
结合级联ASPP和注意力交叉融合的图像语义分割算法*
2022-12-23 02:25:38刘宇红张荣芬
微处理机 2022年6期
陈 娜,刘宇红,张荣芬
(贵州大学大数据与信息工程学院,贵阳 550025)
1 引言
随着深度学习的发展,全卷积神经网络为语义分割带来了巨大的飞跃。2015年,一种基于全卷积网络的语义分割模型文献被提出[1],可实现密集的推理;2017年,具有编码器-解码器结构的SegNet网络被提出[2],编码器通过池层逐渐减小输入特征图的大小,解码器通过上采样逐渐恢复图像细节和特征图大小。为了优化输出,又有人提出了DeepLab的几种变体,其中,DeepLabv3+[3]基于DeepLabv2和DeepLabv3,采用了编解码器结构。语义分割本质上是一个逐像素的分类任务,为了生成密集逐像素的上下文信息,非局部神经网络[4]利用自注意机制实现特征重构;DANet[5]引入空间方式和通道方式的注意模块来丰富特征表示。基于注意力的方法[6-7]已被证明是语义分割中获取全局视野和上下文的有效方法。为进一步提高捕获效率与图像分割精度,在此提出一种结合级联ASPP和注意力交叉融合的图像语义分割算法,旨在能够分割出小尺度目标的理想区域,有效避免语义分割和标注不合理等问题。
2 算法设计
2.1 网络结构
DeepLabv3+网络是目前最优秀的语义分割模型之一,然而ASPP多层复杂的空洞卷积叠加容易失去图像中被忽略的小尺度目标信息,从而导致不准确的分割。为此,需对Deeplabv3+网络加以改进。改进算法的网络模型如图1所示。在改进算法中,编码器采用改进后的Xception网络作为骨干网络进行特征提取,在原图1/16大小的特征图后连接DASPP模块,它参考DenseNet[8]的网络结构,通过密集连接改进DeepLabv3+网络的ASPP模块,将其由原来的独立分支法改为级联法,实现更密集的像素采样,提高算法的特征提取能力。
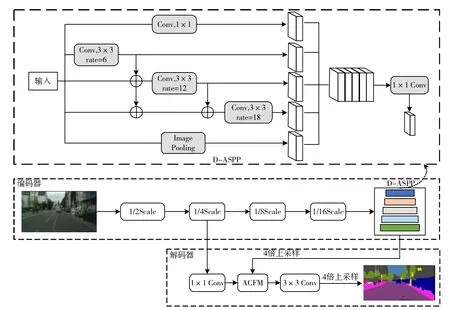
图1 改进算法总体结构模型
改进之后的ASPP模块在原有三个空洞卷积并行的基础上增加了串联结构,将空洞速率较小的空洞卷积的输出和主干网络的输出级联,再一起送入膨胀速率较大的空洞卷积,以达到更好的特征提取效果。
为了在解码器中更好地挖掘空间和信道特征,在对原始图像进行空洞卷积后,使用1×1卷积提取浅层特征,并将提取的浅层特征和D-ASPP模块输出的上下文信息输入到注意力交叉融合模块ACFM中,利用ASPP模块的密集像素捕获和注意机制对重要信息的选择性注意,将得到的特征图进行3×3卷积和四倍上采样,得到最终分割效果图。
2.2 密集空洞空间金字塔池化模块
空洞卷积运算及改进如图2所示。在图2(a)中,当膨胀率为6时,一维空洞卷积的感受野为13,但每次只有3个像素被用于卷积计算。将ASPP模块改为密集连接后,空洞率逐层增加,空洞率较大的层以膨胀率较小的层的输出作为输入,使得像素采样更加密集,提高了像素的利用率。在图2(b)中,在膨胀率为6的空洞卷积之前执行膨胀率为3的空洞卷积,这样最终卷积结果中有7个像素参与运算,采样密度高于膨胀率为6的空洞卷积直接执行的采样密度。在此基础上再次扩展到二维时,膨胀率为6的单层空洞卷积中只涉及9个像素,而级联空洞卷积中涉及49个像素,如图2(c)所示。
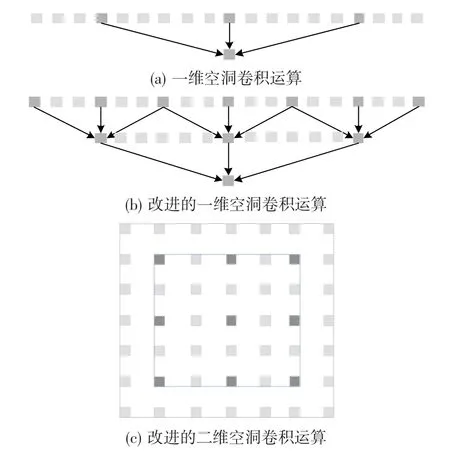
图2 空洞卷积运算及扩展
由此可见,较低速率层的输出通过密集连接的方式连接到较大速率层作为输入,增强了网络特征提取的能力。密集连接的ASPP模块不仅可以获得更密集的像素采样,还可以提供更大的感受野。对于速率为r且卷积核大小为k的卷积,感受野S的大小可表示为下式:
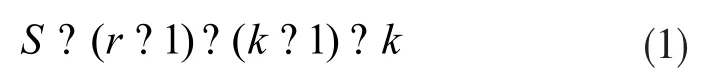
通过叠加两个空洞卷积可以获得更大的感受野,叠加后的感受野大小可以通过以下公式获得:

其中s1和s2分别是两个空洞卷积各自的感受野大小。由公式(1)和(2)可知原ASPP模块的最大感受野为37,改进的ASPP模块的最大感受野为73。改进后的模块通过跳层连接实现信息共享,不同膨胀率的空洞卷积相互补充,增加了感受野的范围。
虽然D-ASPP模块可以获得更密集的像素采样和更大的感受野,但是也增加了网络参数的数量。为了解决这一问题,在密集连接后的每个空洞卷积之前使用1×1卷积来减少特征图的通道数,从而减少网络的参数数量。设C0代表ASPP模块的输入特征特征图的通道数;Cl表示在第l个空洞卷积之前,1×1卷积输入特征图的通道数;n代表每个空洞卷积的输出特征图的通道数。参数数量计算公式为:
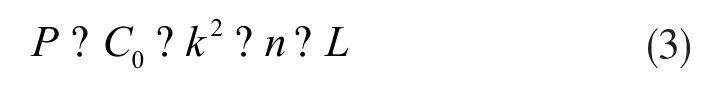
其中L是空洞卷积的个数,k是卷积核的大小,取值皆为3。以优化后的Xception网络为骨干网络时,该网络2048个输出通道的特征图作为ASPP模块的输入。ASPP模块每一个空洞卷积输出特征图的通道数n为256。各数值代入式(3),得P=14155776。
改进后的ASPP模块的参数量可由下式计算:
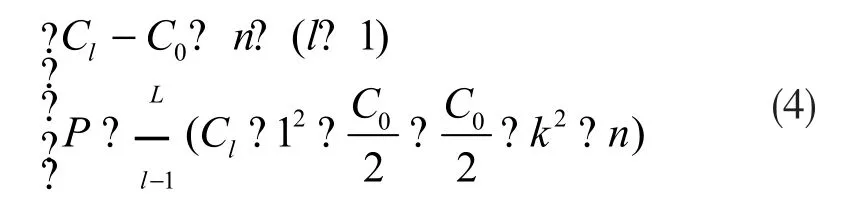
从式(4)中的两个方程,同样得出P=14155776。由此可见,改进后的密接ASPP模块在获得更密的像素采样和更大感受野的同时,成功地保持了与原算法相同的参数个数。
2.3 特征交叉注意力模块
改进设计的特征交叉注意模块如图3所示。利用空间注意(SA)模块提取浅层空间信息细化像素定位,利用通道注意机制(CA)捕捉全局上下文信息后再融合处理来抑制不重要的信息凸显关键特征。
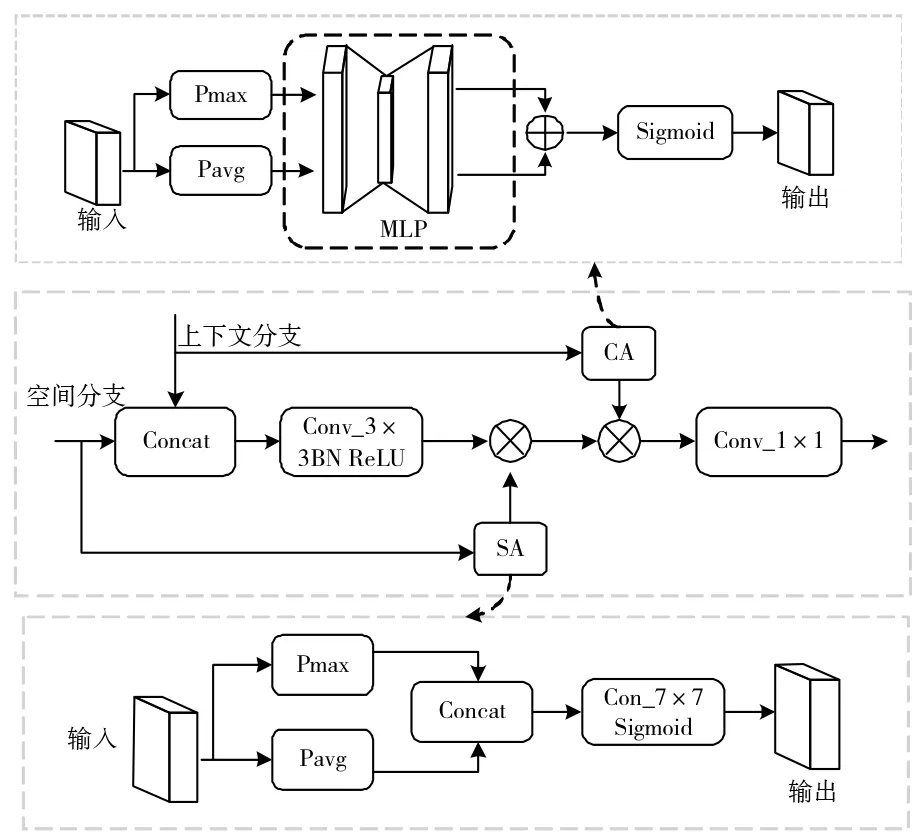
图3 新设计特征交叉注意力模块
首先连接两个分支的输出特征,并对融合的特征进行3×3卷积、批量归一化和ReLU单元处理。SA模块的特征被归一化和非线性卷积后乘以融合的特征被用作输入来帮助改进定位。再将上下文分支的输出应用于通道注意力模块,通过全局池和最大池沿空间维度压缩上下文特征,得到两个向量共享到一个全连通层和Sigmoid算子生成注意图。将注意力图乘以来自空间注意力模块的输出特征,并添加到融合特征。最后对获得的特征进行1×1卷积和四次上采样以获得特征图。在几乎没有额外训练参数和开销的情况下,本模型可以获得更重要的空间和信道特征图。
3 实验分析
3.1 实验条件与评价指标
Cityscapes是城市街景相关的数据集,作为图像语义分割任务中的重要数据库,其包含了50个大小城市和21个类别的5000张图像,其中2975张为训练集,500张为验证集,1525张为测试集。实验采用Pytorch框架、Ubuntu 16.04系统和Nvidia GeForce GTX1080Ti显卡;网络输入图像的尺寸大小是512×512像素;批量大小设置为8;初始学习率设置为0.0001;动量是0.9。
在评估所提出网络的分割性能时使用平均精度和均交并比MIOU来度量。MIOU值越大,模型的效果越好。假设总共有N个类,N+1是加上背景以后总的物体类别,pii(i=1,2,...,N)表示类别像素预测正确,pij和pji表示像素预测错误,数学公式可以表示为:
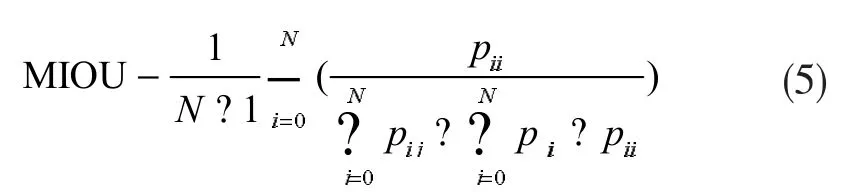
3.2 消融实验
为研究网络中D-ASPP和ACFM模块的性能,设计消融实验。采用Aligned Xception作为基准模型,然后逐步添加各个模块进行实验。分割结果如表1所示,尝试将各模块组合起来使用并对结果加以对比。
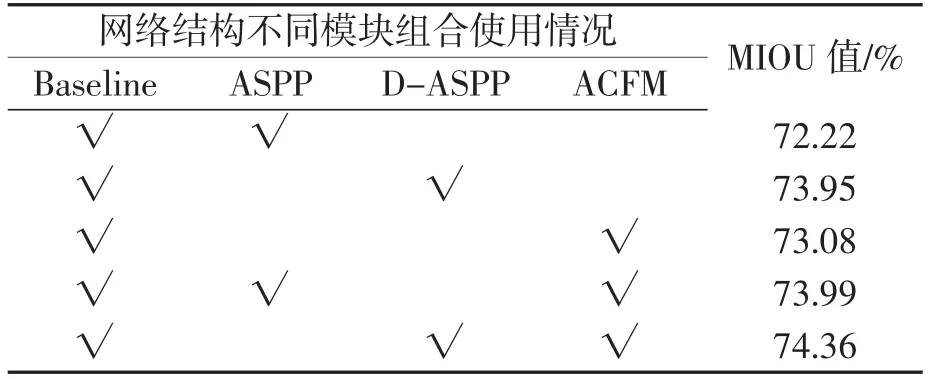
表1 不同模块组合使用对应MIOU值
如表中MIOU数据可见,以主干网络搭配DASPP使用,比组合使用ASPP模块的情况有更好的效果,MIOU值增加了1.73%。利用空间和通道注意力设计的ACF模块,其MIOU值增加了0.86%,在大量融合特征中通过抑制相同冗余信息提取出更为关键的特征。经实验,改进后的网络算法最终的MIOU值达到74.36%,相比原模型提高2.14%,证明了所提出模型的每个模块对于获得最佳分割结果的必要性。
3.3 常见模型分割性能对比
为进一步验证改进算法的有效性,将所提出的算法与其他经典网络FCN-8s、SegNet、DenseNet、DANet和DeepLabv3+在数据集Cityscapes上进行测试,测试结果对比如表2所示。
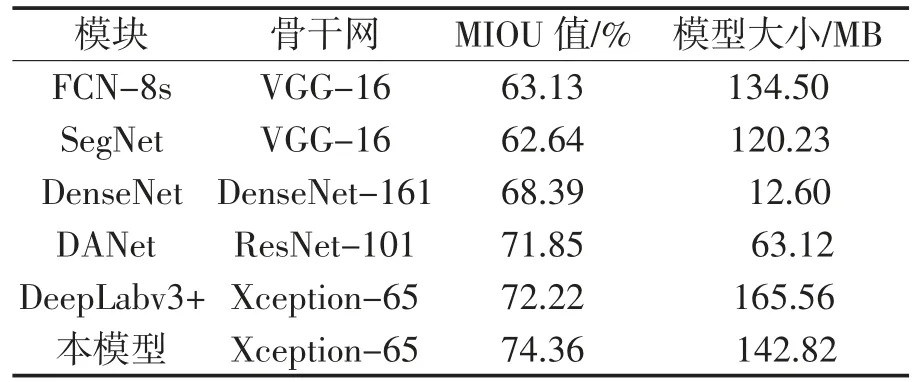
表2 不同网络模型测试结果对比
可以看出,FCN-8s由于没有考虑像素之间的关系,网络分割精度最低;SegNet网络没有考虑图像的上下文信息,MIOU值也不理想;由于引入双注意模块,DANet整体分类结果达到71.85%;虽然DeepLabv3+结合了多尺度信息,但各种复杂街景的分类精度并不理想。本研究的改进算法分类结果达到最优值74.36%,表明该模块设计有效改善了网络分类的识别能力。
从参数量、模型大小、帧速率方面考查改进算法相比原DeepLabv3+模型的改善,结果如表3所示。

表3 DeepLabv3+改进前后计算量对比
结合表2和表3可以看出,改进算法相比于其他经典网络具有更好的实用性能,虽然预测速度提高不多,但取得了更高的分割精度和更小的内存,综合效果最优。算法改进前后模型可视化划分结果对比如图4所示。可以看出,当分割目标过多时,原模型局部特征提取不连贯,容易使小目标信息丢失且目标边缘分割不完整。而在所提出的改进算法的结果中,图中交通灯及电线杆等纤长细小目标物均有更精细的分割结果,有利于减少意外的错误分类。
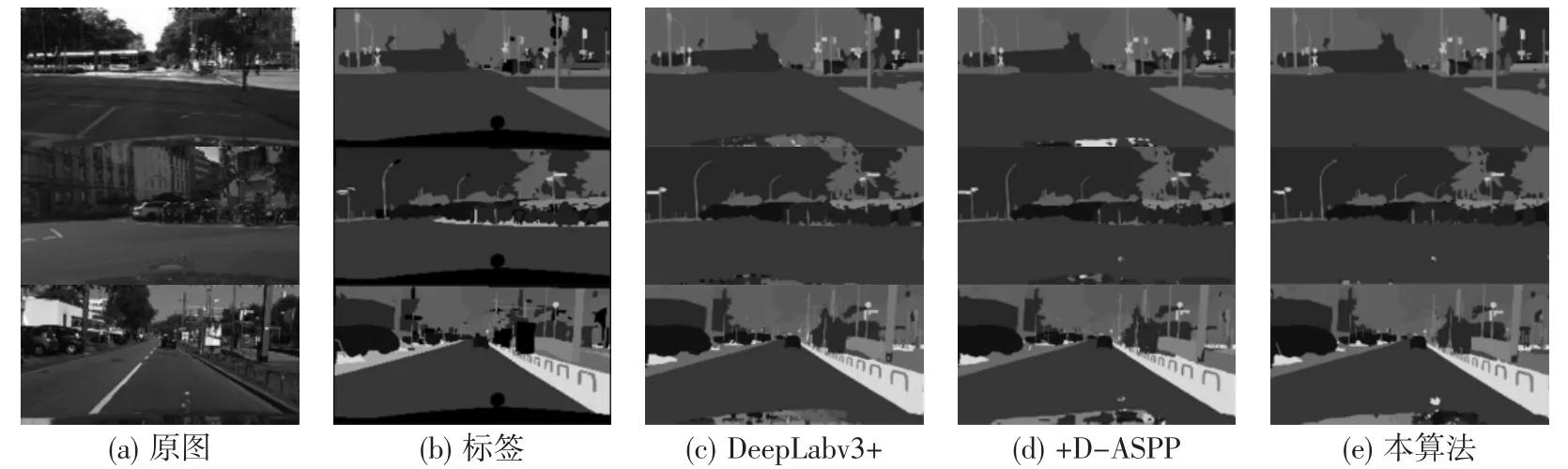
图4 Cityscapes数据集不同模块可视化比较
综上实验可知,在网络编码端,改进后的算法将原网络中的ASPP模块由各分支并行结构改为密集连接形式,实现了更密集的多尺度信息编码,获得了更密集的像素采样和更大的感受野,合理控制了网络的参数个数。在解码端,利用通道特征提供全局信息,利用空间特征细化目标边缘。通过密集连接的ASPP模块和交叉注意模块的联合学习得到图像分割,使模型整体具有更高的分割精度。
实验结果证明了改进算法在小目标检测上的优化,整体MIOU值达到74.36%,比原DeepLabv3+算法提高了2.14%,具有更高的分割准确率。
4 结束语
结合级联ASPP和注意力交叉融合的图像语义分割算法,针对的是DeepLabv3+模型多层卷积叠加造成的图像小目标细节信息丢失、目标边缘分割精度低等问题,已在公开数据集Cityscapes上验证了其有效性。改进算法取得了一定的效果,但还缺少泛化性,在后续研究中可考虑将模型中密集连接后针对小目标精准分割的特点拓展到其他领域,比如桥梁和建筑裂缝问题等,使之发挥更大更广的作用。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
今日农业(2021年9期)2021-11-26 07:41:24
英语文摘(2021年2期)2021-07-22 07:56:52
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
故事作文·高年级(2017年2期)2017-03-01 13:03:27
CHIP新电脑(2016年3期)2016-03-10 14:22:03
新闻传播(2015年20期)2015-07-18 11:06:46
中国质量与标准导报(2015年2期)2015-02-28 22:27:22
法人(2014年5期)2014-02-27 10:44:28
