等特殊符号予以去除;
3)去除中英文井名、构造名、区块名等修饰成分信息.如,标题“辽中南洼南部旅大A构造B井三维定量荧光录井总结报告”中“三维定量荧光录井总结报告”为区分成果数据类别的有效关键信息,“辽中南洼南部旅大A构造B井”等修饰部分予以去除;
4)对于较长标题,如文本标题中包含多个附件信息,如“渤东凹陷蓬莱C构造G井地化录井完井总结报告 附件一:现场样品采集分析记录,附件二:地化路径分析数据表,附件三:油组组分图谱”,只取第一个“地化录井完井总结报告”作为有效文本.
其次,英文标题文本数据清洗主要包含以下步骤:
1)将文本内容全部转为小写,去除标题文本中中特殊符号、数字等;
2)将英文标题文本中单字母或双字母视作停用词去除;
3)去除英文标题文本中括号内的内容以及有规则特征的井名、构造名等,只保留关键类别信息.
英文标题文本清洗后示例如表2所示.

表2 英文标题文本清洗前与清洗后示例
数据清洗完成后,对规范后中文标题文本进行分词预处理.本研究采用jieba分词算法中的精确模式对中文标题文本进行精确切分.该算法将基于字符串匹配算法与基于统计算法结合,在准确度和速度方面都表现良好[12].分词结果如表3所示:

表3 英文标题文本清洗前与清洗后示例
2 Word2vec自训练和文本聚类
本文中将所搜集的勘探开发成果数据文档标题文本作为初始数据集,对初始数据集进行数据清洗和整理后采用jieba算法包对文本进行分词处理,在Word2vec基础上使用成果数据文档标题二次训练词向量后对文本进行特征表示,再将文本向量矩阵作为CNN模型的输入提取文本深层语义特征,最后采用K-Means算法进行聚类,并为每一类文档进行类别标引,实现对勘探开发成果文档自动聚类.具体技术流程如图2所示.

图2 基于Word2vec和CNN的勘探开发成果文档聚类流程
2.1 文本特征提取标题文本预处理完成后,需将文本相似度问题转换为向量矩阵.使用基于Word2vec二次训练获取词向量和CNN进行特征提取,从而获取文本的深层特征.
2.1.1 自训练Word2vec向量表示 Mikolov等[13]采用神经网络的思想提出了Word2vec模型,使用此模型在训练文本语料库的过程中,主要考虑上下文间的语义关系,在目标词前的一定数目的词语影响目标词的出现,来获取某个词的向量表示.
由于数据集的特殊性,为了取得最佳聚类效果,选择在预训练Word2vec向量的基础上基于自有开发成果文档标题语料库进行再训练,再训练后得到的Word2vec词向量对含有专业词汇更多的文档标题短文本的向量表示更符合实际应用.

图3 卷积神经网络模型图
通过将预处理后的标题文本作为输入进行训练,得到一个由文本向量构成的矩阵表示.其中,每个词初始设置为随机n维向量,经过训练后获得每个词语的最优向量.
2.1.2 CNN语义特征提取 在获取的Word2vec向量表示基础上,采用CNN对向量进行进一步的局部特征提取.卷积神经网络主要包含输入层、卷积层和池化层、全连接层和输出层[14].图3展示了CNN模型图.

图4 K-Means聚类流程图
使用CNN网络模型对文本进行特征提取,输入层输入Word2vec文本特征向量,卷积层进行局部特征提取,之后采用最大池化对文本特征向量的局部部分进行深层次的特征提取,获取一个标量.最后全连接层将所有特征向量相连,得到一个完整的最终文本特征向量.
经过CNN模型训练后,文本与文本特征向量一一对应,通过输出层将最终的文本特征向量输出,最后进行聚类分析.
2.2 K-means文本聚类采用K-Means算法对Word2vec2-CNN文本特征向量进行聚类分析,通过迭代计算寻找最佳类别划分方案[15],使得用k个聚类的均值的总体误差J(c,μ)最小.
(1)
其中,μc(i)表示第i个聚类的均值,其算法过程如图4所示.
3 聚类结果输出与评估
3.1 聚类结果输出为选择最佳聚类类别k值,本研究在实验过程中采用SSE(误差平方和)[16]作为指标对聚类效果进行评估.
(2)
将k值分别设置为50、100、200、250、300、350、400、450分别进行聚类实验,结果如图5所示,可知当k=200时,SSE递减增量开始减小,算法趋于收敛.
使用Matplotlib可视化工具对聚类结果进行可视化.图6分别为当k为200时,中英文标题文本的聚类结果可视化图.

图5 中英文标题文本聚类算法SSE值的变化趋势

图6 中英文标题200类聚类结果可视化图
本文中将200类聚类结果分别写入文件,每个文件命名为当前类别的label名,示例如表4.
每个文件写入内容格式为“标签 DocID 原标题”,以“录井完井报告”文件为例,内容示例如下,
标签 DocID 原标题
录井完井报告 0e0363ea-7d43 LD凸起JZ2构造M井FLAIR录井完井报告
录井完井报告 144fd275-fe9d HHK凹陷KL1构造N井FLAIR录井完井报告
....
图6中(a)可知,中英文标题文本聚类数据簇分布较为集中,整体聚类效果较好,但仍有部分零散点无法得到最终聚类.中文标题文本共33 577条,其中,30 217条文本实现聚类并获取了相应的类别标签.其中,3 360条无法获取最终分类,需要人工辅助做进一步分类.而英文标题文本聚类同样存在部分问题.英文标题文本共35 522条,其中,33 239条获取了相应类别标签,2 283条无法获取最终分类,需要人工辅助做进一步分类.如表5所示为中英文标题聚类结果统计.

表4 文本聚类结果文件部分示例

表5 文本聚类结果文件部分示例
综上,采用本文中提出的方法,在拟定的69 099条勘探开发成果文档文件标题数据集中,91.8%的标题文本实现了自动分类,与手工分类相比,效率极大提升.
3.2 评估测试集本文提出的方法使分类效率极大提升的同时,为验证分类结果质量,本部分对采用自动分类方法获得类别标签的63 456条勘探开发成果文档标题进行效果评估.在渤海油田项目知识库勘探开发成果数据文档详细信息表中,“DocType”字段为知识库中每条文本入库时的原始类别标签,“正标题”为所有成果文档的入库原标题名称.因此,本研究拟定在全部69 099条原始数据中,随机抽取5 063条“正标题”和“DocType”作为评估数据集,数据不包含重复数据且各类别种类齐全,具有代表性.评估数据集部分示例如表6所示.

表6 评估数据集部分示例
3.3 评估指标与评估结果将所有标题文本聚类得到200类,因此对多标签聚类结果的评估,本研究通过相似度计算来确定每条标题的标签是否预测准确.
由于标签文本为短文本,采用编辑距离[17]来计算二者的相似度,计算公式如下:
(3)
其中,sum是指label_test和label_pre字串的长度总和,Idist类编辑距离.
同时,本文中设置相似度阈值为0.6,即如果Similarity值大于0.6则判定类别标签准确,否则判定标签错误.聚类结果如表7所示.

表7 聚类结果效果评估
评估结果显示,采用本文提出的方法进行聚类获得的类别结果与标签准确率达93.6%,在分类效率极大提成的同时,标签获取准确率也表现优异.
4 实验与结果分析
4.1 实验数据实验采用的数据为渤海油田开发成果文档标题文本经过预处理后获得的短文本语料,总数为69 099条.根据数据集特点,数据集分为中文和英文数据两种,其中,中文标题文本共33 577
条,英文标题文本共35 522条.
4.2 实验参数本次实验涉及的参数包括Word2vec的特征维度,卷积核数量.具体参数如表8所示.

表8 参数设置
4.3 对比实验为了验证模型的有效性,设置多组对比实验对数据进行聚类分析.实验具体设置为在相同聚类模型K-Means下分别采用不同的文本表示方法时的聚类结果对比.即文本表示方法包括Word2vec模型(未使用开发成果文档语料进行二次训练的词向量模型)、自训练Word2vec(在原Word2vec模型基础上使用开发成果文档语料进行二次训练后的词向量模型)、向量空间模型one-hot编码、词袋表示TF-IDF以及预训练模型Bert.使用不同词向量方法的聚类结果如表9所示.
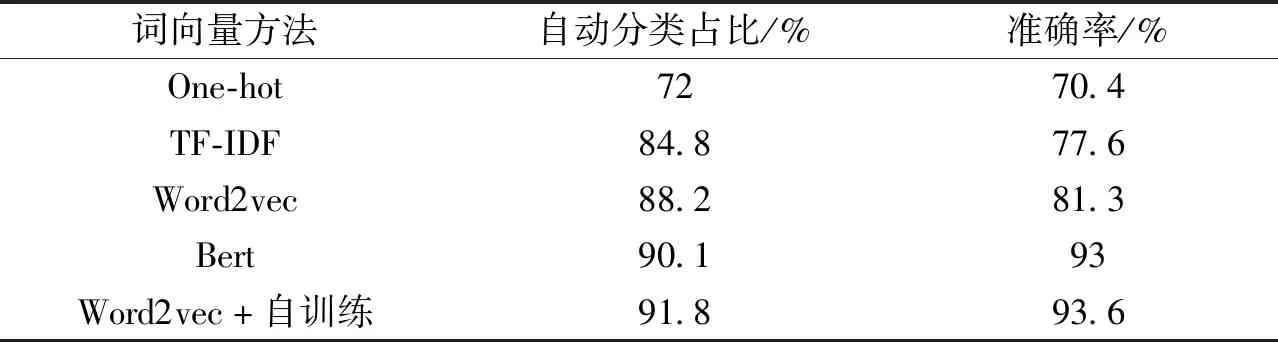
表9 不同词向量方法的聚类结果对比
从实验结果可以看出,传统的one-hot方法和词袋表示TF-IDF在聚类时仅能对72%和84.8%的标题文本进行自动分类,仍有较大比例的数据仍需手动分类.在使用Word2vec和Bert模型后分类效果有明显提升,尤其在最后一组实验中,通过结合Word2vec和开发成果文档标题数据进行再训练后进行聚类,自动分类比例提升了3个百分点.说明本文提出的方法能够有效提高文本表示能力,从而提高聚类算法的性能.
5 结论与展望
综上所述,采用本文中提出的基于Word2vec自训练和CNN的文本特征提取并结合K-Means聚类算法的方法对勘探开发阶段的成果文档进行自动分类,不仅使得成果文档分类效率提升了91.8%,还使得分类结果标签获取准确率也达到93.6%,极大地提高了渤海油田勘探开发成果文档的分类效率和准确率.
受制于成果文档标题文本数据的特殊性,原本就字数较少的情况下使得专业词汇占比更大,给分类带来了更大的挑战,此次研究的解决方法主要是将文本表示模型Word2vec用专业词典再训练后投入使用,分类准确率尚未达到95%的突破口.下一步的研究重点将放在如何加强模型对专业词汇的理解,从文本更短更专业化的标题文本中提取信息,实现更精确的分类效果.
通过将获取类别标签的文档分类结果调用相应录入程序实现快速入库,为数据治理工作提供了坚实的基础,同时也为进一步实现渤海油田科研人员研究协同、成果共享、提高研究效率奠定了数据基础.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
电子测试(2017年15期)2017-12-18 07:19:27
信息安全研究(2016年4期)2016-12-01 06:06:54
公民与法治(2016年10期)2016-05-17 04:12:58
智能系统学报(2015年4期)2015-12-27 09:38:39
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
计算机工程(2015年8期)2015-07-03 12:20:27
电子设计工程(2015年6期)2015-02-27 12:04:53
