
面向医学图像分割的多注意力融合网络
2022-12-18 08:11邹俊颖谭茜成李贵洋
计算机应用 2022年12期
李 鸿,邹俊颖,谭茜成,李贵洋
(四川师范大学 计算机科学学院,成都 610066)
0 引言
医学图像的语义分割是计算机辅助诊断中必不可少的步骤,在放射治疗的计划中,准确描绘肿瘤所在区域能最大限度地扩大靶区所覆盖的范围,同时能极大降低周围高风险器官的毒性[1]。在临床实践中,肿瘤勾画通常都是以手工或半手工方式来进行,这项工作不仅代价昂贵、单调乏味,标注人员还需要具备极强的专业知识且耗时耗力[2];因此,通过深度学习对病变区进行图像分割来辅助医生诊断一直是多年来研究的重点[3-4]。目前,医学图像分割已在多个器官上得到了应用,如肝脏分割[5-6]、脑肿瘤分割[7]、细胞分割[8]、心脏分割[9]等;但是,现阶段医学图像分割任务仍存在数据集不足、标注位置不准确等诸多问题亟待解决[10]。
近年来,随着计算能力的提高,深度学习通过学习输入数据与预测结果之间的非线性映射,在医学图像分割上也有了突破性的进展。Long 等[11]将编码器、解码器结构引入图像分割领域,提出全卷积网络(Fully Convolutional Network,FCN),通过将全连接层改为卷积层来保存图片的位置信息,使用反卷积(Deconvolution,Deconv)和跳跃连接相结合的方式进行上采样,得到较为精细的分割图。Ronneberger 等[12]提出U-Net,该网络主要是由U 形结构和跳跃连接两部分组成,融合图像的低层信息和高层信息,能较好地满足医学图像的语义特点。Zhou 等[13]通过整合U-Net 中每一层堆叠的特征来获取不同感受野的图片特征,达到分割的效果。Jégou 等[14]将U-Net 中的普 通卷积 替换为Dense Block 模块[15],模块中密集的跳跃连接能有效地解决梯度消失等问题,加强了U-Net 中每一层的特征传递,更有利于上采样后的图像恢复。Oktay 等[16]在跳跃连接部分使用注意力门控(Attention Gates,AGs)模块来突出图像的显著特征,抑制图像的无关特征,增强模型对前景重要特征的敏感度。Cai等[17]使用多尺度预测融合机制,通过跳跃连接将解码器的所有特征拼接起来,获取不同尺度的全局信息,在输出端融合空间、通道注意力来增强模型对不同特征的敏感度。
尽管基于卷积神经网络(Convolutional Neural Network,CNN)的模型已具有极为出色的表示能力,但由于卷积计算只有固定的接受域,难以对图像中存在远程依赖关系的特征进行建模,导致无法捕获足够的上下文信息。相较于CNN,Transformer[18]通过自注意力(Self-Attention,SA)机制不仅能有效建立长距离依赖,也能对下游任务显示出卓越的可传递性。现阶段,Transformer 已经受到广大学者的关注,已有一些结合CNN 与Transformer 的一些研究,如Zheng 等[19]用Transformer 作为编码器,压缩原始输入图像的空间分辨率,逐步提取更加高级的语义特征,通过解码器将特征映射为原始的空间分辨率来进行最终的像素级分割。Petit 等[20]提出U-Transformer 网络结构,它使用多头自注意力(Multi-Head Self-Attention,MHSA)来获取图片的远程依赖,使用多头交叉注意力(Multi-Head Cross-Attention,MHCA)与跳跃连接相结合进行上采样来过滤掉非语义特征,从而强化空间特征重构,优化空间分辨率。Zhang 等[21]通过融合两个并行的CNN分支和Transformer 分支,可以通过较浅的层数来获取图片的全局依赖性和局部细节特征,使用AGs 来融合不同层之间的多级特征。Valanarasu 等[22]提出局部全局(Local-Global,LoGo)训练策略,通过浅层全局分支提取图片的细节、纹理等几何特征,将整张图片进行切片,每一块切片通过深层局部分支来提取空间位置信息,两相结合得到最终的分割结果。Zhang 等[23]使用Transformer 金字塔,将CNN 提取的细节特征与不同分辨率的分辨图相结合能捕获多范围关系,通过自适应方案来访问不同的接受域以获取最佳的分割结果。Ji 等[24]通过将SA 模块嵌入基于CNN 方法的编码器、解码器架构中来充分利用视频所含有的时间信息和空间信息,以实现快速准确的息肉定位。由于Transformer 无法获取每一个切片之间的内部关系,Chu 等[25]在Transformer 中加入条件位置编码生成器,生成隐式的位置编码,让像素间分片后仍保持原有的空间位置关系。
近 期,Chen 等[26]提出了 TransUNet(merit both Transformers and U-Net),它同时具有Transformer 和U-Net 的优点:在编码器部分通过Transformer 为来自CNN 所传入的特征图进行编码,以此来获取图片的上下文特征;在解码器部分,对编码后的特征进行上采样与高分辨率特征图拼接来获取图片的精确定位。但TransUNet 在Transformer 进行编码的过程中,缺乏图片在局部区域内的信息交互,在切片重新组合的过程中,忽略了图像的线条、边缘、形状等几何特征;在图片解码的过程中,只是简单地将编码后的特征上采样与高分辨率特征相拼接,并未考虑两者通道、位置之间的相关性。针对以上问题,本文提出了一种多注意力融合的网络(Multi-attention FUsion Network,MFUNet)模型。该模型在编码器部分通过在Transformer 中引入分组卷积[27]来为编码特征提供长距离依赖的同时兼顾局部信息交互[28-30],增强编码特征的鲁棒性和特征间的局部联系;在解码器部分提出一种新颖的双通道注意力机制[31-34],融合多级特征的通道信息,弥补了模型所缺乏的通道间的信息交互,增强模型对通道间的关键信息的敏感度,进而提高分割精度。实验结果表明,MFUNet 能得到更精确的分割结果,在Dice 相似系数(Dice Similarity Coefficient,DSC)和 Hausdorff 距 离(Hausdorff Distance,HD)等指标上明显优于其他对比模型。
1 理论基础与基线模型
1.1 Transformer
Transformer 最早应用于机器翻译[18,35],擅长在建模序列元素之间建立远距离依赖关系。受到Transformer 强大表征能力的启发,研究人员将Transformer 扩展到计算机视觉任务[36-38],与其他网络类型相比,在各种视觉基准上(如图片的多模态信息融合、图片的多任务学习等)Transformer 显示出了卓越的性能。它主要由4 个重要部分组成:
1)自注意力。自注意力机制是注意力机制的一种改进,减少了对外部信息的依赖,增强特征的内部相关性,将输入的向量转化为3 个不同的矩阵,分别为查询矩阵Q、键值矩阵K和值矩阵V。将查询矩阵Q与键值矩阵K的转置相乘,得出两者之间的相似度矩阵QKT,若值越大表明越相关,通过softmax 函数对相似度矩阵进行归一化得到权重矩阵,最后将权重矩阵与值矩阵相乘得到输入矩阵的注意力,最终结果如式(1)所示:
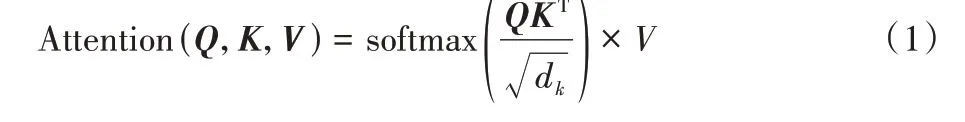
其中:dk表示查询矩阵或者键值矩阵的维度。
2)多头自注意力。多头自注意力机制是Transformer 的核心组件,它由n个自注意力模块组合而成,其中分别表示第i个自注意力的线性变换矩阵,它们分别与输入向量Xi相乘以获取在不同空间上的投影,增强模型的表征能力,得到对应的Q、K、V;然后把所有的输出矩阵拼接起来,再与线性变换矩阵Wo相乘,得到最终的自注意力输出矩阵,如式(2)(3)所示:
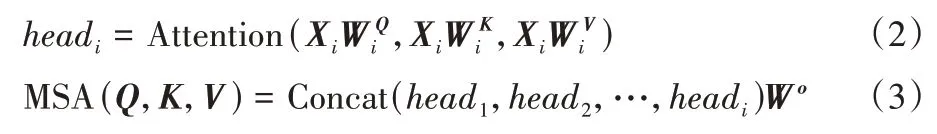
3)多层感知机。多层感知机主要由两个全连接层和一个线性激活层ReLU(Rectified Linear Unit)线性组合而成,W1、b1和W2、b2分别表示两个全连接层的权重和偏置,计算公式如式(4)所示:
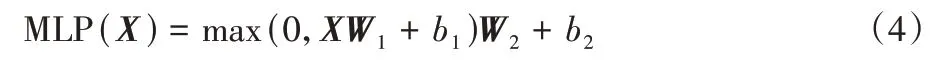
4)位置编码:不同于自然语言处理,图像只是一个单一的个体,在获取它的自注意力时,首先需要通过卷积神经网络将整张图片分割成固定大小的小块,然后拼接成一个可学习的位置编码矩阵来学习得到图片的位置编码信息。
最终,每一层Transformer 可以表达如式(5)(6):

其中:zl-1表示上一个Transformer 层的输出,通过Transformer变换后得到的zl作为下一个Transformer 层的输入,以此类推。LN为层归一化,能稳定向前传输图像特征,加快模型收敛。
1.2 TransUNet
TransUNet 通过将Transformer 层融入U-Net 的方式获取图像的全局联系和对特征图进行多尺度预测以及深层监督。TransUNet 在下游任务中展现了优越的可转移性,实现了特征的精确定位[39],完成了全局建模的优化,实现了图像的精确分割。TransUNet 主要由3 部分组成:混合型编码器模块、级联的上采样模块和分割头模块。
1)混合型编码器模块。完成原始图像从原始像素空间到多级特征空间的映射。混合型编码器由CNN 和Transformer 组合而成,首先将原始图像输入到CNN 特征提取器中来获取图像的高级特征并保留部分中低级特征,以便与上采样的特征进行拼接;然后将CNN 特征提取器输出的高级特征作为输入特征传入Transformer,获取图像像素之间的全局联系,实现图像特征的提取。
2)级联的上采样模块。完成从高级特征到分割掩码的解码过程。它由多个上采样步骤组合而成,与U-Net[12]一致,通过上采样将高级特征与混合型编码器模块中保存的相同尺度的中低级特征拼接,防止在图像恢复过程中单纯的上采样造成的一些细节特征的丢失,并保证复原图像的精确度。
3)分割头模块。完成对分割掩码的分割预测任务。通过一个卷积核大小为3×3 的卷积层,保证输出的分割掩码与医生标注的真实掩码保持一致。随后分别使用交叉熵和Dice 损失计算分割损失和分类损失,并将其加权平均计入总损失。
2 多注意力融合网络
2.1 问题描述
TransUNet 模型将Transformer 融 入U-Net 中,通 过Transformer 的内部自注意力解决了卷积运算无法远距离建模的局限性问题,通过跳跃连接和级联上采样有效地解决了编码特征恢复到分割掩码过程中所造成的部分特征丢失的问题。但TransUNet 依旧存在以下两个问题:1)由于Transformer 只接收1D 的长序列作为输入,在处理2D 图像时仅仅是将图片分为N个空间上毫不相干且大小相同的分块,缺乏相邻分块序列中的局部信息交互,导致在最后图片复原过程中相邻分块拼接部分细节特征丢失,影响最终的分割效果。2)在上采样解码的过程中,仅简单地将高层特征进行上采样后与低层特征拼接起来,然后通过卷积层,并未考虑通道间的信息交互,导致数据的空间层级化信息丢失,以致出现过度分割和错误分割等问题。
2.2 模型结构
针对TransUNet 模型的问题,本文提出了一种医学图像分割下的多注意力融合网络(MFUNet)。该网络模型通过使用CNN 特征提取模块、带有卷积操作的特征融合模块(Feature Fusion Module,FFM)和带有双通道注意力(Double Channel Attention,DCA)的级联上采样模块,建立模型的远程上下文交互和空间上的依存关系。首先通过CNN 特征提取网络来提取图像的全局特征,并保存其中的N个中低级特征以防止在上采样过程中所造成特征丢失的情况;再将得到的特征传入带有分组卷积操作的Transformer 特征融合模块中,通过其本身的自注意力机制来增强图片内部的长距离依赖,通过卷积操作来增强不同分块之间的局部联系,完成图像的编码过程;图像的解码是由一个级联的上采样组成,在每一次2 倍上采样的过程中,加入双通道注意力机制,从通道方向来增强特征的表征能力,弥补了模型对通道间的关键信息敏感度不足,进一步增强了模型在空间上的远程依赖关系;最后,通过最小化交叉熵解决分类过程中类别不平衡的问题,通过Dice 损失约束图像的分割大小,以完成最终的分割任务。模型如图1 所示,其中:n_patch为Transformer 分块个数,D为Transformer 矩阵编码维度(默认大小为768)。Conv 模块是由大小为3×3 的卷积和ReLU 构成,特征融合模块(FFM)细节如图2 所示,双通道注意力(DCA)模块细节如图3 所示。
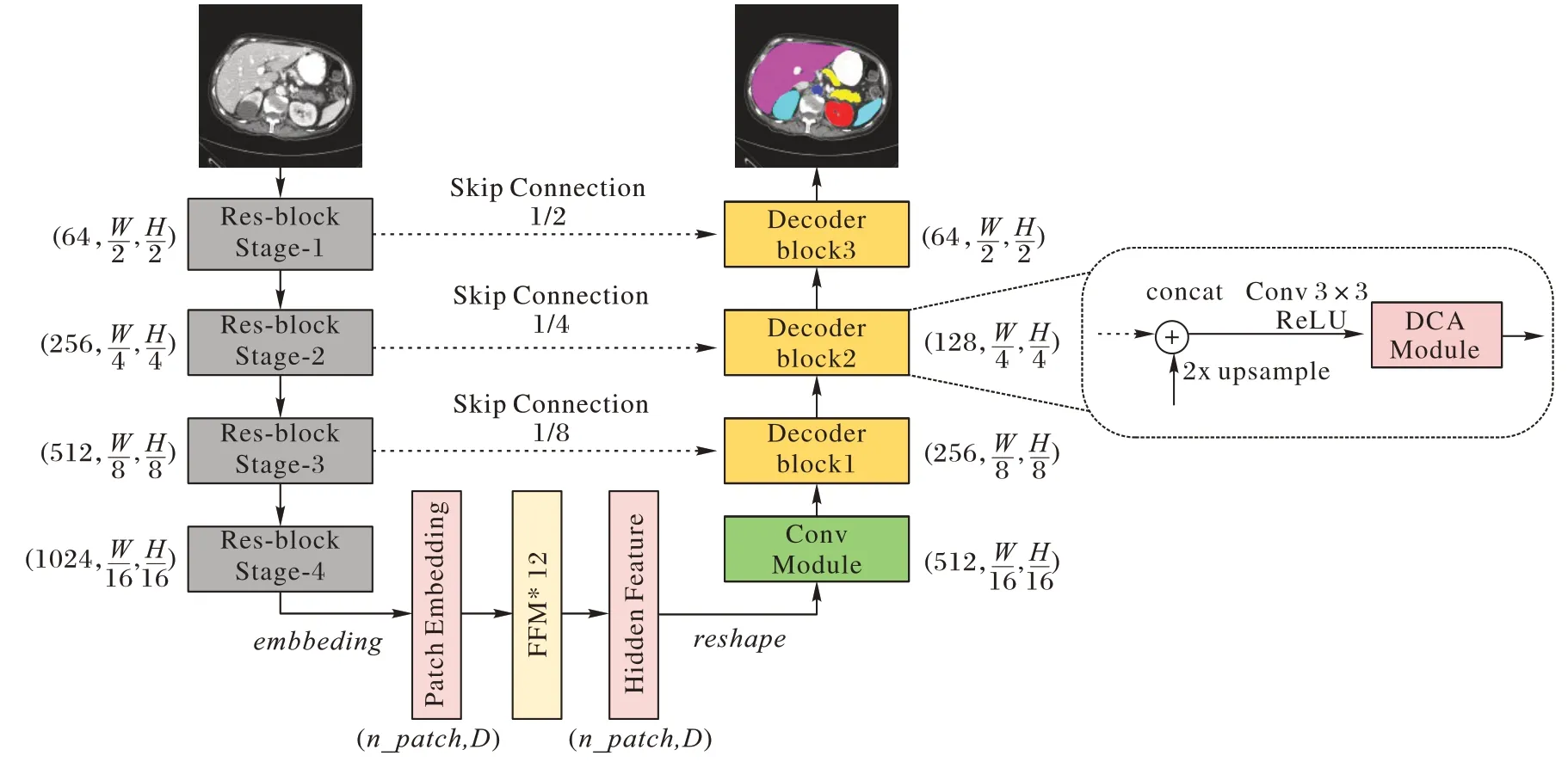
图1 MFUNet模型Fig.1 MFUNet model
1)CNN 特征提取模块。首先将n张图片随机打乱,选取其中t张图像数据x∈RH×W×C×m输入到由ResNet50 组成的CNN 特征提取网络中,其中n表示图片的总数,m表示批次数,C表示图片的通道数,实现图像数据从高分辨率图像到低分辨率图像的转化,完成图像特征的粗提取,同时保留N层中低层特征(N≤3),从小到大分别表示为,以便于还原上采样所造成的信息损失。
2)带有卷积操作的特征融合模块。将CNN 特征提取网络所得到的低分辨率图像xc转化为Transformer 所需要的1D长序列,编码序列的长度为embedding,每个切片的分辨率大小为(P,P),默认大小为16,分组个数N=WH/P2。受到Transformer 条件位置编码[25]和卷积的局部相关性和空间不变性特点的启发,设计了FFM。整个网络沿用了Transformer本身的特点,由层归一化单元、多头注意力和多层感知机组成,在输出端加入卷积操作。通过将Transformer 与分组卷积操作串联起来,在获取图片的长距离依赖的同时也可以增强相邻切片之间的局部联系,最终得到带有自注意力机制的图像特征。具体如图2 所示。

图2 特征融合模块Fig.2 Feature fusion module
3)带有双通道注意力的级联采样模块。为了将带自注意力的低分辨率图像xt恢复到原始图像大小,首先将低分辨率图像特征xt通过双通道注意力模块(DCA),将特征分别进行全局平均池化和全局最大池化,得到大小为C× 1 × 1 的图像特征x1和x2,依次将x1和x2传入共享的全连接层、ReLU层和全连接层,完成x1和x2的通道数由C到C/r再到C的转变(r表示通道的缩放比例,默认为16)。通过将数据特征映射到样本标记空间并重构,实现模型通道间跨信道交互并增强模型对通道间关键信息的敏感度[31]。最后将经过挤压和扩张操作后的x1和x2相加,然后通过Sigmoid 层以获得通道权重矩阵,再与输入的特征进行点乘以获取最终的通道注意力特征图,具体如图3 所示。然后对双通道注意力模块输出的特征进行2 倍上采样并与CNN 特征提取器中对应的高分辨率特征拼接,依次通过卷积、批归一化、ReLU 激活函数,重复上述操作N次(N≤3)。将经过上采样网络输出的特征xf∈RH×W×16通过由3×3 卷积组成的分割头来获取最终的分割图像xs∈RH×W×class。最后,通过计算医生标注图像与解码器所获得掩码图像的交叉熵损失作为分类损失Lclass,如式(7)所示;Dice 损失作为分割损失Lseg,如式(8)所示;将两者加权平均以得到最终的损失值,如式(9)所示,以实现最终的分割任务。

图3 双通道注意力模块Fig.3 Double channel attention module
2.3 损失函数
损失函数是一种衡量损失和错误程度的函数,可以很好地反映分割图像与标签图像之间的差异,本文采用的损失函数由交叉熵损失和Dice 损失两部分组成[40-41]。
Lclass为交叉熵损失,用于评估图像数据在分割过程中对像素点分类时所产生的损失,能够衡量同一随机变量中的两个不同概率分布的差异程度,值越小表明模型的预测效果越好。计算公式如式(7)所示:
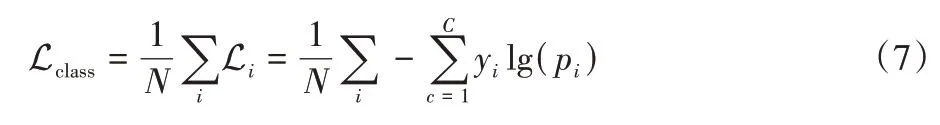
其中:C为标签;yi表示是否为类别i,若为该类别,yi=1,否则yi=0;pi为样本i属于类别C的概率。
Lseg为Dice 损失,用于评估预测的分割图像与真实的分割图像之间的相似度的一种度量损失,取值范围为[0,1]。计算公式如式(8)所示:

其中:|X∩Y|表示真实图片与预测图片的交集,|X|与 |Y|分别表示各自的元素个数。
MFUNet 模型的总损失函数为Ltotal,公式如式(9)所示:

3 实验与结果分析
3.1 实验数据集
1)Synapse 多器官 分割数据集(Synapse multi-organ segmentation dataset,Synapse)。使用MICCAI2015 挑战赛中多图谱腹部标记数据集中的30 张腹部电子计算机断层扫描(Computed Tomography,CT)进行实验,共含有3 779 张切片,每个CT 扫描中含有85~198 张切片。整个数据集被划分为训练集和测试集,分别包含18 个训练样本和12 个测试样本。本文使用DSC 和HD 作为8 个腹部器官(主动脉、胆囊、脾脏、左肾、右肾、肝脏、胰腺、脾脏、胃)的评价指标(见3.3 节)。
2)自动心脏诊断挑战(Automated Cardiac Diagnosis Challenge,ACDC)数据集。ACDC 数据集从100 名患者的核磁共振成像(Magnetic Resonance Imaging,MRI)扫描仪获得,每个MRI 扫描中含有18~20 张切片;同时,MRI 扫描仪分别标记了每个患者的左心室(Left Ventricle,LV)、右心室(Right Ventricle,RV)和心肌(MYOcardium,MYO)。整个数据集被划分为70 个训练样本、10 个验证样本和20 个测试样本,仅使用DSC 来评估本文模型。
3.2 实验参数设置
实验基于PyTorch 1.7.1 深度学习框架。对于所有的训练样本,使用图片旋转和翻转来增加数据的多样性。在训练过程中,先将图片裁剪为224×224 大小,采用小批量随机梯度下降方法,每次实验进行150 轮迭代,训练批次为24,动量参数为0.9,学习率为0.01,优化器中权重衰减参数为0.000 1,所有实验在32 GB 的NVIDIA V100 下完成。
3.3 评估指标
评估指标主要用于评估模型的性能优劣,判断当前模型是否稳定且获取的结果是否精确。本文采用的评估指标由Dice 相似系数(DSC)和Hausdorff 距离(HD)两部分组成[40-41]。由于DSC 对分割像素的内部填充的约束性更强,HD 对分割的边界的敏感程度更高,将两者结合起来评估更有利于图像分割任务,以获取最精确的分割结果。
1)DSC。DSC 用于度量两个集合的相似性,通常用于计算两个样本之间的相似度。与Dice 损失类似,取值范围为[0,1],值越大表明两个样本越相似。具体公式如式(10)所示:
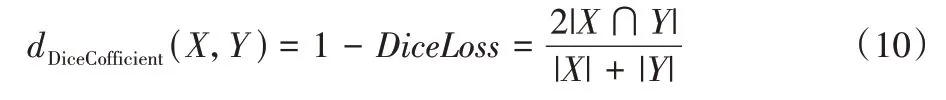
2)HD。HD 是描述两组点集之间相似程度的一种量度方式,它能捕获两个多边形的细微之处,主要是指一个点集中的点到另一个点集中的点的最短距离的最大值。具体公式如式(11)所示:
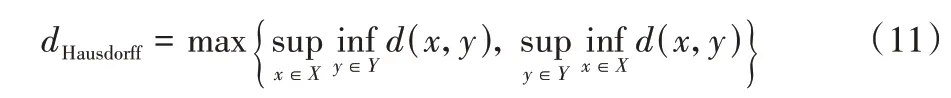
3.4 结果与分析
为了验证本文模型的分割效果,在同等条件下进行了对比实验。本文的对比网络采用了较为先进的分割模型,如V-Net[42]、DARR(Domain Adaptive Relational Reasoning)[26]、U-Net[12]、Att-UNet(Attention U-Net)[16]、Vit(Vision Transformer)[26]以及最近提出的TransUNet[26],R50 是指模型的编码器是由ResNet50 构成。为了避免实验的分割精度出现偶然峰值的情况,每组实验经过n次训练(n≥3),再加权平均后得到最终的实验结果。Synapse 数据集与ACDC 数据集的实验结果分别如表1、2 所示,图4 为模型在Synapse 数据集上的分割实例。
3.4.1 Synapse多器官分割数据集
如表1 所示,实验结果表明本文所提出的MFUNet 在DSC 上达到81.06%,HD 降低至28.05%,与基线模型TransUNet 相比,MFUNet 模型在DSC 上提升了4.6%,HD 减少了11.5%。为了进一步说明FFM 和DCA 模块的有效性,本文分别进行了两组消融实验:1)MFUNetfffm,不包含DCA 模块;2)MFUNetdca,不包含FFM。从数据结果可知,与基线模型TransUNet 相比,MFUNetfffm模型和MFUNetdca模型在DSC 指标和HD 指标都具有显著的改善;同时,结合了FFM 和DCA模块的MFUNet 分割模型所产生的分割图像在内部填充和边缘预测方面都明显优于其他对比模型。
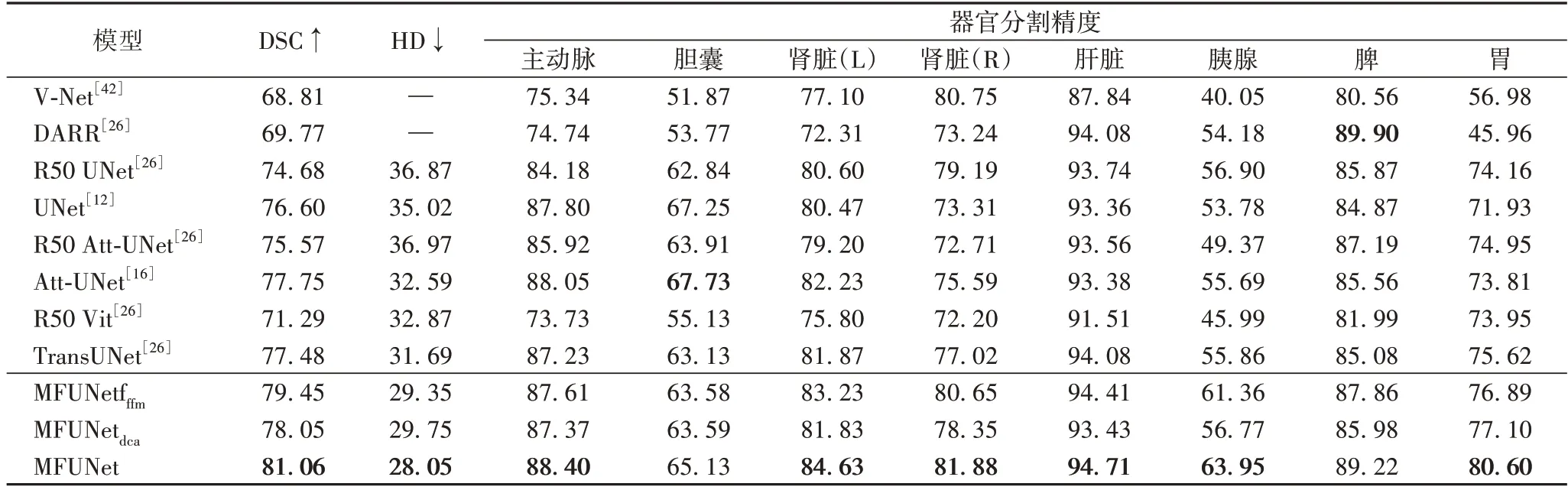
表1 不同模型在Synapse多器官分割数据集上的分割精度 单位:%Tab.1 Segmentation accuracies of different models on Synapse multi-organ segmentation dataset unit:%
图4 是多种不同的分割模型在Sy napse 多器官分割数据集上的分割结果。图4(d)(e)是由Att-UNet 和U-Net 两个只基于CNN 的模型生成的图像,由于单纯卷积操作的局限性,两者都存在对器官的过度分割,如将脾脏误判为肝脏(图4第二行(d)(e))。相较于本文所提出的MFUNet,图4(c)的TransUNet 模型仅仅考虑到图片的长距离依赖和融合上下文信息,并未考虑图像的局部依赖关系和融合上下文信息的过程中通道信息的重要性,因此在胃上的分割存在漏标记和过度标记的情况(图4(c)第一行和第三行)。实验结果表明,MFUNet 模型相较于其他对比模型分割更加精确,更接近于医生手动分割结果。
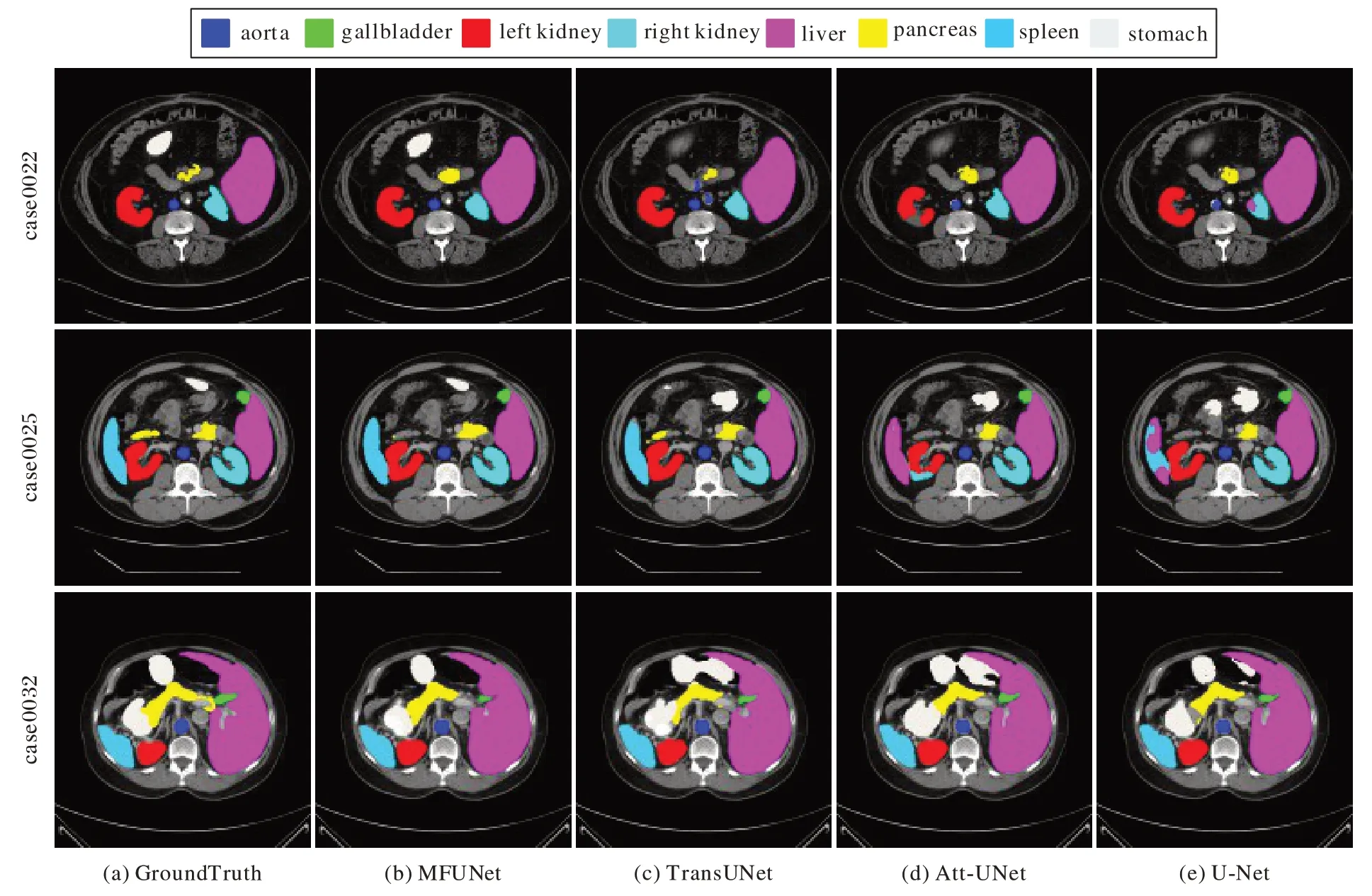
图4 不同模型在Synapse多器官数据集上的分割结果Fig.4 Segmentation results of different models on Synapse multi-organ segmentation dataset
3.4.2 自动心脏诊断挑战数据
相似地,将本文所提出的MFUNet 模型与其他对比模型用于自动心脏诊断挑战数据集,实验结果如表2 所示。从表2 可知,MFUNet 模型仍然有极好的性能,其整体分割准确度达到90.91%,并且在右心室和心肌两部分的分割精度明显优于现有模型。与基线模型TransUNet 相比,MFUNet 在右心室和心肌两个器官的分割精度分别提升了1.43 和3.48 个百分点。实验结果进一步表明本文所提出的多注意力融合网络MFUNet 具有良好的泛化性和鲁棒性。
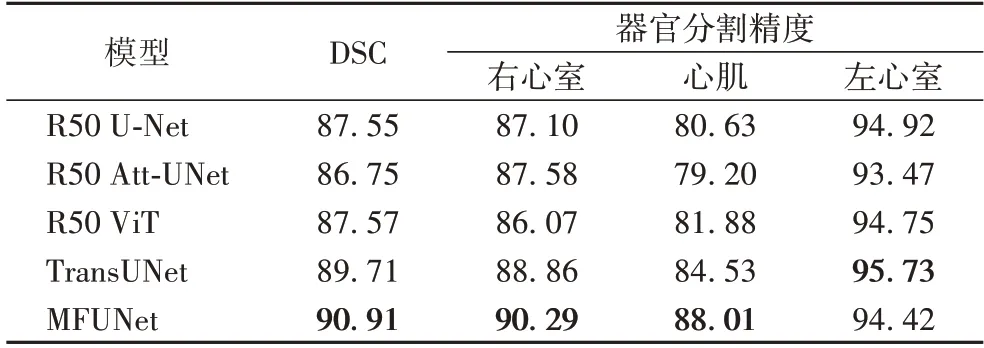
表2 不同模型在ACDC心脏分割数据集上的分割精度 单位:%Tab.2 Segmentation accuracies of different models on ACDC heart segmentation dataset unit:%
3.5 消融实验
为了探讨不同因素对模型性能的影响,本文通过控制变量的方式在Synapse 多器官分割数据集上进行了一系列的消融实验,主要包含了以下几点因素对模型性能的影响:
1)跳跃连接数量。为了探讨不同连接数量对模型造成的影响,在1/2、1/4、1/8 分辨率尺度下分别添加跳跃连接,连接数量分别设置为1、2 和3,结果如表3 所示。从实验结果看出,分割性能随跳跃连接数量的增加而提升。因此,本文将跳跃连接数量设置为3 以追求更精确的分割精度。

表3 跳跃连接数量的消融实验 单位:%Tab.3 Ablation experiment for number of skip connections unit:%
2)模型规模大小。从表4 可见,实验训练两个规模大小的模型“base”和“large”,两个模型的隐藏层大小、Transformer层数以及每层Transformer 中注意力的个数分别为12、768、3 072 和24、1 024、4 096。从表4 可见,“large”模型能获得更精确的分割结果,但提升不显著且会带来巨大的算力开销。因此最终选择“base”模型来进行本文实验。

表4 模型规模大小的消融实验 单位:%Tab.4 Ablation experiment for model scale unit:%
3)输入分辨率。本文考虑了低分辨率图像(224×224)和高分辨率图像(384×384)对模型造成的影响。从表5 可见,在保证分割的切片大小一致的情况下,高分辨率图像的输入序列将会更大,因而提升了模型的相对性能。考虑到高分辨率图像会使网络的计算负荷显著增加,本文选择以224×224分辨率图像作为输入。

表5 输入分辨率的消融实验 单位:%Tab.5 Ablation experiment for input resolution unit:%
4)卷积分组数。本文设置了不同的分组数,分别为1、48、768:当分组数为1 时表示普通卷积,当分组数为768 时可理解为深度卷积(Depthwise Convolution,DC),深度卷积能极大地缩小卷积重复计算所带来的巨大参数量,达到简化模型的效果。从表6 可见,使用深度卷积时模型分割更为精确。

表6 MFUNet中卷积分组数的消融实验 单位:%Tab.6 Ablation experiment for number of convolution groups in MFUNet unit:%
4 结语
本文提出了一种新颖的多注意力融合网络模型(MFUNet)用于医学图像的分割。该模型通过在Transformer中加入分组卷积操作来增强相邻分块特征间的局部联系,在上采样部分加入双通道注意力来进一步增强模型对通道的重要特征的敏感程度。通过对多器官分割任务和心脏分割任务的大量实验结果表明,MFUNet 具有出色的性能和泛化能力,其实验结果均优于其他对比模型。此外,对于如何实现更好的边缘预测,以保证预测分割图更贴合医疗靶区大小是需要进一步研究的问题。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
共产党员(辽宁)(2015年2期)2015-12-06
