
基于决策树算法的客服终端冗余数据迭代消除方法
2022-12-27 13:14丁毛毛吕静贤王笑一
计算技术与自动化 2022年4期
张 莉,丁毛毛,李 玮,王 颖,吕静贤,王笑一
(1.天津大学,天津 300072;2.中国农业大学,北京 100193;3.索尔福德大学,英国 曼彻斯特 03101;4.华北电力大学,北京 102206;5.波尔多第一大学,法国 波尔多 33000)
为提高企业信誉,维护客户,提高销量,相关企业都会设立一个客服岗位,通过客户终端与客户联系,提供销前服务和销后服务。然而,若是问题得不到及时、有效的解决,客户会频繁地联系商家客服,如果客服尚未一对一服务,问题就会被重复地记录,严重干扰维修人员的分配,经常造成无人处理问题或者多人同时处理一个问题的现象,不仅降低了客户服务满意度,还造成了资源浪费[1]。针对上述现象,如何解决客服终端重复记录的冗余数据问题成为很多商家客户服务领域的难点。
冗余数据是指相似度较高或者重复的数据。若是不能有效地将其消除,会直接影响客服服务质量。关于冗余数据消除的研究有很多,大部分方法的原理都是通过计算相似性来检测重复数据并消除,即计算数据之间的距离,距离越近,代表数据之间的相似性越高,将相似度高的数据只保留一个,即完成冗余数据消除[2]。这种方法操作简单,效率快,但是只对小规模的数据有效,一旦数据规模很大,这种方法的处理效率就会受到极大的限制。
针对基于相似度的消除方法存在的问题,研究基于决策树算法的客服终端冗余数据迭代消除方法。通过本研究以期为客服终端冗余数据处理提供新的解决思路,提高面对大量冗余数据的处理能力。
1 基于决策树算法的客服终端冗余数据迭代消除研究
对于企业和商家来说,客户终端数据有利于提高服务质量,挖掘潜在客服,为销售策略制定提供重要依据[3]。客户的重复咨询导致客服终端数据中存在很多重复记录,这些重复记录就被称为冗余数据。冗余使得数据利用困难。为此,有必要进行冗余数据消除处理。在这里通过引入决策树算法寻找同类数据,计算同类数据之间的相似度计算,以解决基于相似度的消除方法在处理大规模数据能力较差的问题。
1.1 客服终端数据集成
客服终端冗余数据消除首要环节是集成各个客服终端中的记录[4]。为此,首先就要将这些客服终端中记录下的数据集中到一起,以进行后续的处理。在本章节采用数据仓库法对客服终端中的数据进行抽取,完成数据集成工作。集成过程如图1所示[5]。
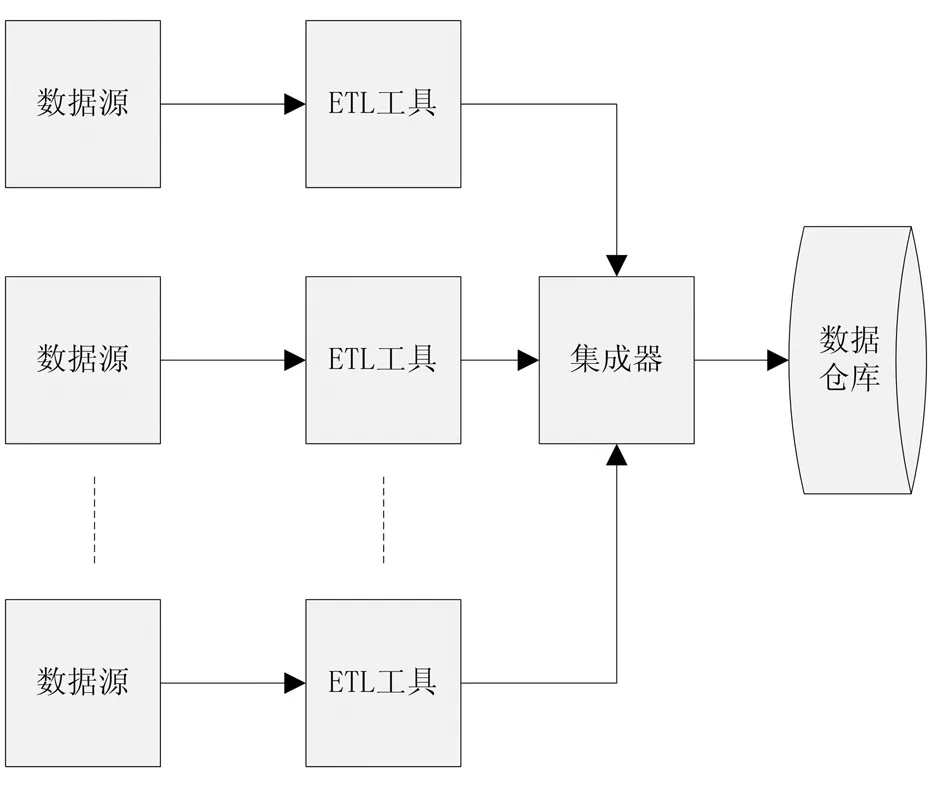
图1 数据仓库
数据仓库中ETL工具是关键,主要作用是将数据从各个客服终端中抽取出来,然后对数据进行转换,使得数据具有一致性,最后将其装载到数据仓库当中,等待进一步的处理[6]。
1.2 客服终端数据预处理
为降低后续冗余数据查找和消除难度,需要对集成客服终端数据进行预处理[7]。预处理过程包括两个环节,下面进行具体分析。
1.2.1 字符类数据处理
1)去掉停用词
去掉停用词,即去除文字记录中没有实际意义的词,如“的”“地”“吗”等。去除方法是对比停用词词典[8]。只要是出现在词典上的词,文字记录中都可以直接删除。
2)中文分词
中文分词是指将字符串切分成单独的词[9]。具体过程如下:
步骤1:构造分词词典。
步骤2:输入待切分的中文字符串,将其记为D,长度记为L。
步骤3:判断长度L是否大于1?若大于,进入下一个环节;否则,分词结束。
步骤4:计算D中每个字开头词语的最大词长,记为l1,l2,…,ln。
步骤5:比较l1,l2,…,ln,并取其中的最大值lmax。
步骤6:比较lmax与L。若lmax>L,让最大匹配初始长度等于L;否则,则等于lmax。
步骤7:以L或者lmax为最大词长,进行正向最大匹配。
步骤8:根据匹配结果实现分词。
步骤9:是否所有记录都分词完毕?若完毕,完成所有字符类数据的分词;否则回到步骤2。
1.2.2 数值类数据处理
1)缺失值填补
针对数据中缺失部分进行填补,以保证数据完整[10]。原理是计算缺失值所在序列的数据平均值,让平均值填补上缺失位置,计算公式如下:
(1)
式中,n代表缺失值所在序列的长度;x1,x2,…,xn代表除缺失值外序列中所有数值;xi代表缺失数据。
2)离散值处理
离散值主要是指与正常值区别较大的数值,包括异常值、错误值。去除方法可以通过分箱操作直接清除[11]。
通过上述几个部分的预处理工作,客服终端数据更加完整、规范,方便后续的运算和处理。
1.3 基于决策树算法的客服终端数据分类
若是通过计算所有数据的相似度来消除冗余,消除工作量巨大,工作效率较慢,因此在计算相似度之前,先通过决策树算法分类客服终端大数据,以降低后期消除工作的难度[12-13]。
选择ID3决策树,计算信息增益,并选择最大信息增益对应的属性构建分裂规则,实现数据分类[14]。信息增益计算公式如下:
G(X,A)=F(X)-F(X|A)
(2)
其中,
(3)
(4)
式中,G(X,A)代表信息增益;F(X)代表信息熵;F(X|A)代表条件熵;Sk代表集合X中属于第k类样本的样本子集;Xi代表X中属性A取第i个值的样本子集;Xik表示Xi中属于第k类的样本子集。
ID3构建决策树过程如下:
步骤1:初始化并设置信息增益的阈值,记为E。
步骤2:输入m个训练样本。
步骤3:创建一个初始节点。
步骤4:判断样本是否为同一类输出?若为同一类输出,则算法终止,把节点标记为树叶节点,并标记该类别为Pi;否则进入下一个环节。
步骤5:计算所有属性,选择信息增益最大的属性作为节点的分类属性,记为Amax。
步骤6:判断Amax是否小于E?若小于,回到步骤3;否则,进入下一个步骤。
步骤7:分裂属性中的每一个值都延伸出一个相应的分支,并依据属性值划分样本。
步骤8:判断分支是否还有样本?若有样本,重复上述过程;否则,得到一棵决策树[15]。
通过训练样本,完成了决策树的构建。基于构建好的决策树实现客服终端数据分类。
1.4 客服终端冗余数据迭代消除实现
基于上述决策树分类结果,计算同类间数据的相似度,以此实现客服终端冗余数据迭代消除。
在整个冗余数据消除过程中,同一类的类间相似度计算和消除器设计两个步骤最为关键[16]。下面针对这两个关键步骤进行具体分析。
1.4.1 类间相似度计算
类间相似度计算,即计算同一类数据间的相似性。计算公式如下:
(5)
其中,
(6)
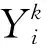
将相似度Sim(i,j)与设定的判别阈值Q作对比,判断是否为冗余数据。判断规则如下:
(1)当Sim(i,j)>Q时,认为数据是冗余数据;
(2)当Sim(i,j)≤Q时,认为数据不是冗余数据。
1.4.2 消除器设计
消除器的作用是根据冗余判断结果消除冗余数据。消除器结构如图2所示。
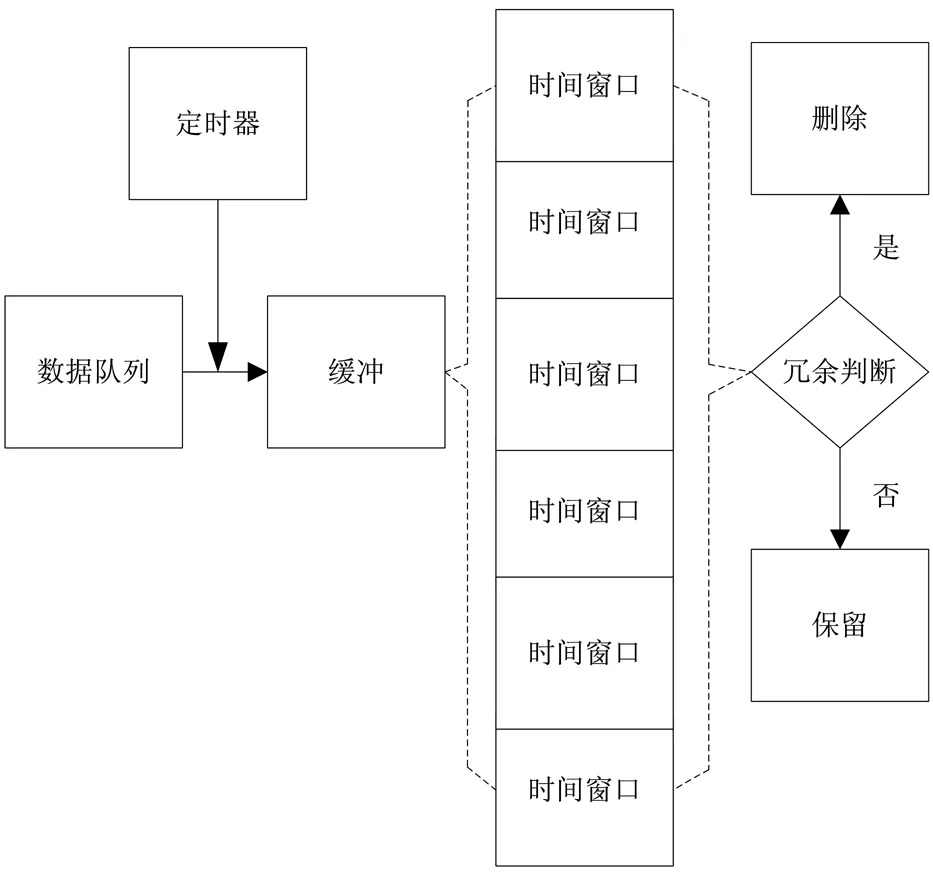
图2 消除器结构图
消除器是依据冗余判断规则,按照时间顺序逐一消除,最后留下相似数据中小于阈值Q的数据,组成消除后的客服终端数据,完成冗余数据消除。
2 仿真测试与分析
为测试研究方法在客服终端冗余数据迭代消除中的应用效果,以文献[2]提出的基于最大时间阈值与自适应步长的数据去冗余方法作为实验对照方法,与研究方法的实验结果进行对比。
2.1 测试样本
客服终端数据测试样本共有10个,其中前6个为训练样本,用于构建决策树;后4个为测试样本,用于测试方法的消除效果。各个样本的数据量、属性个数以及冗余率如表1所示。
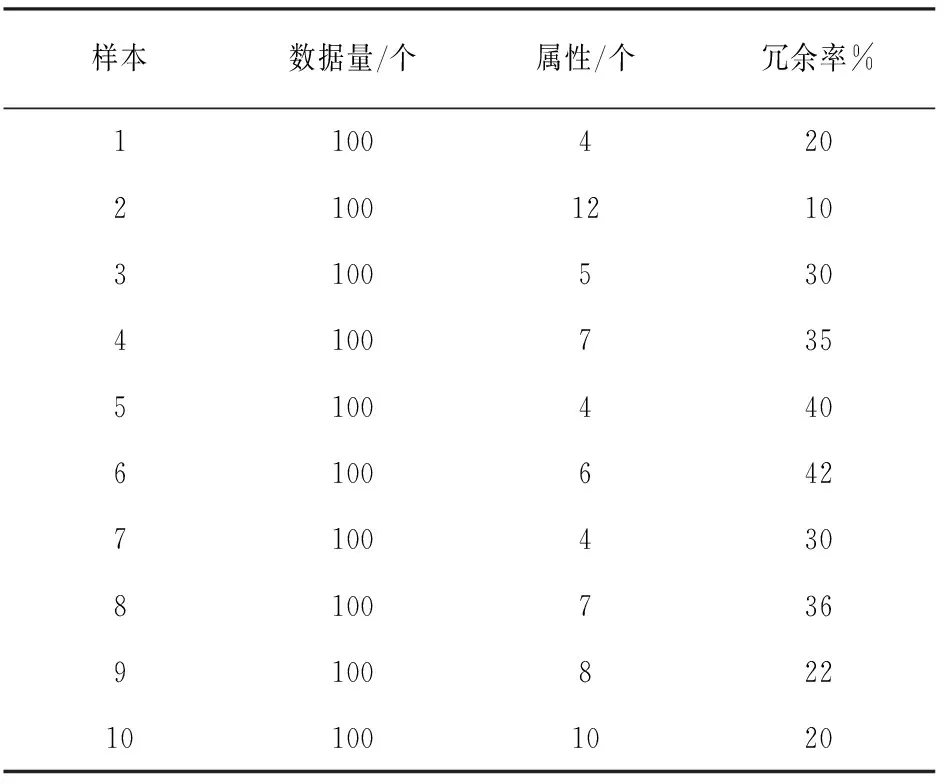
表1 样本的数据量、属性个数以及冗余率
2.2 决策树构建
按照1.3节流程,首先计算属性的信息增益,选择最大信息增益的属性作为分类规则,然后借助8个训练样本,通过ID3构建决策树。以样本1为例,构建的决策树结构如图3所示。
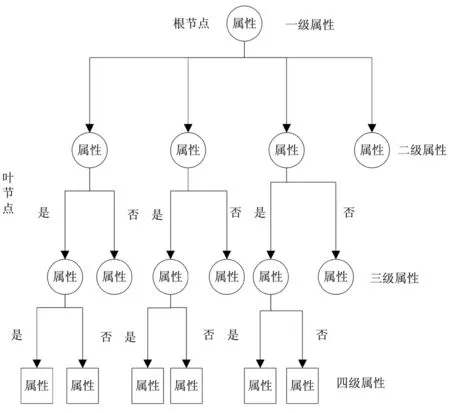
图3 样本1的决策树结构图
2.3 决策树分类
利用构建的决策树对剩余4个测试样本进行分类,分类结果如图4所示。
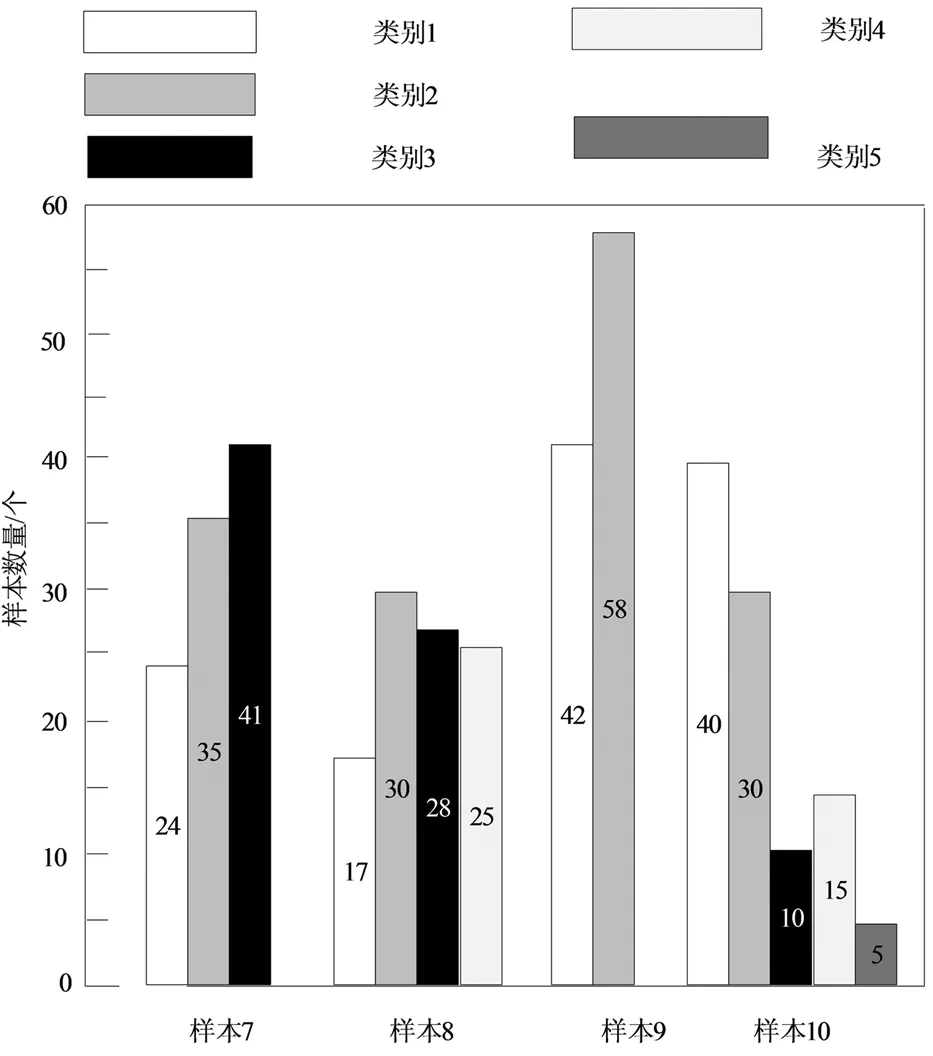
图4 决策树分类结果
2.4 冗余数据消除效果评价指标
选择空间缩减比作为冗余数据消除效果评价指标。该指标计算公式如下:
(7)
式中,R代表空间缩减比;c代表删除的冗余数据量;C代表样本数据总量。
2.5 冗余数据消除效果
计算类间数据相似度,完成最终的冗余数据消除处理。根据消除结果计算空间缩减比,结果如表2所示。

表2 冗余数据消除结果
对比表1实际结果,与文献[2]方法相比,研究方法的空间缩减比更接近真实的冗余率,说明消除效果更好,准确性更高。
3 结 论
客服终端的作用是记录用户需求,对制定销售策略以及提供售后服务都具有十分重要的作用,因此其咨询记录的价值非常高。然而,目前由于冗余数据的存在使得客服终端数据的挖掘十分困难。针对上述问题,提出了基于决策树算法的客服终端冗余数据迭代消除方法。该研究首先通过决策树对客服终端数据分类,然后通过计算类内数据间的相似度冗余消除。通过测仿真测试,证明了所研究消除方法的有效性。受到研究时间和篇幅的限制,研究深度有待进一步提升。下一阶段研究方向为如何改进决策树算法,因为决策树算法本身存在一定的缺陷,在一定程度上会影响冗余数据检测准确性。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
读者·原创版(2020年2期)2020-02-20
电子制作(2019年19期)2019-11-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年19期)2018-11-14
电子制作(2018年16期)2018-09-26
作文小学中年级(2018年12期)2018-01-25
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
中国交通信息化(2015年2期)2015-06-05
爆笑show(2015年1期)2015-03-26
