
基于眼睛状态多特征融合的疲劳驾驶检测
2022-11-25 07:26黄德启
计算机工程与设计 2022年11期
任 俊,魏 霞,黄德启,刘 栋
(新疆大学 电气工程学院,新疆 乌鲁木齐 830047)
0 引 言
视觉检测[1-3]主要提取面部特征来判断疲劳状态,然而这些特征提取会受到外界干扰,如何避免光照、眼镜以及姿势等因素的影响,提高疲劳状态检测的精度和速度是研究的关键。其中,吴良超等[4]提出构建特征点动态变化图和神经网络的动态表情结合的识别法,该方法通过特征点动态变化图提取人脸轮廓信息,用卷积和循环神经网络提取人脸的纹理信息、人脸序列的时序信息。樊飞等[5]围绕着人脸特征点检测改进算法进行疲劳检测,通过牛顿提升树结合统计量特征,提出CNBT人脸特征点检测算法,能够有效提高疲劳识别准确率和稳定性,但是没有考虑驾驶员头部姿势变化等情况,在真实环境下的实用性有待提高。对于上述提到的问题,需要设计一种实用性广泛的疲劳检测框架尤为重要,同时由于驾驶员会有不同程度的头部偏转,采用单眼检测来代替传统的双眼检测机制,增强检测的范围,提高实用性。根据特征点和二值图像得到的纵横比值、累积黑色素差值以及人眼水平投影高度和宽度比值作为支持向量机的3个输入特征,进而在三维立体图形中得到眼睛状态分类结果,最后根据眼睛状态计算ECR值作为眼部疲劳特征参数判断驾驶员的疲劳状态。
1 图像预处理及人脸检测与跟踪
1.1 本文整体流程设计图
本文框架分为3个部分,经过图像预处理后检测和跟踪人脸,对定位好的3类特征点进行提取和校正,特征融合判别疲劳状态,本文设计流程如图1所示。

图1 设计流程
1.2 图像滤波去噪与光照均衡化处理
在实际采集驾驶员视频和图片时可能会受到周围环境的噪声和光照的影响,使得图像变得模糊,因此需要先对采集的图像进行滤波去噪,提高后期人脸检测和特征提取的准确率。采用自适应中值滤波[6]的方式,实际是利用中值滤波来消除孤立的斑点,并采取自适应邻域中值代替是噪声的原始像素值,再采用图像动态阈值的光照均衡化处理,使图像的光照均匀分布,如图2所示,均衡化处理后,图片光照和亮度得到较好的改善,进而有效提取人脸的特征。

图2 光照均匀化前后对比
1.3 基于AdaBoost人脸检测
1.3.1 基于Haar-like特征的AdaBoost人脸检测算法
目前在人脸检测过程中,人脸图像可以用图像灰度变化的特征来表征,而Haar-like特征[7]可以反映灰度变化。先用积分图算法快速得到任意区域的像素和,再可以由像素灰度和差值来得到Haar-like模板特征。AdaBoost算法[8]用于人脸检测,是通过训练集训练弱分类器,形成分类效果较好强分类器,进而训练出最能代表面部特征,从而加快检测速度和提高准确率。其算法流程如图3所示。

图3 AdaBoost算法流程
1.3.2 实验结果分析
对人脸特征识别完成后进而对眼睛特征进行检测,输出可以识别的人脸区域和眼睛区域的矩形框,检测效果如图4所示,可以清楚标识出来。

图4 人脸检测效果
1.4 面部目标跟踪算法
考虑到在实际图像采集的过程中,由于驾驶员面部偏移距离较小,都在一定范围内,在第一次检测到人脸之后,只需要跟踪人脸上一帧人脸信息,快速获得下一帧人脸位置信息。采用基于帧间差分法的Mean Shift算法[9]进行人脸跟踪,利用连续两帧图像之间的联系,进行差分运算,然后利用二分阈值法提取边缘区域,获得下一帧人脸的位置信息,提高检测速度。
2 基于SVM的睁闭眼状态识别
2.1 基于级联回归树的人脸特征点定位
为了减少外界环境因素对人脸特征部位的检测及定位的影响,在人眼检测定位之前先使用了基于级联回归树算法[10-12](ERT)对人脸的关键特征点进行定位,然后在人脸特征点定位的基础上,快速定位到人眼。基于级联回归树算法是一种人脸对齐算法,不断检测特征点然后进行更新,最后逐步定位到真实人脸位置。
如图5所示,ERT算法可以实现多个角度的人脸特征点定位且效果较好。

图5 不同角度人脸特征定位
2.2 基于人眼特征点计算人眼纵横比
在提取人脸特征点之后,通过实验发现,驾驶员在正常眨眼过程中,眼睛的特征点也会随之变化,因此我们根据人眼特征点来求取眼睛的纵横比值来表示人眼的状态信息。而且纵横比值不会因为驾驶员面部位置和摄像头距离改变而改变。如图6所示P1到P6分别对应人眼6个特征点,眼睛纵横比计算公式
(1)

图6 人眼特征点分布
由式(1)可知EAR由眼睛纵向长度与横向长度比值得来的,当头部左右偏转时,眼睛的横向长度发生变化,当头部上下点动时,眼睛的纵向长度发生变化。因此针对头部左右偏转和上下点动时进行特征点校正。图7为眼睛纵向长度变化。

图7 人眼纵向长度变化
图7中l0表示初始状态下真实眼睛的纵向长度,分别发生了点头和抬头,导致俯仰角β0变成β1和β2,l0也随之变化为l1和l2。h0为l0投影到二维图像的高度,h1为l1投影的高度,由于实际情况下点头和偏转眼睛真实纵向长度不变,即l0=l1,则有
(2)
人眼左右偏转变化和上述过程类似,以w0和w1分别表示初始状态下以及变化后的眼睛横向长度,α0和α1分别代表初始状态下以及变化后的偏转角,得到w0和w1关系
(3)
由此可以得到图像中人眼纵横比为
(4)
式中:EAR1是校正前眼睛纵横比值,图8是校正后的眼睛纵横比值随帧数变化的折线图,由图8可以看出,当眼睛睁开时纵横比维持在0.32左右,当纵横比小于0.2时可视为闭眼状态。因此可以通过计算人眼纵横比值来判断人眼状态。

图8 人眼纵横比值随帧数变化
2.3 基于自适应阈值计算人眼黑色像素累积差值
根据定位的人眼区域,先进行人眼图像二值化处理,再经过中值滤波处理后显示眼睛的轮廓,表1为人眼不同状态下的二值图像。

表1 人眼不同状态二值图像
在眼睛闭上的情况下,计算眼睛区域内的黑色像素数的累积差值,虽然睫毛和眼睑等黑色区域可能会保留,但是瞳孔区域最大的黑色区域不会出现,也就是说,当眼睛闭上的时候,黑色像素数量会比睁眼的时候大幅减少,然而,黑色像素的数量不仅会随着眼睛状态变化而变化,还会随摄像头与驾驶员面部的距离变化而变化,当这个距离增大时,眼睛区域黑色素的数量会减小。
如图9所示,图(a)显示了根据帧数变化的二值化区域内的黑色像素数,看到在第101帧之后当面部离开摄像头更远时,眼睛区域的黑色像素减小,因此仅使用第101帧之前的阈值,就无法区分第101帧之后的眼睛是睁开还是闭上的,可以采用连续图像中眼睛区域的黑色素的差值。

图9 人眼睁闭过程中黑色像素值随帧数变化
当采用的连续图像中眼睛区域的黑色像素的差值作为特征时,可以识别部分闭眼状态,但如图(b)中在第41帧、105帧和106帧的差值小于静态阈值,错误地识别眼睛状况,为了解决这一问题,使用一种新的特征,即眼睛图像中黑色像素数的累积差值,当检测连续两帧及以上图像的差值小于0的条件下,将连续的差值进行累加,如图(c)中第一个满足条件的情况出现在第40帧,而在第102帧时,尽管差值小于0,但是它没有在超过两帧情况下保持,因此它不累加。
然而对于如图10所示,图(a)这种情况,累积差值法在识别眼睛状态时存在以下问题,如图(b)的第257和260帧所示,虽然它们显示的是闭眼,但是由于差值大于0,它们不是累积的,导致图(b)的第255帧到260帧都被错误地识别为睁开眼睛,因此使用了具有自适应阈值的累积差值作为特征。
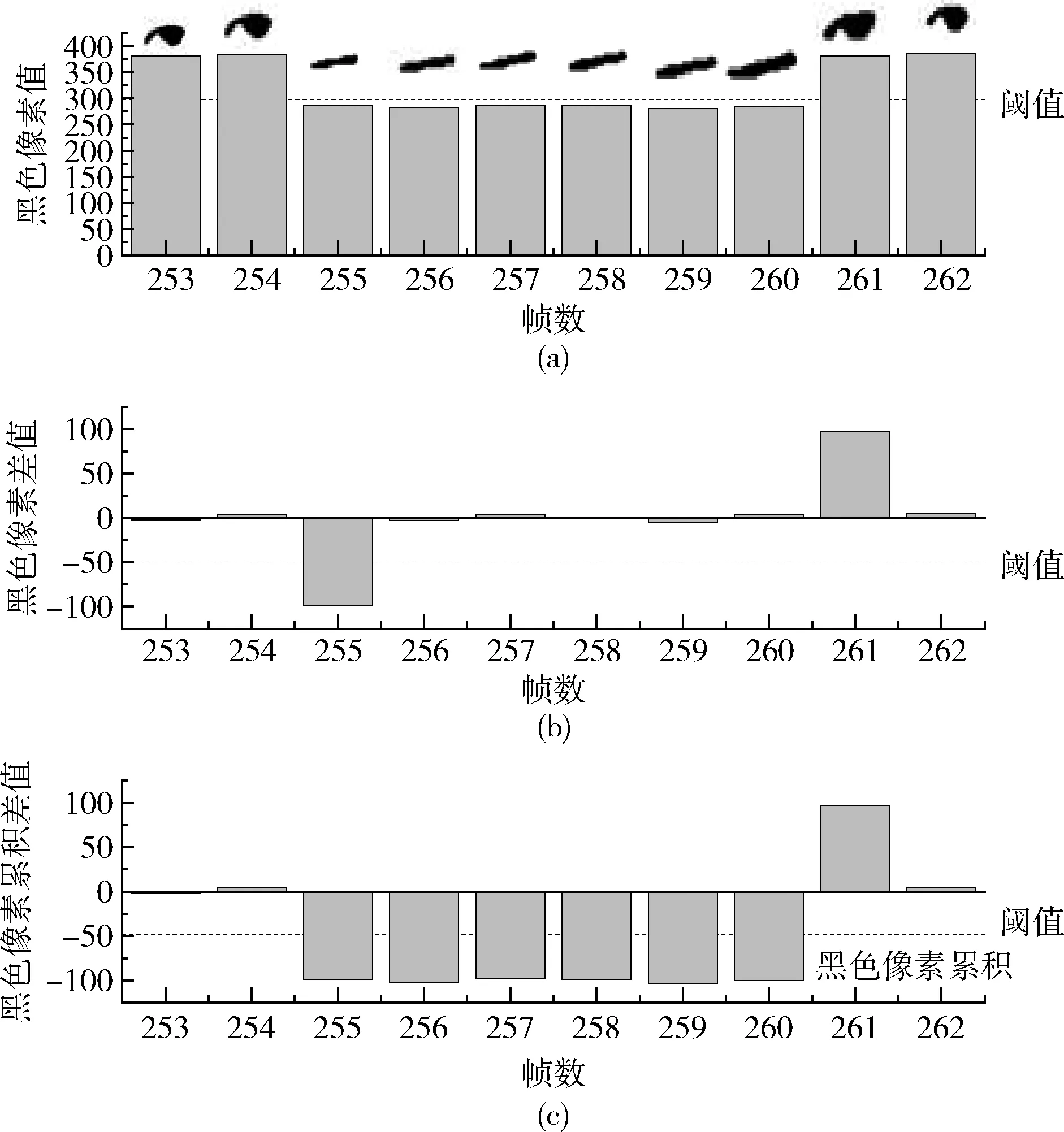
图10 自适应人眼睁闭过程中黑色像素值随帧数变化
如图11所示,将累积差与自适应阈值的使用规则建模为有限状态机[13](FSM),FSM有两种状态,状态0和状态1,首先检测当前帧黑色像素与前一帧的差值是否大于或等于0,若大于或等于0设定为此时为状态0并保持状态不变,否则由状态0变成状态1,在状态1时,再检测此时的差值是否小于阈值T(t)时,若小于T(t)保持状态1,并连续累积差值,否则,状态1变成状态0,差值不累积。

图11 有限状态机
基于自适应阈值黑色像素算法如下
(5)
T(t)=α*|D(t-1)|,α∈[0,1]
(6)
FSM定义如下,其中ΔN(t) 为第t帧与前一帧的黑色像素数差值,D(t-1) 为在t-1帧的累积差值,α为0到1之间的定值。
通过自适应阈值算法,如图10(c)中255帧开始差值小于0,设定为状态1,且差值小于阈值,进行连续累加差值,如图10(c)中257帧和260帧差值可以正确累计,因此第255帧到260帧可以正确判断为闭眼状态。
2.4 基于积分投影计算人眼水平投影高度和宽度比值
根据定位的人眼区域,提取人眼二值化图像,再对二值化图像进行水平投影,得到如图12所示不同状态下人眼水平投影曲线。

图12 不同状态下人眼水平投影曲线
如图12中所示,眼睛睁开时纵坐标跨度较大,横坐标峰值较小,而闭眼时纵坐标跨度较小,横坐标峰值较大,但是实际情况二者差距不大,因此通过计算人眼水平投影的高度与宽度的比值来识别眼睛状态。先计算水平投影曲线的高度h和宽度w,计算并保存h、w和h/w这3个值,分别记为H、W、K。当满足K值大于0.4时,可以定义睁眼状态,否则为闭眼状态。
2.5 SVM分类器融合多特征状态识别
SVM通过找出边际最大的决策边界,来对数据进行分类的分类器。拥有更大的边际的决策边界在分类中泛化误差较小,从而使实际样本间隔更大。通过SVM分类器来进行二分类,其中数据选取、处理、训练、测试都是基于PyCharm开发环境和OpenCV视觉库等平台进行具体实现的。
2.5.1 数据选取
本文从YawDD驾驶环境中拍摄的视频数据集[13]、ZJU眨眼数据集[14]中各选取20人,男女各20人,其中20人戴眼镜,20人不带眼镜,再从中采集4000张睁眼图像、4000张闭眼图像,同时自己采集2000张睁眼图像、2000张闭眼图像,一共采集12 000张睁眼和闭眼状态图像。
2.5.2 数据处理
首先对每个样本进行提取人脸特征点,然后通过式(4)计算眼睛纵横比值记为第一个特征值F1、由自适应阈值法得到的黑色像素累积差值记为第二个特征值F2、把水平投影高度和宽度的比值h/w记为第三个特征值F3,即对每个样本提取3个特征值,3个特征值分别对应X、Y、Z轴,对每个睁眼样本和闭眼样本都进行特征提取操作。
2.5.3 特征参数归一化
由于不同特征参数之间的量纲不同导致数值较小的特征参数在训练过程中的占比较小,需要对每个特征参数数据进行归一化处理,采用Z-score标准化方法,即求取原始参数数据的均值和标准差,再把均值和标准差进行数据的标准化处理,使处理后的均值和标准差符合正态分布,然后再进行以下转化函数
(7)
式中:x*为归一化后的值,x为原始特征值,μx为所有样本数据的均值,σx为所有样本数据的标准差。
2.5.4 模型训练即参数寻优
SVM分类器[15]可以表示为
(8)
(9)

(10)
式中:N是训练数据的总数,yi∈{-1,1} 为训练样本眼睛状态类别,-1表示闭眼状态,1表示睁眼状态,K(x,xi) 表示核函数,系数ai可以通过由线性约束的二次规划得到,常数b是偏差项。本文采取3个特征输入,通过引入核函数,支持向量机可以扩展到非线性决策面上,然后利用支持向量确定可以区分两类的超平面,来寻找让数据线性可分的高位空间。根据最小分类误差,RBF核函数分类非线性情况效果较好,故本文采用RBF核函数进行模型训练,式(9)为RBF核函数,参数γ定义单个样本的影响大小,式(10)为目标方程,w和b是模型参数,ξ参数为松弛变量,惩罚参数C是在错误分类样本和分界面简单性之间进行权衡,这两个参数的选取对预测结果的精度非常关键。我们通过分类器交叉验证法来寻找使预测结果最优的参数C和γ,从收集到的特征值中选取2000组特征值分为10组,每次选9组为训练集,剩余1组为测试集,选取的所有特征值都经过归一化处理,测试结果标签保存到对应类别中,经过寻优发现,当参数C=1.92,γ=0.9时,模型预测分类效果较好。
2.5.5 实验检测
当用SVM分类器融合校正后的特征点计算人眼的纵横比值以及人眼二值图像计算累积黑色素差值这两个特征时,得出的二维平面分类结果如图13所示,睁眼和闭眼这两种类别基本可以区分开来,但是还是有少量类别区分错误。当用SVM分类器融合校正后的特征点计算人眼的纵横比值和人眼二值图像计算累积黑色素差值以及人眼水平投影高度和宽度比值这3个特征时,在三维立体坐标系中进行分类,如图14所示,图(a)和图(b)采用了不同的角度展示分类效果,在二维平面分类错误的点在三维坐标系中得到正确的区分,分类准确率提升到97.51%。

图13 SVM二维平面分类结果

图14 SVM三维立体分类结果
通过表2可以看出,提出基于融合多特征算法可以较准确的识别眼睛的两种状态,表3为不同算法对眼睛状态的分类准确率对比,结果表明提出的SVM三维立体分类的识别方法相较于SVM二维平面分类的状态识别方法分类准确率更高,与文献[16]相比,本文算法睁眼和闭眼识别的准确率也都要更高。

表2 基于SVM融合多特征算法分类测试结果

表3 不同算法在眼睛状态分类对比
2.6 基于眼睛筛选机制的实验对比
在实际驾驶过程中,驾驶员会有多种头部姿态,当左右偏头幅度过大时,会出现一只眼睛被遮挡,这时很难准确提取双眼的特征,一旦出现一只眼睛错检,就会影响最终眼睛状态的判断,对实验结果有很大干扰。为验证头部多姿态时检测结果的准确率,以驾驶员的正前方为中心轴,头部向各个方向偏转一定角度进行双眼检测。
如图15所示,给出部分具有代表性的4种头部偏转状态实验图。当驾驶员头部偏转较小方位内,双眼检测可以达到较好效果,图(d)当头部出现极端角度时,眼睛状态检测时出现了错检,准确率会大幅下降,因此可以采用单眼检测机制,用未被遮挡的单只眼睛代替双眼检测机制。具体操作如图16所示。

图15 双眼检测示例
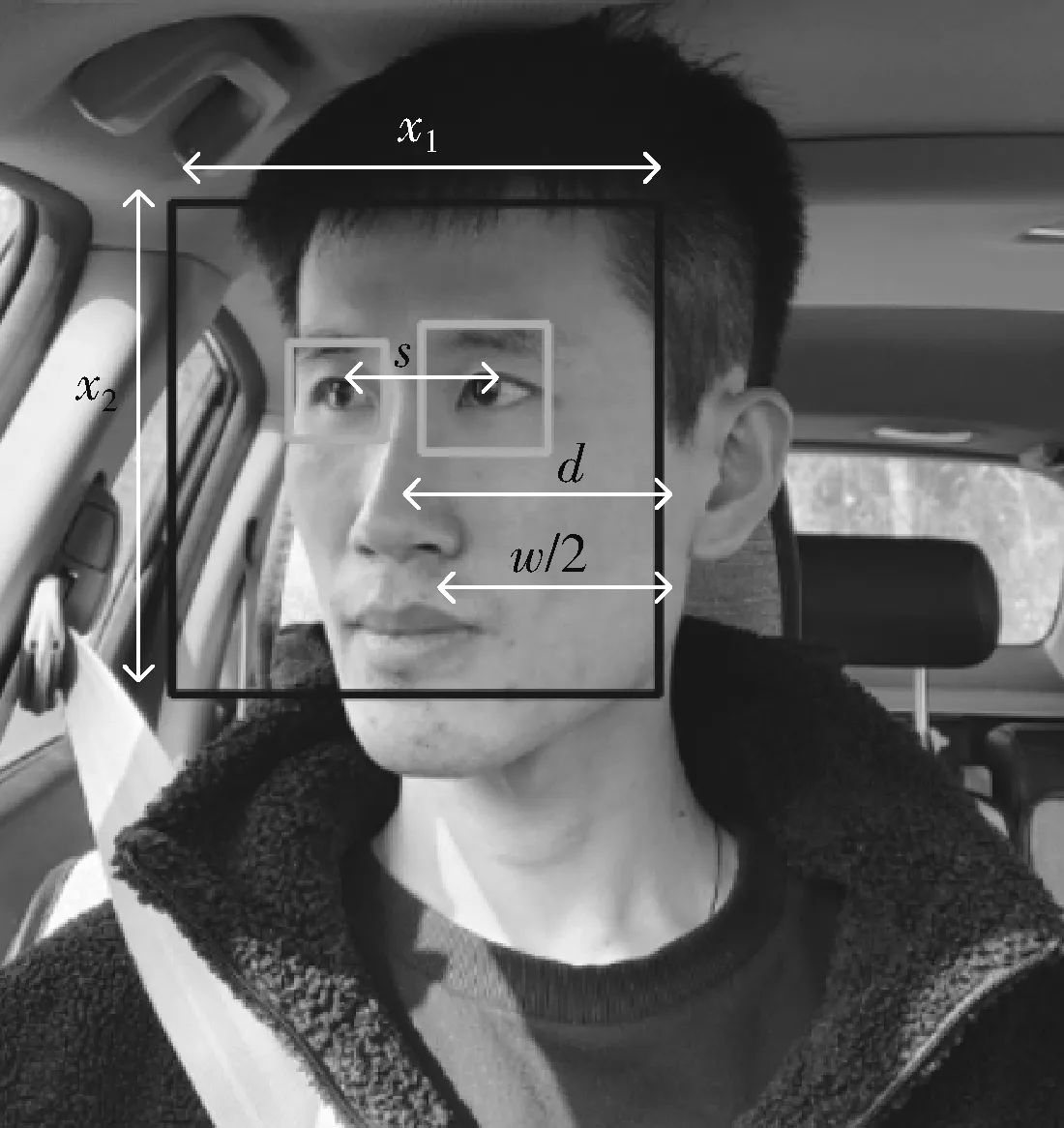
图16 眼睛筛选机制
图16中x1和x2分别表示检测框的宽和高,s表示两个瞳孔中心间的距离,d表示瞳孔连线中心点到人脸右框的距离,由于检测到的人脸大小不一,所以要对边框进行切割,提高准确率,令w=3/4x1, 当d大于w/2时只对图中右眼进行状态判断,反之只对图中左眼进行状态判断。这里测试600张人脸图像,分别选取在转动角度为-30°到30°以及转动角度为-60°到60°情况,第一组检测睁眼状态,第二组检测闭眼状态,实验部分单眼检测不戴眼镜各种转动角检测结果如图17所示。

图17 基于眼睛筛选机制单眼检测不戴眼镜示例
如图18所示,第一组检测睁眼状态,第二组检测闭眼状态,戴眼镜时单眼检测不同转动角识别效果也较好。

图18 基于眼睛筛选机制单眼检测戴眼镜示例
由表4和表5可知,单眼检测对头部适应性较好,当检测到头部大幅度偏转时采用单眼检测具有较高准确率。

表4 单眼检测不戴眼镜结果
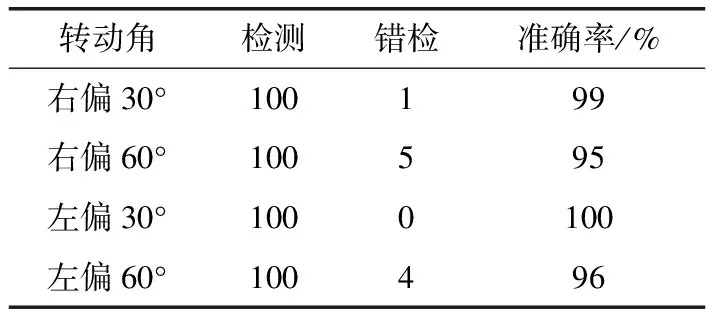
表5 单眼检测戴眼镜结果
采用YawDD视频数据集、ZJU眨眼数据集来测试单眼检测和双眼检测的准确率,各选取20组不戴眼镜,10组戴眼镜,总共从拍摄的视频中选取10 000帧图片,见表6,实验结果表明自适应单眼检测无论是在戴眼镜还是不戴眼镜情况下准确率都更高。
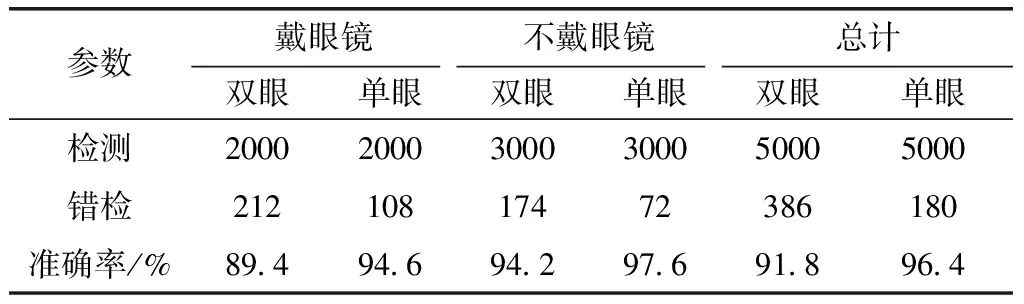
表6 单眼检测和双眼检测眼睛状态对比
2.7 疲劳驾驶检测
当在实际行驶过程中,驾驶员疲劳时会出现频繁眨眼的现象,同时眼部状态信息是最能显示疲劳状态,为此可以通过获取驾驶员眼部的状态信息来判断驾驶员的疲劳状态。本文选取基于PERCLOSE准则[17]的ECR作为眼部疲劳特征参数,ECR指检测到闭合状态时帧数与一次眨眼整个过程帧数的比率,即
(11)
式中:n为闭合状态时帧数,N为眨眼整个过程帧数,根据眼睛筛选机制判断眼睛状态方法得到参数n和N,当ECR范围在0.3到1视为疲劳状态,ECR范围在0到0.2视为正常状态,ECR范围在0.2到0.3内时介于正常和疲劳状态之间,为此对ECR这个范围的阈值进行6000组测试,测试结果见表7,当ECR为0.25时,检测的准确率最高。

表7 不同ECR值的疲劳检测准确率对比
文献[18]采用CNN回归网络检测人脸关键点,并用宽度学习对面部状态进行判别,最后,通过二级宽度学习网络融合眼睛,嘴部和头部状态预测驾驶员疲劳状态。文献[19]采用深度卷积层学习获取图像和特征,并利用相邻帧间关系预测疲劳状态,不同算法疲劳检测对比见表8,相比之下本文精度更高。根据研究发现,驾驶员正常情况下的眨眼频率为15到30 次/分钟,本文提出的方法检测每帧图片只需要0.091 s,正常平均每次眨眼0.25 s到0.3 s,所以本文算法可以检测多种姿态下的眼睛状态,同时满足实时性的要求。
3 结束语
本文提出多特征融合的疲劳驾驶检测方法,通过传统的方法进行特征提取,基于SVM分类器融合人眼的纵横比值、累积黑色素差值、人眼水平投影高度和宽度比值3个特征,再结合眼睛筛选机制进行状态检测,不仅可以适应不同光照强度、减少头部姿态和戴眼镜的干扰,而且能实时更新检测的疲劳状况,实验结果表明该方法具有较高的识别率和较强的实用性。
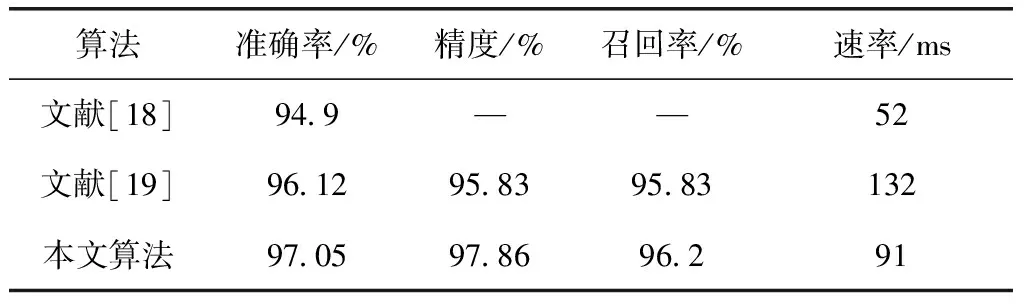
表8 不同算法的疲劳检测性能对比
猜你喜欢
气象水文海洋仪器(2021年4期)2021-12-11
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
快乐语文(2019年9期)2019-06-22
中学生数理化·八年级物理人教版(2018年11期)2019-01-31
动漫星空(2018年9期)2018-10-26
中成药(2017年6期)2017-06-13
优雅(2016年12期)2017-02-28
电影故事(2016年5期)2016-06-15
奇闻怪事(2014年5期)2014-05-13
