
基于改进PGGAN的口腔图像数据增强算法
2022-11-25 07:26翁鹏涛杜玉军张道奥王舒研汪苑苑
计算机工程与设计 2022年11期
翁鹏涛,杜玉军,张道奥,刘 青,王舒研,汪苑苑
(1.西安工业大学 光电工程学院,陕西 西安 710021;2.空军军医大学第三附属医院 口腔粘膜科,陕西 西安 710032;3.军事口腔医学国家重点实验室(国家口腔疾病临床医学研究中心),陕西 西安 710032)
0 引 言
口腔图像是基于深度神经网络的智能口腔医学研究的基础。由于病例隐私保护、医学样本图像来源少等原因,临床上口腔病灶图像获取难度大,难以建立完备的数据集[1],因此深度学习在口腔医学领域的研究相对较少。
传统的数据增强算法可以从色彩和空间位置等方面有效地解决数据容量小的问题,但提升数据多样性的能力较弱[2,3]。区别于自然图像,口腔图像的病灶区域形态、颜色及纹理细节都影响着病情定性分析的结果。对于同一口腔疾病,其病灶特征个体差异较大,并且时常伴随着多种疾病并发的情况,此时病症判断更为复杂,因此其数据集的建立和扩增,必须以高质量、高细节为前提,仅靠传统数据增强算法无法胜任。
生成对抗网络(generative adversarial networks, GAN)及其衍生模型正朝着更多样化、更高质量的图像生成方向发展[4,5],已经广泛应用于图像生成领域。Radford等[6]提出的深度卷积生成对抗网络(deep convolutional generative adversarial networks,DCGAN)最先应用于色彩鲜明、内容区分度较大的自然图像数据集扩增,却不适用于色彩单一的口腔医学图像。Shrivastava等[7]使用GAN对MPIIGaze数据集进行数据增强,并提升了眼球角度预测和手势识别的准确率,巩固了GAN在数据增强领域的重要地位。Arjovsky等[8]和Gulrajani等[9]解决了GAN的训练过程不稳定、生成样本多样性差的问题,并改进出了Wasserstein GAN。Karras等[10]提出的渐进增长式生成对抗网络(progressive growing of generative adversarial networks,PGGAN)在训练时大部分迭代都在小尺度下进行,因此可以稳定地生成高质量、高细节的图像。同时,PGGAN提出的小批量标准差(minibatch standard deviation)有效地缓解了Mode collapse问题。但无法直接应用于病灶特征区分度小、颜色单一,且对图像细节要求严苛的口腔图像。
为此,本文针对口腔白斑和口腔扁平苔藓,研究了一种传统数据增强和PGGAN算法结合的数据增强方法,解决了口腔图像多样性的问题,融合轻量化的通道注意力突出了病损区域的特征,提升了图像质量。
1 PGGAN的网络增长模式
PGGAN由生成网络(generator,G)和判别网络(discriminator,D)构成,其两部分网络结构都是随着训练进行更新的,如图1描述了其“网络生长”的思想。在图1中, PGGAN的生成网络和判别网络呈镜像对称分布,即生成网络和判别网络的各级网络模块一一对应。其中,“4×4”表示4×4像素级的生成(判别)网络模块,该模块可以生成(判别)4×4像素的图像。在训练初始,生成网络的输出和判别网络的输入均为4×4像素的口腔图像;在完成当前级网络的训练后,添加新的网络模块,使当前级的网络更新为更高一级的网络,此时生成网络的输出和判别网络的输入“生长”至8×8像素级的口腔图像,并将两级模块共同作为新的网络结构进行训练;以此类推,直至网络“生长”至256×256像素级,最终生成256×256像素的口腔图像。

图1 渐进增长式生成对抗网络结构
2 本文方法
2.1 网络模型
本文的口腔图像数据增强模型的主要结构如图2所示,模型由生成网络和判别网络两部分组成。生成网络的输入和输出分别为随机噪声和生成图像,其作用是将随机噪声生成为口腔图像,判别网络的目的是区分输入的图像是真实图像还是生成图像。其中,在生成网络增长时添加的上采样模块,而在判别网络中添加下采样模块。生成对抗网络在生成较高分辨率的图像时训练会变得不稳定,生成的图像细节变得扭曲、不真实,因此本文模型在64×64像素级以上的网络中融入了通道注意力机制,用以有效地获取局部特征,把握全局有效信息,丰富生成图像的语义信息。

图2 本文方法的结构

图3 采样模块结构
本文模型通过各级采样模块拼接从而形成更高级的网络,如图3为本文网络模型在网络增长时添加的采样模块结构图。其中,Leaky ReLU是激活函数,Conv 3×3表示卷积核为3×3的卷积层,PixelNormalization是像素归一化层,SE block是本文采用的轻量化通道注意力模块。上采样操作基于最邻近插值实现,不仅可以减少网络训练参数,提升训练效率,还可以一定程度上避免图像生成中的“棋盘网格效应”。而下采样操作通过平均池化实现。生成网络在42->322阶段时,添加图3(a)所示的上采样模块以更新网络,在642->2562阶段时,则添加图3(b)中所示的加入通道注意力的上采样模块;而判别网络在42->322和642->2562阶段时,分别添加图3(c)、图3(d)所示的下采样结构。
图4是本文方法用以生成256×256口腔图像的生成网络和判别网络,此处的Conv 1×1、Conv 3×3和Conv 4×4分别表示卷积核大小为1×1、3×3和4×4卷积块。生成网络中的卷积块由卷积层、激活函数和像素归一化层构成,判别网络中没有像素归一化层。
2.2 增长平滑机制
由于新添加的网络层不含初始化参数,本文方法在网络增长阶段增加的新卷积层和采样层会引起网络性能的“断层式”下降,严重影响网络的训练方向。这里的增长平滑机制就是先训练一个低像素级的网络,训练完成后再逐步过渡到更高像素级的网络进行训练;然后稳定训练当前像素级网络,再逐步过渡到下一级更高像素级网络。
图5以4×4图像到8×8图像的过渡过程为例,其中图5(a)和图5(c)分别表示4×4图像和8×8图像的网络结构,图5(b)是增长平滑机制的网络结构。nearest的作用是通过最邻近插值将图像的长和宽加倍,pooling的作用是通过平均池化把图像的长和宽减小一倍。此处,toRGB使用图4(a)中的1×1卷积,表示将特征向量转化为输出的RGB口腔图像;fromRGB使用的是图4(b)中的1×1卷积,可以将输入的RGB口腔图像转化为特征向量。
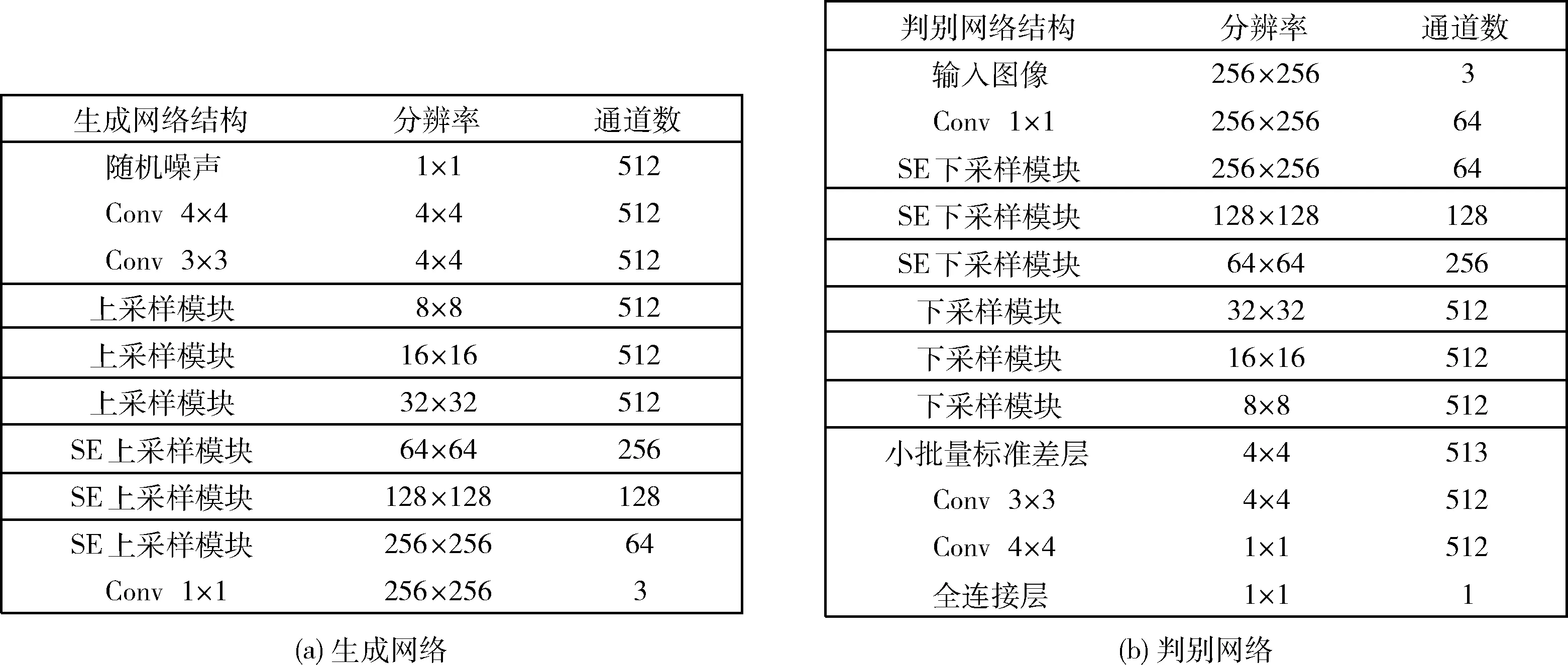
图4 本文用以生成256×256口腔图像的网络结构

图5 增长平滑机制原理
当生成网络G和判别网络D的像素分辨率增加时,通过图5(b)的网络结构逐渐平滑地加入新的网络层,若把在更高像素级上操作的网络层看作一个残差块,则wg和wd分别是生成网络G和判别网络D中新加入层的权重。增长平滑机制充分利用了低像素级网络的训练参数,当该权重为0时,相当于网络中没有加入新的网络层,即当前是低像素级的网络;当该权重为1时,表示当前已经过渡到更高像素级的网络。在训练中,wg和wd同步从0线性增加到1,使得更高像素级的网络训练更加稳定。
2.3 通道注意力
生成对抗网络在低像素级的训练任务中是比较稳定的,如DCGAN可以比较稳定的生成64×64像素的图像;在128×128像素、256×256像素的图像生成过程中,图像质量往往难以保证,且训练时间较长;在256×256像素以上的高分辨率及超分辨率图像生成任务中,训练过程不稳定,会生成扭曲的图像细节。高分辨率图像蕴含的高频语义信息更加丰富,结构较为简单的网络无法学习和关联像素之间的空间属性,故难以生成高分辨率的图像。
注意力机制是模拟人眼视觉处理机制的模型[11],主要作用是对卷积提取的特征进行校正,由注意力校正过的特征可以更好地突出病灶区域特征,其本质就是加权。SE模块(squeeze-and-excitation block,SE block)是Jie等[12]提出的一种轻量化的通道注意力机制。SE模块在不引入新的空间维度的情况下,通过学习的方式捕获每个特征通道的重要程度,以此为标准一致对当前任务用处不大的特征。以很小的参数量和计算量换取注意力的加权计算,从而实现了性能的提升。
在本文方法中,当网络增长至64×64像素及以上级别时,加入SE模块使得网络可以有效地提取局部特征、把握全局有效信息,增加生成图像的语义信息。图6是SE模块的结构示意图。

图6 SE模块的结构
在图6中,SE模块的核心步骤是特征压缩Fsq和非线性激活Fex。定义SE模块的输入特征图是X=[x1,x2,…,xC′]∈H′×W′×C′, 其中xk表示第k通道的特征向量,首先其通过卷积操作Ftr转化为所需的多通道特征图U=[u1,u2,…,uC]∈H×W×C, 其中uc∈H×W表示特征图U中第c通道的特征向量。设V=[v1,v2,…,vC] 表示学习到的一组卷积核,其中是第c个卷积核,是2D空间核,表示k方向上的某个单通道vc。则uc可由式(1)计算
(1)
式中:*表示卷积。
特征压缩解决了每个输出利用不到卷积区域之外信息的问题。SE模块沿着空间维度(H×W)进行特征压缩,把每个通道上的特征图压缩生成通道表征符,即H×W×C维度的特征图U通过式(2)转换为1×1×C维度的通道表征符向量z=[z1,z2,…,zC], 以表征c个通道的特征向量的分布情况,也称全局信息。其中zc∈C表示经压缩后第c个通道特征向量的通道表征符,可由式(2)算得
(2)
为了建模和学习各特征通道间复杂的相关性,可以将压缩得到的通道表征符进行两次非线性激活Fex。通道表征符向量z先进行特征维度缩减,再将其特征维度增长回原本维度,以增加网络的非线性表达能力,最终求得数值区间为[0,1]的权重向量S=[s1,s2,…,sC], 进一步有效地利用全局信息。式(3)为Fex操作的表达式
S=Fex(z,W)=σ[W2δ(W1z)]
(3)
式中:δ表示ReLU激活函数,σ表示Sigmoid门函数,其中W1和W2分别是维度缩减和维度增长参数。
因此,sc可以表征多通道特征图U中各通道上特征向量的权重,再通过乘法逐通道加权到原有的特征向量上,将U进行重新标定作为SE模块的输出Y=[y1,y2,…,yC]∈H×W×C, 其中yc是第c通道的输出特征向量,计算公式为式(4)
yc=Fscale(uc,sc)=sc·uc
(4)
式中:Fscale代表第c通道的特征uc与相应通道的权重sc相乘。
2.4 目标函数
WGAN-GP已被证实可以进一步稳定生成对抗网络的训练过程[9],因此本文模型使用其目标函数,保证当网络增长至较大像素级阶段时,训练可以稳步进行。WGAN-GP就是使用梯度惩罚项的方法代替WGAN中的权重裁剪以确保判别网络D满足Lipschitz连续约束,即经过训练后判别网络D的梯度值在1附近。通过在WGAN的目标函数中增加额外的梯度惩罚项,以表征其目标函数的平滑性,保证了训练的稳定性。
随着训练进行,生成数据的分布是向真实数据的分布靠近的,因此处于这两个分布之间的样本的梯度信息可以有效地指导训练过程。记生成数据的分布pg和真实数据的分布pr之间的数据分布为pχ,选取一个任意数ε∈[0,1], 在一对真实数据x和生成数据y上随机插值得到随机采样的数据x′,则有x′服从分布pχ。x′可通过式(5)算得
x′=εx+(1-ε)y
(5)
最终得到WGAN-GP的目标函数为式(6)

(6)
式中:x是真实数据,y是生成网络G生成的数据,y~pg表示y为生成数据的采样,x~pr表示x为真实数据的采样,x′~pχ表示x′为随机采样数据的采样,E(·)是分布函数的期望值,D(·)是数据通过判别网络D判断其为真实样本的概率,λ为梯度惩罚项的权重系数,文献[9]中提出,梯度惩罚权重λ取10,可以最大程度上确保判别网络D满足Lipschitz连续约束,因此本文沿用λ取10。
3 分析与讨论
3.1 实验数据集
近年来,深度学习在医学影像领域取得众多突破,网络模型通过大容量的医学影像学习特征参数,可以避免过拟合现象,也可以提高网络性能[13-15]。口腔白斑和口腔扁平苔藓是两种常见的口腔粘膜斑纹类疾病,本文实验所用口腔样本图像由第四军医大学口腔医院提供,在临床上使用数码相机在白光环境下采集的两种病损样本图像如图7所示。

图7 口腔图像样本
3.2 传统数据增强与数据集建立
临床上收集到的这两种病灶样本数量较少,远远不足以支撑神经网络的训练。因此,本文结合传统数据增强算法和神经网络,研究口腔图像的数据增强问题。首先使用传统算法进行数据增强,再将增强过后的数据用于神经网络的训练。
图8为使用传统算法增强后的结果,图示为本文使用到的方法,从左至右依次为:原图、随机对比度、90°旋转、高斯噪声、水平翻转和随机剪裁。在通过5种数据增强算法的随机结合使用,实现了现有的两种口腔病灶样本数据量成倍增长,在删除一些相似和疑似数据后对口腔图像数据进一步处理。

图8 传统算法增强后的结果
临床上收集的口腔病灶样本受到采集方法、病损处的位置、形态和大小等原因影响。为了提高模型的生成效果,减少生成对抗网络训练的难度及所用时间,需进一步对数据增强过后的口腔医学数据(大小为5184×3456像素)进行感兴趣区域(即病灶区域)剪裁,其剪裁区域大小均为1024×1024像素,图9为截取感兴趣区域后的部分图像,即用于本文神经网络训练的图像。

图9 本文建立的部分口腔图像数据集
至此,可以建立本实验所用的口腔医学数据集,两种病损图像的数目见表1。
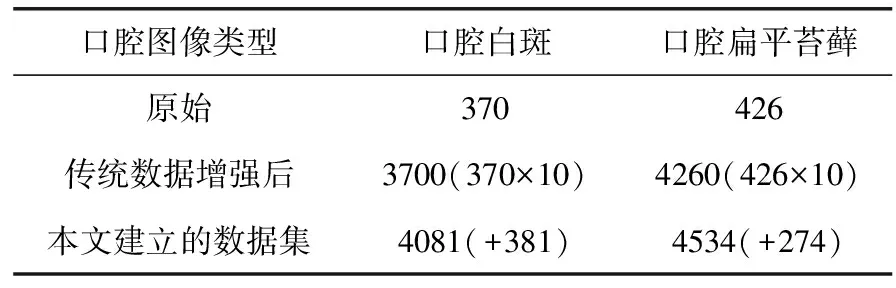
表1 本文建立的口腔图像集数目
3.3 实验参数
为验证本文网络模型的图像生成效果,实验设置在相同训练参数下与原始PGGAN进行对比。本文网络模型的训练是一个“网络生长”的过程,从4×4像素至256×256像素的训练一共经历7级“网络生长”阶段。实验在每级网络上训练轮次为500,受实验设备的限制,前6级网络batch_size设置为16,steps_per_epoch设置为255,最后一级网络batch_size设置为4,为了保证得到最好的训练效果,将steps_per_epoch设置为1020。本文所有实验均部署在Linux环境下,使用Tensorflow2.1的GPU版本,硬件配置为2块NVIDIA RTX 2080Ti。
在训练期间,将真实口腔医学图像随机翻转并归一化至[-1,1]输入判别网络,生成网络的输入为512维的噪声向量。两部分网络均使用Adam优化器,学习率设为2×10-4,生成网络最终生成的口腔图像大小为256×256像素。测试阶段,将生成网络输入的随机向量归一化至[-1,1],输出为256×256像素的口腔图像。
4 实验结果与评价
4.1 定性分析
4.1.1 网络增长及增长平滑机制分析
分别在口腔白斑和口腔扁平苔藓数据集上进行实验,共包含7级网络增长结构,实验设置4×4阶段为初始化网络,其余各级网络的训练均分为过渡阶段和稳定阶段,因此整体上一共有13个阶段,其中 42->82、82->162、162->322、322->642、642->1282和1282->2562为过渡训练阶段。图10是过渡阶段生成图像的部分。过渡阶段新添加的网络层不含初始化参数及权重,导致网络性能下降,因此生成图像中存在网格状的伪图,称为Checkboard。由图可以得出,该现象在162->322时最为严重,在642->1282时逐渐减弱,在1282->2562时伪图基本消失。

图10 过渡阶段的部分生成结果
图11是稳定阶段生成图像的部分。由图可以得出,随着网络结构的逐渐增加,生成图像的高频语义特征逐渐清晰,图像的质量越来越高。其中,4×4和8×8像素的图像内容无法辨认,图像质量差,仅能反映出图像生成的趋势;16×16和32×32像素级的网络生成了病灶区域的大致轮廓和部分简单的病灶特征;在64×64和128×128像素的图像中,病灶区域的形态和纹理细节较为模糊,整体图像的质量不高;256×256像素的图像质量较高,较为清晰地生成了原始图像的病灶纹理、病灶颜色等高频语义特征。

图11 稳定阶段的部分生成结果
4.1.2 病灶图像生成效果分析
本节通过对比CGAN、BEGAN、DCGAN、PGGAN和本文方法生成的两种病灶图像,以验证本文方法的性能。图12是各网络生成图像的结果。可以直观得到,CGAN不能很好地捕获病灶特征的形态,其生成的白斑图像的病灶边缘呈现锯齿状伪图,扁平苔藓图像病灶边缘不清晰。BEGAN的生成结果保留了较为清晰的病损特征,但生成图像中仍存在“棋盘网格”,呈现出伪图。DCGAN的生成图像较为模糊,无法观察到具体的病灶形状,整体图像质量较差。PGGAN的生成图像较原图而言,存在比较明显的“棋盘网格”。本文方法生成的图像基本保留了原始图像中病灶区域的特征,其病灶区域轮廓和纹理清晰。由于原始口腔图像是在临床白光照射情况下进行采集,因此部分训练图像中存在有反射光和唾液泡的现象。在本文方法生成的白斑图像中存在的较亮区域,推测为生成的强白光照射下的唾液反光现象;在扁平苔藓图像的左下角为生成的唾液泡现象。实验结果表明,本文方法较好地生成了256×256像素大小的口腔白斑病和口腔扁平苔藓图像,基本保留了原始图像的病灶区域细节。

图12 不同网络生成图像的结果
4.2 定量分析
生成模型的性能评价通常从两个方面出发:生成图像的清晰程度和多样性。生成图像的清晰度反映其图像质量的高低;多样性是要求对生成图像进行分类,每个类别的图像数目尽可能相等。
IS(inception score)是基于预训练的Inception网络计算出的评价指标,常用于评价生成模型的性能,其值表示生成数据集的图像类别数[16,17]。在生成图像清晰程度方面,记y是类别标签,预训练的Inception网络能以很高的概率对生成图像x进行分类判断,计算出条件概率p(y|x) 以表示生成图像属于某个类别的概率,该概率越高说明图像质量越好,p(y|x) 的分布函数图越尖锐;针对生成图像的多样性,若用p(y) 表示类别标签的分布,则生成图像越多样化,p(y) 越趋近于均匀分布。
KL散度可以衡量两个概率分布间的距离,其值越大,说明两个分布越不接近。因此IS通过KL散度综合了以上两个方面来评价生成模型,见式(7)
IS(G)=exp(Ex~PgDKL(p(y|x)‖p(y)))
(7)
式中:DKL是KL散度,Pg是生成图像数据的分布,x~Pg表示x为生成数据的采样,E是分布函数的期望。IS值越大,往往表明生成模型的性能越好。
FID(fréchet inception distance)是用来计算真实图像与生成图像的特征向量间的距离。使用预训练的Inception网络提取真实图像和生成图像的特征向量,通过其均值和协方差计算两张图像之间的相似程度。计算公式如式(8)

(8)
式中:r是真实图像,g是生成图像,μr和μg分别是真实图像和生成图像的特征的均值, ∑r和∑g分别是真实图像和生成图像的特征的协方差矩阵,Tr是矩阵的迹。当真实图像和生成图像的特征向量越相近时,FID值越小,说明生成模型效果越好,即生成图像的清晰度更高,且多样性更丰富。
虽然IS可以很好地评价生成模型的好坏,但其计算只考虑了生成图像,即无法反应生成图像和真实图像之间的关系,并且IS无法判断同一类别中的生成图像的多样性(例如,同一类别中生成图像全部相同);FID是利用生成图像与真实图像之间的关系进行判别,同时,从特征向量层面衡量两者之间的距离,因此FID对于模型坍塌更加敏感,对噪声具有更好的鲁棒性。口腔图像对病灶位置的形态、纹理等特征要求较高,因此本节使用IS和FID两个评价指标,可以更加全面、有效地表征本文算法性能。
本文实验中,网络模型训练时所使用的学习率决定着生成模型是否取到全局最优解,即算法性能是否达到最佳,因此在实验中先对其它参数进行统一,分析不同学习率对本文算法性能的影响。训练完成后,使用IS和FID分别对各个学习率下生成的5000张口腔图像进行分析,其结果见表2。
从表2中可以看出,针对口腔白斑和扁平苔藓数据集,

表2 不同学习率对算法性能的影响
当学习率为2×10-4时,对应本文算法性能最佳。基于此,分别使用CGAN、BEGAN、DCGAN和PGGAN在两种口腔图像数据集上进行训练,各生成5000张口腔图像,并计算其IS值和FID值与本文方法进行对比,结果见表3。

表3 本文方法与不同网络的算法性能分析
由表3可以得出,在口腔白斑和口腔扁平苔藓数据集上,本文方法较未改进的PGGAN在IS值上分别提升了0.32和0.07,FID值分别降低了0.13和0.09,且优于实验中其它的对比方法。由于实验环境限制,在计算IS值时没有使用10次训练,生成求均值的通用方式,而是采用1次训练,10次生成后再计算的方式,因此存在一定的计算误差。实验结果表明,本文方法相比于原始PGGAN在口腔图像的生成上性能更优,更适用于色差单一,内容复杂的口腔图像。其生成的病灶图像有更高的质量,且更加多样化,可以有效地扩增口腔图像的数据集。
5 结束语
本文联合传统数据增强算法与神经网络解决口腔图像的数据增强问题。研究了一种基于改进PGGAN的数据增强算法,利用轻量化的通道注意力,生成了256×256像素大小的口腔图像,生成图像的质量和多样性均有所提升,满足口腔图像数据集增强的要求。但本文所用方法生成的口腔图像仍存在部分病灶形态不合理、病灶颜色差异等问题,下一步将针对该类问题展开研究和改进。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
中老年保健(2021年3期)2021-08-22
中国生殖健康(2020年4期)2021-01-18
今日农业(2020年19期)2020-12-14
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国与非洲(法文版)(2017年10期)2017-11-23
