
基于源语言句法增强解码的神经机器翻译方法
2022-11-30 07:30龚龙超郭军军余正涛
计算机应用 2022年11期
龚龙超,郭军军*,余正涛
基于源语言句法增强解码的神经机器翻译方法
龚龙超1,2,郭军军1,2*,余正涛1,2
(1.昆明理工大学 信息工程与自动化学院,昆明 650504; 2.云南省人工智能重点实验室(昆明理工大学),昆明 650504)(∗通信作者电子邮箱guojjgb@163.com)
当前性能最优的机器翻译模型之一Transformer基于标准的端到端结构,仅依赖于平行句对,默认模型能够自动学习语料中的知识;但这种建模方式缺乏显式的引导,不能有效挖掘深层语言知识,特别是在语料规模和质量受限的低资源环境下,句子解码缺乏先验约束,从而造成译文质量下降。为了缓解上述问题,提出了基于源语言句法增强解码的神经机器翻译(SSED)方法,显式地引入源语句句法信息指导解码。所提方法首先利用源语句句法信息构造句法感知的遮挡机制,引导编码自注意力生成一个额外的句法相关表征;然后将句法相关表征作为原句表征的补充,通过注意力机制融入解码,共同指导目标语言的生成,实现对模型的先验句法增强。在多个IWSLT及WMT标准机器翻译评测任务测试集上的实验结果显示,与Transformer基线模型相比,所提方法的BLEU值提高了0.84~3.41,达到了句法相关研究的最先进水平。句法信息与自注意力机制融合是有效的,利用源语言句法可指导神经机器翻译系统的解码过程,显著提高译文质量。
自然语言处理;神经机器翻译;句法信息;Transformer;增强解码;外部知识融入
0 引言
随着深度学习技术的发展,基于深度学习方法的神经机器翻译系统取得了显著的效果[1-3],成为机器翻译任务的新范式。神经机器翻译任务旨在将给定的源语言句子转换为目标语言句子,其核心思想是使用神经网络将源语言句子编码为一个稠密向量,然后从该向量解码出目标语言句子,通常依赖端到端的编码器‒解码器结构实现这种序列转换[4-5]。
先验的语言知识,特别是句法,是一种预先定义的语言规则。图1给出一个句法依赖关系的实例,词语之间通过特定的关系连接构建成一个句子。无论是理解语义(对应于编码)还是构建语言(对应于解码),这种蕴含于词语与词语之间的“主谓宾”等关系都作为一种重要依据而必不可少。但由于其本身的复杂性和语言的多样性,如何有效学习和理解更深层的蕴含关系和预定规则,仍是目前自然语言处理任务亟需和正努力解决的根本问题。
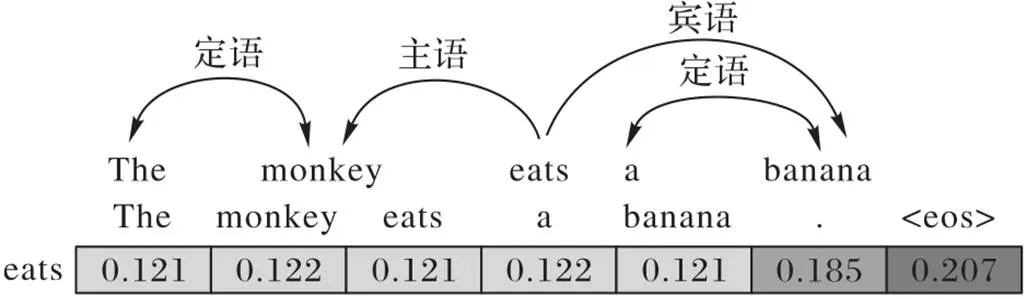
图1 句法依赖关系的实例
一方面,基于Transformer[3]的编码器‒解码器结构舍弃了传统的循环神经网络(Recurrent Neural Network, RNN)[2]层和卷积神经网络(Convolutional Neural Network, CNN)[6]层,仅利用注意力机制[5]并行地执行序列转换,大幅地提高了建模的效率,成为机器翻译任务的基线模型。然而,尽管自注意力机制通过并行的方式将输入语句中的每个词语都表示为包含其上下文信息的表征,但由于模型仅依赖于平行语料,而没有使用先验的语言知识,这种方式不可避免地会造成编码和解码过程中语句表征质量的下降。图1展示了Transformer在编码句子“The monkey eats a banana.”过程中为根节点词“eats”分配的注意力权重。直观上,在翻译词语“eats”时,其主语“monkey”和宾语“banana”应得到更多的关注,但从注意力权重的分配上看,Transformer模型显然没有区分出这种句法上的差别。相关研究也表明Transformer的确不能有效挖掘这种深层的语言信息,特别是在低资源环境下[8-9]。笔者认为,从注意力的角度来看,Transformer的软注意力方式适用于更广的范围,保证了模型的泛化能力;在此基础上,显式地添加句法以硬约束注意力则倾向于句子本身的差异性。将两者结合,则可在不损害模型泛化性的同时优化语句的表征。
另一方面,相关研究也表明在机器翻译系统中融入句法信息是有效的[10-14]。在模型浅层,Saunders等[10]将句法表征穿插在单词之间;Zhang等[11]将句法解析模型的表征与翻译模型的词嵌入表征相结合。在改变模型中间表征方面,Bugliarello等[12]根据词语之间的句法距离调节编码源语句时的注意力权重。在模型结构方面,Wu等[13]引入额外的编码器和解码器将句法关系融入机器翻译系统中,并利用目标端的句法信息;Currey等[14]提出适用于低资源的句法解析——机器翻译多任务模型,和适用于富资源的混合编码模型。这些方法虽然在基线模型的基础上提高了性能,但仅在编码器中利用源语言句法信息,或是在解码器中利用目标语言句法信息,并没有研究源语言句法信息对解码过程的影响。
针对以上问题,本文在Transformer模型的基础上:1)优化编码器中的自注意力机制,引入句法感知的遮挡机制,在原注意力的基础上生成一个额外的句法相关表征,与原注意力表征互补,明确使用源语言的句法信息;2)增强解码器,使用句法注意力将编码端生成的句法相关表征融入解码过程,指导目标语言的生成,实现源语言句法信息对机器翻译系统的增强。本文的主要工作包括:
1)提出一种基于源语言句法增强解码的神经机器翻译方法SSED(Source Syntax Enhancing Decoding),引入句法信息补充优化源语言表征,探索结合源语言句法信息作用于解码过程对翻译系统性能的影响;
2)将源语言句法信息作为优化模型的依据,而不是简单地作为额外特征输入模型,且适配于子词单元;
3)使用不同方法在解码端融合源语言句法信息,探索在不同融合方式下源语言句法信息对模型性能的影响;
4)在几个标准机器翻译数据集上的实验结果表明,本文方法在几乎不引入额外的训练参数和计算开销的情况下显著提高了基线模型的性能,并取得了句法相关工作的最好结果。
1 相关工作
在基于RNN模型的句法信息增强机器翻译方法中,Sennrich等[15]将源语言句子的语法依赖标签作为额外特征输入翻译系统中,以提高译文质量;Eriguchi等[16]将解码器与一个基于句法的语言模型[17]结合,通过共享句法解析与翻译任务将语言先验纳入机器翻译系统;Chen等[18]采用自底向上和自顶向下两个方向的树结构编码,有效利用源端句法信息;Chen等[19]基于句法距离构造一个句法感知的局部注意力机制,根据句法距离调节注意力权重,选择性地加强对句法相关词的注意。
基于Transformer的序列转换模型大幅提升了神经机器翻译的并行性和译文质量,一些研究也在Transformer模型的基础上对句法增强的方法进行了探索。Wu等[13]为将由RNN构建的依赖解析树融入Transformer结构中,使用一个具有三个编码器和两个解码器的大模型,且需要目标端的依赖关系;Zhang等[11]从更浅的词嵌入层着手,将句法解析器生成的隐状态与翻译模型的词嵌入向量拼接,以一种更隐式的方式集成源语言句法。与本文的方法相比,这种方法无法适配子词切分,会诱发词表过大和未登录词的问题。Currey等[14]基于数据增强技术提出两种分别适用于低资源和富资源的方法;Saunders等[10]致力于将目标语言的句法信息融入机器翻译系统,但将句法表征穿插入词语表征之间的方式带来长序列的问题,需要累积梯度才能进行有效的训练。最近,Bugliarelllo等[12]基于自注意力强大的表征能力将句法信息与自注意力网络相结合,通过词与词之间的句法距离重新分配注意力权重,实现对句法相关部分的强调。然而,这种仅依赖调整后表征的方式容易引入噪声。
不同于以往基于Transformer的工作,本文根据源语句的句法依赖关系,在编码自注意力的基础上利用遮蔽机制生成一个额外的句法相关表征作为原表征的补充,进而在解码过程融合源端的句法知识,共同指导目标语言的生成,以实现对解码过程的句法约束,提高机器译文质量。
2 SSED
为使用句法信息增强神经机器翻译,同时探索源语言句法对解码过程的影响,本文在Transformer模型的基础上提出基于句法增强的神经机器翻译模型SSED,在编码过程中提取和转换源端句法知识,并将其融入解码过程。
本章介绍了SSED模型的整体结构、处理流程和框架中主要模块的设计和细节,包括获取并向量化源语句句法关系以将其适配至编码器,句法感知在多头注意力中的实现,以及如何将句法增强适配到解码器的不同层。
2.1 模型整体结构
图2中展示了SSED模型的结构,与Transformer模型相比,主要改动包括:1)编码器中,优化自注意力,使其利用源语句的句法依赖关系生成句法相关的表征;2)解码器中,添加句法‒解码交互注意力和整合机制用于融合源语言句法,实现句法增强。

图2 SSED模型总体结构
2.1.1句法感知的编码器


由此,除原本的注意力表征之外,句法感知的自注意力还额外生成一个句法相关的注意力表征,式(1)变为:


值得注意的是,由于本文并没有额外初始化一个前馈网络,而是仅使用原本的前馈网络,因此,相较于传统的Transformer编码器,句法感知的编码器并没有引入额外的训练参数。
2.1.2句法增强的解码器
社会治理在乡镇土地管理中的运用(李昊 ) ..................................................................................................2-31



2.2 句法依赖关系的向量化
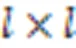
为缓解词表过大和词汇稀疏问题,本文将句法感知适配到子词单元,定义由同一原词语切分而成的子词之间的关系为句法相关,并作为整体与句子中的其他词语相互关联,以适应子词切分技术。
2.3 句法感知与多头注意力的适配


具体到本文,源语句的句法关系被作为调整编码自注意力进而生成句法相关表征的依据,而不是简单地作为语言特征输入模型。这种对注意力权重的调整是建立在多头基础上的,保留了多头表征的多样性,使得所生成的句法相关表征蕴含来自不同表示子空间的信息,避免了由于仅保留句法相关部分而可能带来的局部偏差。从局部建模的角度考虑,基于多头的方式完善了可能忽略全局信息的句法感知建模方式。因此,作为补充信息,由局部建模得到的句法相关表征没有引入额外的噪声,相反,它在引入句法信息的同时也丰富了源语句表征的多样性。3.3.4节中的实验结果也表明,句法相关表征为模型解码提供了有效信息。
2.4 句法感知与多层注意力的适配
最近的研究表明,Transformer不同的层倾向于捕捉不同的特征。Anastasopoulos等[20]的研究表明,相较于低层,较高层更具有代表性;Peters等[21]以及Raganato等[22]指出,低层倾向于学习更多的句法知识,而较高的层则倾向于编码更多的语义。基于此,本文在编码器输出层中生成句法相关表征,并研究了解码器哪些层从源语言句法中受益最大。
3 实验与结果分析
3.1 实验设置
为测试本文SSED模型的性能,在通用的NC11(News Commentary v11)英德、德英和IWSLT14(International Conference on Spoken Language Translation 2014)德英,以及标准低资源WMT18(Conference on Machine Translation 2018)英土、IWSLT15(International Conference on Spoken Language Translation 2015)英越翻译任务上进行实验。为便于与句法相关的工作进行比较,NC11与WMT18英土两个任务的数据设置与Bugliarello等[12]相同;对IWSLT14德英任务,跟Edunov等[23]的设置相同;在IWSLT15英越任务中使用tst2012作为验证集,tst2013作为测试集。表1统计了实验使用的语料规模。语料中的句子都进行了规范化(normalize)、符号化(tokenize)以及BPE(Byte Pair Encoding)[24]子词切分等处理;使用Stanford CoreNLP[25]工具对英语和德语端句子进行句法解析,得到对应的句法关系。
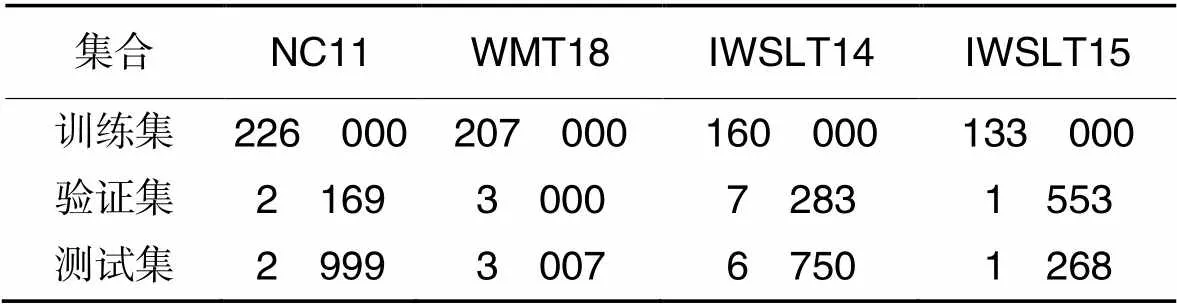
表1 实验使用的语料规模统计

在译文质量评价方面,本文使用开源脚本multi‑bleu.Perl计算机器译文的BLEU(BiLingual Evaluation Understudy)值,对所有机器译文均采用大小写敏感的BLEU值。为保证结果的有效性,平均最后5个检查点作为评估模型,波束搜索大小设为5。
3.2 实验结果
首先,与已有的句法相关工作进行比较,包括:Currey等[14]提出的共享机器翻译和句法解析任务的Multi‑Task方法,以及混合编码的Mixed Enc.模型;Bugliarello等[12]提出的句法增强的最好方法PASCAL(Parent‑Scaled Self‑Attention);参数优化的Multi‑Task;将句法信息以依赖标签的形式加入到Transformer编码器词嵌入矩阵中的S&H(Sennrich and Haddow)[15];被迁移到机器翻译任务中,将自注意力与句法解析相结合的LISA(Linguistically‑Informed Self‑Attention)[27]。
其次,在通用的IWSLT(International Conference on Spoken Language Translation)任务上与其他机器翻译方法进行比较,包含:基于传统RNN和CNN的ELMo(Embeddings from Language Models)[28]、CVT(Cross‑View Training)[28],SAWR(Syntax‑Aware Word Representations)[11]和Dynamic Conv[29];改进Transformer模型结构的Tied‑Transform[30]和Macaron[31];融合预训练模型的C‑MLM(Conditional‑Masked Language Modeling)[32]和BERT‑fused(Bidirectional Encoder Representations from Transformers‑fused)[33]。
实验结果如表2所示,可以看到:对于句法增强的神经机器翻译方法,在词嵌入表征中加入依赖标签(+S&H)以及简单地共享模型的多任务方法(+Multi‑Task)相较于基线模型并没有明显的提升;相比之下,改变注意力机制,在其中融入句法信息以辅助机器翻译的方法(+LISA)有了明显的提升,说明了句法信息对提高译文质量的有效性,以及将其与注意力网络结合的可行性。
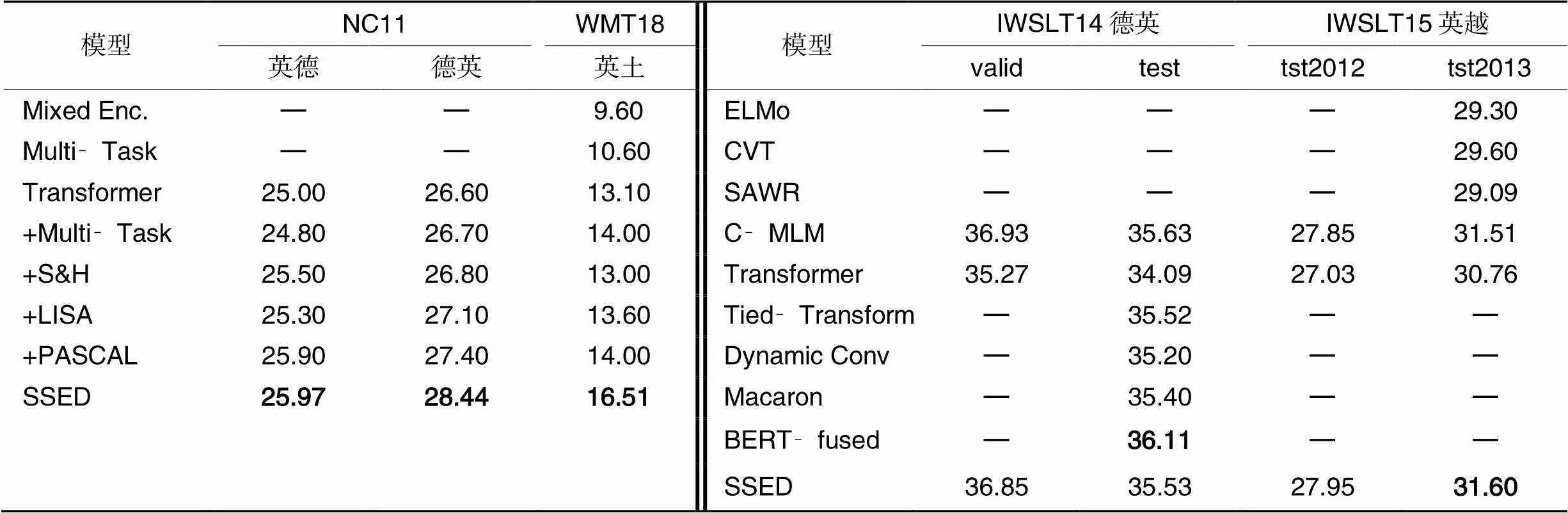
表2 不同机器翻译方法在各数据集上的BLEU值
进一步地,根据源语句句法信息对编码自注意力进行调整,而不是简单地将其作为额外的特征输入模型(+PASCAL),取得了更好的优化效果,证明了这种调整优化方式的效力。与此不同,本文在此方法的基础上进一步改进,在不改变原注意力表征的情况下使用源句句法信息引导自注意力生成一个额外的句法相关表征,将其作为原表征的补充信息,有效缓解调整自注意力过程中可能会引入的噪声偏差,在保证注意力表征有效性的同时,也增加了其丰富性。此外,本文采用更直接的解码端融入方式,将句法信息直接作用于目标语言的生成过程。实验结果表明,本文的方法取得了最好的效果,BLEU值在基线模型的基础上取得了+0.97到+3.41的提升,且始终优于当前句法相关的最先进方法PASCAL。这验证了SSED模型的有效性,在解码过程中使用源语言句法信息指导目标语言的生成能够大幅提高机器译文质量。
另一方面,在通用的IWSLT任务上,本文方法同样表现优异,能取得与其他精心设计的机器翻译模型相当或更好的BLEU值。其中,Tied‑Transform通过共享编解码器实现了一个轻量型的模型,但需要更强的调参技巧以及更长的训练时间来使模型收敛。相比之下,本文方法SSED在不需要额外训练时间的情况下达到了与Tied‑Transform相当的性能。Macaron通过在每层的注意力网络之前增加前馈网络使Transformer模型更稠密,但模型参数量也随之大幅增加,而本文所提方法仅在单层操作,在仅引入少量参数的情况下表现出更好的性能。
此外,借助预训练语言模型的C‑MLM和BERT‑fused方法将预训练语言模型BERT的表征融入翻译系统,使模型包含更大规模的训练参数,也需要更长的训练时间,而基于轻量模型的SSED在IWSLT15英越任务上取得了高于C‑MLM的BLEU得分,表现出强大的翻译性能。
3.3 消融实验
为探究模型不同组件和方法的具体效用,本文进行了一系列的消融实验。首先,在解码端通过不同的方式融合句法信息;之后,使用不同的方法整合编码‒解码注意力和句法‒解码注意力表征;然后,研究解码器中哪些层从源语言句法中受益最大;最后,具体验证句法相关表征的有效性。
3.3.1不同融合方式对模型性能的影响
本文基于注意力机制在解码端自适应地提取原语句表征与句法相关表征中的信息。在解码端使用注意力机制融入额外信息辅助神经机器翻译的方法通常可分为两类:串行方式和并行方式。串行方式即依次执行编码注意力或额外信息注意力,后一注意力的查询向量为前一注意力的输出[34-36];并行方式即分别执行编码注意力和额外信息注意力,两种注意力的查询向量相同,之后再对输出结果进行整合[37-40]。
图3在本文的基础上对串行方式进行了简单示例。本文进行了不同的实验以探究将源语句句法信息融入解码过程的最有效方法,实验结果展示在表3中。其中:“Enc+Syn”和“Syn+Enc”分别表示在解码自注意力后依次执行编码、句法注意力及句法、编码注意力的串行方式;“Enc//Syn”表示并行执行编码、句法注意力。实验中将并行输出的两个表征进行拼接,之后经线性层整合为一个整体。所有方式均在所有解码层中执行。
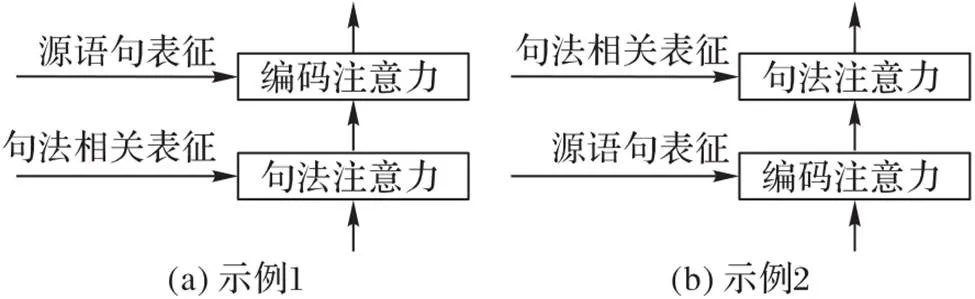
图3 串行融合的简单示例

表3 IWSLT15英越任务上不同融合方式的BLEU值
从表3可以看出,串行执行注意力的方式并不能有效提升模型性能,反而会造成译文质量的大幅下降。与之前串行处理的工作相比,本文认为造成这种结果的原因是:当额外特征提供给模型的是与编码输出的源语句表征差别较大的不同类型信息,且拥有全局属性时,递进的方式能够为模型提供更好的规范性信息,进而有效提升模型性能,相反则不能。本文方法是用句法感知的方式在原编码输出表征的基础上进行局部建模,得到额外的句法相关表征,与原表征有较高的相似性,可以作为原语句表征的补充信息,而不适合单独作为全局信息提供给解码器。并行执行注意力的实验结果验证了这一猜想。将所生成的句法相关表征以辅助信息的形式整合到模型中,而不是以包含的形式,这种融合方式有效强化了原表征的特征多样性,进而提升模型性能。
在之后的实验中,本文在解码端采用并行执行的方式,并进一步实验了不同的整合方式对模型性能的影响。
3.3.2不同整合方式对模型性能的影响
1)平均池化(Average):将两个注意力输出表征经平均池化层求平均值,结果送入下游模块。
2)门控单元(Gate):将两个注意力表征进行拼接,之后经门控单元生成一个门控变量,控制两个注意力表征在整合过程中所占权重。可用公式表示为:

3)高速网络(Highway):拼接后的注意力表征分别经过两个不同的线性变化和非线性激活,生成一个控制变量和一个输入变量,之后借助控制变量控制拼接变量和输入变量的权重,生成最终表示。

4)线性变换(Linear):拼接后的注意力表征仅经过线性变化层生成下游模块的输入变量。
根据表4可以看到,使用平均池化和高速网络整合注意力表征时,不管是在验证集还是测试集,不仅在基线模型上没有所提升,反而损害了模型性能。而门控单元和线性变换在测试集上表现出同等的效力,都有效改善了译文质量,但其中门控单元在验证集上表现不佳。有关这点,本文在后续实验中进一步探索了门控单元的有效性。
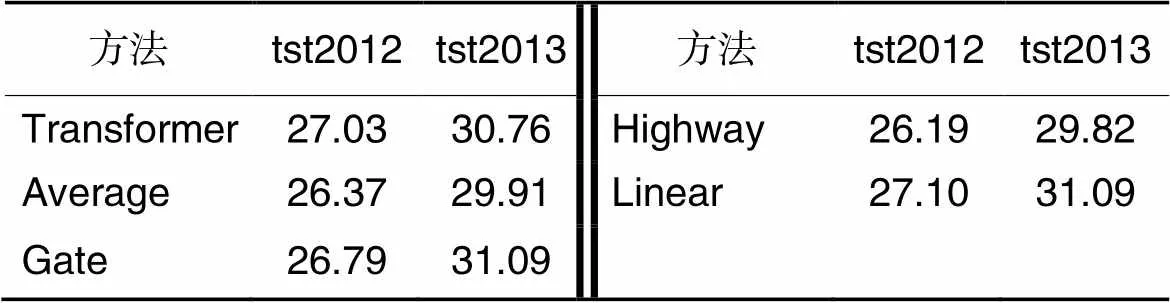
表4 IWSLT15英越任务上不同整合方式的BLEU值
本文将表4的结果归因于:简单地对两个表征求均值并不能有效区分并整合有效信息,反而会损害多个表征中所包含的特有信息,使其失去多样性,甚至会在原注意力表征中引入噪声,造成质量下降,导致模型表现不佳。同样地,高速网络并没有有效识别出拼接后的表征中哪些部分需要经过激活,哪些部分需要保持不变。相反,门控单元和线性层则有效筛选出了有效信息,实现了句法增强表征的有效融合,从而优化了模型表征,进一步实现对译文质量的提升。在接下来的实验中,本文使用线性层作为整合方式,并进一步验证门控单元的效力。
3.3.3不同解码层引入句法信息对模型性能的影响
针对已有研究指出的不同层捕捉不同特征的现象,一个自然的问题是:是否需要在所有解码层中增强句法?为解答该问题,本文在不同层的基础上进行了一系列实验,结果如表5所示。其中:“Base”表示Transformer基线模型;“Gate5”表示使用门控单元作为整合机制,在解码器第5层中利用注意力机制引入句法信息。
表5中结果显示:1)所有方法的BLEU值相较于Transformer基线模型都有不同程度的提升,其中在第5层中融合句法信息效果最好,BLEU值在基线模型的基础上取得了+0.84的提升。这验证了基于句法增强的神经机器翻译模型的有效性。2)相较于仅在单一层中融合句法信息增强解码,在多个层中融合并没有明显的提升;且随着自底向上增加融合层数,机器译文的评分整体上并没有明显的变化,反而会有所下降。这表明,多层融合并不能在模型性能方面带来增益,相反,增加过多的线性层会引入更多的训练参数,造成模型结构的冗余,不利于充分挖掘语料中蕴含的信息。此外,多层融合一定程度上也更容易造成信息的重复和冗余。结合Raganato等[20]有关低层偏向注意语义,高层偏向注意上下文信息的发现,包含局部信息的句法相关表征并不适宜于被作为补充信息提供给所有层,而是适合作为上下文信息与源语言表征形成互补,在较高层中发挥更大的效益,完善源语言表征的信息完整性。3)较高的层更能从源语言句法增强中受益。相较于在第1~4层中融合句法信息,在第5、6层中融合句法信息使模型性能有很大幅度的提升。这一定程度上与之前有关不同层的研究相符合,即在较高层中额外引入的句法相关表征与原本包含更多语义的表征互为补充,使整合后的表征含有更为全面的信息,且较高层生成的表征更具代表性。此外,拥有较好效果的较高层在堆叠融合的情况下(表5中的4-6、5-6)性能依然不佳,说明文中基于句法增强的方法的确不适用于多层融合。4)使用线性层整合的方式更适用于模型。尽管使用门控单元作为整合方式在第5层中融合句法知识取得了很好的效果,但仍差于基于线性变换的方法。
基于以上实验结果,本文在主实验中基于编码器输出层生成句法相关表征,并仅在解码器第5层中使用线性层作为整合方式融合句法信息。
3.3.4不同整合方式对模型性能的影响
为排除在解码器中增加线性层所带来的干扰,证明模型性能的提升仅来自句法相关表征,使用原始的编码器输出替换句法相关表征,将其作为句法‒解码注意力的输出与编码‒解码注意力输出进行整合,结果如表5的“Enc5”。Enc5的结果表明,虽然线性层提升了基线模型的性能,但与基于句法相关表征的结果相比仍有很大差距,说明SSED模型的性能改善得益于源端句法信息,验证了本文方法的有效性。另一方面,结合3.3.2节中的结果,从高速网络到门控单元,再到线性层,随着模型复杂度的递减,模型性能呈现递增的趋势,简单的线性层就能明显提升模型性能,本文认为这与Transformer模型结构的稀疏稠密度有关,具体原因将在未来工作中进一步研究。

表5 IWSLT15英越任务上不同解码层引入句法信息的BLEU值
3.4 实例分析
为了定性揭示基于句法增强的神经机器翻译方法的有效性,表6给出了在IWSLT14德英任务上,Transformer‑base模型生成的原机器译文以及利用本文方法增强句法后生成的译文示例。与参考译文对比发现,句法增强的方法能够有效借助源语言句法信息对原模型解码时的句法错误进行校正。在第一个例子中,解码“one”时应更多地注意其指代主语“my supermarket”,而不是“this is my supermarket”,加入句法信息使模型在解码该位置时有倾向地指向“supermarket”,可有效避免指代主语不明确的问题。同样,在第二个例子中模型有效纠正了错误的谓语,保证了翻译过程中语意表达的准确性。

表6 原机器译文与句法增强的机器译文的对比示例
4 结语
为缓解低资源场景下神经机器翻译模型缺乏先验约束、句法信息表征不足等问题,同时探索在解码过程中有效利用源语言句法信息指导目标语言生成,本文提出了基于Transformer的源语言句法信息增强解码的神经机器翻译模型。该模型通过改进Transformer结构,实现了句法感知的编码和句法增强的解码。使用并行注意力的方式分别从源语句表征和局部建模的源语句句法相关表征中提取信息,能够有效提升模型表征能力,融合句法信息指导解码端目标语言的生成。在几个通用机器翻译任务上的实验结果表明,所提方法显著提高了机器译文质量,达到了句法相关研究的最先进水平,证明了使用源语言句法信息指导解码对增强机器翻译模型性能的有效性。
[1] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 3104-3112
[2] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[EB/OL]. (2016-05-19)[2021-08-11].https://arxiv.org/pdf/1409.0473v7.pdf.
[3] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:6000-6010.
[4] 李亚超,熊德意,张民. 神经机器翻译综述[J]. 计算机学报, 2018, 41(12): 2734-2755.(LI Y C, XIONG D Y, ZHANG M. A survey of neural machine translation[J]. Chinese Journal of Computers, 2018, 41(12): 2734-2755.)
[5] 刘洋. 神经机器翻译前沿进展[J]. 计算机研究与发展, 2017, 54(6): 1144.(LIU Y. Recent advances in neural machine translation[J]. Journal of Computer Research and Development, 2017, 54(6): 1144.)
[6] GEHRING J, AULI M, GRANGIER D, et al. Convolutional sequence to sequence learning[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1243-1252.
[7] LUONG M T, PHAM H, MANNIN C D. Effective approaches to attention‑based neural machine translation[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015:1412-1421.
[8] ERIGUCHI A, HASHIMOTO K, TSURUOKA Y. Tree‑to‑sequence attentional neural machine translation[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016: 823-833.
[9] NGUYAN X P, JOTY S, HOI S C H, et al. Tree‑structured attention with hierarchical accumulation[EB/OL]. (2020-02-19)[2021-08-11].https://arxiv.org/pdf/2002.08046.pdf.
[10] SAUNDERS D, STAHLBERG F, DE GISPERT A, et al. Multi‑representation ensembles and delayed SGD updates improve syntax based NMT[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 319-325.
[11] ZHANG M S, LI Z H, FU G H, et al. Syntax‑enhanced neural machine translation with syntax‑aware word representations[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 1151-1161.
[12] BUGLIARELLO E, OKAZAKI N. Enhancing machine translation with dependency‑aware self‑attention[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 1618-1627.
[13] WU S Z, ZHANG D D, ZHANG Z R, et al. Dependency‑to‑ dependency neural machine translation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing,2018, 26(11): 2132-2141.
[14] CURREY A, HEAFIELD K. Incorporating source syntax into transformer‑based neural machine translation[C]// Proceedings of the 4th Conference on Machine Translation (Volume 1: Research Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 24-33.
[15] SENNRICH R, HADDOW B. Linguistic input features improve neural machine translation[C]// Proceedings of the 1st Conference on Machine Translation: Volume 1, Research Papers. Stroudsburg, PA: Association for Computational Linguistics , 2016: 83-91.
[16] ERIGUCHI A, TSURUOKA Y, CHO K. Learning to parse and translate improves neural machine translation[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 72-78.
[17] DYER C, KUNCORO A, BALLESTEROS M, et al. Recurrent neural network grammars[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2016: 199-209.
[18] CHEN H D, HUANG S J, CHIANG D, et al. Improved neural machine translation with a syntax‑aware encoder and decoder[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 1936-1945.
[19] CHEN K H, WANG R, UTIYAMA M, et al. Syntax‑directed attention for neural machine translation[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 4792-4799.
[20] ANASTASOPOULOS A, CHIANG D. Tied multitask learning for neural speech translation[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 82-91.
[21] PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 2227-2237.
[22] RAGANATO A, TIEDEMANN J. An analysis of encoder representations in transformer‑based machine translation[C]// Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Stroudsburg, PA: Association for Computational Linguistics, 2018: 287-297.
[23] EDUNOV S, OTT M, AULI M, et al. Classical structured prediction losses for sequence to sequence learning[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 355-364.
[24] SENNRICH R, HADDOW B, BIRCH A. Neural machine translation of rare words with subword units[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2015: 1715-1725.
[25] MANNING C D, SURDEANU M,BAUER J, et al. The Stanford CoreNLP natural language processing toolkit[C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Stroudsburg, PA: Association for Computational Linguistics, 2014:55-60.
[26] OTT M, EDUNOV S, BAEVSKI A, et al. FAIRSEQ: a fast, extensible toolkit for sequence modeling[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Demonstrations). Stroudsburg, PA: Association for Computational Linguistics, 2019: 48-53.
[27] STRUBELL E, VERGA P, ANDOR D, et al. Linguistically‑ informed self‑attention for semantic role labeling[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 5027-5038.
[28] CLARK K, LUONG M T, MANNING C D, et al. Semi‑supervised sequence modeling with cross‑view training[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 1914-1925.
[29] WU F, FAN A, BAEVSKI A, et al. Pay less attention with lightweight and dynamic convolutions[EB/OL]. (2019-02-22)[2021-08-11].https://arxiv.org/pdf/1901.10430.pdf.
[30] XIA Y C, HE T Y, TAN X, et al. Tied Transformers: neural machine translation with shared encoder and decoder[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019: 5466-5473.
[31] LU Y P, LI Z H, HE D, et al. Understanding and improving Transformer from a multi‑particle dynamic system point of view[EB/OL]. (2019-06-06)[2021-08-11].https://arxiv.org/pdf/1906.02762.pdf.
[32] CHEN Y C, GAN Z, CHENG Y, et al. Distilling knowledge learned in BERT for text generation[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 7893-7905.
[33] ZHU J H, XIA Y C, WU L J, et al. Incorporating BERT into neural machine translation[EB/OL]. (2020-02-17)[2021-08-18].https://arxiv.org/pdf/2002.06823.pdf.
[34] TU Z P, LIU Y, SHI S M, et al. Learning to remember translation history with a continuous cache[J]. Transactions of the Association for Computational Linguistics, 2018, 6: 407-420.
[35] ZHANG J C, LUAN H B, SUN M S, et al. Improving the Transformer translation model with document‑level context[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 533-542.
[36] MSRUF S, MARTINS A F T, HAFFARI G. Selective attention for context‑aware neural machine translation[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 3092-3102.
[37] CAO Q, XIONG D Y. Encoding gated translation memory into neural machine translation[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 3042-3047.
[38] KUANG S H , XIONG D Y. Fusing recency into neural machine translation with an inter‑sentence gate model[C]// Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2018: 607-617.
[39] STOJANOVSKI D, FRASER A. Coreference and coherence in neural machine translation: a study using oracle experiments[C]// Proceedings of the 3rd Conference on Machine Translation: Research Papers. Stroudsburg, PA: Association for Computational Linguistics, 2018: 49-60.
[40] VOITA E, SERDYUKOV P, SENNRICH R, et al. Context‑aware neural machine translation learns anaphora resolution[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 1264-1274.
Neural machine translation method based on source language syntax enhanced decoding
GONG Longchao1,2, GUO Junjun1,2*, YU Zhengtao1,2
(1,,650504,;2(),650504,)
Transformer, one of the best existing machine translation models, is based on the standard end‑to‑end structure and only relies on pairs of parallel sentences, which is believed to be able to learn knowledge in the corpus automatically. However, this modeling method lacks explicit guidance and cannot effectively mine deep language knowledge, especially in the low‑resource environment with limited corpus size and quality, where the sentence encoding has no prior knowledge constraints, leading to the decline of translation quality. In order to alleviate the issues above, a neural machine translation model based on source language syntax enhanced decoding was proposed to explicitly use the source language syntax to guide the encoding, namely SSED (Source language Syntax Enhanced Decoding). A syntax‑aware mask mechanism based on the syntactic information of the source sentence was constructed at first, and an additional syntax‑dependent representation was generated by guiding the encoding self‑attention. Then the syntax‑dependent representation was used as a supplement to the representation of the original sentence and the decoding process was integrated by attention mechanism, which jointly guided the generation of the target language, realizing the enhancement of the prior syntax. Experimental results on several standard IWSLT (International Conference on Spoken Language Translation) and WMT (Conference on Machine Translation) machine translation evaluation task test sets show that compared with the baseline model Transformer, the proposed method obtains a BLEU score improvement of 0.84 to 3.41 respectively, achieving the state‑of‑the‑art results of the syntactic related research. The fusion of syntactic information and self‑attention mechanism is effective, the use of source language syntax can guide the decoding process of the neural machine translation system and significantly improve the quality of translation.
Natural Language Processing (NLP); neural machine translation; syntactic information; Transformer; enhanced decoding; external knowledge incorporation
This work is partially supported by National Natural Science Foundation of China (61866020, 61732005), Science and Technology Innovation 2030 — "New Generation of Artificial Intelligence" Major Project (2020AAA0107904), Yunnan Applied Basic Research Program (2019FB082).
GONG Longchao, born in 1997, M. S. candidate. His research interests include natural language processing, machine translation.
GUO Junjun, born in 1987, Ph. D., associate professor. His research interests include machine learning, natural language processing, machine translation.
YU Zhengtao, born in 1970, Ph. D., professor. His research interests include machine learning, natural language processing, machine translation, information retrieval.
1001-9081(2022)11-3386-09
10.11772/j.issn.1001-9081.2021111963
2021⁃11⁃19;
2021⁃11⁃25;
2021⁃12⁃06。
国家自然科学基金资助项目(61866020, 61732005);科技创新2030—“新一代人工智能”重大项目(2020AAA0107904);云南省应用基础研究计划项目(2019FB082)。
TP391.1
A
龚龙超(1997—),男,河南南阳人,硕士研究生,CCF会员,主要研究方向:自然语言处理、机器翻译;郭军军(1987—),男,山西吕梁人,副教授,博士,CCF会员,主要研究方向:机器学习、自然语言处理、机器翻译;余正涛(1970—),男,云南曲靖人,教授,博士,CCF高级会员,主要研究方向:机器学习、自然语言处理、机器翻译、信息检索。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
大连民族大学学报(2021年2期)2021-07-16
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
考试周刊(2015年36期)2015-09-10
