
基于多粒度特征生成对抗网络的跨分辨率行人重识别
2022-11-30 07:41耿艳兵廉永健
计算机应用 2022年11期
耿艳兵,廉永健
基于多粒度特征生成对抗网络的跨分辨率行人重识别
耿艳兵,廉永健*
(中北大学 大数据学院,太原 030051)(∗通信作者电子邮箱lyj@nuc.edu.cn)
现有基于生成对抗网络(GAN)的超分辨率(SR)重建方法用于跨分辨率行人重识别(ReID)时,重建图像在纹理结构内容的恢复和特征一致性保持方面均存在不足。针对上述问题,提出基于多粒度信息生成网络的跨分辨率行人ReID方法。首先,在生成器的多层网络上均引入自注意力机制,聚焦多粒度稳定的结构关联区域,重点恢复低分辨率(LR)行人图像的纹理结构信息;同时,在生成器后增加一个识别器,在训练过程中最小化生成图像与真实图像在不同粒度特征上的损失,提升生成图像与真实图像在特征上的一致性。然后,联合自注意力生成器和识别器,与判别器交替优化,在内容和特征上改进生成图像。最后,联合改进的GAN和行人ReID网络交替训练优化网络的模型参数,直至模型收敛。在多个跨分辨率行人数据集上的实验结果表明,所提算法的累计匹配曲线(CMC)在其首选识别率(rank‑1)上的准确率较现有同类算法平均提升10个百分点,在提升SR图像内容一致性和特征表达一致性方面均表现更优。
跨分辨率;行人重识别;生成对抗网络;自注意力机制;多粒度特征
0 引言
行人重识别(Re‑IDentification, ReID)[1]是对一定时间内出现在不同监控区域里同一行人的身份确认,为行人跟踪、行人检索以及行为分析等研究提供技术支撑。现有研究更多关注于高分辨率(High Resolution, HR)的行人图像[2-4],然而在实际监控中,监控距离和监控环境的不同以及摄像头质量的差异,造成同一行人在不同的监控视频中具有明显的分辨率差异。在这种情况下,高分辨率的行人图像具有丰富的细节信息,而低分辨率(Low Resolution, LR)的行人图像细节模糊,二者可有效提取的特征不一致,给行人的准确重识别带来挑战。
针对跨分辨率图像存在的特征表达不一致问题,最初的办法是对HR图像下采样或者对LR图像插值上采样,然而前者会造成细节信息的丢失,后者只是对现有的像素内容进行插值运算,并不能恢复丢失的图像细节。自2015年起,国内已经有研究者关注跨分辨率行人ReID的研究[5-7],尝试将HR和LR图像特征映射到共同的特征空间,学习分辨率不变的特征表达,但由于存在于HR图像中丰富的细节内容在LR图像大量丢失,这类方法为保持跨分辨率图像特征在特征空间的一致性,而难以学习到细粒度的鉴别信息。文献[7-14]的研究试图借助超分辨率(Super Resolution, SR)重建技术恢复丢失的图像细节。其中:Wang等[9]将半耦合字典学习模型用于图像的SR重建,该方法虽然对复杂度低的图像效果较好,但对纹理结构丰富的图像则效果一般。随着深度学习技术在图像处理领域的广泛应用,Dong等[10]构建了SRCNN,将卷积神经网络(Convolutional Neural Network, CNN)用于图像的SR重建,有效改善了重建图像效果,但依然会损失部分细节信息。鉴于生成对抗网络(Generative Adversarial Network, GAN)[15]在图像生成和风格迁移等领域的突出表现,Ledig等[11]提出基于GAN的图像超分辨率(SRGAN)算法,重点研究图像内容在高频细节上的信息恢复。上述研究为提升图像视觉上的清晰度,关注重点为重建图像在内容细节信息方面的恢复,对保持重建图像在特征一致性方面存在不足,无法满足提升图像识别性能的需要。
近年来,国内也有研究者陆续尝试将SR重建应用于跨分辨率行人ReID问题[16-19],重点关注将SR重建后的图像用于提升重识别的性能。其中,鉴于跨分辨率行人除了面临特征表达不一致问题外,同一行人不同图像的表观差异问题也将影响重识别的准确性,文献[17-18]尝试采用级联SR和行人ReID的多任务联合学习框架来解决这一问题。Jiao等[17]构建了SR重建和行人ReID联合学习网络将LR行人图像的SR重建和行人ReID任务联合优化,以提升跨分辨率行人ReID的准确度。CSR‑GAN[18]通过级联多个GAN逐步恢复LR行人图像的细节信息,以解决跨分辨率行人图像在匹配过程中的特征空间不一致问题。然而上述方法都需要在训练过程中预知图像的分辨率大小,这在实际应用中难以实现。Li等[19]提出跨分辨率对抗双边网络,将学习分辨率不变特征表达和SR相结合,在学习分辨率不变表达的同时有效恢复LR图像的细节信息;但是,由于通过级联的模型向后传播梯度的难度显著增加,因此这种设计存在模型训练无效的问题。Cheng等[20]提出了任务间的关联机制,通过构建关联评论网络,联合学习SR网络和行人ReID网络,增强二者的兼容性。上述方法验证了GAN在恢复图像细节方面的优势,但在利用GAN生成HR图像时,更多通过保持SR图像与真实HR图像在内容上的一致性来提升生成图像质量。而在跨分辨率行人ReID应用中,重点是能够通过保持SR图像与真实HR图像在特征上的一致性,提升重识别的准确性。
为此,本文提出一种基于多粒度信息生成网络的跨分辨率行人ReID方法。该方法设计了一种新型的多粒度信息融合生成对抗网络,该网络为提升生成图像的纹理结构细节信息,首先将自注意力机制引入到生成器中,同时在生成器后增加一个识别网络,联合生成网络和识别网络进行多粒度信息融合,在训练过程中联合最小化SR图像和真实HR图像在像素级内容损失、中低层特征损失和高层语义损失,使生成的SR图像尽可能保持与真实HR图像在特征表达上的一致性,满足识别的需要。
1 本文方法
1.1 框架概述
本文提出的基于多粒度信息生成网络的跨分辨率行人ReID方法包含两个网络:多粒度信息融合的生成对抗网络和行人ReID网络。整体框架如图1所示。
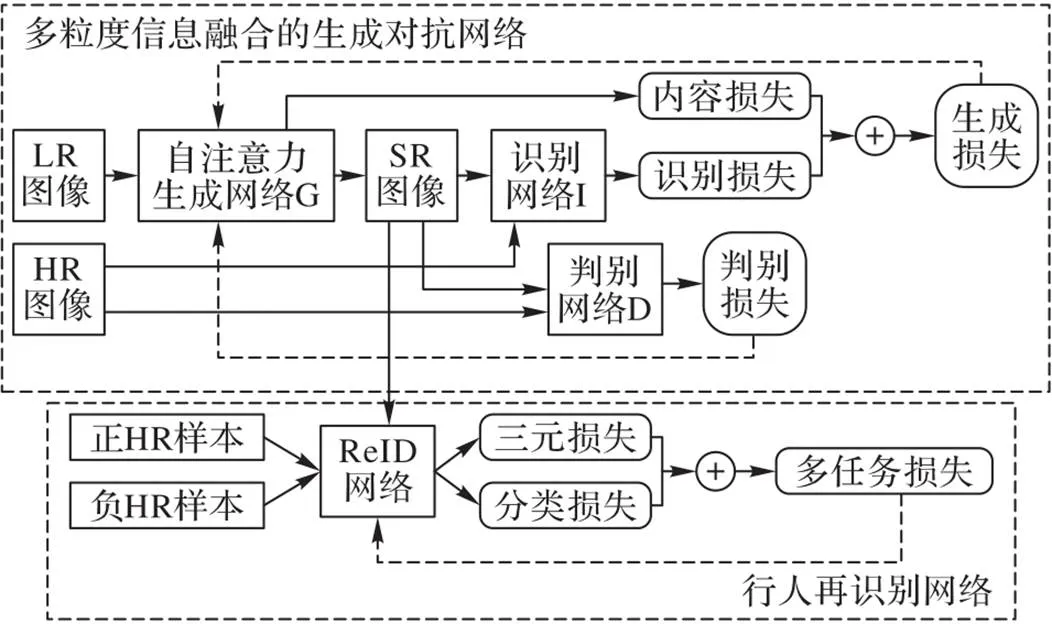
图1 本文方法的整体框架
图1中的多粒度信息融合的生成对抗网络部分由基于自注意力机制的生成网络G、识别网络I和判别网络D组成。其中网络G负责将LR的行人图像生成HR的行人图像,在此基础上,网络I通过识别生成的SR行人图像的与真实的HR行人图像在身份特征上的一致,确保生成的SR图像在特征表达上能够满足识别的需要。网络G和网络I联合用来估计真实图像的数据分布,从而生成判别网络D无法分辨的图像;判别网络D用以辨别一个样本来自真实HR图像数据而非SR图像的概率。在训练过程中,两者交替优化,直至判别网络无法“判伪”,达到纳什均衡状态。模型的具体训练过程将在1.4节进行详细说明。
图1中的行人ReID网络以生成的SR图像、相对于SR身份的正、负HR样本组成三元组,输入行人ReID网络进行特征提取,通过联合最小化上述特征的三元损失和分类损失,反向传播优化行人ReID网络的参数,提升行人ReID对表观差异问题的鲁棒性。
上述两个网络在训练过程中采用交替优化方式,提升跨分辨率行人ReID的准确性。
1.2 多粒度信息融合的生成对抗网络
本文首先介绍多粒度信息融合的生成对抗网络。基于GAN的基础框架,考虑到GAN在结构信息生成方面劣于纹理细节信息的生成,为确保网络G能够在生成HR行人图像的过程中恢复具有结构关联的区域,参考文献[21-23]中提出的结合注意力机制的生成对抗网络,在进行图像SR重建时能够有效重建图像的结构关联区域,本文将自注意力机制引入到生成器G中,确保生成的图像在纹理细节和结构上都具备较好的生成能力。此外,本文在生成网络G之后增加一个识别网络I,通过最小化生成的SR行人图像与真实的HR行人图像在多粒度上的特征损失,提升生成的SR图像在特征表达方面与真实HR图像的一致性。
参考文献[24],生成网络G的结构如图2下半部分框图所示,包含3个卷积层、9个残差块和3个反卷积层。其中每个卷积层后面跟着一个实例规范化层(Instance Normalization, IN)和一个激活层ReLU。反卷积层也包含相同的IN和ReLU。其中,在每个卷积层都增加一个自注意力模型,自注意力模型的结构如图2上半部分框图所示。

图2 自注意力生成器的结构

生成网络的内容损失可表示为生成图像和真实图像的像素级损失,即:
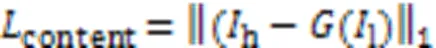
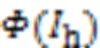

将生成网络的内容损失和识别网络的识别损失加权融合即为生成损失:

判别网络D的网络结构由5个卷积层组成,每个卷积层都跟随一个归一化(Batch Normalization, BN)层,其中前4个BN层均采用ReLU激活函数进行非线性变换,最后一个BN层采用正切函数进行数据的非线性处理。本文采用WFAN‑GP[26]作为网络D的判别损失,如式(4)所示:
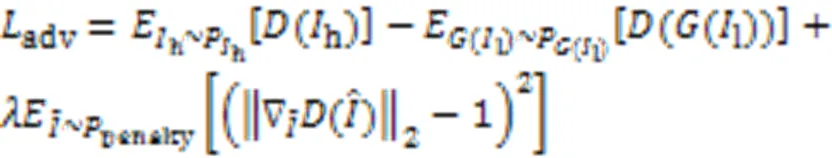
其中:

因此,本文提出的基于多粒度信息融合的生成对抗网络的目标函数可以表示为:
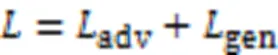
1.3 行人重识别网络
行人ReID网络采用ImageNet[25]上预训练的ResNet50网络为基础骨干网络,本文采用联合多任务损失函数[27]从多个角度优化网络模型参数。本文的多任务损失函数包含式(7)所示的softmax分类损失函数和式(8)所示的triplet三元组损失函数。。

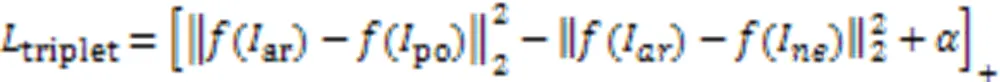
最后,采用式(9)对softmax损失和三元组损失[28]进行不同损失上的融合,以权衡不同损失函数对参数优化的作用:

1.4 模型训练
本文对于生成对抗网络和行人ReID网络的训练采用交替训练的方式进行。首先使用原HR行人图像预训练行人ReID网络,然后固定其参数,进行生成对抗网络的训练。多粒度信息融合的生成对抗网络的训练以摄像机B下的HR、SR行人对为输入,对于模型中的生成网络、识别网络和判别网络采用交替训练的方式进行参数优化,即在判别网络参数固定的情况下,联合优化生成网络和识别网络,然后固定生成网络和识别网络的参数,优化判别网络的参数,直至模型收敛。根据式(6)所示的网络优化目标函数,对生成网络和判别网络的参数进行交替优化,具体如下:
1)初始化判别网络和生成网络的参数;保持生成网络的各项参数不变,先使用真实的数据集训练判别网络,让判别网络获得一个“标准”;再保持判别网络的各项参数不变,训练生成网络。
2)生成网络和识别网络的参数优化:将LR行人图像由模型中的生成网络生成SR行人图像,利用式(1)计算内容损失;然后将生成SR图像和真实HR图像组成图像对,输入识别网络,利用式(2)计算识别损失;最后通过计算式(3)的生成损失,进行反向传播进行参数优化。
3)将摄像机B下的HR图像和生成的SR图像输入判别网络D,利用式(4)计算判别损失,进行反向传播进行网络参数的优化。
4)迭代步骤1)~3),直至判别网络无法“判伪”,达到纳什均衡状态。
5)固定上述生成对抗网络的模型参数,将生成的SR行人图像与摄像机A下与其相对的HR行人正负样本组成三元组,输入行人ReID网络,利用式(7)~(9)计算多任务损失,根据结果反向传播进行行人ReID网络参数的优化。
6)多粒度信息融合的生成网络和行人ReID网络采用交替训练的方式进行参数优化,直至模型收敛。
2 实验与结果分析
2.1 数据集与实验设置
本文选用在跨分辨率行人ReID方面具有挑战性的行人重识别数据集CUHK03、VIPeR、DukeMTMC‑reID、Market1501和CAVIAR进行实验验证。其中:CUHK03数据库包括1 360个行人的13 164幅图像,数据量大,拍摄范围广;VIPeR数据库包含632个行人的1 264幅图像,每个行人的两幅图像具有明显的拍摄视角变化和光照变化;Maket1501数据集包含1 501个行人的32 668幅图像,由于图像来自5个高清摄像机和1个低清摄像机,部分图像的分辨率差异明显;DukeMTMC‑reID数据集包含1 404个行人的36 411幅图像,由8个摄像机同步拍摄,较CUHK03数据库的拍摄角度变化更大、拍摄范围更广。
所有图像统一调整为256×128像素大小。在缺少SR行人图像库的情况下,对CUHK03、VIPeR、DukeMTMC‑reID和Market1501数据集,分别对其中一个摄像头下的行人图像,随机采用{2,3,4}中的采样率进行下采样,再通过双三次插值到256×128像素,模拟得到低分辨率行人图像。参照文献[19-20],将经过下采样处理过的上述数据库分别命名为MLR‑CUHK03、MLR‑VIPeR、MLR‑DukeMTMC‑reID和MLR‑Market1501。将上述每个数据库中的行人平均分成两部分,分别用于训练和测试。CAVIARED数据库是在一个购物中心从不同摄像头获取的视频中选取的72个行人的1 221幅图像,除了一些光照、姿态以及视角变化外,不同于其他库最大的挑战是图像分辨率介于17×39像素到72×144像素之间,变化大,且大多图像的分辨率普遍较低,本文去掉22个高分辨率行人的图像,其余行人均分两组,分别用于训练和测试。由于CAVIAR数据集本身包含大量的低分辨率图像,本文采用真实的低分辨率行人图像进行模型训练。

2.2 消融实验
为了研究所提多粒度信息融合生成网络的有效性,本文主要对组成该网络的两个关键部分:自注意力生成网络和识别网络在MLR‑CUHK03数据集上分别开展定量实验和定性验证。在定量实验中,本文参考现有图像生成质量的客观评价方法,分别选用结构相似性(Structural SIMilarity, SSIM)、峰值信噪比(Peak Signal‑to‑Noise Ratio, PSNR)和学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)三个指标评价本文方法生成SR行人图像的质量。此外,针对行人ReID的任务需要,还选用累计匹配曲线(Cumulative Match Characteristic, CMC)在rank‑上的重识别准确率评判模型的有效性。其中:SSIM用于量化评测两幅图像间的结构相似程度,取值介于0到1之间,值越大图像相似度越高;PSNR用于评测图像的失真程度,值越大表示图像失真越少;LPIPS用于度量图像间的差异程度,值越低表示两张图像越相似;CMC在rank‑上的重识别准确率则表示匹配结果中第张图是正确结果的概率。
2.2.1自注意力生成网络分析
保持行人ReID网络不变,本节首先验证自注意力模型在生成网络中的有效性。从表1可知,相较于传统GAN,在GAN上引入自注意力模型(即“GAN+自注意力”)后,生成的HR图像在SSIM和PSNR两个指数上有了明显提升,而LPIPS下降明显,生成图像和真实图像在像素级更为相似。生成的HR行人图像用于行人ReID时,识别的准确率较传统GAN有了明显的提升。而在GAN中引入识别网络且只考虑高层语义损失(即“GAN+识别网络(高层损失)”)时,其图像的生成质量相比“GAN+自注意力”也有明显提升,再次验证了自注意力模型在图像的纹理结构等细节信息生成方面的优势。但是,当生成的SR图像用于行人ReID时,“GAN+自注意力”在rank‑1上的识别准确率明显劣于“GAN+识别网络(高层损失)”的识别准确率,由此验证了本文所提识别网络在保持生成SR图像与真实HR图像在特征一致上的有效性。
2.2.2识别网络分析
本节进一步分析所提出的识别网络和该网络在联合特征损失和语义损失方面的有效性。
从表1可知,将本文所提的识别网络和传统GAN相结合时,为了确保生成的HR行人图像的与真实的HR行人图像在身份特征上的一致性,在只考虑识别网络高层语义特征损失(即“GAN+识别网络(高层损失)”)时生成的SR行人图像用于行人ReID的准确率也有了明显的提升;但生成的SR图像在SSIM和PSNR两个指数上低于引入自注意力模型的GAN(即“GAN+自注意力”),且LPIPS明显升高。由此验证了本文所提识别网络能够提升生成SR图像与真实HR图像在特征上的一致性,但在图像生成质量上略显不足。

表1 多粒度信息融合生成对抗网络在 MLR‑CUHK03数据集上的消融实验结果
此外,在只考虑识别网络中低层特征和内容损失时(即“GAN+识别网络(中低层损失)”),生成的SR行人图像用于行人ReID时,识别的准确率较“GAN+自注意力”提升明显,由于在识别网络中考虑了和自注意力类似的内容损失,生成的SR图像在SSIM、PSNR和LPIPS三个指数上与“GAN+自注意力”基本保持一致。由此验证了所提识别网络在融合中低层信息时,不仅能够提升生成SR图像与真实HR图像在特征上的一致性,还可生成较高质量的SR图像。
类似的结论可在引入自注意力机制的情况下得到,且在生成图像的质量和重识别准确率上较上述方面有了更进一步的提升。在计算识别网络的损失函数时,同时考虑多粒度信息的特征损失(即同时计算高层语义损失和中低层特征损失),生成的HR图像在SSIM和PSNR两个指数上较单层特征损失提升明显,而LPIPS明显下降,说明多粒度信息融合下的识别网络能够确保生成的HR行人图像在像素级质量更接近真实图像;同时,这种情况下,生成的HR行人图像用于行人ReID比对时,识别的准确率提升明显,说明联合识别网络的生成网络生成高分辨率图像在特征表述方面也更接近于真实图像。而同时联合引入自注意力机制的生成网络和多识别网络,生成的高分辨率行人图像的质量在用于重识别时的准确率达到最优,验证了所提多粒度信息融合生成网络的有效性。
2.2.3定性分析
为了进一步验证本文所提多粒度信息融合生成网络的两个重要组件:自注意力生成网络和识别网络在生成图像细节恢复上的有效性,在MLR‑CUHK03数据集上通过可视化生成图像定性分析上述两个组件。

图4 多粒度信息融合生成对抗网络的不同组件在MLR‑CUHK03数据集上的可视化结果
2.3 与现有方法的比较
本文与现有同类方法在不同数据集上的重识别性能在CMC上的比较结果如表2所示,通过比较每种算法首选识别准确率(即rank‑1)和正确匹配结果出现在前5位的识别准确率(即rank‑5),可以得到如下结论:
1)将现有基于HR行人的重识别方法直接用于跨分辨率的行人ReID,如CamStyle[29]和FD‑GAN[30],识别性能下降明显,说明待识别行人的分辨率差异导致的特征分布不一致会严重影响重识别的准确性。
2)相较于现有SR行人ReID方法,本文算法明显优于基于字典学习的SR行人ReID算法SLD2L[7],原因在于深度学习在特征表达学习方面明显优于传统的特征学习方法,而且SLD2L只是在一个预定义的特征空间进行跨分辨率的特征转换;相对而言,SING[17]和CSR‑GAN[18]相比SLD2L在性能上有了很大的提升,因为SING和CSR‑GAN同时考虑到行人的超分图像在内容上的信息重建和特征匹配。因此,忽略了图像在内容上的信息(像素级)恢复,只对单一粒度上的特征空间转换是不够的。此外,虽然SING和CSR‑GAN将SR和行人ReID级联优化,且CSR‑GAN联合多个GAN生成SR图像,但是它们忽略了SR图像在多粒度信息上的特征恢复,因此,本文所提多粒度信息融合生成网络明显优于上述算法。
3)本文算法明显优于现有分辨率不变特征表达的跨分辨率行人ReID算法JUDEA[6]、SDF[31]和RAIN[5],再一次验证基于GAN的SR重建思路有助于跨分辨率行人ReID性能的提升。
4)CAD和INTACT均考虑了将分辨率不变特征表达的学习任务与SR图像细节恢复任务相结合进行跨分辨率的行人ReID,但与它们相比,本文算法的重识别准确率也有明显的提升。原因是:①本文算法在GAN的生成网络中引入了自注意力机制,更加关于图像在鉴别性细节方面的重建,有利于提升低分辨率图像在有效内容上的细节恢复;②本文算法在GAN中增加了识别网络,该网络重点关注基于GAN重建后的图像与真实图像在特征表达上的一致性,通过最小化多粒度特征的损失函数,综合考虑重建后的行人图像与真实图像在不同粒度上特征表达的一致性。因此,在图像重建时关注图像鉴别性内容信息的恢复的同时,综合考虑重建后的图像在中高层纹理等特征和高层语义特征表达上的一致性,有助于提升跨分辨率行人ReID的性能。
但是,不同于SING和CSR‑GAN均采用联合生成对抗网络和行人ReID网络的损失函数进行参数优化,本文在进行网络训练时,参照文献[32],每次使用已经预训练好的自注意力生成对抗网络模型引导行人ReID网络的训练,以确保优化后的参数性能达到更优;不足之处是会增加有限的额外训练时间和GPU内存,这将是下一步研究工作的重点。

表2 本文方法与现有同类方法在不同数据集上的CMC rank‑1和rank‑5准确率 单位: %
3 结语
本文提出了一种基于多粒度信息融合生成网络的跨分辨率行人重识别方法,联合考虑行人的超分图像优化和匹配,将自注意力机制引入生成器以重点恢复图像的纹理结构信息,同时为了使SR重建后的信息有助于提升行人匹配性能,在生成器后增加一个识别网络,联合生成网络和识别网络,综合图像在多粒度上的信息重建,以满足识别的需要。最后,本文对所构建的多粒度信息生成网络和行人ReID网络采用交替训练的方式进行参数优化,直至模型收敛。实验结果表明本文方法在多个跨分辨率行人集上的重识别性能都优于对比方法。此外,在跨分辨率行人重识别研究中,对图像分辨率高低的判定也至关重要,仅借助图像尺寸和质量高低的定性定义是不够合理的,结合定量界定图像的分辨率,正确判定分辨率的高低并针对性提出解决方案,将是提升行人重识别算法应用与真实监控场景的关键问题之一。
[1] 魏文钰,杨文忠,马国祥,等. 基于深度学习的行人再识别技术研究综述[J]. 计算机应用, 2020, 40(9):2479-2492.(WEI W Y, YANG W Z, MA G X, et al. Survey of person re‑identification technology based on deep learning[J]. Journal of Computer Applications, 2020, 40(9):2479-2492.)
[2] CHANG X B, HOSPEDALES T M, XIANG T. Multi‑level factorisation net for person re‑identification[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2109-2118.
[3] CHEN D P, XU D, LI H S, et al. Group consistent similarity learning via deep CRF for person re‑identification[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8649-8658.
[4] FARENZENA M, BAZZANI L, PERINA A, et al. Person re‑identification by symmetry‑driven accumulation of local features[C]// Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2010:2360-2367.
[5] CHEN Y C, LI Y J, DU X F, et al. Learning resolution‑invariant deep representations for person re‑identification[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019:8215-8222.
[6] LI X, ZHENG W S, WANG X J, et al. Multi‑scale learning for low‑resolution person re‑identification[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway:IEEE, 2015: 3765‑3773.
[7] JING X Y, ZHU X K, WU F, et al. Super‑resolution person re‑identification with semi‑coupled low‑rank discriminant dictionary learning[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 695-704.
[8] 胡雪影,郭海儒,朱蓉. 基于混合深度卷积网络的图像超分辨率重建[J]. 计算机应用, 2020, 40(7): 2069-2076.(HU X Y, GUO H R, ZHU R. Image super‑resolution reconstruction based on hybrid deep convolutional network[J]. Journal of Computer Applications, 2020, 40(7):2069-2076.)
[9] WANG S L, ZHANG L, LIANG Y, et al. Semi‑coupled dictionary learning with applications to image super‑resolution and photo‑sketch synthesis[C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2012: 2216-2223.
[10] DONG C, LOY C C, HE K M, et al. Image super‑resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2):295-307.
[11] LEDIG C, THEIS L, HUSZÁR F, et al. Photo‑realistic single image super‑resolution using a generative adversarial network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 105-114.
[12] 欧阳宁,梁婷,林乐平. 基于自注意力网络的图像超分辨率重建[J]. 计算机应用, 2019, 39(8):2391-2395.(OUYANG N, LIANG T, LIN L P. Self‑attention network based image super‑resolution[J]. Journal of Computer Applications, 2019, 39(8):2391-2395.)
[13] 焦云清,王世新,周艺,等.基于神经网络的遥感影像超高分辨率目标识别[J].系统仿真学报,2007,19(14):3223-3225.(JIAO Y Q, WANG S X, ZHOU Y,et al. Super‑resolution target identification from remotely sensed imagery using Hopfield Neural Network[J]. Journal of System Simulation, 2007, 19(14):3223-3225.)
[14] 潘志庚,郑星,张明敏. 多分辨率模型生成中颜色和纹理属性的处理[J]. 系统仿真学报, 2002, 14(11):1506-1508, 1530.(PAN Z G, ZHENG X, ZHANG M M. Processing of color and texture attributes in multi‑resolution modeling[J]. Journal of System Simulation, 2002, 14(11):1506-1508, 1530.)
[15] 陈佛计,朱枫,吴清潇,等. 生成对抗网络及其在图像生成中的应用研究综述[J]. 计算机学报, 2021, 44(2):347-369.(CHEN F J, ZHU F, WU Q X, et al. A survey about image generation with generative adversarial nets[J]. Chinese Journal of Computers, 2021, 44(2):347-369.)
[16] HAN K, HUANG Y, SONG C F, et al. Adaptive super‑resolution for person re‑identification with low‑resolution images[J]. Pattern Recognition, 2021, 114: No.107682.
[17] JIAO J N, ZHENG W S, WU A C, et al. Deep low‑resolution person re‑identification[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018:6967-6974.
[18] WANG Z, YE M, YANG F, et al. Cascaded SR‑GAN for scale‑ adaptive low resolution person re‑identification[C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2018: 3891-3897.
[19] LI Y J, CHEN Y C, LIN Y Y,et al. Recover and identify: a generative dual model for cross‑resolution person re‑identification[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 8089-8098.
[20] CHENG Z Y, DONG Q, GONG S G, et al. Inter‑task association critic for cross‑resolution person re‑identification[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 2602-2612.
[21] 丁明航,邓然然,邵恒. 基于注意力生成对抗网络的图像超分辨率重建方法[J]. 计算机系统应用, 2020, 29(2):209-211.(DING M H, DENG R R, SHAO H. Image super‑resolution reconstruction method based on attentive generative adversarial network[J]. Computer Systems and Applications, 2020, 29(2):209-211.)
[22] 许一宁,何小海,张津,等. 基于多层次分辨率递进生成对抗网络的文本生成图像方法[J]. 计算机应用, 2020, 40(12):3612-3617.(XU Y N, HE X H, ZHANG J, et al. Text‑to‑image synthesis method based on multi‑level progressive resolution generative adversarial networks[J]. Journal of Computer Applications, 2020, 40(12):3612-3617.)
[23] 王雪松,晁杰,程玉虎. 基于自注意力生成对抗网络的图像超分辨率重建[J]. 控制与决策, 2021, 36(6):1324-1332.(WANG X S, CHAO J, CHENG Y H. Image super‑resolution reconstruction based on self‑attention GAN[J]. Control and Decision, 2021, 36(6):1324-1332.)
[24] 杨婉香,严严,陈思,等. 基于多尺度生成对抗网络的遮挡行人重识别方法[J]. 软件学报, 2020, 31(7):1943-1958.(YANG W X, YAN Y, CHEN S, et al. Multi‑scale generative adversarial network for person re‑identification under occlusion[J]. Journal of Software, 2020, 31(7):1943-1958.)
[25] DENG J, DONG W, SOCHER R, et al. ImageNet: a large‑scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009:248-255.
[26] GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANs[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 5769-5779.
[27] LI W, ZHU X T, GONG S G. Person re‑identification by deep joint learning of multi‑loss classification[C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2017: 2194-2200.
[28] YUAN Y, CHEN W Y, YANG Y, et al. In defense of the triplet loss again: learning robust person re‑identification with fast approximated triplet loss and label distillation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 1454-1463.
[29] ZHONG Z, ZHENG L, ZHENG Z D, et al. Camera style adaptation for person re‑identification[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5157-5166.
[30] GE Y X, LI Z W, ZHAO H Y, et al. FD‑GAN: pose‑guided feature distilling GAN for robust person re‑identification[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 1230-1241.
[31] WANG Z, HU R M, YU Y, et al. Scale‑adaptive low‑resolution person re‑identification via learning a discriminating surface[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2016: 2669-2675.
[32] SUN Y F, ZHENG L, YANG Y, et al. Beyond part models: person retrieval with refined part pooling (and a strong convolutional baseline)[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer, 2018: 501-518.
Cross‑resolution person re‑identification by generative adversarial network based on multi‑granularity features
GENG Yanbing, LIAN Yongjian*
(,,030051,)
Existing Super Resolution (SR) reconstruction methods based on Generative Adversarial Network (GAN) for cross‑resolution person Re‑IDentification (ReID) suffer from deficiencies in both texture structure content recovery and feature consistency maintenance of the reconstructed images. To solve these problems, a cross‑resolution pedestrian re‑identification method based on multi‑granularity information generation network was proposed. Firstly, a self‑attention mechanism was introduced into multiple layers of generator to focus on multi‑granularity stable regions with structural correlation, focusing on recovering the texture and structure information of the Low Resolution (LR) person image. At the same time, an identifier was added at the end of the generator to minimize the loss in different granularity features between the generated image and the real image during the training process, improving the feature consistency between the generated image and the real image in terms of features. Secondly, the self‑attention generator and identifier were jointed, then they were optimized alternately with the discriminator to improve the generated image on content and features. Finally, the improved GAN and person re‑identification network were combined to train the model parameters of the optimized network alternately until the model converged. Comparison Experimental results on several cross‑resolution person re‑identification datasets show that the proposed algorithm improves rank‑1 accuracy on Cumulative Match Characteristic(CMC) by 10 percentage points on average, and has better performance in enhancing both content consistency and feature expression consistency of SR images.
cross‑resolution; person Re‑IDentification (ReID); Generative Adversarial Network (GAN); self‑attention mechanism; multi‑granularity feature
This work is partially supported by Natural Science Foundation of Shanxi Province (201901D111154).
GENG Yanbing, born in 1980, Ph. D., lecturer. Her research interests include image processing, pattern recognition, artificial intelligence.
LIAN Yongjian, born in 1975, Ph. D., lecturer. His research interests include image processing, pattern recognition, artificial intelligence, virtual reality.
1001-9081(2022)11-3573-07
10.11772/j.issn.1001-9081.2021122124
2021⁃12⁃17;
2022⁃02⁃28;
2022⁃03⁃07。
山西省自然科学基金资助项目(201901D111154)。
TP391.41
A
耿艳兵(1980—),女,河南漯河人,讲师,博士,CCF会员,主要研究方向:图像处理、模式识别、人工智能;廉永健(1975—),男,山西平遥人,讲师,博士,主要研究方向:图像处理、模式识别、人工智能、虚拟现实。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
佳木斯大学学报(自然科学版)(2022年3期)2022-06-27
粉末冶金技术(2021年3期)2021-07-28
意林(2021年5期)2021-04-18
小型微型计算机系统(2020年10期)2020-10-21
扬子江(2019年1期)2019-03-08
新作文·高中版(2017年6期)2017-07-06
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
CHIP新电脑(2016年3期)2016-03-10
