
河西走廊降水预报模型的建立与样本检验
2022-12-01 16:46王海燕田庆明于亚楠刘新雨
暴雨灾害 2022年5期
王海燕,田庆明,于亚楠,刘新雨
(甘肃省酒泉市气象局,酒泉735000)
引 言
近年来随着预报模式的深入研究,降水预报研究成果日益增多。路志英等(2018)构建深度信念网络(Deep Belief Networks,DBNs)短时强降水模型,对于提高短时强降水预报的命中率、误警率和临界成功指数,有较好的效果;熊洁等(2020)使用全球中期数值天气预报模式(YinHe Global Spetral model,YHGS)针对华中一次暴雨预报进行研究,结果显示YHGS 模式预报是可行的;何邓新等(2020)利用变分方法估计全球/区域同化预报系统(Global-Regional Assimilation and Prediction System,GRAPES)的非系统性误差,从而对预报做出修正;吴志鹏等(2020)对西南地区4次强降水过程进行模拟试验,结果表明升尺度邻域平均预报法一定程度上可降低强降水预报的不确定性。然而河西走廊地处西北干旱区,涵盖平原、戈壁、沙漠、冰川等复杂的地形(杨梅,2021),DBNs 短时强降水模型只预报未来0—3 h的短时临近预报,河西地区多为系统性降水,DBNs 短时强降水模型在河西地区实用性较弱;YHGS 模式和升尺度邻域平均预报方法,对于戈壁沙漠地形,在降水强度方面有过度预报的问题。
欧阳首承等(2005)针对突发性天气的结构,提出V-3θ图,其中V是探空资料中直接观测的风向、风速信息,3θ分别为位温(θ)、假相当位温(θse)、饱和假相当位温(θ*se),3θ在P-T(横坐标为气温,纵坐标为气压)坐标图上构成3条曲线,作为每一个测站的V-3θ图。青泉(2019)使用L 波段探空数据绘制V-3θ图形,成功地分析了四川盆地24 次大范围的暴雨天气过程,证明了V-3θ图在暴雨短期预报中的作用。可见,正确识别V-3θ图形,可以准确地预报暴雨。周林腾(2018)指出Keras方法可解决很多复杂的模式识别难题。它通过组合低层特征,形成更加抽象的高层表示属性类别,最后发现数据的分布式特征。Keras方法更容易创建新模块,允许可配置的模块用最少的损耗自由组合在一起。郑洋洋等(2019)基于Keras 方法建立长短时记忆网络(Long Short Term Memory network,LSTM)模型,对太原市空气质量指数(AQI)进行仿真预测,此模型为大气污染防治工作提供了科学合理的理论依据;Daouda等(2019)利用Keras方法成功预测出西非地区水汽总量(TCWV)。
本文受欧阳首承等(2005)垂直方向信息差异构成涡旋运动理念的启发,增添特征值,改变识别方式,衍生新的V-3θ图,以此预测降水天气,可提高中长期降水天气预报效果。同时吸纳Keras 方法建立LSTM 模型框架和多元回归模型框架时实验快速的优点,使用Keras 方法建立河西走廊降水模型框架,实现降水预报的客观定量化,最终得到格点降水预报,以此提高河西走廊降水预报质量。
1 资料与方法
1.1 河西走廊降水预报模型原理简介
本文对传统V-3θ图进行了衍生,改变探空资料为一级资料,利用ECMWF预报资料作图,可直接得到未来时刻的大气垂直结构图像,改善传统V-3θ图在暴雨中期预报效果不显著的问题。
河西走廊降水预报模型将位温(θ)、假相当位温(θse)、饱和假相当位温(θ*se)、比湿和垂直速度五种廓线资料,量化为69个特征量,使原始V-3θ图的图形数字化,以此描述新V-3θ图。此方法可降低原始V-3θ图人为识别时候的主观意识偏差,同时针对复杂的气象资料,使用Keras 方法建立晴雨分类和降水量拟合预报模型框架,进行机器识别学习。由于传统V-3θ图的中风向和风速在机器学习中不易量化,尤其垂直方向风速变化小,风向变化大的样本,为避免缩放时影响特征值的精确率,本文将风向、风速用垂直速度替代,同时特征值增加比湿,提高模型特征量多元性。
1.2 河西走廊降水预报模型资料
1.2.1 河西走廊降水预报模型资料简介
使用的资料包括:(1)2018年4—9月(70°—110°E、30°—50°N) 范围内10 189 个自动站逐小时加密观测雨量,并计算逐3 h累积雨量。(2)2018年4—9月水平分辨率为0.25°×0.25°、垂直分为10 层的ECMWF 预报资料,选取每日20∶00(北京时,下同)起报,未来75 h内间隔3 h的气压、温度、相对湿度、比湿和垂直速度5个物理量。(3)2018年4—9月(70°—110°E、30°—50°N)范围内,水平分辨率为0.125°×0.125°的ECMWF 降水量预报资料,选取2019 年7 月15 日20∶00 起报,未来75 h内间隔3 h的格点资料。
1.2.2 河西走廊降水预报模型降水标准
甘肃地域广阔,河东地区与河西地区降水差别大。靳生理等(2012)提出河西地区降水少且分布不均匀,河西西部降水量多年平均值为84 mm,降水标准不同于国家级降水量等级。表1 是根据《甘肃省河西地区降雨等级》(DB62/T 1732-2008)得到的河西地区降水标准,降水时间段分为24 h 和12 h 两种,降水强度分为11个等级,本文中河西走廊降水预报模型使用此标准。

表1 河西地区降水标准Table 1 Precipitation standard in Hexi area.
1.2.3 资料处理
图1 给出数据资料处理流程框架图,分为资料说明和样本处理两个环节。
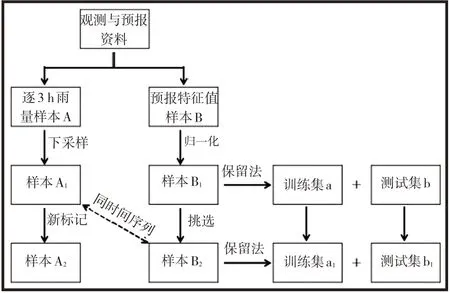
图1 数据资料处理流程框架图Fig.1 The frame diagram of sample processing flow
(1)资料说明
将逐3 h 雨量作为样本A,按晴雨分类,有降水为“雨天”,标记为“1”;无降水为“晴天”,标记为“0”。ECMWF 预报资料垂直分为100、200、300、400、500、600、700、850、925和1 000 hPa共10层的,利用各层气压、温度和相对湿度3 个基本要素场,计算得到位温(θ)、假相当位温(θse)、饱和假相当位温(θ*se),分别作为大气热力指标1、大气热力指标2 和大气热力指标3;计算各层假相当位温和位温的差值(θse-θ)作为大气干湿度指标1;计算各层饱和假相当位温和假相当位温的差值(θ*se-θse)作为大气干湿度指标2;计算850 hPa 与500 hPa 的位温差(θ850-θ500)作为大气稳定度指标1;计算850 hPa 与500 hPa 的假相当位温差(θse850-θse500)作为大气稳定度指标2;比湿采用模式输出值,共10 个层次,作为大气水汽指标;垂直速度采用模式输出值,取100、200、500、700、850、925 和1 000 hPa 共7 个层次,作为大气动力指标。利用大气热力指标1、2、3,大气干湿度指标1、2,大气稳定度指标1、2,大气水汽指标和大气动力指标作为预报特征值,共计69个。此预报特征值作为样本B,利用样本B 使原始V-3θ图形数字化。
(2)样本处理
通过对训练集进行归一化处理,可有效提高了目标识别分类工作中的准确率。由于样本B中,各特征值之间数值差异较大,为消除特征值之间的量纲影响,对特征值进行了归一化处理(孙然,2018),计算公式如下
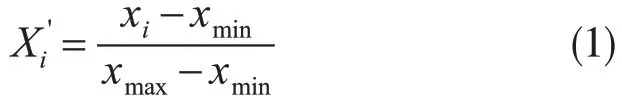
将特征值xi(i=1,2,3,…,69)按公式(1)进行计算,其中xmax为最大特征值,xmin为最小特征值,计算得到X′
i,使得特征值均映射到0~1 范围内,处于同一数量级,作为样本B1(3 136 596个数据)。根据周志华(2016)提出的数据留出法,本文将样本B1按3:1切分,数据随机分为训练集a和测试集b。使用训练集a(2 351 682个数据)建立河西走廊降水预报模型。由于样本A 的晴天和雨天比例约为7:1,如果用训练集a建立晴雨分类模型,会使分类结果趋于晴天,当模型应用到预报数据上时,模型输出结果的准确性很差。杨子元(2021)提出利用下采样方法,可以有效抵御干扰。针对以上问题,利用下采样技术,使晴天和雨天样本数量相差变小,使样本A 中“0”和“1”比例为1:1,记为样本A1。
在样本B1中筛选与样本A1同时间序列的特征值,记为样本B2。通过数据保留法,将样本B2按3:1 切分,数据随机分为训练集a1和测试集b1,用训练集a1(587 908 个数据)生成模型,用测试集b1(195 966 个数据)检验河西走廊降水预报模型的准确率。
将样本A1中标记“1”样本换回雨量,“0”样本雨量记为0,作为样本A2。
2 河西走廊降水预报模型的建立
预报模型的建立可分为两步,第一步是晴雨分类,通过对晴天和雨天进行分类,训练特征值来构造分类器(即分类模型),预测未来是否出现降水;第二步是降水量拟合,统计样本中不同的特征值在不同的雨量下的概率,记忆各种最大概率的雨量相匹配的特征值,从而预测未来雨天时的降水量。
2.1 晴雨分类模型
通过keras 方法(周林腾,2018)建立晴雨分类框架,采用二分类方法,使用训练集a1(587 908个数据)建立晴雨分类模型。本模型共设置3 层神经网络,第一层为输入层,设48层;第二层为隐含层,设24层;激活函数选用relu,第三层为输出层。优化器选用rmsprop(root mean square prop),监控器的指标使用平均绝对误差(MAE)。
交叉验证用来估计泛化误差,其中k折交叉被广泛使用(杨柳和王钰,2015)。晴雨分类模型使用k折交叉来验证预报特征值的可靠性,其数据处理流程如图2所示,将训练集a1随机平均划分为10 个不相交的子集,其中一个子集做拆分集M;剩余的9个子集做拆分集N。拆分集M定义为测试集c,拆分集N定义为训练集d,再将训练集d 按保留法,划分为训练集e 和验证集f,用训练集e 训练模型,验证集f 验证模型的有效性,计算10次模型的分类率,然后再平均,最后挑选最佳效果的模型。由于模型建立要求训练集e大于验证集f,验证集f 大于测试集b1和测试集c,故训练集e 和验证集f样本比例为4:1。将模型进行迭代,挑选模型合适的迭代次数,其中迭代次数以等差数列的形式增加,公差为10,迭代至450 次结束,迭代过程中发现模型有欠拟合问题。高毅等(2019)提出折线平滑对多组数据随时间的变化趋势。对比每次迭代的趋势发现:迭代到200 次时,MAE 达到最低值,模型二分类错误率最低,指标更加可靠。
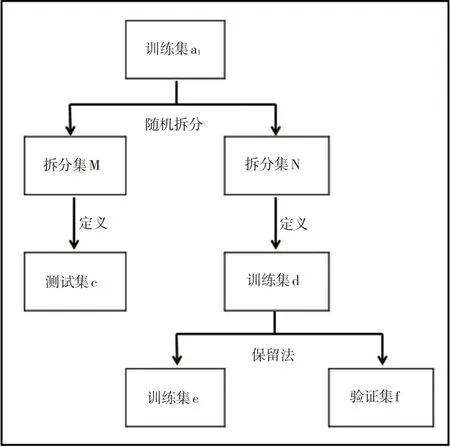
图2 晴雨分类模型数据处理流程图Fig.2 Data flow chart of sunny and rainy classification model
2.2 降水量拟合模型
通过keras 方法(周林腾,2018)建立降水量拟合框架。由于晴雨分类为二分类模型,逻辑回归方法可处理二分类问题,同时逻辑回归增加正则化可以提升深度学习模型的识别精度,解决模型中过拟合现象(胡艳梅等,2021),所以降水量拟合模型使用逻辑回归,加入正则化项。首先对训练集a1标准化处理,得到训练集a2,再将训练集a2和样本A2用逻辑回归,建立降水量拟合模型,最终预测未来的降水量。利用公式(2)计算特征值数据xi,以及对应的样本A2,得到公式(3),此方法可减少预测范围,将预测值限定在[0,1]间;再通过y=1时分类,化简为公式(4),避免训练集a2分布不准确带来的问题;使用极大似然估计公式(5),求解公式(6)得出参数,从已知的结果推导最大概率的结果参数,以此构建逻辑回归模型,用于预测未来雨天的降水量。
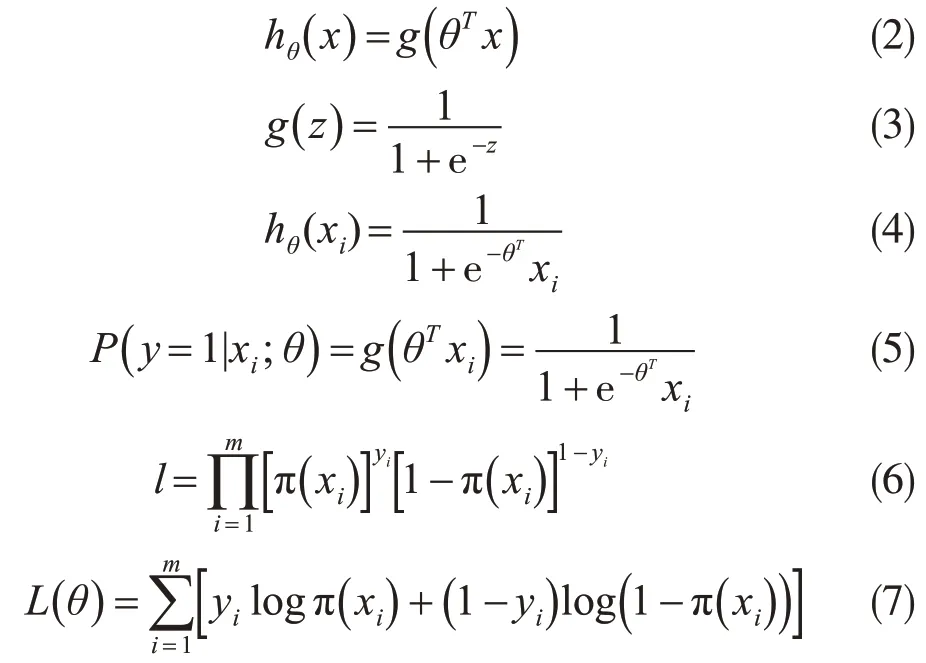
假设权重参数θ和函数公式(2)~(3),输入训练集a2中的特征值xi(i=1,2,3…69),使之为公式(4),机器自动枚举参数的可能取值,将训练样本带入,计算当y=1 时,公式(5)的概率,此时g(z)作为Sigmoid 函数,选择0.5 为阈值(0.5 处函数中心对称),利用公式(6),m为样本数(587 908),此时y为样本A2,求对数,得公式(7),对对数似然函数(公式(7))求极大值,作为权重参数θ。同时在公式(7)的基础上,加入正则化项,减少样本B归一化处理后模型的误差影响。分别使用正则L1和正则L2,进行超参数调优。假设正则参数为a,对比L1 正则化和L2 正则化结果,发现特征值之间具有很好的关联性,L1(0.9415214688342473)优于L2(0.940421367831 123 8)。确定模型选用正则L1 方法。同时,将正则参数a以等差数列的形式增加,公差为10,至300 结束,发现在L1正则参数a为300时,误差函数的值最小,故将正则参数固定为300。
3 河西走廊降水预报模型的样本检验
用样本B2中的测试集b1(195 966 个数据)对预报模型进行检验,不同预报时段的样本数量无明显关系。分别使用TS、损失函数及均方根误差三种检验方法,检验结果见表2。
3.1 TS检验
河西走廊地区气候干燥,酒泉市近30 a年平均降水量仅为83.8 mm,大雨及以上量级出现的频率仅占3%,因此对大雨及以上量级进行分级阈值检验意义不大,同时河西走廊降水预报模型在晴雨分类上使用的是二分类方法,因此只对降水进行晴雨检验。TS(TS)检验方法(熊洁等,2020)由式(8)给出,检验结果数值越大模型准确率越高。
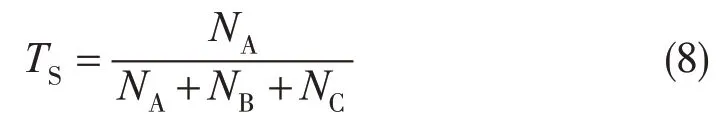
晴雨检验中,通过晴雨预报正确的站(次)数NA和空报的站(次)数NB以及漏报的站(次)数NC的比值,反映分类器对整个样本的判定能力,直观地判别出降水模型晴雨预报的准确率。从表2中可见,晴雨检验准确率均在0.78 上,其中42 h 之前准确率均在0.80 以上,其中12—18 h 准确率较高,表明该预报时段模型的晴雨预测值与天气实况最为接近,42 h后准确率略有下降。
3.2 损失函数检验
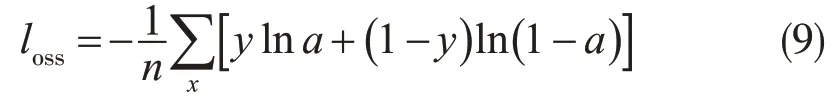
由于河西走廊降水预报模型在降水量拟合模型上使用的是逻辑回归方法,因此损失函数检验在此基础上进行。损失函数检验方法(黄晚晴,2021)由式(9)给出,检验结果数值越小模型预报效果越好。式(8)中,测试集b1为样本x,a为样本x预测为正类的概率,y为样本x对应的实际降水量,正类为1,负类为0,n为预报时次的样本数,此方法可估量模型的预测值和降水真实值的差异程度。从表2 第四列中看出,预报时效21 h 之前,检验结果均小于0.4,说明预报时效21 h前降水模型预测的降水数据和真实数据分布很接近,此降水模型性能良;其中12—18 h,损失函数较小,此时段降水模型的预测值与真实值最为接近;之后随着预报时效的推移,检验结果呈波动上升趋势,说明预报时效21 h后,降水模型的预测值与真实值不一致程度呈波动逐渐增加,降水模型的预测值与真实值也对应降低。
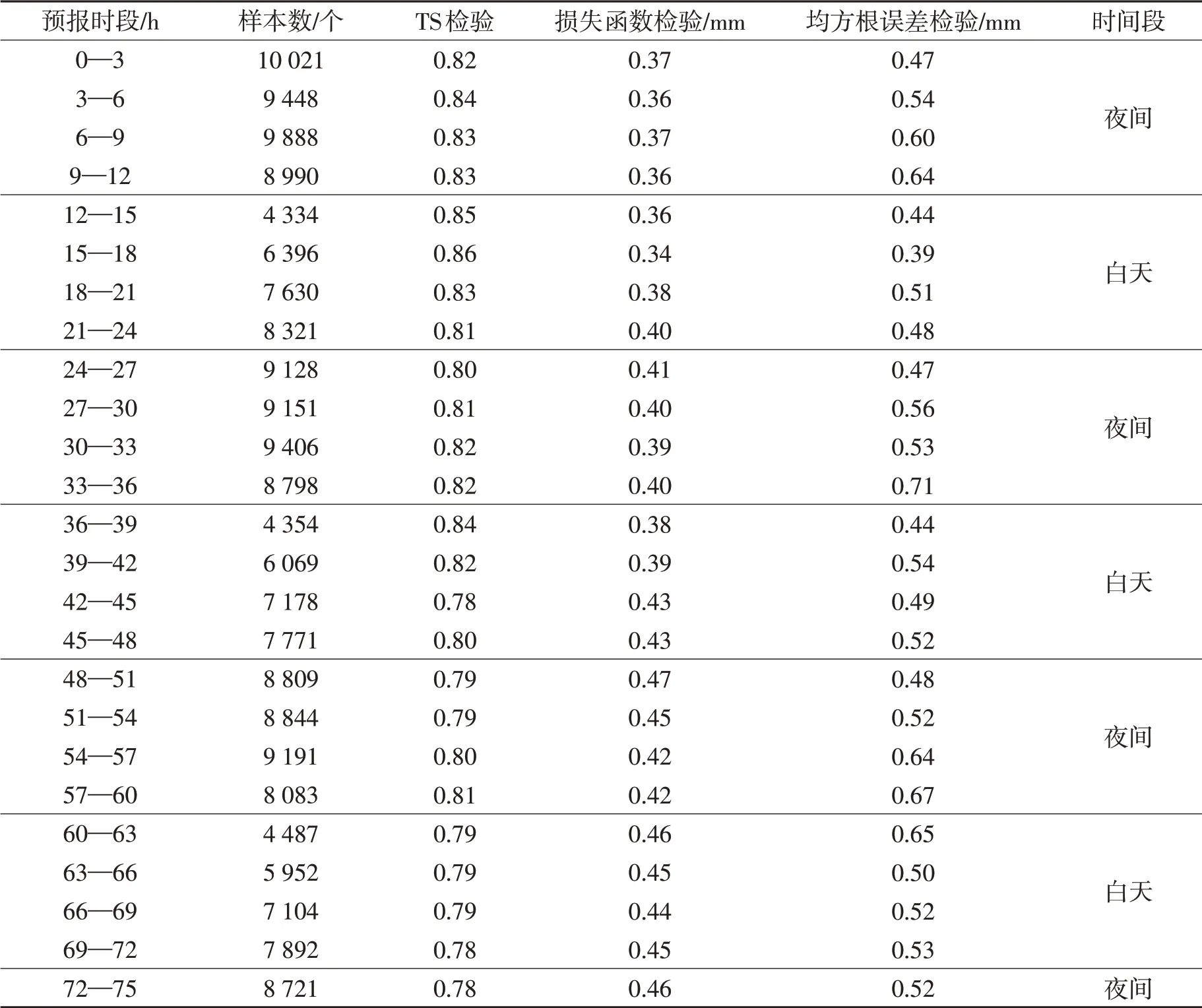
表2 河西走廊强降水预报模式TS检验、损失函数检验和均方根误差(RMSE)检验对比表Table 2 Comparison of precipitation forecast model in the Hexi Corridor(TS test,loss function of classification test, and RMSE test)
3.3 均方根误差检验
由于无法检查测试集b1中的每个值,从而了解特征值是否异常,可利用均方根误差(RMSE)对异常值敏感的特性,来反映河西走廊降水预报模型的稳定性。RMSE(RMSE)检验方法(段子誉和姚振强,2021)由式(10)给出。
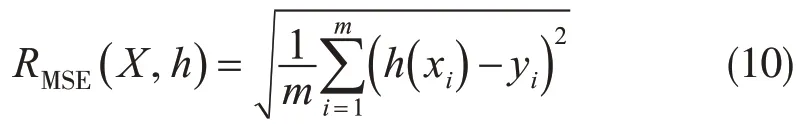
RMSE是预测值h(xi)与平均值yi偏差的平方和除以样本数(m)后的平方根,数值越小表示模型预报水平差异越小,它描述的是一种离散程度。由于河西走廊2018年4—9 月期间3 h 降水量大于9.9 mm 的样本过少,所以只进行降水量预报时次检验。用图3 绘制表2 中RMSE检验结果,可以更加清晰地看到25个时次之间的差异,其中红色柱所表示的白天误差更小(平均值为0.5),而黑色柱所表示的夜间误差平均值达到0.57,表明该模型对白天时段的预报效果比夜间更好。
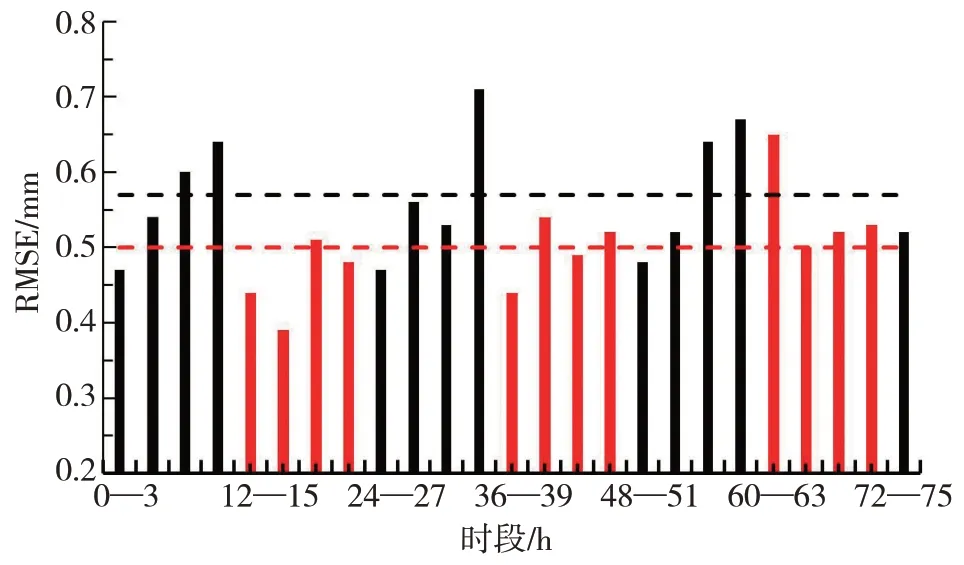
图3 RMSE检验图(黑色柱预报时段为夜间,红色柱预报时段为白天,黑色虚线和红色虚线分别为夜间和白天的RMSE检验的平均值)Fig.3 Test diagram of root mean square error(The black bar indicates that the forecast period is at night,the red bar indicates that the forecast period is daytime,the black dotted line is the average value of root mean square error test at night,and the red dotted line is the average value of root mean square error test during the day)
从三种检验方法的结果综合对比看,12—18 h 的预报结果相对最佳,白天预报结果总体优于夜间。
4降水实况与预报结果的对比分析
图4 给出甘肃省酒泉市2019 年7 月16 日20 时—17 日20 时日降水量。甘肃省酒泉市辖肃州区、玉门市、敦煌市、金塔县、瓜州县、肃北蒙古族自治县、阿克塞哈萨克族自治县共7个市、县、区,92个区域站,其中58 个区域站出现降水,包括小雨24 站、中雨12 站、大雨21 站,最大日降水量出现在肃北站(42.6 mm),达到暴雨量级。

图4 甘肃省酒泉市2019年7月16日20时—17日20时日降水量图(单位:mm,黑色点表示区域站位置)Fig.4 Map of administrative divisions and daily precipitation from 20∶00 BT 16 to 20∶00 BT 17 June 2019 in Jiuquan city(unit:mm,the locations of regional stations are black dot)
对比主要降水时段7月16日20时—17日08时间隔3 h的降水实况和模型预报值可知,模型准确预报出了降水开始时间(图5a),虽然降水预报范围较实际有所偏大,但预报的降水中心值(9.1 mm)与实况(7.9 mm)非常接近,且均位于肃北站;17日00—02时(图5b),模型预报范围与实况也较为一致,但预报的降水中心较实况偏北约150 km,降水中心值(14.5 mm)与实况(16.3 mm)很接近;17 日03—05 时(图5c),模型预报范围与实况基本重合,5 mm以上的降水区域两者也非常接近;17日06—08 时(图5d),降水区域和降水中心也都较为一致。由此可见,河西走廊降水预报模型较准确地预报出了这次降水过程的发生时间、主要降水时段、降水区域范围及降水强度,尤其是肃北站16日20时—17日08时预报为30.2 mm,与实况相差仅为3.2 mm。
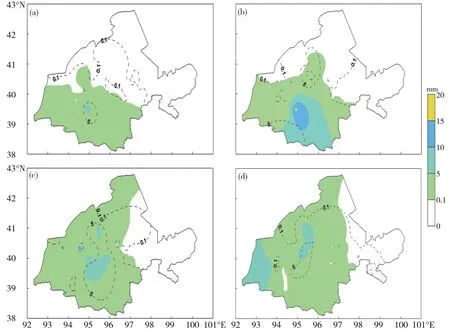
图5 2019年7月16日20—23时(a)、17日00—02时(b)、17日03—05时(c)、17日06—08时(d)酒泉市逐3 h的降水实况与河西走廊模型预报对比图(填色为降水实况,等值线为降水预报,单位:mm)Fig.5 Comparison between actual precipitation and the Hexi Corridor model prediction in Jiuquan city(a)from 20∶00 BT to 23∶00 BT on the 16,(b)from 00∶00 BT to 02∶00 BT on the 17,(c)from 03∶00 BT to 05∶00 BT on the 17,and(d)from 06∶00 BT to 08∶00 BT on the 17 June,2019(The shaded is precipitation actual,the contour line is precipitation forecast,unit:mm)
分别对比2019 年7 月15 日20 时的ECMWF 降水预报和河西走廊降水预报模型在酒泉市2019 年7 月16日20时—17日20时日降水量间隔3 h的预报(图略),可以看出ECMWF降水预报比河西走廊降水预报模型的预报降水区域范围偏大,降水时段偏长,降水强度偏强,降水中心与实况差距更大。总体上,河西走廊降水预报模型降水预报结果优于ECMWF降水预报。
5 结论与讨论
本文利用河西走廊地面逐小时降水资料及ECMWF预报资料,根据69个特征量对V-3θ图进行描述,使用Keras方法构建河西走廊降水预报模型框架,最终预测河西走廊降水量。用分类检验损失函数、晴雨检验、拟合检验均方根误差和个例实况对河西走廊降水模型结果进行对比,得出以下结论:
(1)采用keras建立三层神经网络框架,使用k折交叉方法,通过折线平滑,建立最佳晴雨分类模型,确保模型对天气的快速识别,迭代次数为200,降水预测结果达到最优效果,最终使河西地区降水预报更加准确。
(2)采用逻辑回归模型,挑选最佳的正则函数(L1)及正则参数(300),建立降水量拟合模型,使得在已有的数量级上取得更好的效果,降低模式的复杂性,减少特征值间误差的影响,更准确地预报雨天情况下的降水量级。
(3)利用垂直方向信息差异构成涡旋运动的理念,将传统的V-3θ图衍生为69 个特征量进行描述,使图形数量化,以此降低人为主观臆断导致的降水偏差。垂直速度替换风向、风速,增加比湿,以此增加特征值的精确率和多元性。
(4)对比TS 检验、损失函数检验和均方根误差检验三种方法的结果,河西走廊降水预报模型白天预报结果总体优于夜间,12—18 h的预报结果相对最佳。
(5)通过对酒泉市一次强降水天气过程的预报检验,河西走廊降水预报模型较准确地预报出了这次降水过程的发生时间、主要降水时段、降水区域范围及降水中心强度,证实该模型对强降水天气有较强的预报能力。
由于河西走廊降水预报模型的样本仅使用2018年4—9 月,样本数量过少,河西走廊降水预报模型晴雨检验略低于ECMWF降水预报,然而对比多次降水个例均发现,ECMWF降水预报比河西走廊降水预报模型的预报降水区域范围偏大,降水时段偏长,降水强度偏强。在未来的研究中,需要建立更大规模的样本数据集,期待河西走廊降水预报模型取得更精确的预报。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
文苑(2020年8期)2020-09-09
敦煌学辑刊(2017年4期)2017-06-27
甘肃林业(2016年3期)2016-11-07
金色年代(2016年4期)2016-10-20
东北电力大学学报(2015年1期)2015-11-13
三联生活周刊(2015年43期)2015-10-23
丝绸之路(2015年21期)2015-03-16
