
可穿戴设备部署位置对羊只行为识别的影响与分析*
2022-12-02 06:03曹丽桃程曼袁洪波刘月琴随海燕赵晓霞
中国农机化学报 2022年12期
曹丽桃,程曼,袁洪波,刘月琴,随海燕,赵晓霞
(1. 河北农业大学机电工程学院,河北保定,071000; 2. 河北农业大学动物科技学院,河北保定,071000)
0 引言
羊养殖业是畜牧业的重要组成部分,截至2020年,中国羊出栏量已经达到了31 941.3万只,养殖方式已经过渡到规模化[1]和集约化[2]方式为主。伴随着规模化养殖的发展,养殖密度上升易使羊只处于不健康或亚健康状态,如跛行[3-4]、拉稀等疾病的发病率呈现出直线上升的趋势[5],同时也增加了人畜共患病的风险。羊只行为状态能够直接反映其健康状况,因此对羊只行为的监测与识别是保护动物福利[6]亟待解决的关键问题之一。传统的监测方式主要依赖人工饲养员的直觉和经验来判断,工作效率低下,不适合规模化的养殖场。
当前对于动物行为的自动化监测方法大致可以分为两类:基于机器视觉方法和基于可穿戴装备方法。机器视觉方法[7]可以通过对图像或视频的处理识别动物行为。利用机器视觉监测动物行为是一种非接触方式,能够避免动物出现应激反应。但是随着养殖规模的不断扩大,养殖密度也随之上升,对于密度较大的圈养情况,动物体之间经常出现相互遮挡现象,难以准确的定位和跟踪某一特定个体;此外这种方式也容易收到光照等因素的影响[8]。可穿戴装备[9-11]一般利用RFID技术 、声音识别技术和位姿传感器[12-14]感知和识别动物的行为,该方法属于一种弱接触方式,动物出现应激反应不强烈,能够满足连续和实时的监测要求。RFID技术一般以标签的形式附着在动物的身上,可以实现多标签的识别,但是由于羊天性好动,标签掉落的现象时有发生;利用声音识别技术[15]一般是将录音笔或者麦克风捆绑在嘴巴附近的缰绳上[16],来采集动物的声音信息[17]。但对于群养的动物来说难以获得独立个体的声音,并且该方法对于音频质量要求比较高。加速度传感器是在动物行为检测中使用较多的一种位姿传感器,它可以嵌入可穿戴设备中获取多个维度的传感器信息,实现动物行为的实时检测和分类[18-20]。
利用可穿戴设备可以实时监测并反馈动物行为,为高效健康养殖提供数据参考。但是对于不同物种的不同行为进行监测时,传感器部署位置存在较大差异[21]。为了明确可穿戴设备用于羊只行为监测时的最优部署位置,本文构建了一套基于三轴加速度传感器的可穿戴行为监测装置用于识别羊只静止、行走和饮食三种行为,并对传感器的不同部署位置对识别结果的影响进行了对比试验和分析。
1 材料与方法
1.1 试验环境及条件
试验于2021年2月5日—5月7日在河北省衡水市武邑县韩庄镇志豪畜牧科技有限公司种羊养殖基地进行。试验选择12只体况基本一致,健康无病、月龄6个月左右的小尾寒羊作为试验对象,其中10只作为试验组,2只作为对照组,对照组用于验证佩戴行为监测装置是否会对小尾寒羊的日常行为产生影响。试验过程中每天07:30~08:00和14:30~15:00分别进行一次饲料和饮水的供给。试验全程利用视频监测设备同步记录羊只的行为信息,根据行为发生的时间与传感器采集的数据的时间标签进行对照以验证行为识别效果。
1.2 羊只行为监测装置构建
可穿戴式羊只行为监测装置由电源模块、充电控制模块、传感器模块和433无线传输模块组成,如图1所示。电源模块为锂电池,电压3.7~5 V,容量3 200 mAh。传感器模块的核心为MPU9250传感器,它集成了3轴陀螺仪、3轴加速度计和3轴磁力计,是检测羊只行为的核心部件。传感器采集的数据通过无线传输模块,以433 MHZ的频率发送到后台计算机进行存储。所有模板集成在一个长宽高58 mm×51 mm×33 mm 的盒子中,可以利用绑带固定在羊只躯体上。


(a) 可穿戴装置外观 (b) 可穿戴装置内部构成
1.3 试验数据采集
用于羊只行为监测时,传感器可以部署在头颈、躯干或腿部[22]。因此为了寻找最优的位置,结合传感器部署的方便程度,试验时将传感器分别部署在颈部(NE)、背部靠近前腿处(BL)、前腿(FL)和后腿(HL)四个部位[23]。如图2所示,X、Y、Z代表传感器所在坐标系的坐标轴方向。试验共分4轮进行,以测试传感器处于不同位置时的识别效果,每一轮中10只羊均在相同位置佩戴传感器。
试验目的为根据传感器采集的信息对羊只静止、行走和饮食三种行为进行识别和监测,传感器将羊只的日常运动行为以数据的形式表征出来,传感器监测的信号包括三维的重力加速度、三维的角速度、三维的角度、三维的磁场、温度等数据。对于静止、行走、饮食三种行为这12维的数据之间存在不同,因此可以利用采集的羊只的运动行为数据来区分这三种行为。
表1所示为三种行为的定义。由于羊只佩戴行为监测装置会有适应期(NE和BL的适应期为24 h,FL和HL的适应期为36 h)[24],所以适应期内不采集数据。为了保证试验数据的丰富性和全面性,每轮试验中,确保每只羊的每种行为时间出现时长不低于2 h。


(a) NE (b) BL


(c) FL (d) HL

表1 羊只日常行为分类Tab. 1 Daily behavior classification of sheep
动物的行为都是一系列不同姿态的组合,即行为是一个动态和持续的动作表现。因此对某一行为的判定需要考虑行为特征的完整性和冗余度[25],这就要求利用一个短暂其持续时间内的全部信号进行分析。在试验过程中,当羊只行为持续时间为1 s时,数据的冗余度不高,而且行为特征数据质量良好,因此以1 s作为一个时间单元,在一个时间单元内,传感器共采集10组数据,这10组数据被称为一个基础数据单元(BDU)。由于存在丢包的现象,部分数据单元中不足10组数据。
针对静止、行走、饮食3种行为,共选取并标记了BDU共71 594个,其中NE选取了18 285个、BL选取了16 987个、FL选取了17 279、HL选取了19 043个,数据样本的具体分布如表2所示。试验时从每个部位的每一类行为中随机选取80%作为识别算法的训练样本,其余20%作为测试样本。

表2 羊只行为识别试验数据样本分布Tab. 2 Sample distribution of sheep behavior recognition test data
1.4 数据预处理
1.4.1 数据去噪
传感器在采集数据时,会受到各种干扰因素的影响,如周围环境、羊只的呼吸和打斗等。这些干扰因素会产生很多噪声数据,如果不进行滤波,则噪声数据将对分析结果的准确性造成一定的负面影响。本文采用小波降噪对原始数据进行第一次处理,原始数据经过小波变换后被分解为含有较大小波系数的有用信号和较小小波系数的噪声信号,利用合适的阈值进行低通滤波后噪声信号被过滤。小波降噪的具体步骤如下所示。
1) 选择小波基函数并确定分解的层次。本文中选择sym7作为小波基函数,分解层次为3层。
2) 确定小波系数,即滤波的阈值进行滤波。本文采用Bayes Shrink阈值法,即利用Bayes估计自动分割阈值。
3) 进行信号的小波重构,即对滤波后的信号进行小波逆变换。
1.4.2 特征降维
原始传感器数据经过小波降噪后虽然过滤掉了大部分的噪声,但仍然是一种包含了三个方向的加速度(ax、ay、az)、角速度(wx、wy、wz)、角度(Anglex、Angley、Anglez)和磁场(hx、hy、hz)信息的共计12维信号。为了准确地分辨出羊只不同的行为,需要对这些信号进行特征降维,因为高维度的特征会降低识别的效率,还会出现“过训练”的现象。因此,滤波后的数据需要进行第二次处理,利用主成分分析进行特征降维。主成分分析就是将多维的特征按照相应的比例重新组合在一起,凸显有效维度并降低干扰因子。主成分分析具体步骤如下。
1) 对本试验中12维的数据进行中心化处理。利用试验中的12维数据生成原始矩阵X,然后将利用公式(1)计算得到X中每一维数据减去该维均值后得到的新矩阵X′。
(1)
式中:xi——矩阵X中12维的样本;
m——矩阵X的样本数量;
j——随机数,取值范围为(0,m]。
2) 利用中心化处理后的新矩阵X′,通过式(2)计算协方差矩阵
(2)
3) 计算C的特征值,对特征值按从大到小进行排序,并取前k个特征值所对应的特征向量组成矩阵w。k的取值可以通过式(3)得到
(3)
式中:n——特征值个数;
k——所取特征值个数,k的取值范围为[1,n];
λi——第i个特征值;
t——主成分的比重阈值,取值范围为(0,1],本文t的取值为0.9。
可以根据式(3)计算出k值,在本试验中k取8。
4) 根据式(4)得到降维后的数据样本集D。此时经过预处理之后的数据样本集D就变成了8维,达到降维的目的。
D=WTxi
(4)
1.5 数据分析方法
1.5.1 基于k-means均值聚类算法的羊只行为识别方法
k-means均值聚类算法是一种无监督学习算法[26],它通过将数据集划分成不同的类别,使得每个类别内数据更加紧凑,不同类别间数据更加独立,从而实现聚类[27]。本文利用MATLAB编写k-means均值聚类算法的程序,具体试验步骤如下。
1) 选取初始聚类中心。本文识别的羊只行为共有3种,所以聚类中心数量k=3,静止、行走和饮食的初始聚类中心分别为c1、c2和c3。
2) 依据最小距离原则对试验数据进行分类。所谓的最小距离是指任意一个样本数据到3个初始聚类中心的欧式距离,如式(5)所示。

(5)
3) 计算每个类别中,每个数据到聚类中心的距离平均值。
4) 变更聚类中心位置,重复步骤(2)和(3),直到最大迭代次数,或者聚类中心位置不再改变,在本试验中最大迭代次数设置为20次。
1.5.2 基于支持向量机的羊只行为识别方法
支持向量机(Suppor Vectpor Mchine, SVM)是种机器学习算法[28-30],它通过建立一个超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化,从而实现分类的目的。本试验利用MATLAB LibSVM工具箱实现基于SVM的羊只行为识别,该算法支持的是二分类,因此本文需要构造多个二分类器。试验步骤如下所示。
1) 对试验数据进行归一化处理,将原始数据归一化到区间[0,1],归一化方法如式(6)所示。
(6)
式中:x——任意一个原始数据;
y——归一化数据;
xmin、xmax——原始数据中最小和最大值。
2) 根据式(7)确定高斯核函数。
(7)
式中: sgn(x)——符号函数,若x≥1则sgn(x)=1,若x<1则sgn(x)=-1;
w——权值向量;
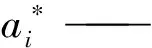
xi——随机样本数据;
yi——归一化后的数据;
b*——分类的阈值,由式(8)确定的约束条件可以得到。
ai[yi(wxi+b*)-1]=0
(8)
将归一化后的数据代入以上述核函数为中心的模型中得出f(x)的值,如式(9)所示。

(9)
当f(x)=1时,表示xi为支持向量;当f(x)=-1时,则表示xi为不支持该平面的向量。根据支持向量,可以将数据进行分类。SVM算法支持的是二分类,因此本文构造多个二分类器进行羊只三种行为的识别。
2 结果与分析
2.1 数据预处理结果
2.1.1 滤波结果
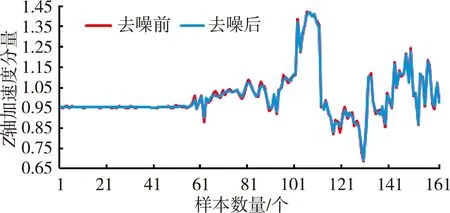
滤波操作可以去掉噪声的干扰,图3所示为滤波前后效果对比。图3中显示的为从10只试验对象中随机选取的一只羊的一部分随机数据,该数据为传感器部署在NE位置时采集的一段信息,包括6个静止的BDU,6个行走的BDU,5个饮食的BDU。

(a) X轴加速度分量去噪前后对比图

(b) Y轴加速度分量去噪前后对比图
(c) Z轴加速度分量去噪前后对比图
从图3中可以看出加速度的噪声分量在X轴和Z轴比Y轴多,滤波后比滤波前曲线更平滑,加速度分量的变化趋势更明显。
2.1.2 降维结果
试验采集数据时,为了让行为特征更加全面通常采集多维数据以增加信息多样性。数据降维的目的是凸显主要特征的影响,提高数据处理效率。主成分分析的实质是将试验过程中采集的12维数据以组合变量的形式进行表达,然后提取累计贡献率较高的组合。
本试验中共提取了8个主成分,这8个主成分的累计贡献率超过了90%,图4所示为8个主成分的累计贡献比较图,表3所示为成分矩阵。

图4 8个主成分累计贡献比较图

表3 成分矩阵Tab. 3 Component matrix
2.2 k-means分类结果
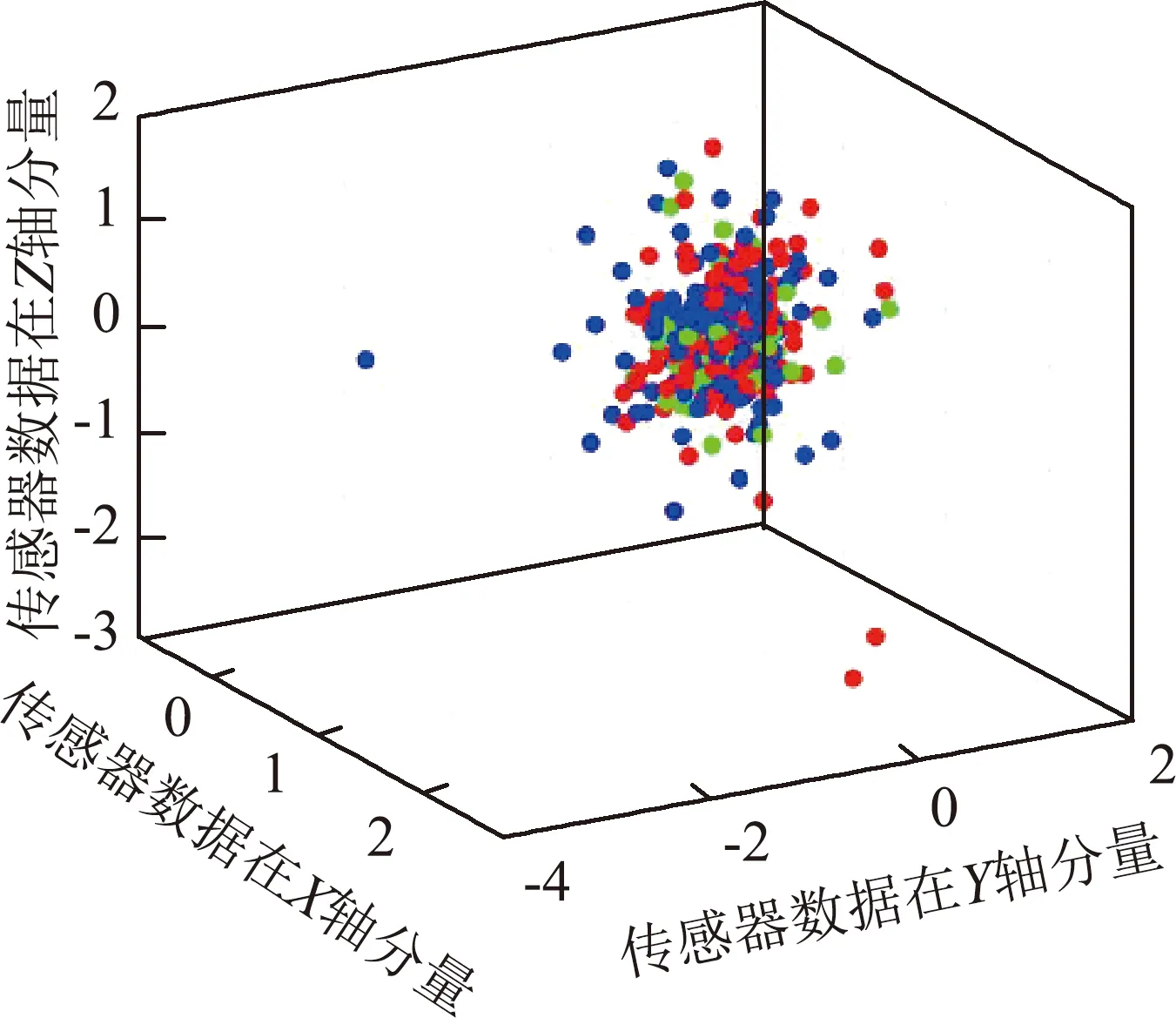
本试验利用MATLAB编写的k-means均值聚类算法程序,对小尾寒羊的静止、行走、饮食3种行为进行聚类。测试集样本数据的反复迭代训练20次,最终得到相对稳定的聚类中心,如图5所示。图5中,绿色、红色和蓝色点分别代表行走、静止和进食三种行为。从图5中可以看出,这3种行为的聚类效果不佳,多点堆叠在一起,没有明确的界限。
图6为测试集利用k-mean聚类模型识别和分类的混淆矩阵。传感器部署在NE位置处,羊只三种行为的识别准确率最高,其中静止、行走和进食的识别率分别为67.34%,90.4%和80.29%。传感器部署在FL位置处,羊只三种行为的识别准确率最低,其中静止、行走和进食的识别率分别为40.8%,9.95%和50.07%。从测试结果看,k-means均值聚类算法对于3种行为的区分效果不是很好,四个部署位置的平均识别率为58%。

(a) NE

(b) BL
(c) FL
(d) HL
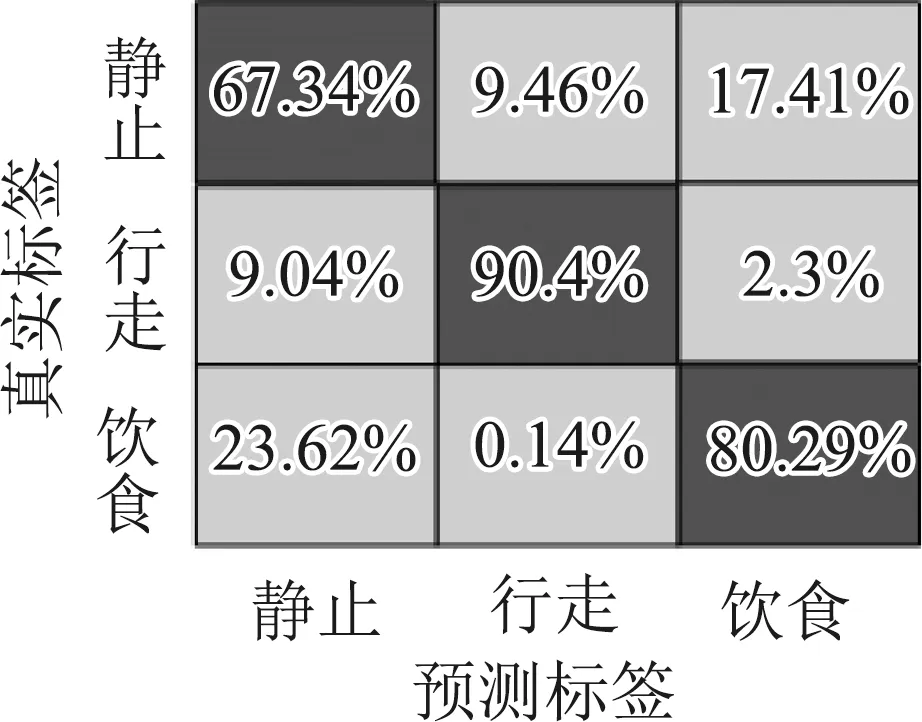

(a) NE混淆矩阵 (b) BL混淆矩阵


(c) FL混淆矩阵 (d) HL混淆矩阵
2.3 SVM分类结果
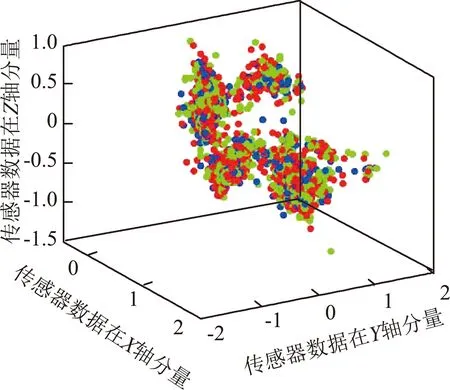
图7为测试集利用SVM分类模型识别和分类的混淆矩阵。传感器部署在NE位置处,羊只三种行为的识别准确率最高,其中静止、行走和进食的识别率分别为89.5%,91.1%和97.3%。传感器部署在FL位置处,羊只三种行为的识别准确率最低,其中静止、行走和进食的识别率分别为73.14%,71.63%和58%。从测试结果看,SVM支持向量机算法对于3种行为的区分效果较好,4个部位的平均识别准确率为75.85%。
利用SVM模型对测试集进行识别的结果如图8所示。图8中,绿色、红色和蓝色点分别代表行走、静止和进食三种行为。从图8中可以看出,羊只三种行为的分类效果较好,正确分类数量较多。
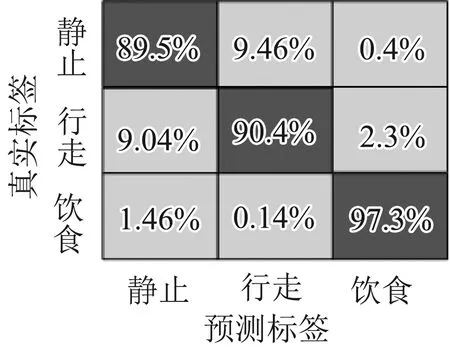
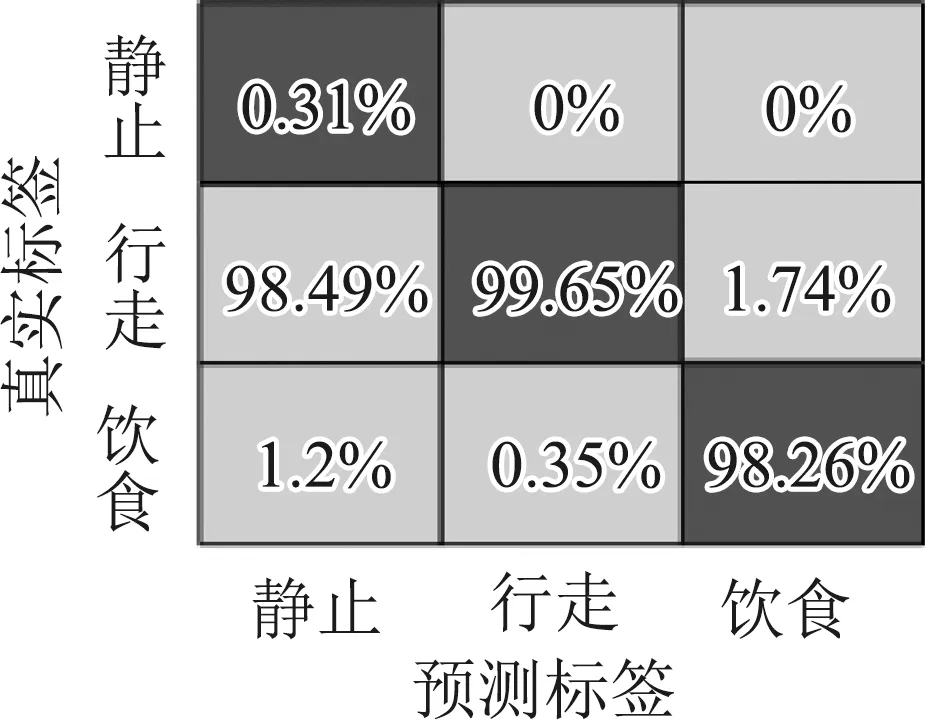
(a) NE混淆矩阵 (b) BL混淆矩阵

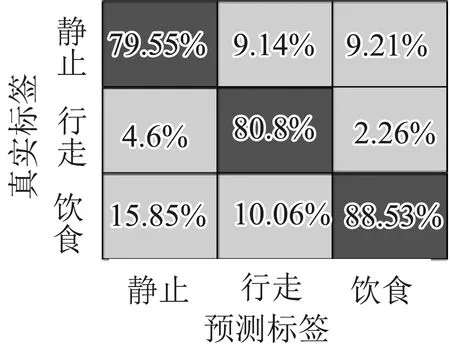
(c) FL混淆矩阵 (d) HL混淆矩阵

(a) NE

(b) BL
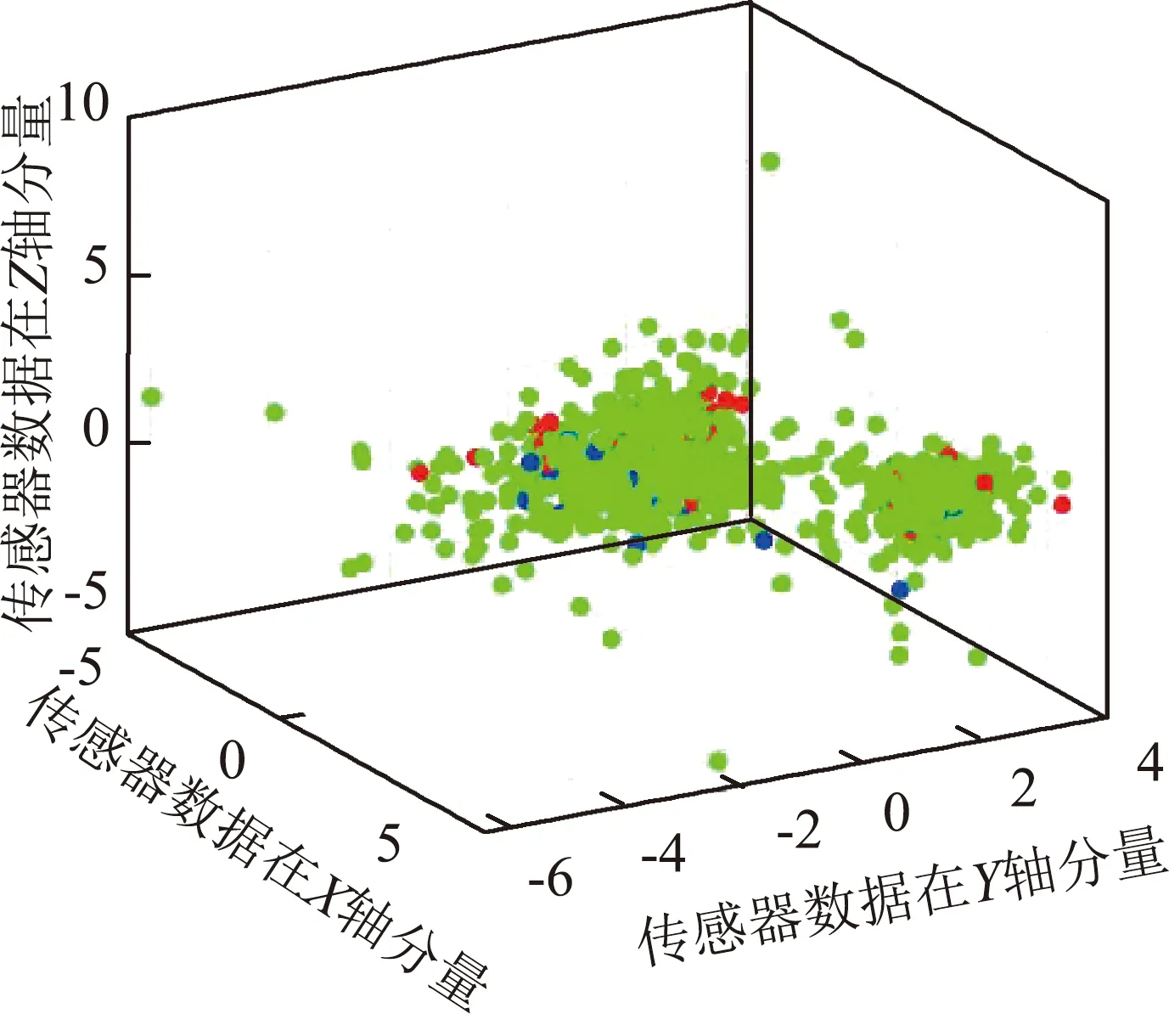
(c) FL

(d) HL
3 讨论
3.1 数据预处理前后对比
试验中采集是数据在预处理过程中分别经过了去噪和降维,表4所示为利用SVM算法对预处理前后测试数据进行识别的结果对比。从表4中可以看出,在不同的部署位置获取的传感器数据在经过预处理步骤后,识别准确率全部得到了提升,因此将试验数据先预处理是很有必要的。

表4 数据预处理前后SVM算法识别准确率对比Tab. 4 Comparison of SVM algorithm recognition accuracy before and after data pretreatment
3.2 不同传感器部署位置及算法识别结果比较
为了明确传感器相对优化的部署位置,利用k-means 和SVM方法在相同位置的识别结果进行对比,结果如表5所示。

表5 4个部署位置k-means算法与SVM算法测试集结果对比Tab. 5 Comparison of k-means algorithm and SVM algorithm test set results in four deployment locations
由表5可知,传感器在不同的部署位置时,利用SVM进行行为识别的准确率大于k-means方法。传感器位于NE部位时,在k-means和SVM两种方法中识别准确率均为最高,分别达到了79.34%和92.63%;传感器位于BL部位时,利用k-means识别的准确率为67.2%,高于SVM方法的66.2%;但是在FL和HL部分,SVM的识别率均远高于k-means,其中FL部位在不同识别方法中准确率均相对较低。通过表5可以证明,对于羊只行为的识别,传感器部署在NE位置,识别效果最佳;此外,SVM的整体识别效果优于k-mean方法。
表6所示为传感器部署于NE位置时,羊只不同行为识别结果。从表6中可以看出,k-means对于行走的识别率最高,达到了90.4%;SVM对于进食的识别率最高,达到了97.3%。静止行为在两种方法的识别结果中均为最低,分别时67.34%和89.5%。但是,k-means 方法对三种行为的识别准确率相差较大,识别准确率较高的行走和较低的静止之间差距达到了23.06%;而SVM方法对三种行为的识别准确率差距较小,对于静止和行走的识别准确率比较接近。SVM方法中最低的识别率最与k-means方法中最高的识别率也较为相近,这再次证明了SVM方法用于羊只行为识别时优于k-means方法。

表6 NE处测试集k-means和SVM算法识别率比较结果Tab. 6 Comparison results of recognition rate between k-means and SVM algorithm in NE test set
4 结论
1) 本文设计一种基于加速度传感器的可穿戴式装置用于羊只静止、行走和进食三种行为的识别,并针对传感器的不同部署位置进行分析和比较。试验结果表明,传感器位于NE位置时,在不同的识别方法中识别准确率均为最高,且利用SVM方法整体识别准确率达到了92.63%。在不同行为的识别中,进食的识别准确率最高,利用SVM方法识别准确率达到了97.3%。
2) 利用加速度传感器进行羊只行为的识别是一种行之有效的方法,这种方法中传感器的部署位置对识别结果有着明显的影响,因此明确相对优化的部署位置对于构建自动化的羊只行为识别系统具有现实意义。此外,数据处理和分析方法也是影响识别结果的关键因素之一,合理的数据预处理方法能够提高最终的识别率。随着深度学习方法的兴起,如何利用深度学习算法进行数据处理,进一步提高识别准确率,并对羊只更多的行为状态进行识别是本文下一步关注的重点。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
今日农业(2021年7期)2021-07-28
非公有制企业党建(2020年5期)2020-06-16
铁道通信信号(2019年6期)2019-10-08
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
雷达学报(2017年6期)2017-03-26
太空探索(2016年9期)2016-07-12
中国交通信息化(2016年2期)2016-06-06
