
汽车智能座舱遗留物品检测
2022-12-28 08:04:30王兴宝雷琴辉胡佳睿
汽车电器 2022年11期
王兴宝, 雷琴辉, 李 韬, 胡佳睿
(1.科大讯飞股份有限公司智能汽车事业部, 安徽 合肥 230088;2.武汉大学测绘遥感信息工程国家重点实验室, 湖北 武汉 430071)
车内遗留物品检测是智能座舱系统的重要组成部分。如果能及时对车主遗留的贵重物品在车舱进行提示或者警告,不仅能避免车主后续回来拿东西的麻烦,也能降低被破窗盗窃风险,还可以有效提升车主的用车体验,也是车厂卖车的一大亮点。
1 目标检测技术概述
1.1 目标检测的定义
目标检测的任务是识别图像中出现的物体的类别以及对应物体的位置。物体是图像中存在的物体对象,但是需要检测哪些物体需要根据具体任务的需求来确定。例如智能座舱遗留物品定义为手机、钱包、pad、笔记本电脑和背包这5类,对应的目标检测任务只需要检测出该5类物品,如果检出其他类型的物品,则被定义为虚警。
目标检测的位置信息一般分为两种格式:极坐标表示和中心点坐标表示。
1) 极坐标表示:(xmin,ymin,xmax,ymax),其中xmin,ymin代表目标框坐标的最小值,xmax,ymax代表目标框坐标的最大值。
2) 中心点坐标:(x_center,y_center,w,h),其中,x_center、y_center为目标检测框的中心点坐标,w、h为目标检测框的宽、高。
1.2 目标检测算法的种类
1.2.1 Two-Stage目标检测
Two-Stage目标检测是基于区域的目标检测算法,比较有代表性的算法有R-CNN[1]、SPP-Net[2]、Fast-R-CNN[3]等。该类方法首先需要得到候选区域,然后进行分类与回归的预测,具有较高的检测准确度,尤其对小目标的检测。但是由于需要事先获得候选区域,其效率不如单阶段目标检测。
1.2.2 One-Stage目标检测
One-Stage目标检测算法不需要首先获得提议区域,直接产生物体的类别概率和位置信息,因此有着更快的检测速度并且更容易部署。比较典型的算法如YOLO[4]、SSD[5]、YOLOv2[6]、YOLOv3[7]、Retina-Net[8]等。
2 智能座舱遗留物品检测
首先将图片的数据格式转换成HSV格式,通过设定HSV域的阈值抽取图片的红分量,如图1所示。

图1 抽取红分量
根据红分量的比例可将整体数据集分成3个域,如图2所示,分别为Normal(图2a)、Gray(图2b)、Red(图2c)。

图2 根据红分量的比例可将整体数据集分成3个域
2.1 域内外类别分布不均衡
对采集回来的数据进行分析,我们发现样本的域内域外数量分布很不均衡,如图3所示。对于域内样本,如图3a所示,包含pad的样本十分稀少。对于域间样本分布,发现Gray域的样本占了多数。域间类别数量分布如图3b所示。

图3 样本域内域外类别数量分布情况
2.2 目标尺度分布不均衡
数据小目标占比较多,其中phone全部为小目标,packsack中超过一半也为小目标,总体78%为小目标,如图4所示。

图4 小目标数量分布
数据分布的特殊性需要结合特定的策略进行优化。下文中,将介绍算法设计以及针对数据分布的难点使用的优化方案。
3 算法主体架构
3.1 基线模型
基线模型选择anchor base架构,通过RPN[3]生成高品质候选框,通过ROIPooling[3]提取固定大小的特征,最后使用Cascade级联head逐步提高边框的预测品质。Cascade RCNN示意图如图5所示。

图5 Cascade RCNN示意图
在RPN阶段,我们采用Global Context[9]策略,如图6所示。通过加入全局范围的pooling特征,帮助后续的分类和回归。
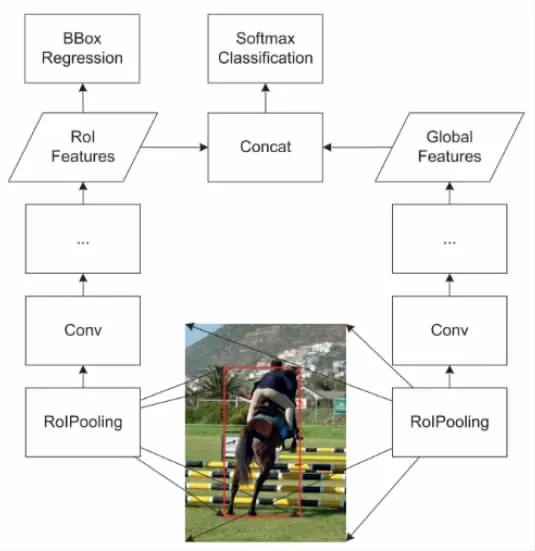
图6 全局语境方法
3.2 CBNet+Swin Transformer
如图7所示,CBNet[10]通过组合复用多个backbone的方式增强对backbone和fpn部分的特征提取,可有效提高检测精度。本文使用Swin Transformer作为网络主干。

图7 CBNet结构
如图8所示,Swin Transformer[11]的设计非常巧妙,具有创新又紧扣CNN的优点,充分考虑的CNN的位移不变性,尺寸不变性,感受野与层次的关系,分阶段降低分辨率增加通道数等特点,相对于CNN结构每个layer看到的区域更大,比CNN中的padding、pool等有着明显的优势。

图8 Swin Trainsformer
3.3 YoloX
YoloX[12]网络,属于Anchor Free架构,如图9所示,使用darknet作为backbone,并采用PAPN特征金字塔增强对不同layer特征的提取。

图9 YoloX网络结构
YoloX网络的头部采用decouple解耦设计,将分类任务、边框回归任务、前景检测任务采用单独分支进行特征增强,加速收敛的同时可有效提升精度。同时,YoloX采用SimOTA样本分配策略,将单阶段的候选框依据前景和分类loss进行粗筛,再根据动态正样本排序策略获得高品质的正样本。图10为SimOTA标签分配策略。

图10 SimOTA标签分配策略
3.4 模型融合
模型融合策略包括两个部分:WBF和NMS。WBF[13](Weighted boxes fusion),该策略重点是融合,根据较为准确的框来获得更加准确的框,分段的依据是框置信度在0.3以上。NMS[14]对框进行筛选,去掉大量不准确的框,获得较为准确的框。分段依据是框的置信度在0.3以下。模型融合策略如图11所示。
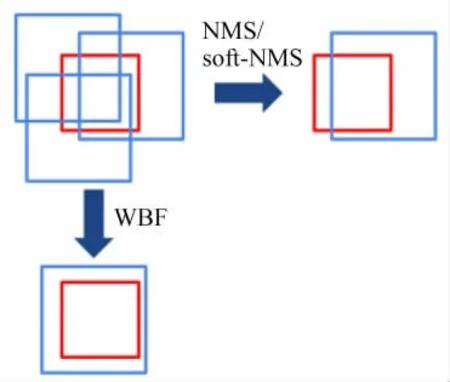
图11 模型融合策略
4 难点问题解决方案
4.1 域内不均衡和域间分布不均衡
针对域内和域间分布不均衡问题,我们使用软均衡采样策略来解决。
经过软均衡策略后,域间和域类样本数量分布更加平衡,软均衡采样效果如图12所示。

图12 软均衡采样效果
4.2 小目标识别
为了优化小目标识别问题,我们采用马赛克增强[15]和SoftNMS[16]策略。
如图13所示,马赛克数据增强将4张训练图像按一定比例组合成1张,丰富了检测数据集,增加了很多小目标,有效提升模型对小目标的检测能力。

图13 马赛克增强
Soft-NMS将重叠度大于阈值的其他检测框不会直接删除,采用一个函数来衰减这些检测框的置信度,可以一定程度避免小目标被删除。其算法流程如下。
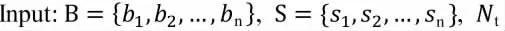
其中B是检测框集合,S是检测框对应的得分,Nt为NMS阈值。

4.3 过拟合
由于实车场景可以采集的数据比较少,这样会导致模型过拟合。针对模型过拟合问题,在YoloX的训练过程中,我们依次尝试了AutoAug V1、AutoAug V2、AutoAug V3,对比详情如图14所示。

图14 AutoAug效果对比
可见,AutoAug V2在我们的任务中表现较好,达到了0.816的mAP。AutoAug V2参数配置如图15所示。

图15 AutoAug V2参数配置
除此之外,我们还采用gridmask[17]增广策略强迫模型不拟合训练集。具体效果将在实验部分开展说明。
5 实验
5.1 实验环境和参数配置
以实车采集的2500张图片作为测试集,1000张图片作为训练集。实验中除了模型融合方案,都使用非极大抑制算法作为后处理方案,其交并比为0.5。实验的评估指标选用平均精度均值(mean average precision,mAP)。
实验所用的GPU型号为NVDIA Tesla V100,使用pytorch以及mmdetecion工具包构建目标检测模型。
5.2 对比实验
以Cascade RCNN作为基线方案,为了让基线方案有效检测出小目标,其设定的训练尺度比较大,分别为4096×800和4096×1408。在训练过程中,将batch_size设定为24,初始学习率为0.001,采取余弦退火的方式更新学习率,使用adamW作为优化器。表1给出了不同模型和trick组合情况下的检测效果对比。

表1 模型效果对比
可以看出,Cascade RCNN作为基线其在测试集的最优mAP为0.745,接着加入软均衡采样策略以及样本扩充方法使mAP上升到0.76。在此基础上使用TTA(Test-Time Augmentation,测试时数据增强),达到了0.78,接着应用global context算法使效果进一步提升达到0.79,和基线对比相对提升17.6%。可见,我们提出的软均衡策略以及引入global text对检测效果有着明显的促进作用。
对于单阶段检测器,通过结合CBNetV2和Swin Transformer,可以使模型效果直接达到0.8,在此基础上,我们通过引入gridmask算法使效果进一步提升,使mAP达到了0.815,和基线对比相对提升27.4%。
由于我们最终方案是集成学习,因此还训练了YoloX,其训练尺度选择1280,推理尺度分别为1024、1280、1408,并在模型推理环节使用测试时增强。将原始图片进行3个尺度的flip,分别进行推理,再对多个结果进行合并,最终得到最优结果为0.81。接着我们通过在训练过程中引入AutoAug V2,使YoloX的检测结果进一步提升,达到0.816。
为了进一步提升检测效果以及模型鲁棒性,使用模型融合策略对以上3种模型进行融合,融合过程采用上文提及的WBF+NMS策略,最终达到最优效果0.817,并且比单模型有着更强的鲁棒性。
6 总结与展望
本文针对车载场景的遗留物品检测任务,进行深入数据分析,根据车载场景图像数据的难点提出了相应的解决方案,有效解决了数据分布不均衡问题以及小目标检测的挑战。
实际车内贵重物品检测场景中除了训练集中的手机、平板、笔记本电脑、钱包、背包5类外,往往存在手表、手环、项链、戒指等未知类别的样本,这类样本的检测属于FSD(Few Shot Objection) 或者ZSD(Zero Shot Objection)。端侧推理中基于摄像头可以获取视频流,可以基于连续帧的特征来增加遗落目标的前景置信度,从而提高整体的检测效果。
猜你喜欢
今日农业(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
高技术通讯(2021年3期)2021-06-09 06:57:46
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:38
科学(2020年5期)2020-11-26 08:19:14
现代出版(2020年3期)2020-06-20 07:10:34
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数学学习与研究(2017年3期)2017-03-09 18:12:42
舰船电子对抗(2016年5期)2016-12-13 08:41:14
