深度EM 胶囊网络全重叠手写数字识别与分离
2022-12-31 02:56姚红革董泽浩喻钧白小军
自动化学报 2022年12期
姚红革 董泽浩 喻钧 白小军, 2
识别并分离高度重合数字对象的问题由Hinton等[1]于2002 年提出,多年来也有其他研究者在该领域进行了研究,如Goodfellow等[2]使用深度卷积网络,Ba等[3]使用视觉注意力机制和Greff等[4]使用深度无监督分组进行尝试.他们均是利用对象形状的先验知识进行分离.在性能最好的Ba等[3]的研究中虽然实现了95%的识别率,但图片也只是4%的重叠率.
直到Sabour等[5]所研究的胶囊网络CapsNet面世,重叠手写体识别成功率才有了大幅提高,当重叠率80%时识别率可达95%.胶囊网络的主要特征是,使用胶囊神经元代替了普通神经元,使用向量代替了在网络中流通的标量.胶囊神经元除了承载着网络权值的联系之外,其向量内部也存在着维度上的联系,丰富了图像特征的表达与提取能力.在CapsNet 中使用了迭代路由算法,该算法用向量内积来表示向量方向的同向程度,动态路由通过迭代来实现.CapsNet 将最突出的向量作为分类结果输出,向量的突出程度跟胶囊内与输出向量方向相近的向量数目和模长正相关.为避免在使用内积作为衡量手段出现无上界的情况,对向量进行了输出前的压缩.
CapsNet 的优势是简单易实现,但在使用它进行全重叠数字图片识别时发现,由于网络深度宽度不足,中间向量的规模太小,同时内积路由算法效率低.这些因素降低了网络的速度,影响了网络的聚类效果,从而使网络对图像特征提取不够充分,在分类时表现不佳,导致重构出来的分离图片不够准确和清晰.为了提高对全重叠手写数字的识别精度,基于CapsNet,本文提出以下改进方法:
1)首先对胶囊网络CapNet 进行加深.在它的Conv1 层之后加入一层卷积层 “卷积层2”,提高目标特征提取能力;另外在CapNet 的DigitCap 之后,对应本文 “初级胶囊层(胶囊部分)”之后加入一层全连接胶囊层 “聚类胶囊层1”,增加聚类能力以增强网络识别能力,参见图1(a).

图1 深度胶囊网络结构图Fig.1 Deep capsule network structure diagram
2)提高胶囊维度为16 维.这样使各个胶囊层胶囊统一维度为16 维,既提高了胶囊对图片特征表达能力,减少维度转换时系统消耗和信息的丢失和变异,也便于各层间信息的传输.
3)用EM (Expectation-maximization)向量聚类取代原路由聚类,提高聚类效果.胶囊网络中向量神经元将低级特征预测为高级特征,输出向量的分布符合以不同高级特征为期望的混合高斯模型[5].混合高斯模型是有限混合概率分布模型,其可用EM 算法找到最大似然估计[6−7].通过假设隐变量的存在,简化似然函数方程的求解[6−8].基于此特点,本文将EM 聚类改为EM 向量聚类,并用它取代胶囊网络中的迭代路由,提高了聚类效果.也减少中间变量的产生,降低显存以及空间消耗,总体提高系统的运行效率.
4)设计了一个并行重构网络.因为要分离两个重叠的数字,需要取两个模数最长的向量来进行重构,因此数字重构网络必须要设计成并行的两个网络结构,才能对模数最长的两个向量分别并行重构.依据这一想法,本文设计了一个双并行重构网络结构,实现了对两个全重叠手写数字的分离重构,参见图1(b).
1 相关工作
胶囊网络的思想最早出现于Hinton等[7]提出的分组神经元.基于此,Sabour等[5]进一步提出胶囊间的动态路由算法,该算法使胶囊进入了初级应用阶段.尽管是初级应用,但它实现了目标属性间的 “等变性” (Equivariance),“等变性”保留有图像各部分信息间的关联.而在此之前的神经网络只是实现空间不变性,空间不变性实现的一般方法是卷积神经网络(Convolutional neural network,CNN)的池操作,空间不变性与 “等变性”比较丢失了图像各部分间的关联信息.它的实现要归因于网络内的动态路由算法,但动态路由算法优化能力较弱,于是 Wang等[9]通过引入耦合分布KL (Kullback-Leibler)散度来优化动态路由,使胶囊网络性能获得一定的提升.胶囊网络的又一应用是CapsGan[10]网络,它使用胶囊网络作为生成式对抗网络(Generative adversarial network,GAN)中的甄别器,比CNN 的GAN 获得更好的生成效果.以上方法均是对胶囊网络优化和新领域的应用,在网络构造上基本没有改变.
LaLonde等[11]和 Rajasegaran等[12]对胶囊网络结构进行了加深.LaLonde 等通过卷积,让所有胶囊沿深度方向作为输入进行转换,包含在较高层的胶囊里.加深胶囊层必定增加动态路由量,引起计算复杂度的增加.为了降低计算复杂度,Rajasegaran等[12]采用了如下措施: 在初始阶段减少路由迭代次数;在路由中间层使用三维卷积,采用参数共享而减少参数的数目;同时提出本地化路由代替完全连接的路由.新加深的胶囊网络具有捕获更细致信息的能力,增强了它的实际应用能力,可以处理比MNIST 数据集更复杂的数据集.本文对胶囊网络的加深主要体现在前端的特征提取和后端的分离方面,目的是增强对重叠手写体的识别能力和分离能力.
将EM 算法应用于胶囊路由也起源于Hinton等[13]的研究之作,底层胶囊的姿态矩阵通过与转换矩阵相乘而得到高层胶囊的姿态矩阵,这个过程可以看作是每一个底层胶囊对高层胶囊所表达图像特征的投票.投票通过分配一个权重系数来实现.这个系数是由EM 算法进行循环更新的,通过EM算法系统将底层胶囊的输出路由给高层胶囊.底层胶囊与高层胶囊的这种联系反应的是图像中实体的整体与部分间关系,它使胶囊网络具有了对所关注实体的视角不变性.EM 算法在文献[13]中是直接应用,并未改动.本文依据输入向量的独立性对EM算法的E (Expectation)步进行了改进,并依信息熵重新定义了混合度,优化了胶囊间的迭代,加速其收敛,并将其用于手写体数字分离中,相较于文献[13]分离效果有了明显提高.
Mixup[14]和Between-Class learning[15]是两个对类别不同的样本进行重叠的算法,可以是两个图片按不同混合比的重叠.其目的是通过丰富训练样本的状态来提高所训练模型的泛化能力.Mixup和Between-Class learning 算法说明将不同类别的图片重叠来训练模型能提高模型的分类能力.这一点与本文方法相同.但这两种方法目的是分类,不能将混合的像素按图像本来分离.本文方法是基于细致识别下的重叠图片的重构分离.
2 DCN 网络
基于胶囊网络CapsNet,本文构建了一个以EM为向量聚类的深度胶囊网络(Deep capsule network,DCN),其网络结构如图1 所示,由分类网络(参见图1(a))和重构网络(参见图1(b))组成.
因为卷积层在神经网络中具有提取多级特征的能力,而且可以通过卷积核的共享降低运算量.因此在DCN 中,使用了两个卷积层对输入图像的特征进行提取,其中卷积层1 使用512 个 9×9 的卷积核对图像进行卷积在卷积层2 中使用256 个5×5 卷积核进行卷积,最终得到 256×16×16 的特征图.
然后构建一个初级胶囊层,其前半部分通过多重卷积获得一组 32×16×6×6 的标量,由其后半部分的胶囊生成一组由16 维向量组成的1152 个向量神经元,每个神经元输出一个16 维的向量.在每个 6×6 的网格中,设定权重共享给每一个胶囊,然后对每个输出向量进行输出.
接下来使用两个聚类胶囊层进行最终的分类,增加的聚类胶囊层1 是对初级胶囊中的向量,通过EM 向量聚类进行初步筛选,形成较为高级的有明显倾向性的高级向量给聚类胶囊层2,然后再由聚类胶囊层2 进行第2 次EM 向量聚类,细选出可用于表示不同类别信息的向量.在每次聚类之后是压缩.聚类的过程使得高级特征更集中,压缩的目的是为了限制向量的模长.模长被限制于0~ 1 之间,用以表达其所属类别的概率.再由最后一层产生10 个16 维的向量代表0~ 9 的10 分类结果,作为输出.
在检测重叠手写数字时,选取输出模最长的前两个向量作为最可能重叠的结果进行输出.如果模长第二的向量模长不足0.1,就认为是由两个分类相同的数字叠加而成.
重构由重构网络完成,本文重构网络是由两个结构相同的3 层全连接网络构成,详见图1(b).重构时选取 “分类网络”输出的模长最长的两个向量,为避免其余8 个向量的干扰,将其全部值置为“零”.然后将这10 个16 维向量,首尾接续分别传入两个并行重构网络进行重构.
2.1 姿态变换矩阵
底层胶囊所生成的向量可以认为其代表了某种低级特征,该低级特征通过姿态变换矩阵可对高级特征进行预测,这种预测是对向量的方向以及维度的变换,其表达式为

其中,U(l+1,j)表示在第i层中第j个胶囊的预测向量,即预测结果.W(i,j)表示由l层的i胶囊输出到第l+1 层中第j个胶囊特征的姿态变换矩阵.V(l,i)表示第l层中第i个胶囊的输出向量.
2.2 EM 向量聚类算法
胶囊网络中向量神经元将低级特征预测为高级特征,输出向量的分布符合以不同高级特征为期望的混合高斯模型[5].基于此,将EM 聚类改造成为EM 向量聚类,用它取代胶囊网络中的迭代路由,以优化系统,提高其运行效率.
2.2.1 EM 向量聚类
经过姿态变换方程产生的一组预测向量是符合混合高斯分布的[5],如式(2)所示,经过多轮迭代获得概率最大的分布函数[6−7],作为胶囊的输出.

其中,j代表类别,X为输入向量,αj为第j类的概率且 Σjαj=1,µj为第j类的向量期望,Σj为协方差矩阵.
因为低级特征来自于输入图像的变换结果,所产生的向量之间可以认为是相互独立的,因此协方差矩阵是一个对角阵,这样就相当于输入X在各分量解耦.所以本文相较于标准EM 迭代算法进行了改动,即

因为将输入分布视为混合高斯分布进行聚类,聚类中心向量是类内向量的加权平均,无法通过模长来衡量显著性.所以引入一个标量aj作为缩放尺度来衡量显著性,并在输出之前代入asquashing 函数来控制输出向量的模长.
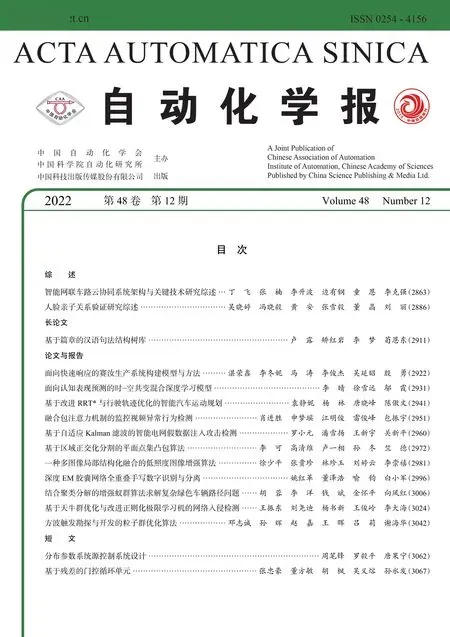
用EM 聚类结果得到输出高斯分布的方差,方差越大意味着预测向量分布越接近均匀分布,说明这个输出胶囊输入的预测结果并不明显接近同一种特征,此时aj应该小;方差越小意味着分布越集中,说明这个输出的输入的预测结果大致相近,此时aj应该大.基于这种思想选择使用信息熵Cj来辅助aj衡量特征的显著程度[6−7, 16],Cj表达式可定为
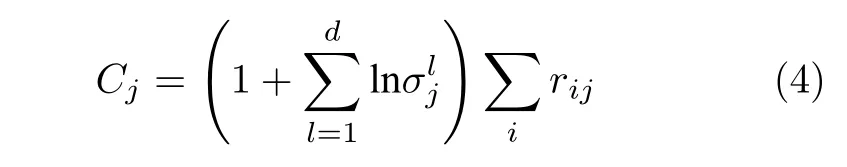
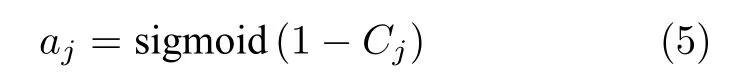
当分布的方差越小时Cj的值越小,因此通过最大化Cj的方式实现迭代优化.为防止无上限的情况,在此采用sigmoid 激活函数.
2.2.2 算法流程
EM 向量聚类算法的流程如图2 所示.
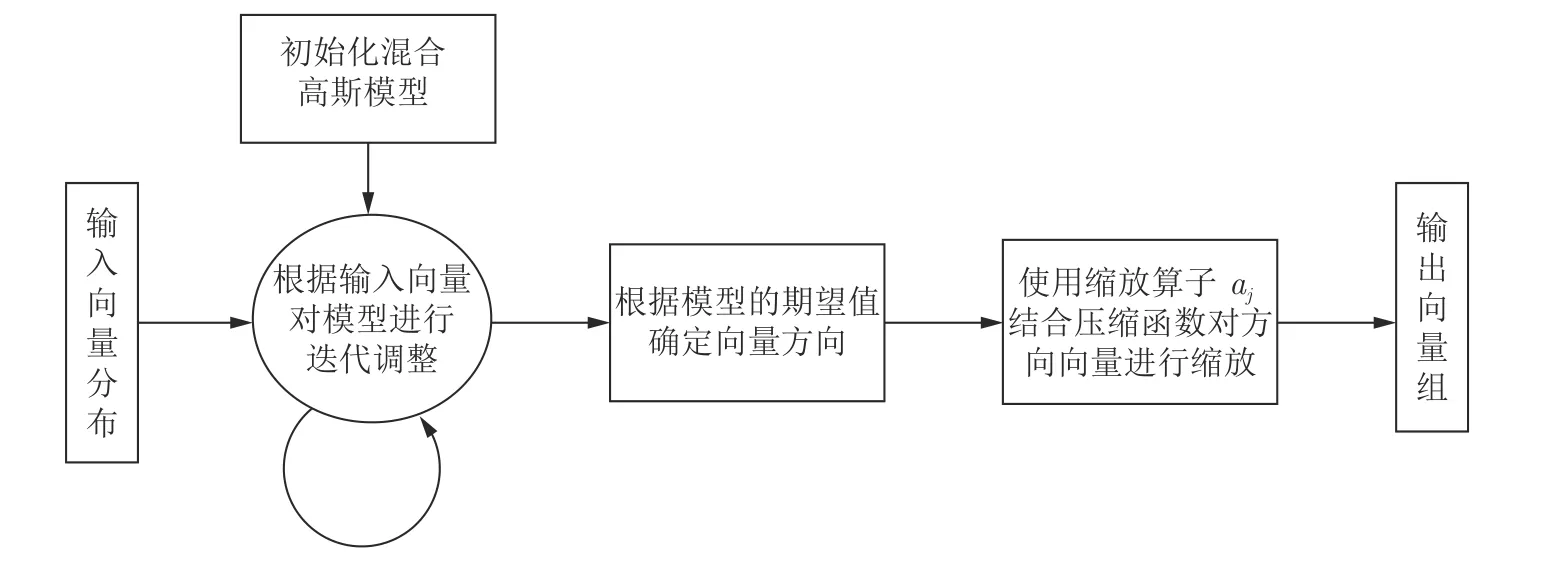
图2 EM 向量聚类算法流程图Fig.2 Flow chart of EM vector clustering algorithm
在已知Uij,Sj,aj的情况下,其中Uij表示l层的第i个胶囊输出经过姿态转换矩阵处理后向l+1层的第j个高层胶囊输出的向量预测;Sj表示l+1层胶囊的输出方向;为l+1 层胶囊的输出方向的方差;aj表示其特征的显著程度.EM 向量聚类的具体算法流程如下.
算法 1.EM 向量聚类算法


在进行多次迭代之后,以概率aj作为j胶囊的输出尺度,对输出的方向向量进行缩放,得到最终的输出向量,即
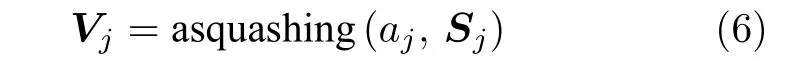
式中,asquashing 为压缩函数,参见第2.3 节.
2.3 压缩函数
为了防止胶囊向量在后续运算中无限增长导致网络 “爆炸”,同时又能用其模长表示分类概率,使用一个非线性函数对这些向量进行压缩,并使模长维持在0~ 1 之间.这也在一定程度上抑制了与当前高级特征相关性小的向量.压缩函数asquashing为

其中,Vj表示最终输出向量,Sj表示在进行压缩之前的原始输出,aj是缩放尺度.
2.4 并行重构损失
为了实现对并行重构网络(见图1(b))的训练,构建了一个并行重构损失函数Lrecon,通过使用均方误差计算输入图片与输出图片的差来实现,即
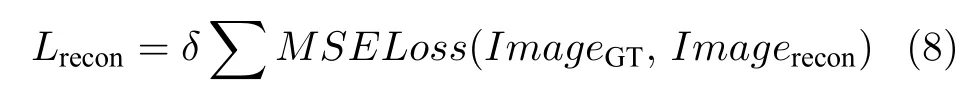
式中,ImageGT为叠加前的真值图像,Imagerecon为重构后的结果,δ为重构损失的缩放倍数.当重构损失在总损失中占比过大时会导致网络的过拟合,本文使用δ取值为0.0005 对重构损失进行缩放.
训练时选取模长最大的两个向量,同时放入两个重构网络进行训练.将上式的重构误差加入总损失函数中,参见第2.5 节,可以使重构网络与分类网络一起进行共同训练.
2.5 代价函数
因为重叠手写数字识别,需要进行两分类,也即需要最后输出的向量中有两个模长较长的向量.由于是双向量结果,所以要避免这两个向量间的竞争.在此选择使用Margin Loss 作为代价函数,它适用于双分类,在不同类识别结果之间不进行竞争,其具体形式为

式中,Lcls表示k个分类的胶囊的分类误差,Tk表示第k分类的标签值.
为防止过优化,将式(9)中的m−和m+分别设定为0.1与0.9.若为正标签,则式(9)的前半部分有效,希望正标签的胶囊输出的向量的模长vk保持在0.9 以上;若为负标签,则式(9)的后半部分有效,希望负标签的胶囊输出的向量的模长vk保持在0.1 以下.最后,将每个分类的损失函数值进行相加,再与重构损失Lrecon联合起来形成最终的损失函数值Ltotal,即

通过式(10)进行分类网络与重构网络的联合训练.
3 实验与数据分析
3.1 数据集
本实验采用的数据集为3 种: 1)MNIST 原数据集;2)全重叠数据集;3)前两种数据集的混合集.其中第2 种是由MNIST 原数据集生成,生成方式是将MNIST 数据集的一半(30000 幅图像),与另一半(30000 幅图像)进行叠加生成,重叠率为100%,也即全重叠生成,叠加后效果如图3 所示.

图3 全重叠数据集Fig.3 Full-overlapping dataset
标签是对原one-hot 标签进行处理后得到的,如表1 所示.若由两个不同数字叠加,将这两个数字的位置置为1,其他位置置为0;如果是由相同数字叠加,将其位置置为2,其他位置置为0.

表1 数据集标签Table 1 Dataset label
3.2 EM 向量聚类效果实验
3.2.1 EM 向量聚类模长
输出向量的模长是对分类概率的度量,模长越长属于该类的概率越高.它也是聚类效率和效果的反映,因为聚类是将正确的类别向量进行放大,提示降低不正确类别向量模长,所以越快达到高模长,说明所用聚类形式的效率越高,效果越好.
在DCN 结构上分别用MNIST 数据集、全重叠手写数字数据集以及混合数据集进行训练.对全重叠图片进行测试,以测试不同聚类迭代次数R下EM 向量聚类的模长,见图4 所示.以下本文实验不做特别说明时其值均为3,并与CapsNet 路由模长进行对比,如表2 所示,其为分别进行10 次测量的均值.
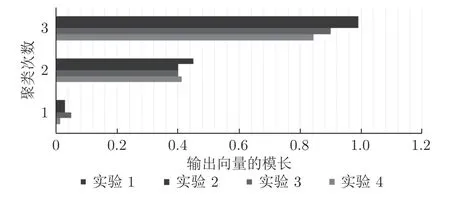
图4 不同聚类次数下输出向量的模长Fig.4 Module length of output vector under different clustering times
从表2 和图4 可发现,对重叠数字识别时,不同的聚类次数对输出向量的模长有着相当大的影响.在进行聚类之前,最长的输出向量只有不到0.1的长度,而在进行了3 次聚类之后,正确的向量的长度已经达到了0.85 以上(由于压缩函数的存在,向量的长度不能超过1).从表2 可见,DCN 所用EM 向量聚类效果,在第3 轮聚类时(R=3),在3个数据集下模长都明显高于CapsNet 的路由聚类,说明EM 向量聚类效果较路由算法更好.

表2 在不同聚类次数下的激活向量模长Table 2 Active vector module length under different clustering times
3.2.2 EM 向量聚类速度
在DCN 中一共进行两次EM 聚类,分别在初级胶囊层与聚类胶囊层1 之间和聚类胶囊层1与聚类胶囊层2 之间,见图1(a).因为聚类是一个无监督过程,该过程并不对学习参数进行保存,所以在每一次网络进行聚类时,都先初始化参数然后多次迭代.迭代过程无论在训练还是测试中都会进行,是整个网络中最耗时的部分.表3 是在不同的聚类次数之下网络进行一个Epoch 所花费的时间(实验平台是单张titan XP).从表3 可知,每次聚类中每增加一次迭代,训练时间都会增加近三分之一(对比进行一次聚类的网络).

表3 参数量与不同聚类次数下的单Epoch 消耗时间(s)Table 3 Parameter quantity and single epoch consumption time under different clustering times (s)
因为DCN 是原CapsNet 网络的加深与扩宽,DCN 的参数量达到了原CapsNet 网络的2.45 倍(增加140%),所以DCN 网络相较于CapsNet 网络能够提取更多细粒度特征,识别能力更强.但DCN 较CapsNet 的运行时间也增加了40%,如表3所示.
DCN 较CapsNet 在增加网络深度与宽度,从而导致训练参数量增加140%的情况下,对相同训练数据量的训练时间仅增加40%,缩短的运行时间可以认为是EM 向量聚类算法较CapsNet 迭代路由算法快的时间.这说明单纯就DCN 的EM 向量聚类算法,与CapsNet 的向量内积迭代路由算法比较,在速度上前者有明显优势.
在DCN 中,分别用迭代路由和EM 算法对单Epoch 消耗时间进行了实验,结果如表4 所示.在相同条件下,对于不同的迭代次数R,EM 算法较迭代路由算法消耗时间减少约30%~ 40%.

表4 DCN 不同聚类算法单Epoch 消耗时间(s)Table 4 Single epoch consumption time of different DCN clustering algorithms (s)
3.3 DCN 识别与分离
3.3.1 不同数据集上的识别率及对比
为了检测DCN 对全重叠手写数字数据集的识别率,用MNIST 数据集、全重叠手写数字数据集和这两种混合数据集训练,对得到的网络模型进行对比实验.设定了两组实验,分别对无重叠的字体识别以及对全重叠字体进行识别.
由表5 可知,DCN 使用MNIST与全重叠数据集混合训练得到的网络不仅在重叠目标识别任务上取得了96.55%的正确率,在无重叠的识别上的正确率也提高到了95.7%.
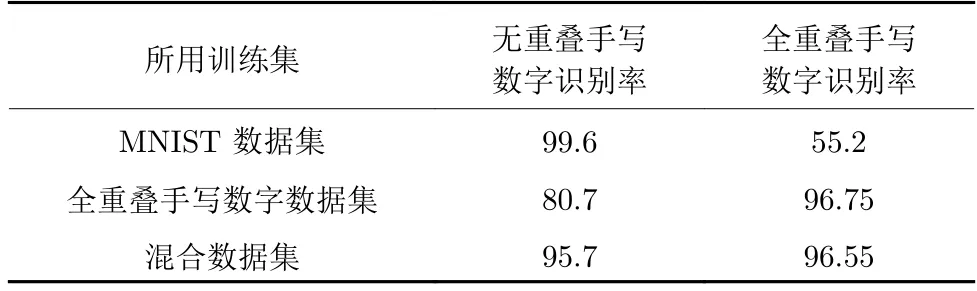
表5 DCN 识别手写数字效果对比 (%)Table 5 Effect comparison of handwritten digits recognized by DCN (%)
值得注意的是,使用MNIST 数据集训练的DCN 模型在全重叠的识别任务上得到了55.2%的正确率.尽管识别率不高,但这是在简单的数据集上进行训练而对复杂数据集的识别结果.一定程度反映了DCN 网络的特征提取,以及运用所提取低级特征对高级特征进行有效预测的能力.
同时,使用重叠手写数字数据集进行训练的DCN模型,在进行无重叠识别时,取得了80%的识别率.这表明在不进行特别的训练集设计时,DCN 网络可以在使用重叠图片进行训练后,对不重叠的图片进行识别,即在特征有区别的情况下,也能保证一定准确度的识别率.
DCN 模型对于全重叠手写数字测试集5000个测试样本的总体识别率达到了96.75%,其识别准确率与loss 值的变化曲线如图5 所示.
由图5 可知,在不到20 个Epoch 下测试准确率达到96%以上,损失由1 开始缩小至低于0.02,且其后没有反复,说明DCN “识别网络”运行收敛快且平稳,能够较好地将重叠的数字进行分类识别.
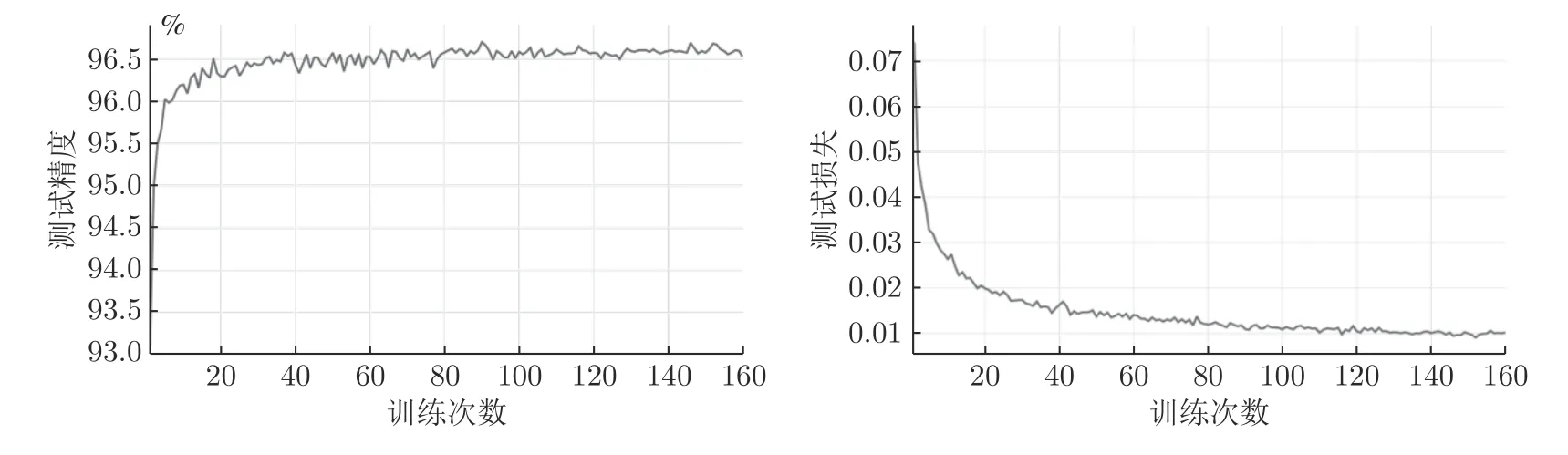
图5 DCN 对全重叠手写数字的识别率与损失函数值曲线Fig.5 Recognition rate and loss value curve of DCN for fully overlapped handwritten digits
与CapsNet 进行对比,CapsNet 在80%重叠率的MutiMNIST 数据集上取得了95%的正确率[5],在全重叠数据集中正确率只有88%.本文DCN 网络结果在全重叠识别正确率达到了96.75%,见表6所示.与CapsNet 对比在全重叠的情况下,DCN 识别准确率高于CapsNet.

表6 重叠手写数字识别率对比(R =3) (%)Table 6 Comparison of recognition rate of overlapping handwritten digits (R=3) (%)
3.3.2 分离效果
本文构建的DCN 重构网络见图1(b).其为对分类网络(图1(a))的输出向量进行重构,得到分离图片.在分离训练过程中,使用掩蔽的方法只把正确的数字胶囊的激活向量保留下来.然后用两个激活向量通过两个并行的重构网络进行重构,最终输出两幅 28×28 像素的灰度图片,显示已经分离的手写体数字的分离效果.
重构时的重构误差是通过计算重构图片的像素亮度以及与叠加之前的图片的像素亮度进行对比,然后加和得到,参见式(9).把得到的此重构误差按一定的占比放入到总误差中,参见式(11),然后对全网络进行统一训练,进而得到重构图片.
图6 显示了在不同缩放数量级的情况下,总损失函数值Ltotal的变化情况.由图6(a)中总损失函数值Ltotal升高的情况可以得知,在重构误差占比大于0.005 时网络出现了过拟合的情况.重构损失占比过大抑制了分类的损失Lcls,导致分类效果的下降.通过反复试调,将重构损失Lrecon占比降低至0.0005 时,重构损失才不会在训练过程中抑制Lcls的作用,得到的总损失Ltotal曲线收敛迅速,在20 Epoch 时Ltotal值下降到了0.02,而且下降平稳,没有反复,见图6(b)所示.

图6 重构loss 函数占比收敛对比Fig.6 Comparison of proportion convergence of reconstructed loss function
图7 为分离结果,图7(a)为100 个待分离重叠数字图片,图7(b)和图7(c)为分类网络识别后由重构网络所重构的分离结果.

图7 重构结果Fig.7 Reconstructing results
表7 显示的是8 个重叠图片的分离情况,其中标注 “∗”的3 组数字 “7”与 “9”的组合中,3 幅重叠图片均由相同数字不同写法的图片叠加而成,在进行准确分类之后,得到的重构结果与原本的数字一样,这说明整个网络对重叠数字分离准确,尽管这3 组数字笔画有些许区别,但网络进行了准确的识别与重构.(3,7),(9,1),(0,8),(0,4)这4 幅图片,重叠后图形复杂,“识别网络”识别准确,“分离网络”分离后字体笔划基本清晰.

表7 全重叠手写数字分类与重构的部分结果Table 7 Partial results of classification and reconstruction of fully overlapped handwritten digits
卷积在标注 “•”的数字 “5”与 “9”的组合中,原图叠加后的特征复杂,网络分类出现错误.由重构结果可以得知,DCN 网络依旧将数字 “9”完整地区分出来,但是将另一个数字 “5”识别成了数字“8”.说明网络对于极复杂的图片的识别不够理想,需要进一步提高.
3.4 对全重叠手写汉字的测试
用DCN 对CASIA 汉字手写图片集中的 “不”、“下”、“丑”、“世”、“专”、“王”、“也”、“卫”、“大”、“人”10 个汉字进行全重叠测试.共进行了150 个Epoch 训练,训练的平均识别率为92.7%,如见图8 所示.
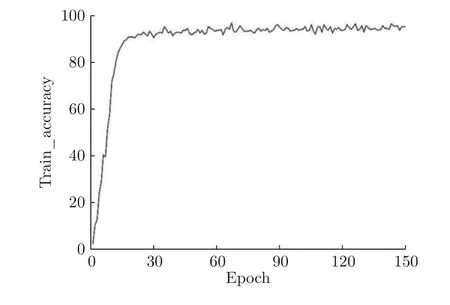
图8 训练识别率Fig.8 Training recognition rate
表8 是部分识别和分离结果.从中可以看出,对图片清晰、字体简单的汉字,识别结果准确,分离基本清晰.但对于字体复杂不规整的汉字,重叠图片识别率低,如最后两个标签(王,丑)、(也,卫)识别错误,分离结果模糊.

表8 部分识别和分离结果Table 8 Partial identification and separation results
对重叠汉字测试,DCN 在所选汉字较简单情况下测试识别误差为15.2%,相较MNIST 手写数字重叠识别误差较高.对于简单图片分离基本清晰,复杂图片识别与分离误差较高.
4 结束语
本文设计了一种深度胶囊网络模型DCN,它具有6 层网络结构,使用向量维数为16 维,用EM的向量聚类算法代替了原路由算法.同时构建了一个并行重构网络,以实现对重叠目标的分离重构.最后用不同的聚类次数与训练集对重叠手写体数字进行了识别实验,结果显示DCN 网络对全重叠手写数字识别率达到96%,超过了胶囊网络CapsNet在80%重叠率下识别率95%,分离重构图片的效果较好.但是DCN 对重叠数字的重构效果还未达到理想效果,重构目标还是有一定比例的模糊和近4%的识别错误问题,这将在后期工作中进行完善.后期工作也将进一步提高该方法应用于重叠手写汉字的识别.
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
现代装饰(2021年2期)2021-07-21
中国生殖健康(2020年7期)2020-12-10
小学生优秀作文(低年级)(2020年4期)2020-07-24
铁道通信信号(2020年8期)2020-02-06
网络安全和信息化(2019年11期)2019-11-25
科技与创新(2018年1期)2018-12-23
商周刊(2017年6期)2017-08-22
电子制作(2017年24期)2017-02-02