
基于荟萃方法的专利发明人综合评价模型研究及实证
2022-12-01 08:31杨毓丽吴华蕾
情报杂志 2022年11期
杨毓丽 彭 博 吴华蕾
(大连理工大学图书馆 大连 116024)
0 引 言
人才作为技术发明创造的主体,是高校创新发展与影响力提升的重要着力点。因此如何构建一套科学的、行之有效的评估方法进行人才专利质量的比较和评价,一直以来都是学术界的研究热点之一。为此,本研究在梳理专利质量内涵与评价方法的基础上,进行了基于综合评价指标构建研究,以期为专利质量评价研究提供参考。
1 发明人专利质量评价方法
目前学术界对如何衡量专利质量尚无一致的结论,但在众多表征专利质量评估指标中,引文被广泛认为是衡量专利对后续技术发展影响的一个有用指标,被引次数反映专利质量信息可以从多个角度予以解释:文献[1]认为核心专利是在某一领域具有首创性的,被后续科技引用及产业化集聚必不可少的专利。一项专利获得的正向引用越多,在一定程度上说明该专利对特定技术的创新就越有价值。文献[2]认为专利间引用关系实质上是技术知识分析、对比、鉴别、判定和选择的共同参与行为。引文是专利知识的溢出,是专利质量的重要影响要素。由于专利对背景技术的引用很可能成为审查员以引用专利为对比文件,作为否定该专利新颖性、创造性的判断依据,因此,发明人在引用时非常谨慎,以防止在后续程序中引起争议。由此可见,专利引用表征着引证专利在技术上的关联性,被引专利是基础技术,对引用专利的权利要求保护范围有限制作用,因此文献[3]认为被引是原始专利具有开创性本质的外在表现。
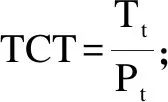
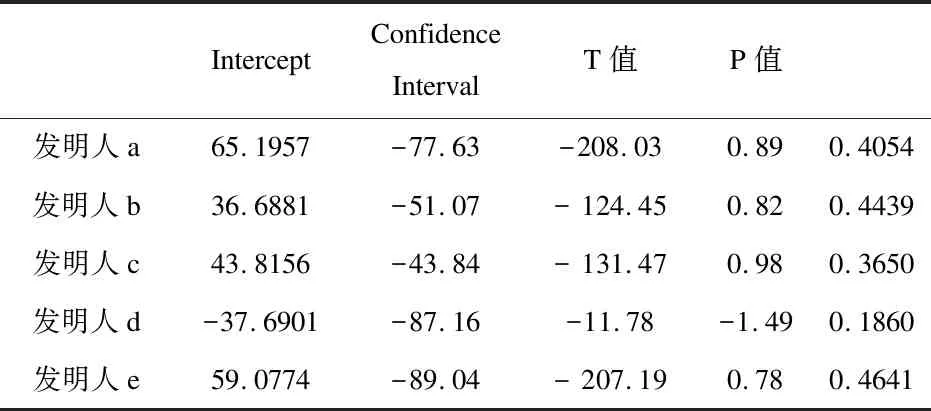
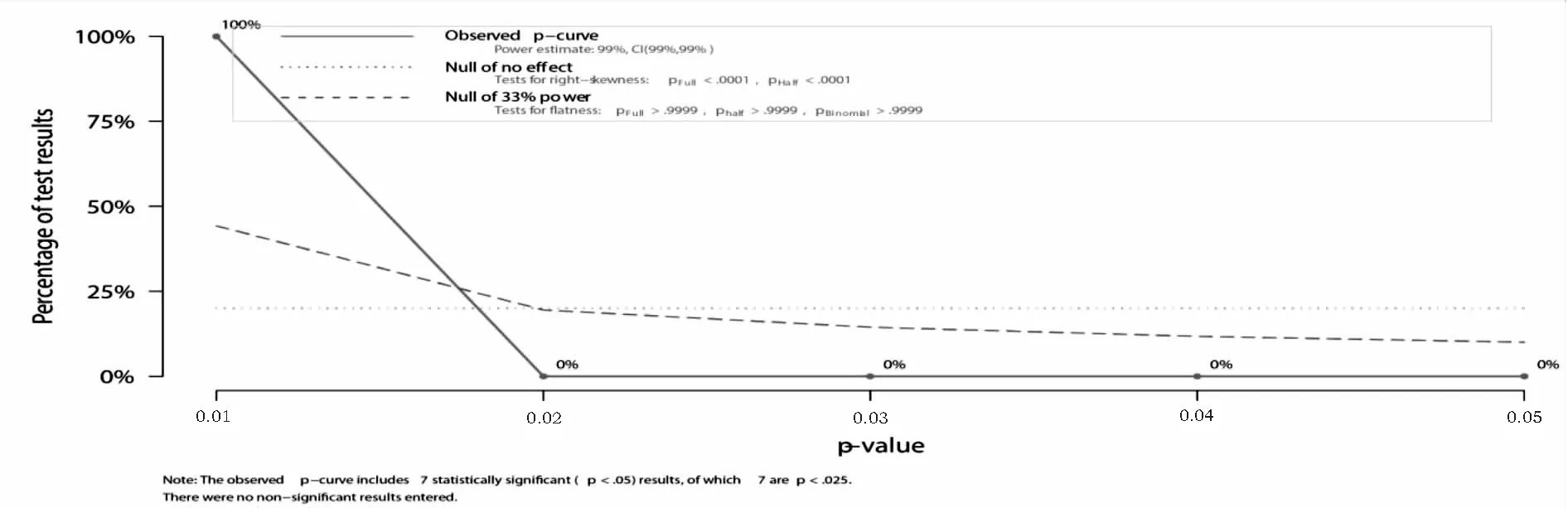
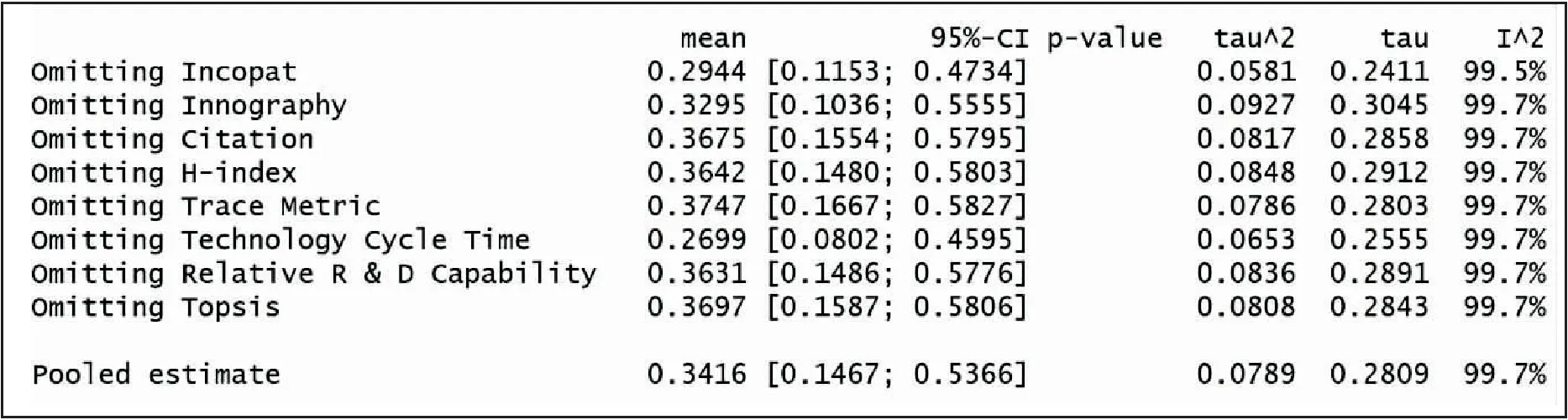
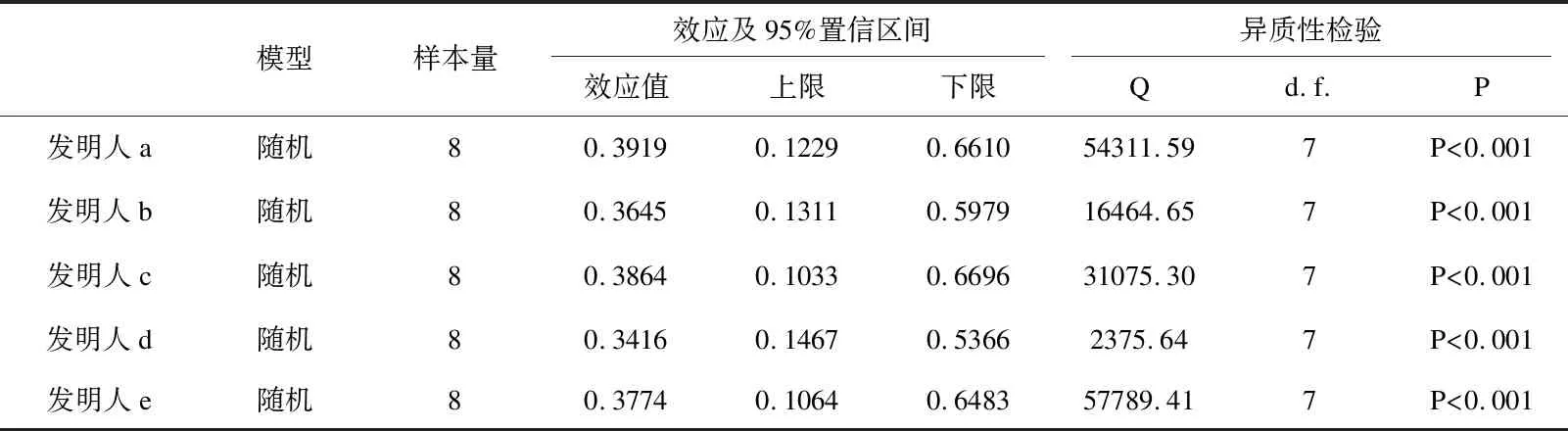
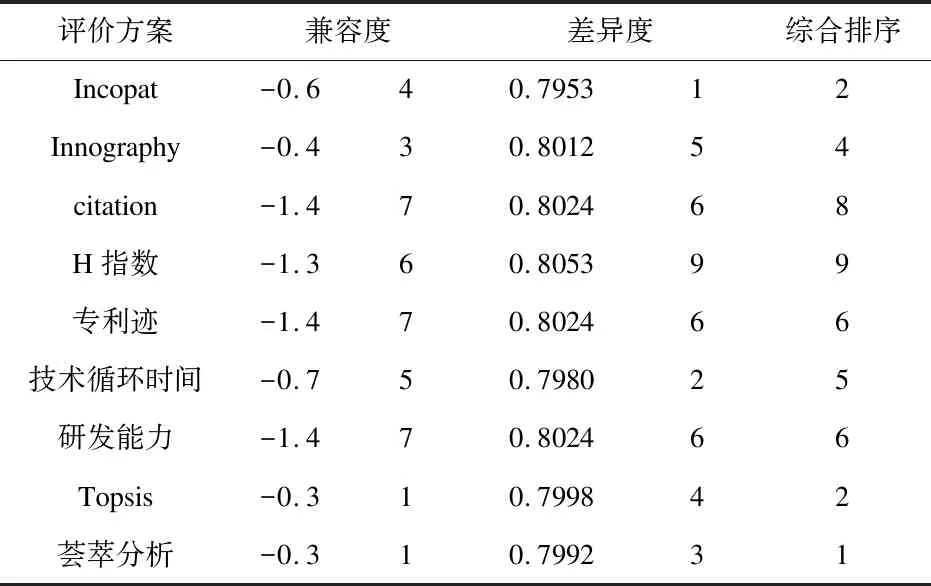
除此之外,影响迹和学术矩阵是2013年Fred Y. Ye等在I3指数基础上融合H指数,构建的成果评价方法。2015年影响迹成功应用于专利发明人影响力研究[9-10],专利迹评价思路是将被引次数降序排序,从而可以得到专利数-引文分布。x轴以H指数和零被引为分界点,将专利数量分布划分为h核(Pc)、h尾(Pt)以及零引专利3个区间。沿着引文的y轴被分为3个区间:(i)e域(Ce>h) ;(ii)h域(Cc=h);(iii)h尾中的引文Ct(0 专利迹即根据3个不同区间(超被引、h核、一般被引)专利量数值与被引文数参数,以此作为专利迹T(T=X1+Y2+Z3)。T越大,发明人专利影响力越高。 关于专利价值的量化,目前许多数据商推出了综合专利价值评估工具,例如专利强度是Innography系统核心功能之一,它是专利影响力判断的综合指标。专利强度的主要影响因素包括:被引次数、每项专利平均参考数量等[11]。价值度则是合享智慧研发的专利价值度评价指标。该指标以主成分线性加权综合评价方法为理论基础,选用了包括被引证次数等在内的26个参数,通过综合均衡、迭代最终获得专利价值度的综合分值。上述评估工具推出后成为研究专利质量的重要指标。例如文献[12]选取虚拟化技术领域中发明人作为实证研究对象,使用Innography数据构建了发明人影响力综合评价Inventor Rank粉方法。文献[13]以中科院先进院专利筛选为例,采用专利分阶评价体系应用于领军人物评选,验证了Incopat作为专利价值评估工具的有效性。 除了上述模型之外,包括Topsis等其他综合评价模型亦可应用于发明人绩效评价。Topsis法通过计算评价对象与最优、最差值的距离进行研究对象优劣排序。在评价实践方面,文献[15]提出了基于熵权法和TOPSIS法,重构了发明人专利质量评价模型,并应用于医学领域。 从上述分析可以看出,关于发明人专利质量评价已经有不少研究涉猎,如果具备一定的应用条件,上述评价模型都适用于专利质量评价(见表1)。但是一般而言,同一组对象使用不同方法进行评价存在评价结果不一致的缺陷。为了解决上述问题,本文引入荟萃分析方法将上述单项评价方法的结果进行融合,既实现不同发明人专利质量之间的比较、验证,同时也使评价结论更加客观、可信。 荟萃分析这一术语由美国教学心理、社会学家Glass在1976 年提出[16]。Rozas将其定义为[17]“将统计技术应用于单项研究的经验性发现的集合,目的是合并分析、整合单项研究,深入探究其研究差异,并使研究结果具有科学价值”。荟萃分析也称元分析。 在科学计量领域中,2013年CNPq委员会(巴西基金资助机构)为了在2 663 名巴西科学家中遴选出下一年度的高影响力科学家予以重点基金资助时,委员会提出了包括同行评审、被引次数等18个维度计量指标来进行衡量。但由于评价视角不同,不同维度数据结果出现显著差异,因此委员会在决策时,面临需要决定采用哪种评价工具作为最后量度结果的问题。针对该问题,Wainer[18]等提出了采用荟萃分析方法—“融合评价”来解决,研究过程包括通过综合多个指标以实现不同指标的可比和整合,获得效应值。目前在科学计量领域有零星研究基于荟萃分析应用于Altmetrics单篇论文层面的评价[19],并且在科研数据管理服务[20]以及健康信息搜索行为[21]等部分重要话题做出了相应的尝试。由此可见,荟萃分析技术在科学计量研究中的认可度和影响率正逐渐上升。 表1 基于引证专利发明人质量评价指标一览 本研究运用荟萃分析方法的主要依据是: 首先,源于方法学问题,不同研究设计和抽样误差不同。如果单点指标视为评价标准,例如在缺乏补充信息的情况下进行学术评估,单项指标可能会被误用[22-23]。而荟萃分析能够对同一领域的多个研究结果进行综合分析,消除单一方法产生的随机偏差,在总结与归纳实证研究方面具有客观性、科学性的独特优势。 其次,对既有原始数据进行综合分析并有效降低研究因统计方法带来的研究偏差,需要根据一定的准则和规则抽取数据。荟萃方法遵循荟萃分析撰写指南(The PRISMA)[24]进行研究方法的选择和使用,具体分析过程主要包括出版偏倚检验、异质性检验等。其中,出版偏倚检验主要判定荟萃分析是否会夸大变量关系效应;异质性检验是判断多项独立研究之间是否具有一致性;综合效应值计算采用各单个效应值方差倒数作为权重进行加权综合[25]。因此研究具有较高的可信度。 考虑被引时滞,本文选取大连理工大学机械学部专利申请量Top5发明人2010—2020年的专利数据,采集及计算具体步骤为: ①以专利数据库Innography为数据源,检索发明人专利,得到发明人专利数量、被引次数、Innography专利强度等数据。②对发明人逐年的专利按被引频次排序,分别得到发明人逐年的H指数。 ③逐年统计每位发明人的专利数量,零被引、H核等引文数据,根据专利迹T计算公式,获得专利迹数据。④将引用专利公开号导入Innography,获得引用专利公开时间。根据技术循环时间公式计算时间差平均值,即引用专利公布年份减去被引用专利的公布年份除以专利数量,得到专利的技术循环时间。⑤将专利发明人专利公开号导入Incopat,获得专利价值度数据。⑥将8个指标数据进行标准化处理,对于正向指标,标准化方法采用各指标值除以极大值。技术循环时间属于反向指标,其标准化方法采用俞立平[26]等提出的反向指标线性标准化方法进行计算,并根据Topsis计算公式,分别得到各发明人逐年的Topsis指数。经计算,发明人专利指标数据(见表2)及发明人排名变动情况(见图1)所示。 从各发明人排名来看,不同指标下各发明人排序结果存在差异,例如发明人a在Incopat、Innography、技术循环时间中排第4位,在被引、H指数、专利迹和研发能力中排第2位;发明人d在不同指标下有不同排序,排名从第1位到第5位不等。由此可见,如果简单利用一种评价方法来判断发明人被引质量水平,其质量孰优孰劣难以判断,如果简单地把几个指标的数据累加求和或求平均值,由于研究指标的数据分布、标准差、极大和极限值均不相同,发明人专利质量的量化比较无实际意义, 因此针对以上独立样本数据评价结论非一致,需要合理选取多项数据指标作为样本数据,对多项研究的结果进行定量合成,纠正由指标系统误差造成的结果失真。 表2 各专利指标数据分布情况 图1 发明人在不同专利评价指标下的排名变化情况 应用荟萃分析之前,首先需要进行偏倚检验,以验证研究之间是否存在统计学差异荟萃分析中较为常用的异质性检验包括漏斗图、Egger's Regression检验等方法。 漏斗图是一个散点图,x轴上为效应值大小,y轴测度标准误。通常,漏斗图中的y轴是倒置的(y轴“高”值代表低标准误)。由于研究样本量和标准误密切相关。样本量越小,标准误越大,置信区间就越宽,并增加了效应值不具有统计学意义的机会。根据经验,只有当荟萃分析中包括至少10项研究时,才可使用漏斗图不对称性测试,当变量太少时,漏斗图无法辨别研究是随机误差还是真实数据不对称,因此无法判断研究之间是否存在偏倚,由于本文研究指标<10,所以不适宜用漏斗图。 Egger测试是另一种常用偏倚检验方法,该方法基于线性回归模型,公式如下[27]: (1) 本文将发明人a-e的样本数据依次导入R语言中,调用Meta包,输入Metabias(m.gen, method.bias = "linreg")函数,Egger检验结果如表3所示。从表3可以看出,Egger 检验截距分别为65.19、36.69、43.81、-37.69、59.07,相伴概率均大于0.05,检验结果表明均没有发现偏倚,说明评价方法的选取是合适的。 表3 Egger检验结果 标准误取决于其样本大小。由于本文样本数据较小, Simonsohn[28]在Betterp-Curves:Makingp-CurveAnalysis… 一文中,针对样本量较少的荟萃分析引入了p-Curve的方法,该方法依据P值作为发表偏倚的主要影响因素,侧重显著效应大小以及P值分布情况。该函数生成的P曲线图包含三条线:实线1:基于样本数据的传统P曲线;虚线2:假设33%效应量的预期P值分布虚线;虚线3:显示的是在没有影响时预期的均匀分布。 将样本数据导入R语言中,调用P-Curve analysis函数,检验结果如图2所示:荟萃分析中包含了k=8个显著效应,这些效应被纳入了P曲线。这些研究中的大多数(k= 7)都有非常显著的结果(即p< 0.025)。所有3个右偏度测试(Right-skewness test)结果都显著(见表4):二项式测试(pBinom;p= 0.008)。全P曲线pp值测试(pFull;P< 0.001);基于半P曲线测试(pHalf;p= 0.001)。根据P-Curve的结果,基本研究数据样本不存在出版偏倚,可以进行进一步的荟萃分析。 图2 样本P-Curve偏倚检验结果 表4 P-Curve偏倚检验结果数据 在进行主效应分析之前,需要先进行异质性检验,以决定选用随机还是固定效应模型。异质性检验通常以Q统计量(其显著性水平户)和I2来评估样本的异质性水平。若Q>df(Q),P<0.05且I2>0.75,则意味着效应值服从异质性分布,采用随机效应模型。 Q检验:传统上,研究者使用Cochran's Q[28]来区分研究抽样误差和实际研究异质性。Cochran's Q被定义为加权方差之和(Weighted sum of squares-WSS),公式如下: (2) 进一步调用Meta数据包,输入metagen(TE,seTE,data=data,studlab=Method),从结果来看,数据异质性较高。为探究各研究间的异质性是否由单个研究引起,研究运用R语言采用逐一排除法,调用trimfill函数进行敏感性分析,剔除Incopat和Tech. Cycle Time两项研究后;总合并效应量降低,但I2无显著变化,说明结果较稳定(见图3)。 图3 逐一排除法检验结果 根据异质性诊断结果,本研究选择随机效应模型进行分析计算,结果见表5。由表5可知,在随机效应模型下发明人a-e的95%置信区间CI均不包括0,可信区间值均为正(见图4-5,由于篇幅,只绘制部分发明人森林图),说明分析结果具有可信性。 表5 发明人专利被引质量荟萃分析结果 综上可知,以均值标准误平方的倒数为权重,metagen函数计算结果表明,发明人a专利被引质量评价值(0.3919[95% CI(0.13;0.66),P<0.01])>发明人c评价值(0.3864)[95% CI(0.10;0.67), P<0.01]>发明人e评价值(0.3774)[95% CI(0.11; 0.65),P<0.01]>发明人b评价值(0.3645[95% CI(0.13; 0.60),P<0.01]) >发明人d评价值(0.3416[95% CI(0.15; 0.54), P<0.01])。 图4 发明人a效应值森林图 图5 发明人d效应值森林图 科学评价必须要经过有效性检验才能被认可,为验证算法有效性,本文选择了兼容度和差异度对研究结果进行事后一致性检验。兼容度[29]是指某评价方案与其他评价方案的等级排序之差的加权平均值。设n为评价对象数。第i、j评价方案之间相关程度,可以通过等级相关系数ri,j来计算,公式为: (3) 其中dt与分别表示第t个对象在第i与第j方案中的排序名次。兼容度越高,说明该指标与其它指标的结果越一致。因此,用兼容度实质基于偏差最小化的决策方法,兼容度指标本质上是一种求同评估决策。 差异度是评价指标的离散程度,本文采用标准差作为衡量差异度的指标,σ(k)为第k种评价方案的差异度,公式为: (4) 根据上述公式推算出各种评价方案兼容度和差异度见表6。从表6中可知,在兼容度上,荟萃分析、Topsis兼容度最大,接下来依次为Innography、Incopat、技术循环时间。在差异度上,Incopat和技术循环时间的评价效果较优,荟萃分析的评价效果较次。综上,荟萃分析方法的综合评价排序最高,其次为Incopat和Topsis。比较结果进一步说明了荟萃方法应用于发明人质量评价的可行性。 表6 评价方案的兼容度与差异度计算结果 主成分分析法是一种通过累加贡献率提炼主要成分的数据统计分析方法。与荟萃法相比,二者都是基于多项研究的结果,并进行定量合成评价。为了验证多属性评价方法的一致性,本文进一步对研究结果进行主成分分析。从方差贡献率分析来看,第一(92.21%)、第二主成分(7.054%)的累积贡献率为99.266%,因此提取这2个主成分作为综合指标。通过成分矩阵提取初始因子(限于篇幅,表略),建立因子载荷矩阵,得到2个主成分Y1、Y2的表达式分别为:Y1=0.077X1+0.156X2-0.008X3+0.0123X4-0.856X5+0.62X6-0.049X7+0.0123X8;Y2=1.413X1+0.109X2-0.251X3-0.568X4+1.78X5-0.36X6-0.329X7+5.3834X8。最后以2个主成分对应的特征值占所提取主成分总特征值之和的比例作为权重,得到综合主成分值,并与荟萃分析结果进行比较。经计算与排序,主成分分析与荟萃分析方法对5位发明人评价结果完全一致,进一步说明了荟萃方法具有较高的稳健性。 科研评价对于高校了解自身竞争优势与可持续发展能力、推动创新驱动发展具有关键性作用。近年来职能部门采用的分析评价大多是根据评价目的,大多以各类指标配合同行评审的方法进行。但如何综合研究结果,依据哪种评估方式作为最终量度指标,仍有诸多争论。甚至有学者提出质疑:综合评估方法,是否属于苹果与橘子合并的关系?事实上,对于现行科学评价方法和政策的重新审视,一直是近年来研究的热门议题之一。《旧金山宣言》和《莱顿宣言》的相继发布,提出了合理利用科学评价指标的原则,但在审读学术共同体对这些倡议文件的回应后,可以发现真正问题不是指标本身,而是如何去解读和使用数据。例如《莱顿宣言》[30]倡议的十条原则包括:量化评估应当支撑质化专家评估,而不是取而代之;保持数据采集和分析过程的公开、透明和简单;允许被评估者验证数据和分析。《旧金山宣言》[30]则提出了对于个人研究成就评价方面,单个指标更易被操纵,成为绩效考核的指挥棒,评判应基于其综合学术产出。在上述原则指导下,如何在认可和尊重多维、有价值的科研评价基础上,获得研究对象整体发展水平,如何正确合理地使用定量数据进行科研绩效分析值得进一步探讨。基于此,本文提出了荟萃分析的研究思路:首先对评价方案进行事前同质性检验,通过荟萃方法获得了加权平均效应值,最后运用兼容度与差异度进行事后一致性检验,研究结果表明基于荟萃分析将多维数据转化为一维指标,满足计量学研究过程统一规范、数据可重复验证的要求,结论具有可验证性和可重复性,为后续专利质量评价研究提供理论和方法方面的借鉴和参考。 然而值得一提的是,尽管综合评价可避免单项评价偏差,但选用多少种评价方案进行组合评价,目前尚未有一定的标准。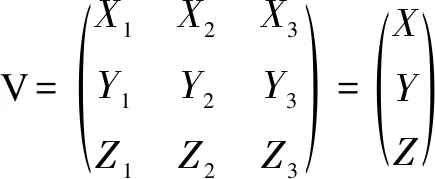
2 研究对象、数据及方法
2.1 荟萃方法

2.2 研究对象和数据
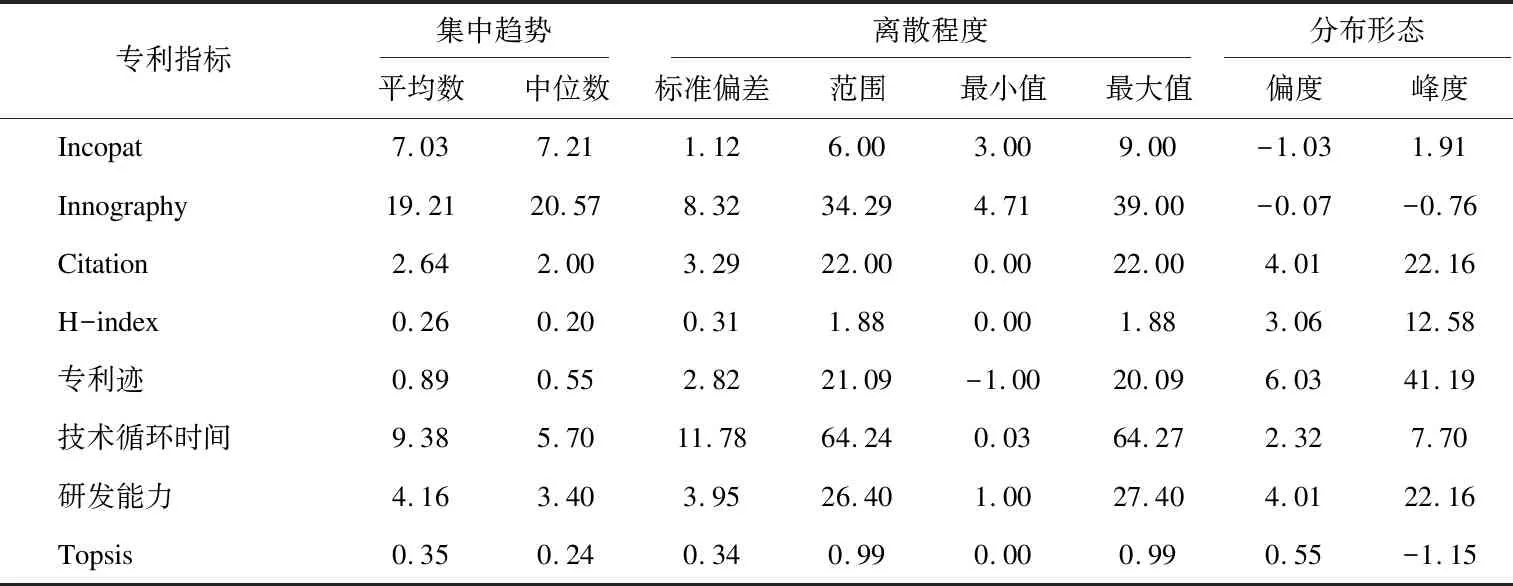
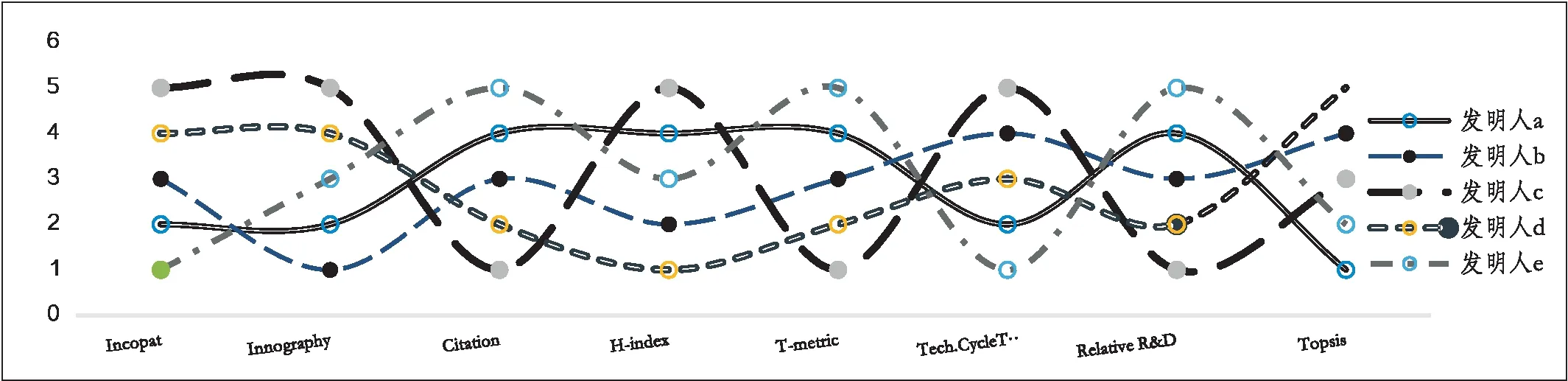
2.3 偏倚检验


3 研究结果
3.1 主效应分析


3.2 事后兼容度与差异度检验
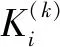
4 结 论
猜你喜欢
情报杂志(2022年1期)2022-01-28
法制博览(2020年36期)2020-11-30
赢未来(2019年29期)2019-12-07
电子制作(2018年16期)2018-09-26
中外玩具制造(2017年12期)2017-12-08
山东工业技术(2016年15期)2016-12-01
试题与研究·中考化学(2016年1期)2016-09-30
小天使·二年级语数英综合(2015年2期)2015-01-14
中国发明与专利(2007年7期)2007-08-09
