基于天牛群优化与改进正则化极限学习机的网络入侵检测
2022-12-31 02:56王振东刘尧迪杨书新王俊岭李大海
自动化学报 2022年12期
王振东 刘尧迪 杨书新 王俊岭 李大海
随着网络技术的快速发展,网络结构趋于复杂,由此发生网络入侵的风险也越来越大,如何辨识各种网络入侵成为人们高度关注的问题.入侵检测(Intrusion detection,ID)技术作为一种能够动态监控、预防和抵御入侵行为的新型安全机制,已经逐渐发展成为保障网络系统安全的关键技术.然而网络规模、网络速率以及入侵类型的持续增大、增多,使得入侵检测技术面临越来越多的挑战[1].因此,如何设计面向当前及未来网络环境的新型入侵检测机制,提高入侵检测的检测速度、降低漏报率和误报率,提升检测性能成为相关领域研究人员关注的核心问题.
在已有研究中,通常认为数据挖掘、机器学习以及神经网络在内的多种方法是有效的入侵检测方法[2−5].但大部分数据挖掘算法对噪声较为敏感,若数据集包含噪声数据较多,则算法极易出现过拟合现象;机器学习算法因其自身比较复杂,数据集过大会导致模型训练时间过长,计算成本较高;神经网络通过模拟人类大脑的思维方式来处理信息,具有自组织、自学习和自适应的特点,将其应用于入侵检测可以很好地解决数据挖掘和机器学习存在的问题,提升检测性能,使得基于神经网络的入侵检测成为研究热点[6].传统神经网络如BP (Back propagation)神经网络在诸多文献中已应用于网络入侵检测,并取得一定效果[7−8],但需多次迭代确定网络输出权值,严重影响网络的学习能力.
作为一种新型神经网络,极限学习机(Extreme learning machine,ELM)[9]的出现引起了研究人员广泛的关注.ELM 是一种单隐层前馈型神经网络,最大特点是输入层和隐含层之间的连接权值,以及隐含层节点的阈值只需通过最小二乘法计算一次即可得到最优初始权值和阈值,而不需通过反向传播算法进行更新.因易于实现、训练速度快,ELM 在数据分类[10−11]、故障识别[12]、能耗预测[13]、入侵检测[14]等许多领域取得了成功.但ELM 并未充分考虑结构化风险可能导致的过拟合问题.Deng等[15]提出了正则化极限学习机(Regularized extreme learning machine,RELM)的概念,并将其应用于SinC 函数的近似、现实世界回归以及UCI 数据集的分类.结果表明,RELM 不仅能够保留ELM 的所有优点,对离群点还具有一定的抗干扰能力,能够获得极小的训练误差,模型的泛化性能也得到显著提高.
鉴于RELM 在分类问题中表现出的优越性能,本文将RELM 引入到入侵检测领域.但直接使用RELM 会存在如下问题: 1) RELM 的输出权值矩阵通过逆矩阵求得,逆矩阵在求解过程中接近奇异值,会降低算法的求解精度,影响分类准确率;2) 随机初始化权值矩阵以及隐含层阈值,会导致原始数据随机映射到RELM 特征空间时出现难以预测的非线性分布,并对算法的分类准确率造成影响.对此,本文尝试使用天牛群优化(Beetle swarm optimization,BSO)算法优化RELM 的初始权值矩阵,并将LU 分解(LU decomposition)引入求解RELM的输出权值矩阵,提出BSO-IRELM 算法,将其应用于入侵检测.实验结果表明,BSO-IRELM 算法具有优秀的数据分类能力,能够有效实现Normal、Probe、DoS、R2L、U2R 等各类攻击的检测.
1 BSO-IRELM 算法
RELM 随机初始化输入层和隐含层之间的权值以及隐含层节点的阈值,通过特征映射使数据分布呈现某种非线性的几何结构,影响分类性能.而使用逆矩阵求解输出权值矩阵,会导致求解过程中出现奇异矩阵的情形.对此,使用具有良好寻优能力的BSO 算法对RELM 的初始权值和阈值进行初始化,并引入LU 分解求解RELM 的输出权值矩阵,规避求解过程的奇异矩阵.
1.1 基于LU 分解的IRELM
由传统统计学原理可知,实际风险包括经验风险和结构风险两种[16].一种具有好的泛化能力的模型应该能够平衡这两种风险.因此增加正则项以调节系数β,提高模型的泛化能力.RELM 的目标函数为

其中,ei为训练误差,∥β∥2和∥ei∥2分别为结构风险和经验风险,λ为惩罚因子.
根据式(1)和式(2)建立拉格朗日方程,得

式中,αi ∈R,i=1,···,N为拉格朗日算子.对式(3)的变量 (α,e,β) 分别求偏导并令其等于零,得
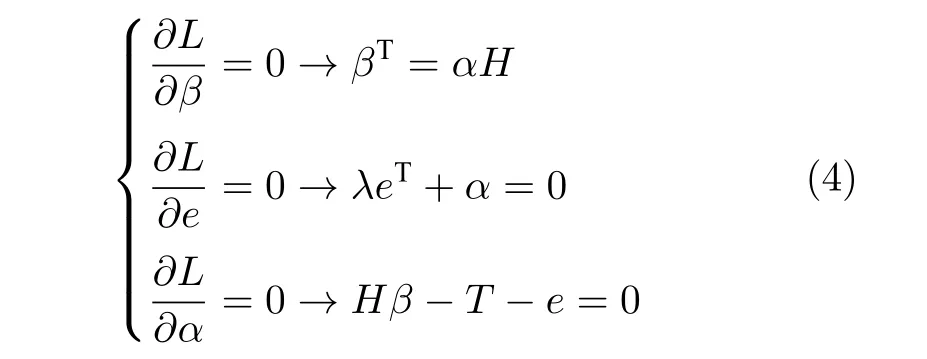
对式(4)进行最小二乘法计算,得到输出权值矩阵
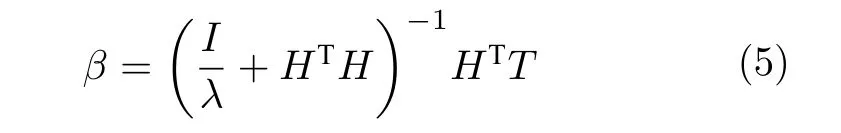
其中,I为单位矩阵.
式(5)计算输出权值矩阵β涉及到矩阵求逆的运算,若输入样本过大,会导致矩阵求逆复杂度增大,从而降低RELM 的训练效率.为降低RELM的计算复杂度,本文提出一种基于LU 分解的IRELM算法,改变RELM 输出权值矩阵的求解方法,降低算法复杂度,提高入侵检测分类精确度.
由式(5)得
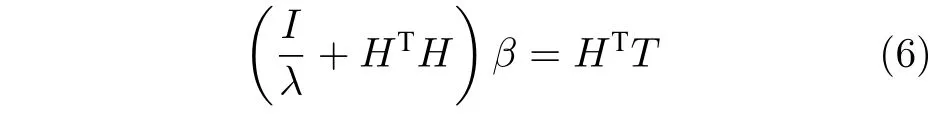
令A=(I/λ+HTH),b=HTT,则式(6)转化为

LU 分解求解RELM 输出权值矩阵的具体步骤如下:
矩阵A可进行唯一的LU 分解,设
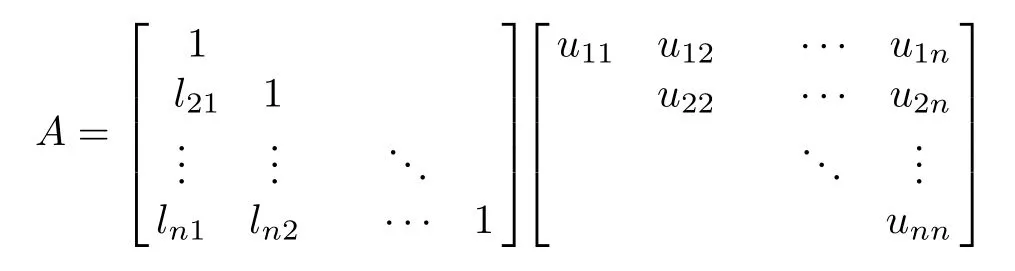
由矩阵乘法并令两边矩阵的 (i,j) 元素相等,得上下三角矩阵中的元素为
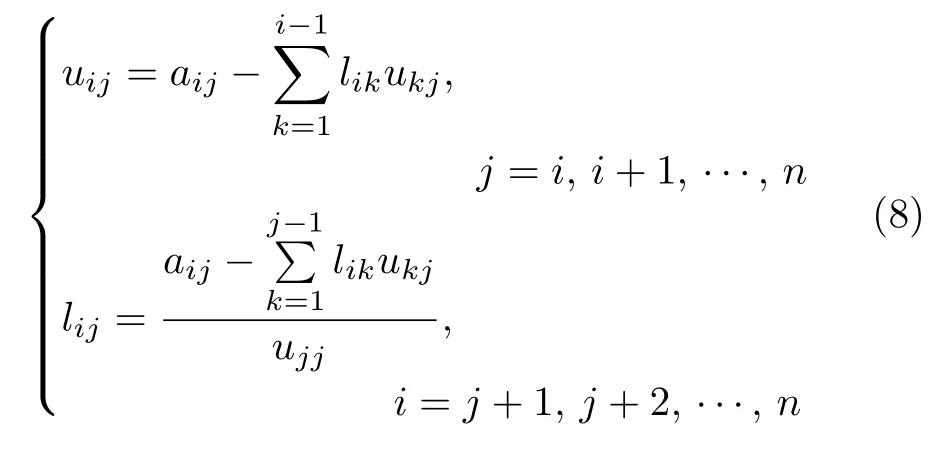
当矩阵A进行LU 分解后,解线性方程组Aβ=b等价于求解下面两个三角形方程组

从上面的求解过程可以看出,输出权值矩阵不需使用式(5) 逆矩阵的方法来计算,只需通过式(8)∼(10)的迭代递推公式进行简单的加减运算即可求出RELM 的输出权值,能够大大降低算法的复杂度.同时,使用LU 分解求解输出权值矩阵可以很好地避免计算过程出现奇异矩阵的情况,提高算法的分类准确率.
1.2 BSO 算法设计
天牛须搜索算法(Beetle antennae search,BAS)是Jiang等[17−18]在2017 年模拟天牛觅食原理时提出的启发式算法,用于解决压力容器和Himmelblau 等非线性优化问题.BAS 算法具有求解速度快和精度高的特点,已成功应用于信号定位[19]和数据分类[20]等领域.但BAS 算法在高维空间搜索时只能收敛到局部极值,且在多维函数优化中,只依赖于单个天牛个体进行搜索会增加算法陷入局部最优的可能性.对此,本文提出了一种带莱维飞行群体学习策略与动态变异策略的混沌天牛群算法.将天牛个体搜索扩展为群体搜索,并使用Tent 映射反向学习初始化种群,促使初始群体信息分布均匀,提高搜索效率.此外,利用莱维飞行群体学习策略,使得天牛个体既能学习自身经验又可以学习群体经验,让各天牛个体有目的和指导性地移动,提高算法的收敛性能.最后引入动态变异策略,增加迭代后期种群多样性,避免算法陷入局部最优.
1.2.1 Tent 映射反向学习初始化种群
研究表明[21],在群智能搜索中,算法的收敛性能会受到初始种群的影响.种群的数量越多、分布越均匀,算法越能够在更短的时间内收敛到最优解;反之,则会影响算法的收敛性能.使用混沌映射初始化种群具有随机性、遍历性以及有界性的特点,能够有效提高算法的搜索效率.而Tent 映射产生初始序列比Logistic 映射产生初始序列更加均匀,所以本文采用Tent 映射对天牛群体初始化,并使用反向学习策略优化初始种群,通过反向个体与现有个体一起竞争,让更优秀的个体被选进下一代学习,可以扩大种群的搜索范围,减少无效搜索,从而提高算法的收敛速度.Tent 映射的数学表达式为

综上所述,采用Tent 映射反向学习初始化种群的具体步骤如下:
步骤 1.在搜索空间中使用Tent 映射产生N个天牛种群的位置xij,i=1,2,···,D;j=1,2,···,N作为初始种群OB;
步骤 2.根据反向解的定义,产生初始种群OB中的每个天牛群体xij的反向群体作为反向种群FB;
步骤 3.合并种群OB 和FB,使用升序将这2N个天牛群体的适应度值排序,选取其中适应度值前N的天牛群体作为初始种群.
1.2.2 莱维飞行的群体学习策略
标准BAS 算法中,天牛个体的搜索范围有限,搜索位置从全局最优向局部最优转移比较困难.虽然将个体搜索改为群体搜索能够扩大种群的搜索范围,但由于天牛个体之间没有信息交流和反馈,会影响算法的收敛精度.根据粒子群算法可知,群体中个体在移动过程中,需不断学习历史群体经验,即个体最优应具有向历史最优移动的趋势,这种移动趋势能够对算法收敛速度的提升起到决定性作用.为此,在粒子群算法框架下,引入具有莱维飞行的指导性学习策略.
莱维分布是20 世纪30 年代法国数学家莱维(Levy)提出的一种概率分布,Mandelbrotb 对其进行了详细描述[22].莱维飞行作为一种服从莱维分布的随机搜索方法,可以增加种群的多样性,扩大搜索范围,避免算法陷入局部最优,可有效增强算法的寻优能力.其中莱维分布满足

莱维飞行模型较为复杂,目前使用Mantegna算法进行模拟,数学表达式如下:
步长t的计算公式为
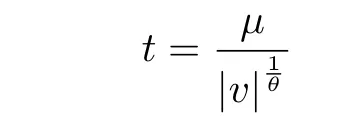
其中,µ,v服从正态分布
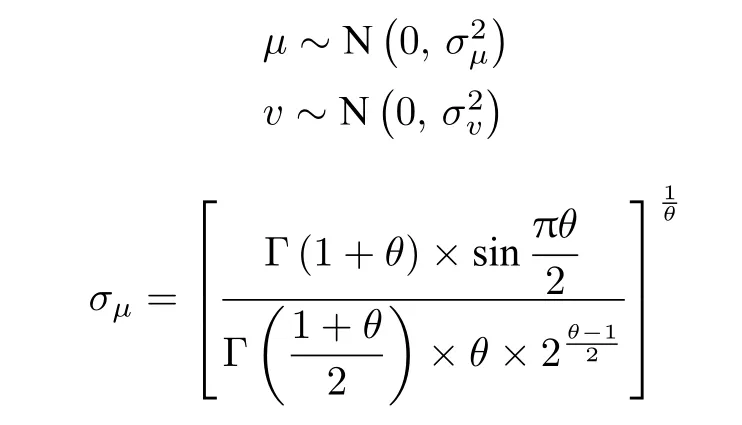
其中,Γ 是标准的伽马分布,为节约计算时间取θ=1.5.
图1 是莱维飞行的轨迹示意图.由于莱维飞行是二阶矩发散的,所以其在运动过程中的跳跃性很大.
图1 莱维飞行轨迹示意图Fig.1 Levy flight path diagram
指导性学习策略中天牛朝向的公式通过莱维飞行策略进行更新:
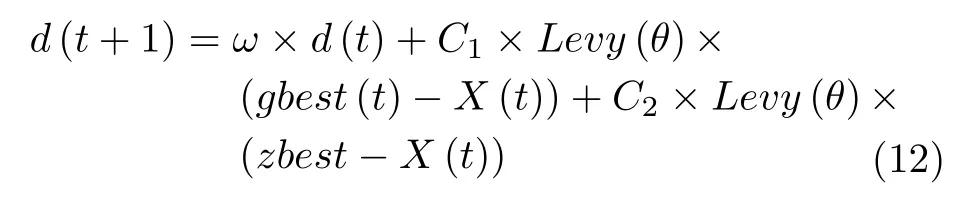
最终个体位置更新式为
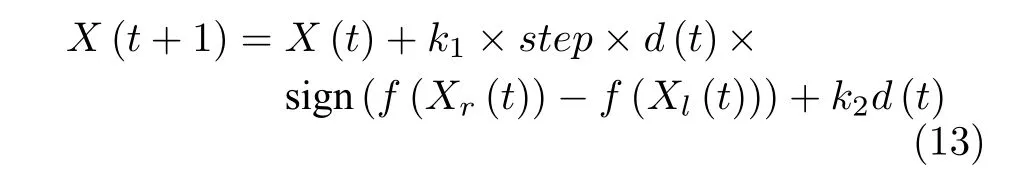
其中,d(t) 表示第t代天牛的朝向,X(t) 表示第t代天牛的位置,gbest(t) 表示第t代天牛的个体极值,zbest表示迄今为止的全局极值,ω为惯性权重,C1,C2为学习因子,Levy(θ) 为 莱维随机数.f(Xl(t))表示第t代天牛左须的适应度函数值,f(Xr(t)) 表示第t代天牛右须的适应度函数值,step为天牛步长,k1,k2为比例系数,s ign 为符号函数.天牛朝向公式中,第2 部分是自学习部分,表示天牛个体对自身历史的记忆,有向自身最优位置移动的趋势;第3部分为社会学习部分,表示天牛个体之间的学习以及群体的历史经验,有向群体最优位置移动的趋势.
1.2.3 动态变异策略
天牛群算法在迭代后期种群的多样性会越来越低,使算法的搜索能力下降.为避免迭代后期出现早熟现象,引入动态变异策略,增加天牛种群在迭代后期的多样性,提高算法的收敛精度.目前,相关学者提出了多种变异算法,典型的变异算法有高斯变异(Gaussian mutation)[23]和柯西变异(Cauchy mutation)[24].柯西算子相比于高斯算子具有较长的两翼,可以产生大范围的随机数,使算法有更大的机会跳出局部最优,同时,当峰值较低时柯西变异只需要花费更少的时间来搜索附近区域.柯西变异概率分布如图2 所示.
图2 柯西变异概率分布图Fig.2 Cauchy variation probability distribution map
因此,选择柯西变异对天牛群体进行二次寻优,对X进行变异操作,即
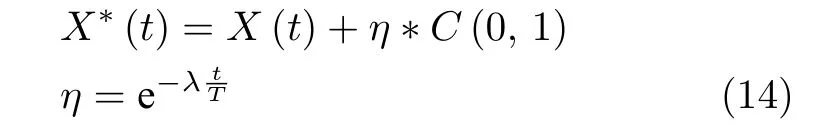
其中,η是变异权重,其值随着迭代次数的增加而减小,T为最大迭代次数,λ=10 为常数,C(0,1)是比例参数为1 的柯西算子产生的一个随机数.
1.2.4 天牛群算法步骤
天牛群算法的步骤如下,具体流程图如图3 所示.
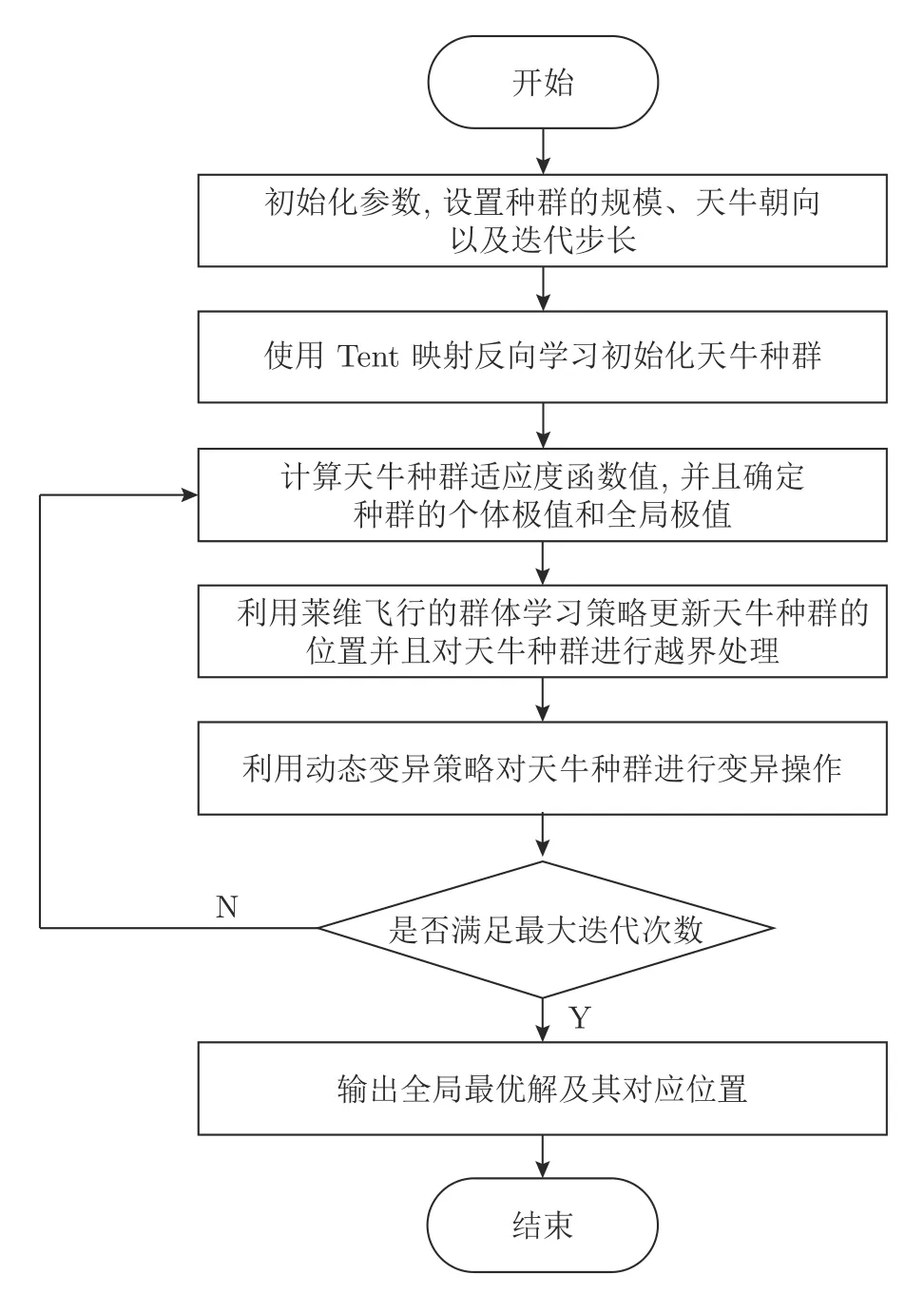
图3 天牛群算法流程图Fig.3 Flow chart of BSO algorithm
步骤 1.初始化天牛群算法参数: 设置天牛规模、迭代步长、最大迭代次数,使用Tent 映射反向学习策略初始化天牛群体,初始化天牛朝向.
步骤 2.计算群体中天牛个体相应的适应度函数值,根据适应度函数值确定种群的个体极值和全局极值.
步骤 3.利用式(12)和式(13) 更新天牛个体的朝向以及位置,对天牛种群进行越界处理.
步骤 4.利用式(14)对天牛种群进行变异操作.
步骤 5.判断算法是否满足迭代终止条件,若满足则输出全局最优解及其对应的位置,否则返回步骤2.
1.2.5 天牛群算法伪代码
天牛群算法伪代码如下所示:

1.2.6 天牛群算法性能分析
为验证BSO 算法的性能,选取F(x):minf(x)=单峰函数对算法进行函数寻优以及收敛性测试,F(x) 搜索范围设置为[ −10,10],并且与GA(Genetic algorithm)、PSO (Particle swam optimization)、DE (Differemtial evolution)和BAS 算法进行对比,算法迭代次数设置为5000 次并运行20 次.图4 描述了5 种算法在函数F(x) 上的测试结果.由图4 可知,相比于GA、PSO、DE、BAS 四种优化算法,BSO 的收敛速度和收敛精度都有明显优势.一方面引入莱维飞行的群体学习策略,平衡算法的全局搜索和局部搜索能力,加快算法的收敛;另一方面加入动态变异策略,帮助算法跳出局部最优,使寻优速率加快.故相比于传统算法,BSO 算法的性能具有明显的提升.
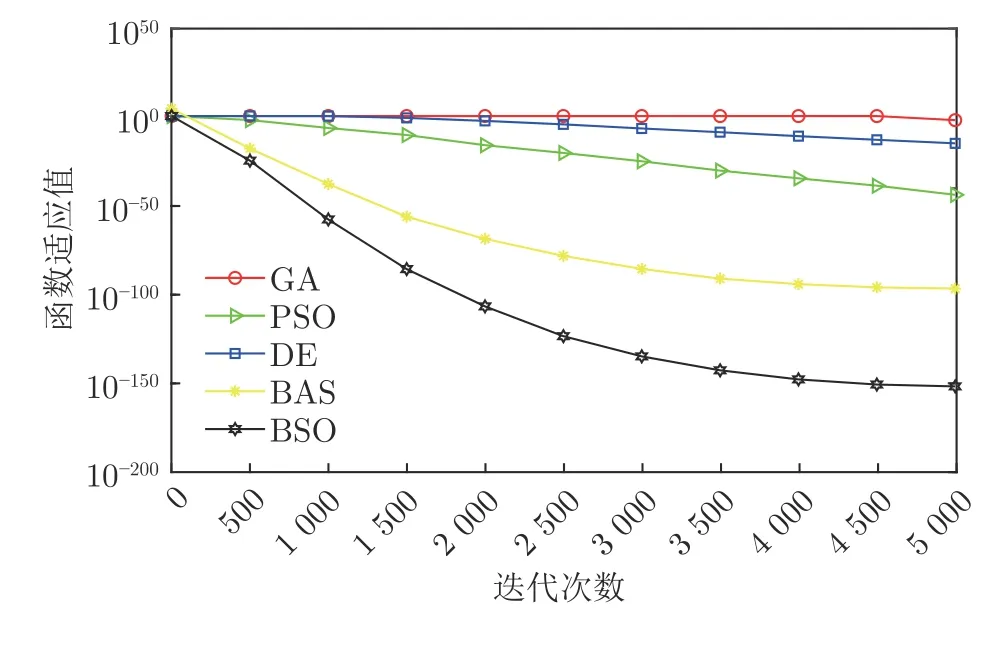
图4 算法测试结果图Fig.4 Test result graph of algorithm
2 BSO-IRELM 的入侵检测算法
基于上述分析和推导,将LU 分解和BSO 算法引入RELM 算法,并建立基于BSO-IRELM 的入侵检测模型.
2.1 适应度函数
适应度函数是判断个体适应环境能力大小的标准.因此,适应度函数的选择直接影响算法的收敛精度以及能否找到最优解.文献[25]将入侵检测准确率、误报率以及特征数的比例权重作为适应度函数,既增加了计算量又会因计数不当导致收敛精度较低;文献[26]将群智能算法函数值的分段函数作为适应度函数,需通过函数值确定适应度函数表达式,增加了计算复杂度.
将入侵检测误差和函数作为适应度函数,预测结果可由神经网络直接得到,计算方便,无需反复确定适应度函数表达式,也不会因计数不当造成误差.其数学表达式为

其中,yk表示网络的实际输出,表示网络的训练输出,M表示输入神经元的个数.
2.2 算法模型描述
使用BSO 优化IRELM 的基本思路是求出适应度函数最好的一组天牛位置,在迭代结束时把该位置作为IRELM 的最优初始权值和阈值建立入侵检测模型,模型描述如图5 所示.
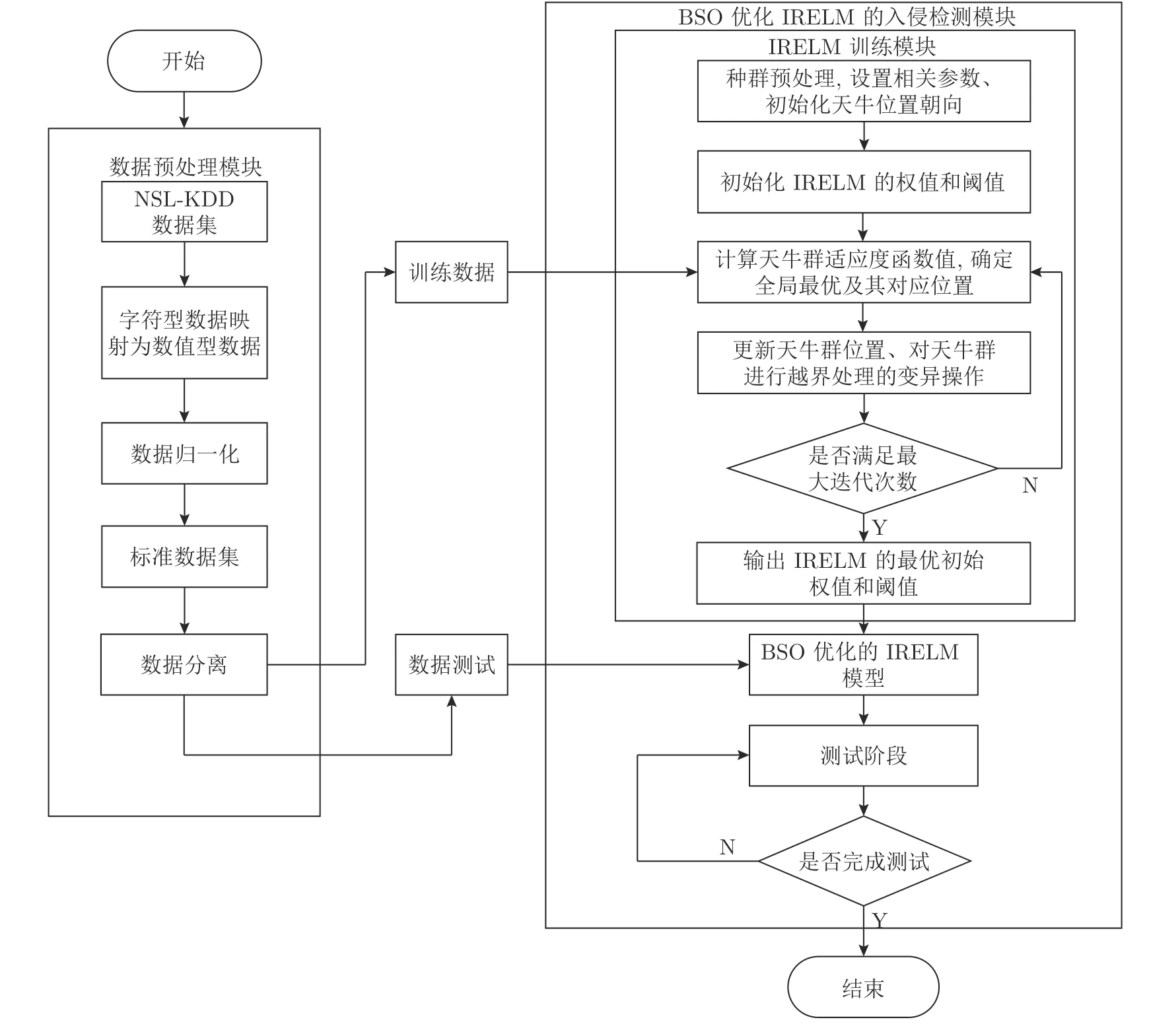
图5 BSO-IRELM 算法入侵检测框架图Fig.5 BSO-IRELM Algorithm intrusion detection framework
入侵检测框架的步骤如下:
步骤 1.对原始的NSL-KDD 数据集进行预处理.预处理过程包括2 个子步骤:
步骤 1.1.高维数据特征映射.本文使用高维特征映射,将离散型特征转化为数字型特征.
步骤 1.2.数据归一化.由于同种属性的数据之间差异较大,影响神经网络的训练,因此将数据归一化为[−1,1]的实数.
步骤 2.标准数据集划分.将标准数据集划分为训练集和测试集.
步骤 3.模型训练.对IRLEM 进行训练和参数调优.本过程包括4 个子步骤:
步骤 3.1.初始化IRELM 模型参数.innum个输入层节点、midnum个隐藏层节点和outnum个输出层节点以及网络初始权值和阈值.
步骤 3.2.初始化天牛群体.天牛种群大小N.所求问题维度D=(innum+1)×midnum(midnum+1)×outnum和最大迭代次数T及天牛种群位置xi.
步骤 3.3.根据训练样本和适应度函数计算天牛群适应度函数值,对适应度函数值升序排列并寻找天牛群的最优位置和最优适应度函数值.若满足迭代终止条件,则迭代结束转到步骤3.4;否则转到步骤3.3.
步骤 3.4.输出BSO 全局最优位置对应的权值和阈值,即IRELM 的最优初始权值和阈值.
步骤 4.将测试数据输入到训练好的BSOIRELM 入侵检测模型中,进而得到每条数据的分类结果.
2.3 BSO-IRELM 伪代码
BSO-IRELM 伪代码如下所示:


2.4 算法复杂度分析
2.4.1 LU 分解复杂度
线性方程组的求解方法较多,直接使用矩阵求逆计算不仅对硬件资源的占有量有影响,还影响权值的更新速度.因此,对于硬件平台来说,由于物理资源有限,需要找到一种低能耗且快速的求解方法.矩阵求逆的计算步骤繁多,运算量大,时间复杂度高,所以在使用硬件实现时考虑采用LU 分解法.为进一步说明LU 分解的优势,对矩阵求逆和LU 分解作如下分析: 对于n阶的方阵,矩阵求逆的算法复杂度为 O (n3),LU 分解的算法复杂度为O(2/3×n3),虽然二者数量级相同,但因系数存在差异,因此在运行时间上存在显著差异.为更加直观地说明两种算法的复杂度,对一个10 阶矩阵进行实验,结果表明,矩阵求逆的运行时间为0.4491 s,LU 分解的运行时间为0.0479 s,运行时间大大缩短.本文后续使用数据集的维度远远大于10 阶,故使用LU 分解的优势将更加明显.
2.4.2 BSO 算法复杂度
假设算法最大迭代次数为tmax,维度为D.在BAS 算法中,初始化天牛个体,其算法复杂度为O(D).在每一次迭代中需要完成以下步骤,先计算天牛个体的适应度值并找出当前最优位置,其时间复杂度为 O (1),之后天牛个体更新位置,其时间复杂度为 O (1),故一次迭代的算法复杂度为O(1+1).总的时间复杂度为 O (tmax(1+1)+D),即为O(tmax).相比于BAS,BSO 使用群体,假设种群规模为N,初始化种群,其算法复杂度为 O (ND).在每一次迭代中需要完成以下步骤,先计算天牛群的适应度值并找出种群中个体最优和全局最优,其时间复杂度为 O (N),之后天牛群位置更新,其时间复杂度为 O (N),故一次迭代的算法复杂度为 O (N+N).总的时间复杂度为 O (tmax(N+N)+ND),即为O(tmaxN).故BSO 总的时间复杂度大于BAS,但BSO 克服了BAS 极易陷入局部最优以及搜索范围有限的缺点,提高了BSO 的收敛精度.
2.4.3 BSO-IRELM 算法复杂度
假设算法最大迭代次数为tmax,种群规模为N,所求问题维度D=(innum+1)×midnum+(midnum+1)×outnum.在BSO-RELM 模型中,BSO 使用Tent 映射反向学习初始化种群,其算法复杂度为O(ND).计算种群的适应度函数值并找出种群中个体最优和全局最优,其时间复杂度为 O (N).在每一次迭代中需要完成以下步骤,根据训练集通过矩阵求逆计算天牛群的适应度函数值,其时间复杂度为O(midnum3×N),之后找出种群的个体最优和全局最优,并对天牛群位置更新,其时间复杂度为O(N),故一次迭代的算法复杂度为 O (N+midnum3×N).最后,使用测试集对BSO-RELM模型进行性能测试,其时间复杂度为 O (midnum3).总的时间复杂度为O(tmax(N+midnum3×N)+ND+N+midnum3).相比于BSO-RELM 模型,BSO-IRELM 中通过LU分解求解天牛群适应度函数值,其时间复杂度为O(2/3×midnum3×N),总的时间复杂度为O(tmax(N+2/3×midnum3×N)+ND+N+2/3×midnum3).故BSO-IRELM 的时间复杂度远小于BSO-RELM,且其检测精度远优于BSO-RELM.
3 实验结果
3.1 实验参数设置
模型中参数设置如下.
1)群智能算法参数[27]如表1 所示.
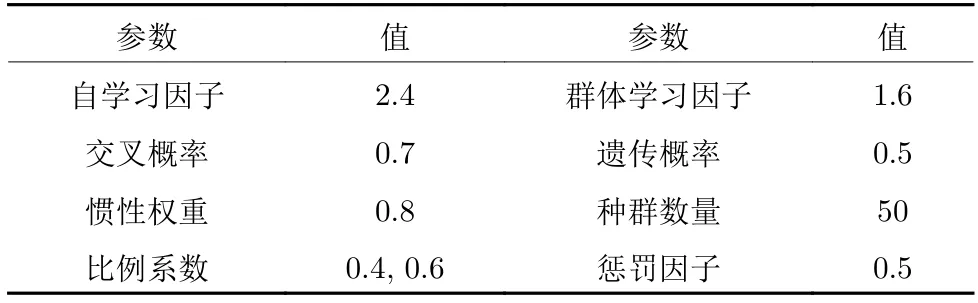
表1 群智能算法参数Table 1 Swarm intelligence algorithm parameters
2) RELM 神经网络模型参数为: 100-50-1,迭代次数为100.
RELM 模型参数通过GA-RELM 二分类实验确定.迭代次数设置为100,隐含层单元分别为20,30,40,50,60.实验结果表明,包含50 个隐含层单元的模型具有最优的检测准确率.当把隐含层的个数从50 增加到60 时,入侵检测的准确率有所下降.保持隐含层单元数量不变,增加迭代次数,模型的检测性能也只会由于过度拟合而产生波动.
3.2 实验数据集
模型中使用到的数据集如下.
1) UCI 数据集[28]如表2 所示.

表2 UCI 数据集Table 2 UCI dataset
2)入侵检测数据集[29]: NSL-KDD 数据集,训练样本9850 条数据,测试样本2000 条数据.
3.3 UCI 数据集实验结果
为了验证算法的有效性,在UCI 数据集上将BSOIRELM与IRELM、GA-IRELM、PSO-IRELM、BSO-RELM 以及传统RELM 进行对比.
在表3~ 5 中列出了各算法的性能评价指标,并在图6 中给出了部分算法的预测结果.从图6 可以直观地看出,BSO-IRELM 算法具有较好的预测结果,在Iris 数据集中,BSO-IRELM 的真实值和预测值完全重合,可以实现完美分类;在Wine 数据集中,BSO-IRELM 仅存在一个错误分类.从表3~5 中可以看出,各算法的性能评价指标均较优,这与本文估计基本一致.因为两个数据集的大小相当,且是平衡数据集,所以检测结果较理想.相比于PSO-IRELM 和GA-IRELM,BSO-IRELM 的性能评价指标均有所提高,这充分说明BSO 算法较PSO算法和GA 算法具有更优的寻优能力.此外,在所有测试条件下,BSO-IRELM 的各项性能也优于BSO-RELM、IRELM 和传统的RELM 算法,这说明了引入LU 分解法以及BSO 算法的必要性,同时也验证了之前关于RELM 存在潜在问题的假设.从而验证了BSO-IRELM 算法具有较优的分类性能,因此,进一步将BSO-IRELM 算法应用到网络入侵检测中验证它的可行性.

图6 部分算法在UCI 数据集上的检测结果Fig.6 The detection results of part algorithm on UCI dataset

表3 各算法在UCI 数据集上的准确率(%)Table 3 Accuracy of each algorithm on UCI dataset (%)
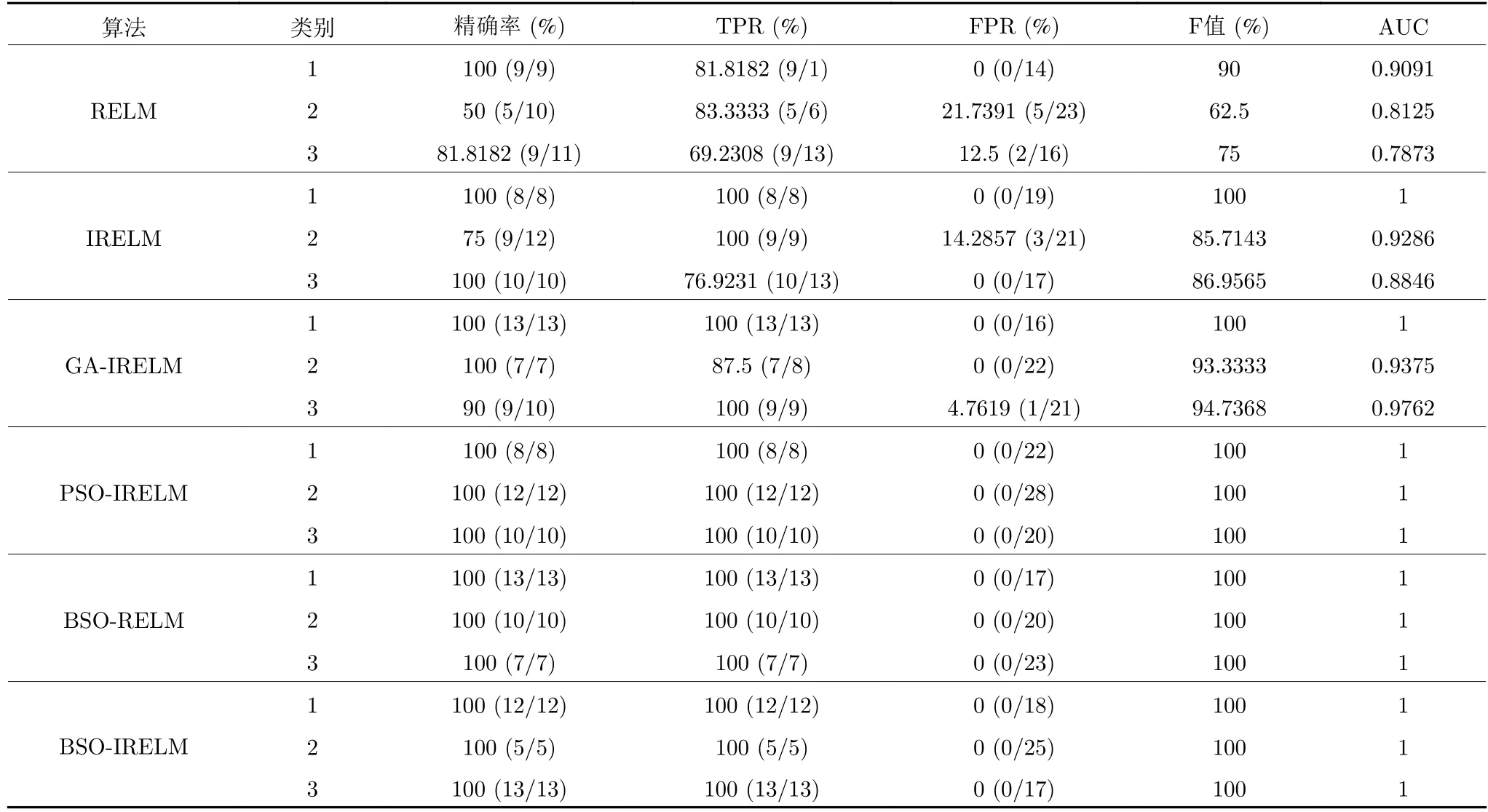
表4 各算法在Iris 数据集上的性能评价指标Table 4 Performance evaluation index of each algorithm on Iris dataset
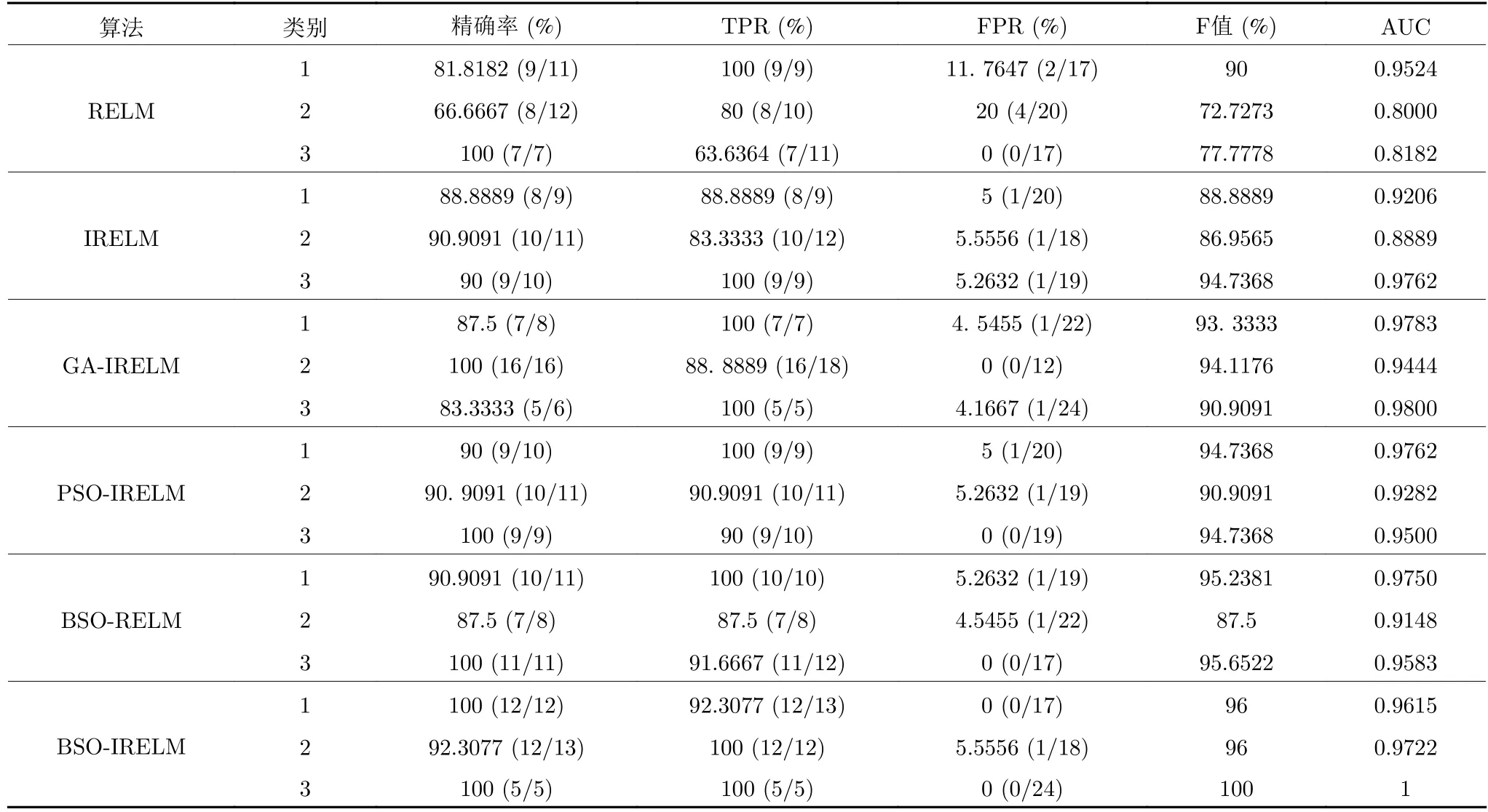
表5 各算法在Wine 数据集上的性能评价指标Table 5 Performance evaluation index of each algorithm on Wine dataset
3.4 NSL-KDD 数据集2 元分类实验结果
将4 类攻击合并为Abnormal (非正常),标记为2,正常数据(Normal)标记为1,实验转化为2元分类问题.表6 和表7 给出了各算法的实验结果.图7 和图8 分别给出了2 元分类混淆矩阵和ROC(Receiver operating characteristic)曲线对比图.从表中可以看出,BSO-IRELM 在检测正常数据和攻击类型数据方面效果较好.由于2 元分类数据集是非平衡数据集,2 种数据数量相差较大,所以准确率无法反映非平衡数据集的真实情况,故除准确率外,还从精确率、真正率(True positive rate,TPR)、假正率(False positive rate,FPR)、F 值和AUC (Area under curve)对2 元分类进行评价,上述指标的计算方法参照文献[30].在大多数测试条件下,BSOIRELM 的性能优于BP、LR (Logistics regression)、RBF (Radial basis function)、AB (AdaBoost),可以取得与PSO-IRELM、GA-IRELM 和SVM(Support vector machine)相近的分类性能,总体上优于PSO-IRELM、GA-IRELM 和SVM.且性能远优于IRELM 和传统RELM.特别地,BSOIRELM 的F 值和AUC 均最优,但在精确率方面,比BP 差2.6477%,在真正率方面,比LR 差1.94814%,而在假正率方面,比PSO-IRELM 差0.3509%.由于测试集是由随机选取的2000 条数据组成,BSOIRELM 中攻击类型数据所占比重较大,故精确率、真正率和假正率略差.混淆矩阵将数据集中的记录按照实际结果和预测结果进行汇总,实现可视化.从图7 可以看出,BSO-IRELM的分类模型最准确,因为此时一、三象限对应位置的数值最大,而二、四象限对应位置的数值最小,且BP 用于入侵检测的能力最差,相比于各算法,BP模型将大量攻击类型数据预测为正常类型,会给网络安全带来很大的威胁.此时BP 神经网络可能因为训练过程中,权值收敛到局部极小点导致网络训练失败.ROC 曲线图是反映真正率和假正率之间关系的曲线.曲线将整个图划分为两个部分,曲线下部分的面积即为AUC,用来表示预测准确性,AUC 越高,说明预测准确率越高.从图8 可以看出,在各算法中,无论检测正常数据还是攻击类型数据,BSO-IRELM 的AUC 均较优,但相比于RBF 的正常数据检测差0.0359.在大多数情况下,BP、SVM 的AUC 优于IRELM 和传统RELM,但相比于PSO-IRELM、GA-IRELM以及BSO-IRELM,AUC 均较差.这充分说明,RELM 潜在的参数问题对于分类性能的影响,突出了引入LU 分解法以及BSO 算法的必要性,验证了BSO-IRELM 相比于BP 和传统RELM对于2元分类的入侵检测具有较好的检测性能.
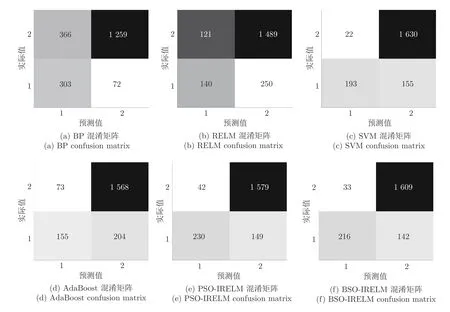
图7 2 元分类混淆矩阵Fig.7 Binary classification confusion matrix
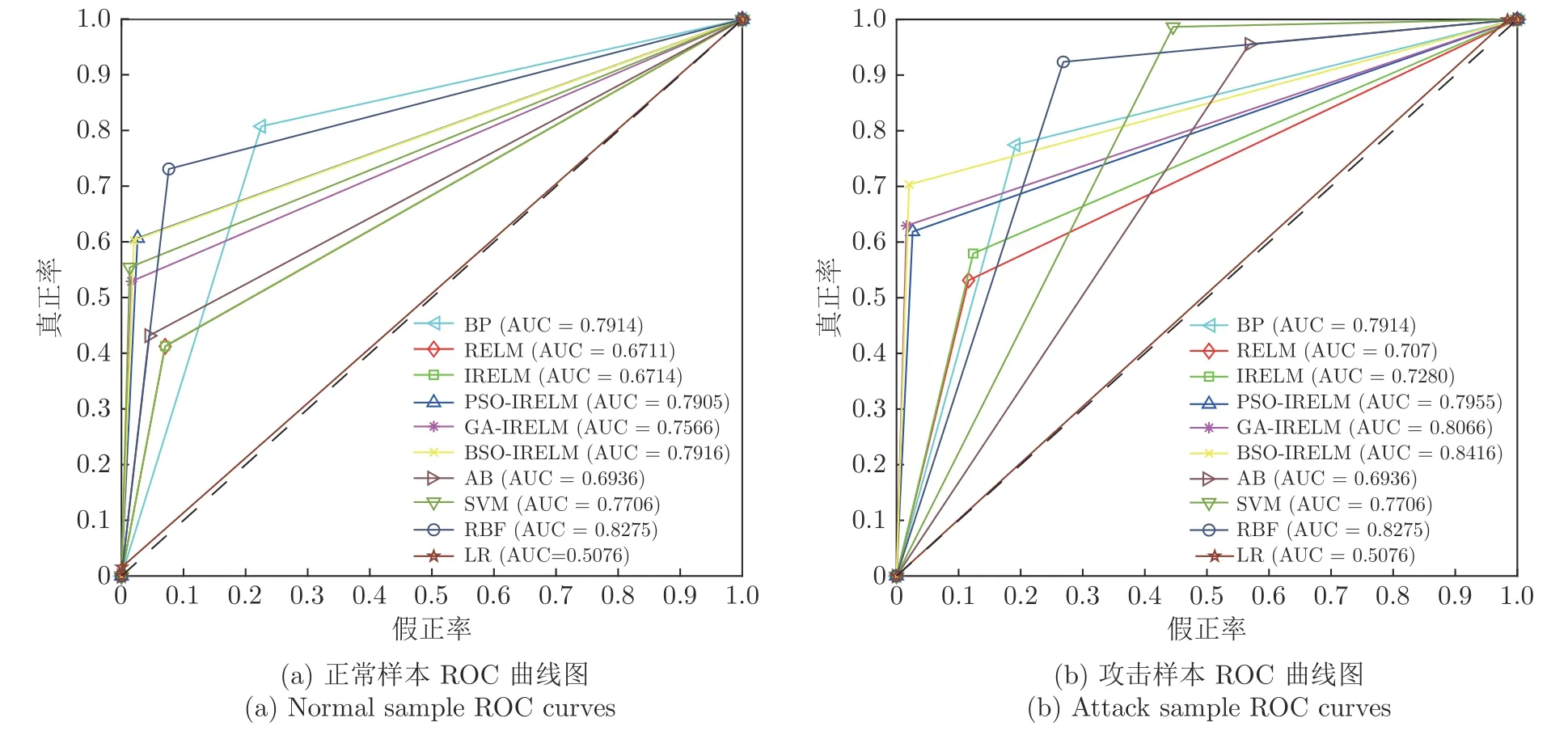
图8 2 元分类ROC 曲线对比图Fig.8 Binary classification of ROC curve comparison diagram
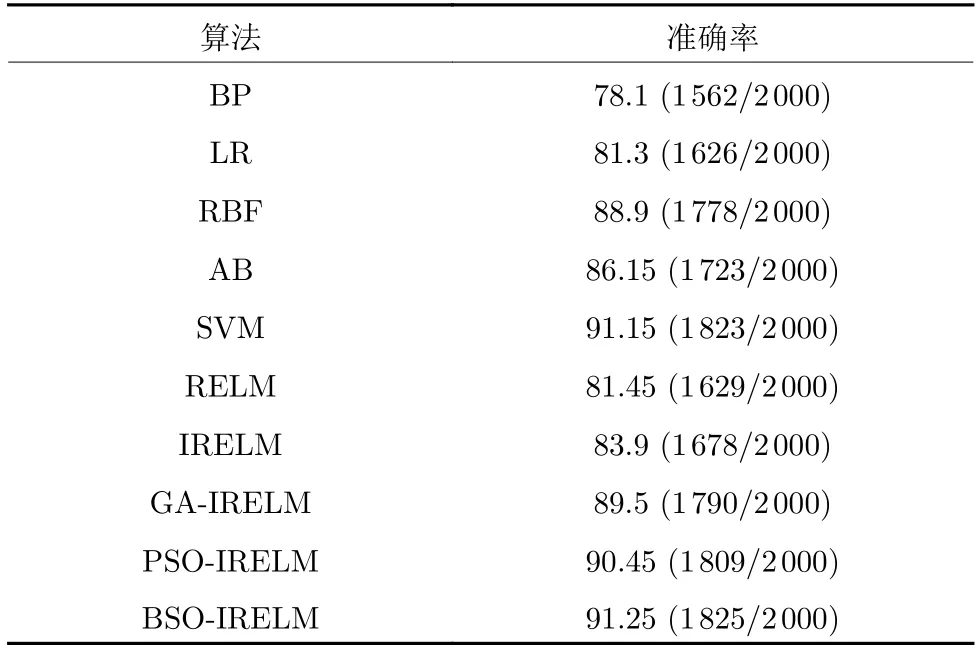
表6 各算法的准确率(%)Table 6 Accuracy of each algorithm (%)

表7 各算法的性能评价指标Table 7 Performance evaluation index of each algorithm
3.5 NSL-KDD 数据集多元分类实验结果
Normal、Probe、DoS、R2L、U2R 各为一类,分别记为1,2,3,4,5,实验变成多分类.在表8~ 13中列出了对比结果,并在图9 中给出了多元分类混淆矩阵,在图10 中给出了多元分类ROC 曲线图.
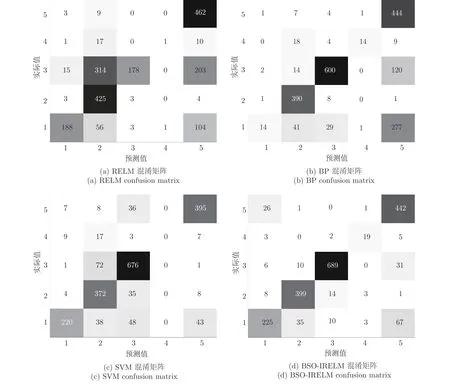
图9 多元分类混淆矩阵Fig.9 Multiple classification confusion matrix
从表8 可以看出,BSO-IRELM 的准确率最高,为88.7%,其他算法,如BP、LR、RBF、AB、SVM、RELM、IRELM、GA-IRELM 和PSO-IRELM 的准确率分别为73.1%,47.2%,81.95%,76.05%,83.15%,62.7%,71.9%,86.35%和86.15%.但由于NSL-KDD 多分类数据集仍是非平衡数据集,故从精确率、真正率、假正率、F 值和AUC 等方面进一步分析各算法的入侵检测性能.

表8 不同算法检测准确率(%)Table 8 Accuracy of different algorithms (%)
从表9 可以看出,对于Normal 类型数据,BP和LR 的综合检测性能最差,真正率仅为3.8647%和3.6723%,较BSO-IRELM 差62.3091% 和62.5042%.大多数情况下,BSO-IRLEM 的分类性能与SVM、PSO-IRELM 以及GA-IRELM 相近,但较AB、RBF、IRELM 和传统RELM 性能均有所提升.由于BSO-IRELM 将大量正常数据误判为攻击类型,因而会导致精确率和假正率略差.

表9 各算法在Normal 上的性能评价指标Table 9 Performance evaluation index of each algorithm on Normal
从表10 可以看出,对于Probe 类型攻击,BP、AB、IRELM、GA-IRELM、PSO-IRELM 和BSOIRELM 的性能相近,远优于LR、SVM、RBF、RELM 的性能,但总体上BSO-IRELM 的性能最优.此时,除了LR 和RELM,其余各算法对于Probe类型攻击均具有较强的识别能力.
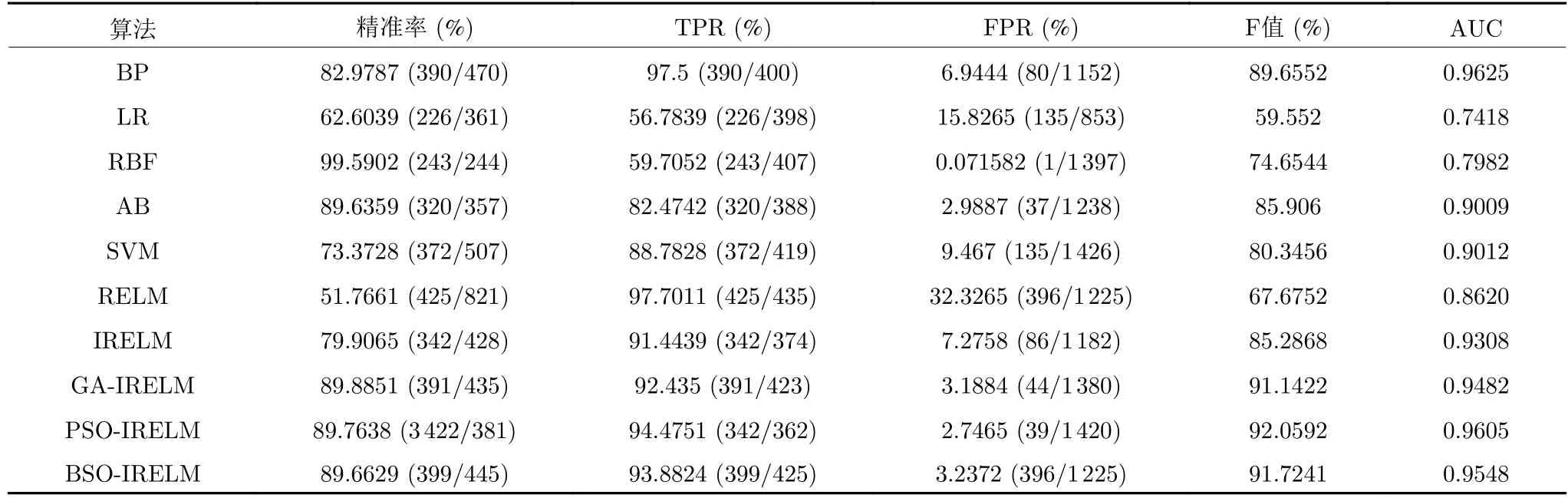
表10 各算法在Probe 上的性能评价指标Table 10 Performance evaluation index of each algorithm on Probe
从表11 可以看出,对于DoS 类型攻击,BSOIRELM 的检测性能最优,LR 检测性能最差,除传统RELM 和IRELM 的真正率较差,仅为25.0704%和54.0079%,其余各算法的性能评价指标均较优.由于DoS 的攻击数目最多,如果使用聚类大小进行判断需要单独处理,否则检测结果不理想.但本文判定是根据入侵数据与正常数据的差异,所以对于攻击数目较多的DoS 攻击仍具有较好的检测结果.

表11 各算法在DoS 上的性能评价指标Table 11 Performance evaluation index of each algorithm on DoS
从表12 可以看出,对于R2L 攻击类型,在大多数情况下,BP、RBF、RELM 和IRELM 的性能相近,效果均较差,LR、AB 和SVM 的检测性能最差,基本上无法正确识别R2L 攻击类型,而BSOIRELM 的性能较优,相比于RELM,精确率提高了42.3077%,效果显著,大大超出预想.R2L 攻击总数很少,而且许多R2L 入侵是伪装成合法用户身份进行攻击,这就使得其特征与正常数据包类似,造成R2L 攻击检测困难.但BSO-IRELM 相比于BP、LR、AB、SVM 和传统RELM,很好地学习了R2L 的特征,并将其正确分类.
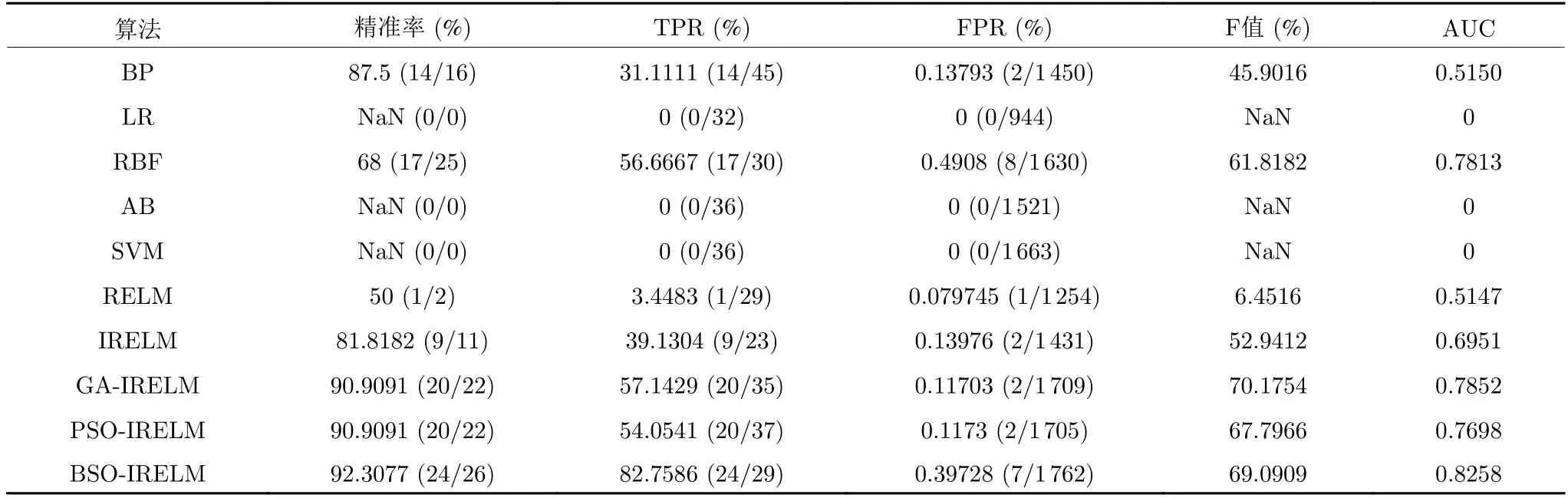
表12 各算法在R2L 上的性能评价指标Table 12 Performance evaluation index of each algorithm on R2L
从表13 可以看出,对于U2R 类型攻击,SVM、AB、GA-IRELM、PSO-IRELM 和BSO-IRELM 的性能相近,效果较优,BP、LR、RBF、RELM 和IRELM 的性能相近,效果较差,且BSO-IRELM 相比于BP、LR、RBF、AB、SVM 和传统RELM,分类性能均有所提高,AUC 分别提高0.0823、0.3940、0.0396、0.0230、0.0124 和0.054.本文对NSL-KDD数据集进行去重并随机产生测试集和训练集,可以在一定程度上降低不同数据类型数量之间的差距,使模型学习到更多的U2R 特征,虽然在某些方面检测性能未最优,但是整体检测性能较好地符合预期.
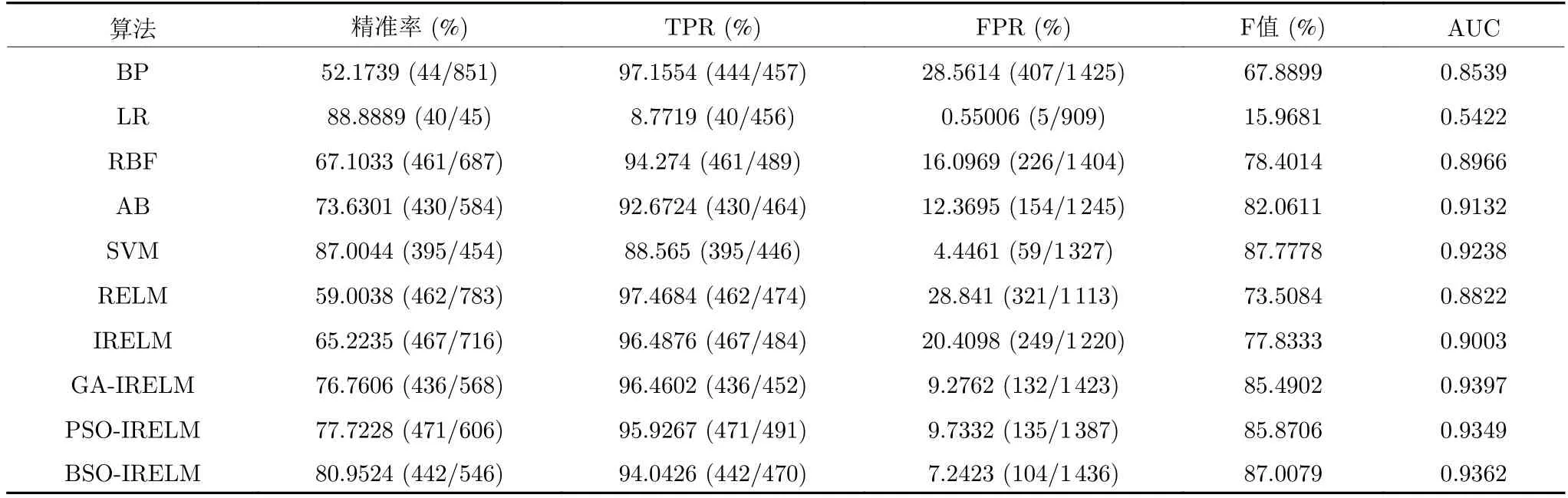
表13 各算法在U2R 上的性能评价指标Table 13 Performance evaluation index of each algorithm on U2R
当精确率和召回率发生冲突时,很难对模型进行比较.而F 值同时兼顾了精确率和召回率,可以看作是精确率和召回率的一种调和平均,能够更好地评价模型.BSO-IRELM 的F 值均较优,对Normal 类型数据,比LR 增加67.0051%;对Probe 类型攻击,比LR 增加32.1721%;对R2L 类型攻击,比RELM 增加62.6369%;对DoS 和U2R 类型攻击,BSO-IRELM 的F 值为各算法中最优的.由于DoS 和U2R 攻击类型数目较多,BSO-IRELM 的特征学习比较充分,所以对DoS 和U2R 攻击类型检测的F 值最优.表明特征库中的特征越多、越丰富,模型的分类效果越好.
混淆矩阵使用热度图,通过色差、亮度来展示数据的差异,易于理解.深色表示预测值和真实值重合较多的区域,浅色表示预测值和真实值重合较少的区域.从图9 可以看出,BSO-IRELM 的深色区域集中出现在混淆矩阵副对角线上,且副对角线之和为1774,其中BSO-IRELM 的分类准确率最优,符合预期.从混淆矩阵也可以看出实际分类情况,如RELM 将大量为DoS 类型攻击和Normal数据预测为U2R 类型攻击,BP 将大量的Normal数据和DoS 类型攻击预测为U2R 攻击类型.SVM基本上无法正确识别R2L 攻击类型.ROC 曲线存在一个巨大优势,当正负样本的分布发生变化时,其形状能够保持基本不变,因此ROC 曲线能够降低不同测试集带来的干扰,更加客观地衡量模型本身的性能.从图10 可以看出,BSO-IRELM 对DoS和R2L 攻击类型具有最优的AUC,对Normal 类型,LR 的AUC 较BSO-IRELM 差0.3007,对Probe 类型攻击,RELM 的AUC 较BSO-IRELM差0.0928,对U2R 攻击类型,BP 的AUC 较BSOIRELM 差0.0823.同时,LR 对各种类型的AUC均较差,AB、SVM、LR 对R2L 攻击类型的AUC均为0,BP 对Normal 类型和R2L 攻击类型的AUC 均较差.
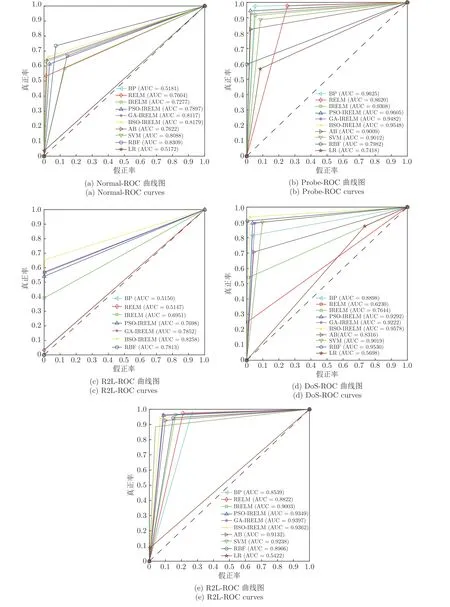
图10 多元分类ROC 曲线对比图Fig.10 Multiple classification ROC curve comparison diagram
综上所述,在UCI 数据集上,BSO-IRELM的各项性能均优于IRELM 和传统的RELM 算法,这说明引入LU 分解法以及BSO 算法的必要性,同时也验证了之前关于RELM 存在潜在问题的假设.从而验证了BSO-IRELM 算法具有较优的分类性能.在NSL-KDD 数据集上进一步进行2 元与多元分类入侵检测,在大多数情况下,BSO-IRELM 的性能优于BP、LR、RBF、AB、SVM、IRELM、GAIRELM、PSO-IRELM 和传统RELM 算法.
4 结束语
本文提出了一种基于天牛群优化与改进正则化极限学习机(BSO-IRELM)的网络入侵检测算法,有效解决了现有方法存在的准确率、精确率、真正率、假正率等偏低的问题.算法使用了LU 分解以求解RELM 的输出权值矩阵,并设计了天牛群优化算法BSO,实现了对RELM 的权值和阈值的联合优化.实验结果表明,无论在机器学习数据集UCI或网络入侵检测数据集NSL-KDD 上,与已有方法相比,BSO-IRELM 算法在各种评价指标上都具有明显优势.下一步研究的重点是扩展BSO-IRELM的检测应用领域,检验其在网络安全威胁检测(如病毒检测、漏洞检测等)中的使用效果.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
小哥白尼(野生动物)(2021年1期)2021-07-16
邮电设计技术(2021年2期)2021-03-13
成都信息工程大学学报(2021年6期)2021-02-12
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
小学生必读(低年级版)(2018年10期)2019-01-04
故事作文·低年级(2018年10期)2018-10-25
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27