
面向边缘计算应用的拜占庭式容错分布式一致性算法
2022-12-30 14:09路红英
计算机与现代化 2022年12期
张 昊,路红英
(北京交通大学计算机与信息技术学院,北京 100044)
0 引 言
在云计算中,为保证服务的可用性与可靠性,业界广泛采用副本技术为服务在不同节点上构建多个副本,并采用分布式一致性算法维持副本间的一致性(Consistency)来预防停止运行(Fail-stop)错误[1]。一致性是指,在所有节点初始状态相同的条件下,执行相同的操作命令,最终所有节点会达成完全一致的状态[2]。Raft算法由于其简单易懂的设计成为了云计算中使用最广泛的分布式一致性算法[3],并广泛应用于Etcd、Zookeeper等分布式应用中。
随着物联网技术的发展,越来越多的物联网设备带来了数据量的爆炸式增长,而云计算现有的资源和带宽还不足以对这些数据进行高效处理,因此,作为云计算的有效补充,能够有效降低云中心计算负载的边缘计算模型得到了广泛的重视[4]。边缘计算是指在网络边缘端进行数据处理计算的一种新型计算模型[5],为用户提供了超低时延和高性能的计算服务解决方案[6]。在边缘环境中可以采用Docker容器技术来解决边缘节点异构性的问题,使其能够快速在边缘端快速部署或终止服务。通常会在边缘集群部署Docker Swarm、Kubernetes等容器编排工具来对容器进行保活、迁移、调度等[7]。为了监控整个边缘集群的全部资源和容器的运行状态,这些容器编排工具均引入Etcd、Zookeeper等组件同步资源和容器信息,同时保证边缘节点间的数据一致性[8]。专门为物联网和边缘计算设计的容器编排工具k3s也于v1.19.5+k3s1版本中将Etcd作为核心组件引入[9],由此可见,在边缘环境中保持分布式应用的数据一致性是有意义的。
此外,与云计算不同的是,边缘计算节点处于高度开放环境中,极易被俘获或被黑客侵入[10],为使边缘集群具有更高的可用性和可靠性,还需进一步使边缘集群具有容忍拜占庭错误的能力[11]。拜占庭错误这一概念由Lamport等人[12]首次提出,一般地,将节点伪造信息恶意响应的行为称为拜占庭错误,对应的节点为拜占庭节点。拜占庭容错是指发生拜占庭错误时,边缘集群仍然能够正常提供服务的能力。由于Raft算法基于所有的错误都是Fail-stop错误的假设[13],无法应对拜占庭错误,因此该算法在边缘环境中发生拜占庭错误时无法保证副本的一致性。
目前已经有许多关于拜占庭容错算法的研究,其主要分为工作量证明(Proof of Work, PoW )[14]、权益证明( Proof of Stake, PoS)[15]等概率一致性算法和以基于状态机复制技术的[16]绝对一致性算法。边缘环境中采用的拜占庭式容错算法需要兼顾效率与可拓展性,尤其是在大规模边缘网络中,仍需具备低时延高吞吐量的特性。而目前已有的一致性拜占庭容错算法,尚不能同时满足这些需求。常用于区块链的PoW算法的效率太低,不适合高并发度的场景,且严重浪费资源。PoS算法及其类似算法易导致“富豪统治的问题”,且这些算法概率一致性算法均依赖虚拟代币,而在实际的边缘场景中并不需要[17]。
由Castro等人[18]提出的PBFT(Practical Byzantine Fault Tolerance)算法是第一个实用的拜占庭容错算法,该算法可以在集群中存在少数拜占庭节点的场景中保持分布式系统的一致性,但该算法在消息传递过程中的时间复杂度为多项式级,在大量节点的边缘环境中易产生广播风暴的问题,可拓展性较差。
本文的主要工作如下:针对边缘环境易于发生拜占庭错误从而破坏服务可用性的问题,提出并实现一种面向边缘计算的拜占庭容错算法Edge-Raft。该算法对Raft算法进行重新设计,在保留其易于理解实现的特性的同时,添加数字签名、同步日志检测、轮询选举、惰性投票、改进的三阶段投票等机制。采用Leader节点协调共识过程中的消息通信,将该算法的通信时间复杂度控制在O(N)。实验结果表明,与Raft算法相比,在牺牲一定性能的前提下,该算法具备拜占庭容错特性,与传统的PBFT算法相比,该算法在保留Raft算法的可理解性的基础上,具有更好的可拓展性。
1 Raft算法概述及分析
1.1 Raft算法概述
Lamport等人[19-22]为解决分布式副本的一致性问题,首次提出了Paxos算法,但该算法难以理解并工程实现[23]。为此,Ongaro等人[13]在Paxos算法基础上提出了更易于理解实现的Raft算法。Raft算法是一种强领导者(Strong Leader)算法,主要分为Leader选举和日志复制2个流程。
在Raft算法中,时间轴被分为若干任意长度的时间段,每段称之为一个任期(Term),任期编号为单调递增的整数。Raft算法的任一节点均处于Leader、Follower、Candidate这3种状态之一,仅在每个任期开始时进行一次Leader选举[24]。图1描述了Raft算法的角色状态转换,初始状态下所有节点均为Follower节点,当Follower节点一段时间内未收到Leader节点发送的心跳时,Follower节点将自身角色转变为Candidate节点并发起Leader选举请求,要求其他节点选择自己为Leader节点,其他节点收到请求后会对Candidate节点进行投票响应,若该Candidate收到半数以上的赞同票,则晋升为Leader节点,否则进行下一个任期的选举。

图1 Raft算法状态转换图
图2是Raft算法日志复制示意图。正常状态下,Leader节点负责为日志追加条目。Leader接收到来自客户端的请求后,会将该请求追加至日志中,并向Follower节点广播复制日志请求,一旦半数以上的服务器确认复制了该条目,Leader节点就将该条目发送至状态机执行,并将执行结果返回至客户端。
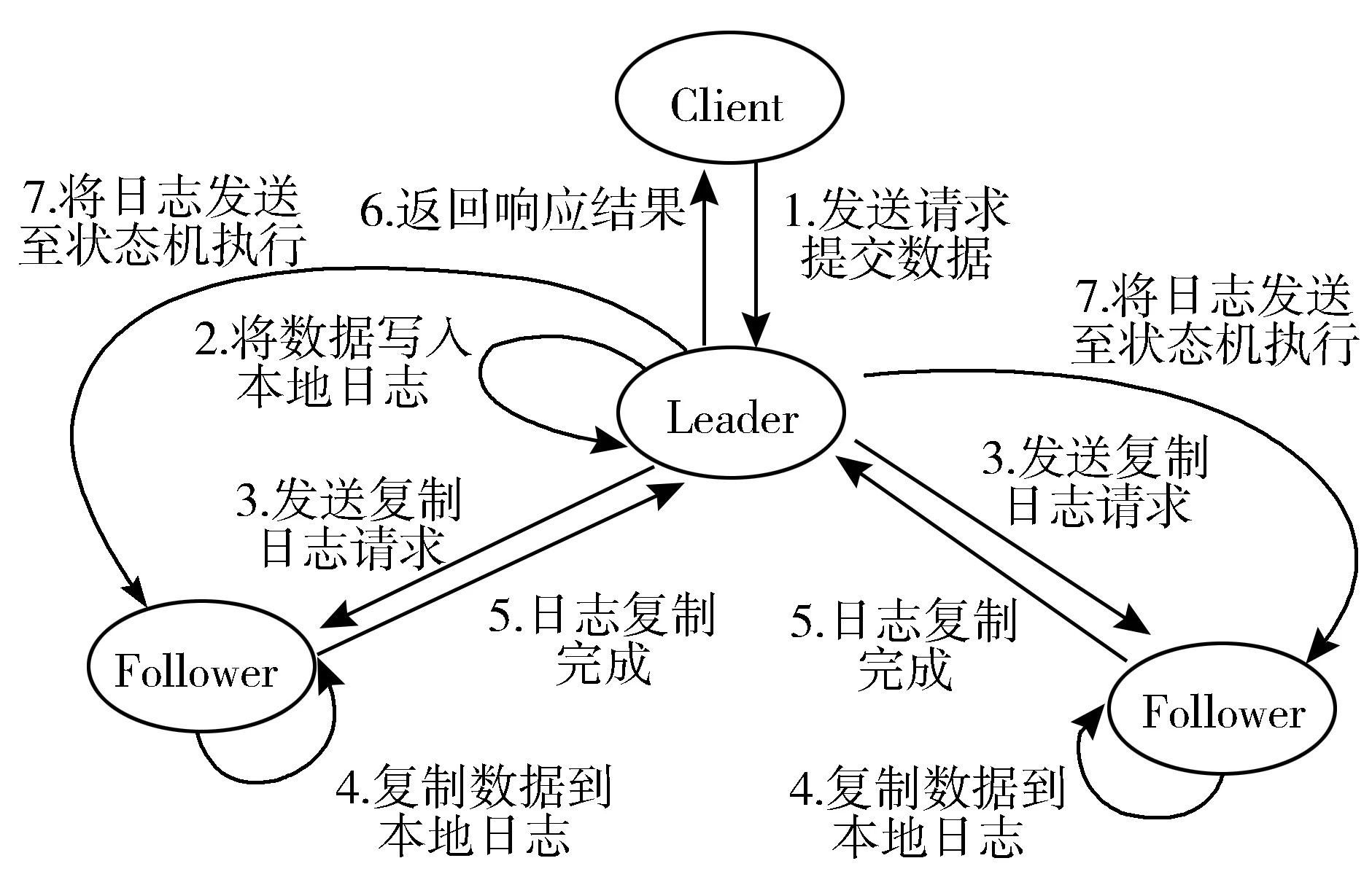
图2 Raft算法日志复制示意图
1.2 Raft算法在边缘环境中面临的拜占庭问题
Raft算法基于所有发生的错误均为Fail-stop错误这一假设。在云计算中,云服务器处于集中监控下,在大多情况下Raft算法足以保证数据的一致性,而边缘环境中发生的拜占庭错误Raft算法没有能力应对,从而无法保证服务的可用性与一致性。
在日志复制阶段,拜占庭节点能够伪装成客户端发送伪造请求,或伪装成Leader节点向其他节点同步未知请求,从而对集群造成不可预知的危害,该过程如图3所示[25]。此外,拜占庭节点可能会对收到的消息进行篡改,从而破坏集群的一致性。当拜占庭节点作为Leader节点时,可能在不断发送心跳以维持自身Leader身份的同时,拒绝任何客户端请求,从而无法对外提供任何服务,该过程如图4所示。
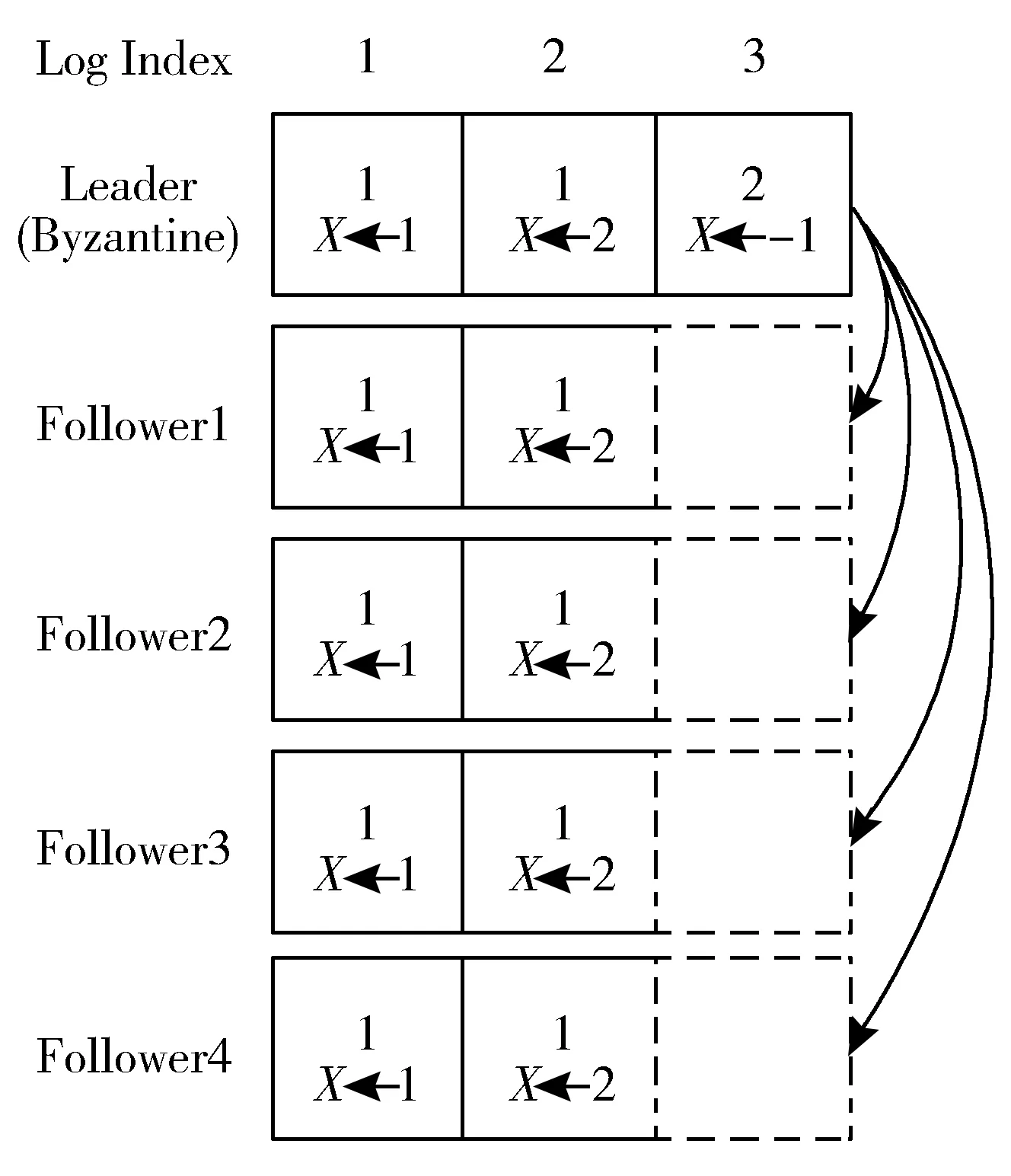
图3 伪造消息的拜占庭错误示意图

图4 拒绝用户请求的拜占庭错误示意图
在选举阶段,集群中任一节点均可发起Leader选举,拜占庭节点可以不断发送Leader选举请求,使整个集群陷入不断的选举,破坏Raft算法的可用性[18]。此外,如图5所示,拜占庭节点还可以伪造其余节点的投票或伪造最高任期的条目来上任为Leader,并通过复制自身不完整日志的方式来覆盖其他节点日志列表中已经达成共识的日志项,无法保证算法的安全性。

图5 伪造最新的日志赢得选举的拜占庭错误示意图
2 Edge-Raft算法
以上分析指出,Raft算法在易于发生拜占庭错误的边缘环境中存在着种种局限。因此,本文提出Edge-Raft算法,该算法对Raft算法的Leader选举机制和日志复制机制进行重新设计,在保留Raft算法的可理解性同时实现算法的拜占庭容错特性。
Edge-Raft算法可分解为Leader选举和日志复制2个部分。针对日志结构,Edge-Raft算法保留了Raft算法独特的任期(Term)、索引(Index)的结构。针对节点角色状态,该算法仅保留Leader与Follower这2种角色状态。
表1是在边缘环境中存在的潜在拜占庭错误及Edge-Raft算法增加相应的应对机制,具体实现细节见下文对应章节。
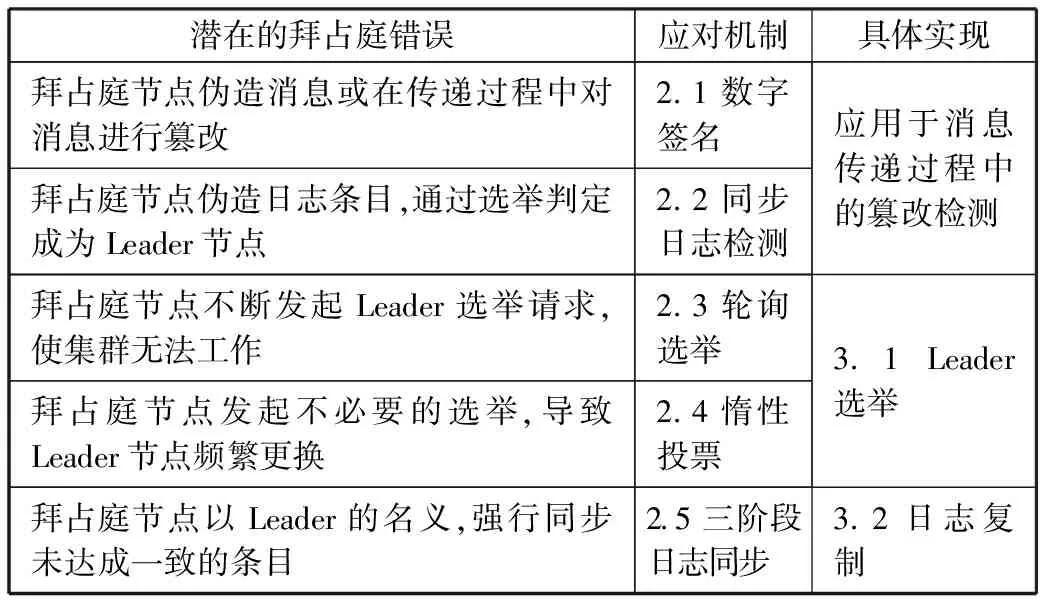
表1 边缘环境中潜在的拜占庭错误及解决方案
该算法的容错率为1/3,即当集群中节点总数为3f+1时,能够容忍f个拜占庭节点存在,以下是详细的证明。若边缘节点总数为N,其中存在f个拜占庭节点,则剩余的非拜占庭节点数目为N-f个,此时仅需要收集到N-f个相同的消息即可向客户端发出响应,但这N-f条相同的消息中仍有可能存在最多f条拜占庭节点伪造的消息,为了让正确的消息占其中的一半以上,以达到多数一致,即(N-f)/2>f,N>3f,也就是说当集群中至少保持2/3以上的正常节点才能为用户提供有效服务,以下各种机制均遵循该约束条件。
2.1 数字签名
在边缘环境下,若无任何保护机制,拜占庭节点能够伪装成其他节点或客户端发送消息,且传递中的任一消息均存在被拜占庭节点篡改的风险。因此,Edge-Raft算法引入了数字签名机制来防止消息篡改或身份伪造,为此Edge-Raft算法的节点需要满足以下几个条件:
1)边缘集群中的任一节点和客户端均拥有客户端和所有节点的公钥。
2)边缘节点的私钥仅自身持有。
3)边缘节点无伪造密钥的能力。
Edge-Raft采用ECDSA加密算法[26]用私钥对发送消息的摘要进行加密,其余节点收到该消息用对应公钥进行解密,通过核对解密后得到的摘要与原摘要是否一致来核对消息是否被篡改,从而保证了算法的安全性。对消息摘要进行加密的目的是为了减少传输过程的网络消耗。
2.2 同步日志检测
Raft算法中,Candidate节点具有全部的日志条目才可当选为Leader节点,其具体约束条件如下:
(LastTC=LastTF&&LastIC≥LastIF)‖LastTC>LastTF
(1)
其中LastTC和LastTF分别为Candidate节点与Follower节点的最后一条日志的任期,LastIC与LastIF分别为Candidate节点与Follower节点最后一条日志的索引。满足该约束条件的Candidate才具有当选为Leader节点的资格。
在边缘环境下,拜占庭节点具有在未拥有全部日志的情况下通过伪造日志条目来绕过该约束条件进而当选为Leader的能力,这会导致先前已经达成一致的条目被覆盖,或向整个集群强行写入伪造条目,从而导致不可预知的结果。为此Edge-Raft算法引入了同步日志检测机制,节点每次进行日志写入时会在消息的末尾添加一个哈希值,该哈希值由上一日志条目的哈希值LastHash与本次写入的日志条目Entries一同生成,即:
Hash=hash(LastHash, Entries)
(2)
哈希算法的抗碰撞性保证了使用同一哈希算法的不同数据所生成的哈希值完全不同。这种当前条目哈希值包含上一条目的信息的链式生成方式使得不同节点的2条日志哈希值一致时,2个节点在此条目之前的所有日志条目均相同,若其中某一节点的日志缺失、增添或遭到篡改,根据哈希算法的抗碰撞性,该节点会生成完全不同的结果。进行Leader选举时,Follower节点不仅对备选节点的最后一条日志的任期、索引进行核对,还会向备选节点请求自身最后一次同步的日志条目对应的哈希值HashC,并与自身最后一条日志的哈希值HashF进行比对,2值相等时才能确定该节点拥有全部的日志条目。该检测机制将原有的约束条件更新为:
(LastTC>LastTF‖(LastTC=LastTF&&LastIC≥LastIF))&&HashC=HashF
(3)
2.3 轮询选举
Edge-Raft算法摒弃了任一节点均可发起选举的Leader选举策略,将发起Leader选举的权利赋予所有节点。当节点在一定时间内未收到Leader心跳时,会主动向公式(4)确定的节点发送投票申请,推举该节点作为Leader选举的目标节点:
NodeID=TmodN
(4)
其中T为投票节点任期,N为节点总数。该节点向目标节点请求Leader选举投票所需的对应条目的任期、索引、哈希值等判据,若判据核对成功则向该节点投赞成票,当目标节点接收到2f+1张以上的赞同票时,该节点晋升为Leader节点。这一机制保证了同一拜占庭节点不会连续2次作为Leader选举的目标节点,且Leader节点不会连续f+1个任期以上出现问题,从而保证了集群的活跃性。
边缘节点动态加入和退出是边缘计算不同于云计算的一个重要特性,Edge-Raft算法大体上沿用了Raft算法的单节点成员变更机制(One Server ConfChange)来处理集群成员的动态变更,每次仅向集群中加入或删除一个节点,防止脑裂现象产生多个Leader节点,从而保证该算法的可用性[13]。
节点加入时,首先将自身公钥发送至Leader节点,并从Leader节点上下载集群中其他边缘节点的公钥。同时,由于Leader节点仍在向日志内写入条目,该节点会在固定数目的轮次内,多次从Leader节点上复制日志条目,以追赶Leader的同步日志,若最后一轮同步日志的耗时小于自身选举定时器设定的时间,则认为该节点与Leader节点的日志已足够接近,可以将此节点加入至边缘集群中,否则抛出异常。当确定该节点能够加入集群时,Leader节点更新节点数N的值,并将该节点的公钥及集群配置更新至集群中其他边缘节点。
节点退出或链接异常时,Leader节点无法接收到该节点对于心跳消息的回应,在经过一定预设轮次的重复发送后,Leader节点认为该节点已经脱离边缘集群,此时Leader节点更新节点数N的值,并将该更新同步至集群中的其他边缘节点。
2.4 惰性投票
Leader选举时,Edge-Raft算法的节点不会接收其他节点的投票请求来为其他节点投票,而是显现出一种“惰性”,即只有当收到客户端发送的强行更新Leader的请求或自身定时器时间内未收到Leader所发送的心跳时,该节点认定当前的Leader存在故障,才会根据轮询算法进行主动投票。至少总数2/3的节点都进行投票后,整个轮次的投票才会产生结果,这一机制防止了拜占庭节点不断发起不必要的选举,使整个集群失效。
2.5 三阶段日志同步
为防止拜占庭Leader节点向集群中同步未达成共识的日志条目,Edge-Raft算法引入了三阶段式的日志同步机制。该机制将日志同步分为预写入(PRE_APPEND)、写入(APPEND)、执行(COMMIT)这3个阶段,将Raft算法现有的仅由Leader节点即可进行同步决策的同步机制,更改为由所有节点共同决策,Leader节点仅用于协调各个节点间的消息传递。
预写入阶段,Leader节点广播PRE_APPEND消息,Follower节点接收到消息后核对消息附带的时间戳、任期、索引及哈希值来验证自身是否具有与Leader节点相同的全部日志,若验证成功,证明该节点具有日志同步的条件,此时该节点会向Leader节点返回带有自身签名的消息作为回应,当Leader节点接收到2f+1条以上不同的回应消息时,证明集群已经对日志写入这一操作达成一致,此时Leader节点进入写入阶段。
写入阶段,Leader节点将接收到的2f+1个不同的签名作为证据进行打包作为APPEND消息广播至所有节点,Follower节点接收到消息后,确认存在2f+1个不同的数字签名时,认为该消息已经达到达成共识的条件。此时节点将该消息写入日志,并向Leader返回携带自身签名的消息,作为写入日志操作的证明。同样地,当Leader节点接收到2f+1条以上不同的回应消息时,证明写入日志成功,集群对该日志条目已达成共识,此时进入执行阶段。
执行阶段,Leader节点同样将2f+1个不同签名打包作为日志条目已达成共识的证据,作为COMMIT消息广播至集群中的所有节点,Follower节点接收到消息后,确认存在2f+1个不同的数字签名时,认为该日志条目在整个集群中已达成共识,此时节点将该日志条目交付给状态机执行,并将执行结果返回给客户端。
Edge-Raft算法采用数字签名作为节点参与共识的证据,通过Leader节点收集并构建证据包并广播至Follower节点,每次同步日志条目时,必须通过核对签名的方式确保存在2f+1个节点已经对该条目达成一致,从而使所有节点都参与了日志同步的决策,保证了拜占庭Leader节点无法独自进行日志同步决策。
3 算法流程
3.1 Leader选举
图6和表2分别是Edge-Raft算法在Leader选举过程中的消息传递示意图及对应的消息定义。
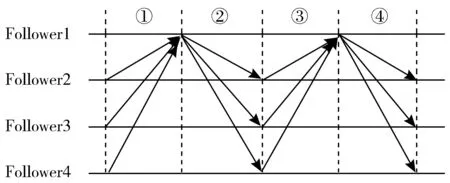
图6 Edge-Raft算法Leader选举过程消息传递示意图

表2 Leader选举过程中消息定义
表2中REQVOTE、REQVOTE-RES、VOTE、VOTE-RES为消息标识符,LastT、LastI分别为当前节点最后一次同步的日志条目的任期和索引,T、I为节点当前任期和索引,HashC为根据请求返回的哈希值,Sign为节点对当前节点ID的数字签名,E为节点收集到2/3节点总数的票数时,将数字签名打包生成的证据包,用来证明该节点确实收到了2/3以上节点的投票。Edge-Raft算法的Leader选举部分的算法描述如算法1所示。
算法1 Leader选举算法
初始状态下,所有边缘节点均为Follower节点:
1)节点在定时器超时仍未收到Leader心跳,通过公式(4)确定目标节点,向目标节点发送REQVOTE消息,启动选举计时器;2)目标节点会根据REQVOTE消息中携带的LastT、LastI生成并返回REQVOTE-RES消息;3)接收REQVOTE-RES消息,若目标节点满足边界条件式(3),则发送VOTE消息为其投赞成票;4)目标节点接收到2f+1个赞同票时,晋升为Leader,将VOTE消息中附带的Sign打包为E并向整个集群广播VOTE-RES消息;5)接收到VOTE-RES消息的节点,对E进行解析,确认其中确实存在2f+1个不同的节点数字签名时,更新自身Leader的ID及任期,停止选举定时器,完成一轮Leader选举;6)若选举定时器超时后仍未选出Leader,此时节点将自身任期加1,忽略比自身任期小的节点发送的消息,并开始下一轮选举,若在选举过程中接收到比自身任期大的Leader发送的心跳,节点会向其请求上任的证据包,若对证据包解析成功,则更新自身Leader,完成Leader选举。
图7为Leader选举过程的流程图,相比于Raft算法,尽管Edge-Raft算法在Leader选举阶段增加了一次广播消息,增加了一部分通信消耗,但仍将通信时间复杂度控制在了与Raft算法相同的O(N),同时避免了Raft算法在Leader选举阶段可能发生的拜占庭错误。
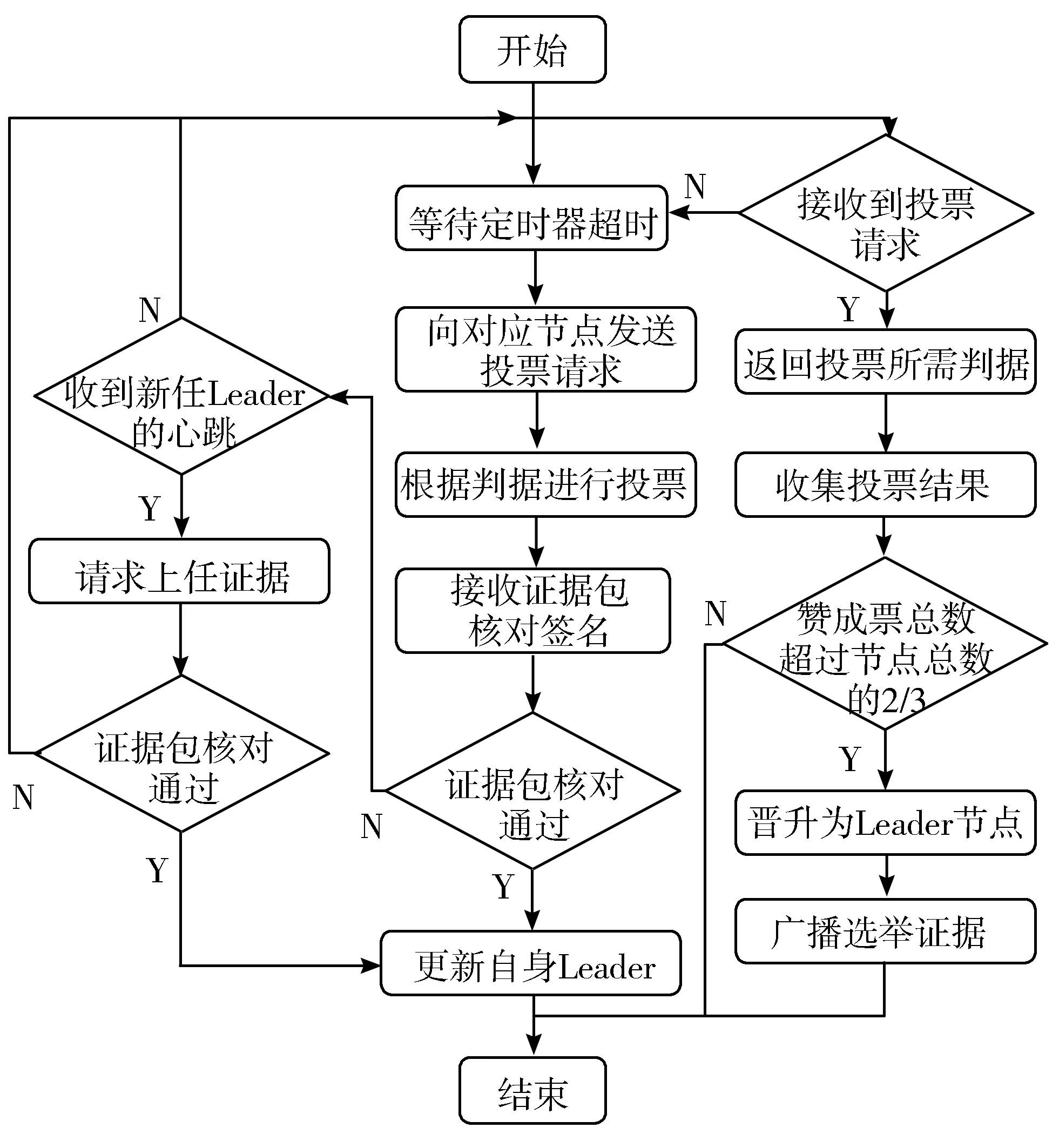
图7 Edge-Raft算法Leader选举流程图
3.2 日志复制
Edge-Raft算法在日志复制的过程中采用了3阶段式日志同步,以防止潜在的拜占庭Leader进行的将未达成共识的日志进行同步的行为。图8和表3分别是Edge-Raft算法在日志复制时的消息传递示意图及对应的消息定义。

图8 Edge-Raft算法日志复制时消息传递示意图
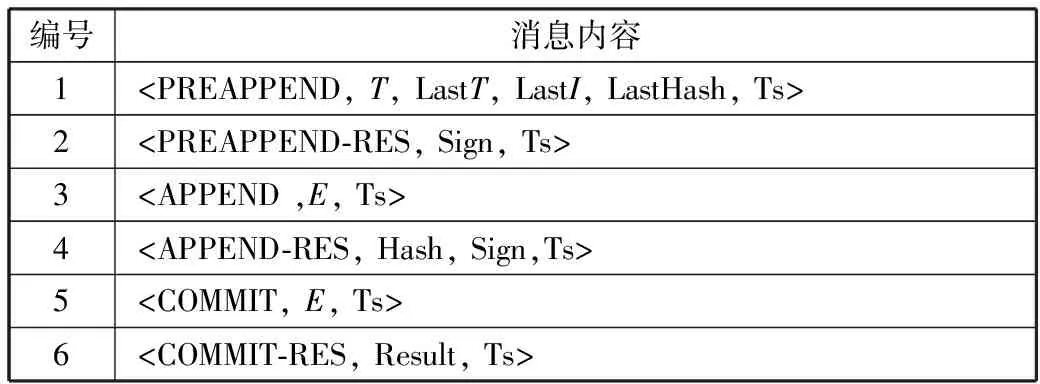
表3 日志复制过程中的消息定义
表3中PREAPPEND、PREAPPEND-RES、APPEND、APPEND-RES、COMMIT、COMMIT-RES为消息标识符,T为节点当前任期,LastT、LastT、LastHash分别为节点最后一次同步日志条目的任期索引及哈希值,Ts为客户端发送请求时附带的时间戳,用于作为请求的唯一性标识,Sign为节点的数字签名,E为节点收集到2/3节点总数的数字签名时,将数字签名打包生成的证据包,Hash为本次同步日志条目生成的哈希值,Result为状态机对请求的处理结果。Edge-Raft算法日志复制部分的算法描述如算法2所示。
算法2 日志复制算法
1)客户端生成并广播带时间戳的APPEND-ENTRIES请求;2)节点接收到APPEND-ENTRIES请求时,若该消息Ts大于上次同步条目的Ts,将该条目存储至寄存队列,准备进行同步;3)Leader节点进入预准备阶段,向所有节点广播PREAPPEND消息;4)Follower节点接收到PREAPPEND消息后核对该消息的Ts与自身寄存器Ts是否一致,节点与LastT、LastI,对应位置的Hash值与LastHash是否一致,若均一致,向Follower节点返回PREAPPEND-RES消息;5)Leader节点接收到2f+1条PREAPPEND-RES消息后,进入准备阶段,将消息中附带的Sign打包为E并广播APPEND消息;6)Follower节点接收到APPEND消息后对E进行解析,当确认其中确实存在2f+1个不同的节点数字签名时,将寄存器中条目写入自身日志中,并向Leader节点返回APPEND-RES消息;7)Leader节点接收到2f+1条APPEND-RES消息后,进入提交阶段,将同步的日志条目交付给状态机执行,同时将消息中附带的Sign打包为E并广播COMMIT消息;8)Follower节点接收到COMMIT消息后对E进行解析,当确认其中确实存在2f+1个不同的节点数字签名时,将同步的日志条目交付给状态机执行,得到执行结果Result;9)节点生成COMMIT-RES消息,将状态机执行结果Result返回至客户端。
Edge-Raft算法更改了Raft算法的日志同步机制,使所有节点共同参与同步决策,Leader节点的作用仅为协调消息传递,防止了拜占庭节点强行同步未达成一致的日志项。Edge-Raft算法的日志同步机制虽然存在3次消息广播,但由于仅有单一节点发起消息广播,其时间复杂度仍为O(N)。与Raft算法相比,牺牲了一部分的性能,但实现了抵抗拜占庭错误的特性。
3.3 客户端交互
除以上2点外,边缘节点在与客户端交互的过程中,拜占庭节点作为Leader节点可能发生拒绝响应甚至篡改响应结果恶意响应客户端的情况。因此,Edge-Raft算法与客户端交互要求所有节点将执行结果经签名后直接反馈至客户端,客户端接收到响应消息后,通过校检响应消息的数字签名以保证响应消息未被篡改,及每个节点仅响应一次客户端请求。
当集群内最多仅允许存在f个拜占庭节点时,若客户端接收到f+1个相同的响应结果,则可认为该响应结果是正确的。由于仅存在f个拜占庭节点,针对单条请求,当客户端接收到f+1条响应时,其中必然有一条是正确的响应,若f+1条响应一致,则这些响应一定是正确的。
此外,客户端在一定时间内未收到响应结果时会重新发送请求,当超过设定的最大重传次数i时,客户端会向所有节点广播消息来请求更换Leader,节点接收到该消息后会初始化自身的Leader信息,并拒绝接收当前Leader所发出的心跳,从而触发惰性投票机制,开始新一轮的选举。图9是客户端交互阶段的流程图。

图9 客户端交互流程图
4 算法分析
4.1 安全性(Safety)
在任何场景下,Edge-Raft算法都需要保证被篡改的日志条目无法在非拜占庭节点间达成一致。Edge-Raft算法通过以下几种机制来保证算法在边缘环境中的安全性。
引入了数字签名来实现消息篡改检测和防止身份伪造。Edge-Raft算法的密码学基础是稳固的。集群中传递的任一消息均携带了发送者的数字签名,且签名所用私钥仅为签名节点所有,集群中的每个节点均可用公钥验证消息是否被篡改,由于所有的节点均无伪造密钥的能力,从而确保了拜占庭节点无法伪造身份,且无法生成有效的客户端命令。
针对Leader节点日志完整性问题,Edge-Raft算法采用了同步日志检测机制,将所有节点最后同步的日志条目的哈希值与Leader日志中对应任期和索引的日志条目的哈希值进行核对,确保了在Leader选举阶段当选的节点的日志列表必定拥有所有已经达成共识的全部日志条目,从而避免了拜占庭节点通过伪造最新的日志条目来晋升为Leader,并用自身不完整的日志将已同步的日志覆盖的行为。
为了保证日志复制过程中的安全性,Edge-Raft算法采用三阶段式同步协议,三阶段消息均需在同一任期内完成,且完成时间需小于心跳定时器的时间。预写入阶段确保了存在至少2f+1个节点对写入日志这一操作达成一致。写入阶段确保了存在至少2f+1个节点达成了日志条目写入的一致性。提交阶段确保足够数目的Follower已经接收并通过准备阶段的证据包,从而防止再次接收相同任期和索引的日志条目,把已经同步的日志项覆盖,从而保证算法的安全性。
4.2 活性(Liveness)
Edge-Raft算法与Raft算法类似,作为一种强领导式算法,任意时刻集群内部都仅存在一个Leader节点来维持整个集群的正常工作,当Leader为非拜占庭节点时,Leader通过定时发送心跳的方式维持自身Leader身份,进而维持整个集群的活性,当Leader节点为拜占庭节点时,为了确保拜占庭节点不会无限期地控制整个集群,若客户端在规定时间内未得到正确的反馈,客户端将向所有节点广播更新Leader请求来更换Leader节点。
进行Leader选举时,Edge-Raft引入以下2个特性来保持集群的活性,首先每个任期内仅存在NodeID=TmodN所确定的一个候选者,这保证了Leader不会在连续f个任期以上出现问题,避免了拜占庭节点连续进行Leader选举判定。其次,节点必须收集到2f+1个选举请求时才可发起选举,这保障了拜占庭节点无法随意启动Leader选举,进而维持了整个集群的活性。
5 实验结果
5.1 实验设置
本文采用Python3.7对Edge-Raft算法进行实现,其中采用SHA-256算法作为消息的摘要算法,采用ECDSA算法对消息进行数字签名,采用Socket机制进行节点间通信,从而将该算法运行于边缘设备上进行多次实验。本节主要从Leader选举、日志复制、通信开销、吞吐量、时延5个方面来对该算法的性能进行分析,并与Raft算法及目前在物联网中最常用的拜占庭容错算法PBFT进行对比,从而验证该算法的有效性及优势[27]。
5.2 Leader选举耗时
图10描述了Raft算法与Edge-Raft算法在不同节点规模的边缘集群下的Leader选举耗时。与Raft算法相比,Edge-Raft算法的选举耗时高于Raft算法约25%,这是由于Raft算法在选举开始时,Candidate节点仅采用一轮广播消息即可完成当前Term的投票收集,而Edge-Raft算法中,Follower仅会在认定当前Leader失效时才会进行投票,这在进行一轮广播消息的基础上,Follower节点在等待投票定时器超时过程中增加了一定的时间损耗。此外由于增加了数字签名及摘要等必要的信息,使得消息的体积增加,从而增加了消息的传输耗时。

图10 Leader选举耗时对比图
5.3 日志复制耗时
图11描述了Raft算法与Edge-Raft算法在不同节点规模下单次日志复制的同步耗时。与Raft算法相比,Edge-Raft算法在进行单次日志复制时所消耗的时间约为Raft算法的4倍。这是因为在Raft算法中同步条目时,Leader节点仅需采用一轮消息广播即可完成日志复制,而Edge-Raft算法进行日志同步时,Leader节点需要进行3轮广播操作,且发送的消息中包含了节点签名、哈希值等信息,增加了数据包的体积,从而增加了一部分通信开销。为了防止在消息的传输过程中遭到篡改或伪造,该算法采用了数字签名、消息摘要等机制,这也进一步加大了时间开销。
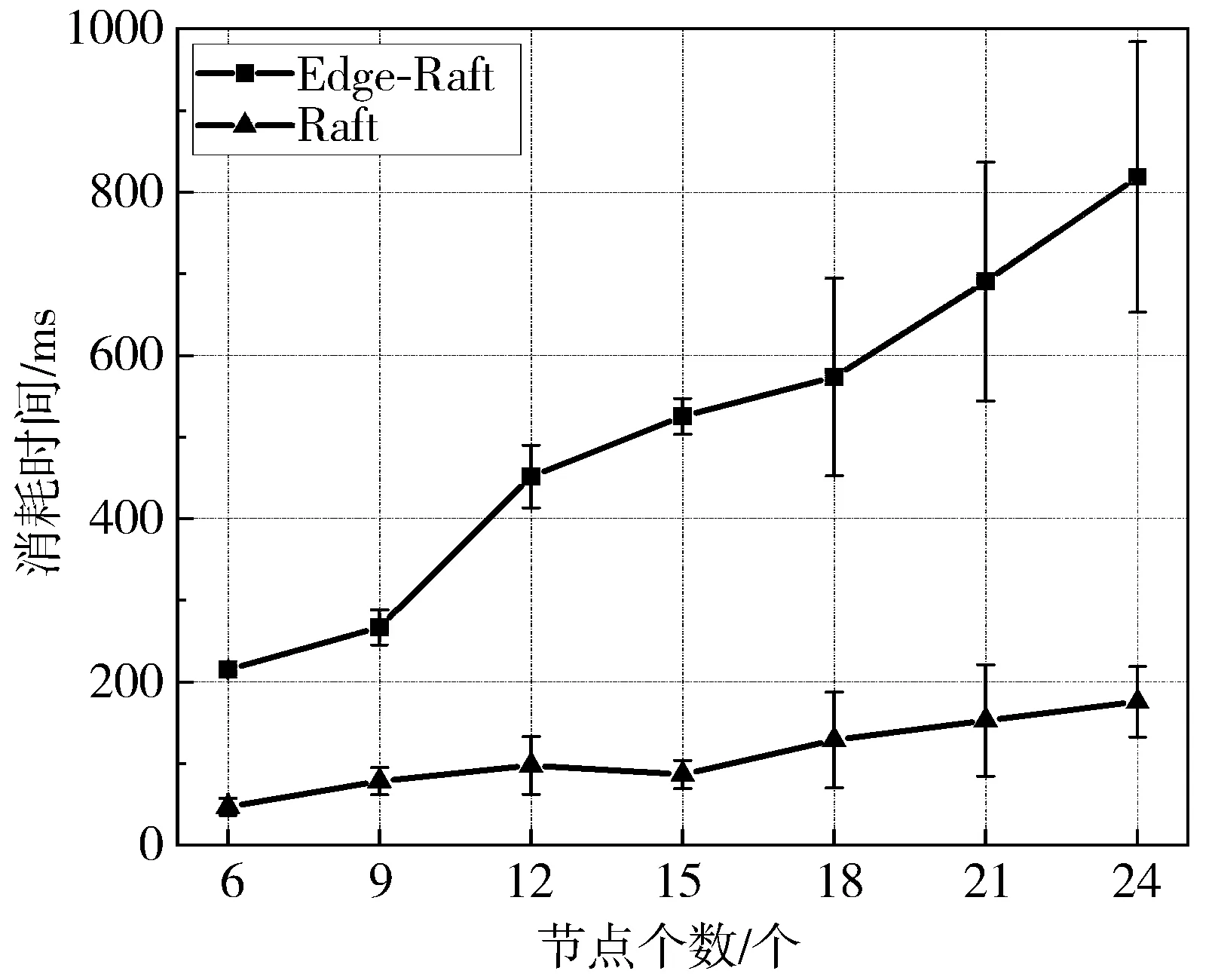
图11 日志复制耗时对比图
相较于Raft算法,Edge-Raft算法在损失了一定性能的基础上实现了拜占庭容错的特性,从而保证了该算法能够应用于边缘环境中,与此相比,本文认为牺牲的部分性能是值得的。
5.4 同步通信开销
图12描述了PBFT算法与Edge-Raft算法在不同节点规模的边缘环境中,在进行日志同步时节点间通信次数的对比,实验表明,当节点规模增加时PBFT的通信次数要显著高于Edge-Raft算法。这是由于在PBFT算法中,当节点总数为n时,其总通信次数为:
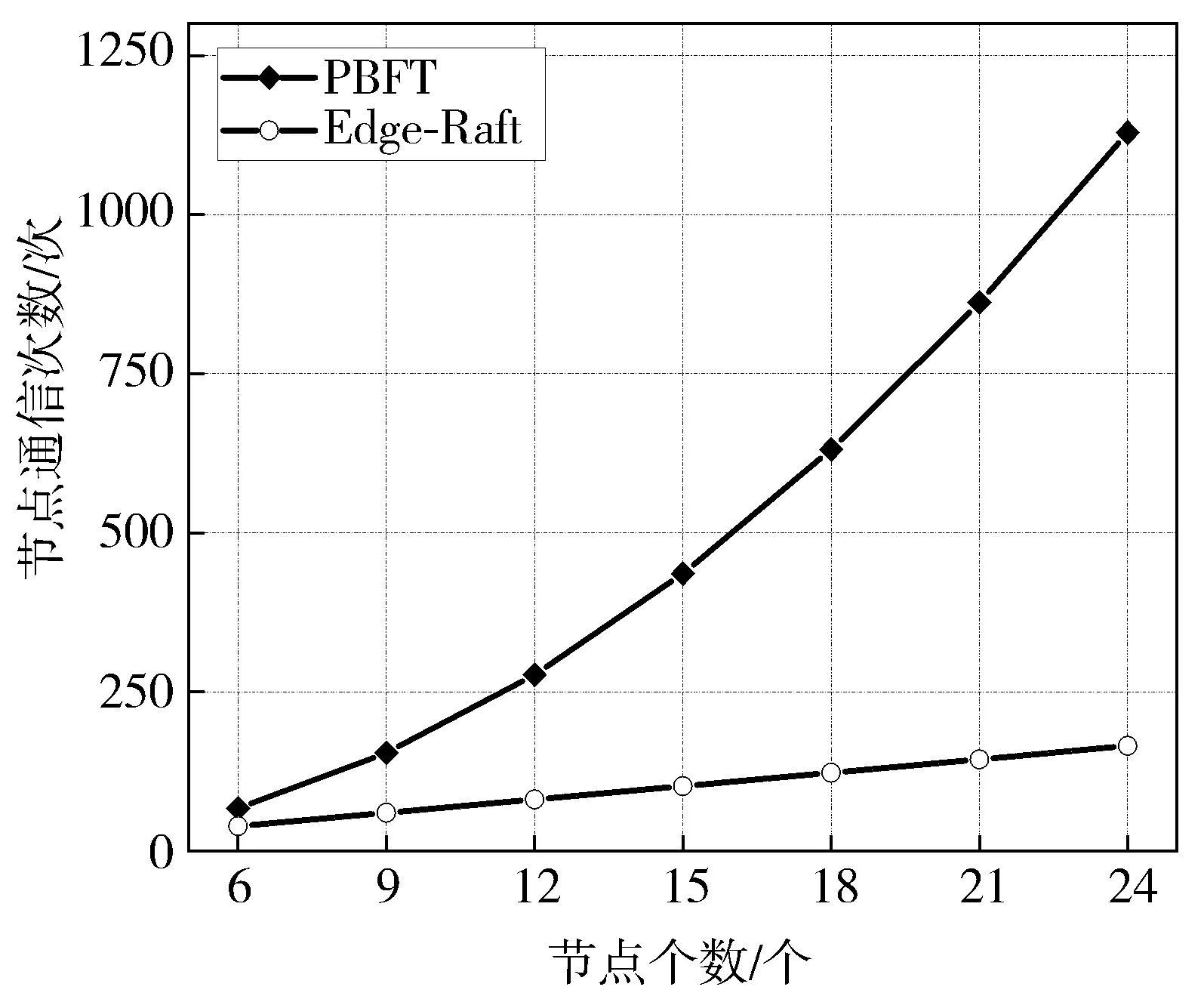
图12 节点通信次数对比图
f(n)=1+(n-1)+(n-1)2+n(n-1)+n=2n2-n+1
其通信时间复杂度为O(n2)。而Edge-Raft算法的总通信次数为:
f(n)=n+2(n-1)+2(n-1)+2(n-1)=7n-6
其通信时间复杂度为O(N),这导致了随着节点规模的扩大,PBFT算法所增加的通信次数要显著高于Edge-Raft算法,会给网络环境带来更高的压力。
图13描述了PBFT算法与Edge-Raft算法在不同节点规模下进行单次共识的通信开销,实验表明,在节点规模较小时,两者通信开销差别不大,随着节点规模增加,PBFT算法的通信开销的增量要远高于Edge-Raft算法。这是由于PBFT算法的通信次数呈多项式级增加,而Edge-Raft算法的通信次数呈线性级增加,节点间每次通信时,会对消息进行加密,并附上数字签名,通信次数越多该部分开销在总的通信开销中占比越大。因此,在大规模边缘集群中,Edge-Raft算法与PBFT算法相比,能够显著降低通信开销,缓解了网络压力。
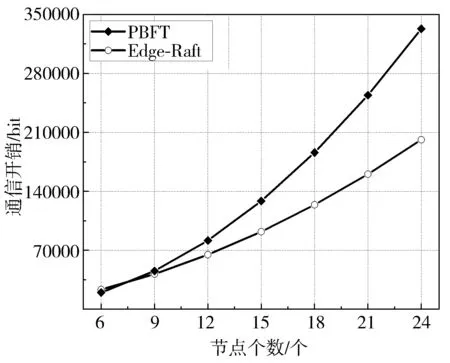
图13 通信开销对比图
5.5 处理吞吐量
吞吐量衡量了单位时间内算法处理客户端请求的效率,在本文实验中体现为单位时间内达成共识的日志条目数。图14描述了PBFT与Edge-Raft算法在不同节点规模下的吞吐量的对比结果,PBFT与Edge-Raft算法的吞吐量随着节点数量的增多均有一定程度的降低,在节点规模较小时二者的吞吐量相差不大,而随着节点数目不断增多,Edge-Raft算法的吞吐量会逐渐优于PBFT。这是由于PBFT算法在共识时消息传递时算法的时间复杂度为O(N2),而Edge-Raft算法消息传递的时间复杂度为O(N),在大规模边缘环境中Edge-Raft算法的同步效率要优于PBFT算法。
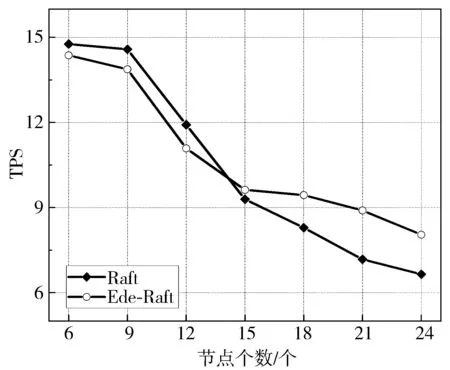
图14 Edge-Raft与PBFT的吞吐量对比图
5.6 达成一致时延
共识时延指从客户端发送请求到客户端收到正常响应回复这一过程所消耗的时间,如图15所示,PBFT算法与Edge-Raft算法在节点数目较少时,其时延差距并不明显,但由于通信成本的差异,PBFT算法的时延随着集群规模的扩大呈指数趋势上升,而Edge-Raft算法的时延呈线性上升,这表明与PBFT算法相比Edge-Raft算法具有更好的可拓展性。

图15 Edge-Raft与PBFT的时延对比图
6 结束语
本文提出了一种面向边缘计算应用的拜占庭容错共识算法——Edge-Raft,该算法基于Raft算法,在保留现有Raft算法可理解性的同时,使其具有拜占庭容错的特性,从而保证了该算法在边缘环境中的安全性与活性。实验结果表明,相比于仅支持非拜占庭容错的Raft算法,该算法在牺牲一定性能的前提下具备了拜占庭容错的特性。相比于主流的拜占庭容错分布式共识算法PBFT,Edge-Raft算法在不失性能的前提下具备同Raft一致的可理解性,且可拓展性强,适用于大规模边缘节点网络。
接下来的研究工作中,笔者将进一步研究如何对该算法的消息传递进行优化,及采用高效的签名算法等方式以进一步提升该算法的性能。当向边缘集群中增加新节点时,如何在边缘集群运行时更迅速地动态扩充集群也是未来需要进行研究的方向之一。
猜你喜欢
华人时刊(2021年13期)2021-11-27
武汉纺织大学学报(2020年6期)2021-01-04
数码设计(2020年15期)2020-12-08
内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03
网络安全技术与应用(2020年9期)2020-09-17
心声歌刊(2020年4期)2020-09-07
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
计算机与网络(2018年3期)2018-09-10
古代文明(2016年1期)2016-10-21
