
多模态内容资源编目及知识表示研究*
2022-12-15 07:36:04刘沛鹞罗卓然魏家泽程齐凯
数字图书馆论坛 2022年11期
刘沛鹞 罗卓然 魏家泽 程齐凯
多模态内容资源编目及知识表示研究*
刘沛鹞 罗卓然 魏家泽 程齐凯
(武汉大学信息管理学院,武汉 430072)
在多模态信息资源体量快速增长的环境下,为更有效地对内容资源开展编目及知识表示工作,本文从多模态的角度出发,探讨在“实体-属性-关系”结构下多模态资源编目可行性,提出一种适用于多模态资源的编目框架M-RDA、梳理内容资源模态归一化方法。本文重点扩展编目框架中的多模态属性与关系类目,从4个模态维度出发,挖掘多种资源间的描述补充关系,在著录资源的同时对其模态特征及关系进行标注。此外,为实现编目规则下知识的组织和表达过程,本文从事件描述的原因、对象、地点、时间、人员、方法6个方面提出一种基于5W1H的多模态知识表示方法,实现多模态资源从标签获取、编目到知识表示的完整过程,为多模态资源的编目自动化提供理论参考和实践案例。
多模态资源;编目;RDA;知识表示
随着互联网信息技术的快速发展,公共信息平台资源组织管理中,多模态内容资源数量激增、知识碎片化给数据使用者带来较大的检索成本,而传统的资源编目方式难以对多模态的碎片化信息进行有效组织,学界对多模态内容资源编目的相关研究也较少。在此情景下,对多模态内容资源进行有效合理的编目与知识表示变得尤为重要。因此,本文将针对编目工作中的多模态著录、多种资源间的关系定义进行讨论,构建一套资源描述型编目规则并合理高效地表示多模态知识。
传统图书编目工作通常是根据资源的特征针对文献种类进行类目的划分,它是一种资源属性的定义和阐释。20世纪国际通用的《英美编目条例》(AACR)和我国早期施行的《中国文献编目规则》将知识世界看作由文献组成的空间,文献需要从不同角度、通过各种指标去描述,但这种做法忽视了实体的关联性[1],也未将“关系”这一类别纳入编目框架中。2010年正式问世的资源描述与检索(Resource Description and Access,RDA),是专为数字环境发展下满足资源著录与检索的新标准[2]。该规则获得了国际上图书馆、档案馆的广泛采纳,成为全球图情、出版、信息等领域数字化背景下的资源管理新标准。
多模态内容资源是指在多种信息载体下资源内容层面的数据对象,呈现海量化、碎片化特点,缺少知识角度的清晰性、完备性,用户需要浏览大量资源才能满足搜索需求。随着文本、图片、音视频等模态数据的指数级增长,在传统的资源编码规则约束下,多模态挖掘算法难以高效运行,从而导致数据处理速度已经无法满足实际需求[3]。如今,随着图片、音视频等多模态资源的形式趋于多样化和体量迅速扩张,使得不同资源对象的多模态属性更加多元,这些属性因为时间、空间等维度的交叉产生多种关联关系。因此,在多模态资源的背景下将“关系”这一属性纳入编目框架对实现内容资源的有效管理显得尤为重要。
1 研究现状
知识表示是指把知识客体中的知识因子与知识关联起来,便于人们识别和理解知识[4]。知识表示主要有逻辑表示法、产生式表示法、框架表示法等。其中:逻辑表示法是基于符号逻辑组织方式的知识表示法,适用于自动定理的证明;产生式表示法是一种条件-结果式规则表示法,对于本文多模态资源的复杂情况无法适用[5];框架表示法是把某一特殊事件或对象的所有知识储存在一起,形成具有一定规则结构的表达式。其主体是固定的,表示某个固定的概念、对象或事件,其下层由一些槽组成,表示主体每个方面的属性[5]。
5W1H分析法最早由美国政治学家哈罗德·拉斯韦尔(Harold Lasswell)提出[6],这种逻辑符合多模态资源系统性表示的知识结构,适合运用在事件陈述和知识表示上。本文提出一种基于5W1H的多模态资源知识表示方法,并介绍不同模态资源的转换方法。相较于其他知识表示方法,5W1H分析法更符合“实体-属性-关系”这一编目逻辑,同时该方法能够较为准确且有效地与本文所构建的编目规则进行结合,形成一套基于5W1H的元数据分类方法并进行知识表示。
英国、美国和加拿大于1967年联合出版的《英美编目条例》[7]是世界上较早实现体系统一的编目规则。1997年,在哥本哈根举行的第63届IFLA书目记录大会上通过了一种更为清晰的结构化编目框架——FRBR,这是RDA规则的前身[8]。在经过长达十多年的编写和修订,一种直接建立世界通用的资源描述与检索的新标准——RDA编目规则,于2010年6月正式出版,并于2014年在我国以译本形式发行。
目前,我国的编目工作主要参照《中国文献编目规则》[9],该编目规则的结构便于人们理解和掌握,但在定义多载体、多载体配套文献、附件、多部分资源的过程中,该规则存在与其他著录规则相矛盾、相关定义划分范围存在交叉等问题。且在其出版前后,中、西方的编目界已经逐步迈入联机联合编目的时代。
RDA编目规则的框架为实体、属性及关系构成的三元组[10]。该编目规则以实体为基础,将实体对应的属性和实体间关系进行扩展,形成覆盖广泛、描述对象全面、功能多元的分类细则。本文提出的多模态编目规则,将在RDA的基础上引入多模态资源的分类方法[11],并对该编目结构进行多模态场景下的调整,从而在利用RDA编目规则对资源及其关系充分描述的同时,提供资源在多模态场景下的编目方法及后续知识表示的新形式。
2 多模态内容资源编目方法
本文在RDA编目规则基础上,为自动化编目过程中的编目字典进行规则的再定义,同时适应内容资源的多模态场景和多资源的关系特征,为多模态内容资源进行元数据的扩充与匹配,现将该多模态资源编目规则简写为M-RDA(Multimode Resource Description and Access)。
2.1 多模态编目规则框架构建
M-RDA分为实体、属性、关系三部分,以实体为核心对象,对实体的属性及实体间的关系进行结构划分。实体属性分为识别属性和描述属性两大类,两类属性中又细分出更多特征类别,实体间关系部分同样有更多细分。本文的编目方法在规则设置上采用“一般”到“特殊”的结构,一般性说明适用于所有资源,特殊性说明适用于某类文献资源的独有特征。在多模态资源中,这点体现为:对属性和关系部分的类别划分中,先按照一般性分类和多模态分类进行区别,一般性分类中的元数据可以收录所有模态下的某种数据类型,如“标题”这一类目既能收录某一文本文献的标题名,也能概括视频数据的名称。而对于多模态分类来说,不同模态的类目具有特异性,这些特征是其他模态数据所不具有的。按照这种由“一般”到“特殊”的结构框架,每种多模态实体都具有一般属性和多模态属性,而这些实体之间也具有一般关系和跨模态关系两种关联。本文提出的M-RDA编目规则整体结构见图1。
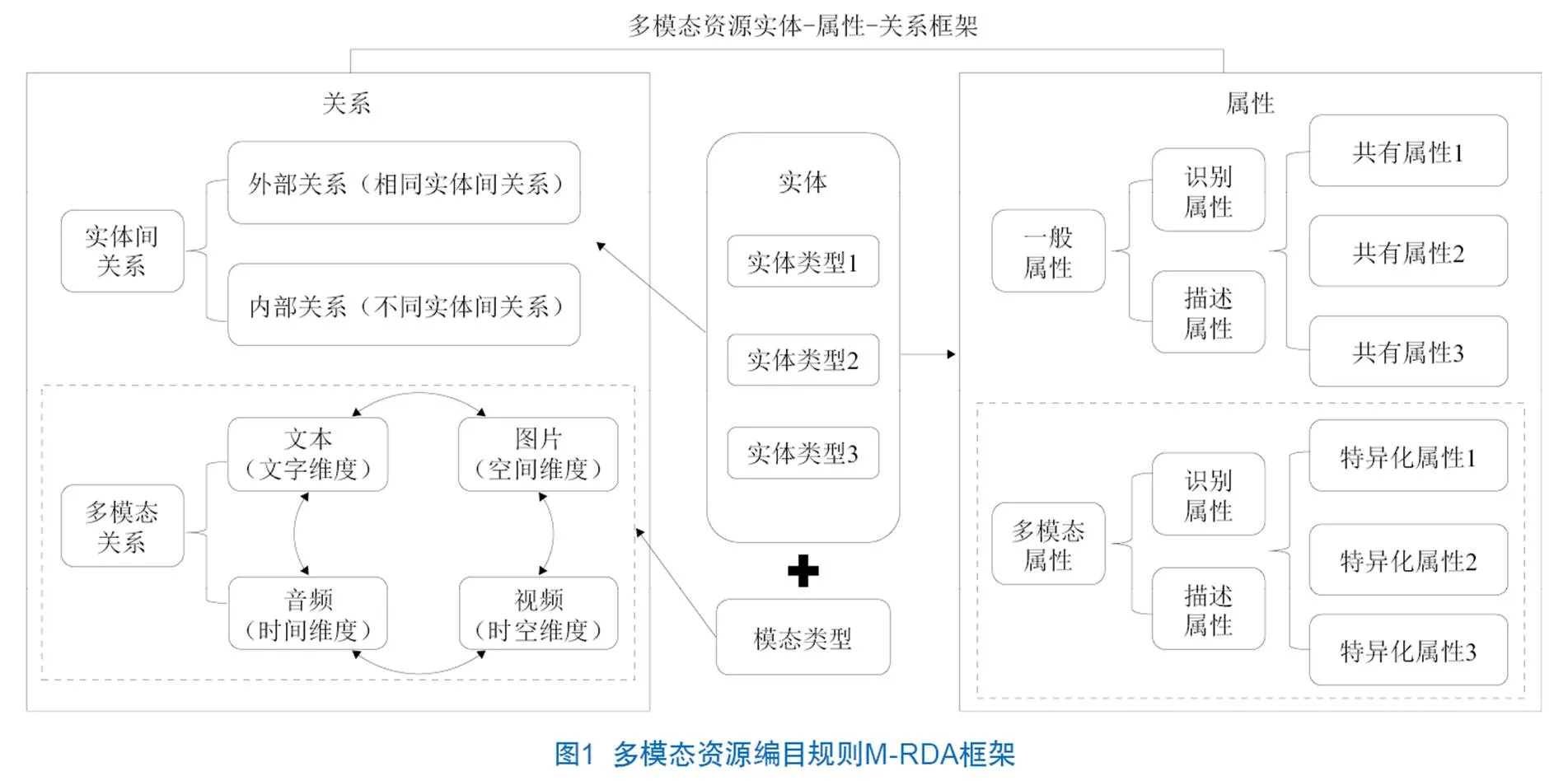
M-RDA编目规则中的属性部分记录了资源、责任者和主题3种实体属性,关系部分记录了3种实体之间的关系。属性是每个实体所具有的特征,能用于识别该实体。关系指实体之间所具有的内在联系,能用于找到关联的实体。上述属性和关系在本文提出的编目规则中被称为元素。
本文在RDA标准的基础上,对属性中涉及其他模态的元素类型进行归类和增设,同时,丰富了各个实体间的关系类型。如视频中的实体之间将更加强调时间与空间维度的关联,图片资源的实体之间强调位置与空间维度的关联等,这部分具有多模态特殊性的属性和关系统一放在了上述多模态分类中。多模态情境下体现的更多维度,都是传统文本模态下的资源所不具备的特征,也是对相关资源类型描述缺失的补充。
2.2 编目规则框架的要素分析
2.2.1 实体
编目对象是组成编目的基本单元,这些对象在RDA编目规则中又被称为实体。实体是具有含义和属性的,不同实体间又相互关联,拥有不同类别的关系。实体可理解为能够在数据库中被识别的事物,是编目过程中的核心元素。
本文提出的资源类型分类方式从宏观的角度解决了多模态问题——每种模态的资源都可以通过5W1H的知识表示法进行陈述,因此视频、音频在内的资源标签也能用3种实体的分类方式进行归纳。例如,视频的创作者是责任人实体,视频的标题中可归纳出该资源的主题实体,其本身又是一个资源实体下的作品。多模态下值得注意的是知识在模态间的转换问题,知识通过转换成文本类型的方式,匹配相应的标签即可完成对不同模态下复杂、非结构化知识的分类过程,这也是解决多模态资源编目的关键所在。
2.2.2 属性
属性是指实体所具有的一套特征,可用来帮助用户查找某个特定实体并获取反馈信息。属性的标识与传统著录方法中利用资源特征进行编目的思想一致,体现了实体本身具有的特性,这些特性如同实体的标签,有助于编目者及读者了解实体的信息。
本文对RDA编目规则进行多模态层面的延伸,即根据模态场景,细化出具有模态特征的资源标签(见表1)。对于模态不同的同种资源,在数据实际应用过程中需要加以区分。而这种情况一般出现在某种资源实体的“载体表现”及“单件”层级,因此本文在该编目规则中做出适当调整,在多模态属性中增设了如“载体类型”“声音特征”“数字文件特征”等传统编目方法中没有的类别。由此也可看出,随着资源类型和技术维度的增加,编目人员仅需在这套分类框架下的某一层级进行修改而不影响其他层级的类目。
本文针对资源的多模态场景做了属性类目的扩充(见表1),这些扩充的属性能更好地服务多模态关联关系的定义,为多模态资源的知识表示提供基础。

2.2.3 关系
RDA编目规则的后半部分分别记录6种不同类型的关系,将前半部分划分的不同属性之间的关系进行定义。关系部分的引入打破了传统书目概念的单一性和平面性,从更多维度重新界定书目元素之间的复杂关系。RDA编目规则在前两个部分构建了实体与实体属性这两个对象型资源,而现今数据流量大、信息载体多样的特征也让实体间存在各类关联。关系作为建立实体间连接的工具,能够有效帮助用户在数据库中识别和理解资源,同时也为聚类知识单元、实现知识表示提供基础。
在本文构建的多模态资源编目框架中,图1左侧关系部分除了包含RDA编目规则的内外部关系,还提出了针对多模态场景下资源的多模态关系。这一模块考虑了文本、图片、视频、音频这4种模态下资源的展现形式,通过资源的模态特征构建模态间的关系,这也是多模态关系的核心。
图2展示了多模态关系的具体延伸方向和各维度之间的关系类别。其中,图片模态的资源更能够展现出实体在空间上的特征,而音频模态的资源着重体现了时间变化下各种属性的差异以及声音本身所能传达的信息特征,对于视频资源来说则兼顾时间、空间维度的特征。在这种多模态资源编目框架下,本文从时间、空间、声音、文本内容维度对模态关系进行再定义,体现了传统编目规则所无法涉及的关系层面。
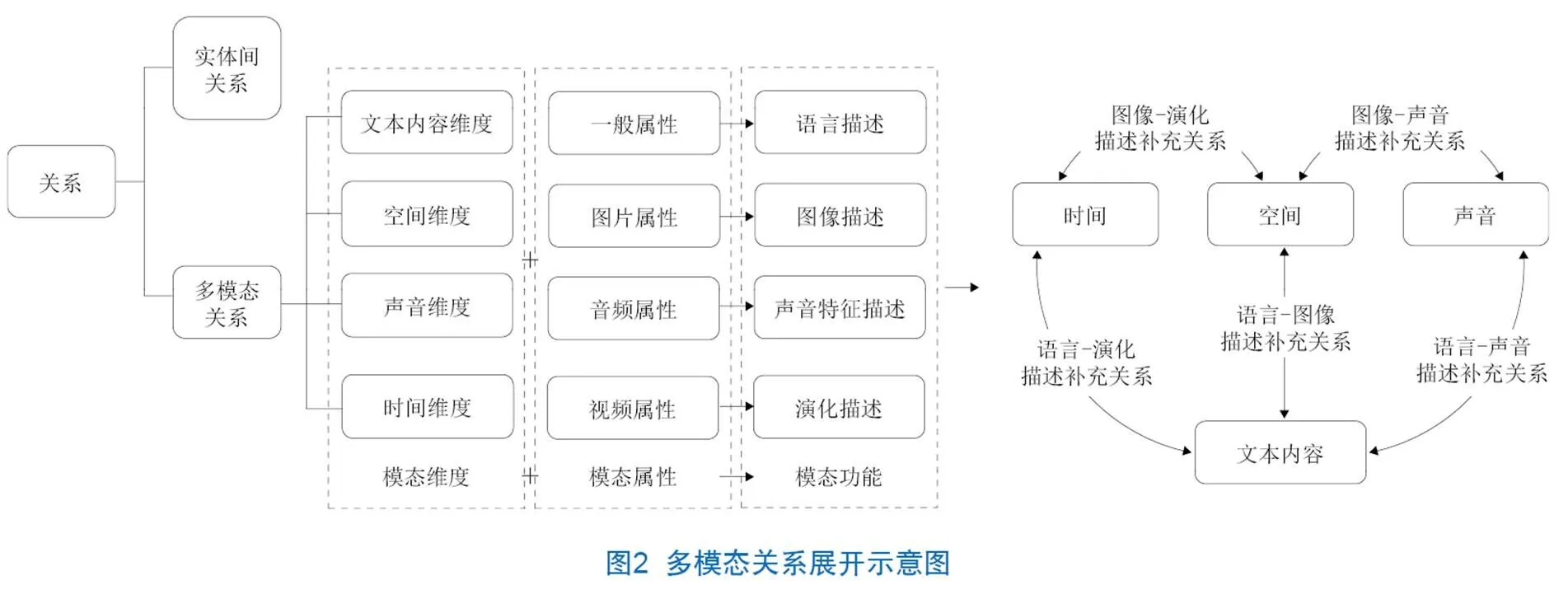
同时,不同模态间同样具有此前编目规则未被定义的关系。图片与文本之间产生的图文描述关系、图片与音频之间产生的语音解释关系等。这些模态之间因为其具备的维度特征差异,在不同模态资源的结合搭配下,将产生这种互相解释、相互对照的多模态关系。因此,这种多模态关系可以充分利用在更多维度的需求中,在传统文本无法充分展示的环境下,利用多模态关系的多模态资源可以补充这一描述。在本文第3章构建的知识表示法中,也将利用这种多模态关系,构建一套融合多模态资源的知识表示模型。下文列出了多模态扩展关系及其说明。
(1)语言-图像描述补充关系。文本语言对图像的补充:如命名、释义、指代等关系。图像对文本语言的补充:如大小、长宽度、颜色等多模态属性上的补充。
(2)语言-演化描述补充关系。文本在时间演化上的补充描述:通过视频、音频等模态资源在时间上的演化过程补充描述文本层面无法捕捉的信息,如事件发生的先后顺序、事件起因、结果等。
(3)语言-声音描述补充关系。音频对文本语言的补充:如音频流声道、音频波长、音频分贝等多模态属性上的补充。以音频的方式呈现文本层面无法传达的信息,如语音、语调等。
(4)图像-演化描述补充关系。文本在时间演化上的补充描述:通过视频模态资源在时间上的演化过程补充描述图像层面无法捕捉的信息,如图像在形态、颜色等多模态属性上的变化。
(5)图像-声音描述补充关系。声音对图像的补充:如音频形式的说明、图像内容中的声音特征等属性的补充描述。图像对声音的补充:如大小、长宽度、颜色等多模态属性上的补充。
2.3 内容资源模态归一化
针对内容资源的多模态问题,本文通过统一转化的思想,将多模态资源中的知识内容转化为文本形式,再利用文本现有方法进行编目及知识表示。表2为各种类型资源的转换方法。
对于结构化的多模态资源,需要进一步处理资源的标题和摘要,标题中的信息可按照5W1H方式进行关键词抽取。例如,对于标题、摘要中出现的人名,可归类到人物类目中,出现的日期信息可归类到时间类目中。按照这样的方式,可以从整体上将连续文本信息转化为类目清晰、相互关联的关键词信息,便于框架表示法提取相应结构。在后期需求明确的场景下,可以人为归类到更精确的二级分类下,丰富知识表示的形式和应用方向。
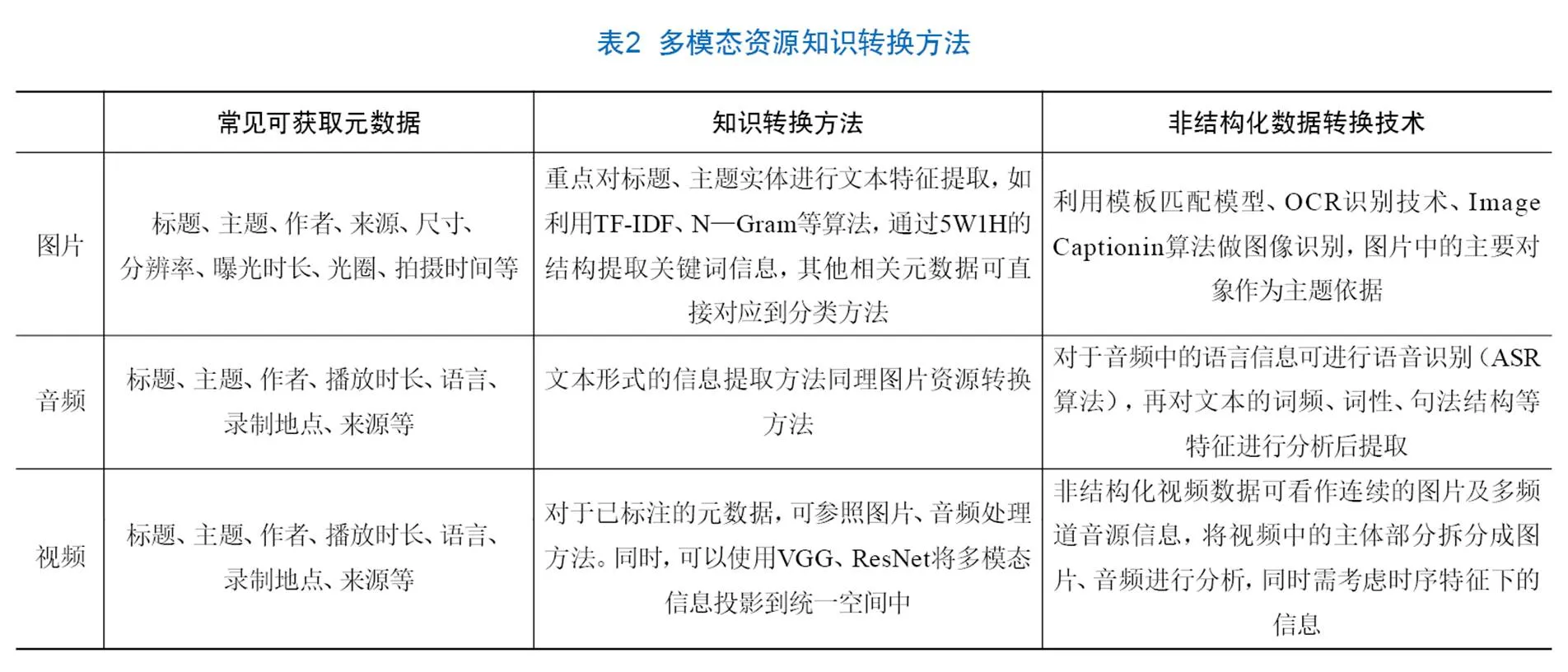
对于非结构化数据,如图片本身并未进行数据标注,可以采取图像识别、音频文字转换等功能提取其中的关键词或段落,再通过词频统计、主题词分析等方式得到编目字典相关的数据标签,最终实现数据结构化。上述方法提取出的信息多对应于主题、时间、人物等便于明确识别的类目,需经过分析、推导过程得到的信息将被大量丢失。
上述针对多模态资源的转换思路将扩充数据来源,使基于5W1H的深度知识表示方法具有更大的应用面。同时,这些资源类型的适用也反映出该元数据分类方法具有较强的覆盖范围和整合能力,而基于框架表示的知识表示方法能够有效表达多模态内容资源,形成逻辑严谨、结构完整的表达式。
2.4 案例分析:多模态场景M-RDA编目实例
下面针对汽车制造领域的安全电子相关资源举例,详细展示一个在线知识服务平台在本文提出的编目方法下多模态资源的编目过程(见图3)。

①在用户/管理员上传题为“通用汽车安全气囊存隐患,全球召回700万辆汽车”的单个资源后,系统识别该资源的模态类型为音频。②提取该资源自带的“摘要”“标题”“作者”等一般属性和“时长”“存储大小”等多模态属性。③该资源识别为音频类型后,运用ASR语音识别技术将音频内容转为文本,并对文本进行关键词抽取、句法语义分析等NLP技术,获取到“安全气囊”“凯迪拉克”等主题、内容相关的数据标签。④获取该音频的主题词、作者等标签后,系统检索平台上其他模态资源的相关内容,匹配到一篇由《人民日报》发表的文本文章和一条新闻报道视频。并将上述资源定义为该资源的“语言-声音描述补充关系”“图像-声音描述补充关系”多模态关系标签。⑤处理并获取该音频资源的全部标签后,将它们按照目录字典的层级进行著录,形成该资源的一份完整目录。
3 多模态内容资源知识表示法
3.1 基于5W1H的知识表示法
本方法运用框架表示的方式,对内容资源中的复杂知识结构进行由主体到下层的层次性描述。它的上层主体表示某个固定的对象、概念,下层可分为一些槽,用于描述主体的不同属性和特征。相互关联的框架连接起来组成框架系统,用于对内容资源进行有针对性的标准化描述。该表示法将本文编目体系中的属性对象和关系对象作为下层槽,通过自动编目过程,把一份资源文件的文本与属性及关系对象做对应,并放入描述体系中形成一段具有规则和语法逻辑的语段[12]。
对于内容资源的多种元数据类型,可利用5W1H的知识表示方法,即人物(Who)、事件(Says What)、渠道(In Which Channel)、时间(When)、效果(With What Effect)和方式(How)[13],进行结构化表示。本文通过对都柏林核心元数据[14]的延伸和知识表示的实际需求,提出一种基于5W1H的元数据分类方法。通过上述方法,可以将识别到的元数据基于本文提出的元数据分类方法进行分类,再通过框架知识表示法对需要的分散元数据加以重组,得到一套有针对性的完整表述过程。
本文针对智能制造领域一篇名为《面向多无人机协同飞行控制的云系统架构》[15]的论文,通过5W1H的知识表示逻辑,提取并匹配编目字典中的元数据,并放入定义规则后的框架表示式中,形成如下语句。
“‘史殿习、洪臣、康颖’等人通过‘期刊《计算机学报》’发表了一篇主题为‘无人机云系统构架’题目为‘《面向多无人机协同飞行控制的云系统架构》’的期刊论文,该文‘提出了一种面向多无人机协同飞行控制的云系统架构UAV3CA’方法。该文章创建于‘2020.08.20’,发布于‘2020.12.23’。文章来源于‘万方数据知识服务平台’,以‘网络文献数据平台及期刊文本’为渠道发布。最终得出了‘从单无人机制导控制到多无人机协同控制两个层面验证出了UAV3CA对多无人机协同控制的有效性’这一结论,得到了‘一种面向多无人机协同飞行控制的云系统架构UAV3CA’的成果”。
语句中括号内字段如“史殿习、洪臣、康颖”“期刊《计算机学报》”“无人机云系统构架”等分别对应编目字典中的“个人名称”“正题名”“主题名称”等元数据。而不同字段又因元数据之间的关系属性具有相对应关系,如“史殿习、洪臣、康颖”与“期刊《计算机学报》”具有创作关系。
3.2 多模态资源编目编码及知识表示流程
在对多模态内容资源进行系统性的编目之后,需要考虑资源类型及资源中的知识能够通过哪种方式被合理、有效表达,多模态资源在何种知识结构下能得到系统地表示。因此,需要构建一套适用于多模态环境下资源的表示方法,使得不同类型的知识得以系统性组织起来,以便人们识别和理解。图4表明了多模态资源从提取数据标签、形成资源目录再到生成特定知识表达式的过程,这一过程为构建编目规则和建立适用于多模态资源的知识表示法提供了依据。

图4左侧部分为识别资源、匹配数据标签的步骤,获取多模态资源后,第一步确定资源的模态类型,以便对不同模态的特征进行特异化处理。第二步为获取资源标签过程,对于非结构化数据及未标注标签的特征,需先经过多模态内容转化步骤,通过已有的转化和识别技术为这些特征进行标签。这一步的详细方法在本文2.3节中进行说明。第三步是对已获取的标签对照多模态资源目录字典进行匹配,这里的目录字典根据第2章的编目方法生成。在这些资源标签收录为资源目录后即完成了多模态资源编目过程,这些收录的标签可进行知识表示或生成知识图谱等应用。图4的右半部分为多模态知识表示过程,其基本思想是构建知识表示式,对获取的资源标签进行提取并放入表示式对应结构中,最终形成一段该资源的完整描述。
4 总结
现行编目规则在多模态场景下无法对内容资源进行充分的分类和著录,本文在资源与描述型编目规则的基础上,对现行编目框架进行适配性扩充与修改,开展了多模态内容资源编目及知识表示研究。本文提出了以“实体-属性-关系”结构为基础的多模态编目规则M-RDA,扩充了RDA编目规则中关于多模态属性和关系层面的类目。由于在著录视频、图片等模态资源时,需要考虑时间、空间等维度下的属性特征和这些维度之下资源间的特殊关系,因此,本文结合模态维度和模态功能的特点,展开定义了多模态资源间的5种描述补充关系。通过多模态场景下M-RDA编目实例的介绍,具体描述了资源在本文提供方法下的编目流程。最后,本文提出了基于5W1H的知识表示方法,建立了多模态资源从编目到知识表达的完整流程。该知识表示法将本文基于多模态的编目体系和自动化过程串联起来,为编目字典中的知识提供了输出表达方式。同时,这种方法对多模态资源进行了高效描述,构建了结构化的表达方式。
总体来看,本文在多模态内容资源编目及多模态知识表达方面提供了新思路,扩展了多模态内容资源的表达与转换机制,也为后续编目自动化技术提供了一种理论基础。在后续的工作中,本文提出的多模态资源编目框架及知识表示法需要在技术层面得到更多检验和修正。同时,多模态资源如何利用相关规则实现编目自动化过程,有待进一步探究和实验,相关理论与方法也需要在具体应用场景及需求下进行测试和补充。
[1] 刘炜,胡小菁,钱国富,等. RDA与关联数据[J]. 中国图书馆学报,2012,38(1):34-42.
[2] OLIVER C. RDA:21世纪的元数据[J]. 图书馆杂志,2016,35(3):4-11.
[3] 李钊. 多模态数据分类与检索的关键技术研究[D]. 北京:北京交通大学,2018.
[4] 马创新. 论知识表示[J]. 现代情报,2014,34(3):21-24,28.
[5] 刘建炜,燕路峰. 知识表示方法比较[J]. 计算机系统应用,2011,20(3):242-246.
[6] 张美琦,李晓娟. 我国科技查新英文论文5W1H分析[J]. 情报探索,2012(3):81-83.
[7] Anglo-American Cataloguing Rules(AACR,AACR2,AACR2R).[EB/OL].[2022-10-01]. https://www.librarianshipstudies.com/2018/12/anglo-american-cataloguing-rules-aacr.html?m=1.
[8] 蔡丹,罗翀. 中国国家图书馆西文编目规则的嬗变与开新[J]. 国家图书馆学刊,2019,28(5):26-33.
[9] 富平. 中国文献编目规则[M]. 北京:北京图书馆出版社,2005.
[10] 罗翀. RDA全视角解读[M]. 北京:国家图书馆出版社,2015.
[11] WU D,ZHAO S,YANG X L,et al. On the strategy of resource catalog and coding[C]//2009 First International Workshop on Education Technology and Computer Science. IEEE,2009:1008-1011.
[12] STOREY V C,CHIANG R H,CHUA C E H. Knowledge representation:a conceptual modeling approach[J]. Journal of Database Management,2012,23(1):1-30.
[13] 姜天笑. 浅谈科技查新工作中的5W1H分析法[J]. 情报探索,2011(5):96-97.
[14] 许四洋,柳晓春. Dublin Core元素与CNMARC字段的匹配、对应[J]. 大学图书馆学报,2001,19(5):73-78,83.
[15] 史殿习,洪臣,康颖,等. 面向多无人机协同飞行控制的云系统架构[J]. 计算机学报,2020,43(12):2352-2371.
Research on Cataloging and Knowledge Representation of Multimodal Resource
LIU PeiYao LUO ZhuoRan WEI JiaZe CHENG QiKai
( School of Information Managemet, Wuhan University, Wuhan 430072, P. R. China )
In order to carry out the work of cataloging coding and knowledge representation for content resources effectively under the background of rapid growth of multi-modal information resources, this paper discusses the feasibility of multimodal resource cataloging under the structure of “entity-attribute-relationship”, based on the RDA, and proposes a cataloging framework M-RDA. This paper reorganizes the method of content resource modal normalization. This paper focuses on expanding the multimodal attributes and relationship categories in the cataloging framework. It explores the description and supplementary relationship between multiple resources from four modal dimensions, and annotates their modal characteristics and relationships while cataloging resources. In addition, in order to realize the organization and expression process of knowledge under the cataloging rules, this paper proposes a multimodal knowledge representation method based on 5W1H to describe events from six aspects: cause, object, place, time, person and method, which completes the process from tag acquisition, cataloging and knowledge representation, providing a theoretical basis for the automation of multimodal resource cataloging.
Multimodal Resource; Cataloging; RDA; Knowledge Representation
(2022-10-19)
G254.3
10.3772/j.issn.1673-2286.2022.11.008
刘沛鹞,罗卓然,魏家泽,等. 多模态内容资源编目及知识表示研究[J]. 数字图书馆论坛,2022(11):26-33.
刘沛鹞,男,1998年生,硕士研究生,研究方向:知识管理与数据挖掘。
罗卓然,女,1993年生,博士研究生,研究方向:创新评价、数据挖掘。
魏家泽,男,1996年生,博士研究生,研究方向:科学计量与智能文本处理。
程齐凯,男,1989年生,副教授,通信作者,研究方向:信息检索,科技情报分析,E-mail:chengqikai@whu.edu.cn。
* 本研究得到国家重点研发计划课题“服务内容资源知识表示、分类与编码和自动编目技术研究”(编号:2019YFB1404702)资助。
猜你喜欢
天一阁文丛(2020年0期)2020-11-05 08:28:36
中国外汇(2019年18期)2019-11-25 01:41:54
戏曲研究(2017年3期)2018-01-23 02:51:01
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年22期)2014-02-27 14:18:37
