
基于机器学习算法的心脏病预测诊断模型研究
2022-11-19 09:16梁靖涵许亚杰
现代信息科技 2022年19期
梁靖涵,许亚杰
(郑州科技学院,河南 郑州 450064)
0 引 言
心脏病是一种没有传染性但致死率很高的疾病,该疾病发病过程缓慢、病程长、发病原因复杂。由于传统的医疗决策模式很难对此类疾病进行准确的分析和诊断,导致患者无法及时发现、无法得到及时的治疗[1]。根据上述问题,很多研究人员提出了基于机器学习的方法,Subbalakshmi 等人利用朴素贝叶斯分类器作为核函数,构建支持决策的心脏病诊断辅助系统。国内有学者将聚类技术和XGBoost 算法进行结合,采用K-means 算法进行特征识别和XGBOOST 算法对心脏病进行预测分 析[2]。机器学习算法涵盖范围广泛,在模型构建时,由于使用不同的特征和机器学习算法都会造成预测精度的差异,因此上述研究模型准确率有待提高。
根据上述分析,本文从数据处理的全局角度出发,对原始数据集进行标准化、特征选择,采用优化数据集的方式提升算法准确率,构建决策树算法和K 近邻算法两种机器学习算法模型进行数据分析和预测,经过实验对比得出最优分类算法模型,为医生在心脏病的预测诊断提供科学依据。
1 数据与特征
1.1 数据描述
本研究数据来源于美国行为风险因素检测系统(BRFSS)数据库中提供的开源数据集,该数据集共有数据319 795 条,有18 个属性,其中有17 个属性为特征变量,有1 个属性Heart Disease 是用来判断患者是否患心脏病的标签属性,属性值Yes 表示患有心脏病,属性值No 表示没有心脏病。数据集各字段含义解释如表1 所示。

表1 数据集属性介绍

续表
1.2 数值特征可视化与数据预处理
如图1 所示为心脏病数据集变量相关性热力图,该图能清楚地显示出各种特性的关系,右边刻度显示的是各种相关系数所对应的色彩深度,相关系数越接近0,则属性间的关联性越低,正数表示属性之间为正相关,负数表示属性之间负相关。从图中可以看出特征Sleep Time、Mental Health、Alcohol Drinking、Asthma、BMI、Sex与标签变量Heart Disease 的相关系数值接近于0,在进行特征工程时可以考虑剔除这些变量,以免导致因多重共线性造成过拟合。从热力图的第一行或者第一列可以看出,对判断是否患有心脏病与Stroke、Physical Health、Diff Walking、Diabetic、Kidney Disease 等变量具有较高的相关性。因此,在创建心脏病诊断模型时需要保留这些属性。同时采用Standard Scaler 模型对数据进行标准化处理,即采用Z-Score 规范化数据,保证每个特征维度的数据均值为0,方差为1。同时,利用scikit-learn 库中的OneHotEncoder 把分类特征中的每个元素的值都转化为可以直接计算的数值。
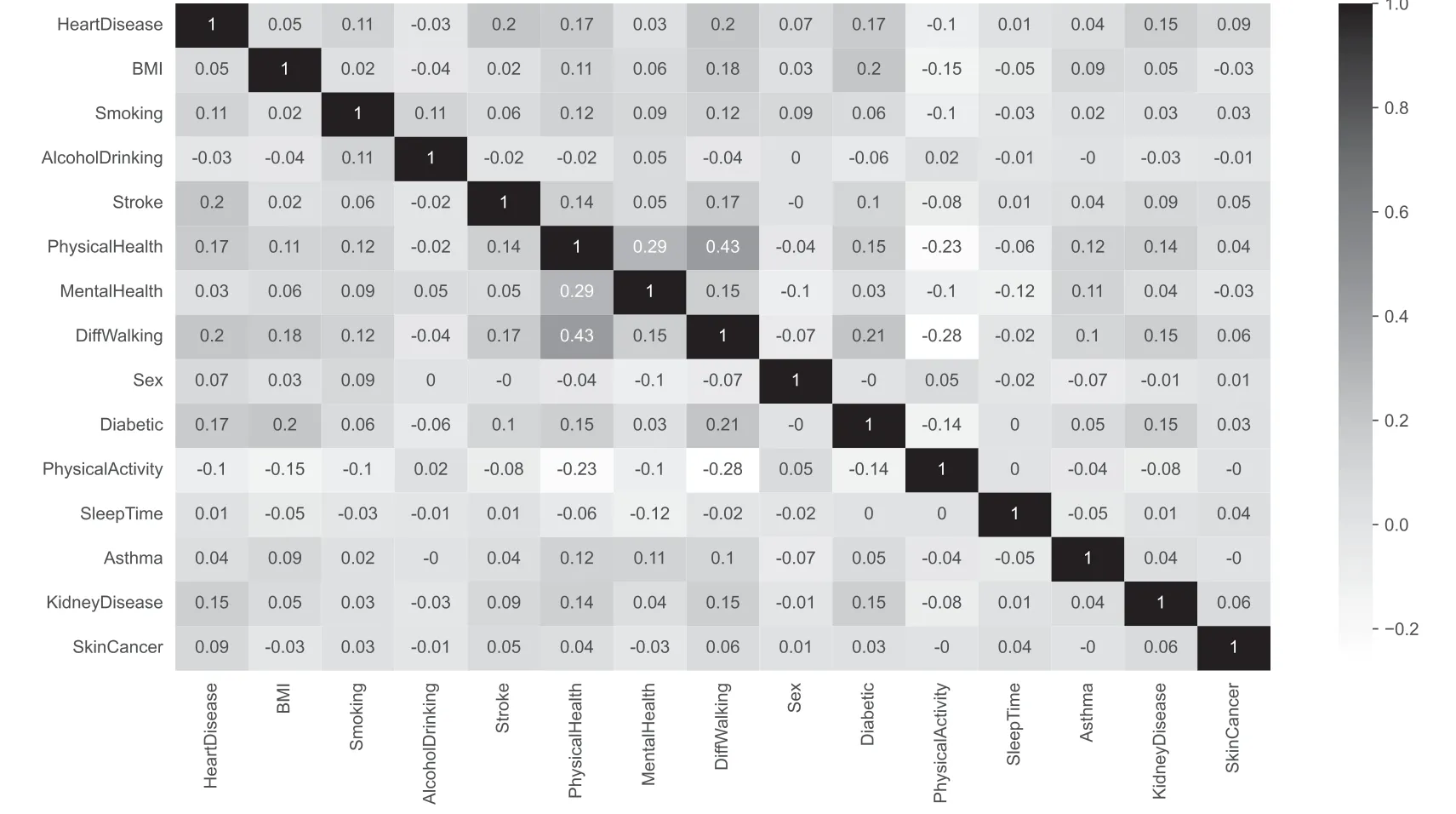
图1 变量相关性热力图
2 机器学习模型创建
2.1 决策树模型创建
决策树(DT)是一种基于已知各种情形的概率的决策分析方法,利用 DT 构造出预期净现值的期望值大于或等于0,以此来评价工程的风险,判定工程是否可行。由于这个决策分支被绘制成了树形结构,因此被称作决策树[3]。决策树是机器学习中的一种能够反映目标属性与目标价值的映射关系的预测模型。决策树模型构建分为以下三个步骤。
2.1.1 特征选择
在信息理论和概率统计学中,熵(entropy)是一种用来衡量随机变量不确定因素的指标。不确定因素的熵定义是:
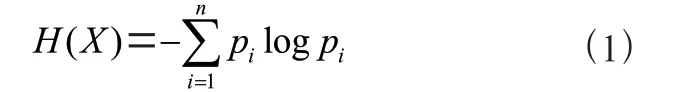
式中:H(X)为熵,pi表示这一批样本中最终属于第i个分类的概率。
随机变量X给定的条件下随机变量Y的条件熵H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望:
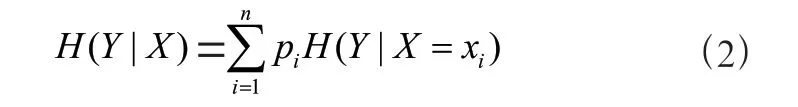
式中:H(Y|X)表示条件信息熵,pi表示这一批次样本中第i类的概率,其中pi=P(X=xi),i=1, 2, …,n表示满足条件X=xi的样本。
2.1.2 决策树的生成
在构造决策树时,首先使用由上到下的递推结构,由单一的节点组成,当所有的样本都位于相同的类时,将其视为叶子节点,而节点的内容就是分类标签。反之,根据某一策略,选取某一属性,将其分成多个子集,以使每一子集中的实例都拥有相同的属性值,并依次对其进行递 归[4]。基本步骤如下:
(1)开始,所有预测变量均看作一个节点;
(2)通过对每一种预测变量进行分割,找出最优的分割点;
(3)分割成两个分支N1和N2;
(4)对N1和N2分别执行步骤2 和步骤3,直到每个节点都足够“纯”为止。
2.1.3 决策树的剪枝
把以生成的树进行修剪的过程称为剪枝(pruning)。决策树的修剪是使决策树总体损失函数(loss function)或代价函数(cost function)最小化而得 到的[5]。设树T的叶节点个数,t是树T的叶节点,该叶节点有Nt个样本点,其中k类的样本点有Ntk个,k=1, 2, …,K,Ht(T)为叶节点t上的经验熵,α≥0 为正则化系数,则决策树学习的损失函数可以定义为:
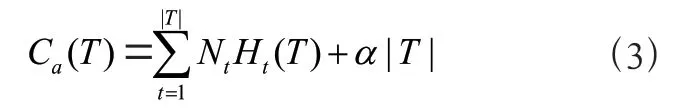
式中:|T|表示叶子节点个数,Ht(T)为叶节点t上的经验熵。
2.2 K 近邻算法模型创建
K 近邻(KNN)是最典型的机器学习算法,KNN 的基本思路是:在已知的样本空间和它的分类中,利用相似性运算,获得最接近于被分类的K个样本,并根据K个抽样的选票确定待分类的类别。在实际计算中,一般采用距离来描述两个样本的相似性。距离越近,相似性越强,距离越远,相似 性越低[6]。测量距离的方法有很多种,比如闵可夫斯基距离、曼哈顿距离、欧氏距离和切比雪夫距离,其中欧氏距离是最常用的距离计算方法。假设两个m维样本:

xi与xj的欧几里得距离定义为:
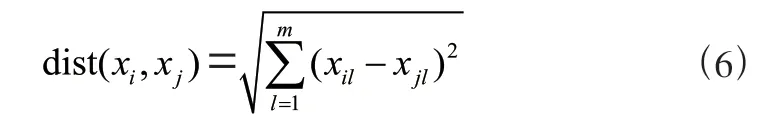
式中:xil表示第l 个点的第i维坐标,xjl表示第l 个点的第j维坐标。
给定训练样本集S={t1,t2, …,ts}和一组类属性C={C1,C2,…,Cm}(m<s),要对待分类样本t进行分类,K 近邻算法的基本步骤为:
(1)先求出t与S中所有训练样本ti(1 ≤i≤S)的距离dist(t,ti),并对所有求出的dist(t,ti)值递增排序;
(2)选取与待测样本距离最小的K个样本,组成集合N;
(3)统计N中K个样本所属类别的频率;
(4)频率最高的类别做为待测样本的类别。
3 模型评价
3.1 评价指标
在机器学习中,对机器学习模型进行评价是一个重要的环节。在此基础上,采用了精确度、精确度、召回率、F1_得分等方法对算法进行了评价。HeartDisease 是用来判断患者是否患心脏病的标签属性分成两类,根据数据预处理将字段值中的“Yes”用“1”表示代表有心脏病,字段值中的“No”用“0”表示代表的是没有心脏病,P代表阳性样本,N代表阴性样本。各种性能指标定义如下:

式中:TN 代表预测为假实际为假的样本个数,TP 代表预测为真实际为真的样本个数;FP 代表预测为真实际为假的样本个数,FN 代表预测为假实际为真的样本的个数。
3.2 实验分析
对所建立的决策树模型(DT)和K 近邻(KNN)模型进行训练。由于Heart Disease 字段是标签列,在模型预测时,在特征子集中要将Heart Disease 列去除,并在模型的预测中进行了交叉验证。引用Sklearn 库中train_test_split,把数据集分成两个部分。其中,测试数据集占的比例为20%,数据集拆分之后,对数据集进行拟合操作,并且对数据集吻合度进行评估。最后采用十折交叉验证方法评估模型的性能,交叉验证的过程为使用训练集训练出10 个模型,用10 个模型分别对交叉验证集计算得到代价函数的值,选取代价函数值最小的模型,使用这个最小模型对测试集计算得到代价函数的值。
创建决策树模型(DT)算法的过程为进行参数优化时预设max_depth 的扫描值为[3,5,7,9,11,13,15] 这7 个值,min_samples_leaf 的扫描值为[1,3,5,7,9],然后对每组参数进行评估得到max_depth 的最佳深度为5.0,获得min_samples_leaf 的最佳值为7。选取最优特征作为分割特征。然后,将两个参数代入模型。创建K 近邻(K-Nearest Neighbors, KNN)模型算法的过程中K值的取值范围[1, 2, 3,4, 5, 6, 7, 8, 9, 10],选取这10 个值遍历,经过实验发现当K为1, 2, 3 时,K 近邻算法的分类准确率变化波动较大,说明不同类样本的特征分布较为密集,导致K值较小时,对分类准确率影响很大。当K值不断增大时,K 近邻的分类准确率呈现减小的趋势。当K值取5 时,分类准确率最高,将参数值带入K 近邻算法模型在数据集上求得模型评估参数的值。
通过上述两种调参之后的算法在心脏病数据集上进行测试得到算法模型的评价指标:准确率(Accuracy)、精确度(Precision)、召回率(Recall)、F1_得分(F1_score)等指标,指标取值范围[0,1],结果如表2 所示,从表中可以看出K近邻算法模型的准确率为0.907,精确度为0.358,而决策树模型的准确率为0.866,精确度为0.235。
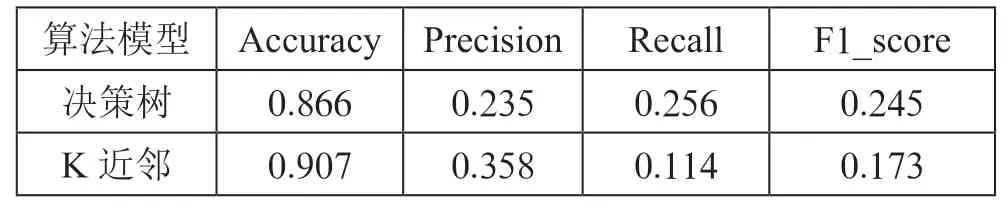
表2 模型评价指标对比
对两种用于心脏病预测的模型进行对比,对比结果进行可视化如图2 所示,从ROC 曲线图中可以看出K 近邻算法模型要优于决策树算法模型。
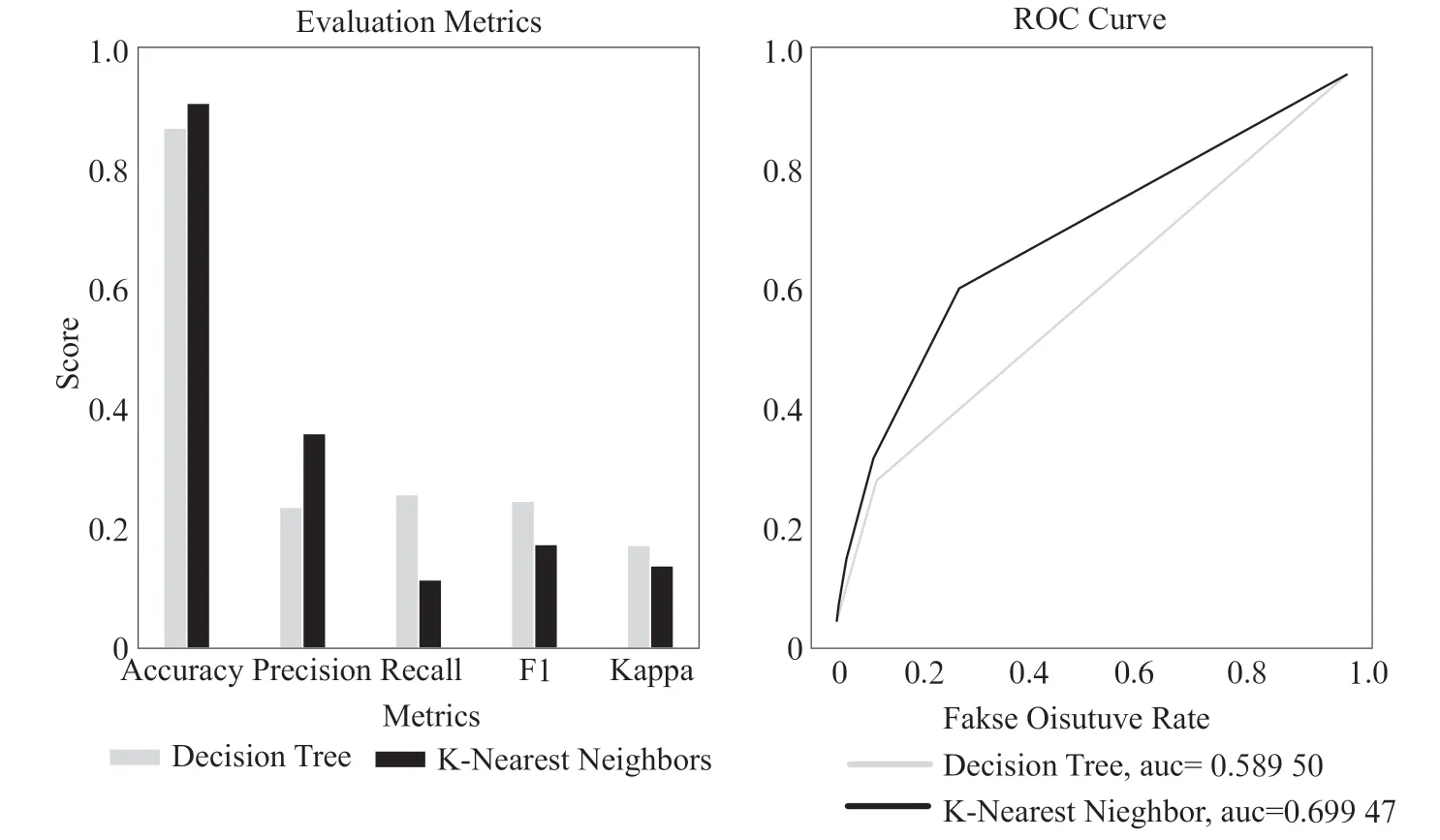
图2 模型结果对比
4 结 论
本论文的主要研究目的是建立一种可以帮助医生进行心脏疾病预测的机器学习算法模型,通过将决策树算法和K近邻算法的参数进行优化,寻找适合心脏病预测的最优参数值。实验结果显示,参数优化后的K 近邻算法模型对预测心脏病的准确率达到了0.907,要比决策树算法准确率高,因此K 近邻算法更适合做心脏病预测诊断模型。与其他的研究结果相比较,本文所得到的结论是比较满意的,可以更准确地反映病人的病情,但是,这些预测值仍然不够精确,因此,心脏病预测的模型还有改进的余地。本文的研究也可以为多类别的应用提供一种新的模型。未来研究的重点是提高预测模型的精确度,提高模型的使用效率,以及在许多疾病的算法分析、模型构建和预测研究中的应用。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
保健与生活(2019年19期)2019-11-06
科学与信息化(2019年28期)2019-10-21
健康管理(2017年5期)2017-07-05
科学与财富(2016年32期)2017-03-04
中学科技(2014年12期)2015-01-06
决策与信息·下旬刊(2013年1期)2013-03-11
