
影响四川省洪灾损失的气象因子分析
2022-12-19 08:38:22陈民瑞黄伟军
东北水利水电 2022年12期
陈民瑞,黄伟军
(1.澳门科技大学创新工程学院,澳门 999078;2.成都大学建筑与土木工程学院,四川 成都 610106)
0 引言
四川省位于长江上游,由四川盆地和川西高原山地两大部分组成,处于亚热带区域,由于地形和不同季风环流的交替影响,气候复杂多样,导致洪涝灾害在四川多有发生且造成的损失巨大。Jim 等人[1]对洪水灾害风险的研究指出,降雨量和降雨频次是洪水灾害风险的主要影响因素。从整个致灾系统而言,杜华明等人[2]认为大气环流、降水量、地形地貌、河网水系是影响川滇地区主汛期暴雨洪水灾害的主要因素,人类活动对区域下垫面性质的改变,是加剧暴雨洪水灾害的触动因素。类似的研究中[3,4],暴雨洪涝灾害监测与评估的应用普遍局限于使用单一的标准化降水指数作为标准,而忽视了其他气候监测指数等因子对暴雨洪涝灾害的影响。在单场或多场洪水的分析中,或者仅仅寻找事物发生的机理,这种分析方法或手段无可厚非,但如果从长期及大范围洪涝灾害的预防和控制而言,气象因子的综合影响极其复杂,有必要增加尽可能多的关联信息[5],以期提高预测能力。目前,气象部门提供的气候系统监测指数(气象因子)产品中包含有132 种,在不考虑其他因素(或者进行归一化处理)前提下,其中哪些因子与洪水损失关联最大,哪些信息可以充分利用,具有重要的研究价值和应用价值[6,7]。本文根据1950—2020年四川省洪灾实测统计数据,基于双指标灾害评价体系对132 个气候系统监测指数与灾害因子用皮尔逊法和HDBSCAN 聚类法进行分析,进而研究影响四川省洪灾的主要气候监测指数。
1 洪水灾害因子分析
1.1 指标选取
洪水灾害的受袭对象主要包括人口、建筑物、基础设施、工矿企业等内容,不同部门统计的对象和口径并不一致。一般而言,人口密度高、地均GDP 高、财产价值高的区域遭受洪水灾害时造成的经济损失相对较高,人员伤亡也较大。为方便起见,本文所有洪灾损失统计指标树围绕的都是受灾人口和经济损失两个主题,并选择这两类指标来表示洪水灾害度。其中,受灾人口以受灾害人口数和死亡人口数2 个指标表示;经济损失用直接经济损失、倒塌房屋量(固定资产损失)和农作物受灾面积3 个指标表示。另外,分析发现受灾人口和直接经济损失2 个指标受社会经济发展的影响大,需要采用相对值表示,即(受灾人口数)/(当年社会人口总数)和(直接经济损失)/(当年国民生产总值)。为了简化计算,本文选取5 个指标中的(受灾人口数)/(当年社会人口总数)和(直接经济损失)/(当年国民生产总值)作为洪灾中评价受灾人口和经济损失的量纲,并把(受灾人口数)/(当年社会人口总数)称为人口损失比,(直接经济损失)/(当年国民生产总值)称为经济损失比,统称为两类洪水灾害损失因子。此外,各部门灾害统计中还有间接洪灾损失指标,但该指标受社会、经济和人为因素干扰过大,不同部门统计成果差异较大,因此不予采用。
综上,从《四川省统计年鉴》中摘录到1978—2020年四川省GDP 和人口总量数据(其中因重庆市1997年直辖,从四川省剔除,相关数据亦作相应处理),同时从《中国统计年鉴1986》中摘录到1949—1990年中国人口总量和社会生产总值,对少量空缺值的日曲线分别依据数据特征采用滑动均值或最相似曲线匹配等方法进行数据填充,将四川省人口总量和GDP 序列延长至1950年,再将其与对应灾害指标相比,得到受灾人口数和直接经济损失的相对指标。
由于1950—2000年的统计数据为年数据,而2001—2020年的数据是月数据,故将2001—2020年的240 组数据进行标准化后进行K-S 正态检验,得到显著性水平为0.057,即可认为统计数据符合正态分布,之后将1950—2000年的年统计数据按照标准正态分布分解成月统计数据。
1.2 数据标准化
洪灾两类指标经可信度分析后,处于不同区间,为消除量纲影响,便于分析和比较,则需要对数据进行标准化,使指标数据处于同一区间。
数据标准化实质是将数据按比例缩放,使其落入一个小的特定区间中,常用的方法有最小-最大标准化、零均值标准化、小数定标标准化等方法。文中采用最小-最大标准化原则将数据压缩到[0,1]闭区间,计算公式:

式中:i=1,2 为两类指标;k为每类指标中样本个数;x′ik为标准化后的值;xik为数据的原值;max(xik)为数据集里面的最大值;min(xik)为数据集里面的最小值。
2 基于皮尔逊相关系数的相关性分析
皮尔逊相关系数广泛用于度量两个变量之间的线性相关程度,其值介于-1~1 之间,在众多领域里得到了广泛应用[8]。本文将皮尔逊相关系数用于评价气候系统监测指数(气象因子)与洪水灾害因子之间的相关性,可以定性定量地对其相关程度进行度量,进而可得出影响四川省洪灾的主要气象因子。
另,由于洪涝灾害主要发生在5—9月,其中7,8月是峰值期,将洪灾损失按正态分布均化,将人口损失比和经济损失比从年数据转换为月数据,使之与月气象因子数据分布保持一致。
两个变量之间的皮尔逊相关系数定义为两个变量的协方差除以标准差的乘积[9],计算公式:
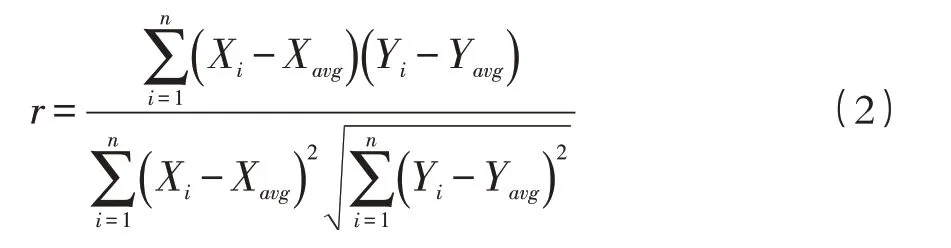
式中:r为皮尔逊相关系数的值;i= 1,2,…,840为1950年1月—2020年12月共计840 个月的月份值;Xi为132 个气象因子在i月的对应值;Xavg为132 个气象因子在840 个月中的平均值;Yi为两个灾害指标在i月的对应值;Yavg为两个灾害指标在840 个月中的平均值。
取两个皮尔逊相关系数的平均值大于0.5 的为强相关,平均值小于-0.5 的为负强相关。计算得出的相关气象因子如图1所示。其中,编号1,2,……,16,分别对应北半球副热带高压指数、北非副热带高面积指数、北非-北大西洋-北美副热带高压指数、北美副热带高面积指数、大西洋副热带高面积指数、北美-大西洋副热带高压区域指数、北半球副热带高强度指数、北非副热带高强度指数、北非-北大西洋-北美副热带高强度指数、北美副热带高强度指数、北大西洋副热带高强度指数、北美-北大西洋副热带高强度指数、亚洲极涡强度指数、太平洋极涡强度指数、北半球极涡强度指数和北半球极涡中心强度指数,即以上16 个气象因子为皮尔逊相关性分析计算所得的相关气象因子。
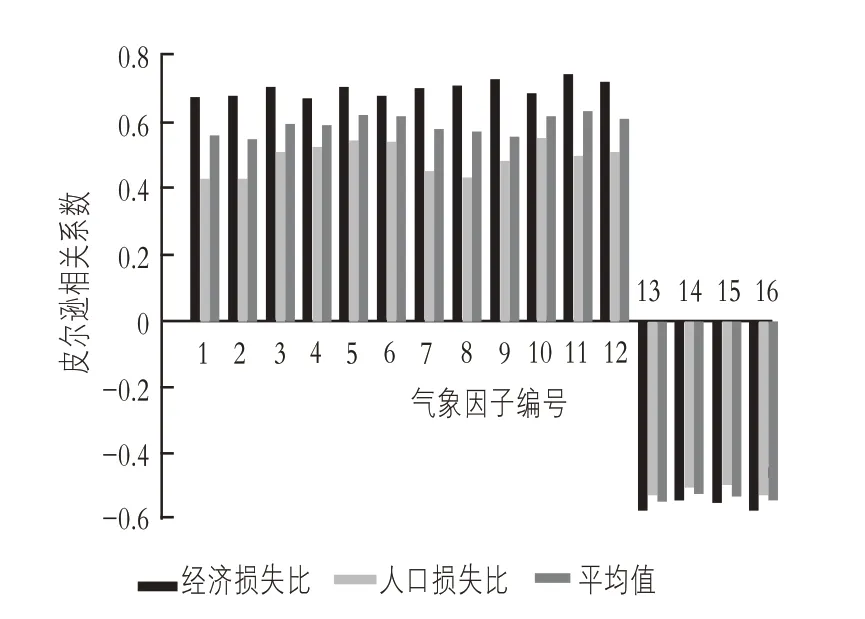
图1 双灾害指标皮尔逊相关性分析计算结果图
此外,由于不能确定得出的相关气象因子是否可以用于预测四川省洪灾的发生,将上面得到的相关气象因子与其前3 个月、前6 个月的双灾害指标用皮尔逊相关系数法进行相关性分析,结果得出的相关气象因子数目分别为16 和14 个,所以可以认为上面得出的相关气象因子可以用于预测四川省洪灾的发生。
3 HDBSCAN 聚类法
3.1 原 理
文中使用HDBSCAN聚类算法,通过将DBSCAN算法转换为分层聚类算法,然后根据聚类的稳定性提取平面聚类,对DBSCAN 算法进行了扩展[10-12]。HDBSCAN 可以被认为是以下步骤的组合。
1)计算数据集中所有数据对象在一个簇中的最小数量数据点(minPts)的核心距离。
2)计算完全图的最小生成树(MST)。
3)将完全图视为加权图,数据点作为加权图的顶点,将任意两个数据点之间边的权重作为两点之间的相互可达度量距离,基于相互可达度量距离对MST 进行扩展,得到MSTest。
4)从MSTest 中提取HDBSCAN 层次结构的树状图。
为了得到树状图的根,给所有的数据点赋予相同的标签(使其属于同一“聚类”)。之后迭代地从MSTest 中按权重递减的顺序删除所有的边。在每次删除之前,树状图将当前层次的值作为要删除的边的权重。在每次删除后,对包含被删除边端点的连接部分进行重新分配标签。为得到下一个树状图的层次,如果数据点仍有至少一条边,就给它分配一个新的聚类标签,否则就将它认作是噪声,最后得到聚类结果。
3.2 对气候系统监测指数进行分析
1)数据来源和预处理
文中的数据源于1950—2020年间四川省洪灾实测统计数据,以及132 个气候系统监测指数,对少量空缺值的日曲线分别依据数据特征采用滑动均值或最相似曲线匹配等方法进行数据填充。
2)分析过程
首先,将标准化后的数据按照时间排序后,将气候系统监测指数和双灾害指标转化为单一维度的时间序列向量,之后对其进行HDBSCAN 聚类分析,其中,参数设置为50,自动分类出不同相关值[13-15];最后,提取出不同数据所出现的不同相关值,之后对各数据在1950—2020年间内出现的不同相关值及状态变化模式绘制时序图进行判别。
3.3 计算结果与分析
对1950—2020年间的132 个气候系统监测指数和双灾害指标数据,采用HDBSCAN 算法进行聚类分析。文中由上至下仅展示了1980年2月、1990年1月、2001年3月的HDBSCAN 聚类图,见图2。

图2 HDBSCAN 聚类结果
此外,为了得出可以用于预测四川省洪灾发生的相关气象因子,文中将132 个气候系统监测指数与其前3个月、前6个月的双灾害指标用HDBSCAN法进行聚类分析,最后计算得出的相关气象因子分别为北半球副热带高面积指数、北非副热带高面积指数、北非-北大西洋-北美副热带高面积指数、北美-大西洋副热带高压区域指数、北半球副热带高强度指数、北非副热带高强度指数、北非-北大西洋-北美副热带高强度指数、北美副热带高强度指数、北大西洋副热带高强度指数、北美-北大西洋副热带高强度指数、热带印度洋偶极子指数和南印度洋偶极子指数。
同基于皮尔逊相关系数方法得到的结果比较后得出,北非副热带高面积指数、北美副热带高面积指数、北美-大西洋副热带高压区域指数、北半球副热带高强度指数、北非副热带高强度指数、北非-北大西洋-北美-副热带高压区域指数、北美副热带高强度指数、北大西洋副热带高强度指数、北美-北大西洋副热带高强度指数是对四川洪灾影响较大的气象因子。
为了验证所选因子的合理性,将其与四川省区域性暴雨过程进行了对比。根据四川省的区域特征,将盆地和攀西地区的日降水量达到或超过50 mm、川西高原的日降水量达到或超过25 mm的定义为县站暴雨日,若暴雨过程开始期与结束期的暴雨县站数不小于5,暴雨过程中总共出现的县站数不小于15,即认为出现了区域性暴雨过程。选取2010—2020年的132 个月间,四川省内发生区域暴雨过程中标准化后的暴雨站数与标准化后对应的气象因子进行比较,从中可以观察到两者的关联性和趋势性是比较明显的,其有效性也将在后续的预测模型分析中得到进一步的验证。
4 结语
根据1950—2020年四川省洪灾实测统计数据,选择全省受灾人口、直接经济损失为灾害因子,根据皮尔逊相关性分析法和HDBSCAN 聚类法,用双重指标对132 个气候监测指数进行分析,可以得出在统计的132 个气候系统监测指数中,北非副热带高面积指数等9 个气候系统监测指数对四川洪灾的范围和强度具有较强的影响。
通过使用HDBSCAN 聚类法,不用人工选择领域半径R和最小距离K,只用选择最小生成类簇的大小,算法可以自动地推荐最优的聚类结果。同时定义了一种新的距离衡量方式,可以更好地反映点的密度,因此,借助计算机系统利用该方法可以迅速且准确地确定影响四川省洪灾的主要气象因子,并且可以广泛地应用于相关领域。
由于从气象因子到区域性暴雨过程再到洪灾损失,是一条非常复杂的因果链,无论是用统计方法,还是用人工智能等新技术,只能概化地反映其中的关联程度,而不能对某一场具体的洪灾进行分析。或者说,某一场具体的洪水和洪灾,可以通过当时监测到的气象要素,比如西太平洋副高的强度、面积、脊线位置、西伸脊点位置,太阳黑子活动数,NINO3.4 区海温距平指数等,对雨洪趋势的形成和发展过程进行分析,但对于中长期的预测预报却力有不逮。本文尝试在一个很大的范围内寻找有效的强关联因子,并为试图建立概化的预测模型做准备,可以看作是一种十分有益的探索。
猜你喜欢
锦绣·上旬刊(2022年2期)2022-05-16 22:16:32
疯狂英语·新阅版(2021年10期)2021-12-08 01:24:54
疯狂英语·新悦读(2021年10期)2021-11-23 03:04:01
云南教育·中学教师(2019年12期)2019-08-13 07:28:26
山东冶金(2019年2期)2019-05-11 09:12:22
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
西藏科技(2016年5期)2016-09-26 12:16:42
大气科学(2015年5期)2015-12-04 03:04:44
上海金属(2015年3期)2015-11-29 01:10:09
少儿科学周刊·儿童版(2015年7期)2015-11-24 03:38:28
