
基于Spark+Flask的大数据可视化系统设计与实现*
2022-12-06 04:06王源陈智勇
科学与信息化 2022年22期
王源 陈智勇
广州理工学院 广东 广州 510540
引言
大数据技术引发各行各业的深刻变革,并已提升为国家战略,处于快速发展的大数据技术浪潮中,新技术的涌现层出不穷,Hadoop和Spark等开发框架已成为其中的代表。在离线大数据处理领域,Hadoop已然成为主流的应用开发平台,并在企业开发实践中得到了广泛的应用[1]。同时,由于Hadoop的MapReduce计算模型延迟过高,很难适应ms速度级的实时高速运算要求,而只能适用于离线批处理场景。Spark采用先进的计算引擎,并支持循环数据流和内存运算,其响应灵敏度相较于Hadoop有了大幅度的提升,并迅速获得了学界与业界的广泛关注与应用,Spark已逐渐发展成为大数据领域最热门的计算平台之一。
1 大数据可视化技术分析
1.1 Spark流计算框架
Spark采用基于内存与DAG的计算模型及任务调度机制,能有效减少内存I/O开销,使得任务响应更为灵敏。同时Spark完美兼容Python、Java、Scala、R等编程语言,丰富的接口支持大大降低了开发难度,能提供更高效的编程体验[2]。
Spark专注于数据的分析处理,其核心组件包含Spark Core、Spark SQL、Spark Streaming、Stuctured Streaming、MLlib机器学习和GraphX图计算等,其中数据存储模块功能依然要基于Hadoop中的HDFS分布式文件系统Amazon S3等来实现。因此,Spark流计算框架可以完美兼容Hadoop生态系统,从而使现有的Hadoop应用程序可以高效迁移到Spark流计算框架中执行。
1.2 Flask
Flask是一个轻量级Web应用开发框架框架,使用Python语言编写,灵活、轻便、安全且容易上手,并可以很好地结合MVC模式进行开发,能高效实现中小型网站开发与Web服务[3]。此外,Flask具备较强的定制性,开发者可以根据自己的需求来添加相应的功能,其强大的扩展插件库可以让用户实现个性化的网站定制,实现功能强大的网站开发。
1.3 Python语言
Python语言以其语法简单、风格简约,交互式编程等特点,已被学界业界广泛应用。由于其开源属性,因此能兼容移植到包括Linux、Windows、Android等主流开发平台[4]。作为一门解释性语言,Python天生具有跨平台的特性,只要平台提供相应的解释器,Python都能兼容运行,如今Python已广泛应用于科学计算、大数据、人工智能、云计算等行业领域。
1.4 Pyecharts
Pyecharts是百度开源的一个用于生成Echarts图表的类库,兼容Python语言,方便源码数据生成图表,内置直观,生动,可交互,可个性化定制的数据可视化图表库,提供了开箱即用的20多种的图表和十几种组件[5]。支持响应式设计,提供灵活的配置选项方便开发者定制。有健康的开源社区,有API和友好接口文档。官方提供了很多第三的插件。Pyecharts凭借良好的交互性,精巧的图表设计,得到了众多开发者的认可。
2 系统设计与实现
2.1 环境准备
本系统采用的软件集群包括Linux系统Ubuntu18.04LTS、Hadoop-3.1.3、Spark-2.4.0、Python3.7.3、PyCharm2021.02,大数据框架采用伪分布式Hadoop集群配置、Spark采用本地模式,便于单机环境下运行测试。
2.2 数据源获取
本系统使用的数据集来自美国数据网站Kaggle中的uscounties.csv流感数据集,该数据集以数据表组织,数据包含以下字段:

2.3 格式转换
原始数据集是以.csv文件组织的,为了方便spark读取生成RDD或者DataFrame,首先将usa-counties.csv转换为.txt文本格式文件usa-counties.txt。转换操作使用python语言代码实现,代码组织在Text.py中:
import pandas as pd
data = pd.read_csv('/home/spark/usa-counties.csv')
with open('/home/spark/us-counties.txt','a+',encoding='utf-8') as f:
for line in data.values:
f.write((str(line[0])+' '+str(line[1])+' '
+str(line[2])+' '+str(line[3])+' '+str(line[4])+' '))
2.4 将获取的文本文件usa-counties.txt上传至HDFS文件系统中
使用$./bin/hdfsdfs -put /home/hadoop/us-counties.txt /user/Hadoop命令把本地文件系统的“/home/hadoop/usa-counties.txt”上传到HDFS文件系统中,具体路径是“/user/hadoop/usacounties.txt”。
2.5 使用Spark对数据进行分析
使用sparkSQL模块进行数据分析。由于本实验中使用的数据为结构化数据,因此可以使用spark读取源文件生成DataFrame以方便进行后续分析实现(共计8个指标参数),在计算指标参数过程中,根据实现的难易程度,采用了DataFrame自带的相关操作函数,又使用SparkSQL数据库查询语言进行了处理[6-7]。
#主程序段:
spark = SparkSession.builder.config(conf = SparkConf()).
getOrCreate()
fields = [StructField("date", DateType(),False),StructField("
county", StringType(),False),StructField("state", StringType(
),False),StructField("cases", IntegerType(),False),StructField("
deaths", IntegerType(),False),]
schema = StructType(fields)
rdd0 = spark.sparkContext.textFile("/user/hadoop/usa-counties.
txt")
2.6 结果文件处理
Spark计算结果保存到.json轻量级数据文件中,由于使用Python读取HDFS文件系统中的数据源文件不太方便,故将HDFS上结果文件转储到本地Linux文件系统中。
2.7 可视化处理
本系统采用Python第三方库pyecharts作为可视化工具,常用的图表类型包含折线图、柱形图、饼图、散点图、雷达图、词云图、统计地图等。结合项目实际,在此选用词云图、象柱状图共3类图表进行.html形式的可视化展示。
其次,使用line()函数绘制折线图,主要代码段如下。
Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add_xaxis(xaxis_data=date)
.add_yaxis(series_name="",
y_axis=cases,
markpoint_opts=opts.MarkPointOpts(data=[opts.
MarkPointItem(type_="max", name="最大值")])
其次,使用Bar()函数绘制双柱状图,主要代码段如下,执行效果如图1所示。
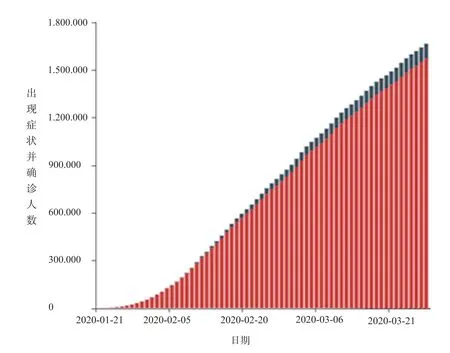
图1 每日出现症状并确诊人数双柱状图
Bar()
.add_xaxis(date)
.add_yaxis("累计出现症状人数", cases, stack="stack1")
.add_yaxis("累计确诊人数", deaths, stack="stack1")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="每日累计
流感人数"))
.render("/home/hadoop/result/result1/result1.html"))
从图1分析可知,出现症状与确诊人数相近度很高,说明确诊率很高,该疾病处于高发期,双柱状图能通过对比分析双柱的分离度或者相近度,有效推导两者之间的关联程度。
最后使用WordCloud()绘制词云图,主要代码段如下;
WordCloud()
.add("", data, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="美国各州确诊Top10"))
.render("/home/hadoop/result/result4/result1.html"))
从图2分析可知,纽约、新泽西、加利福尼亚、马里兰州、伊利诺伊州、马萨诸塞州等地区属于疾病高发区,可以对排名前三地区进行进一步的关联构建,探索疾病的传播路径。
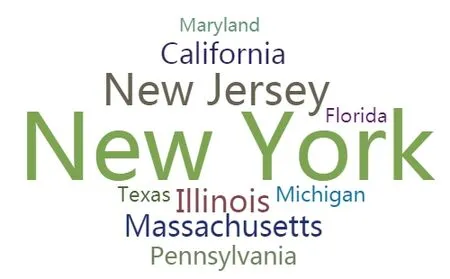
图2 各州确诊人数词云图
3 结束语
本文运用主流大数据开发技术(Spark流处理引擎、HDFS分布式文件系统、RDD 弹性分布式数据集等)进行流数据处理分析,并使用Pyecharts可视化工具实现了图表展示,设计过程涉及大数据采集预处理、分析与数据挖掘、可视化处理等步骤,构建了完整的流数据分析处理框架,突出了大数据开发的实际项目应用,为用户利用Spark等大数据平台进行数据处理提供了一个较为完整的参照模板。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
软件(2018年5期)2018-06-14
名家名作(2017年3期)2017-09-15
课程教育研究·下(2016年12期)2017-04-26
出版科学(2017年2期)2017-04-14
足球周刊(2016年14期)2016-11-02
足球周刊(2016年15期)2016-11-02
足球周刊(2016年10期)2016-10-08
世界博览(2016年16期)2016-09-27
小天使·四年级语数英综合(2015年3期)2015-04-20
