
基于Mask-RCNN的自然场景下油茶果目标识别与检测*
2022-12-02 06:03王梁侯义锋贺杰
中国农机化学报 2022年12期
王梁,侯义锋,贺杰
(梧州学院广西机器视觉与智能控制重点实验室,广西梧州,543003)
0 引言
由于油茶的营养价值丰富且具有保健防病的功能,因此被广大消费者喜爱,需求量也持续增加。据统计,在油茶的生产作业中,收获采摘约占整个作业量的40%~50%[1],机器人收获技术在油茶采摘中得到了大规模的应用,如何实现果实目标精准识别是机器人收获技术中需要重点解决的问题。
自然场景中影响果实目标识别精度的干扰因素主要分为环境因素和果实生长状态因素。环境因素对目标检测的主要影响包括自然光的强度,茎叶的遮挡;果实生长状态因素对目标检测的主要影响包括多果粘附的重叠、果实色泽度不均。
目前,水果目标检测的主要方法是基于结合机器视觉的机器学习算法。Zhao等[2-3]采用一种基于AdaBoost分类和颜色分析的算法进行对温室中的成熟番茄果实的目标识别检测,实现对成熟番茄果实的快速准确识别;He等[4]提出了一种基于改进的LDA分类器的绿色荔枝识别方法,有效的识别背景中的荔枝果实;李扬[5]提出一种K-means聚类算法与HSV颜色空间下阈值分割的柑橘图像分割算法,实现了柑橘目标的有效识别检测。
上述传统方法相比,深度神经网络(DNN)方法具有强大的特征提取能力和自主学习能力,已被广泛用于作物目标检测。闫建伟等[6]结合刺梨果实的特点,提出了一种基于改进的Faster RCNN刺梨果实识别方法,实现自然环境下刺梨果实的快速准确识别;Sun等[7]针对复杂背景、未成熟青番茄与植物颜色的高度相似性导致番茄识别有效率低的问题,提出了一种改进的基于卷积神经网络(CNN)的番茄器官检测方法,采用ResNet-50和K均值聚类方法改进了Faster R-CNN 模型,实验结果平均精度(mAP)明显的提高。
本文提出一种基于Mask-RCNN的自然场景下油茶果的果实目标精确识别方法,先利用Mask R-CNN网络进行图像分割,从像素级别的背景中提取对象区域,再求取果实对象mask的像素面积,求取界定阈值,依据阈值进行果实目标的识别,最后再根据mask图像的形状和边缘特征进行果实的轮廓拟合还原。
1 图像获取与数据库建立
1.1 图像样本的获取
2019年10月7—14日在中国广西壮族自治区桂林市资源县文垌村油茶果农场,分别在3号、5号、7号试验田进行油茶果图像的采集拍摄。利用Canon EOS 760D型号数码照相机,由人工采集白花油茶品种(出油率较红花高)的成熟期油茶果的图像信息(图1)。采集照片时相机的拍摄距离范围为0.5~1.5 m之间;光圈设置为F 5.6;焦距范围为f=18~135 mm;曝光时间为1/250 s[8]。照片的保存尺寸格式为像素值。根据前述拟解决的关键问题,按照树叶遮挡、果实重叠、不同背景、果实色度、光照等影响因素分为5个单因素样本组采集图像,每个图像包含一个影响因素的特征,每组采集500张照片[9]。另外,再取一个多因素样本组,每个图像包含若干单因素的特征,数量为500张。

(a) 不同遮挡率下的果实图像示例

(c) 不同果实色泽度的果实图像示例

(d) 不同光照影响下的果实图像示例
在单因素照片的采集过程中,树叶遮挡的情况按照遮挡率采集10%以下、10%~30%、30%~50%共3类照片[10],果实重叠的情况按照重叠率采集10%以下、10%~30%、30%~50%以上共3类照片[11],并综合考虑照片中有2个、3个以及3个以上果实的情况;背景的情况根据田间环境分为简单、正常和复杂三类背景[12];颜色根据鲜艳程度分为淡红(LR)、浅红(HR)、深红(DR)三类[13];光照程度的情况分别选取上午9~10时,中午12~13时,下午15~16时3个时段采集昏暗、正常、明亮三类照片[14]。多因素照片采集中,按照包含有2/3/4/5种单因素情况分类四类采集。
1.2 图像数据库的建立
数据库共选用有效图像样本3 000张,其中,1 800张用于建立训练模型集,1 200张用于验证模型集[15]。训练集又包含预训练集和优化训练集。用于模型参数预训练的共有600张图像样本,每个单因素和多因素各选择100张;用于模型参数优化训练的共有1 200张图像样本,每个单因素和多因素各选择200张。验证集的1 200个样本包括了每个单因素和多因素各200张,并且与训练集的样本相互独立。
对于训练集图像的标记方法,首先,按比例将图片大小统一调整为600像素×400像素,然后,利用labelme图像标注工具采用“多边形标注”方案标注出油茶果目标的所在区域,即为后续神经网络模型的训练集中待提取特征的预选区域。最后,根据分组类型,对每个组别的图片进行分类标记,得到每张果实图片的json文件,并利用python语言进行文件转化,将每个json文件分解成所标记的原图、灰度图像、类别名、掩膜区域、被标记区域的像素点位置等五个文件为提供给后续模型训练进行调用,如图2所示。

(a) 图像样本示例

(b) 掩膜样本示例
2 Mask R-CNN模型原理和方法
2.1 Mask-RCNN模型结构
Mask R-CNN通过在Faster R-CNN基础上增加一个额外的掩膜分支来扩展其目标检测框架,增加全连接层(RoIAlign)并重新定义ROI损失函数,从而改进得到的一种用于实例分割的深度学习神经网络。如图3所示,Mask R-CNN框架由3个阶段组成:(1)主干网络(ResNet),对输入图像进行特征提取,生成特征图(Feature Maps);(2)区域建议网络(RPN),对主干网络输出的特征图进行处理进一步生成感兴趣区域(RoIs);(3)三分支结构,生成检测目标的类别、回归框坐标以及掩膜。本文选择Mask R-CNN作为成熟油茶果目标检测网络结构,解决传统的图像阈值分割方法难以有效处理自然环境下各种干扰因素对果实识别结果影响的技术问题[16-17]。

图3 Mask R-CNN目标检测网络结构图
2.2 Mask R-CNN模型算法
主要模型算法分为以下5个部分。
1) 将所采集的果实图像进行卷积(CONV Layers)处理,使用ResNet卷积神经网络提取油茶果果实图片的特征,采用残差传播,生成特征图(Feature Maps)。
2) 采用RPN对所得到的特征图进行操作,产生ROIs,对每个候选区域进行目标框回归操作生成目标回归框并得到类别可能性大小。RPN对不同尺度的特征图进行卷积,在每个位置生成3个锚点(anchor),其中针对class生成3×4个卷积核(果实颜色3类和背景)。在卷积层后连接两个全链接层,完成每个像素的前景(目标)和后景(背景)的判别,以及果实目标框的回归修正。
3) 对每一个RPN得到的ROIs和特征图,进行RoIAlign操作,提取每个RoI对应的特征并将特征的维度转化成特定的值,将所有的特征全部输入到全连接层进行权值共享,得到所有RoI规整之后的特征图。
4) 将规整后的特征图分别导入Cls & Reg和Mask掩膜两条通路。其中,Cls & Reg通路包含两个支路,分别用于生成回归框和预测类别;Mask掩膜通路,以像素到像素的方式来对分割掩膜进行预测,该分支为卷积网络,用于生成Mask标记。
5) 输出三个输出结果:目标的类别、目标的回归框坐标以及目标的掩膜。
2.3 Mask R-CNN模型训练
模型训练主要分为预训练、迁移学习训练和验证训练三个阶段,如图4所示。
首先,采用ResNet神经网络对预训练集样本进行预训练,获得成熟果实特征提取器;然后,添加Mask分支和classifier分支,对优化训练集样本进行网络模型参数训练,经多次迭代训练和迁移学习调整,得到优化模型;最后,利用验证集样本对模型进行验证,并进一步调整模型。模型训练过程需要控制loss函数的收敛过程和训练集的识别效果两个关键环节,以及迭代的步长与次数、学习率和置信度等关键参数。
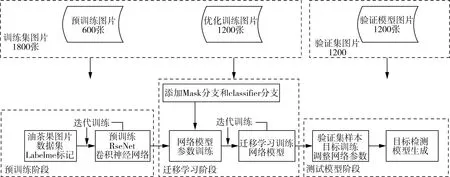
图4 Mask R-CNN目标检测网络模型训练示意图
具体训练步骤分为以下5个部分。
1) 加载预训练好的MS COCO模型参数。
2) 修改配置参数及分类参数。为了获取更快速和准确的训练结果,相关参数范围按照下列原则设置:类别数设定为4,包括果实目标类别3类和背景。图片像素设定为640×960;每张图片的ROI个数设定为100。学习率设定为10-4~10-2,每次训练的迭代步数epoch设定为50~200步,每次验证的迭代步数epoch设定为10~100步,迭代次数设定范围为50~200步。置信度检测设定为0.7~0.9;anchor大小设定为8×6,16×6,32×6,64×6,128×6等五类。
3) 基础网络层训练。在预训练阶段,所取特征的卷积神经网络可以设置不同的数量级网络层进行果实特征提取,本研究首先导入预训练集样本对ResNet 50、ResNet101和VGGNet三种不同的基础网络层进行训练,通过对loss函数的收敛过程的判断和比较分析,优选出一种适用的基础网络层进行后续特征提取。
4) 网络模型优化训练。调整并记录网络模型每次优化所选取的迭代步长与次数、学习率、positiveIoU(置信度)等参数,同时观测并记录模型的收敛下降速度和收敛程度。使用优化训练集样本进行油茶果果实目标检测模型的参数调整和模型优化,获取识别后被标记的果实目标检测图像。评估优化训练集果实目标检测的准确率、漏检率、误检率参数。
5) 网络模型参数调整。重复步骤(4)至模型达到理想的结果。模型的参数确定为训练的迭代步数epoch设定范围为100步,验证的迭代步数epoch设定范围为50步,迭代次数设定范围为100步;positiveIoU(置信度)设定为0.7;学习率设定为10-3。
2.4 Mask R-CNN模型损失函数
基于Mask R-CNN的成熟油茶果目标检测算法的训练损失函数Lfinal描述为
Lfinal=L({pi},{ti})+(Lcls+Lreg+Lmask)
(1)
该算法的核心是通过多任务的损失函数来计算ROIs(感兴趣区域)的输出结果。在RPN层中定义损失函数
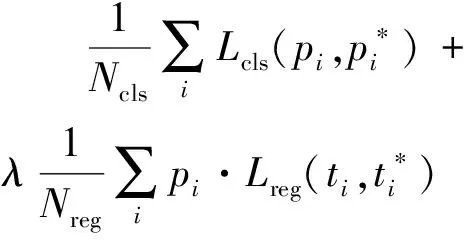
(2)
式中:λ——考虑分类与回归两个结果的权重值。
λ越大表示越重视回归损失,λ越小表示越重视分类损失。
在ROI区域上添加Mask掩膜层,其中classifier分类网络部分的损失函数
L=Lcls+Lreg+Lmask
(3)
Lcls为分类损失函数,表征目标的类别分类损失程度
(4)
式中:pi——候选区域含有目标的概率计算值;
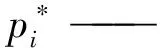
当期望值与真实值越接近时,此时损失函数最小。
Lreg为边框回归损失函数,表征目标的检测框坐标的损失程度,具体公式为
(5)
式中:ti——目标检测框的四个参数化构成的坐标向量计算值;
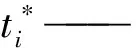
R——鲁棒损失函数。
边框回归损失函数中四个坐标参数化表示公式如式(6)所示。
(6)
其中,x,y,ω,h分别表示目标检测框的中心点坐标和高宽,x,xa,x*分别表示目标检测框计算值、anchor框、目标检测框期望值的x坐标(y,ω,h同理)。
R鲁棒损失函数
(7)
Lmask掩膜损失函数
Lmask=[Km2]i
(8)
式中:m2——掩膜分支对每个ROIs(感兴趣区域)产生的m×m大小的掩膜;
i——当前ROIs(感兴趣区域)的类别;
K——当前图片下果实的类别数目。
如图5所示,表征了基于Mask R-CNN的目标检测算法的模型训练结果。可以看出,整个模型各阶段loss函数均达到收敛,且损失值达到预定阈值0.3以下后无振荡出现,表明整体网络模型训练已经达到参数最优。

图5 神网络模型各阶段损失函数的 loss值收敛过程
3 试验结果与分析
该试验是在TensorFlow和Keras的深度学习开发框架下进行的,采用Intel酷睿i7-7820X型号CPU,显卡RX2080TI,主频2.9 GHz,16 GB内存,GPU为RTX2080Ti型号的硬件平台。在实验过程中,共选择了3 000张油茶果图像进行训练,其中80%为训练集,20%为验证集。为了验证训练模型的稳定性和可靠性,选择了1 800张油茶测试图像进行模型评估,检测识别出油茶果图像中果实目标,并且用目标类别分数、边界框和实例分割模板进行标记。
3.1 油茶果目标检测评估
重叠系数OC用于评估目标检测结果的准确性。重叠系数表示在目标边界框中被正确检测为目标或背景的像素占实际目标或背景像素的比率。
OC值越高,检测性能越好。本文设定当重叠系数为0.9以上,则认为目标检测结果正确。如图6所示,表示重叠系数为0.9以上正确检测的目标。其中,表1列出了目标检测模型对1 800个图像样本的识别结果混淆矩阵。

图6 重叠系数为0.9以上正确检测的目标

表1 目标检测模型的识别结果混淆矩阵Tab. 1 Recognition result confusion matrix of target detection model
表1中,在第一行和第一列分别表示预测类别与实际类别,不同行列组成的数值表示预测类别与实际类别对应关系的数量,如果预测类别与实际类别相同,则表示正确检测;否则,表示错误检出。
基于Mask R-CNN的目标检测模型的检测性能实例效果如图7所示。其中,图7(a)表示在不同类别LR、DR的果实正确检测;图7(b)表示在花叶遮挡影响下的果实正确检测;图7(c)表示在果实重叠影响下的果实正确检测。
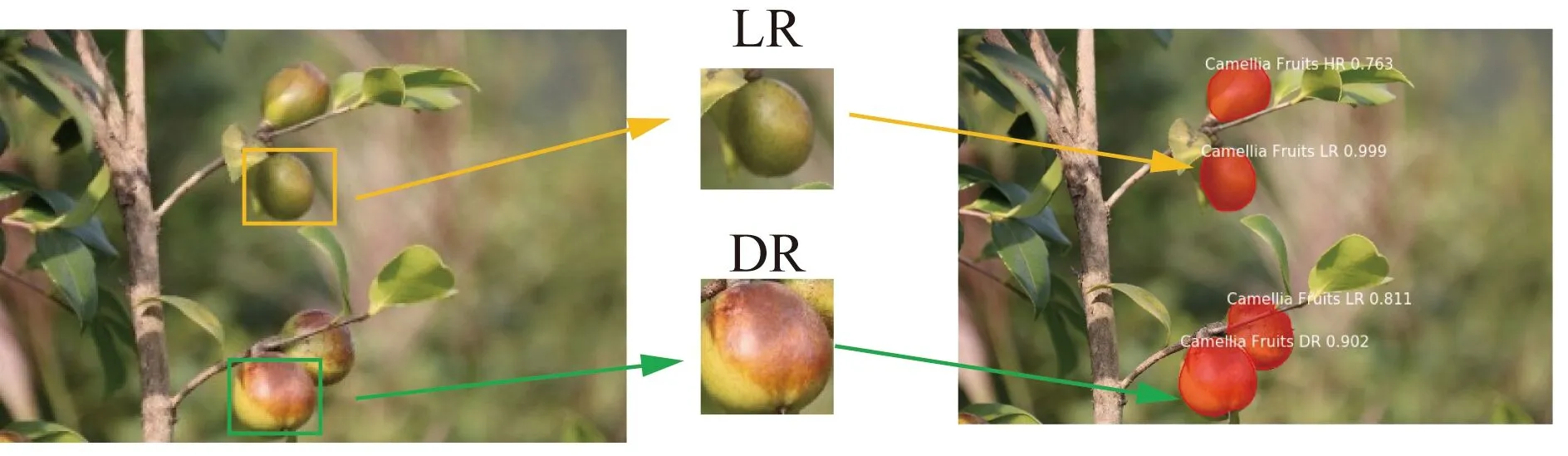
(a) 在不同类别LR、DR的果实正确检测

(b) 花叶遮挡影响下的果实正确检测

(c) 果实重叠影响下的果实正确检测
在此试验过程中,采用精确率P和召回率R作为评估模型的目标检测性能的指标。精确率表示在图片中被正确分类检测目标占实际目标的比率。召回率表示图片中被识别出目标占实际目标的比率[18-19]。
表2列出了对于1 800张验证集图像目标检测模型的详细结果,可以看到,总体准确性和召回率分别为89.42%和92.86%,表明油茶果识别精度较高。
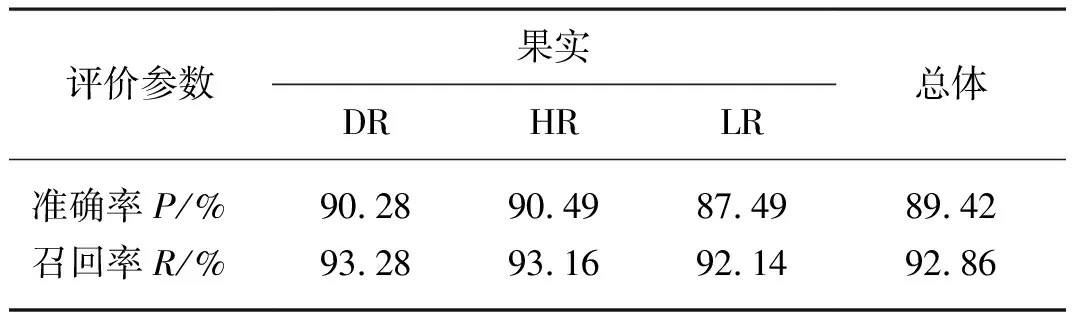
表2 目标检测模型检测结果的准确性和召回率Tab. 2 Accuracy and recall of object detection model detection results
3.2 油茶果实例分割评估
在图像分割领域,MIoU是经常用于评估图像分割性能的重要指标。对1 800张验证集图像的分割结果表明,油茶果的MIoU可以达到89.85%,可以满足油茶果实例分割的需要。油茶果图像的分割实例如图8所示。其中,图8(a)表示在多果实重叠影响下的图像分割;图8(b) 表示在不同花叶遮挡比例影响下的图像分割。
在对油茶果图像进行有效分割后,可以从Mask R-CNN生成的mask图像的形状和边缘特征来实现果实的轮廓拟合还原。油茶果果实识别与轮廓拟合效果实例如图9所示。

(a) 多果实重叠影响下的图像分割

(b) 不同花叶遮挡比例影响下的图像分割

图9 油茶果图像的果实识别与轮廓拟合
3.3 油茶果目标识别结果分析
目标识别精度采用三个元素指标,分别是TP:果实被正确检测到的数目;FN:果实未被检测到的数目;FP:被误检为果实的数目。
评估模型的目标检测性能的指标分为以下3类。
(9)
(10)
(11)
式中:TPR——识别有效率;
FPR——误检率;
P——精确率。
进一步,对验证组样本集图片的实验结果进行分组统计,分组原则与训练集相同,即分为花叶遮挡、果实重叠遮挡、果实成熟度色泽和光照影响4类单因素图片集和无控制组。总体图片样本分组统计的检测结果如表3所示。
由表3可以看到,对各组单因素、多因素情况下的识别效果,TPR均在86%左右,P值均在90%左右;对于所有单因素组的果实目标识别有效率(TPR)均高于92%,对于花叶遮挡、果实重叠、色泽度这三类单一因素干扰,FPR均能有效控制在10%左右,达到了较好的目标检测效果。因此,可以得出训练后的模型能够准确获取图像中果实目标类别、目标像素点坐标以及目标掩膜图像,并且有效克服遮挡、重叠等干扰因素,进行目标特征提取和图像分割。
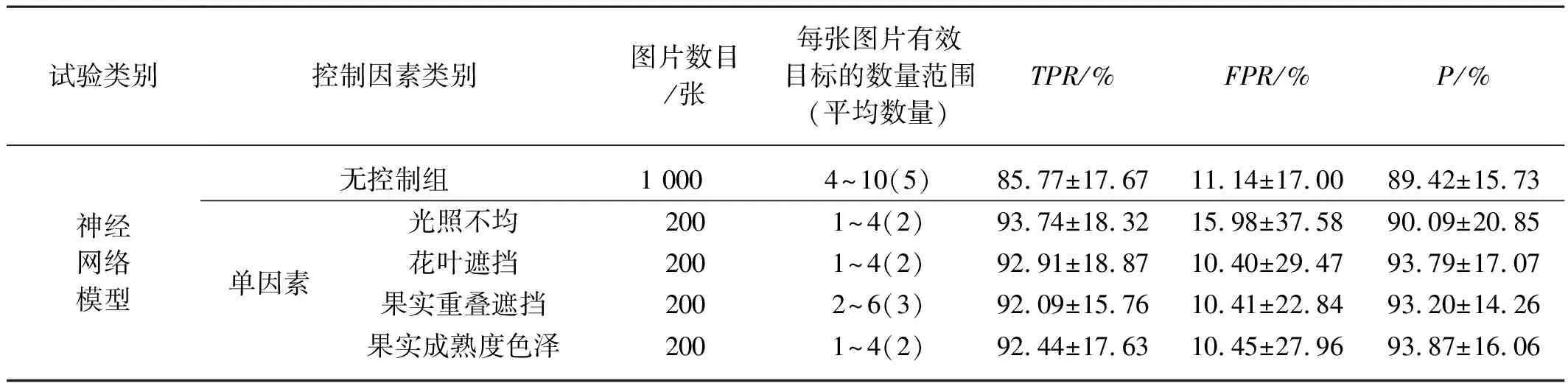
表3 分组统计后验证组样本集图片的试验结果Tab. 3 Experimental results of the pictures of the sample set of the validation group after grouping statistics
4 结论
本文以自然环境下的油茶果为研究对象,对图像采集设备视野范围内的油茶果进行图像处理, 提出一种应用于机器人收获技术的果实目标精确识别方法,解决自然环境下油茶果果实目标识别精度低的问题,有效降低不同光照情况下叶片与花苞遮挡、果实重叠、果实色泽等因素干扰,提高目标识别精度。研究工作主要包括两个部分:提出一个用于深度学习卷积神经网络模型训练的样本库和一个基于Mask R-CNN的油茶果果实目标精确识别方法。
1) 建立了一个包含3 400幅有效图像的深度学习卷积神经网络模型训练样本库,该样本库由预训练集、优化训练集和验证集组成,每个数据集包含4个单因素样本组,分别为花叶遮挡、果实重叠、果实颜色和光照不均匀性;多因素样本组,包含有2/3/4种单因素情况组合以及无控制样本组。
2) 研究了一种可以自动检测成熟和未成熟油茶果的Mask R-CNN模型,并从该模型输出了油茶果的mask图像。1 800张测试图像的果实检测结果表明,平均检测精度,召回率和MIoU率分别为89.42%,92.86%和89.85%。经过训练的模型对油茶果果实的图像检测,能够有效降低图像中的光强度变化,多果附着,重叠,遮挡和其他复杂的生长状态对识别精度的影响。与传统的果实检测算法相比,该模型具有更好的通用性和稳定性,能够克服传统机器视觉算法在油茶果果实检测中准确率低和鲁棒性差的难题。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
电子技术与软件工程(2021年5期)2021-06-16
民族古籍研究(2018年1期)2018-05-21
电子技术与软件工程(2018年5期)2018-04-09
现代园艺(2017年13期)2018-01-19
现代园艺(2017年21期)2018-01-03
现代园艺(2017年21期)2018-01-03
制造技术与机床(2017年10期)2017-11-28
中国西部(2017年4期)2017-04-26
西夏学(2016年2期)2016-10-26
