
某三甲医院患者剖面数据挖掘与分析
2022-12-06 09:05高瞻何强赵亮
微型电脑应用 2022年11期
高瞻,何强,赵亮
(十堰市太和医院,湖北,十堰 442000)
0 引言
经过多年数字化医院的发展,目前各个医院信息系统已经积累了大量、甚至海量的临床数据、检验数据、影像数据以及患者基本信息数据(文中简称“患者数据”)等。其中,患者数据主要包含患者年龄、性别、职业、地区、疾病、病史、用药、花费等属性,挖掘分析这些数据中蕴含的宝贵信息,将为医院运营管理优化、患者疾病精准诊疗分析、患者个性化服务等提供依据。如文献[1]设计并实现了急性发热性疾病监测系统,以辅助医院简化该病工作流程,提高监测工作效率与质量。文献[2]提出了传染病可视分析系统,以直观分析传染病的时空模式,交互挖掘不同疾病、地区之间的关联性和相似性。文献[3]利用医院病案首页数据库数据,分析医院住院患者的疾病种类、住院费用、住院天数的年龄分布特征。
本文以医院现有的医院信息系统(HIS)、检验信息系统(LIS)、电子病历系统(EMR)等系统数据库为基础,根据需求提取有效患者数据。经过数据预处理后,结合相应的数据挖掘规则,筛选出具有显著性差异的疾病,并实现了基于患者数据的可视化分析系统,简单、直观的展示患者数据中的关联元素和规律,为医院针对不同的患者特征优化管理和布局提供参考。
1 数据与方法
患者数据挖掘方法如图1所示,主要分为4个方面内容:数据采集、数据预处理与关联性分析、数据筛选与挖掘、可视化分析。

图1 患者数据挖掘方法示意图
1.1 数据处理
原始数据采集,需要获取置于医院内网的HIS、LIS、EMR等系统的数据,出于安全性考虑,通过绑定用于数据挖掘算法的中间服务器IP,设置相应的通信接口访问数据。本系统展示的数据为医院2019年门诊或住院的患者数据,共计120万余条。其中,住院患者约10人,分为患者基本信息(见表1)和患者疾病信息(见表2),每条患者基本信息对应一条或多条患者疾病信息,通过患者ID关联。
数据预处理是大数据挖掘分析的必要工作,主要包含数据清洗、数据变换、数据集成等操作。本文中主要的数据处理操作包含以下3个部分。
(1) 数据完整性筛选。本系统数据皆抽取自院内的多个结构化数据库,不同数据库之间对于同一患者数据需要使用患者ID字段进行关联,首先需要过滤掉重复数据,然后筛选患者关键信息严重缺失的数据予以删除。
(2) 数据脱敏。医院患者数据中包含非常多的个人隐私信息,这类数据泄露可能会造成严重的后果[4]。本系统从医院内网数据抽取过程中已经执行了严格的数据脱敏操作。主要包含:采用2次加密的患者ID代替患者姓名和原始ID、去除身份证和联系方式等字段、截取患者住址信息到地区的粒度等。
(3) 数据集成。数据量大会拖慢系统性能,除了在数据库中添加索引外,还需要对数据进行集成操作,特征聚集划分规则根据挖掘目标设计,通常需要覆盖所有数据,本文聚集型划分包含:年龄分段、职业分类、疾病分类、住院时长区间统计等,如根据患者年龄小于12岁为童年期,12岁至18岁为少年期等。

表1 患者基本信息表

表2 患者疾病信息表
1.2 方法描述
数据挖掘处理方面,采用Python语言及其丰富的数据处理和机器学习算法库,能够高效完成大批量数据的统计分析、聚类、分类等任务。本文对患者数据挖掘的主要目标是借助统计学方法找出与患者各项特征关联性较强的疾病,如:与职业关联的职业病、与年龄相关的年期病、与发病时间关联的季节病等。首先,选取患者特征,根据数据挖掘目标设计特征分段规则,重新进行特征分段并统计各种疾病患者数量;然后,计算各种疾病在各分段上的患者数均值,由于基数较小的疾病不具备统计学意义,大量分段区间为0的数据也会造成误差,因此通过初筛过滤掉均值小于5的疾病,同时过滤掉高于三分之二以上的分段中数量为0的疾病;最后,采用变异系数计算各类疾病与特征关联性评分,根据评分进行排序,筛选出Top N种疾病。不同疾病在相同特征分段上的均值差异较大,变异系数能够较好地体现疾病与患者某项特征的关联性,计算公式如式(1)~式(3):
(1)
(2)
(3)
大数据可视化方面,基于高性能的Web框架FastAPI,实现了前后端数据高效的异步交互,其性能足以与NodeJS和Go媲美[5],且数据处理和挖掘结果易于组织成JSON格式传输。为了便于二次开发和针对性的可视化展示,采用基于JavaScript的开源库ECharts,可以流畅地运行在PC和移动设备上,能够展现千万级的数据量,同时提供了大量交互式组件和图表用于用户个性化定制[6]。通过访问FastAPI中约定好的访问方式和路径,前端借助于$.getJSON()函数获取对应接口数据,完成数据挖掘结果与ECharts组件的无缝衔接,实现高效、流畅的数据可视化渲染。
系统实现方面,采用前后端分离技术设计,以JSON格式进行前后端的数据通信和传输。系统主体框架分为三个部分:医院内网的数据库访问模块、中间服务器数据处理模块、提供Web服务的前端应用模块。医院内网的数据库访问模块负责访问置于医院内网的HIS、LIS、EMR等系统的数据库获取全面的患者数据;中间服务器数据处理模块是系统的算法核心层,在Python环境中,实现数据抽取、优化与脱敏处理,并通过上述挖掘算法获取有效信息为Web服务器提供JSON格式的后端数据接口;前端应用模块,基于B/S(浏览器/服务器)架构,采用Jsp动态网页设计系统前端界面、JQuery脚本语言访问接口数据、Echarts组件进行可视化渲染,并通过Apache Tomcat为不同的PC端用户提供高效、流畅的数据交互服务。
2 数据可视化分析
伴随医院信息化、无纸化办公的兴起,医院患者数据呈现爆炸式增长,这些数据记录了患者的疾病、诊疗、用药、病史等信息。医院各类系统的应用,导致这些信息相互冗杂,使人们很难在数据层面上直接感知这些数据所传递的关联信息,对于患者数据的挖掘和可视化分析可以有效帮助我们发现数据中隐藏的规律和价值。ANDRIENKO等[7]对可视化关键问题和发展途径展开研究并将可视化方法分为3类:直接可视化、聚集可视化、特征提取可视化。直接可视化,指直接描述数据集中的每个记录,以便分析人员通过查看可视化展示或交互来提取数据最基本的信息;聚集可视化,通过对数据聚合和概括的方法,改进传统直接可视化方法,聚集可视化过程可能涉及各种形式的数据抽象,包括聚合、泛化和抽样,将聚集结果展示给用户观察[8];特征提取可视化,针对非结构数据,如文档、影像等,经过特定算法挖掘和抽取数据特征,形象的展示研究人员所关注的全局特征或局部特征[9]。当面临大量复杂的数据时,直接可视化展现方式有限,且可能因为过度绘图和记录叠加导致视觉混乱,使用户难以感知和理解众多视觉元素,可视化系统响应速度通常也会较慢。因此,本系统主要以聚集可视化和特征提取可视化为主。
季节疾病每年在一定季节内呈现发病率升高的现象,除了人们熟知的季节病如:流行性感冒、鼻炎、过敏等,还有许多疾病也具有季节性发病特点。通过挖掘更多的季节性疾病,不仅有助于提醒患者随季节变迁防患相应疾病,也能够提醒医院提前做好同类患者聚集的收治准备工作。针对该问题,本系统在住院患者数据中筛选出变异系数最大的前30种疾病,绘制热力图如图2(a)所示。图2(a)中颜色越深表示疾病在对应月份发病人数越多,如:1、2月份易发癫痫、腰椎间盘突出、各类肺炎等病;7、8月份恶性肿瘤化疗、阻塞性睡眠呼吸暂停低通气综合征、病毒性脑膜炎等病来院患者较多。
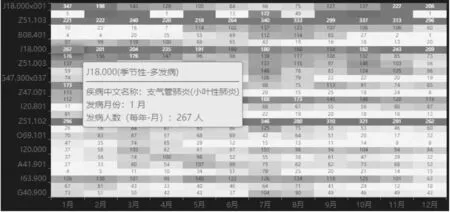
(a) 筛选出的疾病热力图
相同疾病在不同年龄段的治疗代价具有一定差异,通过挖掘住院周期与患者年龄关联性强的疾病,有利于主治医生为对应患者制定出更加符合实际的治疗临床路径,从而提高治疗效果和节省相关花费。本系统以年龄浮动为2,统计各年龄段不同疾病患者的平均住院时长,过滤掉基数较小的疾病,并选取住院时长大于0的数据计算变异系数,筛选出的疾病绘制成气泡图如图2(b)所示。图2(b)中容易发现,年龄层与住院周期关联性强的疾病有:泪小点狭窄、再生障碍性贫血、冲击治疗、恶性肿瘤内分泌治疗等。
除了上述可视化挖掘与分析外,针对患者其他基本信息,系统将挖掘结果采用大屏展示模式,通过提取患者疾病、疾病花费、来源、职业、年期等特征,对其关联因素进行可视化分析,如图3所示。图3中各区域图表通过区域1中地图模块联动变化展示不同来源的患者特征。区域1通过患者住址信息提取所在地区,划分为省外、省内、市内、各区县,直观展示医院患者在各地区的分布情况、占比、依从系数反映该地区患病数量及关联性强的疾病;区域2对患者职业进行分类,展示区域1中所选地区不同职业的患者易患的疾病及数量,容易发现腰椎间盘突出和冠心病是许多职业易患的通病、儿童中肺炎和呼吸道感染较多、学生中癫痫和紫癜较多、退休和教师人员中冠心病较多;区域3展示了该地区各类疾病在院的平均花费情况;区域4通过患者年龄划分为童年期、少年期、青年期、中年期和老年期,统计分析了各时期易患的疾病种类。

图3 患者数据挖掘与分析大屏
3 总结
医院信息化、无纸化办公的发展,使医院积累了海量的患者数据、诊疗数据,挖掘这些数据隐含的规律信息、发挥数据宝贵价值,是智慧医院建设的迫切需求。本文基于医院现有的HIS、LIS、EMR等系统数据库,抽取患者信息进行数据处理和挖掘操作,并设计和实现了基于患者剖面的数据分析系统。该系统采用主流的前后端分离技术,挖掘结果基于JSON格式传输,前端采用ECharts可视化组件,能够高效地完成数据加载和可视化页面响应。
本文基于大量患者数据进行全方位统计学分析,能够简洁、直观地反映患者数据隐含的规律信息,具有突出的应用价值,主要体现在以下几个方面:首先,基于提取患者所在地区、职业、年龄时期等特征,能够使医院医生和管理层从宏观上更加充分的了解患者基本情况和特点,为医院发展布局和个性化诊疗提供数据支持;其次,分析地域、职业、年龄、季节等因素与疾病的关联关系,清晰的筛选出地方病、职业病、季节病、年期病等,有助于部分特殊疾病在不同环境下的预防和医疗资源部署;最后,挖掘患者年龄、疾病等特征对住院周期的影响,有助于住院资源的精准调配,同时使患者从客观角度上认识自己的病情及对相关花费的评估。但本文存在对挖掘结果缺乏深入研究与分析的问题,后期将联合多名资深医生继续研究新的挖掘策略,并结合临床充分研究和利用患者数据的挖掘结果。
猜你喜欢
新作文·小学低年级版(2022年6期)2022-08-30
世界科学技术-中医药现代化(2022年3期)2022-08-22
师道·教研(2022年1期)2022-03-12
大众投资指南(2021年35期)2021-02-16
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
电力与能源(2017年6期)2017-05-14
哈尔滨医药(2016年1期)2017-01-15
中国卫生(2016年7期)2016-11-13
信息通信技术(2015年6期)2015-12-26
