
基于Python机器学习算法的易携出客户模型研究
2022-11-22 04:21:53尹清
中国新通信 2022年16期
摘要:近年来随着公司携号转网工作的深入落实,携号转网用户越来越多,携出用户成了用户流失的一大因素。为了减少用户携出,通过Python中的机器学习算法分析携出用户特征,建立易携出用户模型预测,提前定位易携出客户,进行维稳挽留,有效降低了携出用户的概率。
关键词:携号转网、机器学习算法、携出客户、模型预测
一、引言
近年来随着智能手机的普及,客户规模不断增大,通信企业新增市场趋于饱和,存量客户维稳显得尤为重要。尤其是携号转网工作在通信企业的落地执行,对存量用户有着不小的冲击。文献[1]对携号转网做了全面的概述,用户在不变更号码的同时可以选择不同的通信运营商,方便灵活。文献[2]研究了携号转网对我国移动通信市场的影响,阐述了携号转网用户的关注点及转网的原因剖析,为通信企业的决策提供了参考。
我们关注的重点是如何挽留用户,降低携出用户的概率,从而减少用户流失率。提前锁定要携出的用户,精准开展维稳挽留活动,可以有效降低用户携出的可能性。文献[3]对Python数据分析的研究进行了详述,开拓了分析工作的思路,本文提出了通过Python中的分类算法对易携出用户进行预测,既能提高分析效率,又能提供准确的模型预测。
二、目前数据分析简述
目前工作中最常用的数据分析、模型预测都是数据库和excel相结合的方式开展的。先通过数据库提取出指定用户特征的用户群,通过统计语句进行相关特征用户的汇总,最后通过excel呈现出折线图、柱状图等一些直观的数据表现形式,分析出特定的用户模型。
三、Python机器学习算法建模优势
Python中pandas 库里的相关函数,能够轻松完成数据导入、清洗、预处理,数据分类、筛选、汇总、透视等常见的操作。Sklearn库包括了分类,回归,降维和聚类四大机器学习算法,可以进行特征提取,数据处理和模型评估。Matplolib库中的方法可以进行直观的图形化数据展示。Python 通过函数式编程完成数据处理、统计汇总及分析工作。Python语言本身简洁高效易上手,函数丰富,对大数据的处理分析能力相当强大。将Python的机器学习算法应用到数据分析工作中,使繁杂的分析工作变得轻松自如。
四、易携出用户模型建立
易携出用户模型就是要从用户携出现的海量数据中,找到共同特征,建立预测模型,并将模型应用于在网用户,预测出携出概率高的用户。通过有效的维稳政策,对用户进行精准维系,减少用户携出,提升用户价值。
(一)数据的选取和处理。
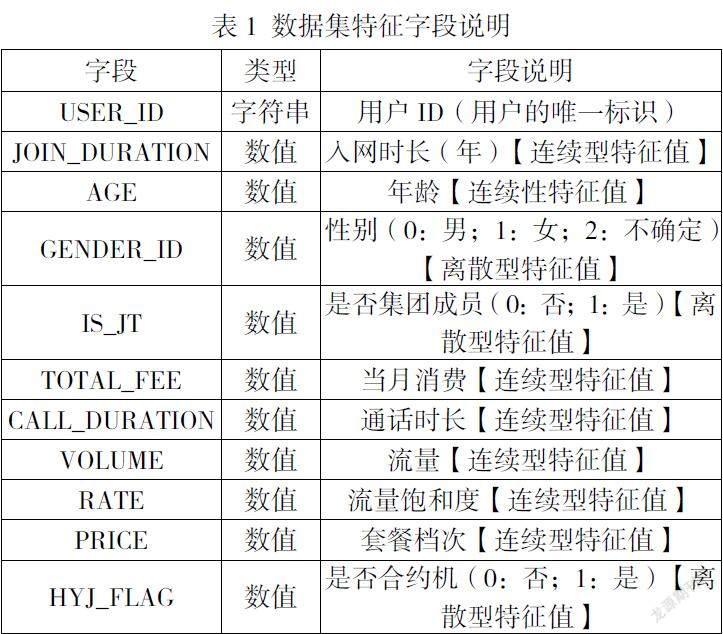
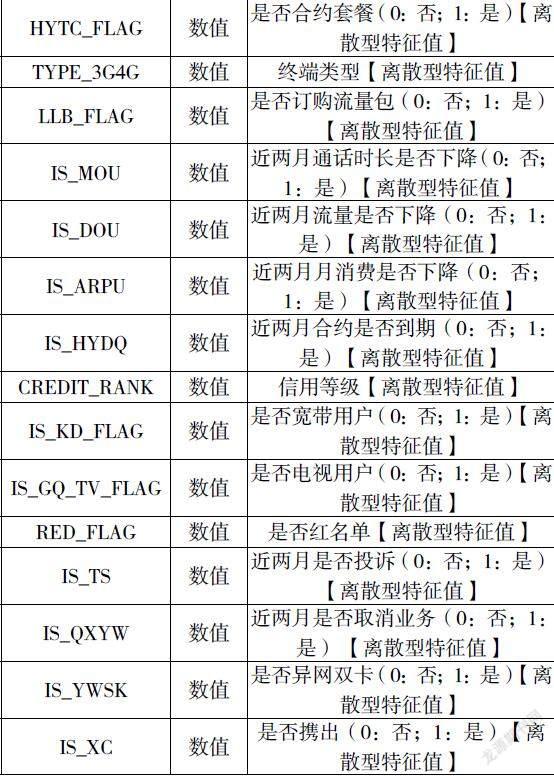
本数据集选取2021年11月状态正常且均为9月之前入网的用户数据10000条,其中次月仍正常用户随机抽取8000条,次月携出用户随机抽取2000条,选取的用户特征列为性别、年龄、入网时长、套餐档次、通话、流量等基本属性和前滚2个月的消费、通信行为的变化等衍生属性。数据集特征字段说明见表1。
本数据集放入yxc5.csv文件中,通过pandas库中的函数read_csv()读入数据集,isnull()查找缺失值(其中PRICE列共5个缺失值,CREDIT_RANK列共2个缺失值),dropna()删除缺失值所在行,最后数据集剩9993行。
(二)特征可视化分析
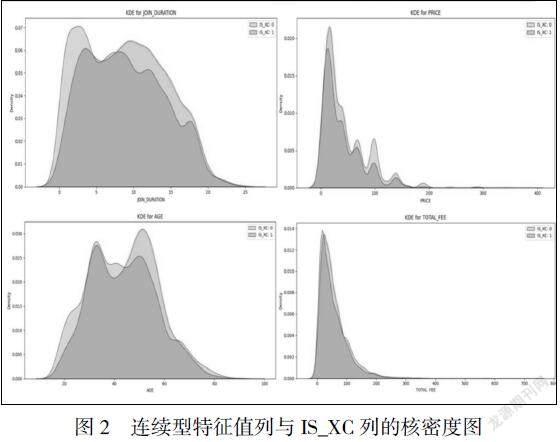
本数据集除了USER_ID是用户唯一标识列,共7列连续型特征值,18列离散型特征值。离散型特征值列可用seaborn库中的计数直方图countplot()展示与IS_XC列的关系,见下图1,连续型特征值列可用seaborn库中的密度函数图kdeplot()展示与IS_XC列的关系,见下图2。
从计数直方图中可以看出,异网双卡客户、DOM下降客户、非合约套餐客户、非身份证开卡客户(性别未知客户)、合约到期客户、非宽带客户、非电视客户的携出占比较高;MOU是否下降客户与携出与否无差异。
从和密度图中可以看出,入网10-15年客户、套餐档次50元以下客户、年龄50-60岁客户的携出较集中;客户月消费、流量、通话时长与是否携出无差异。
(三)特征选择和模型训练
由前面结果可知,USER_ID表示每个客户的唯一标识,对后续建模不影响,IS_MOU 、TOTAL_FEE、VOLUME、CALL_DURATION 与携出的相关性低,均可删除。
现实情况下,一个数据集往往有多个特征,如何在其中选择对结果影响最大的几个特征,以此来缩减建立模型时的特征数是我们比较关心的问题。文献[4]中详述了随机森林进行特征选择的方法,我们通过随机森林函数feature_importances查找剩下特征列的重要性并進行排序,见下图3。
从上图中可知,JOIN_DURATION,AGE,PRICE列的重要度最高,而LLB_FLAG,HYJ_FLAG,RED_FLAG列的重要度最低,可将其删除。
文献[5]和文献[6]提出了随机森林对分类不平衡数据的优势,现实中携出用户远远低于正常在网用户,所以数据集是不平衡的;而且随机森林算法对数据集的适应能力强,既能处理离散型数据,也可以处理连续型数据,数据集无需规范化,故选择随机森林分类算法是最合适的分类算法。选择出与携出特征相关性强的特征值列,建立训练数据集和测试数据集,用RandomForestClassifier()进行模型训练。模型训练准确率可达0.897,具体运行结果见下图4。
选择与携出相关性强的特征列,用随机森林进行建模,训练出来的模型准确率比较高。
五、模型应用效果评估
通过以上的特征分析和选择,为了验证模型,我们在2022年1月份选取了2021年12月的状态正常、入网时间在10-15年、套餐档次50元以下、年龄50-60岁,并且没有开通宽带和高清电视的客户共10万户。在1月份对这部分客户通过微客服的微信公众号推送宽带智家产品、流量大礼包、商超代金券等各类优惠活动,吸引客户参与,提升客户黏性;通过推送专属活动为客户送流量或话费福利,提升客户满意度。效果在2月份显现出来,2月的携出客户占离网客户的比例由12月份的14.16%降低到12.81%,降低了1.35PP。
六、结束语
本文提出了使用Python的机器学习算法分析携出用户特征,找出强相关的特殊值,建立易携出客户模型,提前定位易携出客户,并通过微客服对目标客户推送优惠活动或专属福利,增加了客户黏性,提升了客户满意度,有效降低了携出用户的概率。
作者单位:尹清 中国移动通信集团河南有限公司新乡分公司
参 考 文 献
[1] 胡文玉,窦晓燕.全面实施携号转网对我国移动通信市场影响[J].电信科学,2019(9):124-134.
[2] 郑炜楠.携号转网的影响及应对策略[J].现代营销理论,2018(09).
[3] 韩文煜.基于python数据分析技术的数据整理与分析研究[J].科技创新与应用,2020(4).
[4] 王全才.随机森林特征选择[D].大连:大连理工大学,2011.
[5] 肖坚.基于随机森林的不平衡数据分类方法研究[D].哈尔滨:哈尔滨工业大学,2013.
[6] 徐少成.基于随机森林的高维不平衡数据分类方法研究[D].太原:太原理工大学,2018.
