
基于预训练语言模型的电子乐谱情感分类研究
2022-11-17 02:12沈哲旭曾景杰林鸿飞
复旦学报(自然科学版) 2022年5期
沈哲旭,曾景杰,丁 健,杨 亮,林鸿飞
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
1 介 绍
音乐具有传达情感的功能,与听众之间产生情感共鸣是音乐创作的重要原则之一。对音乐的情感进行正确分析和预测,在诸多现实场景中均具有较高的应用价值。例如,将网络平台中的海量音乐数据按情感分类,可以方便用户检索,也可更好地针对用户喜好进行推荐;利用情感信息来指导音乐生成,可以自动化地提供与场景氛围相匹配的音乐;用音乐进行心理治疗时,治疗师可根据音乐的情感分析结果选择出疗效更好的音乐[1]。乐谱作为准确记录各类音乐信息的载体,一直是人们进行音乐学习、传播与分享的重要媒介。常见的记谱法有五线谱、简谱、TAB谱等,分别应用于不同的乐器与音乐形式。随着计算机音乐技术的发展,陆续产生了多种适用于计算机存取的电子乐谱格式。其中,由Good[2]在2001年基于可扩展标记语言(eXtensible Markup Language,XML)提出的音乐扩展标记语言(Music eXtensible Markup Language,Music XML)[1]电子乐谱格式具有描述精确、检索方便等优点,同时适用于音乐表示与网络传输,在随后的数年之内迅速成为了计算机制谱软件的通用标准。本文基于预训练语言模型,对Music XML乐谱所表达的音乐开展情感分类研究。
国内外对音乐情感分析的研究从21世纪初开始兴起,其中绝大多数研究是针对音频音乐或歌词文本开展的[3]。2005年,Lu等[4]利用音频片段的3种特征,基于高斯混合模型提出了一种分层架构,完成了音乐的情感分类任务。2012年,李静等[5]用歌词中的情感词建立情感向量空间模型,并考虑情感词与所属歌曲情感标签的相似度来实现歌曲分类任务,其改进方法的分类准确度有了较为明显的提升。2013年,Hwang等[6]提取了节奏、动态和音高等音频特征来表示音乐样本,并利用K-最近邻分类器来输出结果。随着数据规模的增加与计算机算力的提升,深度学习(Deep learning)逐渐成为音乐情感分类的主流手段。2019年,Zhou等[7]使用无监督的深度神经网络进行音乐的多模态特征学习,并引入一系列回归实验评估学习到的特征,该项研究证明了深度神经网络具有良好的特征学习能力。2021年,赵剑等[8]提出了一种基于知识蒸馏与迁移学习结合的多模态融合方法,该方法在音乐情感识别任务中的准确率有明显提高,泛化能力也得到了提升。
针对符号音乐(Symbolic music)或电子乐谱开展的情感分类研究相对较少。2010年,Cuthbert等[9]开发了用于计算音乐学分析的工具包music21,大大简化了对符号音乐以及电子乐谱的解析与特征提取过程。2018年,Sun等[10]运用统计学方法探究歌词与其对应音符的音乐特征的情感关联,发现歌词中情感色彩浓烈的词语所对应的音符也往往具有异于其邻近音符的音乐特征。此外,该项研究直接对Music XML电子乐谱进行量化分析,以避免因不同演奏者或演唱者在演绎上的区别造成的听感不一致,也为后续的基于音乐序列的研究提供了一定的指导。符号音乐与自然语言都具有类似的序列特征,故自然语言处理的相关研究手段同样可应用于符号音乐的研究中。2019年,Ferreira等[11]构建了基于VA(Valence-Arousal)模型[12]进行情感标注的符号音乐数据集VGMIDI,并将自然语言处理的研究方法应用于对音乐序列的分析研究中,使符号音乐的情感分类与生成工作有了新的解决方案。
近年来,以基于Transformer的双向编码器(Bidirectional Encoder Representation from Transformers,BERT)[13]为代表的基于大规模文本数据训练得到的预训练语言模型(Pre-trained Language Model,PLM)成为了主流的文本表示模型。相较于早期的语言模型,预训练语言模型采用海量的语料进行训练,模型参数量规模得到了极大的扩增,也能够更好地提取文本特征。在完成不同的任务时,需要将预训练模型依据任务目标增加不同功能的输出层联合训练,进行精调(Fine-tuning)以适应各类下游领域。“预训练+精调”已成为了目前解决自然语言处理相关任务的主流范式。2021年,Zeng等[14]提出了一种符号音乐的编码方式——Octuple MIDI,并在超过150万条的符号音乐数据上采用小节级别的掩码训练得到MusicBERT模型,该模型经过精调后在多项符号音乐理解任务中都达到了较高水平。Chou等[15]在多个符号音乐数据集上进行预训练,得到MIDIBERT-Piano模型,其在主旋律抽取、力度预测、作曲家分类以及情感分类等下游任务中均大幅度超越了未经过预训练的基于循环神经网络的模型。
本文基于预训练语言模型构建的歌词情感分类模型和音乐序列情感分类模型可以较好地学习歌词文本和音乐序列的语义特征,系统的整体表现与未经预训练的方法相比得到显著改善。
2 数据集构建
2.1 Music XML电子乐谱数据集
MusicXML是电子乐谱的一种通用格式,为了方便乐谱的存档、传输及在应用程序之间的共享而设计。正如音频音乐的通用格式MP3一样,MusicXML也已成为了共享交互式电子乐谱的行业标准。MusicXML电子乐谱的一般结构为整张乐谱包括若干个声部(Parts),每个声部之中以小节为单位记录乐谱的音乐信息。音乐信息由元素(Elements)和属性(Attributes)来表示,各类音乐参数均可详细记录。如图1所示为一段MusicXML代码示例。
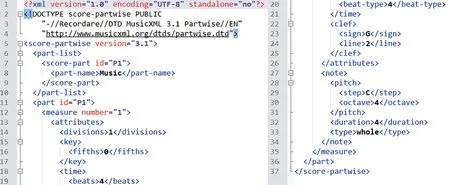
图1 Music XML代码示例Fig.1 Sample of MusicXML code
现有的公开的Music XML电子乐谱数据集较少,本文利用爬虫(用Python编写实现)从互联网上获取Music XML乐谱数据以供研究,使用music21工具包对数据集中所有乐谱进行解析,并提取歌词文本与音乐序列。经检查发现,乐谱数据集中存在一定比例的低质量数据,如乐谱内容为空、音乐序列均为相同单音、无歌词、歌词均为无意义的衬词、歌词非英语等,故进行数据清洗工作以将这部分低质量数据去除。此外,进行乐谱节拍的筛选,仅保留拍号为4/4拍的乐谱数据,以便于音乐序列分析模型的构建。经过数据清洗之后,用于后续研究的Music XML乐谱数据规模在5 000条以上。
2.2 含有情感标签的英文歌词数据集
本文构建含有情感标注的歌词文本数据集,用于歌词文本情感分类模型的训练。多数网络音乐平台允许用户自行创建并公开含有若干情感标签的歌单,其中包含的歌曲均经过用户人工筛选并分类,用户标注的情感标签可作为歌曲情感类别划分的重要参考。为了保证歌曲情感标注的准确性,本文选取的情感歌单播放量均在10万及以上级别,且仅选用“快乐”和“伤感”这两类较为强烈、明显的情感标签,分别作为正向(Positive)和负向(Negative)的判定标准。经初步筛查发现,数据集中的一些歌词存在前后两部分的情感表达不完全一致的现象,且情感波动较为显著,故数据清洗时将这样的歌词去除。在此基础上,采用回译的方式对原始数据进行数据增强,以扩大数据规模。具体操作为: 使用机器翻译系统,将歌词内容从初始的英文分别翻译为4种不同语言,再重新翻译为英文,并补充回原数据集中。歌词数据集的分布如表1所示。
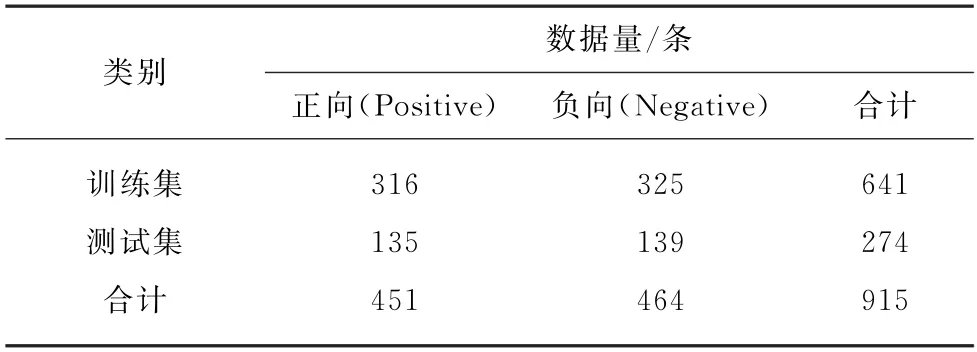
表1 含有情感标注的英文歌词数据集分布Tab.1 Statistics of sentiment-annotated english lyrics dataset
3 构建电子乐谱情感分类模型
3.1 构建歌词文本情感分类模型
3.1.1 基于情感词典的歌词文本情感分类模型
本文选用英文文本情感分析领域通用的标准情感词典SentiWord Net 3.0[16]作为歌词文本情感分类的基线模型之一。该词典中包含每个单词经人工标注的3个情感倾向值,依次为褒义、贬义和中性。通过对整段文字中单词的词频与情感值进行加权平均运算,可得到文本的情感得分,进而判断其情感倾向性。
3.1.2 基于TextCNN的歌词文本情感分类模型
卷积神经网络(Convolutional Neural Network,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,其所具有的独特的卷积处理与池化能力可避免对图像的复杂前期预处理,自动提取其高级特征,在图像处理领域有着广泛应用。Kim[17]于2014年提出的TextCNN模型使卷积神经网络的应用扩展到自然语言处理领域。首先将每个单词映射为一个词向量,作为整个网络的输入,然后经过若干卷积层学习到不同的特征后,通过最大池化层,使不同长度的向量变为定长表示,拼接成为一个特征向量,最后经过一个全连接层分类器输出分类结果,如图2所示。
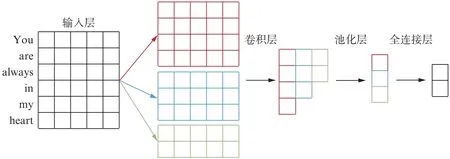
图2 TextCNN模型的结构Fig.2 Structure of TextCNN model
在本文的歌词情感分类任务中,使用预训练好的Glo Ve.6B.100d词向量数据作为词嵌入输入。先通过3种不同尺寸的滤波器将输入分割为不同长度的字节片段,随后依次经过卷积层和最大池化层,最后通过一个全连接层,输出歌词情感分类结果。
3.1.3 基于BERT+Bi-GRU的歌词文本情感分类模型
BERT是Devlin等[13]提出的一种自编码式预训练语言模型。其基于双向深层Transformer网络,拥有双向编码能力和强大的特征提取能力,在11项自然语言处理任务中取得了当时业界的最高水平,使自然语言处理进入了“预训练+精调”范式的新阶段。
BERT的预训练任务之一为掩码语言模型(Masked Language Model,MLM),该训练任务类似于填空,可使得模型对上下文关系有更好的理解。在BERT模型中,掩码(Mask)比例为15%,在这其中的80%用[MASK]标记来替换,10%替换为任意随机词,10%保持原词不变,这样的操作可避免双向语言模型导致的信息泄漏问题。BERT的另一个预训练任务为下一个句子预测(Next Sentence Prediction,NSP)。在该任务中,模型需要判断后一段文本是否为前一段文本的下一个句子。其中的正样本为语料库的两个相邻句子A和B,负样本将句子B替换为其他任意的语句。正负样本的比例设置为1∶1。
门控循环单元(Gated Recurrent Unit,GRU)是Cho等[18]提出的长短期记忆网络(Long and Short-Term Memory networks,LSTM)的一种变体,它将标准LSTM中的遗忘门和输入门组合到一个单独的“更新门”中,模型比标准LSTM模型更加简单,而性能表现几乎相当,能够很大程度上提高训练效率。GRU的单元结构如图3所示。
图3中:x t代表输入;h t-1与h t为相应节点的隐藏状态;r t和z t分别为重置门和更新门;h~t为候选隐状态。计算公式如下所示:
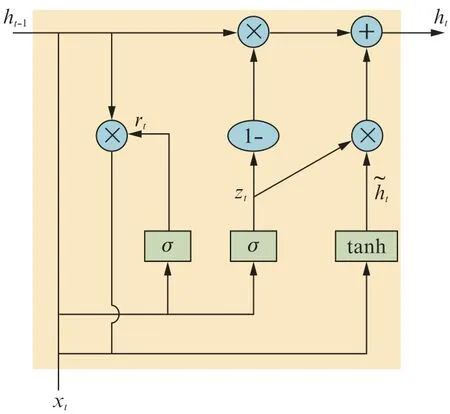
图3 GRU的结构Fig.3 Structure of GRU
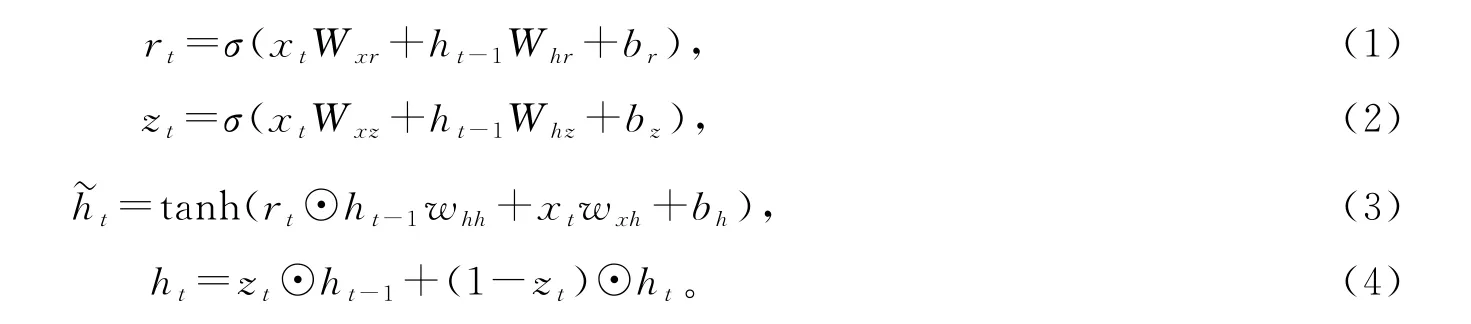
式中:⊙代表张量逐元素积;σ为Sigmoid函数,使得各门的取值范围保持在(0,1);W与b均为待优化的网络参数,其下标用以区分不同门的参数。
本文的任务中,首先将BERT预训练模型中的Transformer层进行冻结处理,保留其原有参数,将其输出的词句表示通过一个多层的双向GRU(Bi-GRU)进行下游任务的精调,通过Softmax分类器输出歌词文本的情感分类结果:
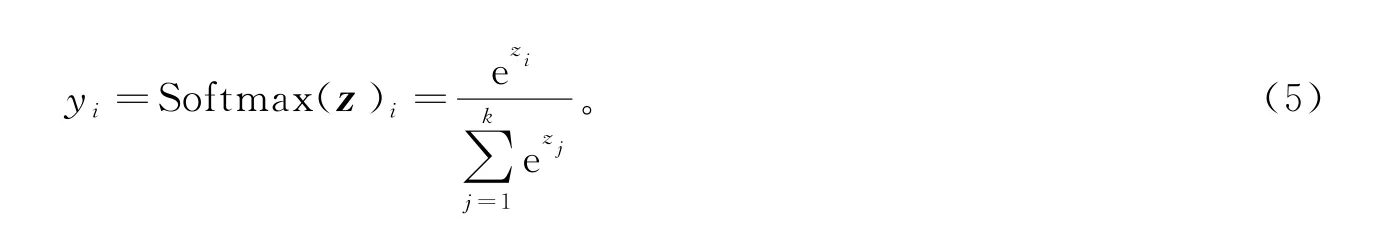
式中:z为输入向量[z1,z2,…,z k];k为类别数;y i表示输入向量属于第i个类别的概率。在本文的歌词情感分类任务中,类别数为2,故式(5)可简化为下面的形式,即Sigmoid函数:

完整的BERT+Bi-GRU模型结构如图4所示。
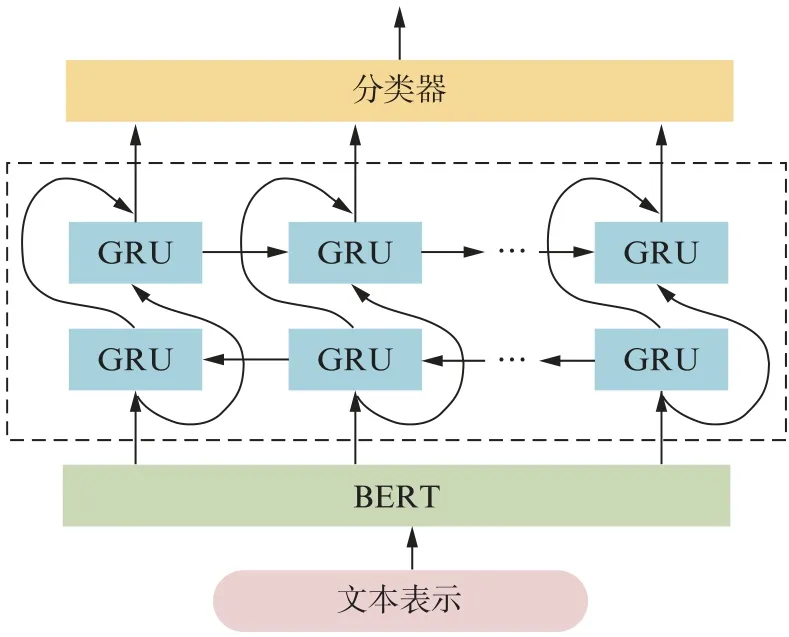
图4 基于BERT的歌词文本情感分类模型的整体结构Fig.4 Overall structure of BERT-based lyric text sentiment classification model
3.2 构建音乐序列情感分类模型
3.2.1 基于MIDIBERT的音乐情感分类模型(1) 预训练阶段
2.2节中构建的Music XML乐谱数据集均为无标注数据,可以用于预训练。将音乐数据输入至模型时,需要对音乐进行合理的表示,以便于模型对音乐信息进行处理。Hsiao等[19]提出的复合词(Compound Word,CP)是一种适用于深度学习的符号音乐序列表示方法,将音乐序列及其时间信息转换为高维向量的表示,使神经网络模型可以读取。本文的研究中将其进行简化,单个标记(Token)仅表示单个音符的相关事件,其具体结构为: 所在小节(新一小节的开始/小节内部)、分拍(以十六分音符为单位,4/4拍的音乐每小节有16个分拍)、音高(同MIDI事件范围,数值为0~127)、时值(以三十二分音符为单位)。一段音乐序列的简化的CP表示方式的结构如图5所示。
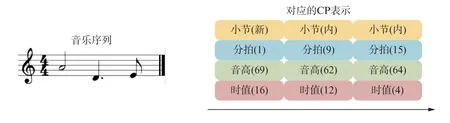
图5 符号音乐的简化CP表示Fig.5 Simplified CP representation for symbolic music
本文将所有乐谱的音乐序列部分提取并转换为CP表示,并将该数据集与MIDIBERT初始预训练使用的5个数据集混合,重新进行预训练,该处理方式相当于扩充了预训练的数据规模,这样可使模型更好地学习音乐序列的上下文知识。预训练任务与BERT模型的MLM任务类似,将一段音乐序列中的某个Token进行掩码处理,让模型还原被掩码掉的音符及其对应的事件。
(2) 精调阶段
EMOPIA数据集是Hung等[20]构建的含有情感标注的钢琴符号音乐数据集。其数据规模为1 000级别,情感标注基于Russell提出的VA模型[12]。在本文的情感分类研究中,仅讨论情感极性,即VA模型的愉悦度(Valence)维度,故分别将VA模型中的第一象限和第四象限、第二象限和第三象限视为同一标签。训练集、验证集、测试集比例划分为7∶2∶1。
本文将预训练后的MIDIBERT模型在EMOPIA数据集上进行精调,使预训练模型适配下游的音乐序列情感分类任务。模型的整体结构如图6所示。
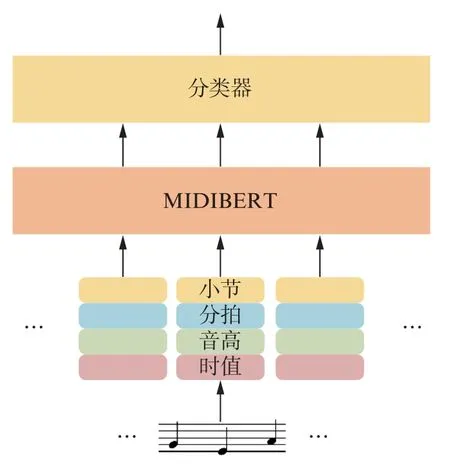
图6 基于MIDIBERT的音乐情感分类模型整体结构Fig.6 Overall structure of MIDIBERT-based music sentiment classification model
4 实验结果与分析
4.1 实验环境与参数设置
歌词情感分类模型所用计算设备的配置为:NVIDIA GeForce RTX 2080 GPU,操作系统为Ubuntu 18.04.2 LTS,Python版本为3.8.3,深度学习框架为Py Torch 1.5.1。实验参数: 批尺寸为64,采用Adam优化器,初始学习率为1×10-4,训练轮次为20。
音乐序列情感分类模型所用计算设备的配置为:NVIDIA GeForce RTX 3090 GPU(双卡),操作系统为Ubuntu 20.04.2 LTS,Python版本为3.8.12,深度学习框架为Py Torch 1.8.2。实验参数: 批尺寸为12,采用Adam W优化器,初始学习率为2×10-5,设置权重衰减为0.01;预训练阶段训练轮次为500,精调阶段训练轮次为10。
4.2 模型性能分析
本文的实验采用准确率(Accuracy)λAccuracy、精确率(Precision)λPrecision、召回率(Recall)λRecall和F1值(F1-Measure)F1作为电子乐谱情感分类模型的评价指标。以下将分别对歌词情感分类模型与音乐序列情感分类模型的性能表现进行分析。
4.2.1 歌词情感分类模型性能表现
将带有情感标签的英文歌词数据集分别输入至TextCNN与BERT+Bi-GRU模型中进行训练,取若干次训练中损失最小的模型在测试集上进行检验。3种分类模型在该数据集的测试集上的最佳表现如表2所示。

表2 歌词文本情感分类模型性能表现Tab.2 The performance of lyric text sentiment classification model
通过以上实验结果可以看出,基于深度神经网络的方法在歌词文本情感分类任务上的表现显著优于情感词典。这是因为歌词文本中除了显式的情感词,还存在很多的隐式情感表达,而情感词典对于隐式情感的处理能力较弱。采用预训练精调方法的BERT+Bi-GRU模型在带有情感标签的英文歌词数据集上相比于TextCNN取得了更好的表现,这表明预训练语言模型确实能有效学习到更丰富的语言知识。
4.2.2 音乐序列情感分类模型性能表现
将EMOPIA数据集输入至MIDIBERT模型中进行训练,取若干次训练中损失最小的模型在测试集上进行检验。为了检验预训练在该任务中的有效性,取未经预训练的模型作为对比。表3为符号音乐序列情感分类模型在EMOPIA数据集上的情感二分类性能表现。

表3 符号音乐序列情感分类模型性能表现Tab.3 The performance of symbolic music sequence sentiment classification model
从实验结果可以看出,经过了预训练的MIDIBERT模型的情感分类性能表现相比未经预训练的方法有了很大程度上的提升,说明BERT类型的预训练不仅适用于自然语言处理任务,对于符号音乐序列也是有效的。
5 结语
本文构建了Music XML乐谱数据集和带有情感标签的英文歌词数据集,并进行了较为完善的数据预处理工作,以保证数据的质量。随后,在英文歌词数据集上分别利用情感词典、卷积神经网络、精调后的大规模预训练语言模型BERT等方法构建歌词文本情感分类模型;在乐谱数据集上利用MIDIBERT预训练模型构建音乐序列情感分类模型。实验结果表明,本文提出的电子乐谱情感分类模型相比于基线模型效果有显著提升,体现了预训练模型在语义特征学习上的优势。在未来的研究工作中将继续关注预训练模型等方法,探究其在情感控制的音乐生成任务中的作用。
猜你喜欢
歌唱艺术(2022年6期)2022-10-23
数学小灵通(1-2年级)(2021年4期)2021-06-09
北方音乐(2019年20期)2019-12-04
制造技术与机床(2019年10期)2019-10-26
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年18期)2018-11-14
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
琴童(2018年11期)2018-01-23
初中生世界·七年级(2017年9期)2017-10-13
小猕猴学习画刊(2017年1期)2017-02-17
