
数字图书馆个性化服务行为信息挖掘系统设计与实现
2022-11-18 14:01:48李火苗
电子设计工程 2022年22期
李火苗
(商洛学院图书馆,陕西商洛 726000)
随着我国经济发展的不断进步,我国高校教育教学事业的发展越来越好。为了向高校的教学事业提供正确的指导,应利用信息挖掘技术针对个性化交互服务行为信息进行二次处理,以此实现教学资源的共享。但传统信息挖掘系统存在响应速度慢的缺陷,该文针对数字图书馆进行个性化服务行为信息挖掘系统的设计。
1 数字图书馆信息挖掘系统架构
1.1 云服务平台基本框架设计
针对个性化服务行为信息挖掘系统中的云服务平台框架进行设计时,应充分结合图书馆的实际情况,将图书馆内部资源进行整合,并将图书馆内部资源进行合理利用。通过该方式可为系统提供大量数据,有利于个性化服务行为信息挖掘系统的稳定运行。针对云服务平台的框架进行设计的过程中,应将基础功能设计作为基础,将图书馆内部资源作为系统设计的主要内容,并将解决读者需求作为系统云服务平台基本框架设计的根本目标,以此设计出将成本低、扩展性高、适应能力强等特点融为一体的云服务平台基本框架[1-2]。
1.2 信息挖掘系统总体架构设计
针对个性化服务行为信息挖掘系统的总体架构进行设计时,主要采用SSH 框架作为个性化服务行为信息挖掘系统的核心架构。通过对SSH 框架进行研究发现,该框架具有结构简单、开发周期较短、维护方便等特点,被广泛应用于多种领域。数字图书馆个性化服务行为信息挖掘系统总体架构如图1所示[3]。
1.2.1 信息挖掘系统用户层
对个性化服务行为信息挖掘系统架构的用户层进行设计时,主要应用JSP技术,该技术凭借自身的高效处理优势,在多种领域中被广泛应用,可用于个性化服务行为信息挖掘系统和用户之间的交互逻辑处理。
1.2.2 信息挖掘系统业务层
为保证个性化服务行为信息挖掘系统的稳定运行,对个性化服务行为信息挖掘系统业务层架构进行设计时,采用SSH 框架针对系统业务层进行开发,利用SSH 架构将系统业务层进行层次细化,主要包括Web 层、Service 层、DAO 层以及PO 层。通过对个性化服务行为信息挖掘系统业务层架构进行细化,个性化服务行为信息挖掘系统的维护将更加方便,且系统开发比较简单,便于操作[4-5]。
1.2.3 信息挖掘系统数据挖掘层
对个性化服务行为信息挖掘系统的数据挖掘层架构进行设计时,主要利用数据挖掘工具Weka 对数据进行处理,将数据挖掘工具Weka 作为个性化服务行为信息挖掘系统数据挖掘层架构的核心,结合决策树分类、神经网络、聚类等算法对个性化服务行为信息挖掘系统的数据进行规划处理,提高个性化服务行为信息挖掘系统的稳定性[6]。
1.2.4 信息挖掘系统数据层
信息挖掘系统数据层主要包括读者个人信息、图书信息、借阅信息以及读者浏览信息,该层具有一定的数据存储能力。因此,应针对图书馆内部数据进行资源整合,并利用该关系型数据库将数据信息进行存储。
2 数字图书馆信息挖掘系统硬件设计
2.1 信息挖掘系统控制器设计
个性化服务行为信息挖掘系统包含大量图书馆内部图书信息,由于个性化服务行为信息挖掘系统所容纳的数据过多,造成个性化服务行为信息挖掘系统出现响应速度慢等问题。需要在个性化服务行为信息挖掘系统的硬件端口处增加控制器,芯片部分主要采用意法半导体的超高密度芯片TQMA93RE7,而半导体部分主要采用控制器体系架构Grema-T1 内核,该部分可作为个性化服务行为信息挖掘系统控制器的中央处理单元[7-8]。
通过对个性化服务行为信息挖掘系统控制器原始半导体指令集进行研究发现,该指令集只包括两种状态,分别是32 位半导体供应状态以及16 位代码宽度的Thumb 状态,而该研究中的半导体Grema-T1内核主要采用Thumb-1 指令集,通过Thumb-1 指令集的选择,可使个性化服务行为信息挖掘系统硬件部分具有高效的数据处理能力以及操作简便的优势。
2.2 信息挖掘系统数据库设计
2.2.1 数据库概念模型设计
个性化服务行为信息挖掘系统内部存在大量数据信息,可造成系统因数据过多而出现响应速度慢等问题。应在系统内部建立数据库,对于系统的稳定运行具有重要意义。主要采用Hadoop 技术架构,并且数据库设计过程中,应充分结合用户的实际需求,其中用户的需求主要体现在信息的提供、保存、更新以及查询等方面,所以应重视数据的输入和输出,并在此基础上进行E-R 图的设计,为系统的后续发展做铺垫[9-10]。
2.2.2 数据库逻辑结构设计
首先应确定数据库的物理数据结构,以此对系统数据库内部管理系统形成结构约束。通过研究发现,在数据库的设计过程中易出现数据冗余,而通常情况下针对数据冗余的程度进行消除时,主要采用“范式”定义的方式进行处理。该研究主要选用最合适的第三范式,但是第三范式在一定程度上可降低系统的数据处理速度,对于系统的开发质量具有一定影响,为此,应充分考虑范式规则和用户的使用体验,结合E-R 模型系统进行数据库逻辑结构设计,读者档案表结构如表1 所示,库存信息表结构如表2 所示,借出信息表结构如表3 所示[11]。
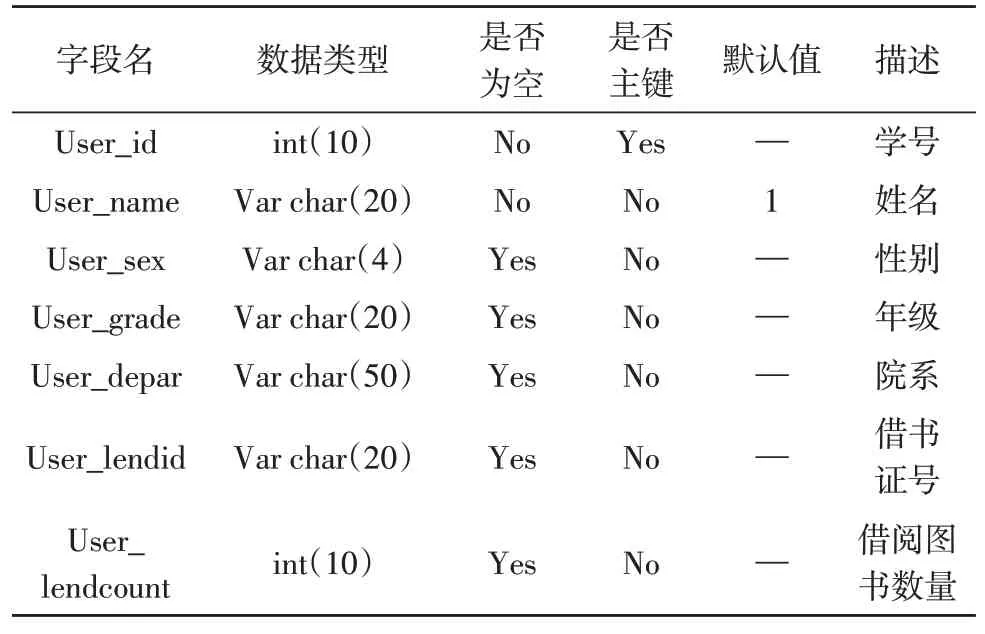
表1 读者档案表结构
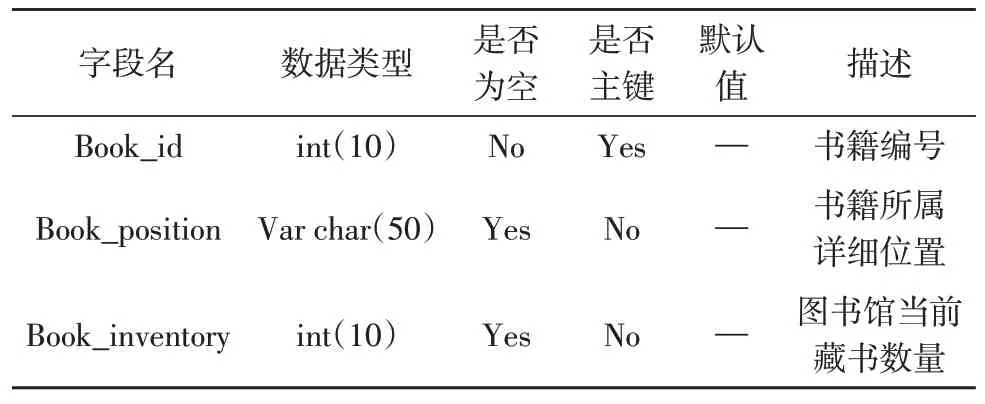
表2 库存信息表结构
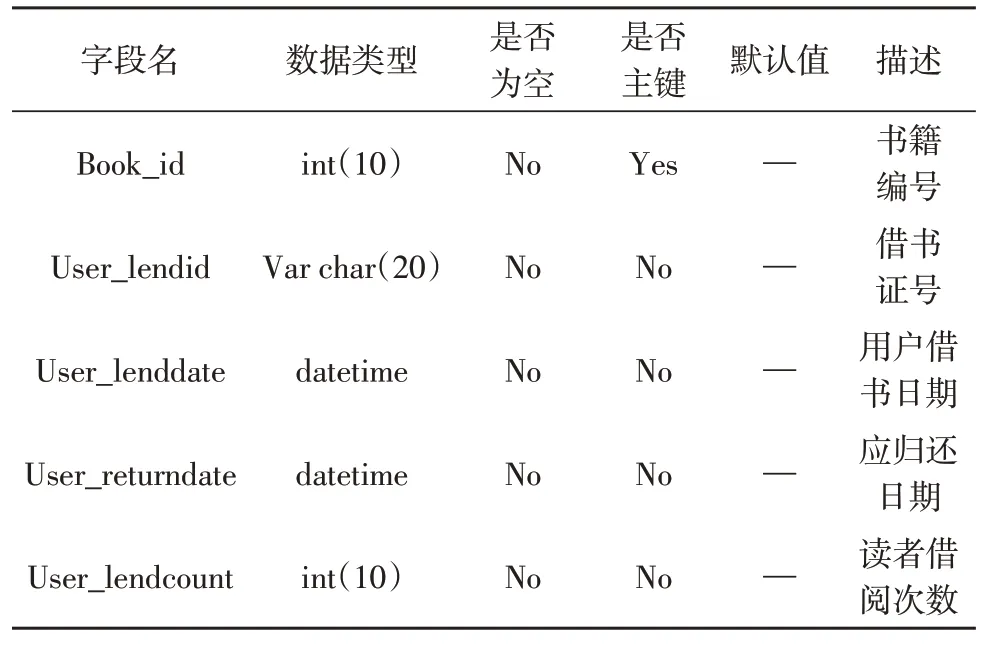
表3 借出信息表结构
2.2.3 数据库E-R图设计
数据库设计对于个性化服务行为信息挖掘系统的稳定运行具有重要意义。因此,应结合系统数据库的基本结构,为个性化服务行为信息挖掘系统提供高性能的结构设计,个性化服务行为信息挖掘系统数据库E-R 结构如图2 所示[12-13]。
3 数字图书馆信息挖掘系统软件设计
3.1 信息挖掘系统信息存储流程
为实现个性化服务行为信息挖掘系统的信息存储功能,应针对系统内部数据的存储流程进行设计。该设计主要建立在模块化程序的基础上,针对信息存储流程进行一次设计,该设计可在系统数据库中调用多次,而针对系统信息存储部分的修改功能具有一定独立性,该功能主要通过系统应用程序的源代码来实现,个性化服务行为信息挖掘系统信息存储流程如图3 所示。
3.2 数字图书馆信息挖掘系统决策树算法
为保证个性化服务行为信息挖掘系统针对信息进行挖掘时,产生的数据皆为有价值信息,应根据类标号进行分类。该文针对决策树算法进行构建,该算法中存在的每个节点皆代表一个属性,而分支则代表测试结果的输出情况[14-15]。R表示节点、C表示信息分组,可采用信息增益率的最高属性来对节点R进行分裂,数据元组分类期待值为:
若此时的信息属性A存在多个信息分组的值,则期待值为:
通过将数据信息存放至系统数据库中进行信息存储过程设计,并充分结合决策树算法,即可完成个性化服务行为信息挖掘的全过程,实现个性化服务行为信息挖掘系统的软件设计。
4 数字图书馆信息挖掘系统测试
4.1 信息挖掘系统运行环境
个性化服务行为信息挖掘系统运行环境如表4所示。

表4 个性化服务行为信息挖掘系统运行环境
4.2 信息挖掘系统测试流程
对该系统进行测试时,应充分了解系统内部协调能力以及数据的流向情况,并结合上述运行环境针对系统进行测试,为保证测试结果的准确性,将测试次数设置为50 次,系统页面响应时间对比如表5所示。

表5 系统页面响应时间对比表
通过对测试结果进行分析可知,个性化服务行为信息挖掘系统在不同界面的响应时间具有明显的差异性,其中传统信息挖掘系统平均响应时间为3.23 s,而该文信息挖掘系统平均响应时间为0.8 s,由此可证明,该研究具有一定可行性[16]。
5 结束语
综上所述,由于图书馆内部信息过多,可造成个性化服务行为信息挖掘系统针对信息进行挖掘时,出现响应速度慢等问题。为解决该问题,该文针对个性化服务行为信息挖掘系统进行设计,并针对该系统进行测试,测试结果表明,该文信息挖掘系统平均响应时间更快,相对于传统信息挖掘系统平均响应时间而言,该研究更具优势。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18 07:31:10
汽车工程(2021年12期)2021-03-08 02:34:30
文苑(2020年4期)2020-05-30 12:35:12
新闻传播(2018年12期)2018-09-19 06:27:10
电信科学(2017年6期)2017-07-01 15:45:17
财经(2017年2期)2017-03-10 14:35:35
汽车与新动力(2016年6期)2017-01-04 10:50:48
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
财经(2016年6期)2016-02-24 07:41:51
