
数据挖掘在学生行为管理中的应用研究
——以沈阳工程学院为例
2022-12-02 11:44胡俊宇
沈阳工程学院学报(社会科学版) 2022年4期
丁 静,胡俊宇,苗 鹤
(沈阳工程学院a.网络与计算中心;b.科技处;c.国际教育学院,辽宁 沈阳 110136)
随着数字校园建设的迅猛发展,学生行为有可能实现量化分析,特别是随着网络管理数据的不断增加,充分利用这些数据,从这些海量数据中利用已有的先进技术手段发现重要信息并将其运用到教学建设、学生管理中是非常必要的。如何从海量数据中挖掘出对学生行为及时干预、精细管理有用的信息,既是对学生工作者的挑战,也是利用新理念、新方法开展工作的新机遇。
一、研究对象与方法
1.指标体系构建
为客观准确地描述学生网络行为特征,结合沈阳工程学院学生使用网络的周期性,本研究通过数理统计方法构建校园网络行为指标体系,用于下一步网络行为特征的分类分析。
管理模式维度:上网总流量、总上网时长、上网类型、学分成绩作为行为管理模式的4 个维度。上网总量为一学期上网总量,由入流量、出流量决定;总上网时长为系统记录的一学期上网总时长,由每次上线时间、下线时间决定;上网类型为日志系统采集到的学生上网时在网络上所访问的类型;学分成绩为教务数据库可以采集到的学生成绩情况。
计费周期:沈阳工程学院网络管理系统的计费周期为按月计费,以每个学期月为统计周期,依据教学周期与校历截取8 月份到12 月份半学期流量情况。
2.数据清理
直接采集到的数据一般是不完整的、带有随机性的,并且伴有一定的噪声,我们在使用数据挖掘方法之前对数据进行了数据清洗。通过数据清洗,剔除部分无效数据和空缺数据,保留研究所需有用信息,进行下一步分析研究。
3.KNN算法
K 最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法。它是给定一个未知样本,k-最邻近分类法搜索模式空间,找出最接近未知样本的k个训练样本,然后使用k个最邻近者中最公共的类来预测当前样本的类标号。
KNN 方法的思路是:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN 算法中,所选择的训练样本都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。本研究所使用的是KNN算法。
二、研究结果
1.数据采集
本研究所采集的是沈阳工程学院自动化学院、经济与管理学院、能源与动力学院及电力学院2020 年级六个班级的180 条学生数据。这180 名同学学期内没有校外实习情况,网络使用情况相对稳定,代表使用人群比较广泛,更能反映学生在校园运用网络情况。
数据采集时间为2020年8月份至2020年12月份半学期。学生网络访问类型较多,其中校园网访问类型多为图书馆、网络教学平台、雨课堂、教务处选课系统等校内资源;外网访问类型多为QQ、百度、新浪、土豆网、迅雷、抖音、游戏等。通过访问类型可以了解到,学生在用校园网期间以使用校园网资源进行选课、查阅资料、下载应用软件和一些学习相关的材料为主,在利用互联网期间则以上网聊天、浏览微博、看电影、游戏等娱乐为主。
2.数据采集汇总分析
(1)结合学生学分情况,对180 个抽样数据半学期流量分析:通过对180 名抽样学生半学期的流量监控与统计和五个月上网时长的汇总,统计出每个学生半学期使用流量,通过流量趋势对学生学分合格情况进行对比,数据中可以观察到:学分不合格学生集中在流量20G 左右区间和40G 以上区间,特别是40G 流量以上区间内聚集了多数的学分不合格的学生。此分析说明流量较多的范围对区别学分是否合格能力较强。图1为180个抽样学生半学期流量与学分对应图。
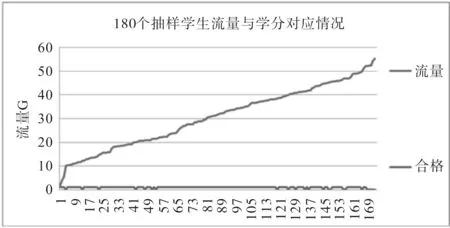
图1 180个抽样学生半学期流量与学分对应图
(2)结合学生学分情况,对180 个抽样数据半学期时长分析:通过对180 名抽样学生半学期的月份时长数据的监控与统计,对每个学生分别产生5个月的时长信息进行汇总,统计出每个学生半学期使用时长。通过时长趋势与学分合格情况对比可以观察到:学分不合格学生集中在使用时长400 小时左右区间和600 小时以上区间,其中不合格的学生主要集中在600 小时以上时长范围,说明总上网时长对区分学分是否合格能力较强。图2为180个抽样学生半学期时长与学分对应图。
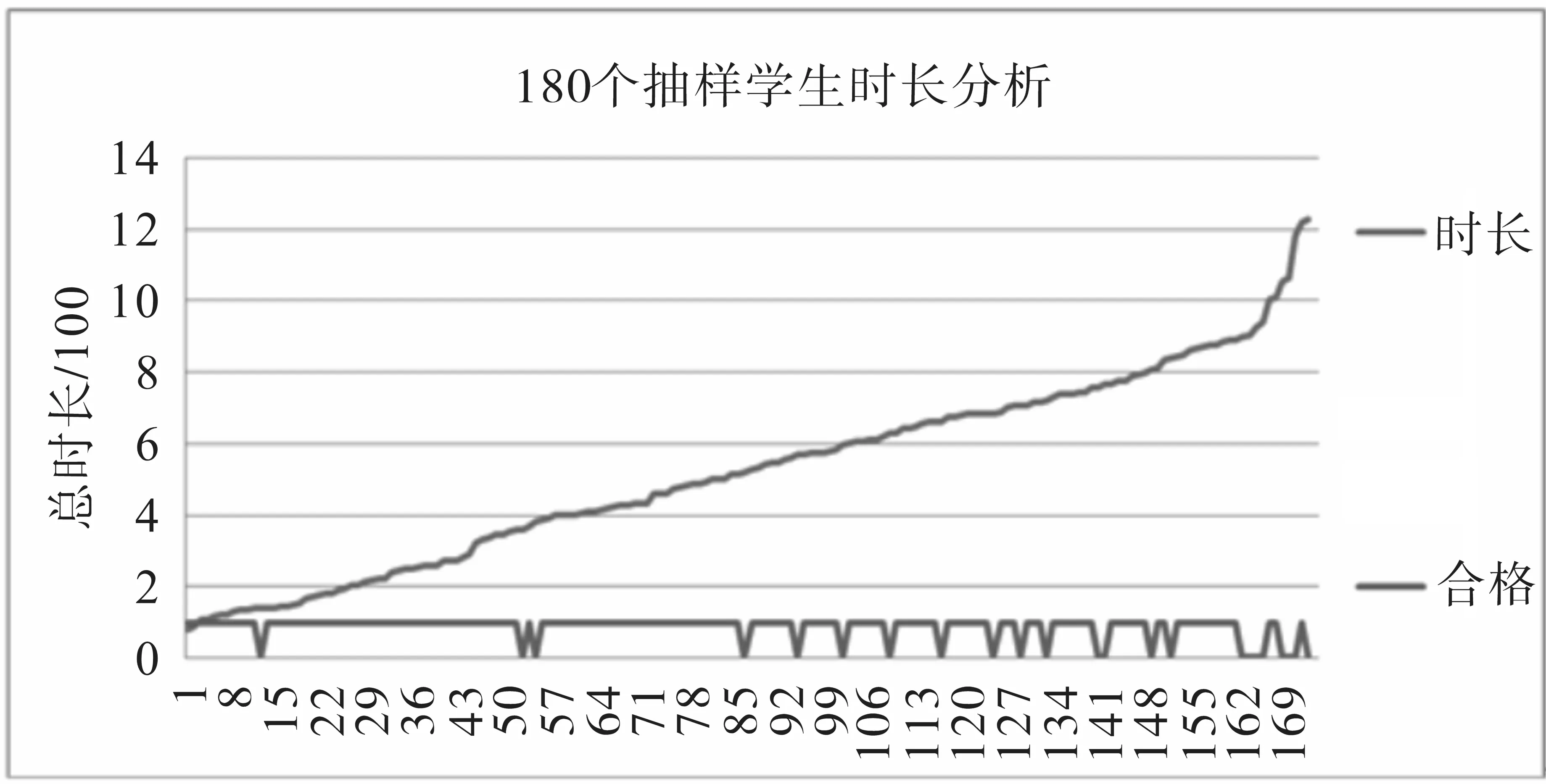
图2 180个抽样学生半学期时长与学分对应图
(3)结合学生学分情况进行分析。在流量与学分结合时,我们把学生分成合格与不合格两组进行统计,可以观察到:①不合格的学生在半学期流量值普遍高于全体学生的平均值及合格学生的半学期流量,说明异常使用流量可能与学分有着一定的关系。②流量趋势在整个半个学期呈现为不明显的“凸”型结构,从八月份开始流量逐渐增加,到十月份达到最大值,十一月份保持平稳,在十二月份降低到最小值。这说明学生八月开学到九月使用网络流量成逐渐增加状态,十月、十一月份成为半学期网络集中使用状态,而到了十二月份,由于临近期末,面临考试,进入低使用状态。图3为180个抽样学生半学期流量趋势图。
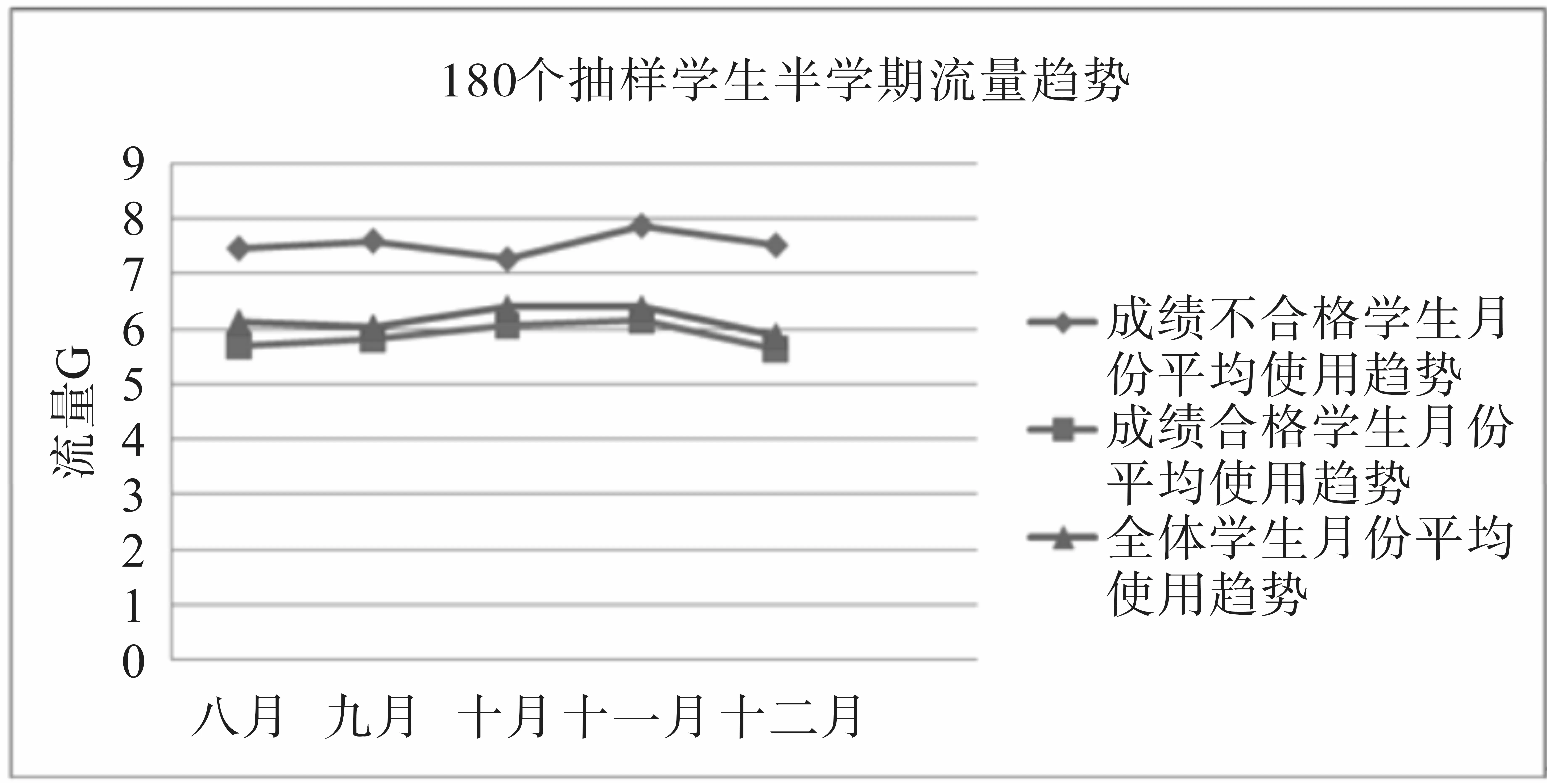
图3 180个抽样学生半学期流量趋势
(4)在时长与学分结合时,我们也把学生分成合格与不合格两组进行统计,可以观察到:①不合格的学生在半学期月平均时长高于全体学生的月平均值,说明时长使用也可能与学分有着一定的关系。②时长趋势在整个半个学期呈现状态为:八月份至十一月份逐渐增加,在十二月份有所回落。图4为180个抽样学生半学期时长趋势图。
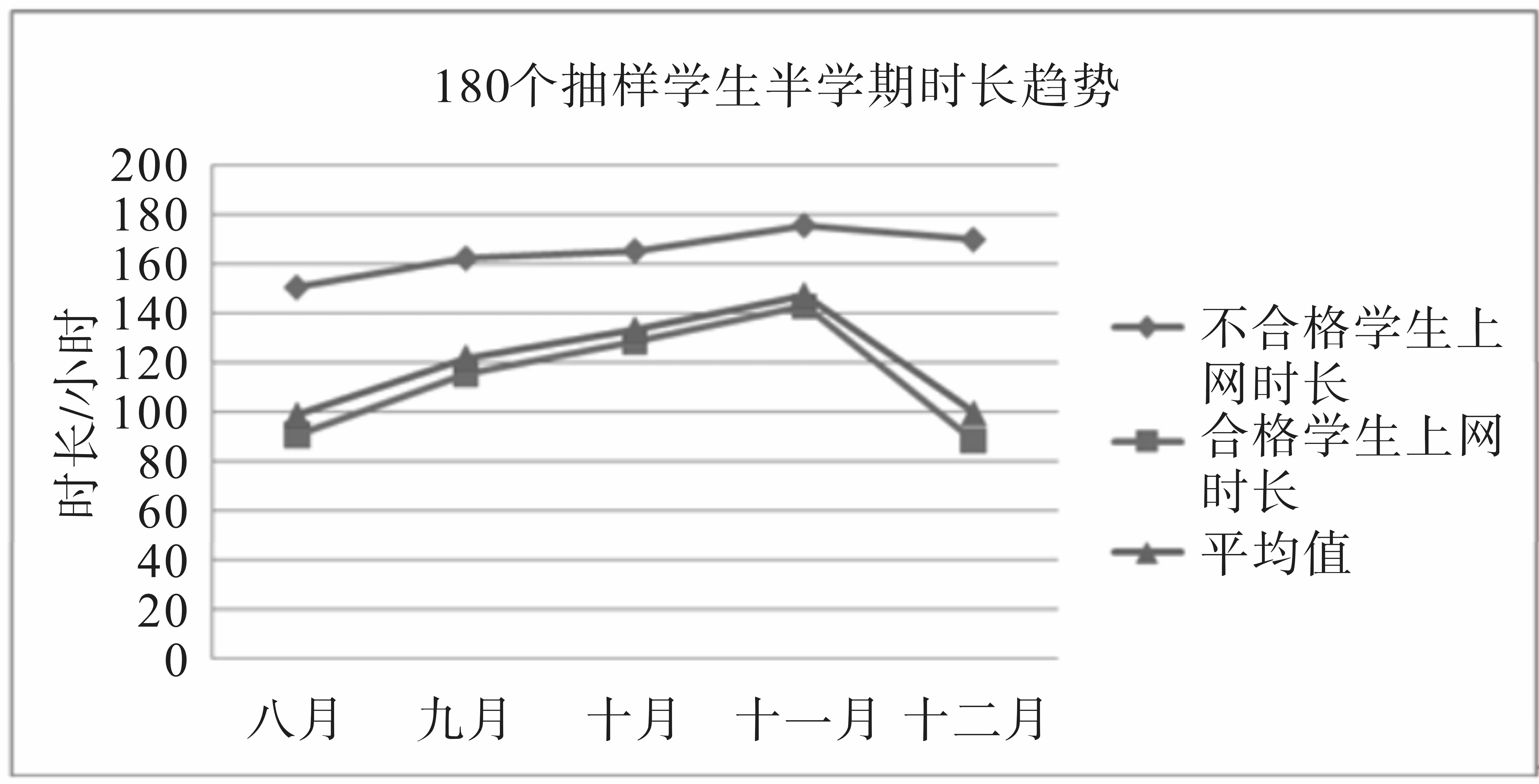
图4 180个抽样学生半学期时长趋势
3.数据内容
通过多方面采集,汇总出180 个样本学生的总体数据,其中有:
(1)学号。IMC 系统、教务数据库系统及日志系统中都采用学生学号来标识学生。
(2)班级。采集的六个班级:测控***、保险***、核工本***、建环***、建环***、电气***。
(3)组名。记录计算机所在位置,根据位置的不同组名有:上网组/学生宿舍网、上网组/教师办公、上网组/多媒体、上网组/独身公寓、上网组/其他;分别标识应用的位置:学生宿舍、教师办公室、图书馆多媒体、独身公寓宿舍、其他位置(科技园区、大学城宾馆、其他经营类位置)等。组名在类型数据采集中起到重要作用,监控学生时,通常多数采集在宿舍应用网络组里,如显示该用户在办公区域或其他区域上网时,有可能说明该学生正在利用网络上课或其他科研活动,将不作为一次应用类型记录。
(4)应用类型。学生上网经常使用类型。访问类型主要有http 下载、游戏、浏览网站、p2p 四个类型。
(5)最常使用应用。通过采集到的最常使用应用决定应用类型。这里把电影音乐网站、论坛、购物网站归为浏览网站类型,各种应用游戏归为游戏类型,应用p2p的产品归为p2p类型。
(6)上传/下载比。上传下载比例说明该学生网络流量的出入情况,该值比例较小时,说明学生利用网络下载的较多;当比例较大时,有可能出现学生非正常使用网络情况,特别是对于P2P 的技术播放软件的不正常利用,会导致学生在某几个月的网络流量很快用尽,这一比值需要与上网时长及总流量进行配合分析。
(7)时长。半学期的学生上网总时长合计,包括五个月的使用时长,以小时为单位记录。
(8)流量。半学期总流量合计,五个月流量总计,以千兆为单位记录。
(9)合格标志。学生本学期学分情况标识,其中0为不合格,1为合格。
通过上面的字段数据采集汇总表,这里对组名进行数字表示法,将上网组/教师办公、上网组/学生宿舍网、上网组/多媒体、上网组/独身公寓、上网组/其他,这五个位置分别用1|1、1|2、1|3、1|4、1|5 来表示。表1为数据采集汇总的部分数据。
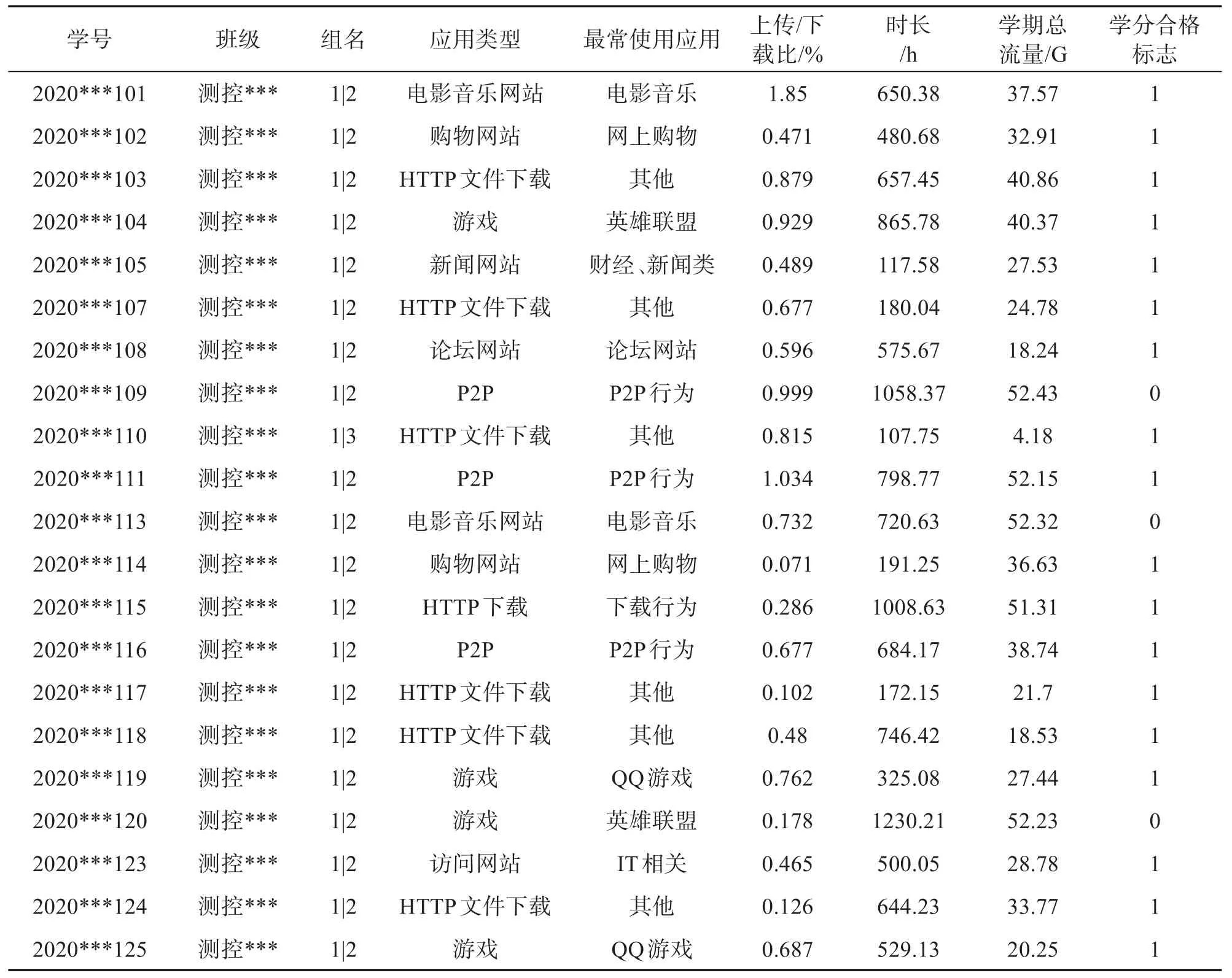
表1 数据采集汇总表(部分数据)
4.数据清理与转换
针对采集来的180 条数据,在进行分析之前要进行消除或减少噪声、填补空取值的数据清理工作。
(1)由于有少部分人没有接入互联网,只有成绩信息,并没有网络相关信息,当对这部分数据分析时会干扰产生的模型,这里将其进行删除,删除没有接入网络的学号有:2020***106,2020***112,2020***121,2020***122。
(2)空缺值的处理将有助于提高数据分类和预测的准确性,从而减少学习时的混乱。本文通过对采集的数据信息进行观察发现,有些学生由于休假等原因,在某天或某月没能上网,对于数据上的这种空缺采取人工填写的方法进行弥补,由于数据需要的连续性,决定填充的方法采用在该属性上最经常出现的值来填充此空缺的属性。
(3)在常用上网应用统计中,有些网址是系统无法识别的,做人工填写,统一填写成网站类型。基于距离数据挖掘中,当数据为非连续性属性时,将不能直接确定对象之间的距离,这时需要对数据进行转换,将其他属性类型转换成数值类型。为计算方便将流量以字节为单位转换为千兆为计算单位;上网时长以小时为单位转换成分钟为单位。
三、实验结果及分析
研究采用数据挖掘中基于距离的分类算法,分类步骤如下:
(1)将180 个抽样数据集组成训练集,由辅导员评定好、中、差三类标号,对数据加上类标号组成训练集。本文将上网总流量、总上网时长、上网类型、学分成绩作为系统的四个属性值。训练样本集为采集的180 个学生的数据,对这些数据进行整理,首先将数据中的非数值性属性进行数据转换,其中上网流量、上网时长及学分标识为数值型数据;其次将上网类型非连续性值进行转换。
(2)上网类型分为四类,http 类型赋值为1,网站类型赋值为2,p2p 类型赋值为3,游戏类型赋值为4。最后得出180 个训练集的样本,表2 为训练样本集部分数据。

表2 训练样本集(部分数据)
分类算法过程如下:
假设某半学期内一组学生上网行为个例样本集合定义为S。其中,S由i个学生样本组成,而每个学生样本由n个属性变量及1个标志量构成。其数学表示式为:

本文的属性变量xij分别代表上网总流量、总上网时长、上网类型、学分成绩4 个要素,最后一个要素Li称为标志量(Label),文中的标志量即为学生评定级别。利用KNN 算法进行网络行为预测可以描述为如下数学模型:假设上网总流量、总上网时长、上网类型、学分成绩4 个要素的集合为Yi={y1,y2,y3,…,yn},称为预测样本;预测时,首先在训练样本集S 集合中找到与预测样本Yi最相似的K 个近邻,然后找出这K 个标志量(评定级别)集合Li={L1,L2,L3,…,Ln},最后按照投票多数原则,选取最多的标志量Li作为预测样本Yi预测结果。
(3)本文的K 近邻居选取采用欧氏距离法进行判定,利用欧式距离计算测试集中的600 个测试集数据与训练集的距离,选取与每个测试数据最近的k个点,统计k个点里面所属分类比例最大的,确定所有测试集的所属分类,经过反复试验,本文选取k值为5。
(4)用测试集来预测模型准确性:180 条抽样数据全部作为训练集样本数,另选600 条清理后的数据作为测试集,采用通过的准确率和召回率对系统性能进行测试,准确率和召回率反映了分类质量的两个不同方面,两者要综合考虑,不能有所偏失,使用了两者的综合指标F-Score值,其数学公式为:
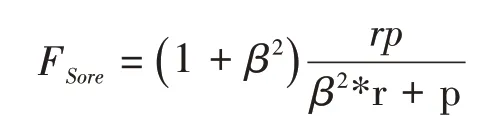
将β取值为1时,公式如下:

p表示精确率,r表示召回率;用上面的方法和数据进行训练和测试,表3为分类测试结果:

表3 分类测试结果
四、结语
本文在综合分析沈阳工程学院网络管理模式基础上,将基于数据挖掘技术的KNN 算法与学生上网行为模式相结合,实现学生上网异常行为预测方法,得到以下结论:①上网行为异常预测的KNN分类器属性特征由上网总流量、总上网时长、上网类型、学分成绩等4 个要素构成,标志量为评定等级;②根据2020 年下半学期所获得的数据的预测结果表明,异常预报准确率与精确率及召回率分别为73.79%,76.55%,80.62%,F-Score 值为78.53%,所获得结果均在可接受范围内,能够提供给学生管理者对异常网络行为学生进行干预。因此,科学使用数据挖掘的KNN 算法进行挖掘探索,合理挖掘开发,将有效提升学校的管理水平和科学决策能力。
猜你喜欢
少先队活动(2021年9期)2021-11-05
中学生数理化(高中版.高二数学)(2021年2期)2021-03-19
甘肃教育(2020年8期)2020-06-11
作文小学中年级(2018年5期)2018-06-11
数学小灵通(1-2年级)(2017年5期)2017-06-05
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
公民与法治(2016年10期)2016-05-17
大江南北(2016年8期)2016-02-27
郑州大学学报(医学版)(2015年1期)2015-02-27
当代修辞学(2014年1期)2014-01-21
