
基于TCN-Attention模型的多变量黄河径流量预测
2022-11-28 15:09高梓勋单春意
人民黄河 2022年11期
王 军,高梓勋,单春意
(1.郑州大学 管理工程学院,河南 郑州 450001;2.郑州航空工业管理学院 大数据科学研究院,河南 郑州 450046)
河流径流量预测一直是水文研究领域的基础工作之一[1],精准的径流量预测对及时有效的水资源管理、灌溉管理决策、洪水风险预警以及水库调度等有极为重要的作用[2]。然而,河流径流量受气候变化、人类活动等的影响[3],呈现出强烈的非线性、随机性特征,因此精准的径流量预测成为水文学者们研究的热点[4]。长期以来,各学者在河流径流量预测方面使用的方法大体上分为两类:一是基于概念性或物理性水文模型的径流量预测方法,此类方法通过过程概念化或物理定律方程组来描述径流形成过程[5];二是基于数据驱动模型的径流量预测方法,此类方法不依赖水文物理机制,把径流量和其他相关要素的历史观测数据输入模型,通过建立变量间的输入与输出关系对径流量进行预测[6]。
近年来,随着水文观测技术和机器学习算法的高速发展,智能算法在水文领域的应用日益受到重视,数据驱动模型受到学者们的广泛关注,以BP神经网络和长短时记忆网络(LSTM)为代表的机器学习算法越来越多地应用到河流径流量预测中。王佳等[7]结合集合经验模态分解(EEMD)与BP神经网络,实现了对黄河上游龙羊峡水库入库月径流量的精准预测。李代华[8]基于主成分分析(PCA)-斑点鬣狗优化(SHO)-BP神经网络对盘龙河月径流量和年径流量进行预测,证实了PCA-SHO-BP组合模型对月径流量和年径流量的预测性能均优于SHO-SVM、PCA-SVM等未优化的模型。范宏翔等[9]利用LSTM构建鄱阳湖流域气象-径流模型,探究最佳的模拟窗口长度,证实了该模型可以有效模拟鄱阳湖流域的径流过程。蔡文静等[10]通过时频分析和预报因子筛选对LSTM模型进行优化,分别将经验模态分解(EMD)、变模态分解(VMD)、离散小波变换与LSTM模型组合来预测玛纳斯河的径流量,结果表明VMD-LSTM模型对径流量的总体变化趋势和极值均具有良好的预测效果。包苑村等[11]在VMD-LSTM模型的基础上引入卷积神经网络(CNN),构建VMD-CNN-LSTM模型对渭河流域张家山水文站、魏家堡水文站的月径流量进行预测,证实了该组合模型具有较高的预测精度。
各学者虽然对BP神经网络和LSTM模型进行了一定程度的优化,但由于影响河流径流量的因素众多,不确定性很大,BP神经网络在预测精度和适应性上还有提升空间,LSTM模型存在梯度问题和训练时间长的问题。时间卷积神经网络(TCN)的因果卷积、膨胀卷积特性可以很好地解决上述问题,其在数值天气预报[12]、风电功率预测[13]、太阳辐射预测[14]方面的精度和泛化性能已经超过了LSTM模型。本文以黄河花园口水文站为研究对象,基于花园口水文站历年降水量、流量、含沙量的观测数据,采用TCN模型预测河流径流量(以日均流量表示),通过引入Attention机制为TCN模型中的关键特征赋予更大权重,建立多变量TCN-Attention黄河花园口水文站日均流量预测模型。通过实验对LSTM模型和TCN模型的预测结果进行比较,得出TCN-Attention模型预测日均流量的精度和泛化性能。
1 黄河花园口水文站概况与数据预处理
1.1 黄河花园口水文站概况
黄河花园口水文站是黄河干流重要的控制站和黄河下游防汛的标准站,控制流域面积为73万km2,占黄河流域总面积的92%[15]。该水文站监测流量长期以来是下游防汛工作的重要参照指标,但该水文站所处河道冲淤剧烈,径流量变化复杂,对径流量的精准预测十分困难。选取黄河花园口水文站2008年1月1日—2012年12月31日共1 827 d的实测日均流量、日降水量、日均含沙量作为研究数据[16],数据源自国家地球系统科学数据中心,研究期内各变量的变化情况见图1。

图1 花园口水文站日均流量、日降水量、日均含沙量变化情况
1.2 数据预处理
为使原始数据满足多维模型训练的要求,需要对各变量的原始数据进行预处理,具体步骤如下:
(1)选取输入变量和输出变量。从图1可以看出,花园口水文站日均流量、日降水量、日均含沙量有相似的变化趋势,把流量、降水量、含沙量作为模型的输入变量,把日均流量作为模型最终预测的输出变量。
(2)数据归一化。为使大小差异巨大的原始时序数据输入模型后加快模型训练收敛速度、提高预测精度,将以上3个变量的原始时序数据统一调整至[0,1]区间[17],归一化公式为

式中:Xt为t时刻的原始观测数据;Xnorm为归一化后的数据;Xmax、Xmin分别为3个变量原始数据的最大值、最小值。
(3)数据集划分。为使模型得到更充分的迭代训练,将3个变量数据中90%的数据作为训练集、10%的数据作为验证集。
(4)数据反归一化。在模型训练完毕后进行模型性能评价时,需要将归一化处理的数据反归一化,以更加准确地评估模型输出的预测值与真实值之间的差距,反归一化公式为

2 研究方法
2.1 TCN模型
传统一维CNN应用于时间序列预测时,用卷积层提取时序信息形成记忆,卷积层感受野决定了记忆序列的长短。CNN虽拥有并行高效计算的优势,但受限于信息易泄露、感受野扩张难度大,预测精度仍较低。TCN是一种新型的可以用来解决时间序列预测问题的模型,由因果卷积、膨胀卷积、残差连接等模块组成,具有更稳定的梯度、更高的计算效率、更长的记忆序列等优势,不会引入未来时刻的数据信息,避免了数据泄露。
2.1.1 因果卷积
TCN作为一个主要用于时间序列预测的网络模型,在该模型中引入因果卷积可以使模型在预测t时刻的目标数据yt时仅对t时刻以及t时刻之前的输入数据(xt,xt-1,xt-2,…)进行卷积计算并提取时序特征,这就使得TCN对yt的预测只与t时刻及t时刻之前的信息有关,避免了传统CNN卷积计算会提取到未来数据信息的缺点。此外TCN还使用步长为1、零填充大小为kz-1(kz为卷积核尺寸)的一维全卷积网络,确保了模型输入大小与输出大小相等。
2.1.2 膨胀卷积
引入膨胀卷积可以在保证TCN模型输入大小与输出大小相等以及引入因果卷积的前提下,使TCN模型的感受野指数倍扩大,从而让TCN以更长的记忆序列进行预测。其原理是按照膨胀系数d的大小对普通CNN的感受野插入空白信息,d的数值通常是形如(1,2,4,8,…)的指数数列。膨胀卷积计算公式为

式中:X为输入序列;s-d∗i为对时序数据信息的索引;f(i)为卷积核的第i个元素。
2.1.3 残差连接
当TCN引入因果卷积和膨胀卷积扩大感受野时,无法避免地会增加网络深度,需要使用残差连接来解决梯度衰退甚至梯度弥散问题[18]。残差连接是在一般的CNN连接结构中增加一条快捷通道,将模型的输入序列X添加至卷积计算的输出序列F(X)中。区别于一般的ResNet模型把X直接添加到残差模块的输出序列中,TCN模型使用1×1卷积处理X,确保F(X)与X有相同的宽度。
2.2 Attention机制
Attention机制是对人脑注意力集中于有用信息的仿真模拟,通过权重分配使模型减少对无用信息的关注,从而充分关注重要信息[19]。Attention权重值计算公式为

式中:ht为TCN模型隐层的输出;et为ht对应的Attention权重值;w、v为所需要训练的权重参数;b为偏置系数;at为归一化指数函数(softmax)计算后ht对应的Attention权重值;yt′为模型输出的预测值。
本文使用多个变量的输入来进行日均流量预测,不同变量与不同时刻的数据对日均流量的影响程度各不相同,Attention机制的使用可以筛选出对日均流量变化影响较大的关键因素,并赋予关键因素较大的权重,减小非关键因素的权重,提升对日均流量预测的准确性。
2.3 TCN-Attention模型
针对黄河花园口水文站流量影响因素多、变化趋势不确定性强、峰值变化大等问题,将花园口水文站的流量、降水量、含沙量3个变量作为模型输入数据,结合TCN模型与Attention机制,设计一种多变量TCNAttention日均流量预测模型,模型整体结构见图2,以ht输出为例展示TCN膨胀卷积和因果卷积过程,前期已进行实验调参。TCN-Attention模型第一层为输入层,将3个变量的时序数据输入模型,依照膨胀系数d分别为1、2、4、8、16、32,结合因果卷积和膨胀卷积的一维卷积隐层对输入数据进行信息提取。隐层通过权重归一化进行加速计算和收敛,隐层之间使用线性整流激活函数(Relu)作为激活函数,并在隔层之间使用残差连接,以1×1卷积操作保证隔层之间维度相同,残差模块结构见图3。每一隐层的卷积核尺寸为2,卷积核数量为32。由Attention机制自动判定隐层输出的特征信息ht对日均流量变化影响的大小,对信息h1、h2、…、ht分别赋予权重a1、a2、…、at,随后每个特征向量与其对应的权重向量合并成新向量,全连接层作为最后的输出层,最终输出TCN-Attention模型的预测值。

图2 TCN-Attention模型结构

图3 残差模块结构
TCN-Attention模型以降低真实值与预测值之间的误差作为训练目标,迭代更新卷积层、全连接层与Attention机制中的参数,直至误差收敛完成训练。使用平均绝对误差(MAE)、均方根误差(RMSE)以及平均绝对百分比误差(MAPE)作为评估模型预测精度的指标,计算公式分别为

式中:n为时序数据个数。
3 预测效果与分析
3.1 仿真实验
使用TensorFlow的Keras框架作为深度学习开发平台进行仿真实验。为验证多变量TCN-Attention模型预测日均流量的性能,设置LSTM模型和TCN模型的预测对比实验。这3个模型均使用黄河花园口水文站流量、降水量、含沙量数据作为输入,在划分好的训练集上进行迭代更新,均使用MAE作为损失函数。按照以往相似研究经验设置实验超参数[20],并经过实验调优得到最终超参数,优化器选择Adam优化器,初始学习率为0.001,batch_size设置为32,训练轮次为200个epoch。LSTM模型结构包括输入层、两个包含20个神经元的隐层以及输出层,两个隐层间有dropout结构缓解过拟合,TCN模型的部分参数与TCN-Attention模型相同。
3.2 预测结果分析
3.2.1 模型训练集预测值、验证集预测值分析
对LSTM、TCN、TCN-Attention模型训练完成后,分别绘制模型输出的训练集预测值、验证集预测值以及对应的真实值的折线图,见图4~图6。对比3个模型的预测值与真实值可知,3个模型无论是在训练集还是在验证集都能大致预测出与真实值接近的日均流量,证明建立基于多变量数据驱动的日均流量预测模型的思路切实可行。但对于不同时间范围内日均流量峰值附近的预测值,3个模型出现了不同程度的误差。LSTM模型在日均流量峰值附近的预测误差最大,这种情况在训练集和验证集中都有出现,集中体现在日均流量超过4 000 m3/s时误差最明显。日均流量峰值的预测对防洪预警、水库调度等非常重要,因此使用单一LSTM模型难以满足实际需求。TCN模型对日均流量的整体预测以及峰值预测均优于LSTM模型,其在日均流量平稳变化和周期变化时可以较好地预测,但日均流量变化具有不确定性,使用单一TCN模型仍无法准确预测在939~944 d、956~961 d时间范围内出现的日均流量小峰值。与TCN模型相比,TCN-Attention模型中的Attention机制可以很好地筛选对流量值影响更大的特征向量,非线性拟合能力更强,解决了TCN模型在预测日均流量部分峰值时误差较大的问题,有效应对随机性强、影响因素众多的流量变化。此外,TCN-Attention模型训练集预测效果与验证集预测效果相差不大,说明该模型没有出现严重的过拟合现象,有较好的泛化性能。

图4 LSTM模型拟合情况
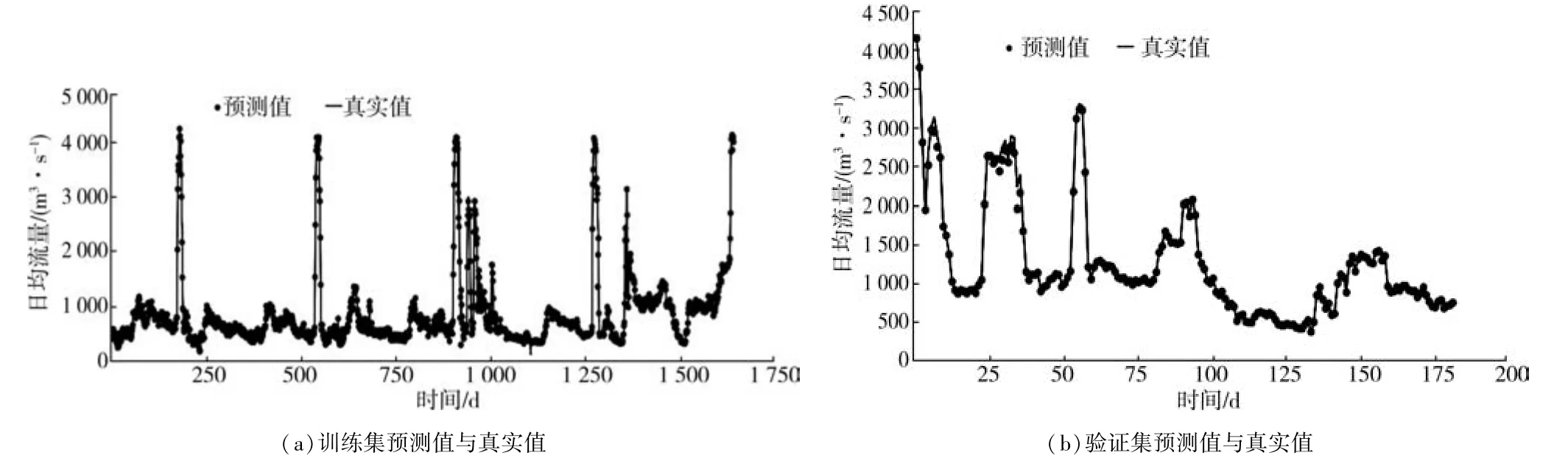
图6 TCN-Attention模型拟合情况
3.2.2 误差评价指标分析
为更直观地比较3种模型预测日均流量的性能差异,表1列出了3种模型预测值与真实值的误差评价指标值。由表1可知TCN模型和TCN-Attention模型的3种误差评价指标值均远小于LSTM的,说明LSTM模型对日均流量峰值预测的较大误差很大程度地影响了模型整体的预测性能,对于多变量情况下的日均流量预测,LSTM模型的整体性能不如TCN模型。与TCN模型相比,TCN-Attention模型的MAE、RMSE、MAPE值分别降低了20.25%、24.90%、24.39%,由此可见,Attention机制的使用有利于TCN模型更准确地预 测日均流量,其平均绝对百分比误差仅为0.967%。

图5 TCN模型拟合情况

表1 3种模型的误差评价指标值
4 结 论
以2008—2012年黄河花园口水文站日均流量、日降水量、日均含沙量历史观测数据为依据,提出了一种基于TCN-Attention模型的多变量黄河日均流量预测模型,该模型在迭代更新卷积层权重的同时,还能自动调整向量权重,使得对日均流量变化影响更大的向量权重增大。该模型使用了因果卷积、膨胀卷积、残差连接的结构,既保留了CNN并行高效计算的优势,增大了记忆序列的长度,还避免了LSTM存在的梯度问题和CNN存在的信息泄露问题。对TCN-Attention、LSTM、TCN模型进行对比,得出了以下结论:
(1)LSTM、TCN、TCN-Attention模型都可以大致预测出日均流量的变化趋势,TCN模型和TCNAttention模型的预测性能整体优于LSTM模型。
(2)Attention机制可以通过调整特征向量权重进一步提升TCN模型的预测性能,与TCN模型相比,TCN-Attention模型的MAE、RMSE、MAPE值分别降低了20.25%、24.90%、24.39%,TCN-Attention模型具有较优的泛化性能。
猜你喜欢
农业灾害研究(2022年2期)2022-05-31
人民黄河(2022年5期)2022-05-20
北京航空航天大学学报(2021年9期)2021-11-02
华北水利水电大学学报(自然科学版)(2020年2期)2020-05-31
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
黄河黄土黄种人·水与中国(2019年4期)2019-05-16
北京航空航天大学学报(2018年1期)2018-04-20
中国水运(2017年7期)2017-07-13
安徽农学通报(2017年10期)2017-06-09
