
机器学习耦合受体模型揭示驱动因素对PM2.5的影响
2022-11-24 12:46张忠诚冯银厂史国良
环境科学研究 2022年11期
许 博,徐 晗,赵 焕,张忠诚,高 洁,李 岳,冯银厂,史国良*
1. 南开大学环境科学与工程学院,国家环境保护城市空气颗粒物污染防治重点实验室,天津 300350
2. 中国气象局-南开大学大气环境与健康研究联合实验室,天津 300074
3. 南开大学计算机学院,天津 300350
细颗粒物(PM2.5)是大气中的重要污染物,不仅影响环境质量,也对人体健康造成伤害[1-3]. PM2.5主要受排放源、大气化学反应、气象条件等多种因素的共同作用. 首先,短时间内大量污染物排放到大气环境中会直接影响空气的质量,造成一次污染;此外,污染源排放的前体污染物(SO2、NOx、NH3等)经历多种大气化学过程会形成PM2.5的二次污染[4-7];同时,低温高湿、静风、低边界层等多种有利于颗粒物二次生成的气象条件也对PM2.5的形成、生长和去除具有重要作用[8-11]. 因此,了解PM2.5的污染特征、来源以及驱动因素对PM2.5浓度的影响对于制定污染防治措施具有重要意义.
定量识别污染物的来源是污染防控的关键. 受体模型被广泛应用于国内外颗粒物的源解析工作中[12-14],其中,正定矩阵因子分解模型(positive matrix factorization,PMF)基于污染源的排放特征可以解析出污染源对PM2.5浓度的贡献. 排放源、大气化学反应、气象条件等因素对PM2.5浓度的影响过程复杂,呈现出非线性的影响,简单的线性模型难以揭示其内在规律. 机器学习方法善于解决非线性问题,近些年逐渐被应用在大气颗粒物研究中,如Hou等[15]采用随机森林模型揭示了灰霾期间PM2.5污染的主要驱动因素. 同时,随着监测设备的完善,可以通过观测获得大量环境数据,为探究污染物排放、大气化学反应、气象条件等因素对PM2.5浓度的影响提供必要数据.基于数据驱动的机器学习方法,如决策树、随机森林、Xgboost等模型虽有良好的拟合性能,但多以数据驱动为基础,计算结果解释较差,往往难以解释实际情况. 近年来,随着夏普利加性解释(SHapley Additive exPlanation, SHAP)等可解释性方法的出现和发展,使得机器学习模型结果的可解释性得以提升. 此外,目前利用机器学习方法研究大气污染主要集中在PM2.5的预测和污染成因等方面,关于量化污染源、大气化学反应、气象条件等驱动因素对PM2.5浓度影响的研究相对较少.
基于此,该研究耦合了机器学习方法和受体模型,基于天津市在线高时间分辨率的观测数据分析PM2.5及其组分的污染特征,利用PMF模型分析PM2.5主要来源的贡献及其时间变化特征. 将受体模型的结果表征为排放源,作为机器学习方法的驱动因素,利用随机森林-SHAP模型量化排放源、大气氧化能力、气象条件等驱动因素对PM2.5浓度的影响,同时深入分析并对比了天津市启动《天津市应对新型冠状病毒感染的肺炎应急预案》一级响应期间PM2.5的主导因素及其效应,以期为PM2.5的排放控制、二次粒子的形成机制以及综合防治提供科学方法和依据.
1 数据与方法
1.1 数据来源
分析数据来源于天津市南开大学津南校区空气质量观测超级站2018年11月−2020年10月逐时在线自动监测数据.在线监测项目包含PM2.5、PM2.5化学成分(离子、元素、碳组分等)、常规气体污染物(SO2、NO2、O3、NH3、CO等)以及气象参数(相对湿度、温度、风速、风向、太阳辐射强度等). 其中,利用聚光科技公司生产的BPM-200型β射线颗粒物自动监测仪(Beta)监测PM2.5浓度,利用Thermo Fisher Scientific公司生产的在线离子色谱(URG9000D型,美国)监测PM2.5中水溶性离子(C1−、NO3−、NH4+、SO42−、Na+、K+、Mg2+和Ca2+)浓度,利用聚光科技公司生产的OC/EC分析仪(OCEC-100型)监测PM2.5中的有机碳(OC)和元素碳(EC)浓度,利用美国API T201型NOx/NH3分析仪、T101型H2S/SO2分析仪、T300型CO分析仪、T400型O3分析仪分别监测NO2、SO2、CO、O3浓度数据,气象参数数据来源于欧洲中期天气预报中心(ECMWF). 数据质量控制是保证结果准确的前提,首先在采样过程中每天对所有仪器进行检查,同时按照制造商的要求对仪器进行定期校准和过滤器更换等维护,以确保仪器正常工作. 在数据处理中该研究将化学组分浓度测量值的总和与PM2.5浓度测量值进行对比,为了筛选有效数据,美国环境保护局建议该比值的参考区间为[0.60,1.32],最终确定6 654条小时在线观测数据. PM2.5组分主要包含碳组分(OC、EC)、水溶性离子(NO3−、SO42−、NH4+、Cl−、Mg2+和Na+)、元素(Ca、K、Br、Pb、Cr、Zn、Cu、Fe、Mn、Ti、Ba、As和Si).
1.2 受体模型—正定矩阵因子分解模型(PMF)
受体模型通过在环境样品和污染源之间建立源与化学质量浓度的线性关系式,定量解析各污染源类对污染物的贡献,PMF模型是受体模型常用的模型之一[16-17]. Paatero等[18]在1993年提出PMF模型,随后经过对PMF模型不断地改进和完善,逐渐在大气源解析领域得到广泛应用. PMF模型将在线观测数据矩阵分解,识别污染源以及估算污染源对环境浓度的贡献.
1.3 机器学习方法
1.3.1随机森林模型
Breiman[19]在2001年提出随机森林模型. 随机森林模型通过自助法(bootstrap)重采样技术,从在线观测数据集中有放回地随机抽取一定量的数据形成一个全新的数据集,然后生成一颗决策树,多次重复上述过程,生成一定数量的决策树组成随机森林. 为防止模型过拟合,随机森林通过十倍交叉验证的方法将数据划分为训练集和测试集. 训练集训练模型,测试集对模型进行验证,用决定系数(R2)和均方根误差(RMSE)来验证模型性能.
1.3.2SHapley Additive exPlanation (SHAP)方法
随机森林模型通过调整参数实现高精度的预测,由于随机森林是一个“黑箱模型”,模型的结果不能被充分利用,导致模型的可解释性差,不利于深入探究PM2.5和驱动因素的关系. 因此,该研究将随机森林模型和SHAP方法结合,深入量化不同因素与PM2.5浓度的非线性关系. 自Lundbegr在2017年提出SHAP方法以来,其在模型解释性领域得到了广泛应用[20-22]. SHAP是python中一个解释模型的包,可以解释机器学习模型的结果[23]. SHAP方法基于博弈论最优Shapley值(合作博弈的贡献分配方法)来解释个体预测的方法,通过计算变量的边际贡献,分析在某一个样本的预测过程中变量对PM2.5的影响,计算公式:
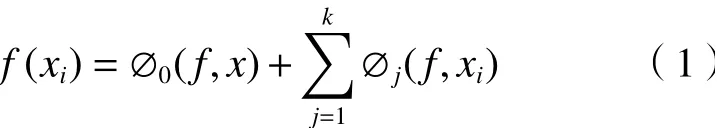
式中:f(xi)为模型输入的第i个样本的预测值,如PM2.5浓度,μg/m3;xi为输入变量,如驱动因素;∅j(f,xi)为模型计算得到的第i个样本中第j个变量对预测值的SHAP值,即对预测值(如PM2.5浓度)的贡献或影响,μg/m3; ∅0(f,x)是为模型输出的期望值,代表整个模型的基准,μg/m3.
2 结果与讨论
2.1 细颗粒物及其化学组分的污染特征
观测期间,PM2.5及其化学组分浓度的变化趋势如图1所示. 由图1(a)可见,观测期间PM2.5平均浓度为(45.65±38.28)μg/m3, 变化范围为3.21~291.80 μg/m3.PM2.5中水溶性离子占比最高,表明二次无机离子对PM2.5的生成起到重要的作用. NO3−、NH4+、SO42−的占比分别达24.25%、13.45%、11.82%,占PM2.5总浓度的49.52%,其中NO3−是主要的二次无机离子. OC和EC也是PM2.5的重要组成,占比分别为8.43%和4.89%;与离子、碳组分相比,元素占比较低,其中K、Fe和Ca的占比分别为1.21%、1.20%、0.71%.
PM2.5浓度具有季节性变化特征,该研究根据天津市集中供暖的特点将观测期间分为采暖季(11月−翌年3月)和非采暖季(4−10月),分析PM2.5及其化学组分浓度的季节性变化趋势. 由图1(b)可见,PM2.5浓度有季节性差异,采暖季PM2.5的平均浓度为(58.22±48.37) μg/m3,高于非采暖季〔(37.45±25.47)μg/m3〕,表明冬季采暖对PM2.5浓度有较大影响.2019−2020年采暖季PM2.5平均浓度〔(53.53±45.44)μg/m3〕小于2018−2019年采暖季〔(65.31±51.72)μg/m3〕,降幅为18%,一定程度上反映了大气污染综合治理措施的有效性. 由图1(c)可见,NO3−、SO42−和NH4+是PM2.5中主要的水溶性无机离子,观测期间NO3−、SO42−和NH4+的浓度与PM2.5浓度的相关系数分别为0.87、0.82和0.90,NO3−、SO42−和NH4+的浓度与PM2.5浓度在时间趋势上有相同的规律,即三者平均浓度在采暖季高于非采暖季. NO3−、SO42−和NH4+在采暖季的平均浓度分别为(13.30±12.28)(6.09±6.72)和(6.88±6.16) μg/m3. 与2018−2019年采暖季相比,在2019−2020年采暖季NO3−、SO42−和NH4+平均浓度均出现下降,分别下降了5%、18%和25%. 由图1(d)可见,OC、EC和所有元素在采暖季的平均浓度分别为(4.89±4.23)(2.42±2.09)和(3.69±3.01)μg/m3,均高于非采暖季〔分别为(3.12±2.49)(2.10±1.66)和(3.36±2.46)μg/m3〕. 与2018−2019年采暖季相比,在2019−2020年采暖季OC、EC和所有元素的平均浓度也大幅下降,分别下降了45%、21%和23%.

图 1 观测期间PM2.5及其化学组分浓度的时间变化趋势Fig.1 The time series of PM2.5 and chemical species concentrations during the measurement campaign
此外,该研究分析了2020年初新冠肺炎疫情期间颗粒物及气态污染物的变化趋势及同比变化情况.由图1(e)(f)所见,2020年1月24日,天津市启动《天津市应对新型冠状病毒感染的肺炎应急预案》一级响应,2月9日后开始逐渐复工复产. 天津市一级响应期间,PM2.5和O3的平均浓度分别为85.32和35.14 μg/m3,比2019年同期增加了52%和53%;NH3平均浓度为9.95 μg/m3,降幅(40%)最大;NO2和SO2的平均浓度分别为34.83和5.83 μg/m3,同比分别减少22%和13%.
2.2 PM2.5源解析特征
2.2.1PM2.5的污染源识别
基于2018年11月−2020年10月的在线观测数据,利用PMF模型对PM2.5的来源进行解析. 该研究尝试使用3~10个因子对PM2.5分别进行解析,当因子数为6时,Qactual/Qtheory(Qactual为通过PMF模型的计算值,Qtheory为通过观测样本数、化学组分个数和因子数的计算值)为1.49 ,结合当地的污染源实际情况,最终确定6个因子来进行计算. 通过模型计算,大部分组分的残差值在−3~3之间,并且结果稳定,表明结果合理. 6类因子对不同化学组分的贡献率如图2所示. 由图2可见:因子1中NO3−、SO42−和NH4+等二次无机离子的载荷较高,OC也有一定的贡献,可识别为二次源[12];因子2中OC、EC占比相对较高,可以识别为燃煤源;因子3主要包含Zn、Mn、Cu等无机元素,Zn和Cu为机动车润滑油的主要添加剂,同时对EC和OC也有一定贡献,可以识别为机动车排放源;因子4中特征组分为Ca等地壳元素,可以识别为扬尘源,扬尘受人类活动影响较大,具有多组分混合的特征,该因子中较高的EC可能来自道路扬尘;因子5中Fe等金属元素贡献相对较高,可以识别为工业源;因子6中OC和K的载荷高,可以识别为生物质源.
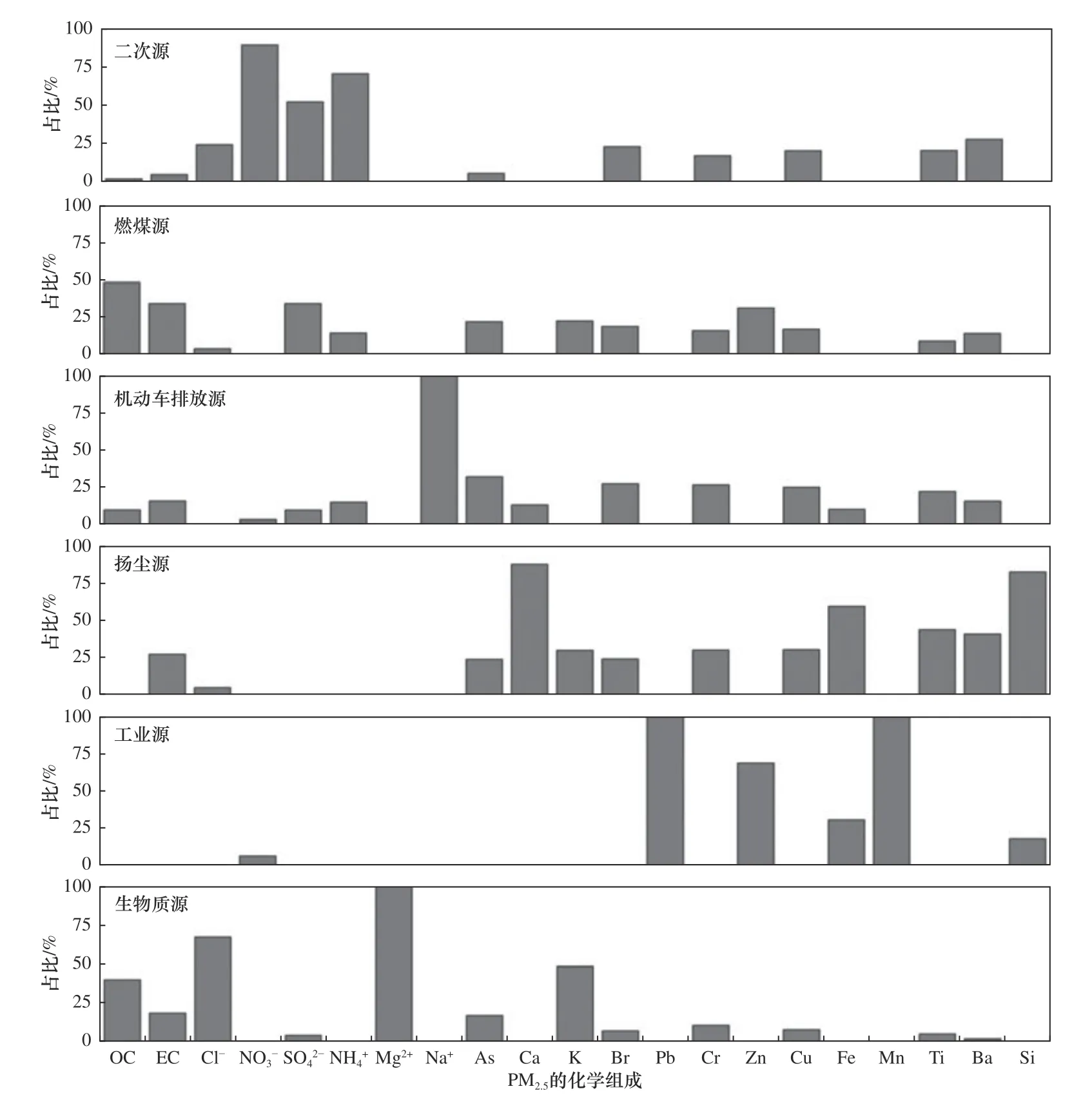
图 2 PMF模型解析的PM2.5污染源成分谱Fig.2 The factor profiles for PM2.5 derived from PMF model
PMF的源解析结果如图3所示. 由图3(a)可见:观测期间二次源是PM2.5的重要来源,对PM2.5浓度的贡献为20.41 μg/m3,贡献率为44.7%;其次是燃煤源,对PM2.5浓度的贡献为10.77 μg/m3,贡献率为23.6%;机动车排放源对PM2.5浓度的贡献为5.05 μg/m3,贡献率为11.0%;扬尘源对PM2.5的浓度贡献为4.54 μg/m3,贡献率为9.9%;生物质源对PM2.5浓度的贡献为3.29 μg/m3,贡献率为7.2%;工业源对PM2.5浓度的贡献为1.64 μg/m3,贡献率为3.6%.

图 3 观测期间污染源对大气PM2.5的贡献情况Fig.3 The contribution of sources to ambient PM2.5 during the measurement campaign
2.2.2PM2.5源贡献的时间变化特征
污染源对PM2.5贡献的季节性变化趋势如图3所示. 由图3(d)可见,观测期间,二次源为首要污染源,其对PM2.5浓度的贡献范围在0~185 μg/m3之间,采暖季二次源对PM2.5浓度的贡献率较高,其中2018−2019年采暖季和2019−2020年采暖季贡献率分别为42.9%和52.9%,贡献值分别为27.7和28.3 μg/m3. 采暖季发生多次重污染事件,重污染期间平均风速为0.9 m/s,相对湿度为75%,边界层高度为287 m,静稳天气不利于污染物的扩散,高湿有利于污染物的二次液相生成. 随着温度升高,非采暖季二次源对PM2.5浓度的贡献率下降,2019年非采暖季和2020年非采暖季其贡献率分别为39.7%和44.9%,贡献值分别为14.2和16.7 μg/m3;燃煤源对PM2.5浓度的贡献范围在0~116 μg/m3之间. 由于天津地区采暖季有集中供暖,采暖季燃煤源对PM2.5浓度的贡献率(26.9%)高于非采暖季(21.5%),贡献值分别为16.4和7.7 μg/m3;机动车排放源对PM2.5浓度的贡献范围在0~28 μg/m3之间,由于机动车源的排放强度比较稳定,机动车源对PM2.5浓度的贡献率和贡献值没有明显差异. 然而,由于新冠肺炎疫情的影响,在管控期间居民多居家办公,道路上机动车数量骤减,2019−2020年采暖季机动车排放源对PM2.5的贡献率(2.4%)较低,贡献值为1.4 μg/m3;扬尘源对PM2.5浓度的贡献范围在0~32 μg/m3之间. 由于天津春季和秋季干燥多风,扬尘源对PM2.5浓度的贡献率存在季节性差异,在非采暖季(12.3%)高于采暖季(6.6%);生物质源对PM2.5浓度的贡献范围在0~52 μg/m3之间,贡献率有季节性差异,在采暖季(9.4%)高于非采暖季(5.4%);工业源对PM2.5浓度的贡献范围在0~17 μg/m3之间,工业源的排放强度相对稳定,对PM2.5浓度的贡献值和贡献率没有明显差异.
此外,该研究计算了天津市2020年新冠肺炎疫情一级响应期间PM2.5的源解析结果及同比变化情况,结果如图3(b)(c)所示. 一级响应期间(2020年1月24日−2月9日),天津市二次源对PM2.5浓度的贡献率为46.3%,同比增加19.2%,超过燃煤源成为首要污染源,此时PM2.5二次生成大幅增长;机动车排放源对PM2.5浓度的贡献率同比减少13.3%,这是由于一级响应期间路面上行驶的车辆骤减,导致贡献率同比大幅减少.
2.3 机器学习耦合受体模型量化驱动因素对PM2.5的影响
2.3.1驱动因素的重要性分析
PM2.5污染主要受到排放源、大气化学反应、气象条件等多种因素的共同作用,是一个复杂的过程[24-26]. 机器学习方法善于处理非线性问题,能够基于数据变化规律建立性能较好的模型,从而量化影响因素对PM2.5浓度的影响. 机器学习包含多种算法,随机森林算法是机器学习最常用的算法之一,在环境领域得到广泛应用[27-30]. 该研究利用随机森林算法探究排放源、大气氧化能力、气象条件等驱动因素对PM2.5浓度的影响. 该研究将PM2.5浓度作为预测值,同时基于PM2.5的生成过程,选择主要的影响因素.受体模型解析了污染源对PM2.5浓度的贡献,该研究将一次排放源对PM2.5浓度的贡献值表征为排放源,作为随机森林算法的驱动因素,实现机器学习方法和受体模型的耦合;总氧化剂Ox(Ox=NO2+O3)浓度代表大气氧化性[31-33],将大气氧化性作为衡量大气氧化能力的指标之一;光化学反应系数(温度与表面太阳净辐射的乘积)代表光化学活性[34],将光化学活性作为衡量大气氧化能力的指标之一;通风系数(风速与边界层高度的乘积)通常用来表征大气的扩散能力[35-37],同时增加相对湿度、大气压等气象要素,作为气象条件驱动因素的指标. 该研究共筛选6个要素作为影响因素纳入随机森林模型. 此外,为深入分析影响因素变化对PM2.5浓度的影响,该研究在随机森林模型的基础上进一步利用SHAP算法量化各因素对PM2.5浓度的影响,其中SHAP平均值代表变量的重要性,将各变量的SHAP平均值归一化代表变量对PM2.5浓度的影响程度. 通过随机森林-SHAP模型的计算,模型的性能指标R2=0.77、RMSE=18.55,表明构建的模型较为理想. 整个观测期间驱动因素的重要性如图4所示. 由图4可见:排放源驱动因素的SHAP平均值为20.41 μg/m3,对PM2.5浓度的影响程度为54.3%,高于其他变量,表明PM2.5浓度受排放源的影响较大;气象条件驱动因素对PM2.5浓度的影响程度为32.4%,其中相对湿度是主导的气象要素,其SHAP平均值为5.88 μg/m3,影响程度为15.6%,特别是在夜间,相对湿度与PM2.5浓度有较强的正相关性.由于二次无机气溶胶具有高度的亲水性,相对湿度通过气溶胶含水量影响颗粒物的液相生成以及吸湿性增长. 此外,大气压的SHAP平均值为5.06 μg/m3,对PM2.5浓度的影响程度为13.5%. 通风系数的SHAP平均值为1.24 μg/m3,对PM2.5浓度的影响程度为3.3%,通风系数代表单位时间内污染物排放到环境空气后被稀释的潜在体积,其影响效应较小可能是因为重污染期往往处于静稳天气. 大气氧化能力驱动因素对PM2.5浓度的影响程度为13.3%,其中光化学反应系数的SHAP平均值为2.59 μg/m3,对PM2.5浓度的影响程度为6.9%,其影响PM2.5的光化学反应. 大气氧化性的SHAP平均值为2.41 μg/m3,对PM2.5浓度的影响程度为6.4%,其影响气态污染物的氧化.
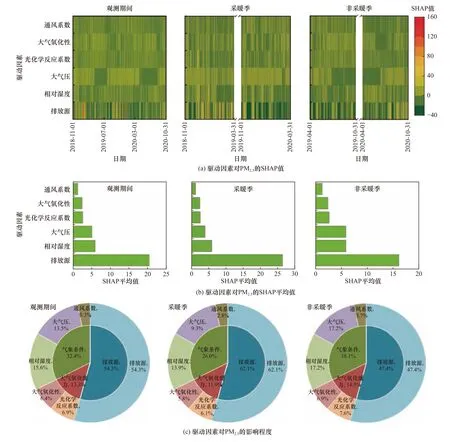
图 4 基于随机森林-SHAP模型的驱动因素对PM2.5浓度的影响程度Fig.4 The impact of driving factors on PM2.5 concentration from the random forest-SHAP model
该研究进一步对比分析了采暖季和非采暖季驱动因素的重要性,结果如图4所示. 由图4可见,采暖季和非采暖季各驱动因素对PM2.5浓度的重要性在排序上没有变化,但驱动因素对PM2.5浓度的影响程度有所不同. 采暖季排放源的SHAP平均值为26.44 μg/m3,对PM2.5浓度的影响程度达62.1%,明显高于非采暖季(排放源的SHAP平均值为16.12 μg/m3,影响程度为47.4%). 然而,采暖季大气压的SHAP平均值为3.96 μg/m3,对PM2.5的影响程度为9.3%,明显小于非采暖季(大气压的SHAP平均值为5.85 μg/m3,影响程度为17.2%).
2.3.2驱动因素变化对PM2.5浓度的影响
该研究进一步计算了观测期间各驱动因素变化对PM2.5浓度的影响,如图5所示:在观测期间,当排放源贡献低于90 μg/m3时,敏感性曲线呈上升趋势,表明PM2.5浓度随排放源贡献的增加而升高;当排放源贡献高于90 μg/m3时,对PM2.5浓度的影响有限.相对湿度的变化对PM2.5浓度有正向影响,当相对湿度低于40%时,对PM2.5浓度的影响不明显,可能由于环境干燥不利于PM2.5的生成;当相对湿度范围在40%~90%之间时,PM2.5浓度有明显增高趋势,可能由于颗粒物通过吸收水分形成湿界面,促进气态污染物在颗粒物表面的非均匀反应;当相对湿度高于90%时,PM2.5浓度下降,可能由于在高湿的环境中湿沉降对大气冲刷导致PM2.5浓度下降. 当大气压低于100.287 kPa时,敏感性曲线呈下降状态,表明PM2.5浓度随大气压的升高而降低;当大气压范围在100.287~102.325 kPa之间时,敏感性曲线上升,表明PM2.5浓度随大气压的升高而升高;当大气压高于102.325 kPa,敏感性曲线呈水平状态,此时PM2.5浓度与大气压相关性较弱. 通常情况下,当区域处于高气压场时大气在垂直方向更加稳定,会阻碍污染物的扩散;当区域处于低气压场时大气气流上升,有利于污染物扩散. 大气氧化性的变化对PM2.5浓度有正向影响,大气氧化性加速了气态污染物生成二次污染物的速率. 当光化学反应系数低于28 000时,敏感性曲线呈上升趋势,表明PM2.5浓度随光化学反应的升高而升高;随着光化学反应系数的升高,PM2.5浓度趋于稳定. PM2.5浓度随通风系数的变化不明显.
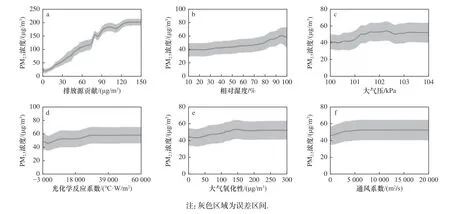
图 5 观测期间驱动因素的变化对PM2.5浓度的影响Fig.5 The effect of driving factors on PM2.5 concentration during the measurement campaign
3 结论
a)观测期间PM2.5浓度的变化范围为3.21~291.80 μg/m3,平均浓度为(45.65±38.28) μg/m3. PM2.5化学组分中水溶性离子占比最高,平均值为49.52%;其次是OC、EC,占比分别为8.43%和4.89%;元素占比相对较低,其中K、Fe和Ca元素的占比分别为1.21%、1.20%、0.71%. 采暖季PM2.5和化学组分的浓度均高于非采暖季.
b)使用受体模型解析PM2.5的来源及其贡献,发现观测期间二次源的贡献率为44.7%,燃煤源的贡献率为23.6%,机动车排放源的贡献率为11.0%,扬尘源的贡献率为9.9%,生物质燃烧的贡献率为7.2%,工业源的贡献率为3.6%. 新冠肺炎疫情一级响应期间,天津市二次源的贡献率同比增加19.2%,机动车排放源的贡献率同比减少13.3%.
c)利用随机森林-SHAP模型量化排放源、气象条件、大气氧化能力等驱动因素对PM2.5浓度的影响,结果表明,在观测期间排放源对PM2.5浓度的影响程度为54.3%,高于其他驱动因素;气象条件对PM2.5浓度的影响程度(32.4%)次之,其中相对湿度、大气压和通风系数等气象条件对PM2.5浓度的影响程度分别为15.6%、13.5%和3.3%;大气氧化能力对PM2.5浓度的影响程度为13.3%,其中光化学反应系数和大气氧化性对PM2.5浓度的影响程度分别为6.9%和6.4%. 在采暖季和非采暖季,各驱动因素对PM2.5浓度的重要性在排序上没有差别,然而驱动因素对PM2.5浓度的影响程度有所不同.
猜你喜欢
戏曲研究(2022年1期)2022-08-26
湘潮(上半月)(2021年10期)2021-12-02
云南档案(2020年4期)2020-12-06
军事运筹与系统工程(2020年2期)2020-11-16
人大建设(2020年3期)2020-07-27
电子制作(2018年12期)2018-08-01
军事运筹与系统工程(2018年3期)2018-03-26
中国科技纵横(2015年6期)2015-03-27
中国火炬(2011年7期)2011-07-25
卷宗(2011年9期)2011-05-14
