
基于Labeled-LDA模型的居民群体分类与出行特征分析
2022-12-03 02:00王长硕蒲英霞
计算机应用与软件 2022年11期
王长硕 蒲英霞,2,3*
1(南京大学地理与海洋科学学院 江苏 南京 210023)2(南京大学江苏省地理信息技术重点实验室 江苏 南京 210023)3(南京大学江苏省地理信息资源开发与利用协同创新中心 江苏 南京 210023)
0 引 言
城市是人类聚居的主要形式之一,是经济社会发展和文化交流的主要载体[1]。城市居民通过在城市不同区域、不同场所间的通勤和迁移,满足居家、上班、购物、娱乐等生产和生活需求,实现生存发展和价值追求[2]。城市居民的出行行为包括出行目的、出行方式、出行时间等,与其包括社会角色在内的群体标签之间相辅相成、互相约束。例如,当“学生”群体的出行目的地为“电影院”等娱乐场所时,其出行行为将受到一定时间限制,大多选择工作日晚间或周末;而若在工作日上午出门,前往“学校”学习这一出行行为则具有更高的概率。通过城市居民群体分类和出行特征分析,有助于发现城市居民的出行行为模式及变化规律,理解居民在城市中的时空参与性,从而更好地服务于人类生活需要[3]。
自19世纪起,地理学家、交通学家和社会学家从个体行为理论[4-5]、居民出行目的[6]、出行方式[7-9]、出行特征[10-11]等不同方向对城市居民出行行为进行了研究。传统城市居民出行特征研究一般是以交通小区为单位分析居民出行交通活动(集计模型),进而获取一个时段内(一般是一个昼夜)的全体城市居民的宏观出行特征信息,主要包括出行频率、出行目的、出行时间分布等。在此基础上,建立回归分析模型等探索居民出行规律。随着城市的发展和人们生活水平的提高,居民出行方式越来越多元化和复杂化,居民出行调查数据的获取周期长、成本高,传统方法逐渐显现出其局限性。全球定位系统(GPS)、遥感技术(RS)和地理信息系统(GIS)的发展使得新的数据采集方法和分析手段不断涌现,国内外学者基于手机信令数据[12]、公交车刷卡数据[13]、GPS轨迹数据[14-17]和社交媒体数据[18],开展了人类出行行为[13,16-17]、土地利用分类[12,14-15,18]等研究。例如,郑林江等[17]基于出租车轨迹数据,提出一种基于网格密度的GScan聚类算法,以重庆市为例分析居民出行热点区域。
由Blei等[19]提出的潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)模型在探究城市居民时空行为方面具有较好的潜力。作为一种概率生成模型,LDA具有潜在语义挖掘和主题提取能力,已被广泛应用于自然语言处理、文本分类、场景分类等领域[20-21]。该模型包含“词汇-主题-文档”三个层次,其中隐含主题由词汇的多项分布表示,而文档则用隐含主题的多项分布表示,通过模型求解确定每一篇文档所隐含主题的概率分布,进而对未知文档完成文本分类。基于城市居民出行行为的特征分类和文本分类研究具有一定的相似性,城市居民在不同时空间扮演社会角色的不同,导致同一居民存在多种对应的群体类别,因此可以根据居民的出行行为构建语料库,利用LDA模型将居民划分为具有不同出行特征的群体。
LDA模型是贝叶斯方法的具体应用。贝叶斯方法的优势在于将定性或定量的先验信息与样本信息结合,通过学习机制,共同得出模型和变量的后验概率分布,它不仅可以避免仅使用先验信息可能带来的主观偏见,还可避免缺乏样本信息时的大量盲目搜索与计算[22-23]。然而传统的LDA模型并没有借助样本信息外的其他信息作为先验,导致了其非监督特性。Labeled-LDA模型通过附加类别标签,将类别先验信息融入LDA模型,克服了传统LDA强制分配隐含主题的缺陷,有效提高了分类的准确性和结果的可解释性[24-25]。因此,基于Labeled-LDA模型挖掘城市居民出行行为,可以得到具有现实意义、易于解释的群体类别。
凭借着用户参与的广泛性与即时性、信息扩散模式与速度等方面的优势,移动社交媒体数据在表达城市居民日常出行行为方面具有明显优势。2016年末的统计显示,Twitter的月活跃用户量已超过3亿,平均每位用户拥有208位直接社交朋友[26]。据此,本文利用2014年波士顿海量Twitter签到数据,构建居民出行活动模式模型和Labeled-LDA模型,将社会角色标签作为附加先验信息,在群体和个体尺度上分析城市居民的日常出行行为,探究居民出行时空特征,为居民在不同时空间表现出的不同出行行为特征提供概率解释。
1 居民出行活动模式
为探究城市居民日常出行规律,分析不同群体时空出行特征,本文建立表征城市居民出行行为的定量模型,现给出如下定义:
定义1移动轨迹。处于活动A1的城市居民在TL时间离开某地RO,在TA时间到达另一地点RD,目的为活动A2,则包含出行目的的居民出行移动轨迹可表示为如下的一个六元组M:
M=
(1)
定义2活动模式。当优先考虑居民出行活动的目的,探究群体或个体出行目的规律时,忽略居民出行的地理位置差异,则移动轨迹可表示为如下的一个四元组M+:
M+=
(2)
现实生活中,居民日常的出行状态:“离开”或“到达”常影响其出行目的和起讫地理位置,并呈现较强的规律性,例如学生群体工作日的“离开”常常指离开“家”到达“学校”。
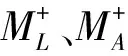
2 城市居民群体分类方法
2.1 研究框架
将每一个居民个体作为一篇文档,居民的群体类别作为主题,居民出行活动模式作为词汇,可以运用Labeled-LDA模型对城市居民进行群体分类,如图1所示。

城市居民的所有出行行为信息→语料库城市居民→文档具有不同出行特征的人群→文档的主题居民出行活动模式→词汇
图1 Labeled-LDA用于居民群体分类的思想类比
为分析城市居民的出行行为特征,探究居民扮演的社会角色作为先验信息与居民出行行为模式之间的潜在规律,研究从以下三个阶段展开:居民出行活动模式构建,基于LDA模型提取社会角色先验信息,基于Labeled-LDA模型完成群体分类和出行特征分析。首先使用Twitter签到数据提取城市居民出行活动类型和时间等信息,生成居民出行活动模式;其次建立LDA模型处理活动模式,得到典型群体的出行活动分布,并作为先验信息;最后建立Labeled-LDA模型,完成城市居民群体分类,于群体尺度和个体尺度分析居民出行特征。
2.2 标签狄利克雷分布模型Labeled-LDA

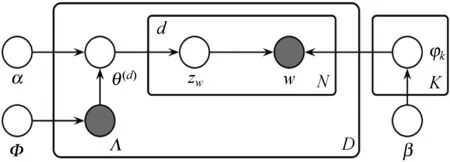
图2 Labeled-LDA模型图解[24]
算法1Labeled-LDA模入:语料库D={d1,d2,…,dm…,dM},Dirichlet超参数α、β,主题数量K,先验标签Φ,先验标签集Λ(d)。
输出:文档-主题多项分布θ(d),主题-词汇多项分布φk。
步骤1对于每一个主题变量k∈{1,2,…,K}:
产生φk=(φk,1,φk,2,…,φk,V)~Dir(·|β);
步骤2对于每一篇文档d:
步骤2.1对于其中的每一个主题变量:
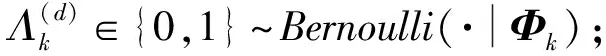
步骤2.2产生α(d)=L(d)×α;
步骤2.3产生θ(d)=(θl1,θl2,…,θld)~Dir(·|α(d));
步骤2.4遍历对于该文档中的每一个词汇:
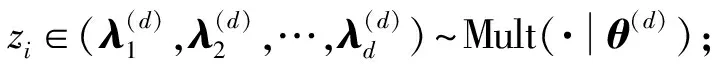
产生词汇wi∈{1,2,…,V}~Mult(·|φzi)。
模型可以得到居民群体类别的后验概率(对应文档-主题后验概率分布)、居民出行活动模式对群体类别的解释强度(对应主题-词汇后验概率分布),结合两者能够对城市居民的出行行为规律做出定量解释和归纳。
在标签集Λ(d)的设置过程中,本文使用传统LDA模型对城市居民的出行行为进行探索性分类,得到典型的居民群体,提取其出行活动分布作为先验信息。具体过程如下:
算法2Labeled-LDA标签集设入:基于签到数据的波士顿城市居民出行活动模式(样本信息D),基于LDA模型的探索性分类结果(先验信息)。
输出:波士顿城市居民先验标签集Λ(d)。
步骤1分析传统LDA模型探索性分类结果,得到具有典型出行行为特征的群体,提取其出行活动分布向量作为先验分布曲线。
步骤2对于每一位波士顿居民:
步骤2.1遍历该居民的所有出行活动模式:M+=
步骤2.2基于欧氏距离比较该居民的出行活动分布曲线与步骤1中的先验曲线,计算曲线相似度。
步骤2.3选择最大曲线相似度对应的群体类别(社会角色)作为该居民的先验标签。
步骤3完成先验标签集设置,继续Labeled-LDA建模。
2.3 吉布斯抽样
求解含有隐含变量的概率主题模型非常困难,无法通过常用的最大似然函数方法对模型进行推导,目前比较常用的方法包括期望最大化算法(Expectation Maximization,EM)以及马尔可夫链蒙特卡洛算法(Markov Chain Monte Carlo,MCMC)等。Labeled-LDA模型的似然函数为非凸函数,采用EM算法容易得到局部最优解,而由于多项分布和狄利克雷分布具有共轭特性,基于MCMC的吉布斯抽样可以极大简化抽样复杂度,因此我们使用吉布斯方法对参数进行抽样,获得参数的后验分布[21]。
3 实验与结果分析
3.1 数据预处理与活动模式生成
本文利用美国波士顿2014年Twitter签到数据展开实验。源签到数据时间跨度自美国东部时间2013年12月31日至2014年12月31日,记录了用户经去隐私化处理的ID、签到时间、活动类型、签到时所在地的建筑物ID、所在地的重要性、家庭住址等信息。
如表1所示,源签到数据中各用户的不同签到记录由“,”链接,同一签到记录下,各数据项由“&”链接。每位用户的第一个签到记录为补充的家庭地址信息,以活动类型为“0”作为标记,除家庭地址的经纬度外其他信息无实际意义。从第二个签到记录开始为用户的实际签到数据,依次包括地址重要性、建筑物ID、签到时间、辅助签到时间(位于一年中的第几天)、活动类型五个信息。其中,活动类型共有12种,活动类型代码与实际意义的联系见表2。

表1 美国波士顿签到数据示例
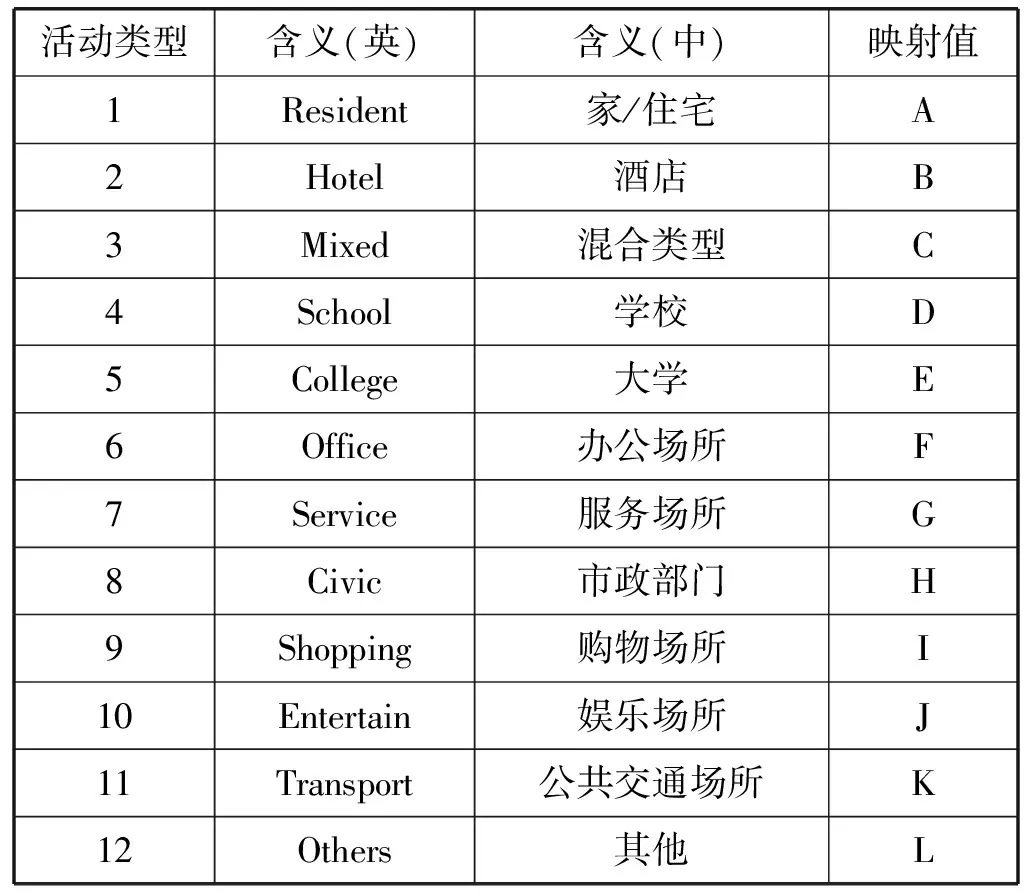
表2 活动类型的实际含义及其映射
根据活动模式模型,本文将Twitter签到数据一一映射为居民出行活动模式,并生成对应的活动模式词汇。由于城市居民出行的活动周期通常为一天,因此以一个小时为时间间隔离散化时间,得到值为0~23的时间序列。为避免时间与活动类型混淆,本文将活动类型映射为“A-L”(表2)。例如,某波士顿居民于2014年5月1日0时在“家”签到,然后于当日9时在“学校”签到,则其对应的活动模式词汇为A_0_D及A_D_9。
本文对由签到数据生成的活动模式进行了统计。源数据中总用户数量为14 177人,可生成3 879 072条活动模式。考虑到数据量不能过小,本文最终选定年签到数据量高于1 500条的588位用户及其1 705 568条活动模式,作为后续研究的数据源。
3.2 标签集设置
使用JAVA语言搭建LDA模型,对城市居民活动模式词汇进行处理,生成居民群体类别的后验概率(文档-主题后验概率分布)及居民出行活动模式对群体类别的解释强度(主题-词汇后验概率分布)。本文将LDA模型类别数量(K)设置为10,模型迭代次数设为3 000。对于文档和主题先验Dirichlet分布超参数(α和β),本文根据文献[27-28]的研究,取α=50/K,β=0.01,此时模型性能较好。
LDA模型可得到10种群体类别。表3为居民出行活动模式词汇从属于各群体类别的后验概率分布,取排名前十的结果。概率越大,排名越靠前,越能解释其相对应的群体类别。
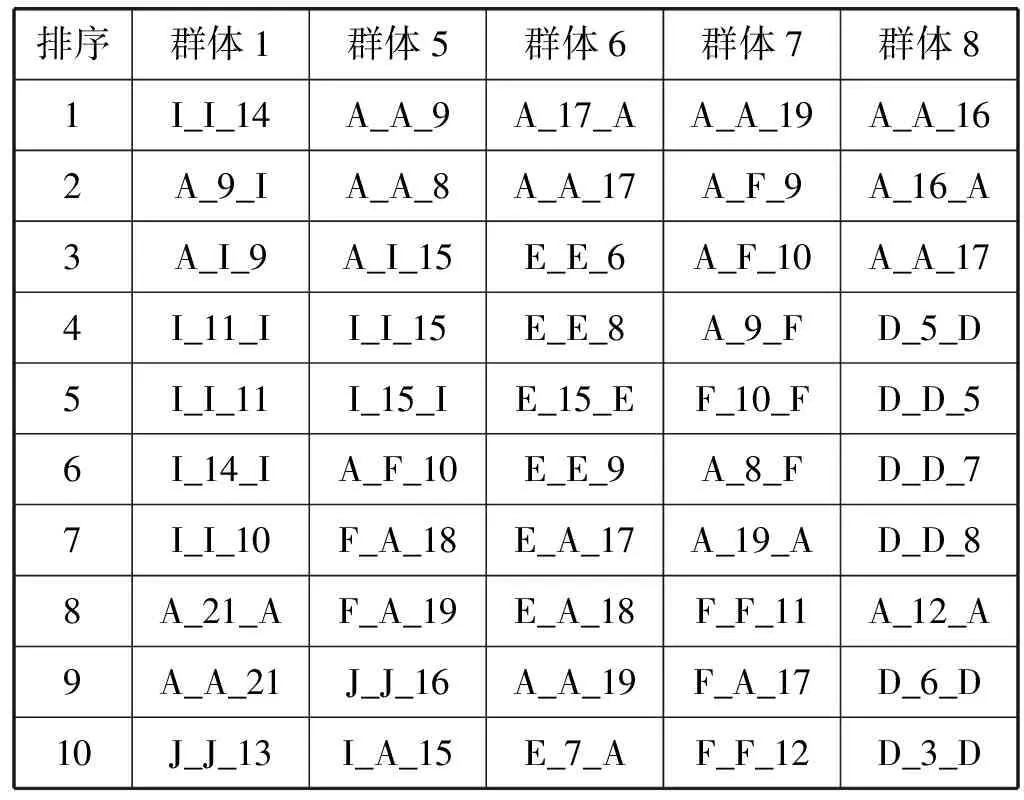
表3 居民出行活动模式对群体类别的解释强度
通过分析各活动模式对群体类别的解释性,我们可以总结和归纳出群体类别的现实意义。其中,群体类别1、5、6、7、8具有典型的出行行为模式,分别与居家人员、夜间活动族、大学生、上班族、中小学生的出行行为相接近,因此提取这5个群体的出行活动分布作为先验信息(表4及图3),为每一位居民设置先验标签。
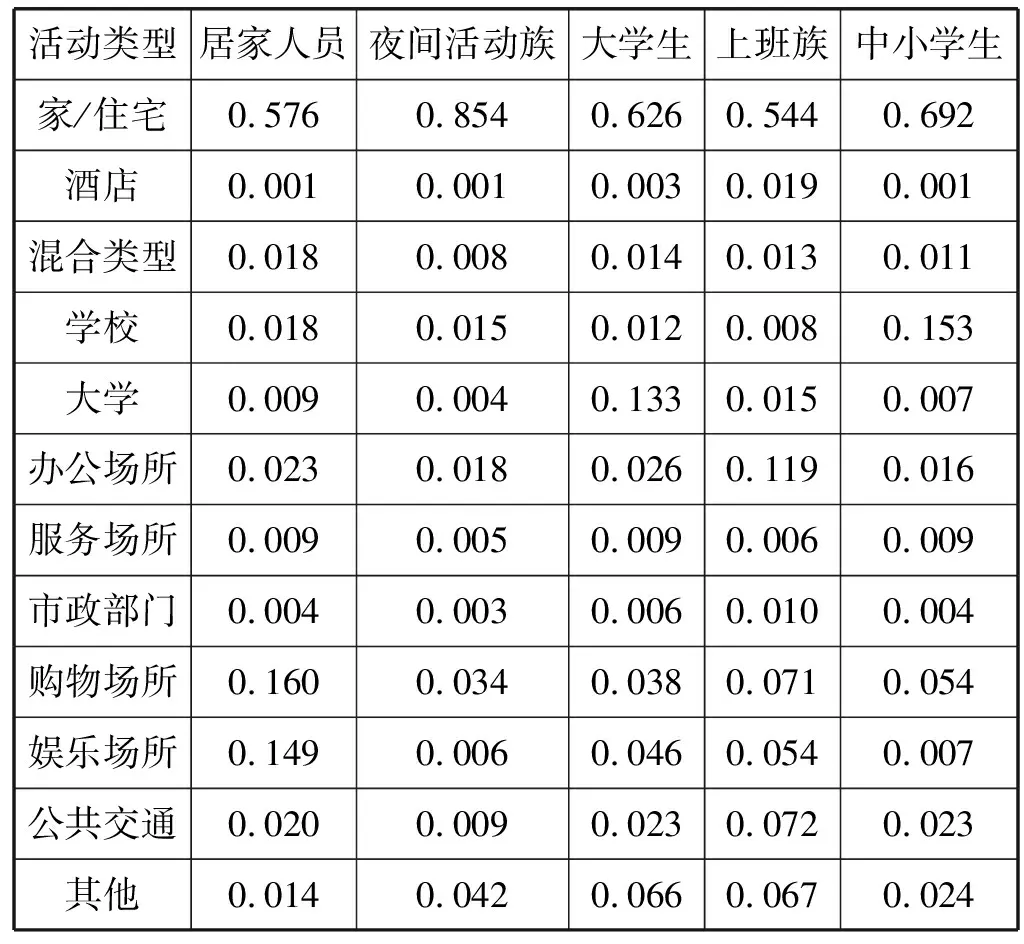
表4 典型居民群体的出行活动分布向量
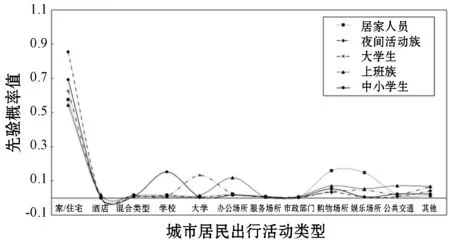
图3 典型居民群体的出行活动分布曲线
3.3 波士顿居民群体分类
Labeled-LDA模型主题数量设为5,其余参数同传统LDA模型。模型可以得到波士顿各居民属于5个群体类别的后验概率分布,如表5所示,编号为1934319254的波士顿居民属于居家人员、夜间活动族、大学生、上班族和中小学生的后验概率分别为0.015、0.407、0.172、0.086和0.320。其中,属于夜间活动族的概率最大,说明该居民通过Twitter签到所反映出来的日常出行行为更符合夜间活动族群体。
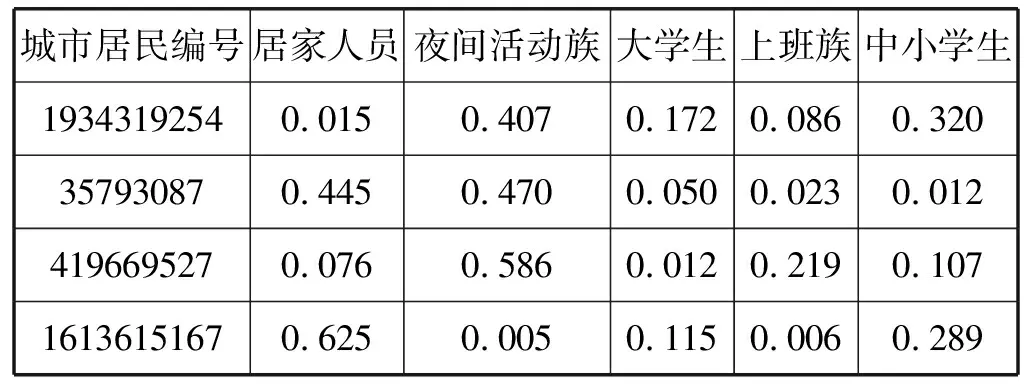
表5 Labeled-LDA建模结果
为分析各群体出行行为时空特征,本文设置后验概率最大的类别作为该居民的群体类别,提取波士顿居民在2014年任意30天内的出行行为,结果如图4所示,横轴代表以一小时计的30天(共720小时),纵轴代表各群体类别的波士顿居民。同时,本文统计了Labeled-LDA主题-词汇后验概率分布,表6所示为排名前十的居民出行活动模式词汇。

图4 波士顿居民群体的出行行为分布
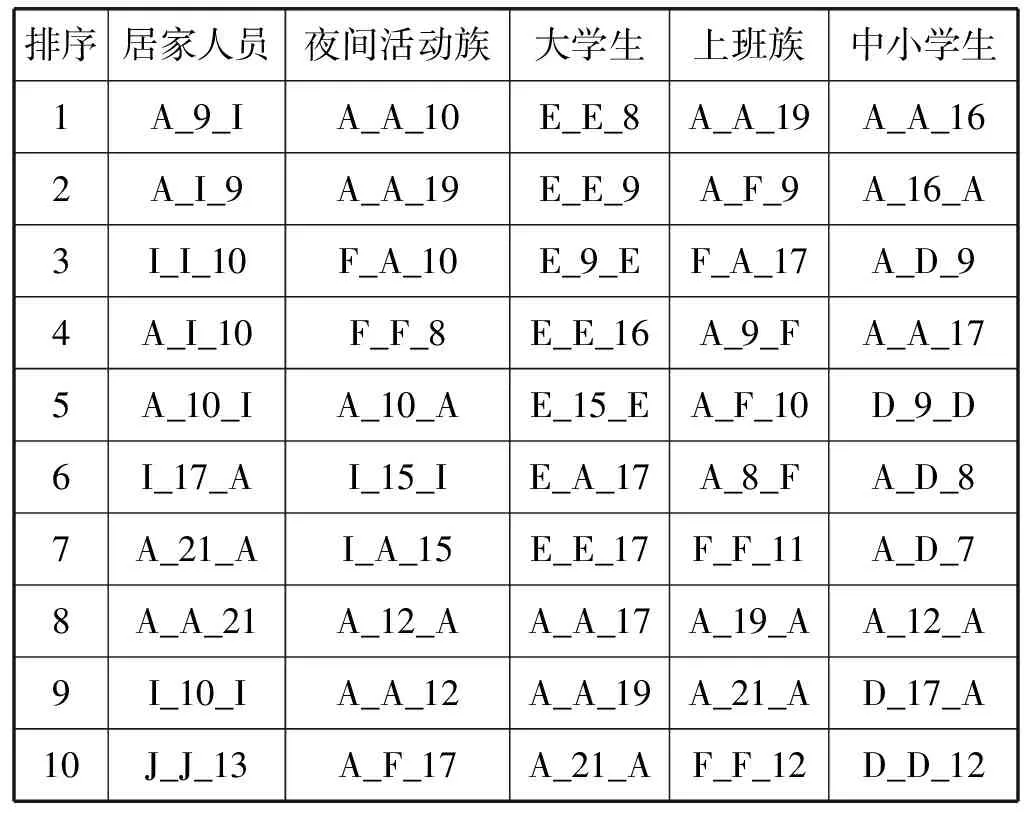
表6 Labeled-LDA建模结果:主题-词汇分布
居家人员的出行行为以“家”与“购物场所”、“家”与“家”、“娱乐场所”之间的通勤为主。更为具体地,早上9点或10点,居家人员从“家”出发前往“购物场所”,于9点或10点到达(由活动模式A_9_I、A_I_9、I_I_10、A_I_10反映,下类似);上午10点,居家人员在“购物场所”采购家用生活物品、食物时,在不同“购物场所”区域内移动,居民可能一边购物一边悠闲玩手机(I_I_10、I_10_I);下午,居家人员可能于13点左右前往“娱乐场所”娱乐和休闲;而到了21点,居家人员或返回“家”中,或由“家”中出发前往其他区域休闲后再度返“家”(A_21_A、A_A_21)。
夜间活动族的出行行为以“家”与“家”、“家”与“办公场所”、“购物场所”之间的通勤为主。更为具体地,夜间活动族于早上8点离开“办公场所”(F_A_10、F_F_8),在10点到达“家”中;在“家”中,他们或休息到12点后再度出门,或不休息直接出门前往其他活动类型区域,或者休憩结束后居家玩手机,期间多次使用Twitter签到(A_A_10、A_10_A、A_A_12及A_A_12);夜间活动族在15点左右会前往“购物场所”采购生活物品,他们在“购物场所”的行为方式与居家人员一样,一边购物一边悠闲玩手机,然后他们于15点左右返回家中;最后,在17点夜间活动族会返回“办公场所”上班,如果没有排班的话,他们则在19点或返回“家”中,或由“家”中出发前往其他区域休闲后再度返“家”。
大学生的出行行为以“大学”与“大学”、“大学”与“家”、“家”与“家”之间的通勤为主。更为具体地,早上8点或9点,大学生到达“大学”并在“大学”内部通勤,可能是在不同教室上课或学习,但他们时常使用Twitter签到;下午大学生的出行行为也是如此,在“大学”内部通勤;直到17点或更晚,家在波士顿的大学生陆续返回“大学”;从17点开始至21点,部分大学生或返回“家”中,或由“家”中出发前往其他区域休闲后再度返“家”。
上班族的出行行为以“家”与“办公场所”之间的通勤为主。更为具体地,早上8点或9点,他们于“家”出发前往“办公场所”,并于9点或10点到达;中午11点至12点,上班族在“办公场所”内通勤,可能是在公司内部或附近吃完午饭,然后回到公司继续上班;17点左右工作结束,上班族开始返“家”;到了19点至21点,他们则在家中休闲刷手机,使用Twitter签到,或由“家”中出发前往其他区域休闲后再度返“家”。
中小学生群体的出行行为以“家”与“学校”、“学校”与“学校”、“家”与“家”之间的通勤为主。更为具体地,早上7点至9点,学生从“家”出发前往“学校”开启一天的学习历程;中午12点,部分学生会离开“学校”到达“家”中,也有部分学生一直在“学校”;到了16、17点左右,学生们结束了一天的学习开始返回“家”中,或已经到“家”,而他们在到达“家”后,有可能前往其他区域休闲,并于更晚时候再度返“家”。
为进一步探究引入先验信息对模型结果的影响,本文统计了各群体居民的活动类型占比(后验分布),对比传统LDA模型得到的居民活动类型占比(先验分布),分析在使用先验信息后,Labeled-LDA模型得到的居民出行行为变化情况。
如表7所示,居家人员群体于“购物场所”、“学校”活动的后验概率相比先验有一定幅度的提升,而于“娱乐场所”活动的后验概率则下降,说明Labeled-LDA在有效加入先验信息进行分类的同时,没有忽略样本数据自身的信息特征。夜间活动族于“办公场所”的后验概率与先验概率相比,提高了0.058,这一方面说明该群体在“办公场所”出行行为与他们的日常生活联系紧密,另一方面给出了该群体在现实生活中所对应的实际人群的可能性解释,例如夜间工作的蓝领员工、从事夜间基础设施服务的服务类型人员等。大学生群体于地点“大学”有关的出行活动概率达到了20.5%,即他们在日常生活中有五分之一的出行行为,其出发地或目的地为“大学”,远高于相应的样本频率和先验概率,说明Labeled-LDA模型有效提取了该群体于“大学”的出行行为模式。上班族群体于“办公场所”的通勤行为中,后验概率为17.6%,相比先验有所升高,说明出行行为模式更集中于“办公场所”的居民被归类为上班族群体。
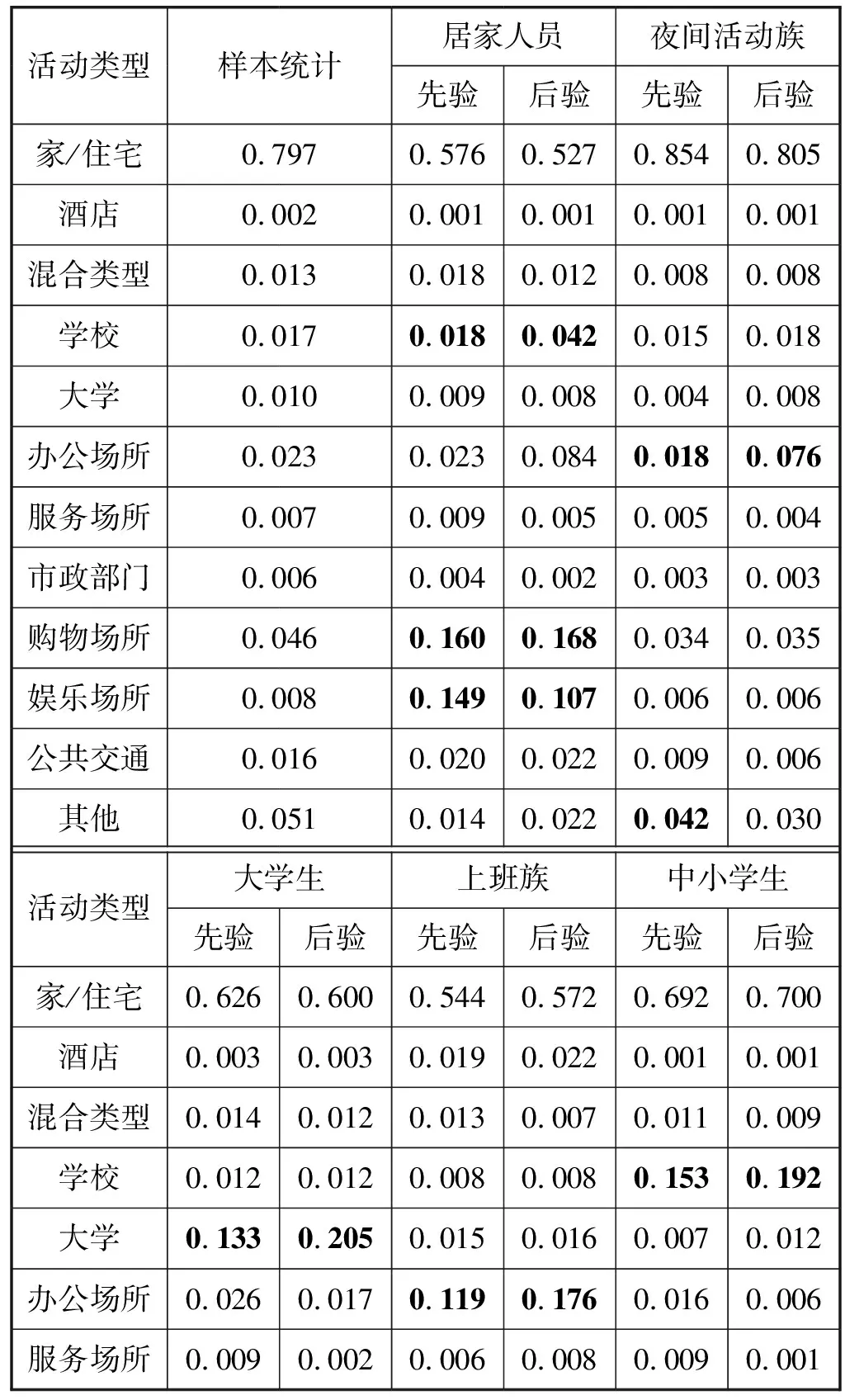
表7 波士顿居民群体的活动类型分布

续表7
3.4 个体出行行为的不确定性讨论
在实际生活中,“人”常常扮演着多个角色,比如工作日在“学校”时,居民扮演“学生”角色,而放假期间在“家”时,居民则扮演“居家人员”的角色,城市居民的出行行为随着不同时空间扮演社会角色的不同而发生着巨大的变化。Labeled-LDA模型将先验信息(标签)和样本信息(波士顿居民出行活动模式)相结合,基于吉布斯抽样通过不断迭代采样而得到波士顿居民属于各群体类别的后验概率分布,这一贝叶斯过程所产生的模型结果,在一定程度上反映了个体出行行为的不确定性。
例如,Labeled-LDA得到ID号35793087的波士顿居民属于居家人员、夜间活动族、大学生、上班族和中小学生的后验概率分别为0.445、0.470、0.050、0.023和0.012,属于夜间活动族的后验概率最大,因此被分为夜间活动族(表5)。然而,这并不意味着该居民在任一时刻的出行行为都反映了夜间活动族群体的出行行为特征。如图5所示,本文提取了该居民于某工作日(3天,不连续)和某周末(2天,不连续)的活动模式,可以发现工作日该居民的出行行为十分符合3.3节对夜间活动族群体出行行为的总结规律,然而,他/她于周末的出行行为却更贴近居家人员群体。
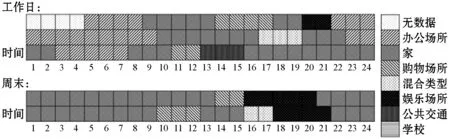
图5 波士顿某居民工作日/周末活动模式展示
由于个体自身的不确定性,导致个体出行行为所表征的出行规律在不同时间周期的表现均有所不同。Labeled-LDA模型能基于先验信息和样本信息,得到城市居民属于不同群体类别的后验概率分布,对个体出行行为的不确定性起到了一定的解释作用,能在一定程度上反映城市居民出行行为的复杂性。
4 结 语
本文提出一种基于Labeled-LDA的城市居民群体分类和出行特征分析框架。首先利用城市居民的海量Twitter签到数据,构建居民出行活动模式模型定量表征城市居民的日常出行行为;其次构建潜在狄利克雷分布模型LDA对城市居民进行探索性分类,针对分类结果提取典型城市居民群体的出行活动分布作为先验信息;最后,构建标签狄利克雷分布模型Labeled-LDA,将城市居民划分为居家人员、夜间活动族、大学生、上班族及中小学生五个群体,于群体维度分析城市居民的出行行为特征,并讨论个体出行行为的不确定性。
通过引入先验信息,Labeled-LDA模型能够有效完成城市居民在群体维度的出行行为特征分类,并定量解释居民群体的出行行为规律。以后验概率分布形式给出的Labeled-LDA模型群体分类结果,有效体现了个体出行行为的复杂性与不确定性,为城市居民在不同时间和地点表现出不同群体的出行行为特征提供了定量的数据支撑。
猜你喜欢
中国典型病例大全(2022年7期)2022-04-22
成都信息工程大学学报(2019年3期)2019-09-25
统计与决策(2019年6期)2019-04-22
自动化学报(2017年5期)2017-05-14
雷达学报(2017年6期)2017-03-26
新疆农垦经济(2016年5期)2016-12-01
中国诠释学(2016年0期)2016-05-17
探测与控制学报(2015年4期)2015-12-15
新疆大学学报(哲学社会科学版)(2015年1期)2015-10-13
吉林体育学院学报(2015年4期)2015-02-28
