
基于SVM 和差分进化算法的输变电工程数据预测与评估模型设计
2022-11-18 14:01:32沈华强丁云峰范殷伟
电子设计工程 2022年22期
沈华强,杨 玲,李 皓,丁云峰,范殷伟
(1.国网浙江省电力有限公司,浙江杭州 310007;2.国网浙江省电力有限公司湖州供电公司,浙江湖州 313000)
随着我国迈入“十四五”规划的新篇章,对电力工业的发展提出了更高的要求,电网项目的投资力度也在不断加大。输变电工程作为国家电网电力输送的核心工程,其建设水平在一定程度上决定了电网的供电可靠性。由于输变电工程项目的建设规模较为庞大,在项目的推进过程中需要考虑多种因素的影响。目前,在对输变电工程的数据进行分析估算时,通常是在采集较多近似工程样本的基础上以传统的人工分析总结为主,结合特定的计算公式进行预测与评估。该分析结果较为依赖人工的经验,这导致在项目开展时受多种因素影响使得项目数据的预测和评估与实际结果存在较大偏差,从而造成项目管理和建设的难度显著上升[1-2]。而随着智能计算的不断进步,时序预测法[3]、灰色模型[4]以及回归分析[5]等方法逐步被应用于输变电工程数据的预测与评估之中。当前,开展科学的输变电工程数据预测与评估方法研究,实现对工程项目合理的精益化管理,已成为了现阶段电力领域的热点研究方向[6]。
1 输变电工程数据特征提取
1.1 输变电工程数据特性分析
输变电工程通常涵盖输电线路工程和变电工程。在实际的项目进行过程中,项目各方一般仅会对工程数据做简单记录,并未深入地对数据进行核验与校正等工作。在进入到最终的数据处理环节前,通常并未采取严格的数据预处理措施。研究表明,输变电工程项目的数据样本在经过一定的预处理环节后,真正适用于输变电工程项目数据分析与预测的数据样本,大约为原有样本容量的50%。而在实际的输变电工程项目开展过程中,由于项目自身受多种因素的影响,造成了输变电工程项目的数据特征维度较多,故整体的数据复杂度显著提升,且呈现出较为明显的小样本条件下的高维度特征。
然而,典型的小样本数据在特征维度较高的情况下,时常会存在某一维度的绝对样本容量较少的问题,而在实际的数据分析与预测时则通常存在明显的“过拟合”问题。此时,高维特征数据会导致分析模型运算效率的显著下降,进而影响输变电工程数据分析与预测的准确度。因此要实现对输变电工程数据的精确预测与评估,需要对输变电工程的样本数据进行特征提取,从而消除高维特征所造成的不利影响。
1.2 基于RBF的输变电工程数据特征提取
为了降低输变电工程项目中小样本数据的高维特征导致的不利影响,文中引入随机比特森林(Random Bits Forest,RBF)算法用于提取数据特征,其具体的运算步骤如下:
1)输变电工程数据特征识别
该文基于k-means 聚类算法实现输变电工程数据的聚类提取并得到C个特征集。其中,特征F1与F2两者的相关距离计算公式如下所示:
其中,Vi表示的是特征簇所映射的特征向量,的计算与式(2)同理。
2)输变电工程数据特征权重计算
利用重采样方法获取N个训练样本集合及OBB测试集,通过采用随机性的特征交换从而得到交换后的训练集。采用RBF 算法对交换前后的训练集分别进行准确率学习,获取相应的OBB 准确率λi与,然后计算特征权重fw:
其中,表示的是RBF 运算时训练集与交换后的随机特征训练集的OBB 准确率的偏差。将λi与分别定义为交换前后训练集的准确率,εF表示特征偏差的平均值,n表示所获取的特征数量,S2表示特征偏差的方差。则特征得分可定义为:
3)删除冗余特征构成相应的特征集合
由所获取的特征总数设置对应数量的特征类别,删除特定阈值P、Q以及多余的特征数。当输变电工程数据聚类识别结束后,若特征类别高于阈值P,则去除G值最低的特征类别中的d/100 特征,去除的特征总数由特征类别数量决定。若特征类别数量低于阈值P且G值最低特征类别的特征总数高于阈值Q时,则去除G值最低特征类别中的d/100 特征;若特征类别数量低于阈值P且G值最低特征类别的特征总数低于阈值Q时,则不采取特征删除操作,直接得到相应的样本特征子集。随后判断终止条件是否符合,若是则得到最终的特征子集;反之则继续迭代。
利用RBF 提取输变电工程数据样本特征能有效完成对高维数据的降维,并充分扩大样本容量从而防止高维小样本数据在进行分析时过拟合现象的发生。其有效提升了输变电工程数据预处理环节的效率,确保了后续数据分析与预测的准确性。
2 输变电工程数据预测与评估模型
2.1 支持向量机回归模型
支持向量机(Support Vector Machine,SVM)的实质是一种自监督学习的机器学习算法,对于具有高维特征的小样本数据处理具有显著优势。因此,该文利用SVM 作为输变电工程数据分析与预测的底层模型。SVM 的核心原理是利用具有非线性特性的映射函数ψ对样本实施映射,使样本得以被映射到高维的特征空间Ω中并完成相应的线性回归,其可以被等效为在原始空间内完成非线性回归[7-8]。
将数据样本定义为(xq,yq),其中q=1,2,···,r,xq∈Rm,yq∈R,r表示的是样本的总数量。SVM 的估计函数可被定义为:
其中,α表示高维特征空间Ω中的加权矢量,B∈R为函数对应的偏置,ρ为密度函数。SVM 的优化目标定义为:
其中,e表示损失函数,与βq表示松弛因子,CP表示惩罚因子,其通常被应用于均衡函数的平滑性与误差超额之和。
根据上述条件,将拉格朗日算子ζ和ζ*引入到目标函数中,从而得到SVM 回归的对偶目标:
由于径向基核函数所映射的特征空间维数是无穷的,因此固定数量样本在此空间中一定具有线性可分的特性,这也使得径向基核函数的应用最为广泛。所以,该文采用的径向基核函数定义为:
其中,μ为核函数参数。
SVM 参数的设定结果对于回归函数具有较大的影响作用。其中,惩罚因子CP的取值会影响到SVM的复杂度与训练时的误差,其取值过小或过大均会导致欠拟合及过拟合现象,进而使得模型的泛化性能下降。损失函数e则会对支持向量的总数造成影响,过小的取值会使运算精度提升但同时也会导致支持向量总数增加;反之,过大的取值则会降低运算精度并减少支持向量的总数。核函数参数μ的取值会对样本的分布范围造成一定的影响[9-10],惩罚因子与核函数参数的取值对于SVM 模型的预测准确性和泛化性能有着直接影响。因此,该文引入差分进化算法实现对以上SVM 参数的寻优,最终的优化目标函数预设为交叉验证条件下的均方差:
2.2 差分进化算法优化支持向量机
2.2.1 差分进化算法原理
差分进化(Differential Evolution,DE)算法的本质是利用种群内部差异完成随机搜索的智能优化算法。其基本原理是从现有种群内部获取搜索步长与方向,并在种群内部完成交叉及变异以获取新个体,从而在新旧个体之间完成筛选并留存更优的个体至下一代。整体的流程包括:初始化种群、变异操作、交叉操作以及筛选操作等[11-12]。
1)初始化种群
在对种群执行初始化操作前,首先要设定参数上下限,进而随机生成特定约束下的初始化种群,由此可得:
其中,a=1,2,…,Na,b=1,2,…,Nb。Na表示种群的初始个数,Nb表示种群内部的维度。χa,b(0)表示第0 代种群内部的第a个独立个体,b表示种群内部的第a个独立个体的第b维。各自代表第b维的上限与下限,rand(0,1)是0~1 范围内的随机数。
2)变异操作
DE 算法利用差分法执行对个体的变异操作,通过从种群内部筛选获得四个互不相同的独立个体得到对应的差分向量,进而完成逐代最优个体的变异。由此可以在确保种群具有多样性的前提下有效提升收敛速率,其具体计算公式如下:
其中,υi(g+1)表示完成变异操作后所获得的个体;χbest(g) 表示第g代的最优个体;R1、R2、R3,R4 ∈[1,2,…,Na]表示互不相同的随机值;ℏ 表示尺度因子,通常可对差分量进行尺度变换。
3)交叉操作
交叉操作的实质是为了随机地筛选以得到个体,其具体公式为:
其中,Pc表示交叉操作发生的概率。
4)筛选操作
DE 算法执行筛选操作主要是基于贪婪思想,即将更优的个体当作新个体,其公式为:
其中,f表示的是优化目标的函数约束,Ua,b(g+1)表示通过变异操作与交叉操作获取的新个体。
2.2.2 优化流程
DE 算法可通过寻优使得SVM 具有最优的预测性能[13-14],其详细步骤为:
1)在设定目标函数的基础上,初始化种群参数,并设置待优化参数的取值范围,从而生成相应的随机组合(Cp,η);
2)将现有的随机组合(Cp,η)定义为SVM 初始参数,并将SVM 应用于训练样本数据,得到初始预测结果并代入实际值进行检验;
3)计算目标函数结果并判定是否达到预设阈值或最大迭代次数,若是,则转到步骤8),否则继续计算;
4)从当前代数的种群中筛选出四个互不相同的独立个体并执行变异操作,生成新一代变异的独立个体;
5)对新一代的独立个体执行交叉操作,生成新一代的实验个体;
6)根据贪婪思想对实验个体执行筛选,选出新一代个体;
7)在新一代种群中计算生成新的参数组合(Cp,η),然后转到步骤2);
8)得到最优的参数组合,获取最优的DE-SVM模型来对数据进行分析预测。
2.3 模型运算流程
该文在设计输变电工程数据预测与评估模型时,首先需要获取输变电工程数据,目前的数据主要为投资数据,然后选择合适的数据划分训练集与测试集。随后通过对数据的特征提取获取所需的数据特征,再将该特征输入到SVM 模型中进行预训练。根据上文的优化流程,利用DE 算法优化获取最优的SVM 模型,并将训练好的模型对测试集数据进行分析预测。其具体流程如图1 所示。
3 算例分析
为了验证所提出的输变电工程预测与评估模型的准确性,保证模型的工程实用价值,该文选取浙江省2012-2020 年实际已完工的输变电工程项目中,杆塔更换工程与杆塔基础设施建设工程造价的100组数据作为样本。在Matlab 2018b 的计算环境下,用前80 组数据作为训练集,后20 组数据作为测试集。用训练好的模型对测试集的样本数据进行预测,通过分析预测结果及实际工程造价的平均偏差并与BP 神经网络和未优化的SVM 进行对比,从而检验模型的预测评估效果[15-16]。
3.1 杆塔更换工程数据预测
用训练集训练该文所提出的预测与评估模型[17-18],然后将测试集数据输入到训练好的模型中,所得到的结果与其他算法的结果对比如表1所示。
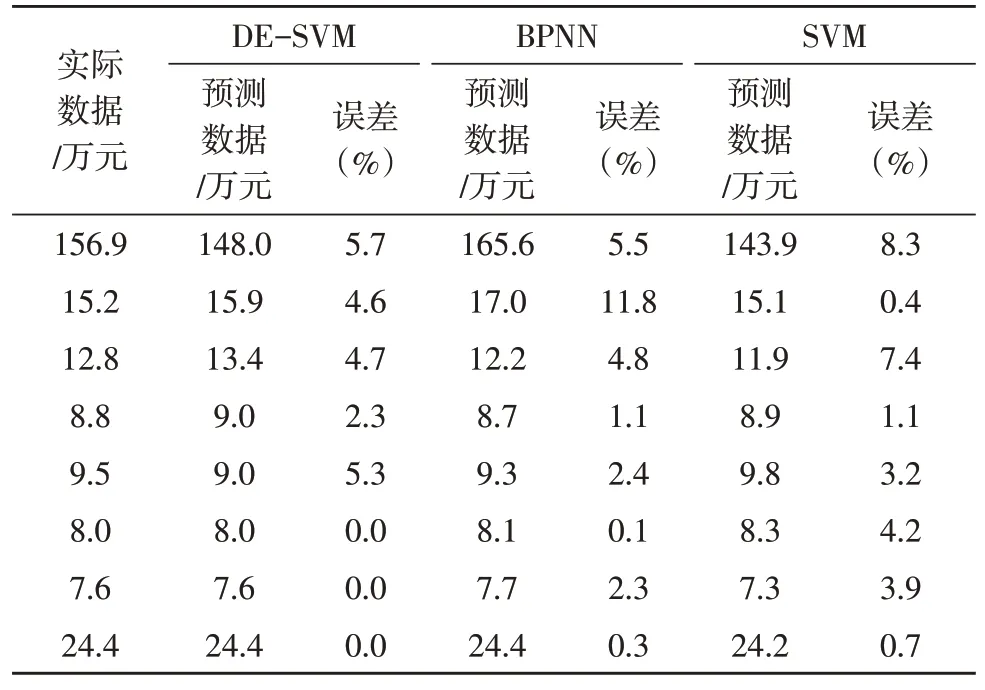
表1 杆塔更换工程造价数据预测与评估数据
当采用该文提出的DE-SVM 模型对杆塔更换工程的造价数据进行预测时,多数样本的预测位于5%以内,少部分误差在5%以上,但均未超过6%,平均误差为2.8%。而采用BP 神经网络进行数据的预测时,多数样本的误差均已超过5%,其平均误差为5.9%。未进行优化的SVM 的预测误差虽低于BP 神经网络,但普遍显著高于DE-SVM 模型,其平均误差为4.2%。
3.2 杆塔基础设施建设工程数据评估
由于杆塔基础设施建设工程的特征较多,因此最终结果主要用于与实际值进行评估对比,与其他算法的对比情况,如表2 所示。

表2 杆塔设施建设工程造价数据预测与评估数据
由表2 可知,当采用该文提出的DE-SVM 模型对杆塔基础设施建设工程的造价数据进行评估时,误差同样也未超过6%。
由以上分析结果可以看出,该文提出预测与评估模型的计算结果基本位于合理范围,能够为输变电工程的数据分析提供较为准确的参考,且具有较高的工程实际应用的价值。
4 结束语
该文针对现有的输变电工程数据分析的难点,针对性地设计了一种输变电工程数据预测与评估模型。该模型通过提取输变电工程数据的特征进而降低数据维度,然后利用差分进化算法实现SVM 模型的参数寻优,进一步提升模型的预测与评估精度。最终使得模型能够对输变电工程数据进行准确的预测与评估。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
劳动保护(2019年7期)2019-08-27 00:41:02
红土地(2018年7期)2018-09-26 03:07:38
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
学习月刊(2015年22期)2015-07-09 03:40:48
中学科技(2015年1期)2015-04-28 05:06:12
当代畜禽养殖业(2014年10期)2014-02-27 07:59:49
