
基于ARIMA和Prophet的水质预测集成学习模型
2022-11-22 00:22嵇晓燕陈亚男姚志鹏安新国
水资源保护 2022年6期
嵇晓燕,杨 凯,陈亚男,姚志鹏,王 正,安新国
(1.中国环境监测总站,北京 100012; 2.北京金水永利科技有限公司,北京 100012)
地表水质自动化监测预警是当前水环境管理的切实需要,是现代管理“安全第一、预防为主”理念的具体体现[1]。水质预测作为地表水质自动化监测预警的基础,已经成为水环境污染防治工作的重要研究内容。水质预测就是针对目标水体在建立基于水动力的机理模型或基于历史数据分析的数理模型的基础上,实现对该水体未来一段时间水质情况的预判。根据模型的预测结果,可以提早发现潜在的污染风险,避免重大水污染事件的发生,为水污染防治工作的决策提供数据支持,因此水质预测具有非常重要的实际意义。
国内外学者对水质预测方法进行了大量的研究,包括基于水动力学模型的水质预测方法[2-3]和基于数理模型的预测方法。基于数理模型的常见预测方法包括时间序列法[4-5]、回归分析法[6-7]、灰色预测法[8]以及神经网络预测法[9-11]等。水质数据作为时间序列数据,具有很强的自相关性以及趋势性,适用于建立时间序列模型进行预测,但常用的单一时间序列分析模型难以捕捉到水质数据序列中的非线性部分。而对于神经网络这类模型而言,因为其强大的非线性拟合能力,导致模型预测的泛化能力较差。考虑到影响水质环境的因素较多,且水质监测数据具有非线性、随机性以及周期性等复杂特性,建立单一模型进行预测会因为模型自身的限制使得模型预测精度及健壮性普遍不高[12]。
本文采用基于时间序列分析模型的集成学习方法进行水质预测,通过融合多个时间序列模型的预测结果,利用神经网络模型对预测结果进一步进行非线性处理,从而能够显著提升预测精度。
1 模型构建
集成学习是使用多个基学习器进行学习,并根据规则整合每个学习器输出的结果,从而获得比单一基学习器更好效果的一种机器学习方法[13]。本文利用Blending集成学习的方式,将时间序列模型ARIMA和Prophet作为基学习器,将BP神经网络模型作为整合学习器结果的集成模型,从而构建本文的集成学习模型。集成学习模型中,ARIMA模型可以很好地获取时间序列中的周期性和趋势信息,Prophet模型可以很好地处理时间序列数据中存在的异常值和缺失值;同时BP神经网络模型可以很好地处理非线性问题[14-15]。
集成学习模型建模流程(图1)如下:①将各个指标的水质历史数据集按照监测时间顺序分割为训练、验证以及测试数据集;②针对训练数据集分别建立ARIMA模型和Prophet模型,计算两个模型对验证数据集的预测结果,将其作为输入数据,结合验证数据集中的输出数据形成学习器结果数据集;③将该结果数据集分割为训练、验证数据集,针对训练数据集建立BP神经网络模型,并根据验证数据集的预测效果判断模型是否提前结束训练;④评估每个模型在测试数据集上的预测精度。
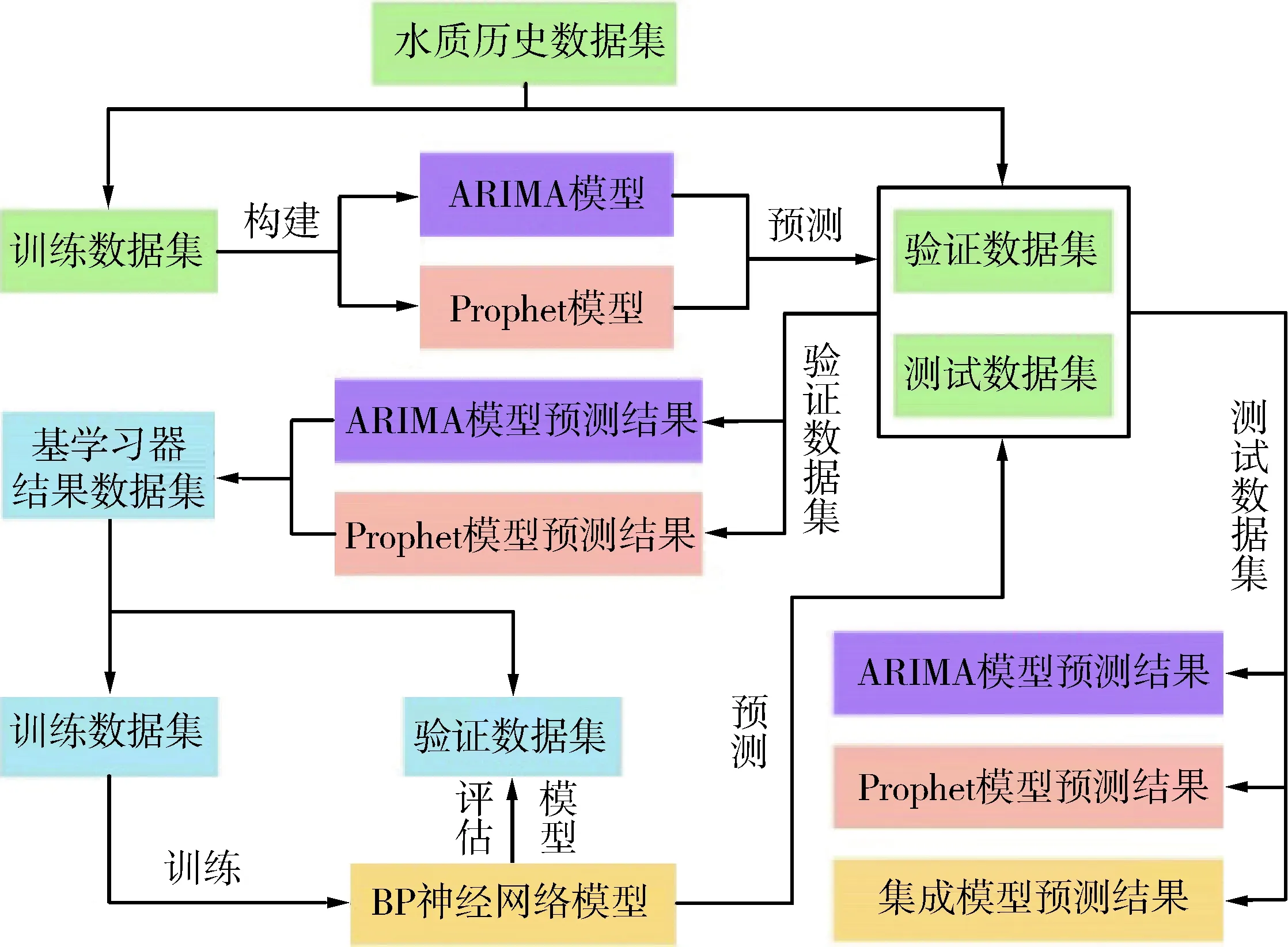
图1 集成学习模型建模流程Fig.1 Modeling flowchart of ensemble learning model
1.1 ARIMA模型
ARIMA模型由自回归(auto regression,AR)模型和移动平均(moving average,MA)模型组成,包括p、d、q3个参数,其中p为AR模型参数,q为MA模型参数,d为时间序列转换为平稳序列所做的差分次数[16]。
a.AR模型。该模型可以描述当前时刻水质数据与历史水质数据之间的关系,也就是利用历史数据对当前时刻数据进行预测。带有随机扰动项的p阶AR模型可以写为
Xt=α1Xt-1+α2Xt-2+…+αpXt-p+ut=
(1)
式中:Xt为t时刻的水质数据;p为用于预测的时刻数;ut为随机扰动项;αi为模型参数。
b.MA模型。该模型认为水质序列数据是平稳的,也就是将AR模型中的随机扰动项ut看作一个q阶的移动平均项,就有下面的形式:
ut=εt+β1εt-1+β2εt-2+…+βqεt-q=
(2)
式中:εt为白噪声;q为受白噪声序列影响的时刻数;βj为模型参数。
c.ARIMA模型。对于不平稳的水质序列数据经过差分得到平稳序列,其中差分次数为d。将AR(p)和MA(q)结合得到ARIMA(p,d,q)模型的表达式为
(3)
1.2 Prophet模型
Prophet模型是一种开源的可处理时间序列数据的模型,可以很好地处理时间序列中的缺失值以及异常值对预测的影响,适用于水质数据的预测分析[17]。
Prophet模型可将水质时间序列数据写为如下关于时间t的函数形式:
y(t)=g(t)+s(t)+h(t)+ξt
(4)
式中:g(t)为趋势项,是时间序列中非周期性变化趋势的部分;s(t)为周期项,是时间序列中呈现周期性变化的部分;h(t)为节假日项,是该序列中受节假日影响的部分,因为在水质预测中节假日的影响较小,在本文中并不考虑这一项;ξt为剩余项。
a.趋势项。在Prophet算法中趋势项可通过逻辑回归函数和分段线性函数两种不同的函数来计算。考虑到水质数据自身的特性,本文采用分段线性函数来模拟趋势项。基于分段线性函数的趋势项形如:
g(t)=(k+a(t)δ)t+(m+a(t)Tγ)
(5)
其中
γ=(γ1,γ2…,γS)T
γj=-sjδj(j=1,2,…,S)
式中:k为增长率;a(t)∈{0,1}S为指示函数;δ∈RS为增长率的变化量;δj为在时间戳sj上的增长率的变化量;m为补偿参数;S为突变点的个数。
b.周期项。使用傅里叶级数来模拟时间序列的周期性,周期项可以写为下面的形式:
(6)
其中
β=(α1,b1,α2,b2,…,αN,bN)T
式中:H为时间序列的周期;β为Prophet模型的初始化参数,β的初始化为β~N(0,σ2),σ越大,表示季节效应越明显,σ越小,表示季节效应越不明显,本文σ=0.7。
在水质预测中设置以年为周期,也就是H=365.25,N=10,此时
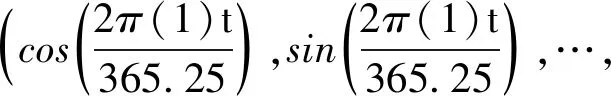
(7)
2 实例验证
2.1 数据来源
选择长江流域某监测断面2019—2020年溶解氧(DO)、高锰酸盐指数(CODMn)、氨氮(NH3-N)、总磷(TP)、总氮(TN)等5个指标的水质自动监测数据(共4 386条)来验证模型。其中2019年1月1日至12月31日的2 190条数据作为训练数据集,2020年1月1日至10月26日的1 800条数据作为验证数据集,2020年10月27日至2020年12月31日的396条数据作为测试数据集。构建集成学习模型阶段,2020年1月1日至9月26日的1 620条数据作为训练数据集,2020年9月27日至2020年10月26日的180条数据作为验证数据集。因为DO的自动监测频次为1 h 1次,其他指标均为4 h 1次,为了统一时间精度,DO数据选用其他指标监测时刻的数据。
2.2 ARIMA模型验证结果
2.2.1序列平稳性检验
利用ADF检验进行序列平稳性判断。如果该检验统计量小于置信度1%对应的值,并且显著性P值小于0.05,则表示序列是平稳的。由表1可知,除CODMn外,其他指标ADF检验结果均小于置信度1%对应的值,并且P值均小于0.05,表明数据序列是平稳的。对CODMn序列进行一阶差分,计算得到检验统计量为-14.461,小于置信度1%对应的值-3.431 852,P值为6.842×10-27,表明经过一阶差分后数据变为平稳序列。
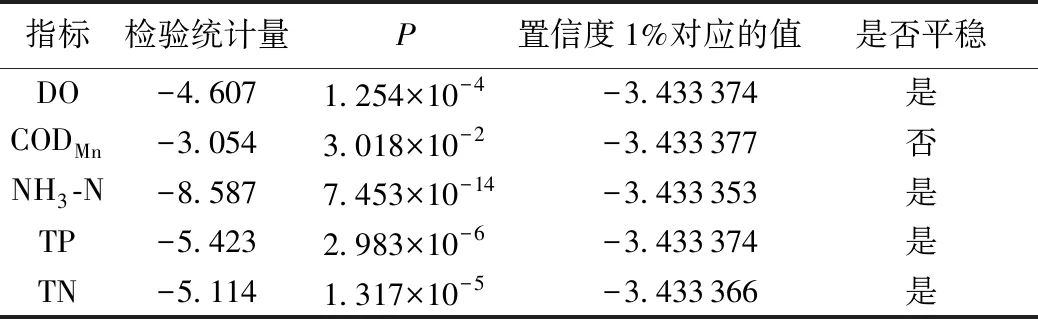
表1 数据平稳ADF检验Table 1 Data stationary ADF test
2.2.2序列随机性检验
Ljung-Box检验可评判时间序列数据是否为随机序列,如果为随机序列则不能构建ARIMA模型。设置最大延后期为40,经过计算,5个水质指标数据序列得到的P值均接近于0,表明序列不是随机序列。
2.2.3确定模型参数
针对每个水质指标,根据赤池信息准则(akaike information criterion, AIC)和贝叶斯信息准则(Bayesian information criterion, BIC),采用参数组合的方式,将使得AIC与BIC的和最小的p、q作为该水质指标ARIMA模型的参数。本文p、q的选择范围均为0~6,d的取值范围为0~2。各水质指标的最佳模型参数见表2。

表2 ARIMA模型参数Table 2 ARIMA model parameters
2.2.4模型构建与验证
ARIMA模型的残差应该满足均值为0且方差为常数的正态分布,并且不具备自相关性。根据各水质指标对应的最佳模型进行训练数据的拟合,对训练数据的模型预测值与监测值之间的残差序列进行正态分布检验和Durbin-Watson(DW)检验(表3),其中正态分布检验的统计量p应大于0.05,DW检验的值应接近于2。如果残差近似正态分布并且不满足自相关性,说明构建的模型是适用于该指标数据序列分析的。

表3 残差检验Table 3 Residual test
由表3可知,各水质指标模型的残差序列均满足正态分布并且不存在自相关性,表明建立的ARIMA模型适用于这5个水质指标的时间序列数据分析。本文的预测方式为静态预测,也就是用真实的监测数据预测下一时刻的数据。采用平均绝对误差(mean absolute error, MAE)、平均绝对百分比误差(mean absolute percentage error, MAPE)以及皮尔逊相关系数(r)进行模型预测精度评价,其中MAE是预测值与真实值之差的绝对值的均值,可以评价预测结果的误差情况;MAPE是预测值与真实值之差的绝对值与真实值比值的均值,可以用于计算模型误差占真实值的比例;皮尔逊相关系数可以用来判断预测序列和真实序列趋势的一致性,接近于1说明模型预测精度较高。表4为模型在测试数据集上的预测效果。
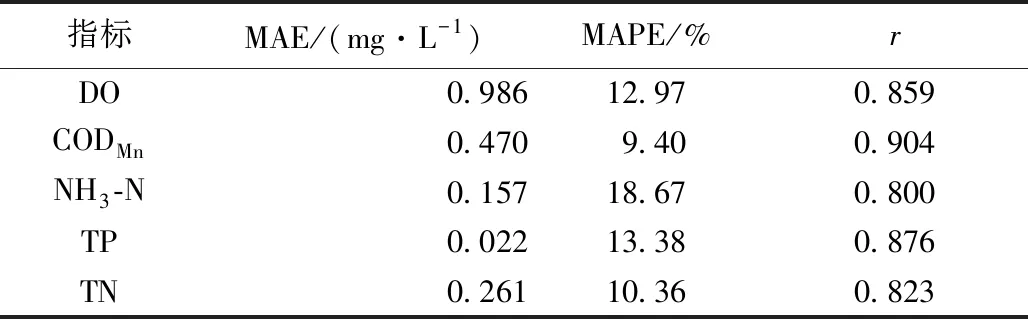
表4 ARIMA模型预测精度评价Table 4 Evaluation of prediction accuracy of ARIMA model
由表4可知,ARIMA模型预测结果的MAPE均在20%以下,相关系数均在0.8以上,表明构建的模型预测效果较好。
2.3 Prophet模型验证结果
对各水质指标的训练数据集构建Prophet模型,表5为各水质指标在测试数据集上的预测精度评价结果。
因为Prophet模型是将原始的水质监测序列分解为不同的项,导致其预测值并不能很好地反应监测数据的时间变化,因此和监测值序列的皮尔逊相关性较低,因此用PIC作为评价模型预测性能的指标。从表5可知,5个指标的PIC值均在90%左右,并且MAPE在20%上下,说明该模型的预测具有一定的精度。
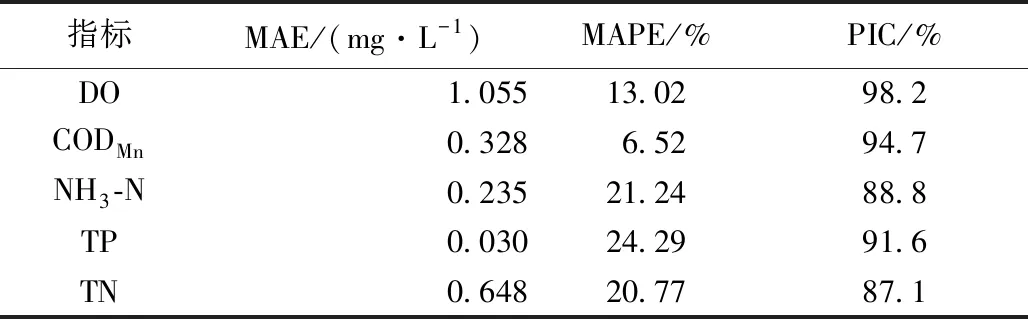
表5 Prophet模型预测精度评价Table 5 Evaluation of prediction accuracy of Prophet model
2.4 集成学习模型验证结果
利用BP神经网络模型对两个模型的结果进行融合。选用6层的神经网络,其中包含4个隐层,每个隐层有80个神经单元。将ARIMA模型针对验证数据集的5个水质指标预测结果、Prophet模型的预测结果以及预测区间的上限值、下限值一起作为BP神经网络的输入数据,将水质的监测数据作为输出数据,构成模型数据集,并按照9∶1的比例将模型数据集分割为训练和验证数据集。
模型迭代次数设置为5 000次,优化求解器采用Adamax。模型训练过程中随着迭代次数的增加,训练、验证数据集的误差逐渐降低,为避免模型过拟合,需要根据验证数据集的预测结果对模型进行评估,当迭代次数为3 430时模型的预测性能最佳。
从表6可看出,DO、CODMn、NH3-N、TP和TN5个水质指标集成学习模型的MAPE比ARIMA、Prophet模型中较低的分别低35.0%、29.9%、4.1%、40.6%和17.1%,皮尔逊相关系数和ARIMA模型相比相差不大,基本在0.8~1.0之间,说明集成学习模型的预测精度较单一模型精度高。

表6 集成学习模型预测精度评价Table 6 Evaluation of prediction accuracy of ensemble learning model
3 结 语
针对水质数据预测建立了一种基于ARIMA和Prophet的集成学习模型。集成学习模型中的时间序列分析模型可以很好地捕捉水质数据中存在的趋势性信息,利用BP神经网络模型进行集成可以对数据施加非线性的处理。这种通过融合不同原理模型预测结果的方式,集成了不同模型的优点,可以学习到更多数据序列存在的信息,从而使得预测结果更为精确。采用长江流域某监测断面5个水质指标的监测数据进行了验证,结果显示集成学习模型的评估指标均优于单一时间序列模型,表明集成学习模型的水质预测精度更高,可以应用于实际水环境管理中的水质预测,为实现更科学、精准的水质自动化预警提供数据支持。
猜你喜欢
一重技术(2021年5期)2022-01-18
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
电子制作(2019年19期)2019-11-23
建材发展导向(2019年10期)2019-08-24
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
当代水产(2019年1期)2019-05-16
当代水产(2019年3期)2019-05-14
电子制作(2019年24期)2019-02-23
电子制作(2018年14期)2018-08-21
电子制作(2018年11期)2018-08-04
