
基于GPU的非合作突发TDMA信号实时检测
2022-11-24 01:53吕志强
无线电工程 2022年11期
吕志强,刘 凯
(上海大学 通信与信息工程学院,上海 200444)
0 引言
海事卫星通信系统主要由同步通信卫星、移动终端、海岸地球站以及协调控制站等组成,通过一系列终端向用户提供不同宽带的网络接入、移动实时视频直播等通信能力,在移动通信领域占有越来越重要的地位。非合作通信中,接收端不知道有关发送信号的调制参数,是一种非授权接入通信方式,因此要对突发信号进行准确匹配,为后续的信号调制方式识别与解调提供基础,是非合作方获取通信内容的重要保证。研究非合作通信中高效检测识别信号是非常有价值的,如在军事通信中对敌方的情报截获,需要对大量突发信号进行高效、快速的检测;在民用领域,为保证无线电频谱管理的有效性,政府常常需要对民用信号进行检测对比。而海事卫星突发信号由于分布不均匀且信号持续时间较短,相邻的突发信号间距可能较近、数据量大,这些不利条件都增加了突发信号检测的准确度和速度。
随着对无线高速数字通信的研究和突发信号检测与同步技术等先进理论的提出,信号的检测[1]与同步根据研究方式不同可分为4大类:基于线性理论的时域、频域、时频域和基于非线性理论的微弱特征信号检测同步方法[2]。时域检测法[3]中主要有能量检测、相关检测、取样积分与数字式平均[4]等。GPU具有多个计算单元和多种内存,适合于计算量较大且计算简单的任务,众多学者已将GPU的多线程技术应用到图像处理[5-6]和卫星信号处理[7-9]等实时性要求较高的领域。
针对所研究的海事卫星信号,为解决数据量大且检测准确度低的问题,从工程实现角度出发,设计了基于GPU的双窗口能量检测和分段差分相关检测的双重检测方案。借助GPU强大的通用计算能力,挖掘并行度,从多维度线程和流架构两方面实现并行处理,通过合理地利用不同内存,设定合适的维度、块数以及块内线程数来尽量实现合并的内存访问,保证最大的内存带宽等优化方式,由CPU与GPU相互协调合作,加快了计算速度,提高了系统的整体性能。通过仿真和实际信号的测试实验表明,所提方法具有较高的检测成功率,单路速度提升约40倍。
1 系统架构设计
本文旨在研究基于GPU的非合作海事卫星信号的检测识别,非合作通信流程如图1所示。在高斯白噪声信道中,通过分析通信协议,确认突发和连续信号的传输格式等属性,利用传输帧中的独特码等条件检测不同类型的信号,计算信号的信噪比等参数。在实际工程中,需要实现多路多频点处信号的实时检测和解调,算法复杂度很高,仅用CPU无法达到理想的运行性能,于是利用GPU的并行计算能力,在CUDA架构下,利用CPU+GPU的异构模型,将整个信号检测方案按一定策略给CPU和GPU划分任务,由GPU完成多路多频点下变频的并行和双重检测算法的优化,完成信号检测后,信号数据量大大减少,然后在CPU上进行信号的频偏、相偏估计和解调处理。

图1 非合作通信流程
突发信号检测流程如图2所示,首先需要把信号采样率由Fs1变采样到目标采样率Fs2,在目标频点进行数字下变频,由于突发信号的长度和分布不同,需要进行文件头部数据的差分相关检测,滑动的距离要大于最大的突发信号长度。这是因为如果信号在读入数据开始时就一直持续存在,双窗口能量检测就会失效,会出现漏检的问题,检测的目的是宁可错检,也不漏检。如果头部并没有检测到信号,则使用双滑窗对信号进行粗检测,标记出信号的大概位置,以大概位置为中心,前后滑动的位置作为起点,分别进行独特码字的差分相关检测,当信号中的独特码和本地独特码[10]完全匹配对齐时,相关峰值最大,从而得到突发信号的准确位置。

图2 突发信号检测流程
2 突发检测算法研究
2.1 双滑动窗口能量检测法
通过设置2个连续滑动窗口,分别计算窗口的接收能量,用能量比作为判决变量。经典的双滑动窗口算法[11-13]原理如图3所示。窗口An与Bn同时向前移动,其中An与Bn分别为窗口An与Bn的采样点能量和。计算公式如下:

图3 双滑窗能量检测
(1)
(2)
式中,L为窗口长度;rn为第n个采样点的值。Mn为这2个窗口的比值,公式如下:
(3)
当Mn达到最大值Mmax时,其中参数β为参考阈值,β的取值与信噪比有关,且其大小会影响漏检与虚检概率,当Mmax大于β时便可判断信号的大概位置。滑动窗口的宽度与信号宽度有关,一般取最小信号宽度。
2.2 基于独特码的分段差分相关检测法
本文研究的是TDMA信号,精确地找到信号起点并进行保存,对后续解调至关重要。经过前面双窗口的粗略检测后,得到大概位置,以步长1为间隔左右移动后,将已知序列的独特码与偏移起点后的信号进行归一化相关,暂存所得到的相关值和对应的起点,求得最大的相关值,若大于设定阈值,则更新对应的准确起点。
通过使用CoolEdit软件查看卫星信号的时频图,存在不同长度的信号,分布在不同的频点且间隔较小,实际卫星信号时频域如图4所示。根据通信协议,确定信号的时间长度主要为5,20 ms和80,2.2 ms,可以分为帧头式、帧头帧尾式和分布式,如表1所示。

图4 实际卫星信号时频域

表1 海事卫星信号类型参数
TDMA信号帧结构如图5所示。

图5 TDMA信号帧结构
以分布式为例进行说明,分布式信号的定义为:信号的独特码数据以信号起点开始,按照通信协议中规定的标号位置,不均匀地分布在整帧信号当中。
由于多普勒频移的存在,卫星接收到固定地球站发来的信号,频谱发生偏离,而卫星转发给移动站的信号,在移动站收到后,也会产生一个频率,当频偏超过500 Hz,仅做相关检测的性能大大降低。为了减小多普勒频移对信号检测的影响,采用分段差分相关的检测方法。
分段差分相关检测算法[14]结合了直接相关检测和差分相关检测算法的优点,将接收信号和本地序列分割成了等长的子序列,又将子序列分别直接相关,子序列间相关结果进行差分求和累加。设相关符号长度L=M×N,其中子序列数为M,长度为K。本地序列C={c0,c1,…,cM-1},其中cm={cm,0,cm,1,…,cm,K-1},cm,k=cmK+k表示第m子段中第k个本地符号,经变采样[10-11]和下变频后得到复基带数据。以检测的位置为起点,按照通信协议标记位置开始取值组合,得到含噪信号为R={R0,R1,…,RM-1},其中Rm,0={rm,0,rm,1,…,rm,K-1},rm,k=rmK+k=smK+k+wmK+k,其中smK+k,wmK+k分别为采样信号中第m段子序列信号中第k个符号精确采样时刻的有用信号值、噪声值。
设recm为第m段接收信号和本地符号子序列的直接相关结果:
(4)
检测结果为:
(5)
对信号的识别结果取模值后进行峰值搜索检测,其算法流程如图6所示。

图6 分段差分相关检测算法流程
3 突发检测CUDA并行处理
3.1 数据访问的内存优化
GPU内存的访问遵循合并对齐原则[15],因为GPU是以整个线程束为单位进行调度,一个线程束包括32个线程,一个线程束访问一段连续内存时,就出现合并内存,线程束的对齐与合并内存访问模型如图7所示。

图7 内存访问模型
将参与运算的数据放到共享内存中,运算速度更快,例如计算窗口能量和时,将窗口内数据放到共享内存。信号的独特码模板放在常量内存中,当使用常量内存中的信号模板时,NVDIA硬件将把单次内存读取操作广播到每个半线程束。在半线程束中包含16个线程,是线程束中线程数量的一半,如果在半线程束中每个线程从常量内存的相同地址读取模板数据,那么GPU只会产生一次读取请求并在随后将数据广播到每个线程;如果从常量内存中读取大量数据,这种方式产生的内存流量只使用全局内存的1/16。
3.2 多维度线程优化加速
为了大幅提升检测性能,将双滑窗能量检测和基于独特码的分段差分相关检测的双重算法方案并行化处理,设计了多维度block和流架构并行优化多路多频点的检测。
双滑动窗口法主要的计算量在于每滑动一次,都要分别计算2个滑动窗口的能量和,而每次滑动时要计算的数据都是相互独立的[16],所以将算法在GPU中处理,用CUDA对其并行编程。
对于多路多频点数据的同时处理,可以在block的X维度上划分各路数据从而实现粗粒度上的并行,例如block.x0处理第1路数据,block.x1处理第2路数据,block.x(N-1)处理第N路数据;在block的Y维度上划分每一路的不同频点,例如block.y0处理第1个频点,block.y1处理第2个频点,block.y(M-1)处理第M个频点,然后在每个block上分配多个thread,每个block里所有的thread再按照放置数据的长度等进行细粒度上的并行处理,如图8所示。

图8 多路多频点CUDA并行编程模型
使每个thread处理的信号能量比的点数最多支持2 048个float类型的点,由于16 kB局部内存的限制,thread的数量等于输入的基带信号长度减掉16 kB后除以16 kB。按照输入的信号长度为2 MB,计算可得每个频点的突发数量最多允许128个,例如窗口的长度为WLEN,思路是先让每个thread计算一个窗口长度WLEN的数据能量和,并放置于共享内存中,计算完成后再让多线程去计算比值,最后找出第1个超出阈值的点进行输出,如图9所示,其中参与运算的信号数据都暂存在共享内存中。

图9 每个block处理流程
双滑动窗能量检测出信号的粗略位置后,在对应位置前后的范围进行独特码字的相关检测,检测出第1个时隙信号的精确位置,即完成TDMA信号的时隙同步。以检测出的第1个信号时隙为基础,每隔1个时隙做1次能量和差分相关检测,如果匹配到突发信号则截取输出,这就是同步跟踪过程[17]。
为了尽可能地把并行处理放到GPU中,设计了三维的block进行处理,类比双窗口能量检测的线程优化,将block的X维度作为路数,并行处理每路的数据,block的Y维度作为频点数,每路信号存在于不同的频点处,需要数字下变频后再检测,block的Z维度作为双窗口能量检测突发数量的最大值,一维thread的X维度为同步跟踪起点的搜索范围,设置为128。
分段差分相关检测GPU工作流程如图10所示。可以看到,把数据按照每一路读进内存,每一路中包含有下变频后不同频点处的数据。通过前面能量检测得到的信号粗略位置,在相关检测过程中,以能量检测的位置为基准,前后偏移64个点,分别以偏移后的位置为信号起点,偏移的点数可以根据具体GPU的性能来进行分配,但数量应为32的整数倍。这是由于设备是以整个线程束为单位进行调度[18-19],如果不把线程块上的线程数目设置成32的整数倍,则最后一个线程束中有一部分线程是没有用的,会耗损多次内存访问事务。

图10 分段差分相关检测GPU工作流程
每个新的起点分配一个线程,不同的起点处同时做差分相关检测,数据的I路和Q路存放在共享内存中,分别与模板做乘加运算,计算出相关值,在GPU中需要进行同步操作,等待不同的线程全部处理结束,判断出128个相关值中的最大值,超过规定阈值则截取保存信号,更新信号准确位置;否则,丢弃,继续下一个准确位置的检测。
考虑到一个完整的信号因为数据处理而被分割开,信号的起始点在上一段数据中,信号的结束点在下一段数据中,但可以把信号的起始点包含在缓存数据中,则在检测过程中,信号在前一数据段的检测中,判决达不到阈值而被丢弃,下一段数据中可以检测出完整的信号。
3.3 基于流处理架构优化加速
在CUDA中使用多个流并行执行可以进一步提高计算性能,线程流中可以有多个线程块,线程块中可以有多个线程。上述使用的并行处理都是线程级别的,即CUDA开启多个线程,并行执行核函数内的代码,而线程流可以处理多个函数和同一个函数的不同参数。
以整个信号检测算法为例,原本程序的3大步骤是顺序执行的:先从主机拷贝初始化数据到GPU,再在GPU上执行核函数,数字下变频滤波、双窗口能量检测以及差分匹配相关,顺序执行,最后将计算结果从GPU拷贝到CPU,进行解调。当数据量很大时,每个步骤的耗时很长,后面的步骤必须等前面执行完毕才能继续,整体的耗时相当长,当每次读入一路数据就达到几十MB时,多路读入时主机和设备间拷贝将占用上百毫秒的时间,有可能要比核函数计算的时间要多。信号检测流程处理架构如图11所示,可以将每一路数据用流来执行,每一路再执行多个频点的同时信号检测,这样也就是将上述第一维度用流来代替执行,在每个线程流中同时执行多个频点的信号检测,其余分配方式不变,流水线并发执行,性能会有很大的提升。

图11 信号检测流处理架构
4 实验结果与分析
4.1 仿真结果
仿真条件:实际的卫星信号,符号速率为33.6 kHz,采样速率为537.6 kHz,信号中心频点出现在12.5 kHz附近,数字下变频之后的信号如图12所示,信噪比为6 dB,验证使用不同数据类型进行相关检测的性能,码元/波形时域直接相关峰值如图13所示。

(a)DDC信号的实部

(a)码元时域直接相关
码元/波形时域分段差分相关峰值如图14所示。

(a)码元时域差分相关
由仿真结果可知,波形相关检测的效果更好,对噪声的抑制能力更强,分段差分相关相比于直接相关检测具有更高的峰值比,易于阈值的设定,减小误检率,即使在较低信噪比的条件下,该算法依旧能较准确地对信号起始位置进行高效、精准地定位,漏检率低,满足工程要求。
4.2 实验环境
本次实验采用的平台详细配置如表2所示。

表2 实验平台的配置
在不同的信噪比下,信号突发数恒为1 000帧的信号时,60 MB的数据包,7个检测频点,测试了单路和多路信号C代码、多维度和流架构的CUDA代码,实验加速比如表3所示。实验表明,用CUDA对检测算法进行并行优化的程序,在相同的信噪比条件下,单路速度提升约40倍,5路速度提升约60倍,10路速度提升约100倍,并且随着处理路数越多,信号检测频点越多,CUDA加速越明显,流架构的使用更进一步提升了检测性能。
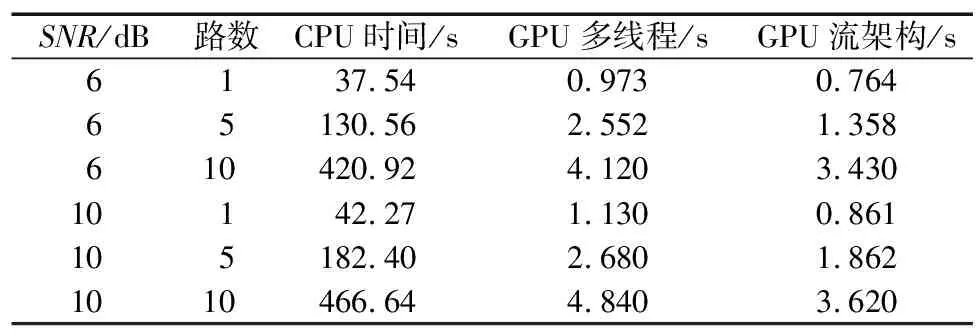
表3 实验加速比
另外,由信号的采样率537.6 kHz和数据量60 MB可计算出信号的时间约为57 s,小于程序的处理时间,所以是实时处理的,同时可实现最高64路信号的实时检测。
误检概率和漏检概率如图15和图16所示,在信噪比相同的情况下,分段差分相关检测的漏检概率与误检概率要低于直接相关检测,当信噪比达到7~8 dB时,检测方案非常实用且性能稳定,达到10 dB时具有理想的漏检概率和误检概率。
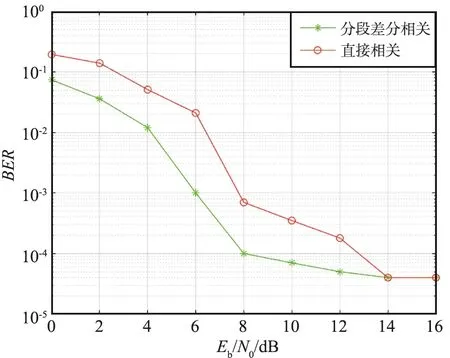
图15 误检概率

图16 漏检概率
5 结束语
本文研究了非合作通信条件下突发信号的检测算法,在GPU平台上实现了多路多频点卫星信号的检测并行化。利用分段差分的算法提高了信号检测的准确率,利用GPU的多线程结构和流架构对检测算法并行化处理,从内存访问事务和内存存取方面进一步提高了信号检测的实时性,具有极大的灵活性,今后可以使用算力更强的GPU运算,只需调整kernel函数的线程维度参数,就可以发挥设备的最大潜力,进一步提高检测性能。
猜你喜欢
数学杂志(2022年5期)2022-12-02
新世纪智能(数学备考)(2021年5期)2021-07-28
山西电子技术(2021年3期)2021-06-28
空军工程大学学报(2021年2期)2021-05-29
通信电源技术(2020年2期)2020-02-22
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
制导与引信(2018年2期)2018-11-09
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
