
基于改进YOLO的飞机起降阶段跟踪方法
2022-11-25 07:26郭晓静隋昊达
计算机工程与设计 2022年11期
郭晓静,李 欣,隋昊达
(1.中国民航大学 电子信息与自动化学院,天津 300300;2.中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
起降阶段飞机目标的识别跟踪,可以辅助塔台进行起降监控决策,更好地监控机场状态[1]。传统的目标识别算法利用决策分类分析飞机目标的特征[2],进而实现飞机目标的识别,但效果受背景影响较大。
目前基于深度学习的目标识别算法识别效果较好,被广泛应用。如杜聪[3]采用基于不变矩的傅里叶描述子和多边形近似的方法进行特征提取,对比构建的模板特征库中的红外图像飞机特征,进行识别跟踪,但准确率依赖于选取的模板特征的好坏;黄蓉蓉[4]将SSD[5]算法应用于军用飞机的识别检测中,但模型缺少泛化性;郭进祥等[6]利用YOLOv3[7-9]算法对机场场面飞机进行识别,实现遮挡情况下的飞机的识别,但对部分飞机的识别精度不高;孙振华等[10]提出了多标签卷积神经网络实现对飞机的精确识别,但是增加了网络的计算复杂度;衣世东[11]采用MobileNet改进SSD,与Faster R-CNN[12]结合实现对飞机的快速精准识别,但是模型过于庞大。
针对前述方法的不足,尤其是避免特征选取对识别精度的影响,本文提出改进YOLOv4[13]的飞机目标识别算法,选择飞机以及飞机垂尾的航空公司标志作为识别对象,用MobileNetv3[14]改进YOLOv4结构,通过深度可分离卷积代替传统卷积,减少模型的参数量,提高模型的检测速度。此外,利用基于马尔科夫链蒙特卡洛采样的K-means++聚类算法[15,16]对飞机数据集进行重新聚类,获得更加合理的目标先验框,提高模型的识别精度,降低参数减少造成的精度损失,实现飞机目标的快速精准识别。
1 相关算法
1.1 YOLOv4目标识别算法
YOLOv4(you only look once v4)在目标识别方面具有多尺度检测优势。其算法结构包含特征提取、特征增强以及识别输出3部分,如图1所示。其特征提取网络是CSPDarknet-53结构,在YOLOv3的基础上引入了CSPNet结构,对引入的残差网络进行融合;通过SPPNet增大感受野,分离出最显著的上下文特征;然后利用PANet改进特征金字塔的特征提取方式,输出13×13,26×26,52×52这3个尺度的特征图,分别对应识别图像的深层、中层、浅层的特征;最后根据学习到的不同层次的特征信息进行识别。
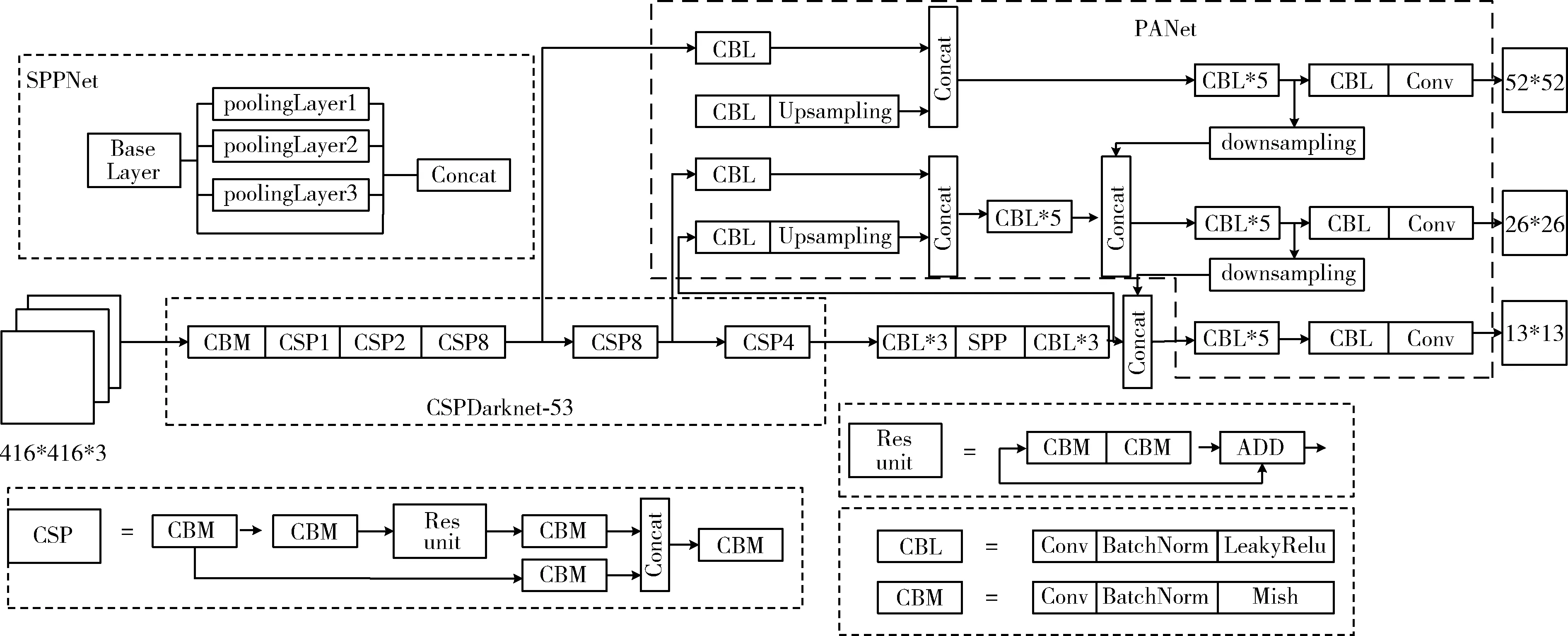
图1 YOLOv4网络结构
YOLOv4算法包含3个不同尺度的特征图,每一尺度对应3个先验框,先验框的尺寸由数据集决定,初始的先验框尺寸是通过K-means聚类算法在COCO数据集上进行聚类,在13×13,26×26,52×52这3个尺度上得到9个不同宽高的先验框,由此可得到输入图像中不同尺度上的目标特征信息,提高算法对目标对象的识别精度。但针对本文所研究的飞机目标识别,部分先验框不适用,需要对聚类中心进行重新计算,获得与飞机数据集相对应的先验框尺寸。
采用YOLOv4做目标特征提取,获得的信息更加丰富,且可利用数据在线增强扩充图像信息,降低数据的内存占用,使得模型训练更加合理高效。
1.2 MobileNetv3轻量型网络
MobileNet是基于深度可分离卷积的轻量型神经网络模型。该结构是通过深度卷积和逐点卷积这两部分的操作大幅降低模型的计算量。假设输入图像的特征映射为 (DF,DF,M), 卷积核为 (DK,DK), 输出的映射为 (DF,DF,N), 即对应的标准卷积计算量(floating point of operation,FLOPs)如式(1)所示
FLOPs1=DK·DK·M·N·DF·DF
(1)
将标准卷积分解为深度卷积(如图2所示)和逐点卷积(如图3所示)。深度卷积为 (DK,DK,1,M), 输出特征映射尺寸为 (DF,DF,M), 逐点卷积为 (1,1,M,N), 输出映射尺寸为 (DF,DF,N)。 即对应的计算量FLOPs2如式(2)所示
FLOPs2=DK·DK·M·DF·DF+
M·N·DF·DF
(2)
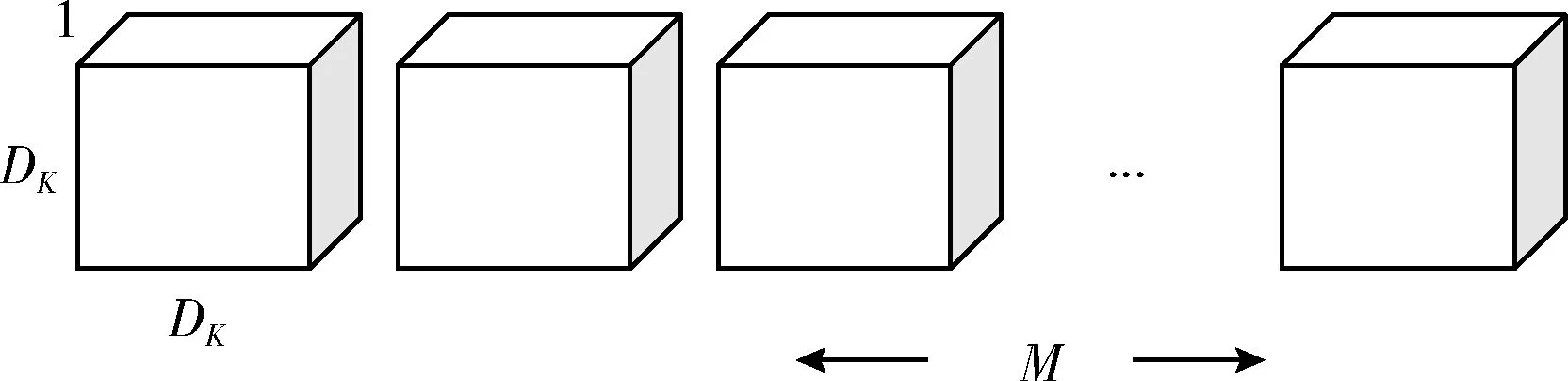
图2 深度卷积
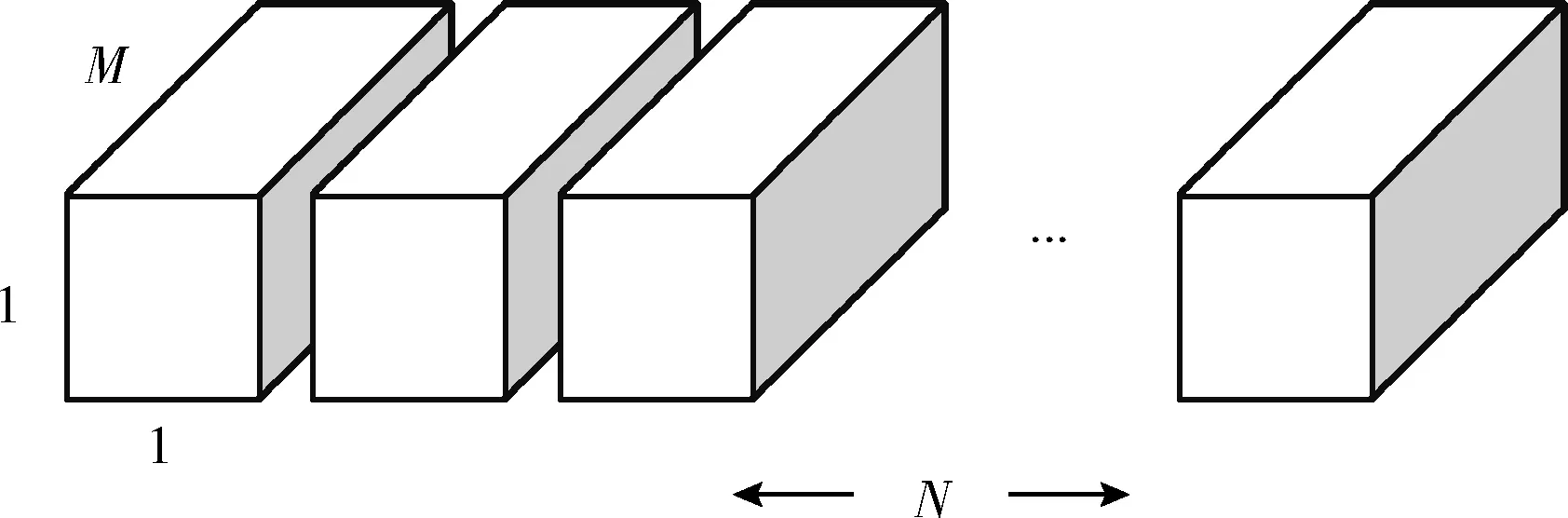
图3 逐点卷积


(3)
除了采用深度可分离卷积外,MobileNet在损失函数方面也先后采用了Relu损失函数和swish损失函数。Relu函数在低维空间进行运算时会出现的神经元失效,信息损失;swish函数是介于线性函数和Relu函数之间的平滑函数,实现了精度的提升,降低了信息损失,但也出现了计算量过大的问题。
本文所采用的MobileNetv3算法基于上述MobileNet特点,加入了SEnet网络,引入注意力机制来调节每个通道的权重,增强通道信息量,同时改用新的损失函数h-swish,即采用近似函数逼近swish,既保留了swish对精度的提升,也降低了模型的计算量,有利于模型在嵌入式设备上的应用与实现。此外,MobileNetv3进一步降低了卷积核的数量,减少了运算量,降低了计算延时,提高了模型的速度。本文采用MobileNetv3-large。
2 本文算法
2.1 改进的YOLOv4目标识别算法
本文研究民航客机目标的检测识别算法,实现对视频图像中的飞机目标识别跟踪,并且根据尾翼标志进一步识别飞机所属。此外,改进后的算法应满足在光照度较低环境下的飞机大目标、尾翼图标小目标识别的实时性要求。
为此,本文采用MobileNetv3改进传统的YOLOv4模型结构,以便使模型轻量化,提升目标识别速度,降低模型部署的硬件要求。改进后的网络结构如图4所示,该结构保留了YOLOv4的多尺度优势,用MobileNetv3替换原有的CSPDarknet-53结构,从中获得3个不同尺度的特征输出,经过逐点卷积变换维度后与预测层进行连接。具体做法是用MobileNetv3中13×13×160,26×26×112,52×52×40这3个特征层,替换CSPDarknet-53中的13×13×1024,26×26×512,52×52×256这3个特征层,将多尺度特征输入到特征加强网络进行特征融合。

图4 YOLOv4-MobileNet框架
YOLOv4结构的卷积运算主要在PANet特征加强网络,包含2个三次卷积块和4个5次卷积块,利用MobileNetv3的深度可分离卷积优势,将卷积块中的3×3卷积替换为1×1卷积,继续降低模型的参数。
改进后算法在飞机目标识别跟踪实验中呈现明显的轻量化特点。当输入图像大小为416×416×3时,模型的参数量在引入MobileNetv3后降至152.5 M,在PANet中进行卷积替换后,模型参数量降为48.4 M。可见,经过特征提取网络的改进和卷积块的替换,模型的参数量大幅下降。
2.2 改进K-means聚类
YOLOv4采用K-means聚类方法获取先验框的信息,见表1。通过聚类算法实现先验框的选取,进而在预测中得到先验框与目标框的偏移量,与直接预测目标框位置相比,降低了目标识别的难度,提高了YOLOv4算法的识别精度。因此,聚类算法得到的先验框在一定程度上影响YOLOv4算法的检测识别效果,先验框越贴合数据集,目标识别的性能就越好。

表1 YOLOv4的先验框尺寸
K-means算法是一种广泛应用的不局限于数据假设的聚类方法,人为设定聚类中心的个数,以数据之间的距离度量数据之间的相似性。通过随机初始化获得初始的聚类中心点,根据数据点与初始中心点的距离来确定各数据点的类别,随后将各类数据进行中心点计算,最终中心点趋于一个值,这个值就是最后的聚类中心。初始的聚类中心在一定程度上会影响最终的聚类效果。
在本文构建的飞机目标数据集中,飞机目标在图片中相对较大,且姿态各异,而飞机垂尾标志相对略小,且占据8类目标,每一类目标的样本个数并不均衡。为了更准确预测目标位置,对数据集引入先验分布假设,提高聚类中心选取的合理性,采用基于马尔科夫链蒙特卡罗采样(Markov chain Monte Carlo sampling,MCMC)的K-means++算法对标注边界框尺寸信息进行聚类分析。
K-means++算法的聚类思想是确保各类初始聚类中心之间的距离尽可能远。因此,本文通过马尔科夫链蒙特卡洛采样进行数据的初始化,选取更加合理的候选节点,得到更加准确的聚类中心。具体流程如下:
假设,边界框尺寸数据集X中共有n个数据点,马尔科夫链长为m,聚类中心为K个。
(1)随机初始化一个聚类中心点,计算与n-1个数据点的距离dx,如式(4)所示
dx=1-IOU(box,centroid)
(4)
其中,IOU(box,centroid) 表示标注的边界框与先验框的交并比。
(2)MCMC采样,引入q(x)分布,构造一个长度为m的马尔科夫链,以p(x)分布进行采样,取最后K-1个点作为聚类中心。其中q(x)和p(x)分别如式(5)、式(6)所示
(5)
(6)
(3)根据K个聚类中心,利用K-means算法对数据集进行聚类分析,获得K个先验框信息。
使用改进后的聚类算法对飞机目标数据集进行聚类,设置聚类中心数为9,最大迭代次数为1000,效果如图5所示,数据点的坐标为边界框归一化后的宽高值,三角形代表聚类中心,可获得9种不同尺度的先验框,见表2。
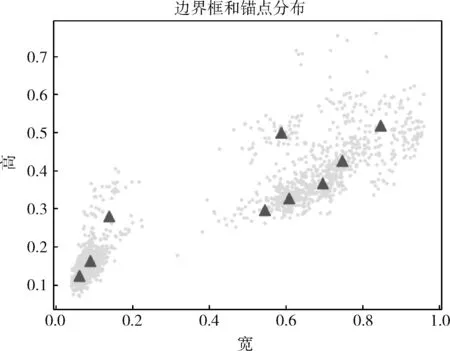
图5 聚类算法效果

表2 改进后先验框尺寸
由于数据集中的数据点不是均匀分布,存在某一类数据点较少的现象,使用原K-means聚类算法可能会导致多个聚类中心聚在一起,影响聚类中心选取的合理性。聚类算法改进后,避免了初始节点扎堆,同时也克服了小样本数据在聚类时无法成为候选节点的问题,可以全面分析飞机目标的信息,得到更加贴合数据集的聚类中心,提高后续目标识别的准确性。
3 实验结果及分析
3.1 数据集及实验环境
本文采用自建数据集(图6),其中含有5000张公开的飞机目标图像,由视频图像按帧获取,目前涉及8家航空公司。图像用labelImg工具标注,其中70%用于训练集,30%用于验证测试集。考虑到光照等因素影响,在图像获取后,利用算法进行了数据增广。

图6 飞机目标数据集
本文的实验环境采用Ubuntu16.04系统,GPU为NVIDIA GeForce RTX 1660,深度学习框架选择Pytorch1.3.0。采用马赛克数据增强方式增强数据集,余弦退火调整学习率,标签平滑设为0.01,防止过拟合。总训练轮数为400,前200轮冻结训练,设置初始学习率0.001,批尺寸(batch size)设置为16。后200轮解冻训练,设置学习率为0.0001,批尺寸(batch size)设置为8。
3.2 模型训练
经过训练后,模型的损失曲线如图7所示,从图7中可以看出,经过400轮训练后,损失值逐渐趋于稳定,模型收敛。

图7 网络训练损失函数曲线
本文的识别目标类别划分为9类,飞机目标为第1类,垂尾所属公司分别为2~9类,进行模型训练。为了检测改进算法的效果与效率,选择检测精度和检测速度两方面指标来衡量模型的性能。检测精度用准确率(precision,P)和召回率(recall,R)衡量,检测速度用每秒帧数(frames per second,FPS)来衡量,FPS越大,实时性越好。
准确率P是指在所有预测为正确的目标中,真正正确目标所占的比例;召回率R是指在所有真正目标中,被正确检测出来的目标所占的比例。如式(7)、式(8)所示
(7)
(8)
其中,TP表示被正确检出的目标数,FP表示被错误检出的目标数,FN表示没有被正确检出的目标数。
根据训练所得的P-R值可以确定P-R曲线,该曲线以召回率为横坐标,准确率为纵坐标绘制,
曲线与坐标轴所围的面积为平均精度(average precision,AP),如式(9)所示

(9)
计算出每一类目标的AP后,可以得到均值平均精度(mean average precision,mAP),mAP值越高,模型的识别效果越好。
本文的9类目标经过模型训练,可以得到全部9类目标的准确率和召回率曲线,训练结果如图8所示,设置IOU即预测框与真实框的交并比阈值为0.5,可以计算出各类目标的精度。

图8 网络训练结果P-R曲线
3.3 实验结果分析
经过模型训练,获得模型对这9类目标的检测精度,见表3。经过计算,模型的mAP达到94.29%,其中1~8类的识别精度都在90%以上,第9类的识别精度在86.74%。按照不同背景颜色进行数据集的重新划分,该类目标的识别精度达98.79%。可见,部分类别识别精度较低的原因,在于飞机垂尾目标图案颜色差异。如果尾标图案略小,且在标志的底色上采用不同的颜色背景,那么在模型训练时,由于数据集划分的随机性会造成图案的随机分布,导致在识别中产生负样本误判,从而降低识别精度。

表3 9类目标的识别精度
3.4 消融实验
通过消融实验进一步验证改进策略对网络模型的影响。将YOLOv4算法、引入MobileNetv3的YOLOv4算法(用YOLOv4-M表示),以及本文改进聚类算法后的YOLOv4-MobileNetv3算法进行相同条件下的实验。
实验结果见表4,YOLOv4-MobileNetv3与YOLOv4-M算法在识别速度方面明显优于YOLOv4,提高了35FPS,可见MobileNetv3的引入,提高了模型的检测速度;在识别精度方面,YOLOv4-M引入MobileNetv3后,略有下降,而YOLOv4-MobileNetv3与YOLOv4-M相比,模型精度提高了2.23%,同时检测速度没有损失,可见,本文聚类算法实现了模型精度的提升,虽然本文算法相比原YOLOv4识别精度下降2.48%,但仍可以达到94.29%,能够满足目标识别需求。

表4 消融实验结果
3.5 对比实验
改进后的YOLOv4模型在检测速度方面的改进效果,由不同算法对比实验加以验证。目前国内外针对可见光飞机图像识别主要采用基于深度学习的方法,如SSD、YOLO等,因此通过使用本文构建的飞机数据集,选择在相同的实验环境下,对改进后的YOLOv4模型与YOLOv4、YOLOv3、SSD这4种模型进行训练测试,实验结果见表5。
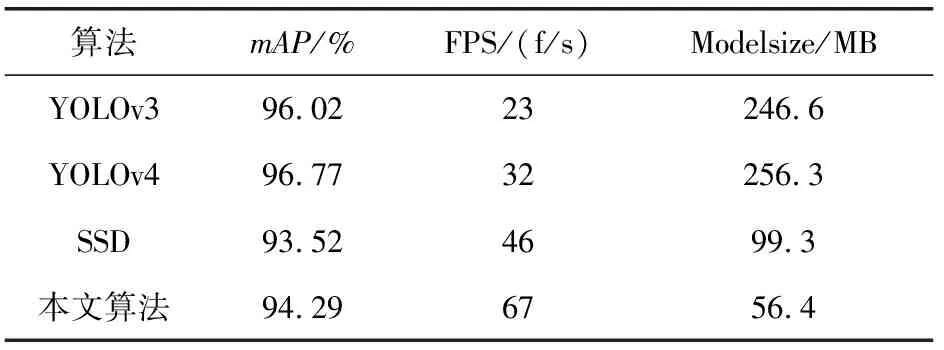
表5 不同算法性能比较
可以看出,本文采用的YOLOv4-MobileNetv3的算法模型大小为56.4 M,是YOLOv4的五分之一,并且与SSD和YOLOv3相比,该模型也是最小的。单帧图像检测时间提高到67 f/s,与YOLOv4的32 f/s相比,检测速度提高了一倍左右。在检测精度方面,本文算法与YOLOv4相比下降了2.48%,比SSD精度高0.7%,总体的识别精度仍然保持在90%以上。识别精度下降是由于模型参数减少、模型轻量化后所导致,但由于采用了本文改进后的K-means++聚类算法,实现了在保证精度的前提下对模型的轻量化和检测速度的提升,能够满足实际场景的识别要求。
为了进一步验证模型对视频图像的检测效果,将一段飞机降落的视频输入到模型中进行实验,比较不同类别飞机目标在本文算法和YOLOv4中的效果。视频总时长为22 s,帧速率为25 帧/秒,每一帧的分辨率为1280×720。图9(a)、图9(b)为改进后的YOLOv4算法的实验效果,图9(c)、图9(d)为YOLOv4算法的实验效果,其中图9(a)、图9(c)是针对3U进行跟踪的某一帧效果,图9(b)、图9(d)是针对CZ进行跟踪的某一帧效果。可见,在相同条件下,原始的YOLOv4算法FPS只能达到10 f/s左右,而改进后的YOLOv4算法可以达到29 f/s左右,与单帧图像识别效果一致,本文算法在视频图像检测速度方面仍有优势,检测精度能维持在90%以上,效果提升明显。

图9 改进后 YOLOv4与原YOLOv4检测效果对比
4 结束语
本文算法以YOLOv4算法结构为基础,融合了MobileNetv3算法的轻量型特点,改进YOLOv4的结构,构建了起降阶段飞机目标识别跟踪的模型。从单帧图像到视频图像,利用模型进行了识别效果实验。实验结果表明,单帧图像的识别速度达到67 f/s,视频图像的识别速度达到29 f/s;检测精度总体维持在90%以上;模型的大小相比YOLOv4及其它传统算法大幅降低,实现了模型轻量化,提高了飞机目标识别效率。目前识别的飞机种类为民航客机,接下来可以尝试对其它种类机型进行识别,进一步提高模型的实用性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
铁道通信信号(2019年6期)2019-10-08
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年5期)2017-05-14
雷达学报(2017年6期)2017-03-26
中国诠释学(2016年0期)2016-05-17
互联网天地(2016年1期)2016-05-04
