
基于混合模式匹配算法的网络入侵检测
2022-12-01 01:06:12周琰,马强
计算机测量与控制 2022年11期
周 琰,马 强
(国家气象信息中心,北京 100081)
0 引言
随着计算机网络入侵技术的快速发展,防火墙、用户身份验证和数据加密等传统安全技术已无法充分保障网络安全[1]。网络入侵检测系统(NIDS)作为对网络传输进行即时监视的防御机制,可以有效提高网络系统的安全性[2]。NIDS可分为两类[3]:基于异常的检测和基于模式的检测。其中,基于异常的检测将入侵者不同于正常网络的异常行为识别为恶性攻击,从而可以检测到未知和已知攻击,但检测结果假阳性率高[4];基于模式的检测通过匹配预定义的攻击模式来检测异常,具有操作简单、误报率低的优点,但无法检测新型入侵攻击模式[5]。
通常,当数据包有效载荷中识别出任何异常模式,NIDS将发出警告并拦截该数据包,从而保护网络中的正常资源[6]。当采用基于模式的检测设计NIDS时,模式匹配过程占NIDS执行时间约70%[7],设计出高效的模式匹配算法对模式识别至关重要。模式匹配消耗系统执行时间的70%,是影响NIDDS系统整体性能的关键因素。模式匹配算法可以分为单模式匹配和多模式匹配。其中,单模式匹配是在一个字符串内找到单一模式,例如,字符串查找(KMP)算法[8]和字符串匹配(BM)算法[9];多模式匹配可以同时识别一个字符串中的多个模式,例如,Wu-Manber(WM)算法[10]和Aho-Corasick匹配(AC)算法[22]。
利用硬件处理的模式匹配算法主要通过可编程门阵列(FPGA)[11]、内容可寻址存储器(CAM)[12]和特定应用集成电路(ASIC)[13],从而实现高效匹配速度。然而相比硬件实现算法相比,在通用处理器(GPP)[14]上通过软件实现算法具有成本低、可扩展性强的优点。目前,单独利用中央处理器(CPU)运算能力无法满足高速网络条件下模式识别速度,现有研究侧重于在软件平台部署具有更高并行处理能力的图形处理单元(GPU)来实现模式匹配算法[15]。尽管GPU比CPU具有更强的处理能力,但基于GPU的模式匹配算法在内核启动和数据传输方面具有延迟,导致整体性能受到限制[16]。此外,CPU所支持的单指令多数据(SIMD)操作可用于加速模式匹配。因此,在CPU和GPU之间设计高效的协同模式匹配算法已成为研究热点。文献[17]提出了基于抛物线Radon变换的CPU/GPU协同模式匹配算法,通过CPU多线程与多个GPU协同并行提高网络流量检测的吞吐量。文献[18]利用基于队列的混合调度策略设计了CPU/GPU协同模式匹配算法,缩短了CPU与GPU完成各自计算任务后的等待时间,加快了网络流量检测的整体延迟。文献[19]和文献[20]根据CPU处理后的数据包加载到GPU平台的移植过程,分别设计了非确定性有穷自动机(NFA)和确定性有穷自动机(DFA),优化了网络接口与CPU和GPU的并行性,从而提高了僵尸网络检测处理性能。文献[21]设计了基于CPU/GPU混合模式匹配算法(HPMA)的NIDS,实现CPU与GPU任务分配平衡,但具有不同长度的输入流量数据包会导致GPU并行处理多线程执行时间的增加,从而导致网络流量检测的吞吐量下降。
本文提出了一种具有长度约束的CPU/GPU混合模式匹配算法(LHPMA)来设计NIDS。当传入数据包加载到CPU时,LHPMA根据预先设定的有效载荷长度约束对数据包进行提前分类。长度超过约束的数据包直接分配给CPU进行快速预过滤;否则,数据包直接分配给GPU进行全模式匹配。通过减少有效载荷长度的多样性,提升了CPU/GPU协同检测网络入侵的性能。
1 CPU/GPU混合模式匹配算法(HPMA)
文献[21]提出的HPMA将网络入侵检测任务分为两部分:数据包预过滤和全模式匹配。利用CPU执行预过滤对“正常”和“可疑”数据包进行分类,结合GPU对可疑数据包进行全模式匹配。HPMA的整体架构,如图1所示。

图1 HPMA的整体架构
首先,传入数据包发送至CPU的主存储器中,CPU访问数据包并根据查找表(表名、基本信息表、间接寻址表和字段说明)对数据包进行预过滤。当表的大小足够小时,可以降低内存访问延迟并减少预过滤时间,从而提高过滤率并降低数据传输延迟。然后,将预过滤后的可疑数据包发送至GPU进行全模式匹配。由于GPU纹理内存的访问延迟比设备内存的访问延迟低得多,采用AC算法[22]对GPU纹理内存中存储的可疑数据包进行全模式匹配,并将查找表(状态转换表、接受状态表和失败状态表)复制到GPU纹理内存中,从而加快检测速度。最后,当全模式匹配完成后,将数据包匹配结果复制并返回CPU主存储器。
通过在HPMA中使用预过滤方法,CPU可以进行快速的预过滤并达到较高的过滤率,从而减少GPU的延迟,提升网络流量检测效率。然而,在以下条件下,HPMA性能会受到限制:①所有传入数据包最终都传送至GPU,造成多余操作[23];②网络流量由不同长度的数据包组成,造成GPU并行处理中每个线程的执行时间不一致[24]。针对限制①,文献[25]提出了基于性能的CPU/GPU混合模式匹配算法(CHPMA),CHPMA首先估计系统的CPU和GPU处理能力,在运行期间,CHPMA根据CPU的历史过滤率和GPU处理能力自动进行处理选择。针对限制②,本文提出了LHPMA来提升CPU/GPU协同检测网络入侵的性能。
2 具有长度约束的HPMA(LHPMA)
2.1 整体架构和程序
与文献[21]中的HPMA不同,本文提出的LHPMA在CPU对数据包进行预过滤期间,增加了长度约束分离算法(LBSA),即传入数据包发送至CPU主存储器之前,通过LBSA处理后进入预过滤缓冲区。LBSA主要用于检查数据包有效载荷长度并对数据包进行分类。在经过LBSA处理后,部分数据包存储在CPU主存储器中的预过滤缓冲区中,从而直接交付给CPU作预过滤的准备;剩余数据包则直接发送至CPU主存储器中的全匹配缓冲区,用于存储要由GPU处理的全模式匹配数据包。LHPMA的整体架构,如图2所示。
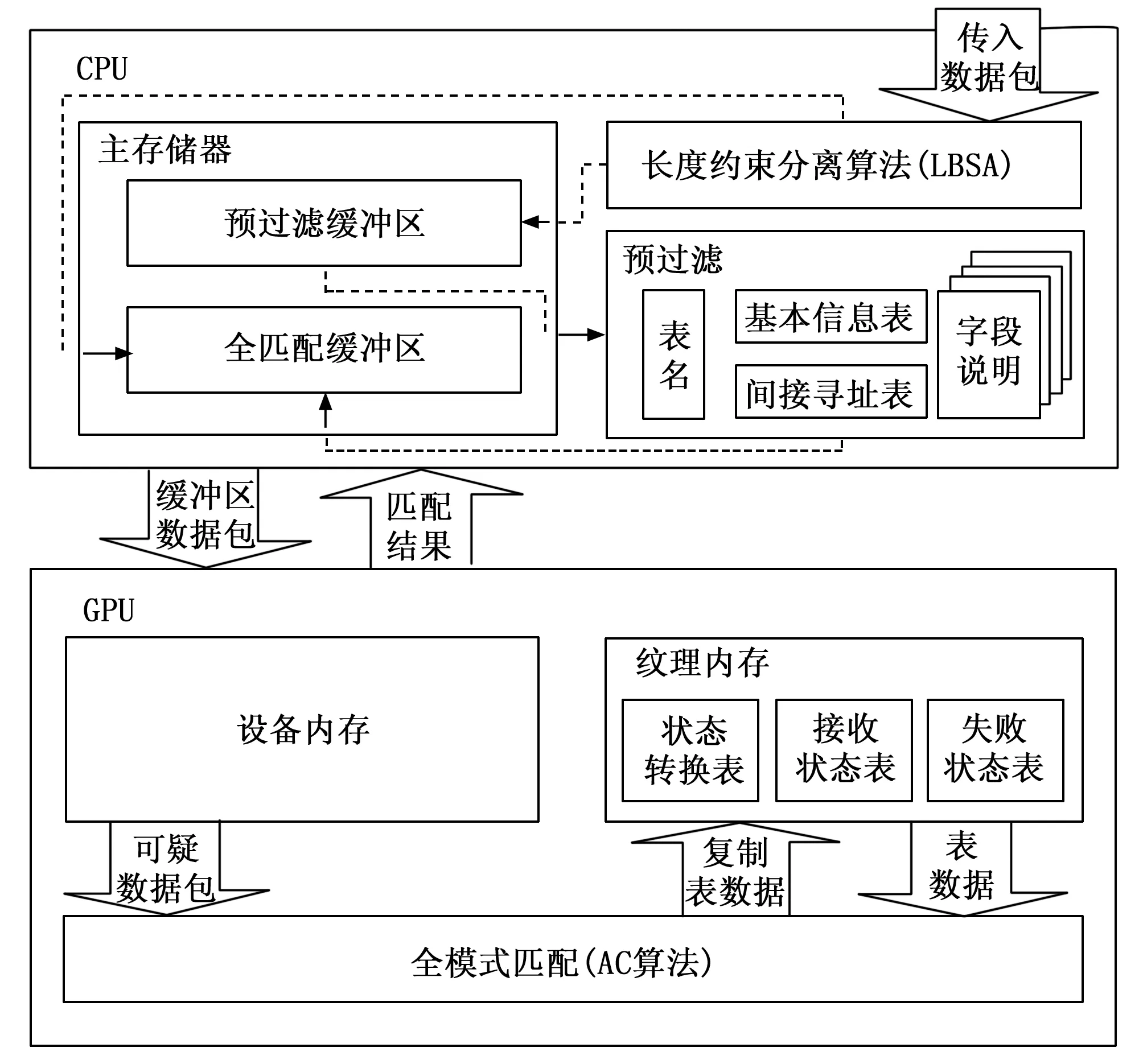
图2 LHPMA的整体架构
当CPU主存储器中的预过滤缓冲区变满时,则由CPU访问数据包并根据查找表(表名、基本信息表、间接寻址表和字段说明)对数据包进行预过滤,预过滤的数据包也发送至全匹配缓冲区;当全匹配缓冲区变满时,缓冲区内的数据包就会转移到GPU设备内存中,采用AC算法[22]对GPU纹理内存中存储的可疑数据包进行全模式匹配,并将查找表(状态转换表、接受状态表和失败状态表)复制到GPU纹理内存中,从而加快检测速度。最后,当全模式匹配完成后,将数据包匹配结果复制并返回CPU主存储器。LHPMA的整体过程,如图3所示。
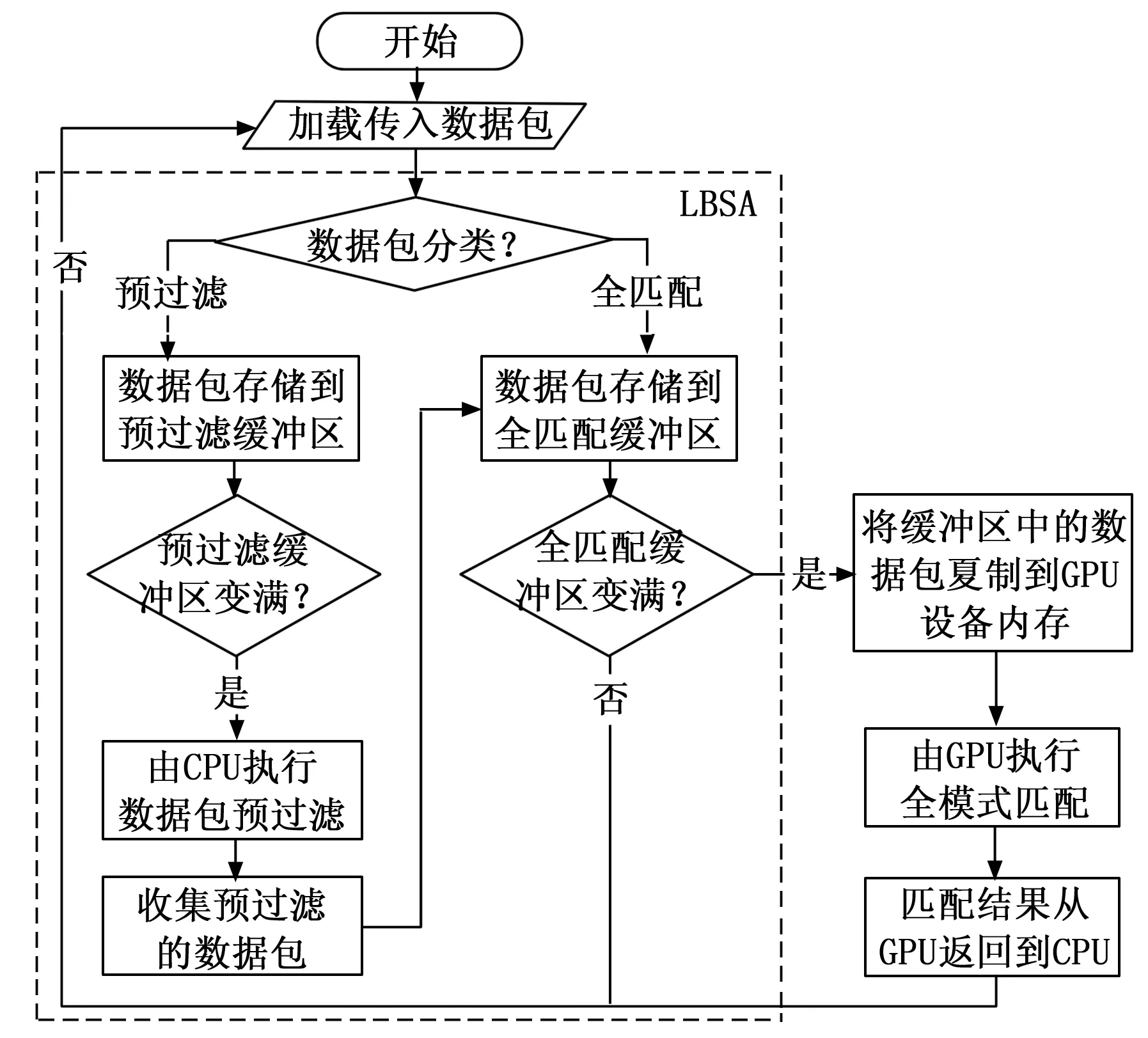
图3 LHPMA整体过程
2.2 长度约束分离算法(LBSA)
LBSA的伪代码,如算法1所示。LBSA算法根据预先设定的有效载荷长度约束对传入数据包进行分类,从而减少GPU并行处理的有效载荷长度多样性。给定数据包有效载荷集P和长度约束Lb,LBSA算法可以用Lb确定P中的有效载荷。
算法1:长度约束分离算法(LBSA)
输入:数据包有效载荷集P和长度约束Lb
输出:数据包有效载荷匹配结果
1)TPB←空;//预过滤缓冲区
2)TFB←空;//全匹配缓冲区
3)Pf←空;//预过滤有效载荷
4)idxPB←0;//预过滤缓冲区的索引
5)for每个Pido
6)Li←Pi的有效载荷长度
7)ifLi>Lbthen
8)TPB[idxPB]←Pi;//将Pi存储在预过滤缓冲区中
9)idxPB←idxPB+1;
10)else
11)TFB←TFB∪Pi;//将Pi存储在全匹配缓冲区中
12)end
13)
14)ifTPB变满时then
15)Pf←预过滤的TPB;//执行预过滤算法
16)TFB←TFB∪Pf;//将Pf存储在全匹配缓冲区中
17)Pf←空;
18)TPB←空;
19)idxPB←0;
20)end
21)
22)ifTFB变满时then
23) 结果←全匹配的TFB;//执行全匹配算法
24)TFB←空;//匹配结果复制并返回
25)end
26)end
最初,预过滤缓冲区TPB和全匹配缓冲区TFB为空。同时,设置有效载荷集Pf用于临时存储预过滤结果,也是空(第1~3行)。预过滤缓冲区的索引idxPB设置为0(第4行)。对于P中的每个有效载荷,LBSA测量数据包Pi的有效载荷长度Li,从而与长度约束Lb进行比较(第5~6行)。如果有效载荷长度Li超过长度约束Lb,则系统将数据包Pi存储在预过滤缓冲区TPB中,并等待CPU执行预过滤过程(第7~8行)。在数据包Pi存储在TPB后,预过滤缓冲区的索引idxPB将增加 (第9行)。否则,数据包Pi将存储在全匹配缓冲区TFB中,并等待GPU执行全模式匹配(第10~11行)。
当预过滤缓冲区TPB变满时,则缓冲区中的所有数据包由CPU执行预过滤得到有效载荷集Pf,并将其存储在全匹配缓冲区TFB中(第14~16行),系统清除存储在Pf、TPB和idxPB中的数据并继续处理下一批传入数据包(第17~19行)。同时,当全匹配缓冲区TFB变满时,缓冲区中的所有数据包将复制到GPU设备内存中并由GPU执行全模式匹配过程。最后,将数据包匹配结果复制并返回CPU主存储器,系统会清除存储在TFB的数据(第22~24行)。
在本文设计的LBSA算法中,较短的数据包有效载荷由GPU处理,从而提高整体效率。由于使用较短数据包是一种典型的攻击方式,大量的数据包可以在较短的时间内生成并发送,如果将此类数据包直接发送至GPU,则可以减少由此类数据包引起的CPU预过滤的冗余操作。此外,GPU可以对较短数据包进行较强的并行处理。同时,较长数据包由CPU进行预过滤而不发送至GPU进行全模式匹配检测,从而减轻了GPU处理负担并减少数据传输延迟。
3 实验分析
3.1 实验设置
本文设计的预过滤和全模式匹配分别基于CPU和GPU组成的通用并行计算架构(CUDA)平台实现多线程并行处理。实验的硬件规格,如表1所示。
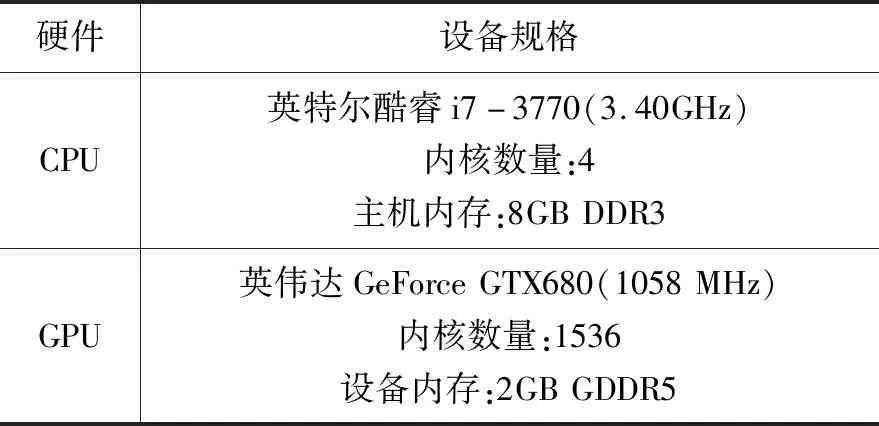
表1 实验的硬件规格
CUDA平台中配置的GPU块数和每块的线程数分别为128和64。同时,设置的预过滤缓冲区和全匹配缓冲区分别为1 MB和256 MB。利用文献[21]中的HPMA算法的源代码创建LHPMA算法的源代码,结合算法1创建LBSA算法的源代码,所有源代码采用GCC4.8.4进行编译,操作系统利用64位的Ubuntu14.04(内核版本3.13)。
本文从Snort入侵检测系统提取并生成实验所需的模式集。Snort构成的模式集包含的模式数量最多,但字符数最少。模式集中的数据包长度从1到208 bytes不等,平均为13.8 bytes。如果输入数据流中的字符串是模式集中任何模式的重要前缀字符串,则视为恶意攻击。如果前缀字符串覆盖了整个字符串的80%以上,则视为正常流量。对于每个输入数据流量,根据匹配率,从模式集中随机选择适当的前缀,并嵌入正常流量中。对于Snort构成的模式集采用HTML格式,并在Linux服务器中的/usr/bin下的所有文件连接起来作为正常数据流。同时,利用模式集生成预过滤和全模式匹配的查询表,并加载到检测系统中。从谷歌、亚马逊和雅虎的门户网站提取的网络流量中选取真实的数据包检测作为传入数据包的输入。输入流量中的数据包有效载荷长度信息,如表2所示。
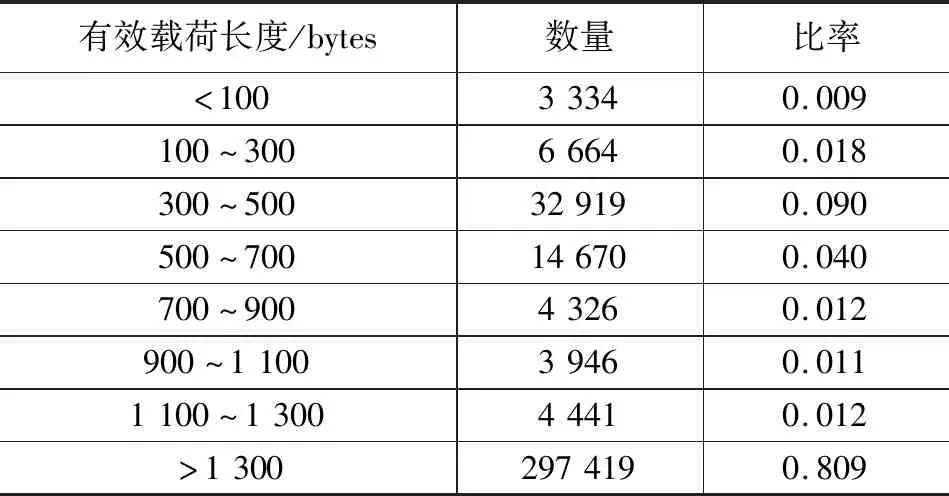
表2 输入流量的数据包有效载荷长度信息
3.2 CPU与GPU之间的数据传输性能
在分析LHPMA的结果之前,还需分析影响GPU处理性能的因素。不同全匹配缓冲区中CPU和GPU之间的数据平均传输速率,如图4所示。其中,x轴表示全匹配缓冲区的大小,y轴表示以Gbps为单位的数据平均传输速率,AC-GPU表示利用GPU通过AC算法检测数据包的匹配方法。
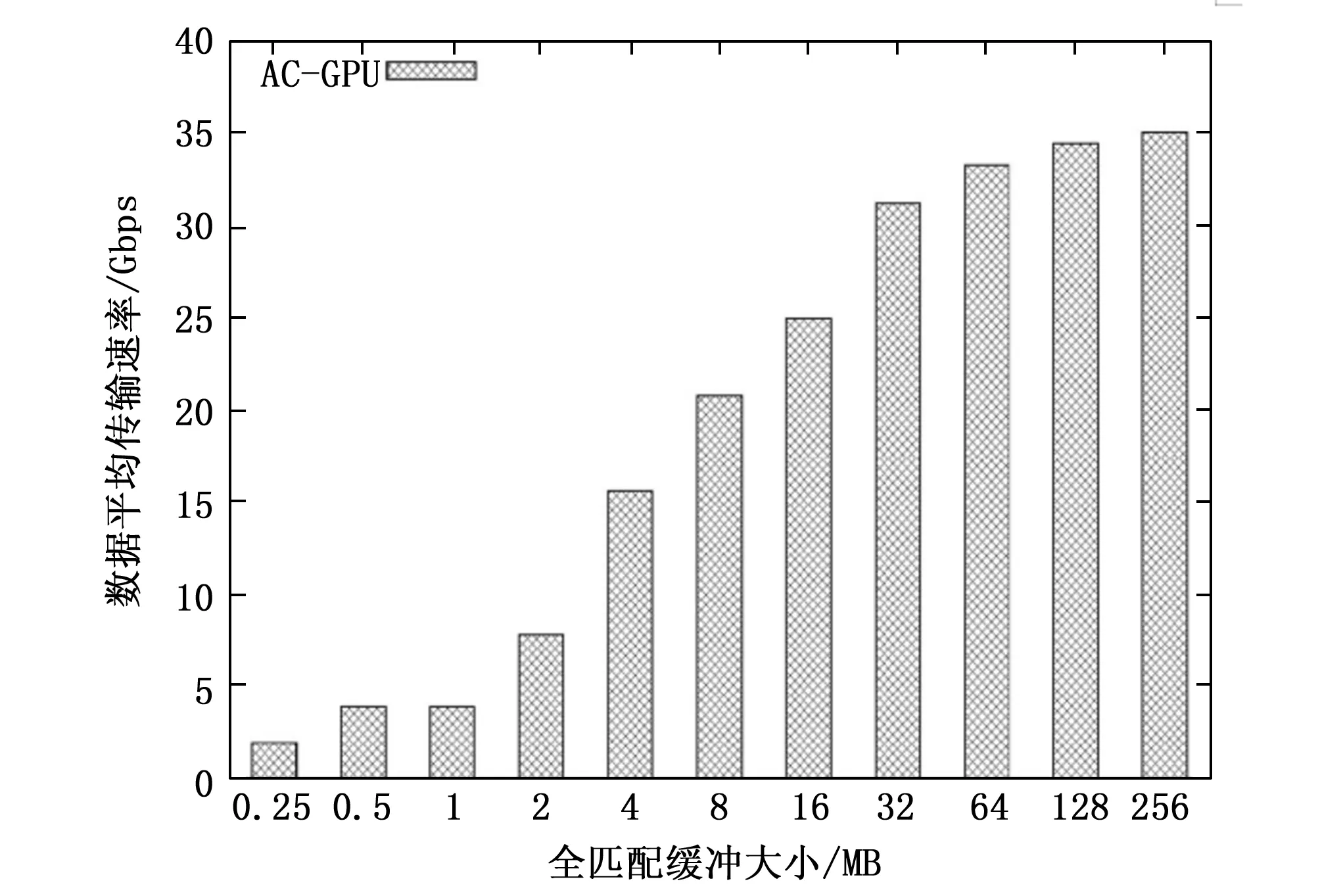
图4 全匹配缓冲区中CPU和GPU之间的数据平均传输速率
由图4可以看出,当全匹配缓冲区较小时,数据传输率非常低,即传输的数据包有效载荷很少。例如,当全匹配缓冲区为0.25 MB时,数据传输速率为1.95 Gbps。当全匹配缓冲区较大时,更多的数据包有效载荷在同一时间被传输,GPU执行的数据传输速率会更高。例如,当全匹配缓冲区为256 MB时,数据传输速率为35.1 Gbps。最佳方案的并不是将全匹配的缓冲区大小设置的越大越好,这是由于过大的缓冲区会导致数据包有效载荷等待时间过长,从而影响整体性能。因此,选择位于数据传输速率收敛的转折点作为全匹配缓冲区的临界值,本文选取全匹配缓冲区为256 MB。
3.3 GPU处理性能
不同全匹配缓冲区中GPU性能,如图5所示。其中,x轴表示全匹配缓冲区的大小,y轴表示以Gbps为单位的平均吞吐量,AC-GPU-100和AC-GPU-1460分别表示较短(100 bytes)和较长(1 460 bytes)数据包有效载荷集。
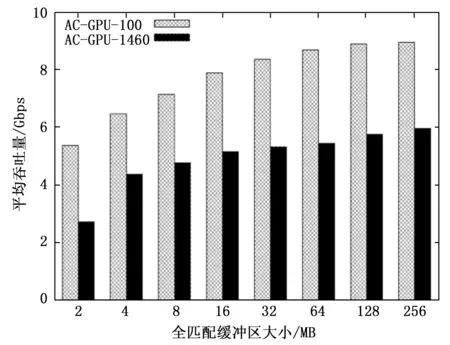
图5 全匹配缓冲区中GPU性能
由图5可以看出,在全匹配缓冲区中,AC-GPU-1460比AC-GPU-100的吞吐量低,较长的数据包有效载荷集在全匹配缓冲区的吞吐量较小,这是由于LBSA算法将较长的数据包过滤后直接发送至全匹配缓冲区,等待GPU的处理,造成了GPU性能降低。当全匹配缓冲区较小时,GPU性能较低,尤其是在全匹配缓冲区为2 MB的AC-GPU-1460情况下。数据包有效载荷的数量很少,导致GPU线程利用率低,从而降低了整体性能。即输入有效载荷集的长度也会影响GPU效率。较短的数据包可收集成更多的数据包,有利于GPU的并行处理能力。因此,AC-GPU-100的效率表现为5.37 Gbps到9.03 Gbps,高于 AC-GPU-1460从2.71 Gbps到6.10 Gbps的效率。
不同有效载荷长度中GPU性能,如图6所示。

图6 有效载荷长度中GPU性能
由图6可以看出,较短的数据包有利于GPU效率。这是由于GPU具有较强的并行处理能力,可将较短的数据包中的有效载荷集在GPU纹理内存中集中收集状态转换表并做统一识别处理,加速了并行处理较短的数据包的能力。当有效载荷集长度为250 bytes时,GPU最多可以完成高达8.0 Gbps的吞吐量。随着有效载荷长度的增加,GPU的吞吐量逐渐下降。这是由于GPU设备内存中较短的有效载荷数量多于较长的有效载荷数量,同时,GPU内核的数量远大于CPU内核的数量,从而GPU利用多线程并行处理提高检测流量的吞吐量。
3.4 LHPMA性能
不同有效载荷长度约束中LHPMA性能,如图7所示。其中,x轴表示有效载荷长度约束Lb,y轴表示以Gbps为单位的平均吞吐量,LHPMA-AC表示LHPMA通过AC算法检测数据包的匹配方法。
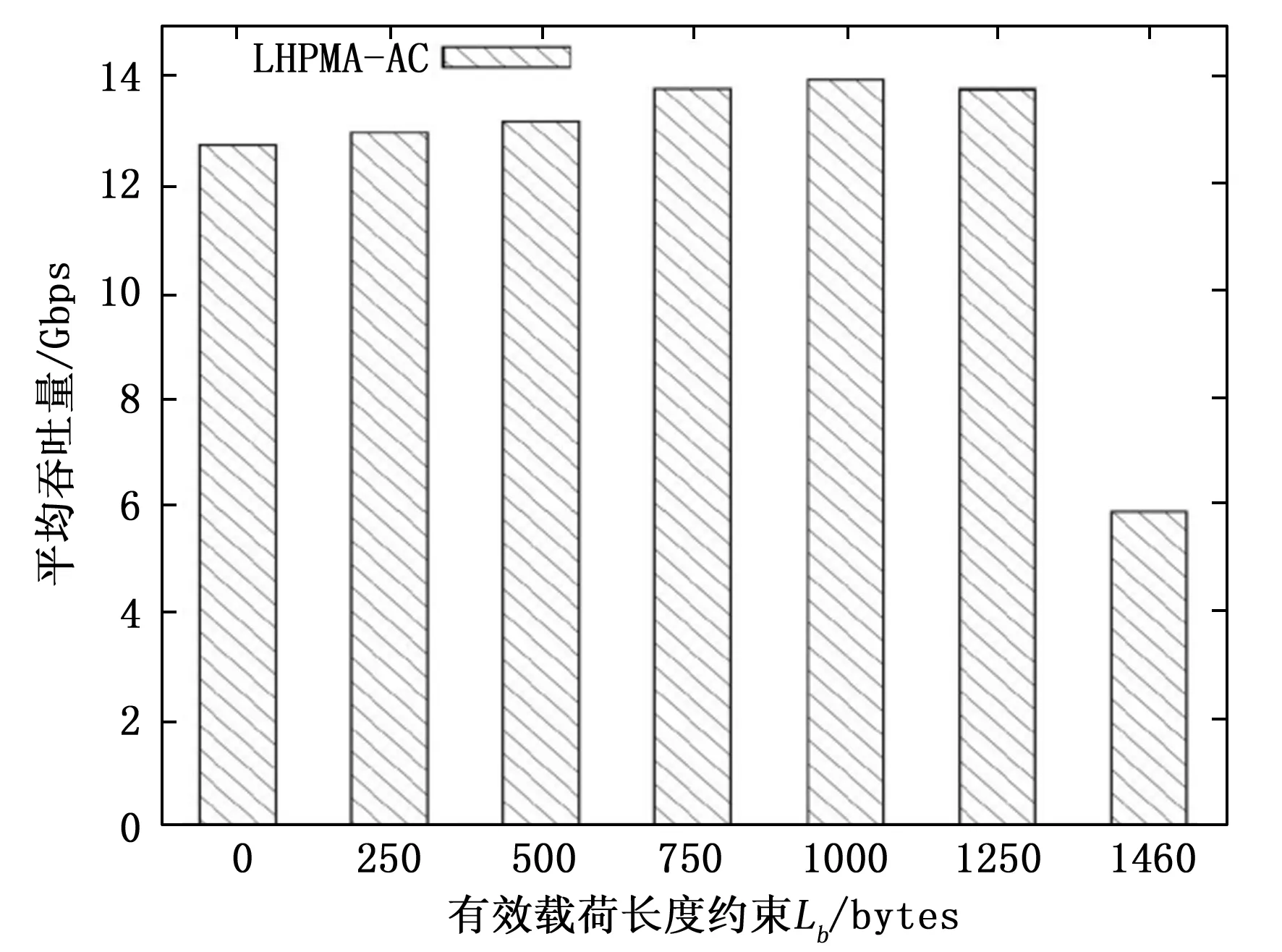
图7 有效载荷长度约束中LHPMA性能
由图7可以看出,当Lb=0时,所有传入数据包都以12.7 Gbps的吞吐量通过预过滤缓冲区,即数据包通过LBSA算法后所有数据包都没有通过预过滤缓冲区就被发送至CPU。随着Lb的增加,吞吐量提升至14.0 Gbps。当Lb=750时,这与图6的结果相对应。即通过LBSA算法将较长的数据包存储在CPU主存储器中的预过滤缓冲区中,CPU访问较长的数据包并根据查找表(表名、基本信息表、间接寻址表和字段说明)对数据包进行预过滤,降低内存访问延迟并减少预过滤时间,同时,较短的数据包存储在CPU主存储器中的全匹配缓冲区中,当全匹配缓冲区变满时,全匹配缓冲区内的数据包就会转移到GPU设备内存中,采用AC算法对GPU纹理内存中存储的可疑数据包进行全模式匹配,AC算法通过插入许多模式,从前往后遍历数据包的整个字符串,要插入的字符其节点再先前已经建成,直接去考虑下一个字符即可,当发现当前要插入的字符没有再其前一个字符所形成的树下没有节点,就要创建一个新节点来表示这个字符,接下往下遍历其他的字符。并将查找表(状态转换表、接受状态表和失败状态表)复制到GPU纹理内存中,使得有效载荷长度的多样性减少,从而提高过滤率并降低数据传输延迟。LHPMA提高了检测流量的吞吐量。当Lb=1 460时,吞吐量下降至5.9 Gbps,这是由于AC算法从数据包的根节点开始,每次根据读入的字符沿着自动机向下移动。当读入的字符,在分支中不存在时,递归走失败路径。如果走失败路径走到了根节点,则跳过该字符,处理下一个字符。因为AC自动机是沿着输入文本的最长后缀移动的,所以在读取完所有输入文本后,最后递归走失败路径,直到到达根节点,这样可以检测出所有的模式。所有传入数据包都没有通过预过滤缓冲区就被发送至GPU,从而数据传输延迟和有效载荷长度多样性导致LHPMA性能的下降。
将本文提出的LHPMA与HPMA[21]、仅使用CPU[26]、仅使用GPU[27]的性能进行对比,如图8所示。其中,HPMA-AC和AC-CPU分别表示HPMA和CPU通过AC算法检测数据包的匹配方法,同时,LHPMA-AC选择的长度约束Lb=750。

图8 LHPMA与其他方法的性能对比
由图8可以看出,LHPMA-AC、HPMA-AC、AC-GPU和AC-CPU的吞吐量分别为13.8、12.7、5.9和4.6 Gbps,表明LHPMA-AC比HPMA-AC增强了性能。这是由于LHPMA-AC比HPMA-AC增加了LBSA算法,根据预先设定的有效载荷长度约束对传入数据包进行分类,较长的数据包分配至CPU主存储器中的预过滤缓冲区中,凭借CPU更强的处理能力可以对较长的数据包进行检测,而较短的数据包分配至CPU主存储器中的全匹配缓冲区中,凭借GPU更强的多线程并行处理能力可以对较短的数据包进行检测,从而减少GPU并行处理的有效载荷长度多样性。同时,LHPMA-AC分别比仅适用GPU-AC和仅适用CPU-AC方法高出了2.3和3.0倍。这是由于LHPMA-AC综合了CPU较强的处理能力和GPU并行处理能力,提升了CPU/GPU协同检测网络入侵的性能。
4 结束语
本文提出了一种具有数据包有效载荷长度约束的CPU/GPU混合模式匹配算法(LHPMA)来设计NIDS,提高了输入流量中各种有效载荷长度情况下的入侵检测效率。通过预先设定长度约束分离算法(LBSA)对传入数据包进行分类,减少有效载荷长度的多样性。将较长的数据包分配给CPU主存储器的预过滤缓冲区中,直接由CPU访问数据包并根据查找表对数据包进行预过滤,并将预过滤的数据包也发送至全匹配缓冲区。同时,将较短的数据包分配给CPU主存储器的全匹配缓冲区中,并发送至GPU设备内存中,结合AC算法对GPU纹理内存中存储的可疑数据包进行全模式匹配,提升了CPU/GPU协同检测网络入侵的性能。实验结果表明,在LBSA算法中选择适当的长度约束,可以有效提升LHPMA的性能,并且LHPMA的性能优于HPMA以及CPU和GPU的单独处理方法。未来的研究中,将致力于分析输入流量中不同有效载荷长度分布情况,改进 LHPMA方法对CPU/GPU协同处理网络入侵的性能。
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14
军民两用技术与产品(2022年1期)2022-06-01 06:28:34
军民两用技术与产品(2021年12期)2021-03-09 05:38:22
航天工业管理(2020年3期)2020-07-25 01:36:30
电子制作(2019年13期)2020-01-14 03:15:32
移动信息(2018年1期)2018-12-28 18:22:52
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:38
山东工业技术(2015年21期)2015-07-27 08:18:10
项目管理技术(2015年3期)2015-04-23 08:44:29
计算机工程与设计(2012年3期)2012-07-25 11:05:00
