
GPU加速光电耦合输运蒙卡程序研发及应用
2022-11-16 04:27:38武祯路伟鄢书畅邱睿张辉李君利
哈尔滨工程大学学报 2022年11期
武祯, 路伟, 鄢书畅, 邱睿, 张辉, 李君利
(1.清华大学 工程物理系, 北京 100084; 2.同方威视技术股份有限公司, 北京 100084; 3.中国人民解放军疾病预防控制中心核化防护科, 北京 100071)
辐射剂量计算是研究辐射效应的基础[1-2],人体辐射剂量计算广泛应用于医学放射诊断与治疗、事故应急照射、职业照射和环境所致公众内、外照射等领域。常见人体辐射剂量计算方法包含4类:确定论方法[2]、解析方法[3]、通用蒙卡方法[4-5]和快速蒙卡方法[6-9]。不同应用领域对于辐射剂量计算在计算精确度和计算时间都有一定的要求。解析方法、确定论方法及快速蒙卡方法计算速度较快,但是在物理模型、几何、材料方面都做了一定的近似,因此在计算精确度方面都有一定的妥协。同时,作为剂量计算的“金标准”,蒙卡方法能够模拟得到问题的精确解,但计算时间明显过长,这样又限制了蒙卡程序在对计算时间有一定的要求领域的应用,比如临床放射治疗等。
近些年,随着计算机硬件的不断发展,蒙卡程序模拟的计算时间逐渐减少。依据摩尔定律,CPU性能每18个月提高一倍,提高性能的2种主要途径:1)集成更多的晶体管、提高时钟频率;2)传统的串行程序加速模式[10]。但每次硬件更新对程序实际性能的提升依然无法满足需求,同时考虑到能耗、计算成本等问题,使用CPU运行蒙卡程序遇到瓶颈。近年来GPU发展迅速,与CPU相比,GPU具备了更强的单精度浮点运算能力和内存带宽,且GPU硬件系统更易维护而且成本较低;同时,虽然2010年以后,国外依托原快速蒙卡程序或从零开始编写了一些基于GPU加速的光子输运或光电耦合输运程序,包括ACHEERrt、GPUMCD、goMC和gDPM,并进行了大量的正确性验证和加速效率测试[11-13],但进一步调研上述文献可以发现,光子电子物理过程做了不同近似处理,因此在一些需要精细模拟的应用中存在一些缺陷。综合考虑上述情况,本文使用完整的光子电子精细物理模型开发了GPU加速光电耦合输运蒙卡程序(GPU-based photon-electron coupled accelerated dose estimation program, Gadep),并进行了多方面的性能优化。
1 程序框架设计及算法实现
1.1 程序架构设计
本文开发的基于GPU加速的光电耦合输运蒙卡程序Gadep主要用于进行基于数字化人体体素模型的辐射剂量蒙卡模拟计算。程序设计框架分为4层,如图1所示。第1层为硬件环境层,主要包含CPU和GPU,作为程序的底层硬件支撑;第2层为软件环境层,主要包括开发环境、开发语言及相关运行库等,其中:开发环境为Visual Studio 2015和CUDA 10.0,开发语言包括C++、C、CUDA C,涉及到运行库包括CURAND随机数库、Thrust库以及支撑CUDA程序运行所必须的运行库和显卡驱动程序;第3层为功能模块层,包括程序的主要功能模块,如几何模块、源项模块、输运模块、物理模块及统计模块等;第4层为用户层,包括蒙卡模拟参数的输入及结果的输出及展示等,其中用户层集成已经在本研究团队开发三维辐射剂量计算与防护设计仿真程序THUDose中,并进行了大量的正确性验证和加速效率测试[14]。

图1 基于GPU加速的光电耦合输运蒙卡程序Gadep设计框架Fig.1 Design framework of GPU-based photon-electron coupled accelerated dose estimation program (Gadep)
1.2 程序物理模型选择
程序主要包含的物理过程为光子电子耦合输运过程。光子物理过程本质上是光子与原子核和核外电子发生反应的过程,前者包含电子对效应和光核反应,后者包含弹性散射、光电效应和康普顿散射,其中光电效应、康普顿散射和电子对效应3种过程中会分别产生光电子、散射电子和反冲正负电子对;电子物理过程包含轫致辐射、电离作用、多重散射和正电子湮灭,其中轫致辐射和正电子湮灭可产生次级光子。全部光电耦合输运过程如图2所示。
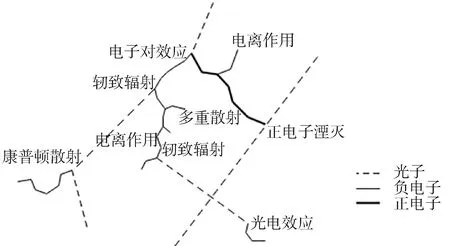
图2 光电耦合输运过程示意Fig.2 Schematic diagram of coupled photon-electron transport process
考虑到本文实现的光电耦合输运蒙卡程序的适用范围,为程序选择了合适的物理模型,轫致辐射和电离辐射包含了连续和离散过程,正电子湮灭包含了静止和离散过程,多重散射则为连续过程。各个物理过程对应的物理模型、适用能量范围如表1所示。其中:光子物理过程主要参考了Geant4提供的Livermore低能模型[5],与Geant4标准物理模型在低能部分的截面主要依靠参数化计算相比,Livermore低能模型直接利用核素的壳层反应截面信息,结果更为准确,可模拟光子的能量也更低,对于Z在1~99的核素范围能量模拟下限为100 eV;多重散射模型则主要使用了基于Lewis理论的多重散射Urban物理模型,该模型的优点是适用于包含电子在内的各种带电粒子,缺点是其在低能区忽略了碰撞核大小因素,电子模拟的精确度不如Penelope、EGSnrc等采用的Goudsmit-Saunderson模型[15]。
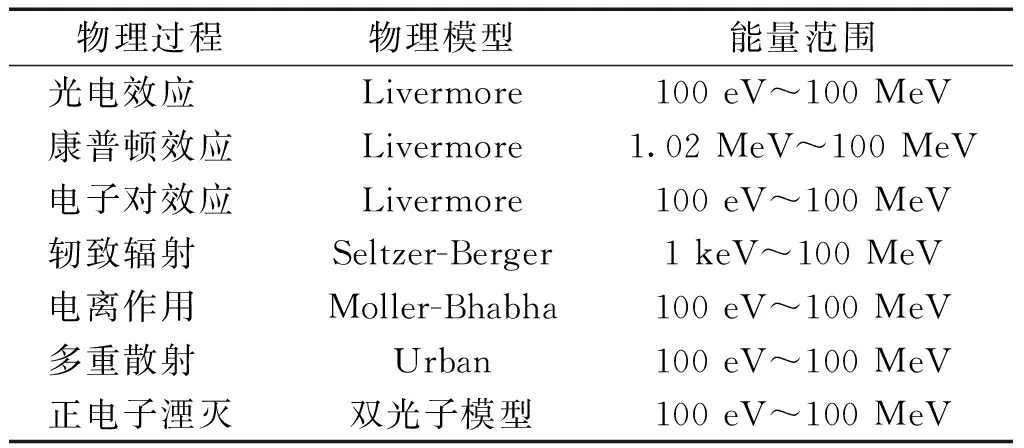
表1 光子电子物理模型Table 1 Photon and electron physical model
1.3 程序实现
基于上述程序设计架构及所选择的光电耦合物理过程,程序实现流程如图3所示,具体描述如下:首先,在GPU上预分配内存空间,通过CUDA系统数据传输函数,将在CPU程序初始化生成的源项、截面、常量、随机数种子、几何、统计和材料等数据传输到预分配的内存上;然后,在显卡设备端(device)实现光子、正电子和负电子3个粒子输运内核函数,可根据入射粒子或次级粒子数组粒子类型调用相应的输运函数;上述内核函数实现后,在CPU主机端(host)选取合适的设备内核函数配置(即执行的线程块、线程网格的个数),并预先给每个线程分配若干(一般取50)次级粒子数组,然后根据初始入射粒子及其次级粒子类型调用输运内核函数,按照先进后出的原则进行模拟。

图3 Gadep具体实现流程Fig.3 Specific implementation process of Gadep
1.4 步长计算方法选择
在通用蒙卡程序中,粒子的输运是以步(step)循环进行模拟,因此步长计算是粒子输运的关键环节之一。通常步长大小计算公式为:
s=nλλ
(1)
式中:λ为粒子的平均自由程;nλ为粒子在介质中输运的平均自由程的个数,其值计算为:
nλ=-logη
(2)
式中η为(0,1)上的随机数。
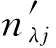
(3)
为了比较2种步长计算算法的优劣,假设2种算法下都经过了n步,穿越了m次几何边界,同时假设每次获取分步长平均自由程时间都是Tλ、生成单个随机数时间是Tδ,则总截面法和分截面法时间总计分别为n[3Tλ+2Tδ]+m[3Tλ+2Tδ]和[n[3Tλ+Tδ]+2Tδ]+m×3Tλ。可以看到,2种算法在平均自由程数据访问次数上一致,但是在生成随机数次数上,同一几何体内总截面法和分截面法之比为2n/(n+2),穿越几何边界时总截面法和分截面法之比为1+2Tδ/3Tλ。因此在使用数字体素模型进行剂量计算的实际应用中,人体模型中的体素个数通常在百万量级,模拟的粒子数在千万量级,采用分截面法需要的随机数将大大减少,从而可以进一步减少时间开销,提高计算速度。
1.5 基于显卡内存的数据存储方案设计
程序中用到的数据类型按用途分为基本物理常量、程序输入输出量和初始化数据。基本物理量包含物理基本单位、物理常量、物理模型参数、原子结合能数据表、原子壳层表等。程序输入输出量包含入射源项、几何数据(体素器官ID、器官材料号、体素密度)。初始化数据主要是指原子反应截面数据,根据输入材料信息生成的康普顿散射、电子对效应和光电效应产生的平均自由程数据库,以及碰撞原子核抽样截面库等。
显卡内存分全局内存(global)、共享内存(shared)、常量内存(constant)和纹理内存(texture)几种,其大小、读写速度、位置上具有不同的特性,因此也有不同的适用性。通过分析程序现有数据,并结合显卡内存各种类特点,本文将程序中数据类型设计为常量、一维数组、枚举和结构体,并放置于不同的显卡内存中。
此外,由于设备端的自定义函数不能直接访问主机端内存,因此,需要利用CUDA内置函数将主机端的数据拷贝到设备端才能访问。程序中使用的CUDA内置内存拷贝函数拷贝全局内存变量数据和常量内存变量数据,一般初始化后在主机端调用这些函数就可以将变量值、数组等简单数据结构拷贝到预先分配的设备端变量中。但是,对于自定义包含指针的结构体类型,CUDA并没有内置结构体内存拷贝函数,因此还需要在程序中编写相应的结构体拷贝函数实现结构体的内存数据转移到GPU内存功能。
2 正确性检验
为了验证本文开发的GPU加速蒙卡程序Gadep的正确性,选取ICRP 116号报告[16]中人体器官和组织受照剂量计算6种照射情景之中的前后照射(antero-posterior,AP)和后前照射(posterior-antero,PA)照射作为模拟对象,如图4所示,统计人体内光电耦合输运下的能量沉积,计算人体器官或组织剂量转换系数,并和ICRP 116号报告结果进行对比。ICRP 116号报告结果是程序FLUKA、MCNPX、PHITS、Geant4、EGSnrc等计算结果经过平均、平滑和拟合处理后得到的。

图4 AP和PA照射示意Fig.4 AP and PA irradiation
使用本程序分别模拟了AP、PA照射下入射粒子分别为光子、电子4种情形下人体器官或组织的外照射器官剂量转换系数,采用的体素模型为ICRP成年男性参考人体模(AM),模拟粒子数为1×108,所使用显卡为NVIDIA GeForce 1080Ti,除深部、小器官外其他器官或组织的外照射剂量转换系数不确定度小于1.0%。图5~8分别为一些代表性器官光子、电子外照射剂量转换系数计算结果和ICRP 116号报告中的外照射剂量转换系数对比图。
从比对结果可以看出,使用Gadep计算得到的外照射器官剂量转换系数与ICRP 116号报告结果基本一致,验证了程序的正确性。对于入射粒子为光子的AP和PA照射(图5和图6),与有效剂量相关的器官剂量转换系数计算结果和ICRP 116号报告[16]之间的差异多数可以达到1%以内,部分小器官或深部器官,由于粒子进入的概率低,不确定度相对较大,但与ICRP116号报告的差异也基本在3%以内。
对于入射粒子为电子的AP和PA照射(图7和图8),在低能部分Gadep和ICRP 116号报告计算结果之间差异较大。这是由于对于同样的粒子数,入射粒子为电子时深部器官计算结果不确定度会比光子要大很多。ICRP 116号报告中也指出,600 keV的入射电子沿AP照射情况下,大器官和小器官的相对统计不确定度分别为4%和10%。
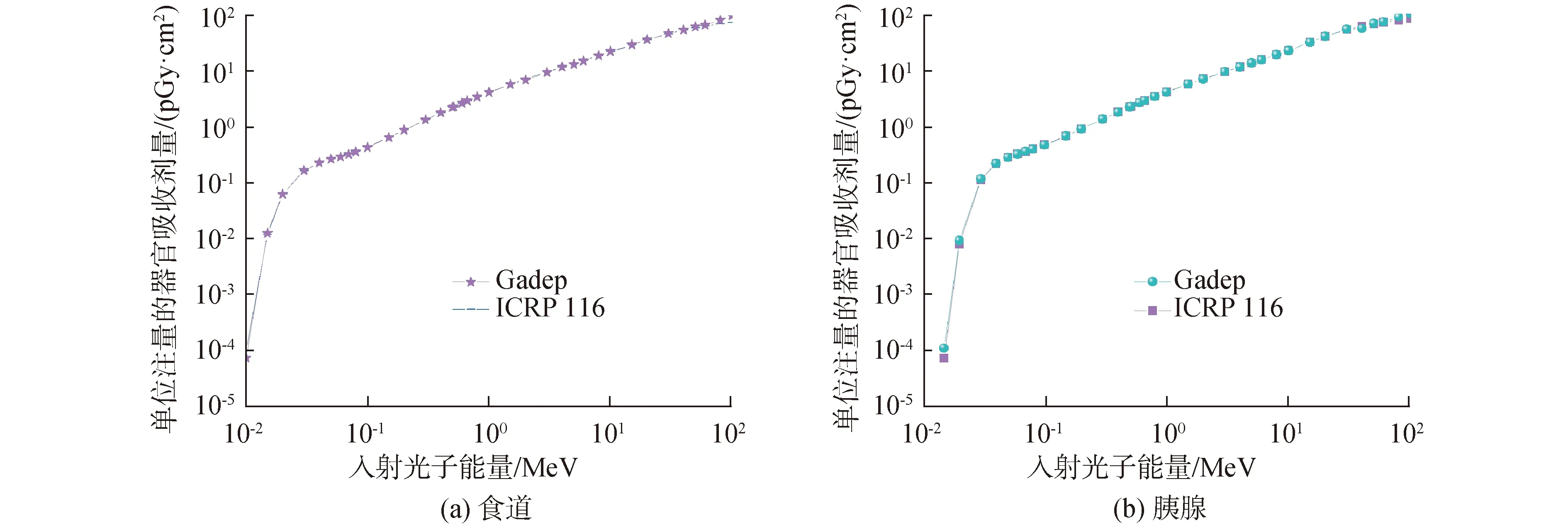
图5 光子AP外照射器官剂量转换系数计算结果和ICRP 116号报告结果对比Fig.5 Comparison of calculation results of dose conversion coefficient of external photon AP irradiation by Gadep program with the results reported by ICRP 116
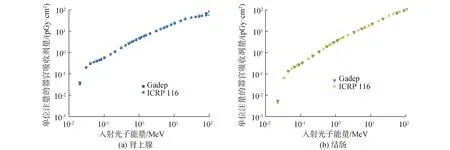
图6 光子PA照射器官剂量转换系数计算结果和ICRP 116号报告结果对比Fig.6 Comparison of calculation results of dose conversion coefficient of external photon PA irradiation by Gadep program with the results reported by ICRP 116

图7 电子AP外照射器官剂量转换系数计算结果和ICRP 116号报告结果对比Fig.7 Comparison of calculation results of dose conversion coefficient of external electron AP irradiation by Gadep program with the results reported by ICRP 116
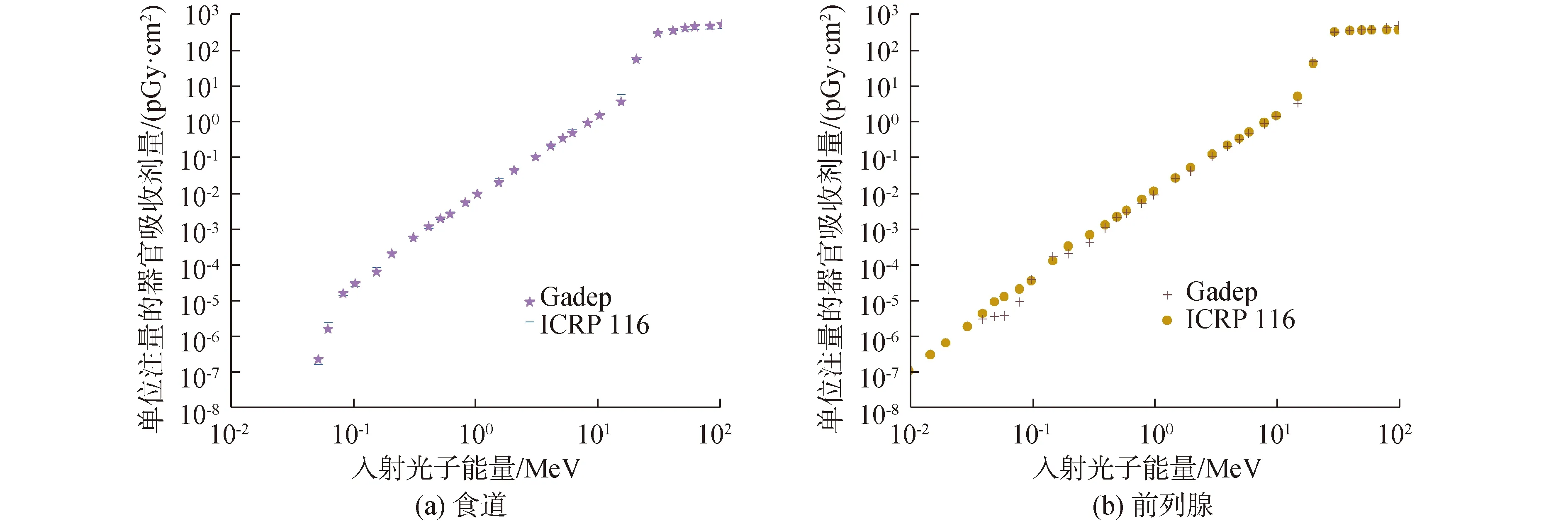
图8 电子PA外照射器官剂量转换系数计算结果和ICRP 116号报告结果对比Fig.8 Comparison of calculation results of dose conversion coefficient of external electron PA irradiation by Gadep program with the results reported by ICRP 116
3 程序优化及加速效果比对
3.1 几何输运算法优化
跨边界算法是一种根据体素模型所做的几何输运算法的优化,如图9所示。其原理是相邻体素如果材料相同,则光子可以穿越几何边界而不停顿,减少输运过程中对同种材料进入相邻体素后反应截面重新抽样次数,达到减少计算时间、提高加速效率的目的。

图9 非跨几何和跨几何边界输运算法示意Fig.9 Schematic diagram of the cross and non-cross geometric boundary transport algorithms
下面以AP照射情形下全身体素径迹长度分布计算为例,对使用跨边界算法的正确性以及优化效果进行了验证。表2给出了不同能量下是否使用跨边界算法的情况下每个体素的计算差异及优化效果,其中σ是采用跨几何边界和非跨几何边界计算结果相对差异,所对应的数值为相对差异小于σ的体素百分比,可以看出,在不同的能量点上,约80%的体素计算结果差异在1%以内;表格最后一行给出了是否使用跨边界算法的优化效果,可以看出计算时间减少了29.4%~41.8%。
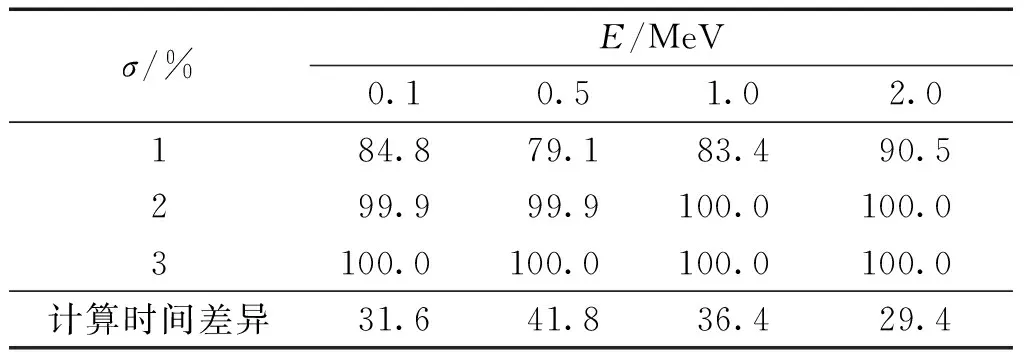
表2 跨几何边界算法下每个体素计算结果差异及优化效果
3.2 GPU硬件结构优化
GPU计算性能一般用浮点数运算峰值(FLOPS)来表示,一般GPU的单精度FLOPS要比双精度FLOPS要高。因此在程序计算精度允许的情况下,使用单精度浮点类型可以提高GPU程序的计算效率。同样以AP照射情形下全身体素径迹长度分布计算为例,测试了将计算精确度要求较高的长度相关物理量分别设为单、双精度浮点类型,对计算结果和计算时间的影响,见表3。可以看出,60%左右的体素径迹长度计算结果相对差异小于1%,相应的计算时间减少了44.4%~58.1%。
3.3 GPU内核函数配置优化
CUDA中线程执行的最小单元是线程束(warp),每个线程束中包含32个线程,每个线程块包含多个线程束。GPU程序在执行内核时,需要分配线程块的大小,线程块的大小和GPU硬件架构相关,通常取32的整数倍;同时,CUDA内核所占资源(寄存器、共享内存、纹理内存等)也会限制GPU线程块池(pool)可执行线程块的个数。上述2个方面的限制都对GPU程序加速效率有影响,图10给出了采用不同的线程执行模型进行AP照射情形下全身体素径迹长度分布计算时,不同能量的光子输运运行时间比较。由图可知,当配置参数取32时,各能量点计算时间最少,32为程序Gadep在显卡GeForce 1080Ti的最优内核函数配置参数。
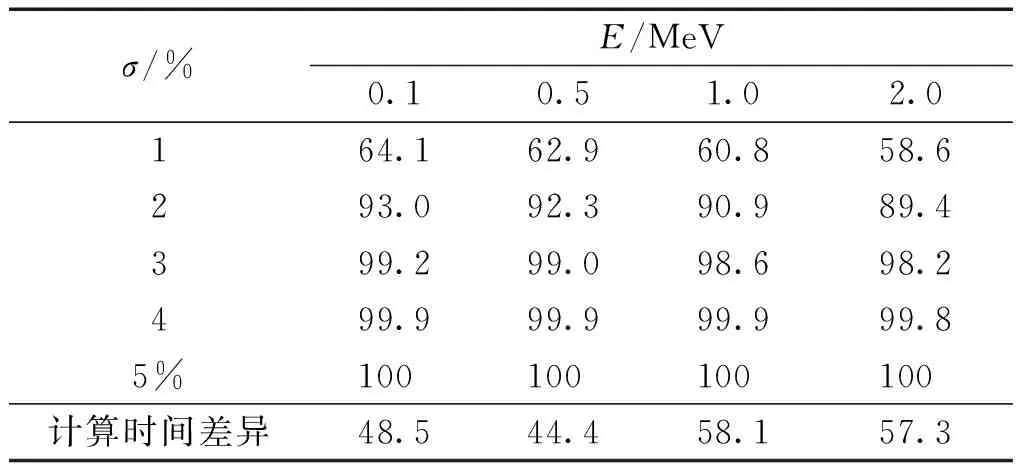
表3 单精度和双精度浮点类型Gadep的计算结果差异及优化效果

图10 不同内核执行模型配置参数下计算时间对比Fig.10 Comparison of calculation time under different kernel configuration parameters
3.4 程序加速效果比对
为对程序Gadep的加速效果进行验证,对该程序计算AP、PA标准照射条件下光子、电子外照射剂量转换系数的计算时间进行统计,并与同等计算条件下使用MCNP进行计算的计算时间进行了比对。其中MCNP中取粒子模拟类型mode P E,为光子电子耦合输运,光子、电子截断能量为程序默认值;测试CPU为Intel i7-4710U,GPU显卡为NVIDIA GeForce 1080Ti。图11给出了4种计算情景下Gadep程序与MCNP程序的加速效率对比结果。
从图中可以看出,对于光子照射情景,Gadep在低能区加速效率可以达到224倍,中能区加速效率在50~100倍;当入射光子能量增加,次级粒子数多,线程歧离变大,加速效率值总体逐渐降低,当光子能量为100 MeV时,加速效率值约为25倍。对于电子照射情景,Gadep在电子能量为0.6 MeV时加速效率最大值达到300倍,增加或降低电子能量,加速效率值变小;AP和PA照射下最小加速效率值分别为48倍和53倍,对应电子能量分别为0.01 MeV和100 MeV。
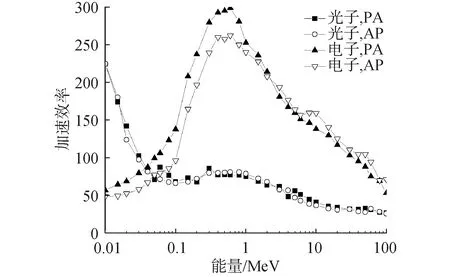
图11 程序Gadep加速效率随入射粒子能量、类型和照射情景变化趋势Fig.11 Trend chart of Gadep program acceleration effect over incident particle energy, type and irradiation situation
4 程序应用
对事故进行剂量重建是评价放射源造成辐照危害大小的重要手段。作者曾使用THUDose和中国参考人体素模型库对2014年5月南京工业探伤机放射源192Ir丢失所致人员受照事故进行了精细的物理剂量重建,模拟了病人全身光子通量、全身器官吸收剂量分布情况,并统计了计算时间[17-18]。本文使用了Gadep程序,采用相同的模拟条件,对南京放射源丢失事故中的病人器官吸收剂量进行计算,并与MCNP程序的计算结果进行了比对,部分比对结果见表4,其中为达到器官吸收剂量统计量不确定度在1%以内,两者模拟粒子数均取1×108。
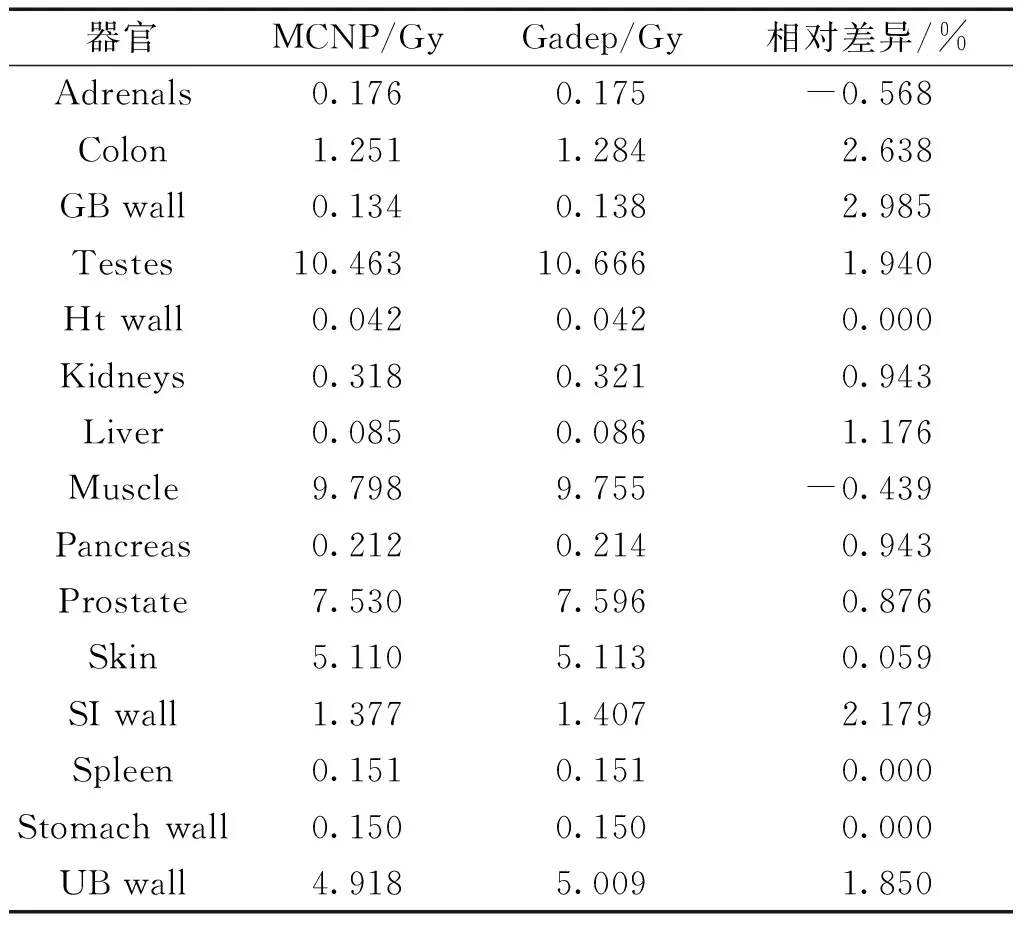
表4 不同程序器官吸收剂量结果对比
对比程序Gadep和MCNP计算结果,多数器官剂量值相对差异小于1%,少数器官(小器官、较远器官)相对差异在3%左右,从而验证了2种程序计算结果的一致性。事故中病人受到最大照射的器官是性腺,MCNP5和Gadep程序性腺吸收剂量计算值在10.46 Gy左右,超过了辐射致永久性不育的吸收剂量限值,而郭凯琳等评估病人睾丸受照剂量约为9.16 Gy[19],在受照后92 d精子存活率降为0,表明临床诊断和物理剂量重建计算结果一致。
在加速效率方面,如表5所示,与MCNP单核CPU计算模拟相比,Gadep程序计算加速效率达到50倍以上。

表5 不同程序器官吸收剂量计算时间对比
5 结论
1)本文开发了一套GPU加速光电耦合输运蒙卡程序Gadep,采用完整的光子、电子精细物理模型,并实现了跨几何边界输运、结构体表访问等算法优化。
2)验证了Gadep程序的正确性。以ICRP 116号报告成年男性参考人外照射器官剂量转换系数计算为例,程序Gadep计算结果和参考数据一致。
3)相比单核CPU程序MCNP5计算时间,Gadep程序在外照射器官剂量转换系数计算中可以实现最高300倍的加速效果,但加速效率是和入射粒子类型、能量相关。
程序还存在较大的优化空间,需要探索进一步提高程序加速效率的方法,例如:通过光子、电子分开模拟进一步减少线程歧离;在异构快速蒙特卡罗程序中实现串行程序成熟的减方差技巧等加速算法。此外,目前程序中几何模块主要实现了基于长方体体素化建模,基本能满足放射治疗、人员剂量评估等模拟需求,但对于复杂几何建模,程序还存在一定的局限,后续将开展复杂几何模型的实现工作,从而进一步拓展程序的适用范围。
猜你喜欢
四川大学学报(自然科学版)(2025年1期)2025-02-10 00:00:00
计算机集成制造系统(2022年11期)2022-12-05 11:40:44
光子学报(2022年11期)2022-11-26 03:43:44
计算机集成制造系统(2020年4期)2020-05-08 02:41:16
中国惯性技术学报(2019年1期)2019-05-21 00:58:46
环球市场(2017年36期)2017-03-09 15:48:21
湖南师范大学自然科学学报(2015年1期)2015-02-27 14:50:05
机械制造与自动化(2014年1期)2014-03-01 04:21:57
原子与分子物理学报(2014年4期)2014-02-28 22:18:47
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
