
基于OCR 的天地图·湖北行政村(居)委会质检关键技术研究
2023-01-03 11:44陈重远张淑芬
地理空间信息 2022年12期
党 琦,陈重远,鲁 钊,张淑芬
(1. 湖北省地图院(湖北省地图数据应用中心),湖北 武汉 430074)
光学字符识别(OCR)是广泛使用的一种文本自动录入技术[1],可以自动对照识别图像和图形中的字符信息。近年来,OCR在计算机视觉和人工智能领域引起的关注。本文提出一种基于OCR技术的智能地名地址识别方法,同时深入研究实施过程中的关键技术,并与常规人工质检方式进行实验对比,实验证明基于OCR 的天地图·湖北行政村(居)委会质检方式是必要与可行的。
1 天地图·湖北行政村(居)委会工作模式
天地图·湖北是指湖北省地理信息公共服务平台,其建设目的是综合利用湖北省全省基础地理信息数据、专题数据集、多源多分辨率影像数据,为社会公众提供一站式、便捷的地理信息服务[2]。
行政村(居)委会作为天地图·湖北地名地址的重要组成部分,通过外业调绘和内业整理得到其空间地理位置和名称等信息。
天地图·湖北行政村(居)委会外业调绘时,利用手机定位软件在行政村(居)委会大门中间定位获取空间地理位置。拍摄两张照片用于记录名称信息,要求两张照片中一张拍摄行政村(居)委会全景、一张拍摄挂牌照片,两张照片均要求清晰可辨、且无遮挡,拍摄形式如图1行政村(居)委会挂牌照片所示。

图1 行政村(居)委会挂牌照片
行政村(居)委会内业整理时,根据外业调绘拍摄挂牌照片,在数据库中录入对应的挂牌名称,需要注意的是挂牌名称以最低行政级别录入。
目前,常规的行政村(居)委会的质检方式是在ArcGIS软件中加载行政村(居)委会数据,人工对照外业调绘拍摄的挂牌照片,逐个检查录入的名称是否正确。该方式能确实检查出行政村(居)委会名称内业整理过程中的漏字、错字等情况,但是效率比较低下。
2 质检关键技术
2.1 OCR技术
OCR是指将图像上的文字转化为计算机可编辑的文字内容[3]。OCR 的概念于1929 年由德国科学家Tausheck[4]最先提出,随着计算机技术和人工智能技术的不断推进,OCR识别技术飞速发展,识别率和准确率均有质的飞跃。目前在国内,OCR技术在金融、医疗、交通等领域应用普通,例如高速公路的ETC使用该种技术自动识别车牌信息,百度和腾讯等互联网公司也使用OCR进行人工智能工作。
2.2 质检方式
本文基于OCR 实现天地图·湖北行政村(居)委会的质检,主要包括图像预处理,文字识别,与数据库行政村(居)委会比较3个步骤,流程如图2所示。
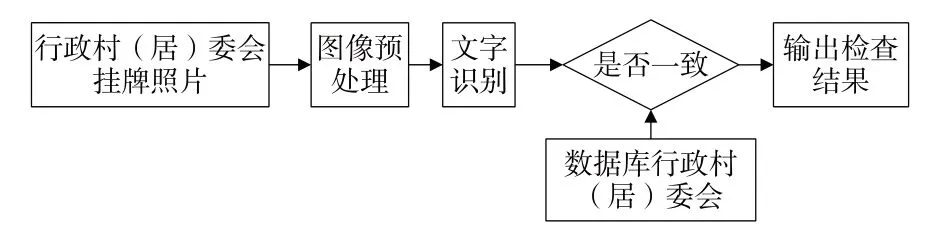
图2 基于OCR的天地图·湖北行政村(居)委会质检流程
2.3 图像预处理
由于行政村(居)委会挂牌照片存在图片分辨率低、饱和度低、噪声多等问题,需要对照片进行图像预处理,提高OCR的识别准确率和效率。图像预处理一般包括灰度化、图像增强等操作。
1)灰度化。采用加权平均法进行图像灰度化,加权平均法公式如式(1)所示。
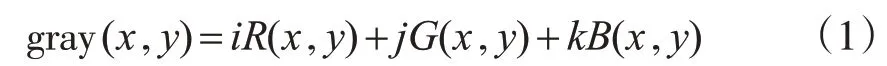
式中,R(x,y),G(x,y),B(x,y)为R、G、B3 个分量;i,j,k分别为加权系数。由于灰度图像只有亮度差别,没有颜色差别,所以不同的加权系数取值影响的是图像的亮度,根据YUV 颜色模型[7]中亮度转换公式,i,j,k分别设置为0.299,0.587,0.114。
2)图像增强。为了减少或者降低图像中的噪声,加强行政村(居)委会文字识别的准确率,需要对灰度化后的图片进行图像增强。行政村(居)委会照片挂牌信息一般为规则的文字排列,为了更加符合挂牌信息的特点,增强突出图像中的挂牌信息部分的文字信息,去除其他无用信息,本文设计了二值化的图像增强方式,将灰度化后的图像转换为黑白图像,即图像中文字部分转换为黑色,其他部分转换为白色。一般二值化的方法是通过指定特定的阀值,图像中每个像素值大于该阀值的值,则为黑色,小于该阀值的值,则为白色,此种二值法方法十分简单实用,但是对于行政村(居)委会照片而言,不能准确突出挂牌照片中的局部文字信息,所以本文设计局部自适应阀值,通过将灰度图像分成若干区块,根据每个区块的亮度分别设置阀值,进行二值化操作,从而得到整个二值化的图像。具体操作为:①将图像切分成n个区块;②计算这些区块中每个像素的加权均值得到该区块的自适应阈值Y;③设区块内的每一像素值为X,当X>Y-C (C 为常量),则该像素点为白色,否则为黑色。图1 中行政村(居)委会照片二值化后后图像如图3所示。

图3 二值化后图像
2)文字识别。PaddleOCR是由百度公司开源的超轻量OCR[8],由于其简单实用的特点目前被广泛运用于文字识别领域。本文使用PaddleOCR,指定卷积循环神经网络(CRNN)模型作为文本识别器,通过Pad⁃dleOCR封装的recognize_text接口,识别出图片中行政村(居)委会挂牌名称,文字识别流程如图4所示。

图4 基于OCR文字识别流程
首先需要对图像预处理后的行政村(居)委会照片进行文本检测得出图像中的文字范围。通过对照片中每一个像素进行文本判断,判断该像素是否属于一个文本目标。对于连续的文本像素,进行分割得到文本区域,再通过后处理方式得到该文本区域的最小包围曲线,从而得出图像中的多个分割后的文字范围。
其次,通过CRNN[9]模型进行文字识别。CRNN模型是CNN+RNN+CTC 的结构,被广泛应用于图像文字识别领域。CNN,卷积神经网络,用于图像特征提取。通过对每个分割的图像文字区域建立一个个的细小矩形框来识别图像中的文字特征,从而得到特征序列。由于一些非文本区域存在一些与文字类似的特征,仅仅依靠CNN判断识别区域中的文字,不足以完全识别文字区域定位和特征,这时RNN 应运而生。RNN为递归神经网络,用于对文字的特征序列进行预测。通过使用RNN对每个特征序列进行预测打分,分数低的区域判断为无效区域,能够更好的识别文字区域定位和特征。最后CTC 解决文字中的去重、去空、无法对齐等问题,对每一个特征序列的结果进行正确的翻译,得到一个最终的文字识别结果。
3)与数据库行政村(居)委会比较。通过OCR程序识别出挂牌名称信息,如图1 行政村(居)委会挂牌照片识别出挂牌名称为“大庄村村民委员会”。再与数据库中的相应的名称进行对比,检查两者名称是否一致,如果一致则表明正确,否则为错误。
2.4 特殊情况
天地图·湖北行政村(居)委会收集时,还存在一些特殊情况,这些特殊情况使用OCR文字识别,无法得出准确结果,如下所示:
1)照片质量不高。部分行政村(居)委会照片由于光照、拍摄条件、调绘人员未按要求拍摄等原因,导致照片出现分辨率低、模糊,照片信息不全等质量不高的情况,造成程序无法准确识别文字。其次,由于挂牌名称信息均为汉字,汉字的结构复杂、形近字较多,还存在一部分生僻字,通过OCR识别有一定几率出现错误。
2)存在行政村(居)委会未挂牌。现实中,存在行政村(居)委会未挂牌的情况。外业调绘人员未拍摄到挂牌照片,内业整理时将未挂牌的行政村(居)委会依据指定名称在数据库中进行录入。
3)行政村(居)委会挂牌中缺少“村(居)民委员会”的说明。此类情况内业人员需在挂牌名称的基础上添加“村(居)民委员会”的后缀说明。
出现上述3种情形时,无法通过OCR自动识别行政村(居)委会,需人工根据照片或通过外业调绘人员处了解后判断录入数据是否正确。
2.5 实验与分析
1)实验数据。实验使用2021年天地图·湖北行政村(居)委会外业调绘恩施市数据,截至2021年6月该市共有208 个村(居)委会。通过实验来验证基于OCR 的天地图·湖北行政村(居)委会质检方式的可行性和效率。
2)实验环境。使用1 台工作站作为实验机器。硬件环境为Intel Xeon 四核3.7 GHZ CPU,内存64 G,硬盘10 T。
3)实验结果分析。考察比较基于OCR的天地图·湖北行政村(居)委会质检方式的前后时间和准确率差异。实验步骤如下:分别使用常规质检方式与基于OCR 的质检方式对恩施市208 个行政村(居)委会进行质量检查,实验结果如表1 和表2所示。

表1 质检方式前后时间对比/min

表2 质检方式前后准确率对比/%
由表1 可知,基于OCR 质检方式(排除特殊情况)的花费时间最少,但是由于天地图·湖北行政村(居)委会信息存在一些特殊情况,这些特殊情况不能被程序自动识别出来,所以需要基于人工再判断一次,导致基于OCR质检方式(包含特殊情况)相比未包含特殊情况时间有所增加,但是与常规人工质检方式相比,效率更高。
由表2可知,常规质检方式准确率为100%。由于特殊情况的存在和OCR识别率本身的原因,基于OCR质检方式(排除特殊情况)的准确率为73.1%。通过人工检查行政村(居)委会的特殊情况,能够使准确率上升到92.8%,剩下7.2%的数据需人工确认核查。尽管基于OCR质检方式的准确率不足100%,但也已达到92.8%,识别效果较好,剩下需核查的点位非常少。
综合实验可知,基于OCR 的天地图·湖北行政村(居)委会质检方式的效率比常规方式高,准确率方面没有常规方式高,但也已达到较高水平。由此可知,基于OCR 的天地图·湖北行政村(居)委会质检方式是必要与可行的。
3 结 语
本文基于OCR设计了一个新的天地图·湖北行政村(居)委会质检方式并研究其关键技术,通过实验可知,基于OCR 的质检方式能切实可行的提高天地图·湖北行政村(居)委会的质检效率,该方法的推广使用在天地图·湖北地名地址质检工作中具备较大应用价值。
猜你喜欢
福建稻麦科技(2022年1期)2022-11-22
今日农业(2022年15期)2022-09-20
华人时刊(2022年9期)2022-09-06
商品与质量(2020年25期)2020-11-26
西部交通科技(2020年1期)2020-05-25
西部资源(2019年2期)2019-11-12
人大建设(2018年1期)2018-04-18
通信产业报(2017年21期)2017-07-31
建筑工程技术与设计(2015年20期)2015-10-21
黑龙江史志(2011年6期)2011-08-15
