
大数据背景下的数据仓库架构设计及实践研究
2022-12-28 11:20贺晓松
中国新技术新产品 2022年19期
贺晓松
(重庆工程学院大数据与人工智能研究所,重庆 400037)
0 引言
21世纪初,随着互联网和移动设备的普及,大数据时代已经到来。早期的数据仓库主要以离线的批处理为主,目的是帮助传统企业的业务决策者、管理者做一些业务决策,其业务决策周期比较长,数据量也比较小。随着大数据技术的发展、整体算力的提升以及互联网的发展,数据量已呈指数级增长,做决策的主体很大部分已转变为计算机算法,例如一些智能推荐场景等。所以这时的决策周期就由原来的天级要求提升到秒级,决策时间是非常短的,会面对更多的需要实时数据处理的场景,例如实时的个性化推荐、广告的场景,一些传统企业已经开始实时监控加工的产品是否有质量问题以及金融行业重度依赖的反作弊等。在该背景下,数据仓库也由传统的离线数仓转变为实时数仓,架构设计也随着时代和业务需求不断演变和发展,以适应增长的数据处理和变化的业务需求。
1 数据仓库概述
1.1 数据仓库的定义
数据仓库(Data Warehouse)是面向主题的、集成的、相对稳定的并反应历史变化的数据集合[1],数仓中的数据是有组织、有结构的存储数据集合,用于支持管理、决策过程。其中面向主题是指数据仓库是面向分析决策的,所以数据经常按分析场景或者分析对象等主题形式来组织,这是与面向应用进行数据组织的传统数据库的最大区别。集成性是指通过对分散、独立以及异构的数据库数据进行抽取、清理、转换和汇总,得到数据仓库的数据[2],这样就保证了数据仓库内的数据针对整个企业不同业务的数据口径的一致性。
1.2 数据仓库的分层
从数据源的采集到多层清洗加工的过程中,数据仓库形成了一套规范的数据逻辑分层,一般分为4层[3],如图1所示。分层的核心思想就是解耦,即将一个复杂的任务分解成多个步骤来完成,每层只处理单一的步骤,将复杂问题简单化。另外通过数据分层,开发通用的中间层,提供统一的数据出口,在规范数据的同时最大程度地减少重复开发。
图1中的各层说明如下。

图1 数据仓库分层图
ODS层:全称为原始数据层(Operation Data Store)。该层对从数据源采集的原始数据进行原样存储。
DWD层:全称为明细数据层(Data Warehouse Detail)。该层对ODS层的数据进行清洗,主要解决一些数据质量问题。
DWS层:全称为服务数据层(Data Warehouse Service)。该层对DWD层的数据进行轻度汇总,生成一系列的中间表,提升公共指标的复用性,减少重复加工,并构建出一些宽表,供后续进行业务查询。
App层:全称为应用数据层(Application)。DWD、DWS层数据统计结果会存储在App层。App层数据可以直接对外提供查询,一般会将App层的数据导入MySQL中供BI系统使用,可提供报表展示、数据监控及其他功能。
2 数仓平台架构设计
一个完整的数据仓库系统通常包括数据源、数据存储与管理以及数据服务,如图2所示。

图2 数据仓库架构
数据源部分包括企业中的各种日志数据、业务数据及一些文档数据,数据仓库就是基于这些数据构建的。构建好的数据仓库可以为多种业务提供数据支撑,例如数据报表、OLAP数据分析、用户画像以及数据挖掘都需要使用数据仓库的数据。
2.1 离线数据仓库架构
早期数据仓库建设理论基于CIF架构建设方案,数据是构建在关系型数据库之上的。但随着大数据时代的来临以及企业数据量的暴增,关系型数据库已经无法支撑起大规模数据集的存储和分析,其性能已成为瓶颈。对此,经典数仓中的传统工具便被以Hadoop为代表的大数据技术栈组件替代,该架构称为离线大数据架构,如图3所示。

图3 离线数据仓库架构
在离线大数据架构中,常见的是使用Hive进行构建,并对数据进行分层处理。当然,也可以使用Impala进一步提高Hive的计算性能。对Hive SQL无法处理的复杂业务逻辑,则可以考虑使用自定义SQL函数,或者MapReduce、Spark代码来解决。
2.2 Lambda架构
随着实时数据处理的业务场景逐渐增多,架构层面逐渐需要满足一些实时性要求。Twitter工程师南森·马茨(Nathan Marz)在2011年提出了一个实时大数据处理框架——Lambda架构,用于满足大数据批量离线处理和实时数据处理的需求,如图4所示。为了计算一些实时指标,Lambda架构对数据源进行了重构,引入消息队列(如Kafka)来处理数据流,实时链路订阅消息队列,对消息流数据进行处理,并将结果推送到下游数据服务。
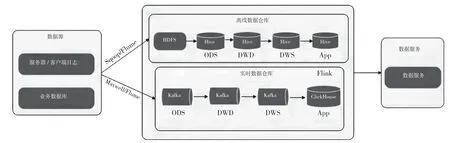
图4 Lambda架构
Lambda架构中的数据从底层的数据源开始收集数据组件(例如Flume、Maxwell和Canal等),并将数据分成2条链路进行计算。批量数据处理离线计算平台(例如MapReduce、Hive和Spark SQL)可计算T+1的相关业务指标,这些指标需要隔日才能看见,以保证数据的有效性和准确性;流式计算平台(例如Flink、Spark Streaming)可计算实时的一些指标,以保证数据的实时性。
虽然Lambda架构可满足实时性要求,但在实际应用时存在需要更多开发和维护工作不足的问题。一则需要开发2套代码来处理相同的需求,使开发变得更加困难(在批处理和流处理引擎上处理相同的需求,针对单独的数据测试应确保结果一致),且不利于后续维护。二则实时与离线计算走2条链路容易导致数据口径不一致。
2.3 Kappa架构
随着流式处理引擎(如Flink等)的不断完善与流处理相关技术(例如Kafka、ClickHouse)的发展,针对Lambda架构需要维护2套系统、运维成本高等缺点,LinkedIn的Jay Kreps提出了Kappa架构,如图5所示。

图5 Kappa架构
Flink SQL提供的“Hive数仓同步”功能为批流一体化数据仓库的实现提供了底层技术支持,所有的数据加工逻辑由Flink SQL以实时计算模式执行。数据写入端会自动将在ODS、DWD和DWS层已经加工好的数据实时回流到Hive表中,离线处理的计算层可以完全去掉,处理逻辑由Flink SQL统一维护,离线层只需要使用回流的ODS、DWD和DWS层的表做进一步即席查询即可,这样就不需要单独维护离线计算任务了。
Kappa架构在Lambda架构的基础上简化了离线数据仓库的内容,构建了批流一体化数据仓库。其核心思想是在Lambda架构上去掉批处理链路,只留下单独的流处理链路,通过消息队列的数据保留功能来实现上游重放(回溯)功能,并使用同一套实时计算和批处理代码,方便维护并统一了数据口径,降低了开发和运维成本。
2.4 湖仓一体架构
Kappa架构完全废弃了批处理层,实现了批流一体,避免了冗余工作,并简化了技术栈。但因使用的消息队列(例如Kafka)在存储功能上不支持高效的数据回溯及数据更新,导致此架构在实际落实过程中存在不足。
数据湖是一个存储各种各样原始格式数据的大型仓库,通常是对象块或者文件。数据湖侧重于存储的内容,包括结构化数据、半结构化数据(CSV、日志、XML和JSON)、非结构化数据(电子邮件、文档和PDF)和二进制数据(图像、音频和视频)[4-5]。从实时数仓的角度看,为了支持上层实时数仓构建,数据湖还具有Upsert操作高效、回溯能力强、支持Schema变更、支持ACID语义以及支持批流读写的优点。
2020年,Databricks提出了湖仓一体(Lakehouse)架构,希望将数据湖(Data Lake)和数据仓库(Data Warehouse)进行优势互补,合二为一。在Databricks的描述中,Lakehouse是数据湖和数据仓库的混合体。一方面,它提供了处理结构化程度较低的数据类型的灵活性,如文本和图像文件,这在数据科学和机器学习项目中较为常用。另一方面,它也借鉴了数据仓库设计的约束和规范,特别是在确保数据质量和管理方面,面向业务实现了高并发、精准化和高性能的历史数据、实时数据的查询服务。
将Kappa架构中的Kafka消息队列替换成数据湖存储之后,该文得到了新一代的湖仓一体架构,如图6所示。

图6 湖仓一体架构
具体来说,和使用消息队列的Kappa架构相比,湖仓一体架构具有如下优点:1)可以解决消息队列存储数据量少的问题。无论数据湖底层存储是使用Hadoop分布式文件系统(HDFS),还是使用亚马逊AWS的对象存储服务(S3)、阿里云的对象存储服务(OSS),都能够存放海量数据。2)数据仓库层(DW)数据支持OLAP查询。目前大部分的OLAP引擎都支持HDFS和对象存储,只需做一些简单适配就可以与数据湖对接。3)批流基于一套存储,因此可以复用一套相同的数据血缘、数据质量管理体系。4)支持Update/Upsert,而消息队列(例如Kafka)一般只支持Append。实际场景中,DWS层的数据很多时候都需要更新,从DWD层到DWS层一般会根据时间粒度和维度进行聚合,用于减少数据量,提升查询性能。假如原始数据是秒级数据,聚合窗口是1 min,那就有可能产生某些延迟数据经过时间窗口聚合之后需要更新之前数据的需求。
3 基于Iceberg湖仓一体架构的电商数据分析平台实践
3.1 Iceberg技术栈
目前市面上有3个开源的数据湖方案,分别是Databricks开源(Delta Lake)、Uber 开源(Apache Hudi)和Netflix开源(Apache Iceberg)。其中Iceberg以自身独特的优势被越来越多开发者关注,其优点如下:1)在架构和实现上没有绑定到某一特定引擎,具有通用的数据组织格式,利用此格式可以与不同引擎(Flink、Hive和Spark等)对接。2)拥有良好的架构和开放格式。与Hudi、Delta Lake相比,Iceberg的架构实现更优雅,同时对数据格式、类型系统有完备的定义和可进化的设计。3)在数据组织方式上充分考虑了对象存储的特性,避免耗时的listing和rename操作,使其在基于对象存储的数据湖架构适配上更有优势。
3.2 项目架构及数据分层
该项目使用Iceberg构建“湖仓一体”架构的数据湖技术来实时和离线分析电商业务指标。项目整体架构图如图7所示。

图7 项目架构
项目中的数据源有2类,一是MySQL业务库数据,使用Flink CDC或Maxwell监听mysql binlog日志,以实现数据实时同步至Kafka。另一类是用户日志数据,通过Flume将数据采集到Kafka各自的topic中,通过Flink处理将业务和日志数据存储在Iceberg-ODS层中。由于目前Flink基于Iceberg处理实时数据不能很好地保存数据消费位置信息,因此这里同时将数据存储在Kafka中,利用Flink消费Kafka数据自动维护offset的特性来保证程序停止重启后消费数据的正确性。整个架构基于Iceberg构建数据仓库分层,经过Kafka处理数据并实时存储在对应的Iceberg分层中。实时数据结果经过最后分析存储在ClickHouse中,离线数据分析结果(直接从Iceberg-DWS层中获取数据分析)存入MySQL中。Iceberg其他层供临时性业务分析,最终ClickHouse和MySQL中的结果将通过可视化工具展示出来。
3.3 项目可视化
项目最终通过可视化工具Sugar BI实现实时浏览pv/uv分析、用户积分指标分析、用户实时登录信息分析、实时商品浏览信息分析等内容指标的可视化呈现。
4 结语
当前,基于Hive的离线数据仓库架构已经非常成熟,随着实时计算引擎的不断发展以及业务对实时报表的产出需求的不断膨胀,最近几年业界一直在关注并探索实时数仓建设。根据数仓架构演变过程,Lambda架构中包括离线处理与实时处理2条链路,由于2条链路处理数据会引发数据不一致等问题,因此发展出了Kappa架构。Kappa架构将2条链路合二为一,实现了批流一体,但Kappa架构中的常用中间件如Kafka存在不支持update/upsert和无法支持高效的OLAP查询等缺点。数据湖技术的出现使Kappa架构实现批量数据和实时数据统一计算成为可能。数据湖技术可以将批量数据和实时数据统一存储并统一处理计算,该文将离线数仓中的数仓和实时数仓中的数仓数据存储统一合并到数据湖上,将Kappa架构中的数仓分层Kafka存储替换成数据湖技术存储,以此实现了“湖仓一体”的构建。
猜你喜欢
防爆电机(2021年4期)2021-07-28
中国特种设备安全(2021年11期)2021-05-05
铁道通信信号(2020年6期)2020-09-21
自然资源信息化(2019年4期)2019-03-29
中成药(2018年2期)2018-05-09
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
中国教育信息化(2015年10期)2015-08-23
