
基于语音图像融合平台的英语与手语自动翻译系统设计
2022-12-13 07:52郑百花雷群泌
中国新技术新产品 2022年18期
郑百花 雷群泌
(湖南环境生物职业技术学院,湖南 衡阳 421005)
0 引言
英语作为世界通用语言,是对外交流的必备工具,手语作为特殊人群的专用语言具有无可替代性。但是两者的互通互译尚属于空缺状态,不便于语言障碍人士与外界,尤其与外宾进行直接交流。因此,设计语音识别平台,并融合图像识别与展示功能,形成英语、普通话和手语的低延时自动翻译工具。
1 自动翻译系统硬件设计
当设计基于语音图像融合平台的英语与手语自动翻译系统时,该控制器由STM32单片机构成,对采集到的语音和图像进行处理,内置STM32M3核心,并与控制器的外部接口集成ADC,设置了集成采集方式,实现对数据的快速传送功能。基于语音图像融合平台的英语与手语自动翻译系统硬件结构如图1所示。
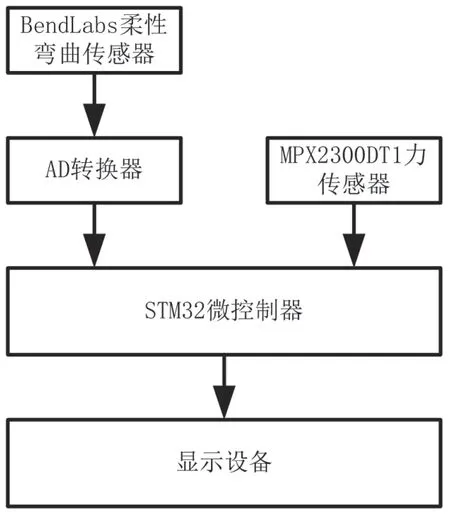
图1 硬件设计
在上述硬件设计的构造中,通过呼叫控制芯片中的信息信道,使控制时钟的频率达到28 MHz,控制系统采用扫描和变换的方式进行操作。在单片机的外端,采用2套传感器结构引脚,完成英语和手语翻译系统间的信息同步传递任务。
2 自动翻译功能软件设计
2.1 语音图像融合识别
该文将语音图像融合技术应用到英语和手语的自动翻译系统中,利用CNN技术可以有效降低语音信号在时间、频率上的损耗,同时也保证了语音的整体特性,便于网络的训练和识别。该文所设计的英语与手语自动翻译系统先利用语音识别模块对输入的语音进行预处理,并抽取其特征,然后将其作为语音特征图像,利用该图像进行CNN的训练和识别。语音识别的流程如图2所示。

图2 语音识别流程
为了获得正确且较为典型的语音信号,要对采集的语音信号进行预处理,并利用能量与过零率法进行终端检测,经过预处理后则可进行特征提取。英语与手语翻译系统中的语音信号源都是以人声为基础的,利用梅尔倒谱系数来进行语音识别[1]。在该基础上,将小波包分解技术应用于快速傅里叶变换中,傅里叶变换是时域—频域变换分析中的基本方法。分割Mel尺度的频域,Mel音阶可以使纯音的感知频率或音调与其实际测量频率相关联,从而保证语音特征完整。
2.2 自动转换翻译特征提取
在英语和手语的自动翻译中,利用语义单元融合本体,从语音及图像中抽取语义上下文。通过修改文本的语义来构造自动转化的联合特征分布集K,并将其与Fuzzy综合判断相结合,构造一个自动转化的分段函数,如公式(1)所示。

式中:t1为翻译时输出在英汉2种语言中的时间序列;t2为采样时英语与手语自动转换翻译的间隔时间;ET为T时的常数函数。
建立自动转换的联合特征值,如公式(2)所示。

式中:δ(t1,t2)为英语与手语之间自动转化的分段函数;u为自动转化分段函数中出现的并集;C为复数集合。
语义融合后获得特征分布节点I1、I2的自动翻译转换,定义I1、I2间的距离,建立联合特征∆x为自动转换翻译特征分量,在区间中,构造一种用于自动翻译的约束最优化问题,并给出英语和手语的自动翻译的联合限制特征量,如公式(3)所示。
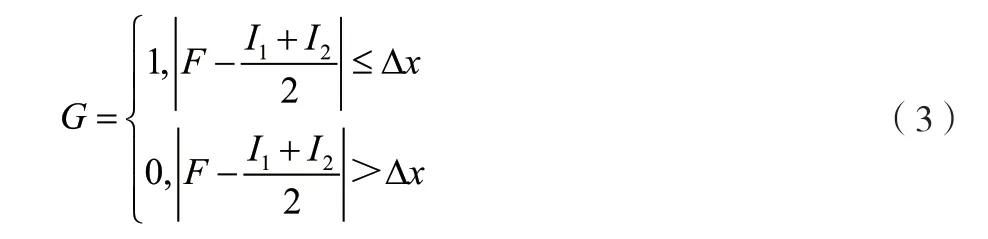
建立计算英语和手语翻译模型中的语义单位向量模型,满足翻译系统在输入时的自适应性,提高语音特征在检测识别时的效率,便于排除歧义特征项。
2.3 消除歧义特征项
通过去除模糊特征项可以有效提高英语与手语自动翻译系统的精度,从而使英语和手语自动翻译成为可能[2]。一方面,由于词性的歧义,因此同一词语的词类差异也会导致译文意义存在差异。另一方面,在不同的环境下,同样的词语的意义也会存在细微差异[3]。为了消除因词类而产生的模糊性,应首先明确词语的词性,并根据相似性来标记词类[4]。通过计算所选的n个句子的相似度,对所选n个句子的相似性进行分析,并将其输入类似的语句组合模块中,相似度如公式(4)所示。

式中:words(A)为英语句子A中的一组单词;words(B)为输入手语B的图像集合;i为字组中的第i个要素;Len为字符串的长度;sim(A,B)为词形的相似性。
通过分析词形相似度可以提高句子的翻译质量。通过所标记的词性可以判断所指的具体意义,从而排除歧义,完成英语与手语间的翻译工作。为了避免由于上下文的差异而产生的歧义,必须采用本体的方法来排除歧义。首先,要单独处理需要翻译的句子。其次,在领域字典中找到每个词,把这个词定义在一个特定的词义范围内,并赋予它一定的意义,从而消除歧义,方便规整双向翻译。
2.4 规整双向翻译
英语和手语自动翻译系统在建立双向翻译时,由于估计的人体阻抗参数偏低,因此使英语与手语翻译系统无法识别所有的翻译节点,翻译路径太少。建立手语处理的空间域,并将手部处理空间与在轨迹中的数据点相结合,将初始节点作为特征向量,手部轨迹匹配函数D如公式(5)所示。

式中:ai为特征矢量;bj为数值单调;wn为手语路径权值。
校准2个循环的轨道变量,该轨迹周期数字变量P(λ)如公式(6)所示。

式中:Bj为数字的似然性。
基于所形成的轨道变量,设置一个模糊的数字控制关系来控制所估计的手部处理空间阻抗参数,其数值关系如公式(7)所示。

式中:M为手部处理空间的转译路径;d为手语的转换循环。
为了达到双向转换,以语义解码技术为支撑实现翻译软件的功能[5]。在实际过程中,通过规整处理2个转换过程,对硬件结构的可视语义进行编码,将其转换成英语语言信息,然后将其输入编码矢量中,输出的语言序列矢量如公式(8)所示。

式中:yt为接收到的视觉语义编码;hm为自然语言序列的映射过程;m为维度参数[6]。
在系统软件中,经过控制维度参数标准化处理,相应地处理了一个具体词汇类的矢量,数字关系如公式(9)所示。

式中:zt为向量索引值;p(zi)为词语类别函数;wk为手语译码产生的单词参数。
与以上具体分类所产生的单词参数相对应,通过转换句式的指标单词构造实际的解码产生过程,数字关系如公式(10)所示。

式中:ht为该索引函数的词汇表;Y为译码产生函数。
译码处理程序被用作所述的语句转换次序,当所述转换程序数据被执行时,所述译码产生函数是由Java程序编写的,严格地遵循译码产生的次序,形成英语与手语的双向自动转换。
3 仿真试验
3.1 试验准备
在caffeine平台上进行试验,采用英特尔3770芯片,主频3.4 GHz,内存16 GB。为了确保试验结果的正确性,对试验参数进行统一设置,将英语与手语的自动翻译中断图取样时间间隔设为0.26 ms,英语与手语的自动转换为15 kHz,转换字长度为1 800 Bit,提取的翻译文本为800 个字符,翻译速度为18 Byte 。FPGA对CMOS进行手语图像的采集、传输及存储等操作,通过VGA显示手语定格图像。该文使用VisualDSP++进行模拟,使用的参数设定见表1。

表1 试验参数
根据上述参数设定,采用基于语音图像融合平台的英语与手语自动翻译系统进行自动转换翻译测试。
3.2 试验结果
3.2.1 手语图像识别结果
在基于语音图像融合平台的英语与手语自动翻译系统设计中,将完全捕捉手语内容才能更具体地翻译相关内容,因此,进行实时手语视频图像采集显示试验。从以上250 个手语样本中选出8 个作为该试验的具体试验样本,通过整理手部姿势生成的数据,从而构成手势数据集,见表2。
根据表2中的手势转换资料设置相应的手指关节空间维度和关节点的置信分数,并将其作为关节点的特征。经过处理后,选择同样的系统性能指数捕获手语图像。在该系统中,采用FPGA对CMOS进行图像控制,VGA显示传送和存储的图像,结果如图3所示。

表2 手势翻译数据

图3 手语显示图像
通过图像捕捉试验可知,8 个手语图像捕捉效果清晰,FPGA的高速并行优点使手语图像捕捉可以更快融入语音图像融合平台,该系统设计捕捉的画面更清晰,采集的图像更流畅。运用试验测试中的手语图像捕捉以及英语语音采集,根据试验环境和有关参数设置对该文基于语音图像融合平台的英语与手语自动翻译系统设计进行仿真分析,将准确率和语义信息召回率检测评价指标作为对手语图像识别的评价依据,如图4所示。
由图4可知,该文设计的双语翻译系统在手语图像识别时,准确率和召回率较稳定,语义样本规模上升,其准确率和召回率也随之上升。由此可见,该文所设计的英语与手语翻译系统的手语图像识别结果准确性和智能化程度较高。
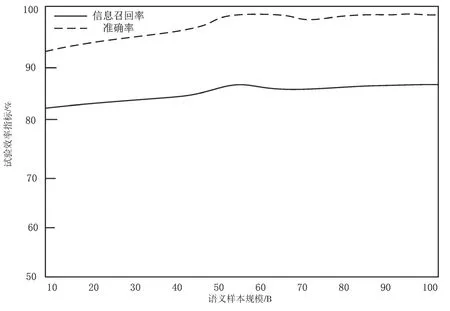
图4 准确率与召回率示意图
3.2.2 英语翻译结果
语音识别作为基于语音图像融合平台的英语与手语自动翻译系统设计中重要的环节,识别内容够准确才能保证语音交互正常运行。采用8 组英语语音句子进行识别,以8 个试验的平均识别率为最终目标,相应的试验数据见表3。

表3 英语语音识别结果
由表3可知,8 个英语句子的识别速度大约都为1 s,识别速度较快,语音字节长度对识别速度没有太大的影响,识别率最高为98.54%,最低为97.33%,召回率最低为82.22%,最高为84.11%。因此,该文所设计的语音识别较准确,可以准确识别语音。
4 结语
综上所述,该文在系统的硬件设计方面,以STM32微控制器作为主控模块,实现英语与手语自动翻译系统的同步信息转换。在系统的软件设计方面,用CNN对特征图像进行模型训练和识别,采用语义单元的本体融合方法自动提取系统内录入的英语和手语的语义语境,按照解码生成的顺序规整双向翻译。试验结果显示,英语和手语的自动翻译系统在语音图像融合平台的基础上,可以有效提高句子的翻译效率和准确性。
猜你喜欢
疯狂英语·新阅版(2023年5期)2023-05-31
开放教育研究(2020年2期)2020-03-31
活力(2019年15期)2019-09-25
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
外语学刊(2011年1期)2011-01-22
