
基于PCA-LDA算法的模拟电路复杂故障在线诊断研究
2022-12-01 02:04:16欧阳洁
计算机测量与控制 2022年11期
欧阳洁
(广州广电计量检测股份有限公司,广州 510656)
0 引言
模拟电路由于其参数可调、功能强大在各个领域得到了广泛的应用,但其容差苛刻、结构复杂所引发的电路复杂故障(多个元器件同时故障)时有发生,由此带来了设备停机、过程等待等令人难以接受的情形。开展在线故障隔离定位研究、从而为精准维修提供条件,是一个重要的研究方向。
传统的模拟电路故障诊断方法包括故障字典法、参数识别法、故障验证法等[1-2]。目前,模拟电路故障诊断一般是针对电路发生的软故障[3]。模拟电路在软故障发生时,表现出容差多样、系统元器件间电气参数耦合性强等特点,导致上述方法在现代复杂电路的精确诊断方面性能较差。随着智能诊断技术的发展,出现了多种新的诊断方法,文献[4]提出了基于PCA(principal component analysis)-LVQ(learning vector quantization)的模拟电路故障诊断,文献[5]提出了BP(back propagation)神经网络开展发控电路故障诊断,文献[6]在时域提取峭度和熵这两类特征参数对模拟电路进行故障诊断,文献[7]和[8]提出了基于RBF(radial basis function)及改进的RBF神经网络的模拟电路故障诊断研究,文献[9-11]对LDA(linear discriminant analysis)进行了改进,并应用于模拟电路故障诊断等相关研究中,文献[12]和[13]研究了基于时域、频域等特征信号的故障诊断,文献[14-16]以电路的故障诊断为基础开展了测试点优化研究,文献[17]提出了基于深度信念网的故障诊断方法。上述文献普遍只研究了模拟电路中的单一元器件失效或简单故障模式问题,未开展诸如出现多个元器件失效模式的复杂故障诊断探讨,部分方法诊断准确率需进一步提高,且没有研究在线诊断问题。
本文基于PCA-LDA算法,开展模拟电路多个元器件同时失效的在线故障诊断研究,为开展精准维修提高技术手段,降低电路故障给其它环节带来的影响。
1 算法原理与应用
1.1 研究问题的数学描述
在模拟电路复杂故障诊断中,若出现多故障模式,反映到电路的输出结果中,表现为样本数据变化多样、难以与故障模式有效匹配。假设在故障定位前,为避免次生影响,不允许拆卸电路板上有可能出现故障的元器件,那么就需要有在线准确隔离定位手段,分辨出确定的故障单元(元器件),方便后续的维修工作。下面对研究问题进行数学描述。
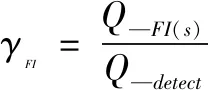
(1)
式中,在隔离率要求高的场合,一般要求隔离到某一确定的元器件,此时s=1,且要求隔离定位元器件采用在线手段,不允选将其从电路板(系统)中拆卸下来,而后用万用表、元器件测试仪等进行测试定位。γFI的结果除与系统诊断能力有关外,也与s的大小有关:在s一定时,γFI越大,系统隔离性能越优越;在γFI一定时,s越小,系统隔离性能越优越。
为评价更加精确定义故障诊断分类的效果,在γFI的基础上,定义分类交叉熵CE:
(2)
式中,yij为样本数据理论上归属某故障模式的标签值,Pij为实际计算出的概率值,U为故障模式的总数,V为某一故障模式中样本的数量。yij取0或1,Pij在(0,1)范围内变化,由式(2)可知,CE越小,故障诊断与隔离定位越准确。在诊断分类精度较高时,CE值一般低于10-3量级。
假定输入样本集与故障隔离集之间有一映射关系:
(3)
论文研究的模拟电路复杂故障在线诊断问题可表述为:为将有故障的模拟电路在线诊断隔离到某确定的元器件,需寻找最优的f、n与tp,目标为:
s.t.γFI≥γFI_set
CE≤CEFI_set
tp≤TP,n≤N,1≤s≤L
(4)
式中,n为样本xi降维过程后的维度,tp为模拟电路测试点数量,TP为可设置的最大值,γFI_set为故障隔离率的目标设定值,CEFI_set为故障隔离时的交叉熵设定值,L为故障隔离时模糊组的最大值,s含义与式(1)相同。该式表明,问题求解可简化为:找寻最优f*、n*与tp*,使得故障隔离率,交叉熵、测试点数量、样本数据维度与可更换元器件数的导数,五者的乘积最大。f过程包括在线数据获取、降维分类、故障诊断隔离等,是决定优化指标的关键,下面,研究f*、n*与tp*的获取方法。
1.2 LDA算法基本原理
从1.1节的寻优目标可看出,如故障电路诊断隔离要到确定的元器件,那么就不能出现模糊组,反映到数据层面上,要求不同类型故障的数据应不能出现误分类。线性判别分析LDA是一种经典的线性学习方法,其思想是:寻找一投影空间,所有样本在该投影空间满足下列要求:同类样本的投影点尽可能接近、异类样本的投影点尽可能远离。对于论文研究的问题来说,就是将模拟电路异类故障模式对应的特征数据尽可能分开、同类故障模式对应的特征数据应尽可能聚集。LDA是有监督的分类法,其分类原理如下[18]。
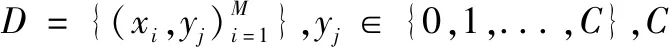
(5)
式中,Sb为类间散度矩阵,其表达式为:
(6)
式中,ki为归属于第i类的样本数量,μ为所有样本的均值。
Sw为类内散度矩阵,其表达式为:
(7)
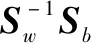
W={wi|wi=eig(Sw-1Sb),i= 1,2,...,R}
(8)
式中,R为矩阵Sw-1Sb的特征向量总个数,W中的各个向量与相应的特征值相对应。为减低数据维度,找寻在其中占据主要贡献的特征值对应的特征向量,将其组合起来,记为Wmin。Wmin与W相比,行数不变,列数减少,即特征向量数量减少,而特征向量的元素保持不变。将样本集D向Wmin方向投影,即完成数据的降维,同时强化了数据的聚集分类,新样本集D′为:
(9)
通过式(9)计算,完成了输入样本集到故障隔离集的降维分类。但计算Wmin时,有一个现实条件需要考虑:Sw并不能保证为正定矩阵,此时,一般需要进行奇异值分解运算,这样易丢失掉零协方差信息,而往往这些分类信息较为重要、影响投影方向,最终导致求出的D′达不到最优。
1.3 PCA算法
式(7)中,Sw不为正定矩阵的原因多为样本数与样本维数相当所致,故在进行LDA运算前,常需要先减少样本维数(可视为第1次降维)。PCA和KPCA(kernelized principal component analysis)是目前较为常见的属性约减方法。PCA可在一定条件下,将样本中有效属性保留,而去掉对样本影响作用甚小的属性。而KPCA将样本属性之间关系视为非线性,将样本属性通过函数关系映射高维空间,转换为线性关系后,进而完成属性约减。本文所研究的模拟电路,在不同的分段区间,属性之间呈现较强的线性关系,故采用PCA进行属性约减。PCA可很好解决各类降维问题[19]。
PCA的基本思想是:将样本向某一空间投影,为使投影后的样本信息得到最大保留,应使所有样本的投影尽可能分开,即应该使投影后样本的方差最大化。该思想与LDA并无冲突,LDA用作分类,要求不同类样本集分开,而PCA用于属性约减,其方差最大化可视为属性约减后,“主要成分”得到最大保留。其基本过程如下:
设样本集E={o1,o2,...,oi,...,on},其中oi为E中的一个样本,其包括m个元素(属性),可看作m维列向量。
为消除样本属性之间的数值大小差异性,对E进行归一化操作,即矩阵的每行均值为0,标准偏差为1。归一化后的样本记为qi,计算所有样本qi的属性协方差矩阵∑:
(10)
对∑进行特征值分解,取最大的K个特征值对应的特征向量,构成特征向量矩阵:
W=(w1,w2,...,wK)
(11)
将矩阵E投影到W张成的空间中,生成新的样本集E′:
E′=WTE
(12)
通过上式,约简了样本的特征属性,从而避免了LDA运算时出现奇异值问题。
1.4 PCA-LDA算法的应用
1.4.1 信息获取
对模拟电路故障诊断信息的在线获取来说,测试点设置遵循的原则如下。
原则1:获取的模拟电路测试点信息应准确;应能最大程度反映电路内部状态;信息应能方便获取,即可达性要好,方便实现。
在模拟电路的测试点设置中,一般认为输入点、输出点是可测试的;输入点、输出点通过相关手段,可与其它电路(系统)电气隔离。
本文研究模拟电路中具有代表性二阶带通滤波器电路,电路原理图如图1所示。
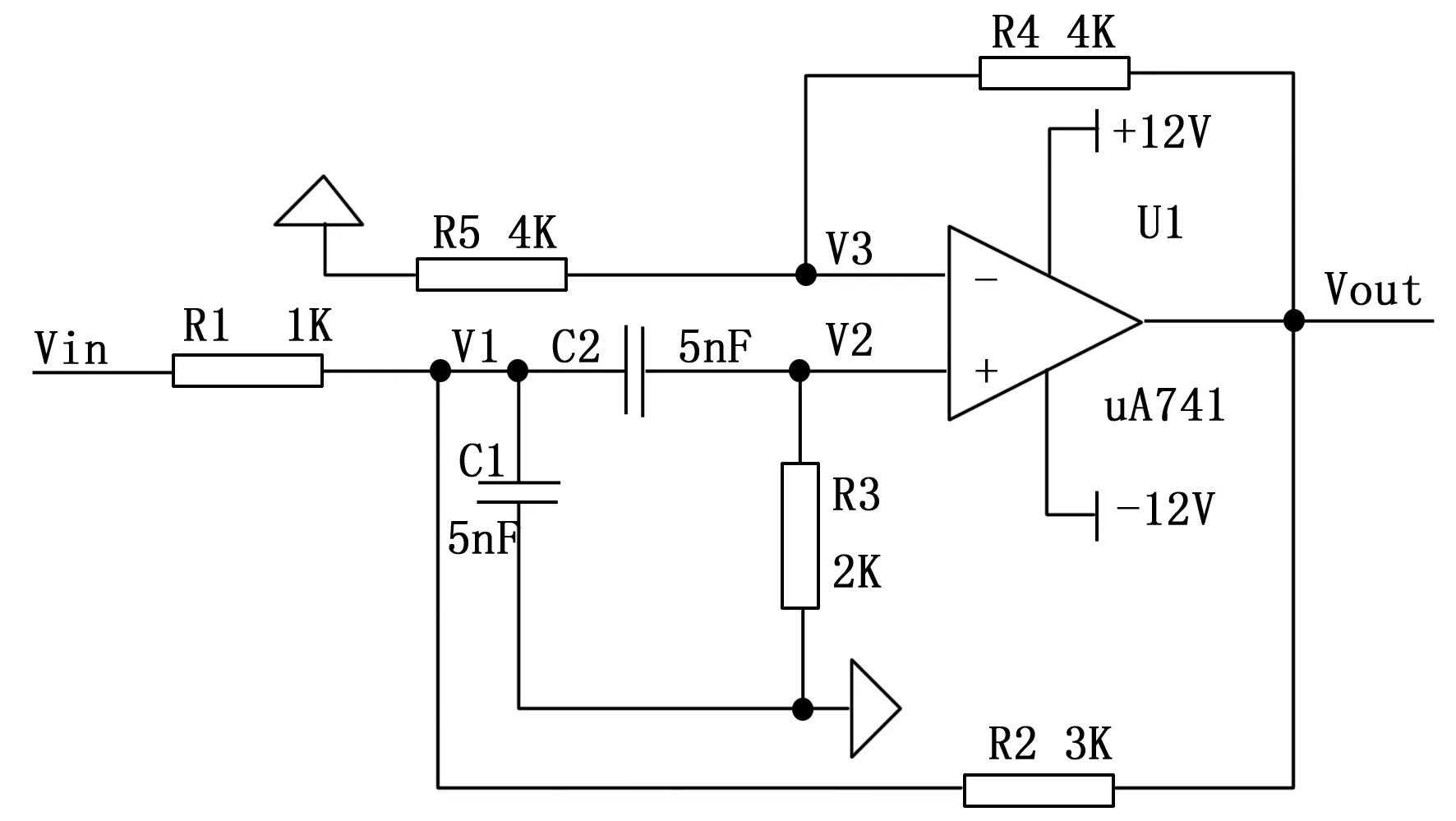
图1 二阶带通滤波器电路原理图
图1中,C1、C2、R1、R2和R3等元器件均为可更换元器件,如出现故障,需要对其进行在线故障诊断隔离定位。该图的工作模式包括正常工作与故障,论文具体研究以下10类代表性工作模式:正常工作、“C1↓”、“C1↑”、“C2↓”、“C2↑”、“R2↓”、“R2↑”、“C1↑and R2↓”、“R3↓”、“C1↑and R2↓and R3↓”等,↑表示某类元器件参数值偏离高于标准值,↓表示低于标准值,“C1↑and R2↓”表示同时出现C1电容值上升和R2电阻值下降故障,“C1↑and R2↓and R3↓”表示同时出现C1电容值上升、R2电阻值下降和R3电阻值下降故障。
现讨论对上述故障进行诊断的测试点选取问题,电路输出点Vout的电压值方便测量,并且该电压值与电路的多个元器件参数相关联,能够反映各个元器件的状态,故选取该测量点的电压值作为特征值。从故障诊断的角度来说,单点(单时单频)的电压值信息量过少,无法完成电路的准确故障诊断。可从时域和频率两方面入手,通过在电路输入点Vin施加动态变化的激励信号,获取输出点Vout的多个特征值。时域层面,可获取的信息包括上升时间、稳态时间、过冲量等,这些信息需要二次计算才能获取到。频率层面,通过扫频手段,可直接获取中心频率上下的多个电压值,方便后续诊断工作,故论文提取二阶模拟电路的幅频值作为诊断数据的输入。
在上述环节设置电路的总输出点作为特征值的信息获取点。在某些诊断、隔离定位场合,可能会出现该点的所有信息无法满足故障隔离的指标要求,此时,需要增加内部测试点数量,例如增加V1、V2、V3作为测试点。内部测试点的增加按照原则1开展,实际过程中以该测试点关联的元器件大小数量作为该测试点选用的先后顺序。
1.4.2 样本降维与分类
为提高故障诊断的速度、减小系统的复杂程度,减少输入到诊断系统的样本维数一直是研究人员关注的焦点。事实上,一个样本中,往往是少数属性对故障诊断发挥着重要作用,并且多数属性之间存在着较强的关联性。论文研究样本数据属性之间的相关性,对其属性进行降维。同时,考虑不同模式样本之间差异,对其进行分类。以1.2和1.3节原理为基础,给出样本降维与分类的流程图,如图2所示。
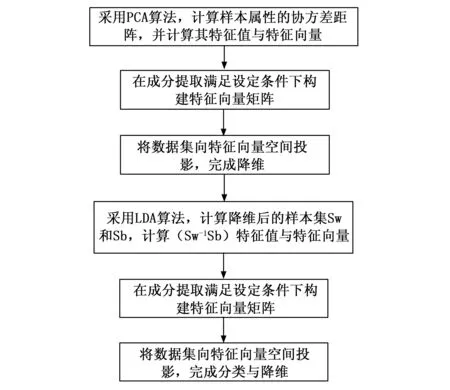
图2 PCA+LDA数据降维与分类流程图
图2中,主要开展的步骤包括两部分:
1)PCA降维。基于PCA算法对原始数据样本进行降维,特征向量的选取以主成分贡献率达到预先设定值为准。
2)LDA分类降维。为将样本数据集进行有效分类,采用LDA算法,将同类数据聚集、异类数据分离,实现样本数据的有效分类。为保证后面环节得到足够多的数据,一般主成分贡献率可设置较高数值,然后再根据需要依次约减。
1.4.3 故障诊断
通过上述方法,数据完成采样、降维后,已经属于分类完备的数据集,不同故障模式对应不同的数据。为方便诊断辨识,采用机器识别的方法进行分类,自动给出结果。人工神经网络在分类中得到广泛应用,且分类精度高,论文采用三层BP神经网络进行故障识别。同时,按照式(4)过程,故障的诊断与隔离定位是寻优迭代过程,降维诊断整体流程如图3所示。
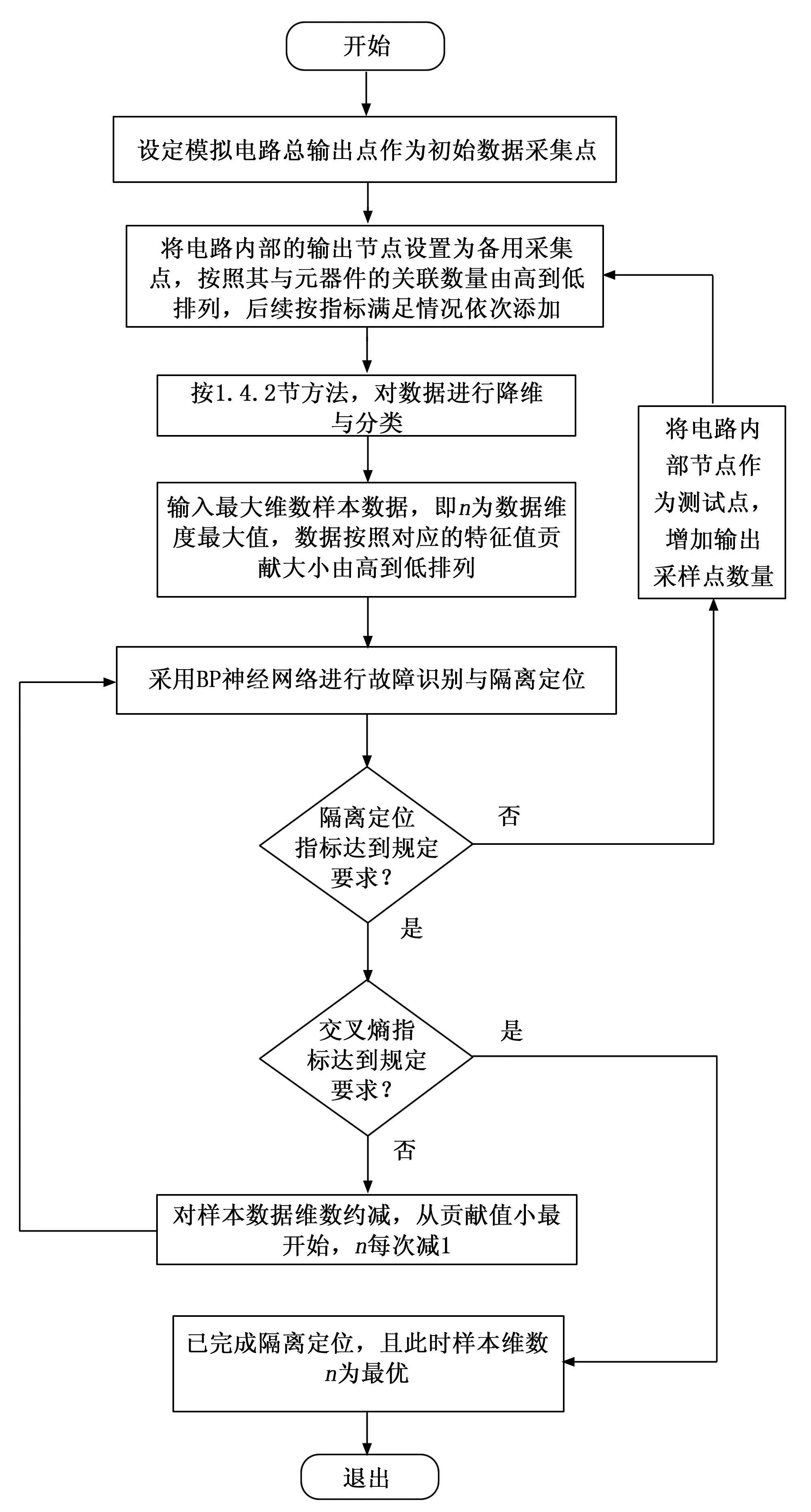
图3 论文降维分类诊断流程图
图3中,在线故障诊断、隔离定位是一循环迭代过程。具体步骤是:
1)在测试点数量最小化的原则采集数据。通过1.4.1方法,提取电路总输出点的幅频值,并采集部分备份测试点数据。
2)样本数据的初步降维、分类。按照1.4.2方法进行PCA、LDA降维、分类。PCA降维后,要求数据的维度远小于数据个数,实际计算时,可按照数据样本数的50%进行降维约减。事实上,经验数据结果表明,对样本分类起关键作用的属性数要小于50%。进一步,LDA分类后,数据的维度在满足小于C-1条件下,取其最大值,C为故障类别总数。
3)故障识别、隔离与定位。将降维、分类后的最大维数样本数据作为神经网络的输入,采用BP网络进行分类、识别。故障隔离定位是关注的首要目标,故先计算此时的故障模式识别正确率(故障隔离正确率)、可更换元器件数,若达到要求,转向后续步骤4,若不满足要求,回到步骤1),然后再向下运行。

表1 不同工作模式下采集到的部分原始样本数据
4)样本的再次降维。计算此时的交叉熵值,指标达到规定要求后,按照样本属性对识别的贡献率依次减少样本数据维度,直到网络出现故障模式识别错误为止。
5)所有循环过程结束后,流程退出,得到最优结果,式(4)完成寻优过程。
2 实验验证
2.1 数据的获取
按照1.4.1中数据获取方法,对图1电路的样本数据进行采集,具体过程如下:
1)电路工作模式设置。预先设定图1电路处于正常、单故障、双故障、三故障等10种工作模式,具体见1.4.1节。
2)测试点与频域设置。在电路输入端Vin加上1 V有效值的交流正弦信号,测量输出点的幅频值。对该电路分析可知,其在元器件参数正常工作条件下,中心频率为25 kHz。对电路进行频率扫描,频率范围为从1 kHz到1 MHz,关键频率点10倍递增,即1 kHz、10 kHz、100 kHz、1 MHz,3个频率段内采样10个频率点,测量输出点Vout在各个频率点电压值,这样,每个工作模式样本包含31个特征值。同时在V1、V2、V3也采集到相应的特征值备用。
3)电路仿真。对元器件的故障以偏离标准值50%进行设定,即“C1↑”表示C1电容值为7.5 nF,其他元器件故障符号与此类似。对每类工作模式开展400次蒙特卡罗仿真,仿真时,电阻值和电容值均偏离标准值5%。通过仿真,获取到输出点10类、每类400个样本、每个样本包括31个属性,共计4 000个样本数据,典型部分数据如表1所示。
2.2 数据降维与分类
2.1节输出点数据样本中,每类模式的样本数据容量为400,数据的维度为31,先开展PCA降维,然后通过LDA再进行降维分类。过程如下:
1)PCA降维。通过图2的方法,对上述4 000个样本数据进行降维与分类,PCA降维后,按10类模式的特征值贡献率均达到99.999%计算,样本数据的维度由31降到13。
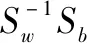
文献[4]和[20]表明,其单一故障模式的样本数据维度分别为5(贡献率为90%)和12,而本文3个以上多故障模式的样本数据维度为3(贡献率为98.8%),反映了数据降维的效果更加明显。

表2 不同工作模式的样本数据降维分类后结果
2.3 诊断与结果评价
按照图3的流程方法,开展寻优迭代过程。具体如下:
1)设置关键技术指标。取测试点个数tp为1,数据维度n为7,设定故障隔离率γFI为100%,可更换元器件数s=1,测试数据的交叉熵CE≤8.0×10-4。
2)BP神经网络训练与测试。将2.2中4 000个降维分类后数据输入到BP神经网络中,网络输入元素(特征属性)个数初始值为7,隐藏层神经元个数为10个,输出为10个元素,每个元素对应一种工作模式,元素值可取0或1,1代表该模式为真,0为假。例如,输出值若为{1,0,0,0,0,0,0,0,0,0}代表电路正常工作,无其它任何故障。70%数据用于训练、15%数据用于验证、15%数据用于测试,以tan-sigmoid函数进行输出层的激活,采用Softmax函数进行多模式分类,输出归属各类的概率值,以式(2)计算出的交叉熵为损失函数,以其不再下降为停止条件,经过多次训练验证、网络在Epoch为60左右结束,寻找到各层的最优连接权值和偏置值。计算机运行环境为:操作系统为Win7、i5处理器、3.3 G主频、8 G内存。
3)输出BP神经网络结果。通过训练与测试后,神经网络对每类故障模式都能正确识别(以Softmax函数输出值高于99.7%认定为归类正确)。按照所有样本数据的计算分类结果:Softmax函数输出值(即样本数据归属各类故障模式的概率)均高于设定值,可认为故障隔离率γFI为100%,而各类故障模式中每个可更换元器件的故障类型组合为确定的状态,即可更换元器件数s=1。可认为tp数量设置为1,满足隔离定位要求,不需要再增加测试点。然后,计算测试数据的交叉熵,结果均在6.0×10-4以下,满足CE≤8.0×10-4的要求。
4)循环迭代。减少网络输入元素个数,循环上述过程,直到网络出现模式识别(归类)错误为止。
5)输出最终结果。经过迭代,网络能够正确识别的工作模式对应的输入元素个数为3,即数据样本降维后的最优维度结果为3维。这样,通过数据获取、降维、分类、诊断隔离,式(4)中的f过程得以完整实现,2.1中的4 000个数据与10类工作模式得到正确映射表达。
现对本文采用的降维分类、诊断方法进行评价。相对其它类型的数据获取、分类降维方法,可从数据样本降维后的维度、测试点数量、可更换元器件数,异类数据的类间距离和、同类数据的类内方差和、类间距离和与类内方差和的比值、分类结果交叉熵、故障隔离率等多个指标进行评价。论文对PCA+LDA算法、LDA算法、KPCA+LDA算法、KPCA算法、PCA算法等5种算法的评价指标结果进行了计算,结果如表3所示。
1)论文采用的降维算法降维效果较优。5类降维算法在准确分类最低维度要求是:PCA-LDA为3维、LDA为5维、KPCA-LDA为5维、KPCA为3维、PCA为5维。如采用LDA算法降维后的4维数据,则分类有错误,准确率为92.6%;如采用KPCA-LDA算法降维后的4维数据,则分类有错误,准确率为97.5%;如采用PCA算法降维后的4维数据,则分类有错误,准确率为96.7%。同时,论文也对原始样本数据进行了分析,得出:采用不降维的样本数据进行故障诊断,也能实现准确分类;但将两种维度:31和3进行比较,明显,降维后的数据容量更小,方便后续处理。由此可见,PCA-LDA和KPCA两类算法在降维效果方面优于其他三类降维算法及不降维过程,下述环节,重点比较这两类算法。
2)论文与KPCA算法比较,综合指标最优。相对于单个Sum_Sb1和Sum_Sw1结果,更关注整体指标Sum_Sb1/ Sum_Sw1,通过表3可看出,论文提出的PCA+LDA算法在Sum_Sb1/ Sum_Sw1、交叉熵CE等指标方面优于KPCA算法。表明论文将样本数据归类在“同类高类聚,异类低耦合”方面表现更加优异。
3)论文实现了模拟电路的准确在线诊断。论文提出的PCA+LDA算法及诊断方法对10类工作模式、4 000个样本数据进行准确映射,实现了图1电路中的正常工作、“C1↓”、“C1↑”、“C2↓”、“C2↑”、“R2↓”、“R2↑”、“C1↑and R2↓”、“R3↓”、“C1↑and R2↓and R3↓”相关模式的正确分类,C1、C2、R1、R2和R3等元器件偏离标准值的单一或组合软故障均得到了正确识别。文献[4]实验结果表明,其在数据样本为5维条件下进行单故障分类时,存在故障模式误分类情形,准确率为97.6%。与其比较可知,本文准确率100%,且故障模式研究更加全面(考虑了多故障)。综合比较来看,本文研究的模拟电路复杂故障在线诊断方法在可行性、准确性方面达到了1.1节提出的要求。
3 结束语
论文采用PCA+LDA方法,对模拟电路复杂故障在线诊断进行了研究,提出了多故障模式下的可更换单元的隔离定位方法。给出了测试点设置与幅频数据获取方法;对样本数据进行了有效分类与降维;对电路工作模式开展了有效识别,准确定位了故障元器件;仿真结果表明了论文方法的有效性。论文在增加内部测试点时,按照该点与其它元器件的关联数量优选,该方法考虑较为单一,后续可在模拟电路测试点设置最优条件下开展复杂故障在线隔离定位研究,提高故障诊断的效费比。
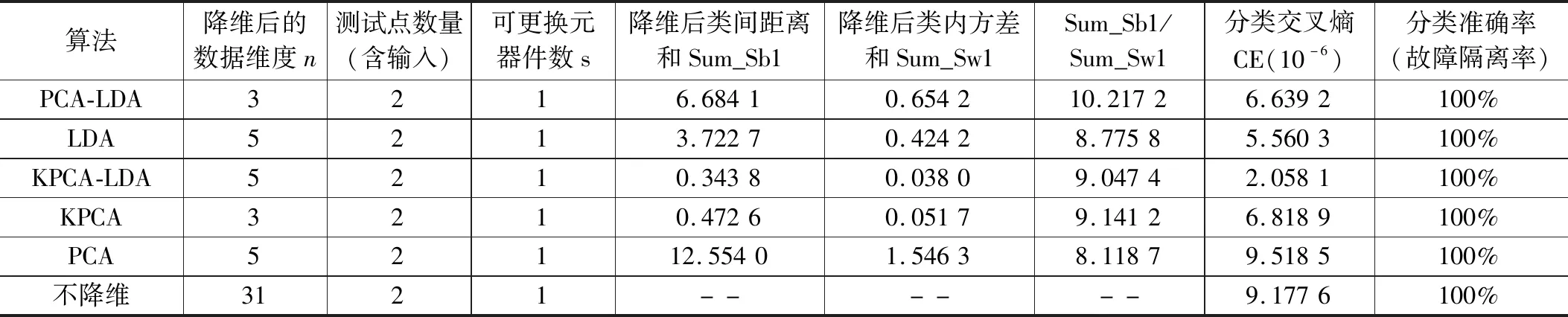
表3 论文所采用算法与其它算法的结果对比
猜你喜欢
机电信息(2023年24期)2023-12-26 10:55:38
车主之友(2022年4期)2022-08-27 00:57:12
军民两用技术与产品(2022年7期)2022-08-06 07:19:10
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
上海大学学报(自然科学版)(2020年4期)2020-05-24 07:29:38
海峡姐妹(2019年12期)2020-01-14 03:24:40
中国军转民(2017年11期)2018-01-31 02:18:01
计算机测量与控制(2017年6期)2017-07-01 16:24:02
橡胶工业(2015年7期)2015-08-29 06:33:46
计算物理(2014年1期)2014-03-11 17:00:18
