
基于K-means算法的数字化教学资源的学生行为数据分析
——以“护理管理学”课程为例
2022-12-06 09:10张政庭周恒宇
中国医学教育技术 2022年6期
张政庭,周恒宇,崔 璀,袁 龙
重庆医科大学:1.护理学院;2.附属儿童医院, 重庆 400016
国家《“十四五”数字经济发展规划》提出推进“互联网+教育”的持续健康发展,即不断推动教育的变革和创新[1]。教育变革的阵地在课堂。随着信息技术的快速发展,数字化教学资源在课堂教学中的应用越来越广泛。数字化教学资源是经过数字化处理,可在多媒体计算机上或网络环境下运行,以实现共享的学习资源[2]。教育数字化转型要求从教学内容、学习资源、教学过程等方面进行数据采集、分析和应用,实现教学过程的数字化,构建泛在的网络学习空间,支撑各类创新型教学的常态化应用[3]。《教育部关于一流本科课程建设的实施意见》指出,课程内容要与时俱进,教学资源应丰富多样[4]。基于此,数字化教学资源在国内各高校得到了广泛推广,逐渐成为必不可少的教学资源,为教育的变革和创新奠定了基础[5]。
随着数字化教学资源的推广,学生在学习数字化教学资源中产生了大量的行为数据,包括视频观看记录、课程点击记录、课程讨论记录等[6]。行为数据是学生学习绩效数据的一种表现[7],这些行为数据为实现学生的学习行为分析提供了研究基础。很多学者基于行为数据进行了学生在线学习态度改变[8]、学生特征分类实现[9-10]、成绩预测[11]等研究。K-means算法[12]是一种典型的基于划分的聚类算法之一,以其实现简单、收敛速度快等特点应用于学生的成绩评价分析[13]、典型日冷热负荷曲线[14]、工件边缘检测[15]等。算法的优点在于结论形式简明,容易从中发现隐含的规律。文章以学生为中心,充分考虑学生的学习体验,从学生学习的角度实现数字化教学资源的优化,利用学生数字化教学资源行为数据,基于无监督的K-means聚类算法进行聚类挖掘,得到聚类结果,对得到的聚类结果进行分析,通过持续监测课程各类数字化教学资源,进而达到提升质量的目标。
1 K-means算法
K-means算法是一种无监督的学习算法,实现简单且效果优秀[16],在数据探索的群组发现中,聚类后簇中的样本彼此相似,与其他簇中的样本不相似,具有容易实现且高效的特点。
对于此文(如图1所示),设样本集X为含有n个学生样本的行为数据集合,即X={x1,x2...xn};每个样本有q类资源数据组成;第i个样本表示为xi=(xi1,xi2...xiq),则任意两个样本间的欧式距离表示为:
(1)

图1 K-means聚类算法流程图
K-means算法实现过程可描述如下:
Step1:输入n个样本的行为资源数据集合,聚类个数k;
Step2:初始化聚类中心;
Step3:根据样本间欧式距离公式(1),计算样本与各中心点欧式距离,并将该样本划分到与中心点欧式距离最近的簇中;
Step4:计算、更新每个簇的中心点;
Step5:各簇中心点是否改变(没有对象被重新分配给不同的簇),没有改变,转到Step6,否则转到Step3;
Step6:输出聚类结果。
为确定最优的聚类个数k,可以将聚类的误差平方和作为聚类效果的评价指标定义如下:
(2)
其中,SSE表示聚类的误差平方和,是样本点到各簇中心点距离的平方和,聚类效果越好,其值越小。ci表示第i个簇,ui表示第i个簇的中心点。
2 基于K-means算法的行为数据聚类
为更真实、有效、全面地获取学生学习数字化教学资源的行为数据,以网络教学平台上学院某课程一学期为时间段,提取平台上所有学生在该时间段内数字化教学资源的行为数据。
2.1 行为数据的获取
该文以学院“护理管理学”课程为例,进行学生行为数据的聚类分析。该门课程是护理本科教育的专业必修核心课程,课程通过在线学习、课堂教学、临床实践、社会实践“四位一体、二平台三阶段”的方式组织混合式教学,拥有丰富的数字化教学资源,网络教学平台开课多期,每期校内选课人数400~500人。该课程2021年被评为重庆市线上线下混合式一流课程。该文对所采集的“护理管理学”课程最近一个学期学生的视频资源学习完成率、参与讨论的次数、章节学习的次数、章节测验成绩、课程作业成绩等五类资源行为数据进行分析,其中视频资源由32个章节视频学习资源组成。所采集的学生行为数据如表1所示。

表1 学生行为数据
其中,yij表示第i个学生对应的第j类资源的数值,具体如表1所示。视频资源由32个章节视频资源组成,学生行为数据为查看资源的完成率;讨论数为学生参加课程发布的讨论主题数,是学生参与课程互动的一种形式;章节学习次数为学生进入章节学习的次数,在一定程度上体现了学生学习兴趣和课程难易度;章节测验和作业分别是学生参与章节测验、课程作业获得的分数,是学生学习效果的一种表现。
2.2 数据归一化
表1显示,从网络教学平台提取的行为数据类型不一致,基于各类资源具有同等重要性,将学生行为数据归一化到0~100内,具体到每类资源,其计算方法如下。
2.2.1视频资源
视频资源的数值表示查看资源完成率,即视频学习的完成情况,数值超过100%(含)可认为完成资源学习,归一化处理如式(3)所示。
(3)
2.2.2其他资源
讨论数、章节学习次数、章节测验、作业的数值归一化处理如式(4)所示。
(4)
其中,max(yj)表示第j类资源的数值最大值。
2.3 利用K-means算法进行聚类
采集后的数据经过归一化处理,基于K-means算法进行聚类。具体流程如下:
算法输入,即资源数值集合y。
算法输出,即聚类结果和聚类误差平方和SSE。
①资源数值集合y归一化处理后表示为含有n个学生样本的行为数据集合X。
②设置聚类数k,输入行为数据集合X,按照图1的算法流程进行聚类。
③输出聚类结果和聚类误差平方和SSE。
④增加聚类数k,重新进行聚类。
⑤输出所有满足条件的聚类结果。
2.4 K值的确定和最有聚类结果
基于K-means算法对行为数据进行聚类,得到聚类结果如图2所示。横坐标表示聚类数k,纵坐标表示误差平方和SSE。
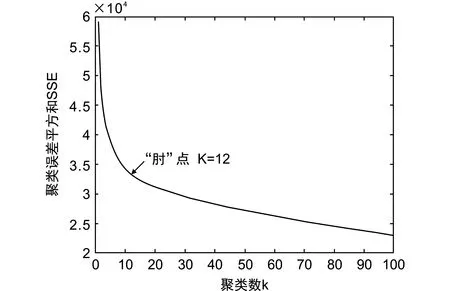
图2 聚类误差平方和
观察每个k值对应的误差平方和SSE,在误差平方和SSE变化过程中,会出现一个拐点,也称为“肘”点,即下降率突然变缓,此时,即认为是最佳k值,根据最佳k值,可将学生行为数据划分为12类。
最佳聚类数为12时,对应的各簇中心点如表2所示。
最佳聚类数为12时,各中心点的均值和标准差如表3所示。
最佳聚类数为12时,各簇学生数、占比情况如4所示。

表2 簇中心点数值

表3 簇中心点均值和标准差

表4 各簇学生数
3 数据分析
各资源学生行为数据归一化到0~100,以60为及格线,结合表2~表4的数据,以“护理管理学”为例的基于K-means算法数字化教学资源学生行为数据分析如下。
3.1 视频教学资源
从表2中心点数值横向分析,簇序号为5、7和10的三个簇所对应的簇中心点数值均在60以上,三个簇学生数占比(如表4所示)为61.57%;簇序号为1和3的两个簇对应的中心点数值小于60的较多,且部分资源数值大幅度低于正常数值,学生数占比为2.82%。以上表明大部分学生认可视频资源,有一定积极性,能按要求完成视频资源的学习。但同时也应关注1和3两个簇学生视频资源学习情况,听取这部分学生意见反馈,有目的地进行调整,不断完善视频资源内容。
从表3中心点数值纵向分析,资源28和资源32所对应的各簇中心点的均值小于60,且中心点数值的标准差较大,说明学生对这两类资源的学习完成度欠佳,学生差距较大,需要课程组对这两个视频资源重新进行调整。
3.2 讨论数
从表2和表3来看,讨论数中心点数值均未超过60,且标准差数值偏小,反映出大部分学生发帖数量偏少,参与课程相关讨论积极性不高,而讨论数是学生积极参与课程互动的直接反馈,是教师与学生不限时空进行沟通的主要路径。课程需要在讨论主题的设置、主题讨论内容编排上重新思考,加强教师在学生讨论、答疑时的引导,强调教师团队在答疑讨论版块的参与度。
3.3 章节学习次数
从表2和表3来看,章节学习次数中心点数值较小,且标准差数值偏小,即学生利用较少的学习次数完成了资源的学习。一方面反映出学生平台学习专注度较高;另一方面课程应调研资源学习挑战度是否有欠缺,导致学生不需要经过多次学习就能掌握课程内容和知识点,需要教师在课程资源高阶性上多加思考。
3.4 章节测验
从表2和表3来看,章节测试中心点数值除簇3以外均超过60,且标准差数值偏大,章节测试成绩反映出大部分学生章节知识点掌握较好,但要关注成绩偏差较大学生的学习情况,例如簇3中的八名学生。
3.5 作业
从表2和表3来看,作业中心点数值均超过60,且标准差数值偏小,通过作业成绩检验的学生课程学习情况较好,平台数字化教学资源对学生学习效果有辅助作用。
4 结束语
该文以“护理管理学”课程为例,采集该课程一个学期497名学生数字化教学资源行为数据,归一化处理后进行基于K-means算法聚类,根据误差平方和SSE结合“肘”点法确定最佳聚类数及最优聚类结果。根据聚类后各项数据分析可见:视频资源整体效果较好,但资源28和资源32需要重新调整;讨论环节学生参与度不高、课程存在不重视学生互动的问题;章节学习次数反映出资源内容学习的挑战度需要增加;章节测验和作业两类资源能够很好地检验学生学习情况。提出的建议为课程数字化教学资源质量持续提升奠定基础。
猜你喜欢
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
铁道通信信号(2019年6期)2019-10-08
电脑报(2019年4期)2019-09-10
福建基础教育研究(2019年11期)2019-05-28
中学数学研究(广东)(2018年24期)2018-03-12
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
大众摄影(2015年9期)2015-09-06
