
测井智能处理与解释方法现状与展望
2022-12-01 08:40韩宏伟王继晨冯德永刘海宁朱剑兵吕文君
三峡大学学报(自然科学版) 2022年6期
韩宏伟 王继晨 康 宇 冯德永 刘海宁 朱剑兵 吕文君
(1. 中国石油化工股份有限公司 胜利油田分公司物探研究院,山东 东营 257022; 2. 中国科学技术大学 自动化系,合肥 230027)
测井是进行地下储层解释与评价的手段,通过记录多种不同的物理参数来间接反映地质信息.常用测井方法包括电阻率、伽马射线、横纵波速度、自然电位等.测井资料的处理与解释是获得岩性类别、渗透率、孔隙度、泥砂比等地质信息的重要环节[1].其中,测井资料处理的目的在于消除多种非地质因素对测井数据造成的影响和偏差,使测井数据更充分准确地应用于测井解释[2].测井解释的核心工作是确定测井数据与地质信息之间的映射关系,从而建立解释模型,将二者有机联系起来[3].
随着大数据和信息技术飞速持续发展,当今世界正在进入数字化和智能化时代,人工智能(artificial intelligence,AI)逐步渗透并广泛应用于科学研究、工业生产、军事国防和人民生活等多个领域,智能化正在悄然改变着人们的思想观念和生活方式[4].如今,AI已经发展成为一门综合性学科,集计算机、信息技术、大数据等前沿技术于一体,也是21世纪引领未来高新技术发展前进的主流学科之一[5].自20世纪80年代开始,随着油气资源勘探和开发难度的提升,传统测井技术迎来极大考验,特别是传统测井解释大多依赖领域专家经验,具有偶然性强、人为影响大、效率低等问题.因此,人们开始将人工智能技术引入测井处理与解释领域,探索全新的解决方案[6].
经历数十年的发展完善,测井智能处理与解释研究成果层出不穷.刘争平等[7]较早在国内引入BP神经网络进行测井解释,一定程度上证实了机器学习模型的实用性、优越性.窦宏恩等[8]从全球视角指出,在国际油价低迷的形势下,AI将成为石油公司智能化发展、变革和转型的重要推力.李宁等[6]定量统计了测井解释研究成果并展示了发展趋势,同时主要从有监督和半监督角度,对岩相预测、测井曲线重构和物性参数预测方面进行了深入阐述.类似地,匡立春等[9]调研了石油勘探开发领域人工智能应用现状,Bergen等[10]系统性地分析并对比了各类机器学习技术在地球科学中的潜在应用价值.
这些综述主要从宏观的角度描述了该领域的研究现状并预测了未来的发展走势;然而,机器学习技术日新月异、文献数量增速极快,因此需要从更细致的微观角度进一步调研.本文首先全面回顾了人工智能发展现状,随后从测井处理与解释的5个重要领域出发,即测井深度匹配、测井曲线重构、物性参数预测、岩相类别预测、测井地层划分,分别描述了人工智能在这5个领域的交叉研究现状,并说明了其相较于传统方法的优势.最后,对测井智能处理与解释的未来发展趋势、当前面临的问题与对应的潜在技术路线进行了展望.
1 人工智能发展现状
1956年,美国达特茅斯学院举办了计算机模拟人类智能主题研讨会,并首次提出“人工智能”这一概念.人工智能的发展主要经历了3个阶段.第一代人工智能是基于知识与经验的推理模型,通常称为“符号主义”[11];一个典型示例如超级电脑“沃森”(Watson)[12],于Jeopardy挑战赛中以极大优势击败了人类选手.然而,符号主义AI主要依靠专家经验获取知识,模型通用性差、效率低下、不确定性高,难以得到大规模应用[13].第二代人工智能时间跨度较大,从神经网络先驱Warren McCulloch和Walter Pitts开始,主要受到连接主义的启发,依托于统计学习方法理论,以深度学习为代表,如:Google旗下DeepMind公司开发的AlphaGo[14],首次在围棋比赛中击败世界冠军;该公司于2017年开发完全基于强化学习且搜索增强的AlphaGo Zero[15],在各种棋类领域中均取得明显优势.类似研究成果还包括神经机器翻译模型GNMT[16]、标准图像库ImageNet[17]、Adam优化器[18]等.第三代人工智能结合第一代知识驱动方法和第二代数据驱动方法,同时兼顾知识、数据、算法和算力四要素,全方位反映人类智能,构造性能更为强大、鲁棒性和可解释性更稳健的AI[13],未来将广泛应用于智慧家居产业、数字化家用电器等众多领域[19].
目前,人工智能及其衍生学科已形成了极为庞大的知识体系,发展势头旺盛,在工业领域得以广泛应用.人工智能以机器学习理论为领域学科和技术发展的基础,在地球物理测井方向,利用机器学习相关算法处理数据集,自动分析数据集获得一定规律,训练出更精确的智能模型,能够为实际生产创造巨大的经济效益.机器学习主要分为无监督学习、半监督学习和有监督学习3种方式,三者的主要区别在于目标数据标签数目.综合近年来大量研究成果,图1分别展示有监督、无监督、半监督和强化学习4种框架下适用的方法和模型,主要包括神经网络和统计模型.

图1 机器学习常见模型与方法
为抢抓人工智能发展的重大战略机遇,构筑我国人工智能的先发优势,加快建设创新型国家和世界科技强国,2017年7月,国务院发布《国务院关于印发新一代人工智能发展规划的通知》[20].该计划拟分3步走,以期到2020年实现人工智能总体技术和应用与世界先进水平同步;到2025年人工智能基础理论实现重大突破;其最终目标是到2030年,中国人工智能理论、技术和应用总体达到世界领先水平,成为世界主要人工智能创新中心.
在当今信息化时代,人工智能是简化处理海量数据的利器,从而能够有力促进多领域可持续发展,有效改善人类生活.目前而言,人工智能正逐渐成为世界范围内促进经济发展的强大推动者[21].在地球物理测井领域,人工智能相关技术的持续飞速发展,也为其在该领域的广泛研究应用打下了良好基础,并逐渐出现取代传统测井解释方式的趋势[22].
2 测井资料智能处理方法现状
2.1 测井曲线深度匹配
作业过程中,测井工具通常会受到井下各种扰动的影响,特别是测井工具在井壁上的粘滞、卡钻和滑动,因此深度本身也可能存在错误,这便导致传统测井曲线大多存在深度偏差[23].如果测井资料深度不匹配,会将岩石物理分析建立在错误的测井资料上,从而导致解释结果错误.测井曲线深度匹配支持多物理数据的综合反演,提供一致性更好的通用地层模型,对于判别不同测井数据间的相关性极其重要[24].测井曲线的深度匹配是测井预处理的首要工作.
在石油行业,对多条测井曲线深度匹配,是一个长期面临的挑战[25].在传统测井中,测井曲线深度匹配方法大多是基于两个信号的经典互相关和协方差测量,然后进行手工调整,这也导致测井深度匹配成为劳动密集型工作,不利于高效自动化生产,也无法避免人工干预和人为错误.现有的很多针对测井曲线深度匹配的方法大都存在如下问题:1)对相关性依赖程度较高,在没有人为干预的情况下难以正常执行;2)计算成本高;3)精确率不够[24].已有研究方法中,互相关联和动态时间规整(DTW)方法[26],虽然取得了一定成效,但是时间复杂度较高,并且在许多复杂的场景中,仍然不可避免地需要测井专家的手工调整.
随着人工智能技术的飞速发展,以机器学习为基础的测井曲线深度匹配方法得到了广泛关注.已有研究工作如:Bittar等[24]在有监督框架下,拟合单井伽马测井曲线以代替同井多道测井曲线深度,该方案有很好的数据增强效果;同时开发特征选择模块以自动选择值得匹配的信号,对信号进行叠加和滤波,并设定指标系统控制质量,减少人工干预;在用户使用过程中,该模型能够不断地自我进化和完善,泛化能力较强.基于深度学习框架的测井曲线深度匹配模型具有较好的研究前景,Zimmermann等[23]训练一个全连接神经网络,用伽马测井同步实现多测井曲线的深度匹配,该模型巧妙操作数据,避免了人为干预,同时采用松弛精度准则以提升训练的性能和鲁棒性.类似工作还有Hong等[27]基于测井曲线本身在相邻深度点特征相似的假设提出的无监督深度神经网络,具有简洁易行、泛化性能好的特点.通过这些研究能够看出,机器学习模型具有较强的特征提取和模型拟合能力,能够有效避免传统方法存在的人工干预强、时间成本高等问题,具有较强的应用前景.对于深度偏差较大且地层较薄的情况,深度匹配的多解性还需深入研究.
代表性实例:Bittar等[24]建立“强化学习+深度匹配”框架,提出一种基于DQN(深度Q网络)的测井深度匹配方法.具体流程如下:使用一维CNN在输入测井曲线中提取特征,根据agent的移动状态对比空间状态给予奖励,使之能够找到最佳匹配点.DQN由多个一维卷积层和可学习滤波器组成,处理输入测井数据提取特征,从而在含噪声信号中找到匹配点.网络结构为双通道滑动窗口,第一通道为agent基于数据集的当前位置深度,即滑动参考井窗口;第二通道为试图匹配的目标深度,即静态目标井窗口.按不同方向不同距离滑动第一通道,直至找到匹配值,求得滑动参考井窗口的长度;网络的输出节点对应agent移动方式种类.最终成功找到相应匹配深度,同时有效避免了错误信息的干扰.该模型的网络结构框架如图2所示.
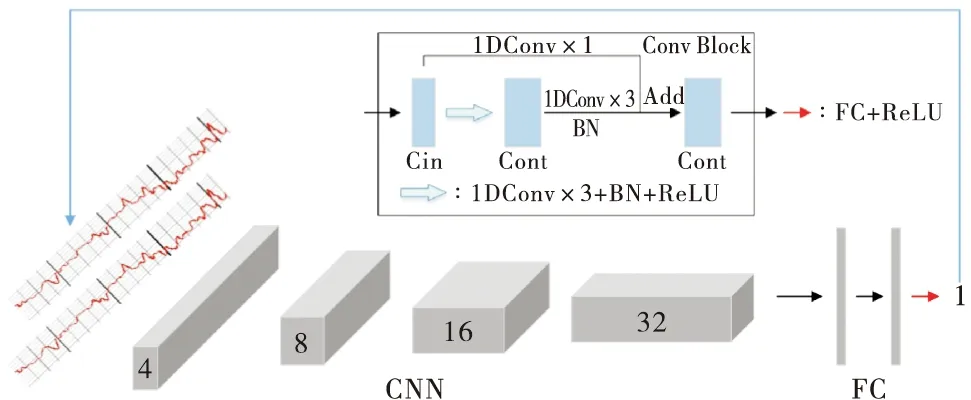
图2 DQN结构框架
2.2 测井曲线重构
在实际应用中,获取足够的测井数据具有极高的成本;此外,由于各种不可避免的原因,如井眼扩大、仪器故障、钻井测井过程中的操作问题,或出于经济考虑而未能实现完整测井[28],常常会导致在某些深度区间或整条测井曲线上,测井信息缺失或不完整,甚至可能会出现测井曲线丢失的情况[29].储层表征包括整合不同类型的数据,以了解地下岩性,为了将多种测井类型整合到储层研究中,估算缺失测井曲线是必不可少的环节.测井记录的缺失始终是油藏研究的一个主要问题,因此测井曲线重构具有极高的科研和工业价值.
针对测井曲线缺失问题,一种常见方法是重新测井,但这种方法通常成本极高,且对于某些已经过固井的油气井无法执行[29].传统的测井曲线重构方法使用经验统计模型,或自动建立不同岩石性质之间的关系,并利用相关性估计缺失的测井数据.经验统计模型通常建立在对大量数据进行统计分析的基础上,阐明各参数间简单的非线性关系,但需要大量的测井数据,并需要依托于专家经验,耗时耗力[30];岩石物理理论模型根据岩石的结构和矿物学理论,建立更复杂的数学模型来表征参数之间的关系,这种方法预测精度较高,但算法复杂,参数多,且计算效率低下[31].此方法的代表性工作如:Luo等[32]修正了原有P-L模型,简化了岩石干模量与岩石基质模量之间的关系,实际应用表明了新模型的稳定性和准确性,但还是未能完全避免上述问题.还有部分研究采用缺失数据的随机重建方法,以填充测井曲线的空白[33],如:Hurley等[34]通过多点统计填充成像测井的空白,最终可以生成完整的井眼图像;Kozubowski等[35]根据统计正态混合模型,估计钻孔剖面的岩石裂缝分布,但此类方法随机性很强,均难以保证结果的稳定性.
近年来,在数据驱动方法和计算机技术飞速发展的背景下,机器学习(ML)模型已然发展成为测井曲线重构的一类新型有效的方法,并且性能显著优于传统方法[28].主要研究工作包括:金永吉等[36]使用遗传算法优化传统神经网络的权值、拓扑结构和阈值等,在此基础上提出基于遗传神经网络优化方法的测井曲线重构技术,该方法能够克服传统神经网络方法易陷入局部最小值的缺点;何苗等[37]将测井曲线异常的井段划分为Ⅰ型、Ⅱ型和Ⅲ型,提出一种改进的MRGC聚类分析方法(MMRGC)进行相关性分析,选择伽马等3条测井曲线为输入,能够高效准确地实现对异常井段、异常曲线的重构;周欣等[30]提出了基于双向门控循环单元(BGRU)神经网络的声波测井曲线重构技术.实验证明,该方法鲁棒性和准确性更强,声波时差测井曲线重构效果更加精确.Feng等[33]在其他完整测井特征的基础上,利用随机森林算法对缺失的测井曲线值进行预测,并在Volve油田测井数据集上进行了验证.Chen等[28]证明长-短期记忆网络(LSTM)能考虑到测井数据空间的依赖性,并以地质力学参数反映的物理机制为先验知识,提出物理约束的LSTM方法,该方法可凭借较低的成本,准确地生成地质力学测井资料,且预测精度更高.
在现有机器学习方法的基础上,进一步改进和优化模型,往往能够有效提升识别性能.如:张海涛等[38]提出了一种基于DBi-LSTM神经网络的测井数据重构方法,可在不额外增加测量成本的条件下,充分考虑缺失数据点的前趋和后继之间的双向关联性,并通过增加双向长短时记忆神经网络深度以增强模型表达能力,实验表明该改进方法具有更好的数据重构精确度;Chen等[39]将集成神经网络和级联LSTM网络优势互补,构建集成长短时记忆(EnLSTM)网络,与常用模型进行比较,大幅降低了MSE指标并提升预测速度;Pham等[29]开发了一种基于全连接神经网络级联的双向卷积长短时记忆(双向ConvLSTM)网络,以挪威大陆架Volve油田、英国大陆架成熟地区(UKCS)、加拿大海上Scotian大陆架Penobscot油田,及怀俄明州Teapot Dome数据集的一系列测井数据作为测试对象,可以对伽玛、中子孔隙度、密度等声波测井曲线进行准确预测.针对大多数钻井缺乏Vs数据的问题,Wang等结合卷积神经网络(CNN)和LSTM网络,提出一种自适应的集成卷积双向记忆网络(ECBMN)[40];还结合CNN和GRU网络,开发出基于深度卷积GRU(DCGRU)方法[31],在实际油藏的数据集上进行测试,这两种方法相比于单一算法,能够提供更可靠和准确的Vs预测值.针对测井资料缺失的问题,Wu等[41]将CNN和LSTM神经网络相结合,提取了测井数据的时空特征信息,并采用粒子群算法(PSO)确定最优CNN-LSTM体系结构的超参数,最终实现了对多井可靠、高效的测井曲线预测,对复杂性强的油藏也能显著减少优化时间.对比传统方法,深度神经网络能够有效提取曲线的形态信息,循环神经网络的引入也能有效利用沉积韵律,因此达到更好的重构效果.然而目前的重构更多是对形态的重构,在缺失目标井缺失曲线取值范围时,其绝对误差难以保证.通过岩心检测的手段可以获取目标井极少量缺失测井信息,因此需要进一步研究跨域半监督学习问题.
代表性实例:Shan等[42]通过将双向长短时记忆(BiLSTM)网络、注意力机制和CNN融合,构建出缺失测井曲线预测混合神经网络CNN-BiLSTM-AT.该网络具有以下双分支的结构:一个分支利用CNN获取测井曲线的空间属性,另一个分支利用带有注意机制的双层BiLSTM进行特征选择;然后合并两个分支的时空相关性以预测目标测井曲线.实验中训练了自然电位测井曲线(SP)、声波测井曲线(AC)、伽马测井曲线(GR)等6个模型.测试结果表明,该方法考虑了测井曲线的时空信息,具有较高的预测精度并可适用于任何区域.
3 测井资料智能解释方法现状
3.1 测井物性参数预测
确定油气储层的性质在勘探工业中极为重要,其中孔隙度和渗透率是储层的关键物性参数;储层非均质性是指孔隙度、渗透率、流体(油、气、水)饱和度等岩石性质在空间上的非线性、非均匀分布.这一性质是由复杂的地质条件和沉积环境所导致,与测井响应特征之间也存在明显的非线性关系,采用线性测井响应方程和经验统计公式不能有效表征储层,难以有效地描述地质条件、沉积环境和储层岩石性质之间的非线性关系,存在较高的不确定性,从而无法满足实际生产需要;而简单的线性方程、经验公式只能应用于某些特定的油藏,并且推导难度大、耗时长,同样难以达到要求[43].
传统的物性参数预测方法主要包括岩心实验和测井资料解释两种途径.如:Huang等[44]基于委内瑞拉稠油带和加拿大油砂带储层厚大、胶结疏松、中细砂岩、高孔高渗等特征,建立了相应的储层评价指标,包括孔隙度、渗透率、泥质含量、饱和度、隔夹层、连续油层厚度和宽度等;然后利用地球物理测井传统解释技术对储量进行了评价和分类.此类方法虽然对储层评价有一定效果,但是太过于繁琐,过度依赖专家经验,时间成本、人力成本过高,不利于推广使用.类似工作还包括:Cedola等[45]开发了一个经验模型,综合UCS-伽马对比,更好地反映页岩孔隙度之间的对比关系,更准确地预测混合岩性和页岩储层段的孔隙度变化.然而,岩石的非均质空间分布导致岩石的性质很难预测,传统的分析技术,如多元回归分析等方法,在这方面的适用性也受到限制.
近年来,在数据驱动方法快速发展的背景下,基于机器学习理论的回归模型,俨然发展成为预测岩石渗透率等物性参数的新型方案.单一模型的使用或模型的细化、具体应用,有逐渐取代传统方法的趋势[46].已有研究采用神经网络、支持向量机(SVM)等机器学习方法.Otchere等[47]总结了现有工作得出结论,在数据有限时SVM比ANN更有效,并对比了这两种机器学习算法的实际应用效果.Al-abduljabbar等[48]基于来自A、B井的现场数据,使用ANN前馈技术从钻井参数预测孔隙度,以A、B井测井数据集分别作为训练集和测试集,结果证明该方法能够有效且高精度地预测孔隙度,并具有较低的均方根误差.在模型细化及改进方面,Sun等[43]选取延安气田延969井区的随钻测井数据进行训练,并比较各种模型对随钻孔隙度和渗透率的预测结果.Bagheripour等[49]提出混合遗传算法-模式搜索(GA-PS)技术,以建立岩心孔隙度与岩石物理测井之间的模糊规则,可以提取模糊聚类的最优参数,转化为最优模糊公式.Wood[50]提出一种新的多测井曲线数据匹配算法,在标准测井曲线和岩相、地层信息的数据集上开展研究,目标在于预测Ke、Sw和EP 3种物性参数.成果应用于解释阿尔及利亚Hassi R'mel气田100米剖面三叠系储层,有效证明了该方法在物性参数预测方面的可行性.
为了解决单一物性参数预测模型的多解性问题,闫星宇等[51]将XGBoost算法应用于致密砂岩气储层,基于某工区测井解释资料,通过XGBoost算法建立回归预测模型,最终准确预测了该区孔隙度与渗透率等物性参数,并能够有效识别该工区致密砂岩气层.Zhong等[52]提出了混合核函数支持向量机(MKF-SVM)模型,构建了常规测井数据与稀疏岩心数据之间的关系模型以预测储层孔隙度,并使用粒子群优化(PSO)算法对模型进行优化,有效提高了MKF-SVM模型中5个控制参数合适值的定位效率,综合得到PSO-MKF-SVM模型.另外,Ahmadi等[53]综合使用多种机器学习算法建立了混合模型,其中包括ANN、模糊决策树、遗传算法、帝国主义竞争算法(ICA)、PSO算法混合模型分别与单一模型综合比较.结果表明,在物性参数估算中混合应用机器学习方法,建立的静态油藏模型更加可靠和有效.
随着深度学习理论发展,深度模型的预测精度和识别能力不断提高,深度学习策略不断被应用到实际问题中,并已经取得了突破性进展[54].为了预测储层孔隙度,王俊等[55]提出深度双向循环神经网络(DBRNN)模型,即叠加多个双向RNN,有效解决孔隙度预测的空间尺度问题,兼顾时间尺度效应.相比于BRNN、DNN等模型,其准确性和有效性突出.Pinheiro等[56]提出基于角竞争神经网络的密度-中子测井方法,通过合成数据方法识别储集岩中所有可识别的黏土矿物,并在巴西Campos盆地Namorado油田进行评价.安鹏等[46]证明了长短期记忆(LSTM)循环神经网络在储层参数预测方面的准确性和稳定性;此后Chen等[54]开发了多层LSTM模型(MLSTM)预测孔隙度,在中国南方某区块的测试表明,MLSTM在深度序列预测方面具有更好的鲁棒性和准确性,可实现高效、低成本的孔隙度预测.Konate等[57]比较了广义回归神经网络(GRNN)和前馈-反向传播神经网络(FFBP)在镇靖油田孔隙度建模中的应用效果.门控循环单元(GRU)神经网络等深度学习模型也取得了良好的效果[58].
测井物性参数预测和测井曲线重构本质上都属于回归问题,因此这两部分的研究具有一定的重合度,也证明了深度学习方法的有效性.区别在于:测井曲线重构的训练集标签可以是完整的曲线,因此标签比较充分,连续性较好;物性参数需要通过对岩心的测试得出,因此成本较高,数量少且往往不是连续的.另外,考虑到成本问题,往往只对目的层甚至是目标储层进行取样实验,因此训练集的有标签样本的相对于无标签样本不满足独立同分布假设,因此标签稀疏、标签分布不均是测井物性参数预测后期需要研究的问题.
代表性实例:Zhang等[59]提出了基于GRU神经网络的多测井参数组合预测方法.首先,采用基于Copula函数的相关测量方法,选取与孔隙度最相关的测井参数;随后利用GRU神经网络,识别测井数据与孔隙度参数之间的非线性映射关系.在鄂尔多斯盆地某勘探区应用结果证明,该方法优于多元回归分析和递归神经网络方法,表明GRU神经网络在预测孔隙度等一系列储层参数方面更为有效,不仅可以同时充分利用不同测井参数对不同地层的响应特性,而且能够摆脱传统经验公式线性预测的局限性.3层GRU神经网络模型结构图如图3所示.
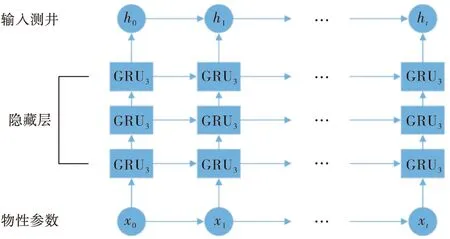
图3 3层GRU网络结构图
3.2 测井岩相类别预测
图储层岩相资料是地层对比、沉积模拟、有利区预测等地质工作中不可缺少的资料.随着油气资源开发难度的提升,对复杂岩相预测技术提出了更高的要求.依托于专家经验或人工干预的传统测井解释方案,难以适用于复杂化的储层地质条件和多样化的测井资料;并且在实际测井中,获得实际的岩相类型,成本通常非常高昂,相关工程极为繁琐[60].因此,实现岩相预测解释技术的突破与升级,成为测井勘探研究与应用的重难点.测井岩相识别是油藏描述、地层评价、储层建模和实时钻井的基础工作,也是油气勘探早期的一项重要工作,能够对储层岩石物理特征进行直观表述,在油气勘探领域意义非凡[61].井眼岩相解释是指在已被解释的测井数据上建立分类器,建立一个从测井曲线到岩相的目标映射函数,预测未解释测井数据所对应的岩相类别.
传统岩相预测主要采用重力场、测井、地震、遥感、电磁,以及各类地球物理和地球化学方法[62].已有研究侧重于从现有知识领域中建立岩性识别的统计模型,但通常需要大量的人工操作,较为繁琐;且不同地区测井数据分布差异大,因此提出的模型在不同地区的井上往往不具有通用性和普遍性.对复杂岩性剖面或新型油气藏储层应用已经成熟的解释方法,是传统测井岩相预测的主流思路[1],其中代表性工作如ECS(地层元素)测井方法.已有研究如赵军等[63]在ECS测井基础上提出一种快速评价模型,即利用岩石薄片资料校正ECS测井所选矿物组合,并利用矿物和指示元素相关关系构建方解石和石膏的评价模型,其解释结果与录井、岩心分析结果吻合度更高,过程相对简便易行.此外,王泽华等[64]提出“常规测井+成像测井+ECS测井+岩心标定”的火成岩岩性预测基本架构,综合以上方案,极大提高了复杂火成岩岩性预测的准确率.但上述方法不可避免地受到人为干预,且对测井、录井资料要求较高.
目前,机器学习逐渐成为解决空间预测、地震处理、地层对比、测井解释等多种地球物理问题的有力工具,结合机器学习模型进行岩性识别,逐渐呈现出替代部分传统地质统计学和传统地球物理方法的新趋势.与传统岩性识别方法相比,结合机器学习模型进行岩性识别不仅减少了领域专家的数据分析工作,而且大幅提高了岩性识别效率,因此实际应用价值极高[65].其中,朱怡翔等[66]基于强非线性环境下的SVM测井数据,得到高精度的火山岩岩性识别结果.蔡磊等[67]经相关研究发现,ELM算法能极大简化参数选择,从而明显缩短训练时间,在岩相预测方面的整体性能要优于SVM;此后,徐鹏宇等[68]使用ELM模型,实现了对川中北部GM区块灯影组灯二段储层岩性的精细分类评价及其物性参数解释,为测井综合评价提供了科学有力的支持.Choi等[69]使用测井数据中多种弹性性质进行非线性转换,基于岩相多元概率密度函数(PDF)贝叶斯推理法预测震区岩相概率体积.另外,Han等[70]基于XGBoost算法,在辽河盆地火成岩岩相上进行岩性识别,从而得到了岩性识别的精确实用型方案.
进一步优化和改进模型,或者多模型混合应用,通常可以有效提升岩相预测性能.陈科贵等[71]建立基于主成分分析(PCA)的ELM模型,分析测井数据得到主成分并输入ELM模型进行测试.相较于常规的测井解释方法,PCA-ELM模型实现了岩性识别的自动化与高效化.吴施楷等[72]提出了基于连续限制玻尔兹曼机的支持向量机(CRBM-SVM)模型,其引入连续限制玻尔兹曼机(CRBM)提取测井数据岩性特征,并基于SVM对优化后特征进行岩相预测,有效解决了物性相似岩相测井响应差别小的问题.Liu等[73]提出了一种基于多核关联向量机(MKRVM)的相识别方法,通过多核学习(MKL)方法将原始数据映射到组合空间,在新空间中更准确地表达特征,有效提高了分类精度.Zou等[74]提出了基于梯度增强决策树(GBDT)的岩相预测方法,利用网格搜索和交叉验证建立GBDT分类器以选择最优特征和超参数.针对致密砂岩储层岩性识别,谷宇峰等[75]提出了混合模型CRBM-PSO-XGBoost,该模型可在最短的耗时内得到最佳预测结果.针对测井数据模糊性和不确定性,Ren等[61]综合决策树、模糊理论K-means++算法,提出了一种新型的混合岩性识别模型,较好地改善了此缺陷.类似工作可见参考文献[76]、[77]等.
深度学习模型能够从海量数据中高效自动地提取特征,并通过逐层特征变化解决复杂的分类或预测问题,从而有效解决多维非线性问题和大数据问题[46].武中原等[78]基于长短期记忆神经网络(LSTM)构建了能够提取和学习岩性沉积序列特征的岩性识别手段,提升了岩性识别效果,为复杂碳酸盐岩储层的表征和评价提供了数据基础.Zhu等[79]提出了一种基于小波分解的方法,为每个测井点构造多层图像,并输入CNN中,从而将测井岩性解释问题转化为有监督图像的识别任务,该方法在大庆油田的实际应用中取得了良好的效果.Gu等[80]综合了3种模型的优点,取长补短,提出了基于连续受限玻尔兹曼机和粒子群优化改进概率神经网络,即CRBM-PSO-PNN,实验证明该方法对复杂岩性的预测是有效的.其他工作还采用了概率神经网络(PNN)[81]、深度卷积神经网络[82]、全卷积网络(FCNN)[83]等一系列常见深度学习模型.
有监督学习一般需要大量标记测井数据作为支撑,然而大多数地球物理问题存在数据集不均衡、标签稀缺,使用半监督或无监督学习算法训练分类模型,可以大幅提高各类别预测的准确率,从而构建更精确的岩相预测模型[84].例如,Chang等[85]在新井无岩性标记的前提下,将无监督域自适应方法引入岩性识别,开发了双流多层神经网络,并根据最大均值差异优化方法训练网络.该方法应用于渤海湾盆地济阳坳陷,有效缓解了该区测井数据分布差异所导致的性能下降问题.Li等[86]提出了一种基于深度平滑特征的半监督加权极限学习机(FD-S2WELM)的半监督学习方法,以解决标签稀缺的岩性识别问题,体现了该方法卓越的安全性和准确性.Liu等[87]提出了一种名为数据漂移联合适应极限学习机(DDJA-ELM)的迁移学习方法,将项目均值最大均值差异、联合分布域自适应和流形正则化引入极限学习机(ELM),大幅提高了源域模型应用于目标域岩性识别的精度.另外,Xu等[88]综合对比5种主动学习算法,采集胜利油田和杭景吉气田的测井数据,不断调整超参数评估实验结果,指出不确定性方法和不确定性熵是测井岩相识别主动学习的最优选择,能够在保证分类精度的同时显著降低标注成本.
测井岩相类别预测已经得到了较为充分的研究,但是仍然存在以下问题:
1)与物性参数预测类似,岩相信息需要通过对岩心的观察得出,因此标签是稀缺的;岩屑录井虽然丢失了岩石本身的结构信息,但是仍然能够从中获取类别且纵向分辨率上较粗的岩相信息;另外,测井学家也能通过其经验对测井曲线直接解释,获取一定连续性好的标签.可见:这3种标签各具特点,能够有效丰富训练集中的有标签样本数量,增加模型训练的准确度.
2)由于测井设备、钻井液等非地层因素的影响,不同井的测井曲线形态、分布上存在较大差异,即使在同一口井不同地层上也能发现这种差异,然而现有工作很少考虑这种非独立同分布假设引发的模型泛化能力下降的问题,这将是今后的研究重点.
在测井智能处理与解释方法中,测井岩相识别研究最多,下面举几个代表性例子.为解决地下岩相分布的强空间异质性,Chang等[89]提出一种新的地球物理测井分割网络SegLog.该工作设计了一个像素增强的卷积子网络以学习像素级测井值所表示的微观细节特征,将其与骨干U-Net提取的宏观语义特征融合,构成兼顾描述测井空间相关性和像素特异性的表征在济阳坳陷实际数据集上的大量实验,验证了该模型的优越性.
针对模型通用性差的问题,Xie等[76]基于具有离群数据集的多类岩性分类模型,提出一种结合异常值检测、极随机树于一体的智能测井岩性识别框架.采用无监督学习方法来检测数据集中的异常值,然后采用极随机树分类器进行粗到细的推断.该模型在DGF和HGF区域的岩相预测准确率分别高达89.4%和91.1%,显著优于其他几种分类器,因此具有较高的精度识别砂岩类的能力.该模型基本原理及流程如图4所示.
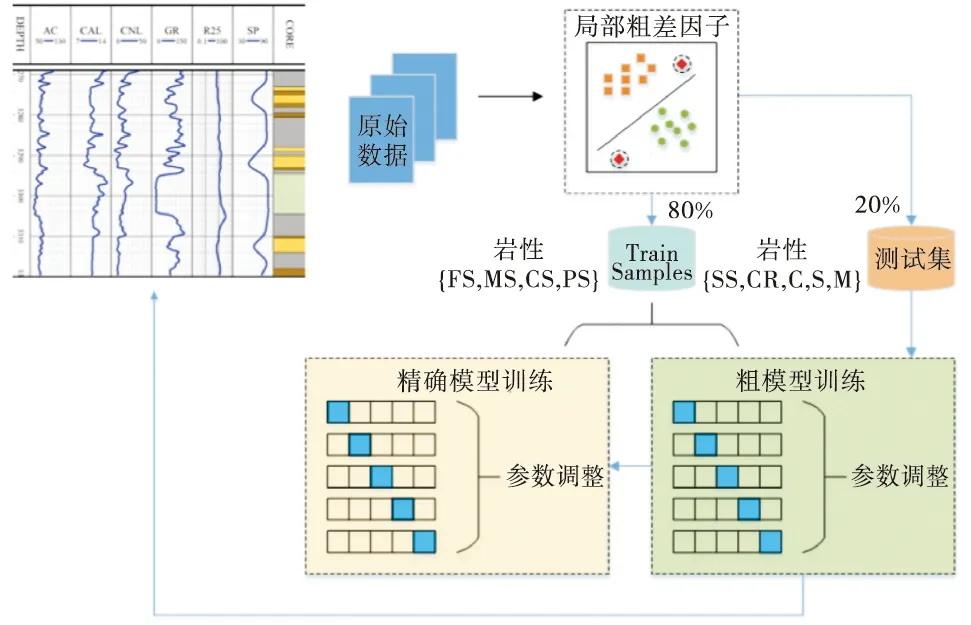
图4 基于极随机树的智能测井岩性识别框架
3.3 测井地层划分
层序地层学是地质学的一个分支;测井层序定义为由不整合面或其相关的相关整合面包围的一般相关沉积地层序列,测井地层划分的目的是根据层序界面将沉积岩划分为不同体系域[90].由于在测井响应中存在较多噪声,难以清晰识别地层交界面,因此地层边界信息的准确性在油气勘探领域具有重要意义.利用测井曲线划分地层是测井分析的首要步骤,也是储层表征和储层建模的重要步骤,是油气勘探中解释地质或地球物理资料的一项必不可少的常规工作[91].
传统测井地层划分,大多结合了特征分析方法或数理统计方法.特征分析法多采用小波变换、傅里叶变换等提取测井曲线特征[92];傅里叶变换不能在时域和频域优化结果,因此不能很好地处理测井曲线的突变点,而小波变换可以有效处理非平稳信号[93].例如:在渤海海域垦东凸起东部斜坡带的浅水三角洲地区,杨建民等[94]针对该区复杂的储层特性,根据测井和地震资料提取频谱特征,识别地层旋回性以划分层序界面,并基于连续小波变换进行层序识别,建立高分辨的等时地层格架,最终得到较精确的地层旋回划分结果.Ali等[95]采用连续小波变换和离散小波变换方法,将伽马测井曲线和孔隙度测井曲线分解为一组尺度不同的小波系数,得到更小的频率带宽.实际应用结果证明,小波变换是一种快捷简便有效的方法,能够从测井资料中有效识别主层序界面.Zhang等[95]针对东营凹陷大厚砂砾岩地层差异不明显、层序界面不清晰、水平对比标志不连续等一系列问题,提出DB5连续小波变换方法,对GR测井曲线进行多尺度分析,有效划分了砂砾岩沉积物,克服了人工划分的局限性.此外,将小波变换方法结合其他信号处理方法,往往能够得到更加精确的地层划分结果.例如,薛波等[96]在小波变化的基础上,首先对测井曲线进行形态学滤波,消除影响分层的奇异样本,有效降低了划分出假地层的概率.Pan等[91]结合小波变换和傅里叶变换方法,对油田自然电位测井和GR测井进行分析,获得了清晰的地层界面识别信号,结果优于常规方法和小波变换方法.类似研究工作还可见参考文献[97]、[98].然而,进行小波变换必须选择特定的小波基,因此导致结果差异性较大;同时,进行地层划分时无法综合多条测井曲线的特点,而且划分主要依靠极值点,从而可能导致划分出假界面的情况,这就决定了进行小波变换必须要有人工干预[96].
数理统计法利用数字化测井信息的层间和层内方法作为统计量,进行定量分析,建立地质旋回与数学最优化结果的对应关系,实现层序地层单元的划分.Partovi等[99]采用方差分析工具和多重比较方法,评价分层过程中各参数的有效性,表明该方法自动搜索地质边界能力较强.Velis[100]等寻找数据中变化点来自动检测平稳段,用统计检验方法设置两个相同概率分布的显著性标记,通过保持产生低概率的变化点来决定数据分段数量,从而可以为识别岩性单元和层序提供辅助.类似研究可见朱常坤等的科研成果[101].
在上述测井地层划分传统方法的基础上,引入机器学习技术,即成为测井地层智能划分方法.现有的测井地层智能划分方面的研究有:Yang等[102]采用了协同小波变换和改进K均值聚类方法,对中国大陆科学钻探主孔变质岩进行分类,提高了CCSD-MH变质岩分类的准确率,减少了计算时间并成功分类整个中国大陆科学钻探主孔的变质岩,有效实现了岩性界面识别.Karimi等[103]将主成分分析(PCA)方法应用于碳酸盐岩储层多条测井曲线的自动井间对比,减少了对单井测井数据统计属性的依赖,显著提高了不同井的岩性界面识别能力.Elkatatny等[104]开发出鲁棒性极强的人工神经网络(ANN),确定了地层顶部界面.另外,Zhou等[105]提出一种用于地质统计序列模拟的机器学习方法,在递归神经网络的基础上,依次建立了地层类型和地层厚度的序列模型,并引入专家驱动学习,从而在一定程度上提高了模型的预测能力.类似研究工作可参考文献[106]等.无论是人工的、还是自动的测井地层划分,本质上是一个无监督学习问题,更准确地说是聚类问题,这类问题很难通过指标对其划分结果进行评估,往往是通过其划分结果在地质学上的一致性进行人工评价.因此这类研究较为特殊,研究程度相对不足.后续有两点值得深入:1)找到更为一般的评价方式,反之指导地质学家建立新的地质认识;2)为其它测井解释服务,通过地层划分预先减小数据的分布差异,进而降低跨域学习的难度.
代表性实例:Zhang等[107]提出一种卷积神经网络(CNN)模型,能够有效地从地球物理测井数据中检测地层界面.该方法可自动从测井数据中提取代表性特征,归一化数据后将数据点转换为二维段,并将其作为单频道图片输入卷积神经网络网络进行训练,利用训练好的模型预测地层界面.模型结构图如图5所示.

图5 基于CNN的地层检测模型基本流程
实验结果表明,地层界面检测平均预测精度高达89.69%,并且地层分类的正确率和召回率均较高,预测的边界点与真实值之间相对误差仅为1%,可以满足实际应用要求.
4 总结与展望
目前,虽然已经进行了大量人工智能与测井处理解释的交叉研究工作,但是从实际应用来看,这些技术方法难以落地,主要存在标签稀缺、分布差异和解释性差这3个问题.
第一,在大多数工况下,出于录井与人工解释成本的限制,标签数量相对于测井样本数目通常较为稀缺,不同来源标签可靠性不一致,且有标签样本数量不足以支撑较大模型的训练.针对此类问题,可以采用半监督学习方法,即组合少量有标签数据和大量无标签数据,从中学习数据分布特性并构建模型.其中,海量数据有助于模型保持数据原有几何结构,少量有标签样本可使模型提取具有可分性的特征,总体上有效提升模型的拟合能力,提高对未标记样本的预测精度.为了有效利用未标记样本信息,半监督学习通常基于分布假设,如:平滑性假设、聚类假设、流形假设等.毕丽飞等[84]提出“聚类-人工标注-伪标注-分类”的半监督学习岩性预测基本框架,实验发现,该模型通过综合挖掘有标注和无标注数据的分布特性,可获得更精确的岩性预测效果,在不均衡数据集上也能大幅提高岩相预测准确率.Koeshidayatullah等[108]针对数千幅碳酸盐岩图像,构建用于目标检测的DNN模型,在训练集较小且分布不均衡时,也可以有效检测识别白云石、生物碎屑、孔隙、方解石等岩石成分.测井样本标签有限且无法充分精确反映地层信息时,相较于无监督学习和有监督学习,引入半监督学习方式能够更充分地利用现有数据,有效解决测井处理与解释中标签不足的问题.
第二,由于沉积环境、井眼条件和测井设备等均存在一定的差异,基于已解释测井数据训练所得模型用于其他样本的解释任务时,往往会出现预测精度下降的情况,该状况可归类于机器学习中的数据偏差问题[109].由于不同地区之间测井数据概率分布差异较大,因此所提出的模型往往不具有普遍性,导致在某一地区建立的模型无法适用于其他地区,模型自适应性、通用性难以保障,甚至会导致同种岩相在两口井之间或同一口井的两层之间表现出不同的测井特征.一种解决方案是对所有地区都进行实时实地测井,但是成本极高,并且测井难度大,不符合现实.针对此类问题,域适应学习是一类有效的解决办法[110].域适应着重强调从源域适应到目标域的学习过程,一般源域含带丰富的标签,而目标域标签稀少,通过某种方式将源域的先验知识迁移到目标域,就能够实现对目标域模型的性能提升.类似成果如:Wu等[111]提出了一种稳健单向对齐(RUA)的岩相分类方法,将数据映射到高维,在高维子空间中将目标域样本特征向源域对齐,从而达到域适应的目的,在渤海湾盆地济阳坳陷的几个测井数据集上开展实验,验证了该方法在精度和稳定性方面的优势.Chen等[112]提出一种基于ELM的空间学习算法—域空间转移极限学习机(DST-ELM),用于处理无监督域适应问题,在保持高效率的同时,准确性方面也能优于现有的几种域适应方法.另外,也可以引入深度强化、自适应神经网络、迁移学习等相关算法,使模型在构建数据库的过程中,逐步提高分析和自适应能力.因此,域适应学习作为减小测井数据分布差异的有效手段,能够有力提升模型泛化性能,可以成为解决数据漂移问题的有效途径.
第三,绝大多数人工智能算法可解释性较差.一方面,多数神经网络模型是黑箱模型,其运行机理并不明确,超越了现有逻辑的可解释范畴;然而测井处理与解释本身是风险敏感领域,其解释成果的可靠性会直接影响后续勘探工作,因此在实际生产中难以建立对人工智能的信任感,从而对其应用范围有所制约.另一方面,端到端训练是人工智能的重要优势,能够减少大量中间工作,然而传统的流程虽然会消耗一定的人力物力,但是其流程已经过大量实践验证,也能够得到专家的理解与认可;而端到端学习,本质上是摒弃了已有的工作流程,导致专家难以理解,且无法通过流程中间结果的评价以实现对整体流程的人工约束与控制.综上所述,可解释性是未来测井智能化的一项重要挑战.已有工作中,Wu等[113]开发了交叉熵聚类-高斯混合模型-隐马尔可夫(CEC-GMM-HMM)模型工作流,并开发基于区域的预测建模方法,模仿传统测井解释工作流,保证了可解释性,能够有效促进分区分配、偏远数据检测和地层属性解释.Zhang等[114]针对地球物理测井曲线校正问题,进行多方位统计解释,提出了一种可解释的机器学习方法—单向对齐(UA),可以在无监督框架下,有效对齐井间测井曲线,且能够不丢失原有物理意义,实验结果准确率高、可解释性强.因此,使智能模型的处理过程对测井专家更加可信和开放透明,对人工智能在测井处理与解释中的规模化部署和工业级应用意义重大,相关设想包括重新构建崭新的逻辑体系,并对模型的可信任度进行量化[115].如今,伴随第三代人工智能技术的发展与推广,机器学习算法和模型不断升级更新,传统机器学习模型的可解释性也必定会迎来一个全新的质的飞跃[13].
猜你喜欢
测井技术(2022年5期)2023-01-10
测井技术(2022年3期)2022-11-25
测井技术(2022年3期)2022-07-16
科海故事博览·上旬刊(2022年5期)2022-05-17
——北美又一种非常规储层类型
石油与天然气地质(2021年5期)2021-10-29
非常规油气(2021年2期)2021-05-24
化工管理(2021年7期)2021-05-13
中国海上油气(2020年5期)2020-10-20
科学与财富(2018年2期)2018-03-16
环球人文地理·评论版(2016年10期)2017-03-20
