
基于联邦学习的火灾图像检测算法
2022-12-01 03:27吴浩宇郭雅婷董迪昊
陕西科技大学学报 2022年6期
杨 帆, 吴浩宇, 郭雅婷, 董迪昊
(陕西科技大学 电子信息与人工智能学院, 陕西 西安 710021)
0 引言
基于图像的火灾检测可分为火焰检测,与烟雾检测.其中火焰检测由于特征明显,信号易被检测,因此早期检测技术多从火焰颜色特征出发.Han等[1]使用基于高斯混合模型的背景减法运动检测结合RGB与HSV多颜色特征规则检测视频序列中的火焰像素.Wang等[2]提出一种两阶段检测方法,先通过帧差法与颜色阈值得到类火颜色运动区域,再对目标区域进行时空分块[3]提取内部特征,并使用SVM进行分类测试.在此基础上,Khalil等[4]提出一种基于RGB与CIE颜色模型的火灾检测方法,该方法将运动检测与目标追踪结合,与现有火焰检测模型相比使用了更少的参数达到了相同的精度.罗小权等[5]改进了YOLOV3网络结构与损失函数,使火灾检测模型具有较好的准确率表现时,拥有更好的实时性.但上述火灾检测算法忽视了火灾早期烟雾特征,虽然精度方面更高,但无法提前预见火情.
与仅使用火焰特征检测相比,使用烟雾特征识别通常更早发现火情.Luo等[6]提出一种基于前景提取的烟雾检测方法,根据烟雾颜色通道信息与运动特征标记疑似区域.使用卷积神经网络对图像进行训练与分类.在此基础上,林高华[7]提出一种基于动态纹理的区域烟雾探测算法,但其训练数据为合成烟雾视频,与火灾现场仍有差别.徐高[8]提出一种基于深度域适应与显著性检测的烟雾检测方法,得到一种具有较优分割精度的模型.但这种方法性能受限于训练数据,面对多源数据集混合训练时模型效果较差.
虽然深度学习在火灾检测领域取得了较好效果,但由于火灾的偶然性和特殊性,目前基于机器学习的火灾检测系统面临依赖训练集,缺乏高质量样本等困难.而很多火灾数据分布于诸如银行、消防局、林业部门等具有隐私属性的区域中,受隐私安全限制无法提供.如果将这些区域分散的样本有效利用,能极大的提升火灾检测系统在面向不同时空[9]、不同图像质量、不同干扰条件下的模型鲁棒性.联邦学习[10]技术为火灾样本匮乏的挑战提供了思路,它是一种具有隐私保护属性的分布式机器学习.联邦学习可以在用户不上传本地数据的情况下,联合训练模型,解决了用户对上传数据安全性的需要.因此使用联邦学习算法训练火灾烟雾检测模型,可以在保护隐私的前提下有效利用各个企业单位摄像头所拍摄到的样本,与合成火灾烟雾样本相比,真实样本环境复杂、干扰差异性大且更贴合实际火情,能更有效的提升识别模型的泛化性与通用性,解决传统训练中样本数据集单一的问题.
因此,本文提出一种基于残差神经网络[11]的联邦学习的火灾视频检测算法.本文利用联邦学习破除数据孤岛的特性,为企业单位提供数据隐私保障,从而多方收集边缘火灾样本,解决火灾样本匮乏的困难.并通过秘密共享与加密技术保护用户上传的模型参数,提高了联邦学习通信过程中的安全性.
1 相关算法概述
1.1 联邦学习
联邦学习是一种通过隐私保护手段聚合多方训练信息,共同构建全局模型的一种分布式机器学习[10].与传统的中心化机器学习相比,联邦学习的特点是数据不离开本地,降低了隐私泄露的风险.
根据数据拥有者的数据特征空间和样本空间重叠关系不同,联邦学习可以分为以下三种类型:横向联邦学习,纵向联邦学习,迁移联邦学习.其中横向联邦学习适用于参与方数据特征重叠较多的情况.火灾图像检测背景下参与方提供的样本主要包含火灾样本、烟雾样本、干扰样本,此类样本数据特征相近,但由于参与方的不同,样本空间重叠较少.因此本文选用的联邦学习框架为横向联邦学习算法(联邦平均算法)[12],其框架结构如图1所示.
联邦平均算法中,具有相同数据结构的K个参与方协同训练综合模型,训练过程通常分为4步:
步骤1参与方在本地计算模型梯度,使用安全技术对梯度信息进行隐藏,将隐藏后的结果发送给服务器.
步骤2服务器接受到各个参与方发送的梯度后,通过安全聚合操作聚合梯度.
步骤3服务器将聚合的结果加密后返还给各个参与方.
步骤4各个参与方使用收到的服务器聚合后的梯度进行本地模型更新,并重复上述步骤.
1.2 AES加密
高级加密标准(AES,Advanced Encryption Standard)是一种对称加密算法,其加密和解密过程使用相同的密钥,加密流程如图2所示.

图2 AES加密流程
AES加密会将明文分为长度相等的数据组,遍历加密直至加密整个明文.AES规定明文长度为128的倍数,若明文长度不符合要求,需要填充空白位.AES的密钥长度可以为128位、192位或256位.AES的密钥长度越长,则安全性更高,相对应的算法开销也会更大.由于联邦学习具有在移动场景中部署的优势,考虑到移动端计算能力存在差异,本文默认使用128位AES加密.
1.3 秘密共享与中国剩余定理
1.3.1 秘密共享
秘密共享(Secret Sharing)可以将一份秘密在群体中合理分配,使全体群成员共同分享秘密[13].秘密分享可以分为秘密拆分与秘密重构两个阶段.
秘密拆分:秘密拆分指借助一个算法将原始秘密S拆分为n份秘密值(s1,…,sn)并将它们分别分发给n个用户.
秘密重构:秘密重构指从n个用户中选取任意t(t≤n)个秘密值,借助一个算法,将t个秘密值作为输入,输出原始秘密.对于任意个小于t的输入都无法还原秘密值.t也被称为门限值,这种秘密共享方案也被称作(t,n)门限秘密共享.本文基于中国剩余定理构建了一种(t,n)门限秘密共享方案.
1.3.2 中国剩余定理
中国剩余定理是一种求解一次同余式组的方法,是数论中的一个重要定理.
假设整数(m1,…,mn)两两互素,则对于任意的整数(a1,…,an)存在方程组:
(1)
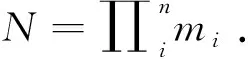
(2)
2 基于联邦学习的火灾检测算法
本文提出一种基于联邦学习的火灾检测算法,针对真实火灾样本缺少的问题,给出一种解决途径.为了解决联邦学习中可能存在的数据安全问题,在联邦学习的基础上,使用AES加密技术保护用户参数上传过程.考虑到面向移动网络环境的联邦学习存在通信环境差,节点连接不稳定的情况,使用门限秘密共享方案,将AES密钥作为原始秘密拆分并分发给各个参与节点.由于门限秘密共享方案的特殊性,即使存在小部分数量的掉线用户,服务器仍可通过算法还原秘密,为联邦学习系统提供了面对不稳定通信环境的鲁棒性.
2.1 联邦学习系统框架
本文采用联邦平均算法作为服务器聚合算法,图3展示了基于联邦学习的火灾检测网络结构,整个联邦学习过程可分为用户本地训练与服务器聚合两部分.
算法将在2.2节详细描述,此处简要介绍联邦学习中本地模型的训练与联邦模型的聚合规则.在联邦学习的开始阶段,服务器初始化全局模型w0(包含模型信息、迭代轮次、超参数等配置信息)并分发至所有参与训练的用户节点.本地节点通过本地数据集x与梯度下降法迭代训练本地模型wi,当达到足够的迭代次数后将本地模型wi发送至服务器.当服务器收到所有本地节点发送的本地参数wi时,将所有节点的wi平均聚合,并将聚合后的新全局模型wt+1(假设当前在第t轮)发送给各个节点.至此一轮全局训练结束,下轮全局训练开始时,各个节点通过新全局模型wt+1开始本地训练.
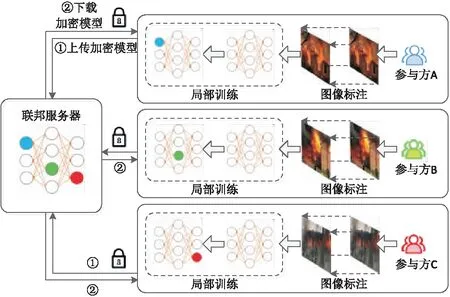
图3 基于横向联邦学习的火灾烟雾检测流程
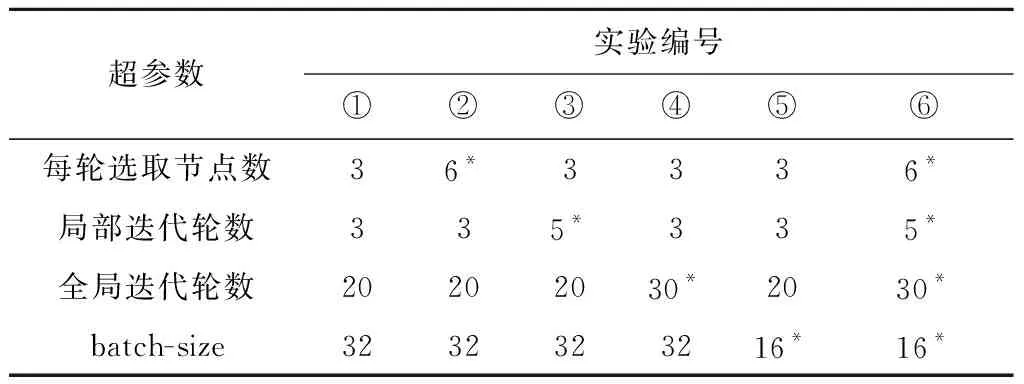
横向联邦平均算法中,计算量由3个关键参数控制:每轮本地迭代次数K、联邦学习全局轮数T、客户端更新所采用的mini-batch大小b.当K、T、b取值越大时,通常可以获得更好的模型泛化能力与识别精度,但也会付出更多的时间开销.
2.2 基于秘密共享的联邦学习火灾检测算法
联邦学习中通常会使用同态加密[14]与差分隐私[15]方法保护用户的隐私数据,然而同态加密[14]开销较高,会对面向移动设备的联邦环境造成过大的计算负担,差分隐私[15]又对训练精度存在一定影响.因此本文提出一种结合AES加密、RSA加密与秘密共享[13]算法的安全方案,与基于同态加密或差分隐私的联邦学习方案相比,具有低计算开销、根据安全需要灵活调控加密复杂度、无精度损失等特点,并且基于秘密共享算法门限的特殊性,具有一定对掉线用户的鲁棒性,一定程度上为联邦学习中通信环境差[12]的问题提出了解决思路.另外,基于移动端计算能力考虑,本文实验中选用1 024位RSA加密,128位AES加密,在有更高安全需求[16]的实际应用场景中,可以通过增加AES密钥长度提升密文混淆程度.
本文中安全方案的系统框架如图4所示,整个方案包含3个角色:可信第三方、本地节点群、服务器.其中可信第三方负责生成与拆分密钥,客户端使用可信第三方的密钥加密编码后的训练结果.当发送结果的节点数满足要求时,服务器才可以还原密钥,解密节点训练结果并聚合.

图4 基于秘密共享的联邦学习火灾检测算法
在本算法中,我们默认节点与服务器均为诚实但好奇的.方案中所有公钥pki、pks公开,而所有私钥ski、sks均秘密保存.基于秘密共享的联邦学习火灾检测算法可分为以下若干步骤:
(1) 系统初始化
①输入:参与节点总数N,每轮参与节点数M,全局迭代轮数T,本地迭代轮数K,样本x,初始化模型w0,训练函数f(.);AES密钥长度lAES,RSA密钥长度lRSA,门限值t.
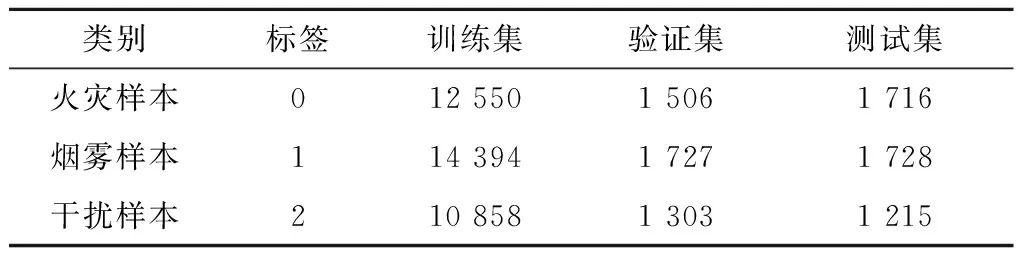
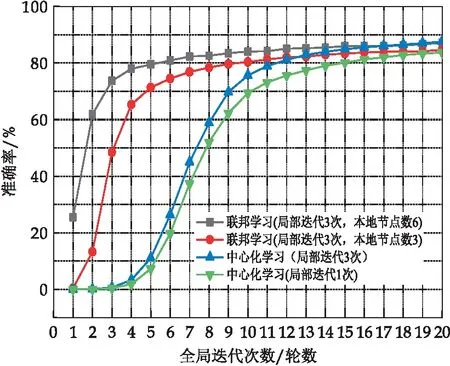
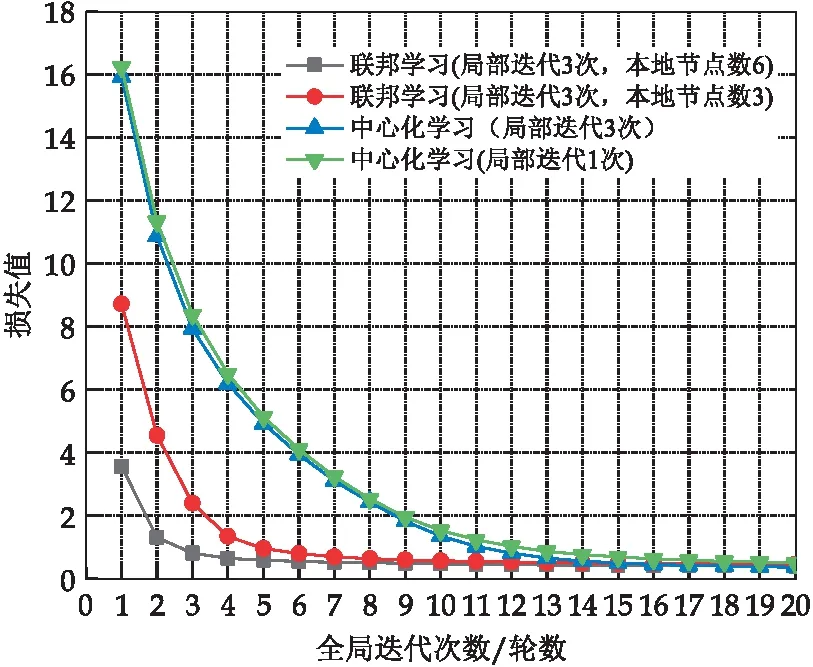
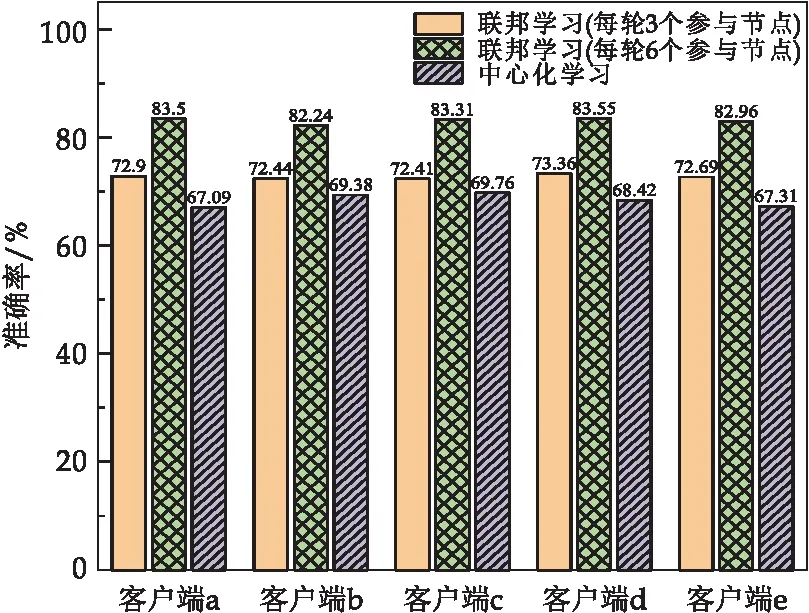
②基于RSA算法的服务器公私钥生成:首先服务器随机选择大素数p,q并计算公共模数,其中ms=p×q的二进制位数等于lRSA.根据素数p,q,模数ms计算欧拉数r=φ(ms)=φ(p)×φ(q)=(p-1)×(q-1).其次,服务器选择一个整数es满足es 参与节点i以相同的方法生成节点公钥pki(mi,ei)与节点私钥ski(mi,di),并广播节点公钥pki,保存私钥ski. (2) 可信第三方生成并分发密钥 ①主密钥生成:可信第三方根据密钥长度lAES,使用AES密钥生成函数生成主密钥k=KeyGen(lAES). ②主密钥拆分:可信第三方随机选择n个互素整数a1,a2,…,an作为模数,根据主密钥k,计算式(3) bi=k(modai) (3) 则(bi,ai)为节点i的秘密份额,在下文中统一以si表示. ③秘密份额与主密钥的加密分发:可信第三方使用系统初始化过程中产生的服务器公钥pks加密每个秘密份额si,通过式(4)得到秘密份额密文Ci. Ci=(si)es(modms) (4) 可信第三方使用节点公钥pki加密主密钥k,通过式(5)得到主密钥密文Cki并将结果Ci,Cki分发至对应节点i. Cki=(k)ei(modmi) (5) (3)本地节点训练模型并加密模型参数 (6) k=(Cki)di(modmi) (7) (4)服务器还原明文并聚合全局模型 si=(Cs)ds(modms) (8) ②主密钥重构:若秘密份额si数目满足(t,n)门限,则通过秘密重构算法,根据t个以上秘密份额si恢复本轮主密钥k,否则本轮重构失败(多于t个节点退出),进入下轮全局迭代.秘密重构算法步骤如下:首先任选t个秘密份额st={si+1,…,si+t},根据模数ai+1通过式(5)计算模数乘积N1. N1=ai+1×ai+2×…×ai+t (9) 根据式(3)可以得到模数方程组形如式(10). (10) 根据模数方程组(10)与模数乘积N1,计算式(11),可得到主密钥k. (11) (12) 服务器将聚合后的全局模型wt+1分发至全部N个节点,至此一轮全局训练结束. 本研究实验环境为Win10 64位操作系统,内存为16 GB,CPU为AMD Ryzen 5600X,GPU为NVIDIA GeForce 3070 8G,在Python3.8编程环境下实现.本节将从联邦学习与中心化学习性能对比、安全方案的时间开销、火灾检测算法性能对比三方面进行分析,以验证联邦学习的有效性与本文安全方案的低开销性. 为验证本算法的有效性,实验所用数据集来自英国杜伦大学提供的火灾公开数据集Collections (durham.ac.uk)[17].该数据集总样本为46 997张,其中37 802张用作训练数据集,4 536张用于验证数据集,4 659张作为测试数据集.数据集包含室内、室外、开阔空间多种环境,干扰物包含水雾、云朵、警示牌等.数据集划分采用留出法划分,表1为实验数据集分类细则. 表1 火灾检测数据集各类样本数量统计 本实验是为了测试联邦学习与传统中心化机器学习在相同数据集的条件下,经过20轮训练得到的识别精度差异.该实验中,采用的神经网络均为残差神经网络ResNet-18,局部迭代次数为3次, batch-size设置为32,学习率为0.001.联邦学习设置中,本地节点数量为10个,每轮选择任意6个节点的训练数据进行聚合.实验结果如图5、图6所示. 图5 联邦学习与中心化学习准确率对比 图6 联邦学习与中心化学习损失值对比 由图5可知,联邦学习与中心化机器学习在火灾检测数据集上最终表现差异较小,然而随着本地节点数的增多,联邦学习较中心化学习有更高的效率.模型达到80%识别精度时,本地节点数为6和3的联邦学习分别需要7轮和11轮,局部迭代次数为3次和1次的中心化学习分别需要13轮和16轮.由图6可知,联邦学习与中心化学习对比,拥有更快的损失收敛速度.因此使用基于联邦学习的火灾检测算法在相同数据集条件下,提高了网络收敛速度,降低了训练时间成本,并且得到与中心化训练一致的训练效果. 图7为全局迭代次数为10轮的条件下,使用本地数据集进行中心化学习的模型识别率与10个节点使用各自数据集进行联邦学习的模型识别率对比.可以得到使用联邦学习训练得到的模型具有更高的识别率,并且随着参与节点数目的增多,准确率有明显的提升.相较之下,使用本地单一数据集的中心化训练无法很好学习数据全局分布特征,模型的泛化性与通用性较差.因此在火灾识别场景下,与中心化学习相比,使用联邦学习能较好的提升模型训练效果.并且,随着参与节点总数与每轮参与节点数量的增加,联邦模型的性能也会提升,但会增加每轮的训练时间,增加的训练时间取决于参与节点中最后完成局部迭代的节点时间. 图7 联邦学习与中心化学习预测性能对比 本实验对比了本方案与同态加密的时间开销.实验设置本地模型迭代次数为3次,本地节点数量为10个,每轮任意选择6个节点,总共经过20轮全局训练.AES密钥长度为128位. 表2为每组实验中神经网络超参数的设置.相同条件下,不同加密方案的联邦学习的时间开销如表3所示.本文采用的同态加密方案为基于Paillier半同态加密提出的一种联邦学习框架[14]. 表2 安全性能实验超参数设置(*表示对照变量) 表3 联邦学习各个安全方案时间开销(单位:秒) 图8基于表3数据绘制,折线图部分为随着表2超参数的调整,时间开销的变化趋势. 本文中设计的安全方案与不使用安全方案的联邦学习时间开销接近,根据表3中时间开销数据计算得到加密开销(1-(无安全方案÷本文方案))不超过1%,远低于基于同态加密[14]的联邦学习.另外可以看出,同态加密所需计算开销随着神经网络计算开销增长而增长.因此在计算昂贵的移动端设备采用此种方案能在保障安全性的同时尽量少的消耗运算资源. 图8 联邦学习安全方案时间花费对比 本实验对近年来其他火灾检测算法的效率进行对比.实验共选取3种不同火灾检测算法,包括图像分割法[1]、动态特征法[4]与改进YOLOV3[5]. 本实验关于火灾检测的性能分析采用文献[18]的评价标准,包含准确率(ACC)、正确率(TPR)、误报率(FPR)评价,其表示如式(13)、(14)、(15): (13) (14) (15) 式(13)~(15)中:N为火灾总样本数,TP为正确检测的火灾样本数,TN为正确检测的无火灾样本数,FP为被错误检测的无火灾样本数,FN为被错误检测的火灾样本数. 本实验联邦学习全局迭代轮次设置为50轮,联邦学习与中心化学习本地迭代轮次均为6次.batch-size设置为32,学习率被设定为前5轮从0.01线性下降至0.001,并在5轮后保持0.001. 表4为实验结果及性能对比.根据表4可以得到:本文算法误报率低至3.41%,较其他算法误报率更低,且与图像分割[1]和动态特征[4]方法相比精度更高.在训练集上得到过拟合程度更低的表现,因此具有模型泛化性强的额外优势,对于实际情况中复杂的火灾场景具有重要意义.根据表4得到,本文算法的识别准确率90.21%与正确率88.72%高于图像分割[1]与动态特征检测[4]方法,与改进YOLOV3[5]方法相比,准确率与其相近,正确率更高且错误率更低.并且,与文献[1]、文献[4]、文献[5]所用的中心化训练相比,本文所用的分布式训练方式可以更有效的收集边缘信息.因此,本文提出的基于联邦学习的火灾检测算法具有综合效果更好的优点. 表4 火灾检测方案对比 为了解决火灾检测背景下,传统机器学习缺乏训练样本,模型泛化能力弱的问题.给出一种基于联邦学习的火灾检测算法,通过多方节点使用自有数据集协作训练,提高了火灾检测模型的收敛速率与模型的泛化能力.在30轮全局迭代后,本算法准确率可以达到90.21%,正确率达到88.72%,误报率低至3.41%.使用基于门限秘密共享的安全方案,加密所需的时间开销仅为总时间的1%,用户可根据隐私需求灵活调整密钥长度.基于联邦学习的火灾检测算法在面向移动端的训练场景下能较好收集边缘信息,并提高模型整体的识别精度与泛化能力.

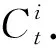
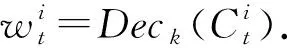
3 实验结果与分析
3.1 实验数据集
3.2 联邦学习实验结果与性能对比
3.3 联邦学习安全方案性能对比

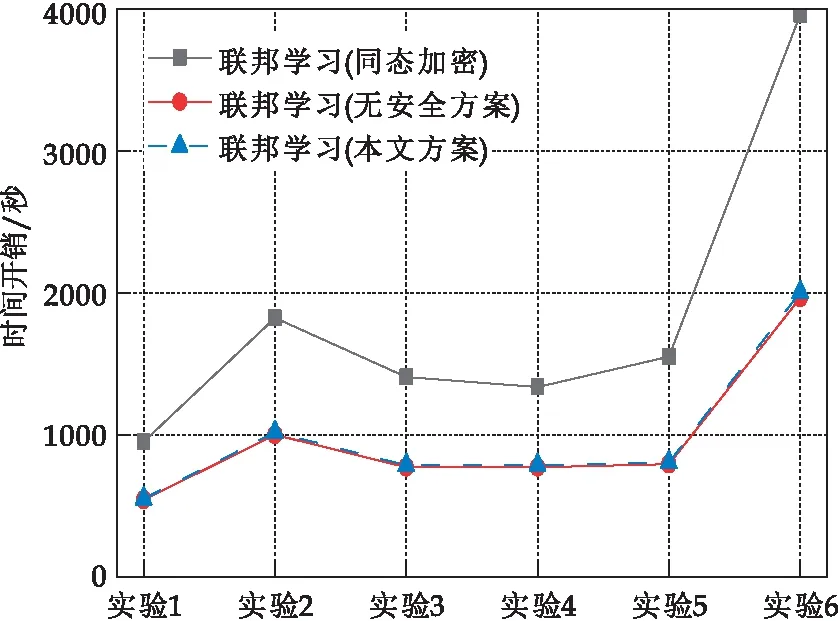
3.4 火灾检测算法性能对比

4 结论
猜你喜欢
湖南理工学院学报(自然科学版)(2022年1期)2022-03-16
故事作文·低年级(2022年1期)2022-02-03
家庭影院技术(2020年10期)2020-12-14
北京电子科技学院学报(2020年2期)2020-11-20
家庭影院技术(2019年7期)2019-08-27
太原科技大学学报(2019年3期)2019-08-05
小型微型计算机系统(2018年9期)2018-10-26
信息安全研究(2018年1期)2018-02-07
课堂内外(小学版)(2017年5期)2017-06-07
俄罗斯问题研究(2013年1期)2013-03-11
