
黑龙江省2025年粮食产能优化分析
2022-11-23 11:51:04刘宝海李晓军高世伟吴立成肖明纲
中国农学通报 2022年28期
刘宝海,李晓军,高世伟,吴立成,肖明纲
(1黑龙江省农业科学院生物技术研究所,哈尔滨 150028;2黑龙江省作物与家畜分子育种重点实验室,哈尔滨 150028;3黑龙江省发展规划研究所,哈尔滨 150030;4黑龙江省农业科学院绥化分院,黑龙江绥化 152052)
0 引言
中国是一个农业大国,也是一个人口大国[1]。粮食是关乎国计民生的物质基础,也是国家社会稳定的基石,是实施乡村振兴战略的首要任务,粮食安全状况的任何变化不仅影响本国,也具有广泛的世界效应[1-4]。目前,中国粮食安全面临很多挑战,如产量增速放缓,国际粮食贸易中中国粮食进口量逐年上升,面临水、耕地质量资源约束越来越明显等[5]。因此,深入实施“藏粮于地、藏粮于技”战略,优化粮食生产布局,合理利用耕地资源,创新突破种子单产,对保障中国粮食安全生产和农业可持续发展具有重要现实意义。
黑龙江省是中国最大的粮食生产基地和商品粮输出基地,黑龙江2020年粮食产量754.1亿kg,实现“十七连丰”,连续10年领跑全国,其粮食总产量、商品量和调出量分别约占全国的1/9、1/8和1/3[6],粮食安全“压舱石”作用彰显。2010—2020年玉米、水稻、大豆合计种植面积占全国比例稳定在11.1%~12.4%[7-9],这3种作物种植面积占全省比例达93.0%以上,3年均值为96.0%,其中2020年最高,为98.3%,是黑龙江省名副其实的“三大作物”,其平均单产分别较全国约增加-0.1%、3.9%和-2.0%,其中2020年较全国增加5.4%、6.2%和-3.8%[10-11]。黑龙江省作为国家粮食供给的重要力量,在找准“三大作物”种植面积、单产优势与差距基础上,如何科学优化种植布局,是提升粮食综合生产能力、建成农业强省的必要举措。
已有诸多学者对粮食产能的预测进行了研究,主要包括3个方面:(1)利用粮食产量历史数据建立数学统计模型,如时间序列模型[12]、灰色预测模型[13]、指数平滑模型[14]等;(2)通过粮食作物生长状况观察及其生长环境分析,对产量进行模拟分析,如气象产量模型[15]、遥感技术模型[16]等;(3)采用遗传法的数据驱动粮食产量预测模型,如人工神经网络模型[17-19]、基于优化灰色模型[20]等。遗传算法是一种通过模拟自然进化过程搜索最优解的方法,类型众多,其中混合遗传算法是遗传算法与其他智能算法结合形成的,包含遗传-蚁群混合算法、遗传-粒子群混合算法、遗传-神经网络混合算法[21]及浮点数编码的遗传算法(FGA)[21]等。采用FGA遗传算法求解极值函数的全局优化问题,优化精度较高,实用有效[22],但多用于电站机组[23]、给水管网[24]、景观特征[25]、颅像叠加[26]等优化问题,而在粮食产能优化求解方面鲜有报道。熵权法是一种应用较广的客观权重赋权方法[27],基于熵权综合评价方法,可对各项指标求解方案进行综合评价优选,表现为值越大越优[28]。熵权综合评价法多用于水生态安全[29]、种质资源评价[30]、育种后代选择[31],而在粮食产能综合评价方面鲜有报道。目前,基于FGA遗传算法与熵权综合评价法的粮食产能优化分析还未见报道。
基于此,本研究将以黑龙江省“十四五”规划中粮食产能极值及作物种植面积结构目标为约束性指标,采用FGA与熵权评价方法,利用统计年鉴及网络公开数据,通过调整作物种植面积和单产的变化提出3种假设,探寻不同假设条件下的作物种植优化方案,以期为黑龙江省粮食作物种植布局和安全生产提供科学支撑。
1 项目区概况与数据来源
1.1 项目区概况
黑龙江省位于中国东北边陲,南起北纬43°26′,北至北纬53°34′,东经121°10′—135°05′,地处寒温带和中温带,湿润区、半湿润区和半干旱区3个分区,属大陆型季风气候区,平均气温由北向南为-5~4℃,全省≥10℃积温为1900~2800℃,无霜冻期平均100~150天,南北跨越5个积温带,地缘辽阔、地貌多样、自然资源丰富。作为中国重要的粮食主产区和最大的商品粮生产基地,下辖13市,2020年耕地面积1443.8万hm2,粮食产量754.1亿kg,主要种植玉米、水稻、大豆作物。生态环境区域差异特性使得省内各地区农业发展水平不尽相同。作物品种生物特性表达具有极强的生态环境选择性,品种的生态适应性将直接影响其生产应用效果。
1.2 数据来源
本研究基础数据来源于《中国统计年鉴》[7]、《黑龙江统计年鉴》[9]和有关电子文献[8,10-11]。所选取指标变量数据主要包括2011—2020年中国和黑龙江省玉米、水稻、大豆的产量、面积和单产。
2 研究内容与方法
2.1 研究内容
本研究以《黑龙江省国民经济和社会发展第十四个五年规划和二〇三五年远景目标纲要》[32]中提出的“到2025年,粮食综合生产能力8000亿kg”、“粮食作物种植面积稳定在1433万hm2以上”和“水稻种植面积400万hm2左右,玉米种植面积600万hm2左右,大豆种植面积367万hm2左右”作为决策目标,建立函数模型,对影响产量极值的玉米、水稻、大豆种植面积及单产数据进行计算分析评价,从而确定最佳优化方案。
2.2 建立模型
2.2.1 构建目标变量关系函数 如式(1)所示,以产量为因变量,面积、单产指标值为自变量的关系函数。

式中,f(xλ)表示产量函数,xλ为待优化自变量,λ=1,2,3,…,κ,其中λ为第κ个待寻优变量,a为截距,b为偏回归系数。
2.2.2 建立产量极值优化函数模型 如式(2)所示,以解决产量最大值的面积、单产指标全局优化问题函数。

式中,xλ∈[lbλ,ubλ],lb、ub分别为下限和上限约束值。
2.2.3 评价产量极值优化解集 利用熵权综合评价法[27]对某些极值优化解集进行评价,具体步骤如下。
(1)设定m个评价方案、n个评价指标,各指标原始数据矩阵表示如式(3)。

式中,rij表示第i个评价方案第j个指标值。
(2)计算标准化数据如式(4),确定如式(5)的标准化数据矩阵P。

式中,Pij表示第i个评价方案第j个指标综合标准化值,m为评价单元数量。
(3)计算评价指标信息熵,可表示为式(6)。

式中,ei表示第j个指标的信息熵。
(4)计算各指标权重,即熵权,可表示为式(7)。

式中,ωi表示第j个指标的权重(熵权)。
(5)计算各指标隶属函数价值系数值,bij如式(8)(指标均为正效益)、式(9()指标均为负效益)所示,从而确定功效矩阵B[式(10)]。

式中,bij表示第i个评价方案第j个指标的价值系数值。
(6)对Pareto解集方案综合评价,计算如式(11)所示。

式中,CIi表示第i个方案综合评价指数值。
2.3 统计分析
利用IBM SPSS Statistics 25.0软件对采集的指标变量平均值数据进行回归线性分析,建立目标变量关系函数式(1)。
采用浮点数编码遗传算法(FGA)[21],利用Matlab编程运行式(2),按照浮点数编码遗传算法步骤(1)~(7),求解极值优化函数。步骤如下:(1)将指定范围内的浮点数排列在一起成为一个个体,随机产生Pop(群体尺寸)个这样的个体作为初始种群;(2)计算每一个体的目标函数值并对这Pop个函数值由大到小排序,记录最优个体(;3)淘汰较小函数值对应的个体并分别替换成相应较大函数值对应的个体(;4)对这Pop个个体随机两两配对,按一指定概率进行式的交叉操作;(5)对每一个体中的每一参数,按一指定概率进行式变异操作;(6)删除种群中一任意个体并替换成步骤(2)中记录的最优个体;(7)若满足收敛条件则输出最优解并退出,否则转向步骤(2)。
利用Matlab(R2017a)软件编辑源代码,运行式(3)~(10),计算极值优化解集的综合评价指数值(CIi)。
3 结果与分析
3.1 粮食产量与作物耕种面积、单产函数关系
选择2011—2020年玉米、水稻、大豆种植面积、单产及3个作物总产量数据值进行统计分析(表1)。从不同作物间看,单产方差值为1057.221达到差异极显著水平(P<0.01),大豆单产均值为1818.5 kg/hm2,小于玉米的6036.6 kg/hm2和水稻的7101.9 kg/hm2,且达差异显著水平(P<0.05);面积方差值为70.955达到差异极显著水平(P<0.01),大豆面积均值为339.9万hm2,小于水稻的381.6万hm2,但未达差异显著水平(P>0.05),玉米面积均值为619.9万hm2,大于大豆和玉米且达差异显著水平(P<0.05)。从同一作物年际间看,10年间变异离散程度为水稻单产(2.09%)<大豆单产(3.19%)<水稻面积(4.34%)<总产量(7.12%)<玉米单产(7.34%)<玉米面积(10.28%)<大豆面积(21.45%),7个变异系数值中大豆面积表现出较大离散属性,其他变量数值范围2.09%~10.28%。以上表明,不同作物间种植面积、单产表现出的差异性极显著水平(P<0.01),以及同一作物年际间种植面积、单产、总产量表现出的差异性与相对稳定性,将有利于目标函数变量参数充分表达,也有利于保障目标函数模型构建的可靠性。
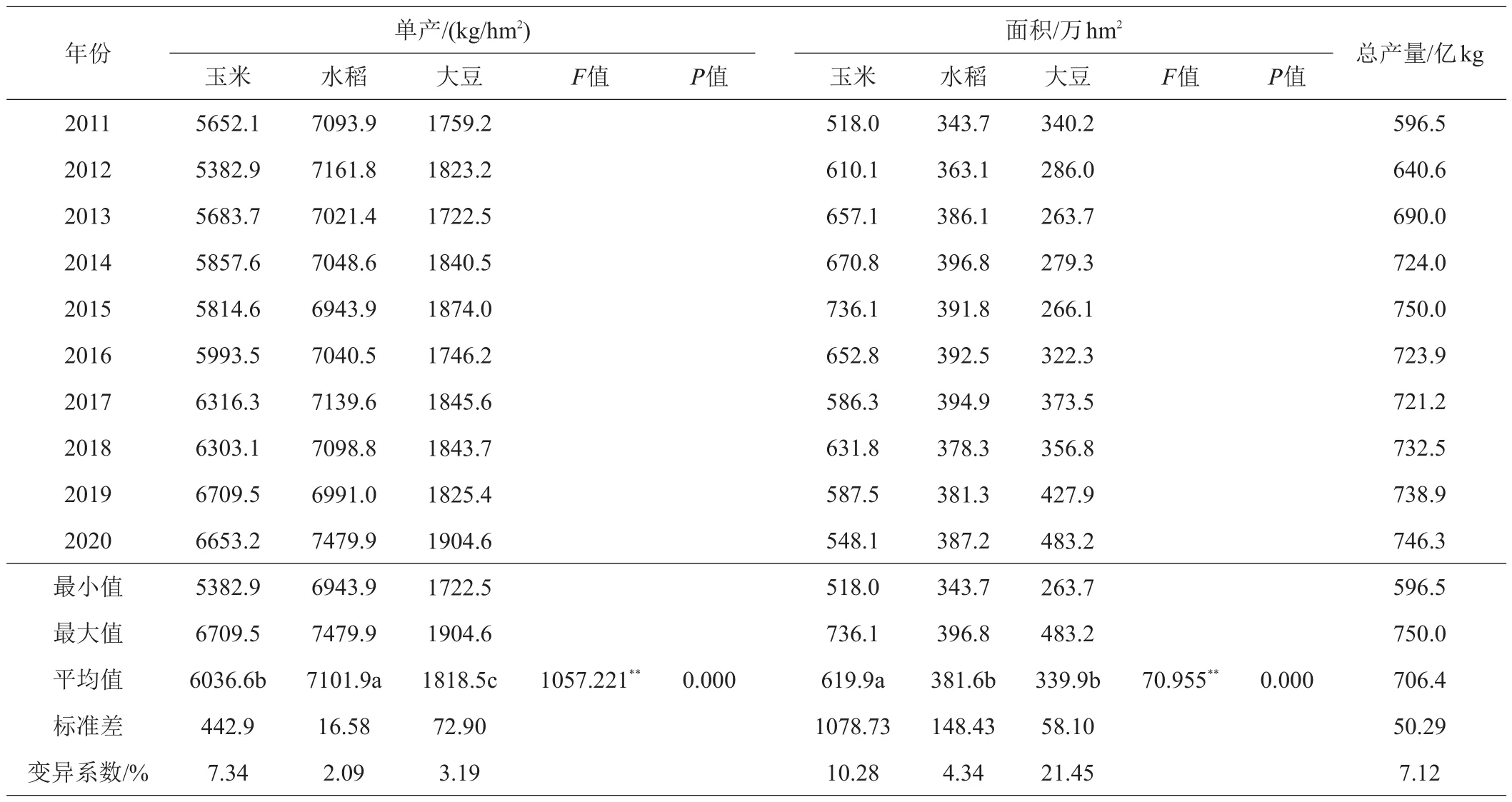
表1 玉米、水稻、大豆种植面积、单产及总产量统计分析
采集表1相关数据值,利用SPSS线性回归计算分析,以总产量(Y)为因变量,玉米面积(x1)、玉米单产(x2)、水稻面积(x3)、玉米单产(x4)、水稻单产(x5)及大豆单产(x6)为自变量,构建多元回归线性函数模型[式(12)],其整体方差检验F值为2391.353,P值为0.000,达差异极显著水平(P<0.01),解释因变量变化百分数R2为0.999。同时根据函数模型[式(10)]对总产量进行计算预测(表2),相对误差在0.19%~0.56%,平均相对误差为0.39%,实际产量与预测产量方差分析F值为0.014,P值为0.908,未达到差异显著水平(P>0.05)。以上说明,构建的预测函数模型精准度良好,可以用于预测未来5年(2021—2025年)玉米、水稻、大豆3个作物总产量。

表2 2011—2020年总产量预测分析 亿kg

3.2 粮食产能极值下作物种植面积、单产优化
根据式(2)设定变量参数值。其中,基于2011—2020年其他作物(除玉米、水稻、大豆外作物)平均产量16.2亿kg,以及黑龙江省“十四五”粮食产能800亿kg目标,确定玉米、水稻、大豆产量值(Y)783.8亿kg;面积、单产变量下限、上限值参考黑龙江省“十四五”规划提出的600万、400万、367万hm2左右数据值及2011—2020年间作物种植面积、单产的最小值、最大值和平均值。
3.2.1 耕种面积不变假设 设定式(12)变量参数值。其中,玉米、水稻、大豆种植面积为2020年数据,分别为548 万、387 万、483 万 hm2,单产(x2、x4、x6)下限值取2011—2020年间平均值,上限值取2011—2020年间最高值的1.05倍。

运行式(12)、(13),随机获取78.8亿kg极值条件下的20个优化解集方案(表3)。从离散程度看,单产3个变量变异系数值范围为0.63%~3.21%,其值为大豆单产(3.21%)>水稻单产(1.05%)>玉米单产(0.63%),均小于5%,表现出3个变量离散的相对稳定性及差异性。平均值水稻单产(7717.5 kg/hm2)>玉米单产(7017.9 kg/hm2)>大豆单产(1912.5 kg/hm2),玉米、水稻、大豆单产最大值(7045.0、7854.0、2000.0 kg/hm2)、最小值(6898.4、7620.2、1819.0 kg/hm2)均介于式(12)上下限范围内。从权重值看,3个单产变量权重值存在差异性,表现为大豆单产(0.8730)>玉米单产(0.0932)>水稻单产(0.0338),大豆单产变化对总产量的影响程度最大。根据综合评价指数值大小排序,筛选出前1位优化方案为3.18,其单产指标是玉米6898.4 kg/hm2、水稻7854.0 kg/hm2、大豆2000.0 kg/hm2,分别较表 3中平均值增加-1.70%、1.77%、4.58%。

表3 面积不变下单产极值优化解集及其综合评价指数值
3.2.2 单产不变假设 设定式(14)变量参数值。其中,玉米、水稻、大豆单产为2020年数据,分别为6653、7480、1905 kg/hm2,面积x1、x5下限、上限值分别取2011—2020年间最小、最大值,x3下限取2011—2020年间最小,上限值400万hm2。
运行公式(12)、(14),随机获取78.8亿kg极值条件下20个优化解集方案(表4)。从离散程度看,3个变量变异系数值范围为3.50%~5.29%,其值为水稻面积(5.29%)>大豆面积(4.27%)>玉米面积(3.50%),均小于6%,表现出3个变量离散相对稳定性。平均值玉米面积(638.2万hm2)>大豆面积(458.1万hm2)>水稻面积(365.0万hm2),玉米、水稻、大豆面积最大值(666.8万、400.0万、483.0万 hm2)、最小值(593.8、344.0、430.4 hm2)介于式(13)上下限范围内。从权重值看,3个面积变量权重值存在差异性,表现为水稻面积(0.4765)>大豆面积(0.3125)>玉米面积(0.2110),水稻面积变化对总产量的影响程度最大。根据综合评价指数值大小排序,筛选出前1位优化方案为4.4,其面积指标是玉米593.8万hm2、水稻400万hm2、大豆483万hm2,分别表4中平均值增加-6.96%、9.59%、5.44%。

表4 单产不变下种植面积极值优化解集及其综合评价指数值
3.2.3 耕种面积、单产均变假设 设定式(15)变量参数值。其中,面积x1、x5下限、上限值分别取2011—2020年间最小、最大值,x3下限取2011—2020年间最小,上限值400万hm2;单产(x2、x4、x6)下限值取2011—2020年间平均值,上限值取2011—2020年间最高值的1.05倍。

运行式(11)、(15),随机获取78.8亿kg极值条件下20个优化解集方案(表5)。6个变量变异系数值范围为3.94%~9.63%,其值为大豆面积(9.63%)>水稻面积(6.26%)>玉米面积(6.07%)>玉米单产(5.31%)>水稻单产(4.06%)>大豆单产(3.94%),均小于10%,表现出各变量离散的差异性和相对稳定性。从作物种植面积看,平均值为玉米(686.3万hm2)>大豆(442.0万hm2)>水稻(371.7万hm2),玉米、水稻、大豆最大值(736万、400万、483 万 hm2)、最小值(591.8 万 hm2、364.9 万 hm2、344.0万hm2)均在式(15)上、下限范围内;从作物单产看,平均值为水稻(7390.0 kg/hm2)>玉米(6268.0 kg/hm2)>大豆(1896.5 kg/hm2),玉米、水稻、大豆最大值(7045、7854、2000 kg/hm2)、最小值(6037、7102、1819 kg/hm2)均介于式(15)上下限范围内。从权重值看,6个变量权重值存在差异性,表现为大豆面积(0.4102)>水稻面积(0.1699)>玉米面积(0.1619)>玉米单产(0.1197)>水稻单产(0.0711)>大豆单产(0.0672),大豆种植面积变化对总产量影响最大,大豆单产变化对总产量的影响程度最小。根据综合评价指数值大小排序,筛选出前1位优化方案为5.8,其单产指标是玉米6805.4 kg/hm2、水稻7205.5 kg/hm2、大豆2000.0 kg/hm2,分别较表5中平均值增加-8.57%、-2.50%、5.46%;其面积指标是玉米591.8 万 hm2、水稻400万hm2、大豆483.0万hm2,分别较表5中平均值增加-13.77%、7.61%、9.28%。

表5 作物种植面积、单产极值优化解集及其综合评价指数值
4 讨论与对策
在市场化和工业化背景下,实现粮食增产、粮农增收和环境可持续的协同并进,已成为国民经济持续健康发展的必然要求,也是保障中国粮食安全的重要目标[33-34]。随着人口数量增长、消费结构不断升级以及资源环境承载力趋紧,粮食产需可能会长期维持紧平衡态势,科技创新则是突破资源刚性约束的一个重要路径[5]。保护和利用好黑土地资源,建设粮食产业强国是维持国家安全的重要基石[35]。鉴于此,建议在本研究基础上进一步综合经济、社会和生态效益来分析优化黑龙江省作物种植结构布局,并针对种子科技创新与耕地保护利用开展深入研究,从而促进粮食产能目标保质保量完成。具体建议:(1)引入效益分析,强调综合评价。对获取的粮食产能极值优化解集方案,从经济效益、社会效益和生态效益角度,全面剖析农作物种植的产出投入比、成本利润率以及生产、加工、销售等环节的利润分配格局,以期获取产能与效益综合考量的作物种植生产最优目标方案,激发农民种粮积极性,保障粮食安全生产。(2)推进种子创新,提高单产水平。创新构建种子高效育种技术体系,让基因编辑、分子设计、人工智能育种等高新技术与田间实践育种有序衔接;加强种质资源收集管理,加快从种质资源向优异基因资源转化,提高种质资源利用率;做好种子推广智力服务,实现创新成果与实践应用“对的上”、“接的好”、“落的实”。(3)严守耕地数量,关注耕地质量。“切实保护好黑土地这个‘耕地中的大熊猫’”,避免土地非耕地化,加强耕地保护执法执政与督察,确保耕地面积安全;防止因注入各种“营养”和大量防治病虫害农药而使土壤“过劳死”发生,落地土壤培肥耕作技术,探索耕地保护经济补偿政策,“实现黑土地永续利用”。
5 结论
综合分析得出以下结论:(1)通过调整作物种植面积,或单产,或面积与单产,均可获取变量动态变化的优化方案,能够实现黑龙江省2025年粮食产能目标;(2)从调整作物单产看,最佳优化方案(3.18)的玉米、水稻、大豆单产达 6898.4、7854.0、2000.0 kg/hm2时,较2020年单产增加3.69%、5.00%、5.01%。(3)从调整作物种植面积看,最佳优化方案(4.4)的玉米、水稻、大豆面积达593.8万、400万、483万hm2时,较2020年面积增加8.34%、3.31%、-0.04%。(4)从调整作物种植面积与单产看,最佳优化方案(5.8)的玉米、水稻、大豆面积与单产分别达591.8万、400万、483.0万hm2与6805.4、7205.5、2000.0 kg/hm2,较 2011—2020 年数据平均值增加-4.53%、4.82%、42.10%与12.74%、1.46%、9.98%,较2020年相关数据增加7.97%、3.31%、-0.04%与2.29%、-3.67%、5.01%。
猜你喜欢
今日农业(2022年16期)2022-11-09 23:18:44
中国化肥信息(2022年5期)2022-08-30 01:58:26
新世纪智能(数学备考)(2021年10期)2021-12-21 06:20:38
今日农业(2021年20期)2021-11-26 01:23:56
今日农业(2021年14期)2021-10-14 08:35:34
今日农业(2021年12期)2021-10-14 07:31:16
今日农业(2021年7期)2021-07-28 07:07:30
河北理科教学研究(2020年3期)2021-01-04 01:49:40
今日农业(2020年22期)2020-12-25 02:30:44
今日农业(2020年20期)2020-12-15 15:53:19
