
软件模型被动学习推断综述
2022-12-06 09:05徐光会高俊涛
微型电脑应用 2022年11期
徐光会,高俊涛
(东北石油大学,计算机与信息技术学院,黑龙江,大庆 163318)
0 引言
软件模型在软件系统的整个生命周期中起着重要的作用。通过模型,软件工程师可以获得对系统行为的深刻理解,而无需处理复杂的实现。尽管良好的软件工程实践建议应该在获得实现之前预先开发模型,但现实显示,模型经常不存在,或者它们与实现不一致。事实上,建立一个合适的模型是昂贵的,困难的,并且需要数学技能和独创性。此外,即使开发了模型,它们通常也不会随着实现中的更改而更新,因此模型和实现逐渐发生分歧。
模型推理是解决这一问题的一种很有前途的方法,它使用机器学习从执行日志中自动推断软件行为模型。精确捕获软件系统的模型对于广泛的软件维护和验证是有用的。最近的研究提出了许多被动学习模型推理技术,大多数推理技术都是将软件系统的一组执行轨迹作为输入,并推断出模型,比如Synoptic[1]、InvariMint[2]、flexfringe[3]、CSight[4]、MINT[5]、GK-tail+[6]和2017年Rick Wieman等[7]推断大型支付系统的模型等。
本文主要从以下几个方面对软件模型推断领域的研究成果进行综述:①软件模型推断的相关定义;②软件模型推断过程;③软件模型被动学习推断技术;④总结与展望。
1 相关定义
1.1 轨迹和事件不变量
定义 1 (事件和轨迹)事件是一个元组(l,v),其中l是一个函数的名称,v是l的参数变量到具体值的映射。轨迹t∈T是一个有限的事件序列,通常写为〈(l0,v0),…(ln,vn)〉。
定义 2 (正轨迹和负轨迹)对于给定系统,正轨迹代表了可能出现的系统可行的行为,负轨迹代表了不可能出现的行为。
定义 3 (日志)日志是由一组轨迹组成。
定义 4 (事件不变量):假设a和b是2种事件,3种事件不变量如下。
(1)a总是跟在b后面(aAlways Followed Byb,写为a→b)。每当事件a出现时,事件b总是出现在同一轨迹的后面。
(2)a从不跟b(aNever Followed Byb,写为a→/b)。每当出现事件a时,事件b就永远不会再出现在同一轨迹中。
(3)a始终位于b前面(aAlways Precedesb,写为a←b)。每当出现事件b时,事件a总是出现在同一轨迹中的b之前。
1.2 状态机
定义 5 (有限状态机-Finite State Machine,FSM)的定义是一个六元组
F=(Q,X,Y,q0,δ,O)
(1)
其中,Q表示有穷的状态集合,X表示有穷的输入集合,Y表示有穷的输出集合,q0∈Q,是FSM模型的初始状态,δ:Q×X→Q,是状态转换函数,O:Q×X→O,是输出函数。通常,有限状态机指的是确定性有限自动机(DFA)或非确定性有限自动机(NFA)。
2 软件模型推断过程
软件模型推断过程从“信息收集”的过程开始,可能涉及到对源代码的分析、对程序执行的观察,或者两者的某种结合。这些信息通常被抽象出来,即它必须在有用的细节级别上捕获程序中相关的兴趣点,以便最终的结果是可读的和相关的。最后,所收集的信息用于推断软件行为模型。
对程序执行观察的软件模型推断过程一般所涉及的关键步骤如图1所示。所有软件模型推断的过程都可以用这些步骤来描述,从目标软件系统执行行为中获取关键信息,形成推断模型所需要的轨迹,然后用推断软件模型的技术推断目标软件模型,最后将生成的模型反馈给开发维护人员帮助理解系统和开发维护系统。

图1 软件推断模型过程
3 软件模型被动学习推断技术
3.1 Synoptic
Synoptic是由BESCHASTNIKH等[1]在2011年提出的,Synoptic总是能生成一个精确满足从日志中挖掘出的事件不变量的模型,开发人员使用Synoptic生成的模型来验证已知的bug,诊断新的bug,并增加他们对系统正确性的信心和改进开发人员对系统的理解。
Synoptic核心算法是BisimH,BisimH算法首先根据正则表达式从日志中提取的信息构建轨迹图,从轨迹图挖掘3种事件不变量,将具有相同轨迹标识符划分一起,并分别构建轨迹图(步骤1)。根据轨迹图,构建初始模型,初始模型是最紧凑或最抽象的模型(步骤2)。然后进行细化和粗化,这是Synoptic的双重操作。从初始模型开始,首先对模型进行细化,判断初始模型是否违反事件不变量,BisimH使用一个基于FSM的模型检查器来检查模型是否满足挖掘的不变量。如果违反事件不变量,则将违反事件不变量的轨迹作为反例来细化模型,直到生成的模型满足所有的事件不变量(步骤3)。当细化完成后,进行粗化,当无法进一步粗化模型时,生成最终的模型(步骤4)。
Synoptic根据购物车应用程序的日志构建的模型如图2所示,该购物车程序包含事件check-out,valid-coupon,reduce-price,get-credit-card。
Synoptic根据图2顶部的日志和正则表达式,将日志解析为3个轨迹,每个轨迹对应访问服务器的3个用户IP地址,分别是74.15.155.103、74.15.232.201、13.15.232.201。根据这3个IP地址分别构建轨迹图,根据轨迹图构建初始模型,经过细化和粗化过程生成最终的软件模型。
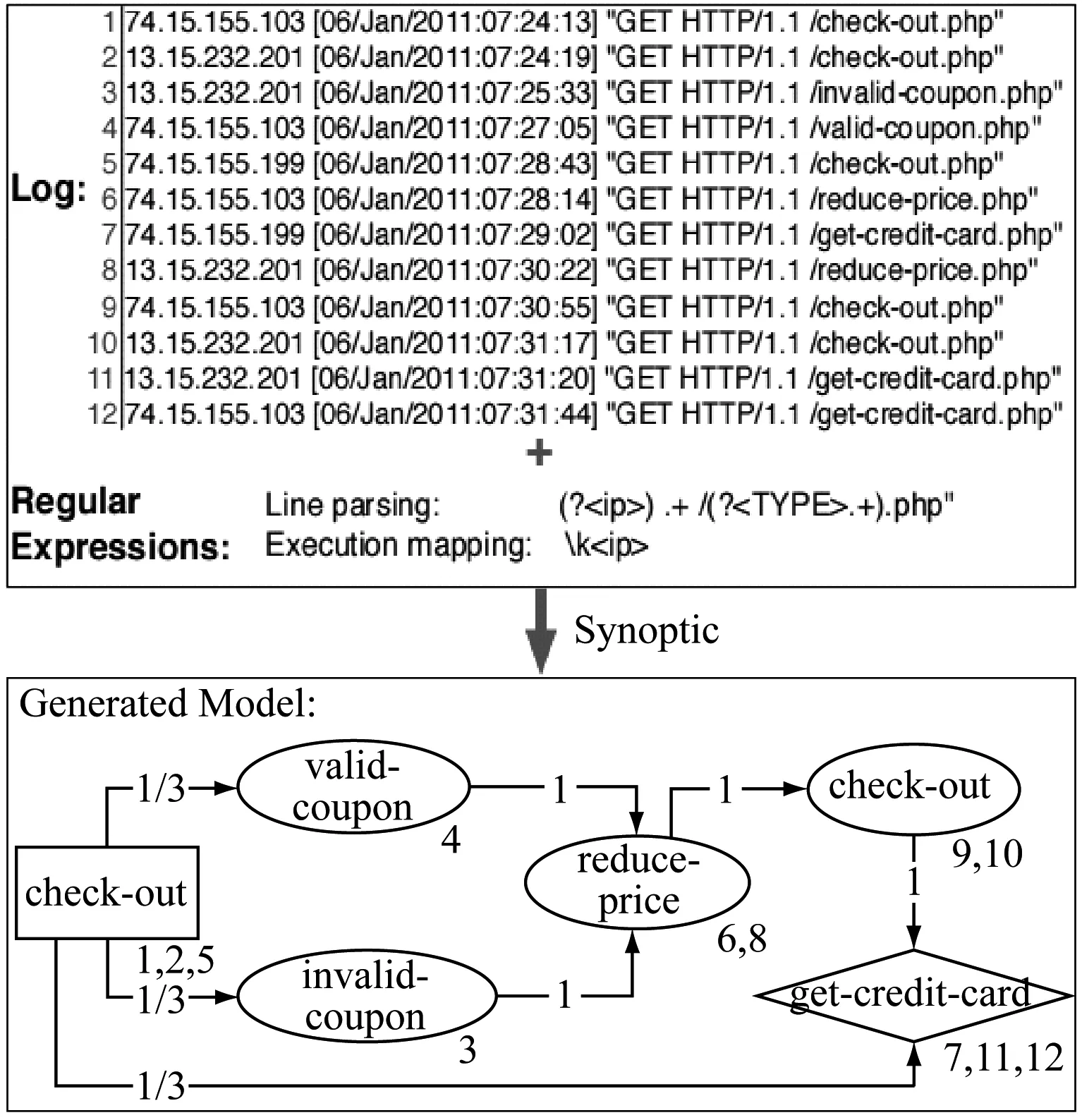
图2 Synoptic根据购物车应用程序的日志构建的模型
3.2 InvariMint
InvariMint是由BESCHASTNIKH等[2]在2013年提出的,是一种以声明方式指定模型推理算法的方法。InvariMint扩展和比较了现有的算法,方便比较和对比先前发表的算法,并且使用InvariMint指定的算法比原本的算法表现得更好。
InvariMint是一种描述模型推理算法的方法,或者说是一种公共语言。InvariMint的目标本身并不是生成模型,而是提供一种用于表示或指定模型推理算法的公共语言,使用相同的语言执行不同的算法可以让我们理解、组合和比较这些算法。
InvariMint将一个轨迹日志作为输入,并输出一个推断模型,该模型描述输入日志的过程。在内部,该算法使用日志属性类型来挖掘属性实例,然后将组合函数应用于属性实例来派生模型。
一个简单的邮件客户端例子如图3所示,包含事件login,check,compose,send,logout。InvariMint可根据输入的两条轨迹生成描述输入日志的模型。

图3 InvariMint生成邮件客户端系统的模型
3.3 flexfringe
flexfringe[3]工具可以从轨迹中推断软件系统的模型,是一种开源代码软件工具,可使用最先进的证据驱动状态合并算法从轨迹中学习有限状态自动机的变体。通过提供灵活、可扩展的界面,满足了在不同应用程序域中对定制模型和定制学习启发式的需求。
flexfringe核心算法是证据驱动的状态合并算法和概率变量,以使用一致性检查和得分功能的启发式搜索为中心,可以处理各种启发式和模型类型。flexfringe工具有效实现了状态合并算法、寻找更好模型的搜索方法、状态合并算法的高级功能、修改flexfringe核心功能和搜索策略的许多参数、通过向代码中添加单个文件来修改模型的启发式和类型及其可视化的能力和提供交互式界面,允许用户修改算法的不同步骤,以微调新定义的启发式算法。
flexfringe工具的目标是为从业人员提供不仅方便且易于使用的工具,而且帮助他们在无需深入了解核心状态合并算法的情况下构建自定义的模型。
使用flexfringe工具生成支付系统的模型如图4所示。将支付系统的相关执行日志作为输入,flexfringe可生成对应的软件模型。

图4 flexfringe生成支付系统模型
4 总结
本文对目前的软件模型推断过程和被动学习技术推断模型进行了概述,虽然目前已经实现了很多软件模型推断技术,比如Synoptic、InvariMint和flexfringe等,但这些软件模型推断技术依旧存在一些问题还需要解决。
正负轨迹问题。目前大部分软件模型推断技术只考虑了正轨迹,并没有考虑负轨迹,但在软件系统运行的实际情况中,并不仅仅有正常执行的轨迹,还存在一些异常或不能正常执行的轨迹。因此,未来可以开发以正负样本算法为核心的工具,用来构建正负轨迹的模型。
软件模型评估问题。目前软件模型推断技术可以生成软件系统的模型,但目前论文中并没有评估模型的标准。因此,未来可以提出一些评估模型的标准。
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
思维与智慧·上半月(2018年9期)2018-09-22
现代装饰(2018年5期)2018-05-26
小学生(看图说画)(2017年6期)2017-11-06
中国三峡(2017年2期)2017-06-09
山东青年(2016年1期)2016-02-28
当代修辞学(2014年3期)2014-01-21
