
一种结合可验证数据库的属性可搜索加密方案*
2022-11-14 01:50:14陈立全张林樾
密码学报 2022年5期
陈立全, 张林樾, 陈 垚
1. 东南大学 网络空间安全学院, 南京 210096
2. 网络通信与安全紫金山实验室, 南京 211111
1 引言
随着数字经济的发展, 数据已经成为受国家、企业和个人重视的关键战略性资源. 随着数据规模的增加, 使用云存储技术存储数据资源, 可以有效减少在软硬件部署与管理环节中的大量成本. 因此, 云存储和云计算技术已经成为业界学者研究的重点. 资源受限的客户端难以处理复杂的计算任务, 越来越多的企业和个人选择将大型加密数据库外包到云存储服务中. 但面对半可信的云存储服务平台, 数据持有者的数据可能面临被篡改和替换的危险, 特别是在属性可搜索加密方案中, 数据使用者属性复杂, 在其对数据进行搜索时, 云存储服务平台可能只会将部分搜索结果返回给用户, 这影响了搜索结果的完整性和正确性.
目前, 云存储系统的数据完整性及隐私安全是学术界的热门话题. 2000 年Song 等人[1]首次提出可搜索加密技术这一概念, 可搜索加密技术是指在密文域中使用关键词搜索, 得到相应的文件, 其特点是在有效减少本地存储空间和通信消耗的同时, 也保证了数据的保密性, 传统的可搜索加密技术主要分为对称可搜索加密技术(symmetric searchable encryption, SSE)[1]和公钥可搜索加密技术(public-key encryption with keyword search, PEKS)[2]. 数据持有者将数据加密后上传至云平台, 再构建合适的搜索索引, 上传至云平台, 数据使用者在搜索数据时, 根据搜索的关键词构造相应的陷门, 将陷门上传至云平台, 云平台执行搜索操作, 将匹配到的文件发送给数据使用者, 数据使用者接收到密文文件后在本地进行解密, 最终得到想要的明文文件. 近年来, 许多学者也在关键词检索等方面提出了多种方案, 例如单关键词检索[3,4]、多关键词检索[5–7]、模糊关键词检索[6,8]等.
近年来, 随着对不同场景需求的不断完善, 更多学者关注于数据及密钥的安全性问题. 对称可搜索加密技术加解密效率较高, 但需要一条安全信道完成密钥传输, 而公钥可搜索加密技术解决了这一问题, 传统的公钥加密方案中需要引入可信第三方作为授权机构颁发公钥证书,提高了方案的复杂度. 因此,Boneh等人在2001 年[9]提出了身份基(identity-based encryption, IBE) 可搜索加密方案, 与传统公钥加密方案相比, 身份基方案将用户的唯一身份信息作为生成公钥的依据, 由私钥生成中心(private key generator,PKG) 产生用户的解密私钥. 为了解决身份基可搜索加密方案在用户身份模糊或敏感时无法使用的问题,Sahai 等人[10]在此基础上提出了模糊身份基方案(fuzzy identity-based encryption, FIBE), 该方案将用户身份分解为一系列模糊身份, 需要拥有d个模糊身份符合条件才能解密密文, 引入访问结构的概念并进一步提出了属性基加密(attribute-based encryption, ABE), 而后其他学者也基于属性基加密提出了多种可搜索加密方案[11–13].
在实际应用场景中, 搜索结果的正确性和完整性同样是非常重要的, 因此就有必要在可搜索加密方案中提供对搜索结果的验证功能. Benabbas 等人提出了第一个实用的高阶多项式函数可验证计算方案, 同时提出了可验证数据库(verifiable database, VDB) 的概念及方案, 允许客户端将大型数据库外包给不受信任的云存储服务器, 并在数据库中进行检索和更新, 服务器在给出搜索结果的同时还会提供搜索结果正确性的证明[14]. 不久后Sun 等人提出了一种高效的搜索结果验证方法, 该方法允许用户自行验证结果正确性, 同时也支持委托给第三方可信机构对搜索结果进行验证[15]. 2020 年Liu 等人提出了一种多用户可验证的可搜索加密方案, 允许多个用户执行搜索操作, 而不仅仅局限于数据拥有者[16].
在基于属性的可搜索加密方案中, 设计者通常采用非对称加密方式来实现属性之间的区分. 使用非对称加密算法会导致数据拥有者执行更新操作时需要将完整的密文数据和索引重新上传, 效率较低, 同时对于属性的更新操作也十分困难; 另一方面, 公钥可搜索加密方案通常在大型数据库场景中难以应用. 关于可验证性的问题, 当前具有可验证性的方案中, 大部分方案验证的是搜索结果的完整性, 这其中并不包括对数据库的验证, 从而无法保证服务器给出的搜索结果是在最新数据库上计算得出的. 针对上述问题,本文提出了一种基于可验证数据库的属性可搜索加密方案(attribute-based searchable encryption with verifiable database, VDB-ABSE), 在实现权限可控功能的同时, 可以确保数据的可验证完整性, 使得可搜索加密方案能够应对更复杂、安全性能要求更高的场景, 主要贡献如下:
(1) 使用对称加密方式对文件进行加密, 使用字典树结构建立搜索索引, 在搜索过程中先对数据使用者的属性进行识别, 然后在对应属性的子树中对关键词进行搜索, 得到目标的文件标识符. 实现了属性、关键词与密文的高效动态更新, 并满足前向安全和后向安全.
(2) 构造一个可验证数据库, 在搜索完成后, 服务器将搜索结果与证明一起发送给数据使用者, 使用者可以对搜索结果以及数据库的完整性和正确性进行验证. 提出了一种结合属性权限与可验证数据库的属性可搜索加密方案.
2 VDB-ABSE 方案
VDB-ABSE 方案主要的方案模型如图1 所示, 主要有三个部分: 云存储平台、数据持有者以及数据使用者.

图1 VDB-ABSE 方案的系统模型Figure 1 VDB-ABSE scheme system model
云存储平台作为系统的核心部分, 具有高效的数据计算功能, 可以存储由数据持有者上传的密文文件集合、文件索引以及哈希树. 数据持有者上传可供搜索的文件, 预先使用关键词分词技术生成每个文件对应的关键词. 数据使用者首先需要从数据持有者处获得一个属性认证, 标志该用户的属性权限.
2.1 VDB-ABSE 算法定义
VDB-ABSE 方案涉及5 个多项式时间的算法, 分别是初始化算法、陷门生成算法、搜索算法、验证算法和更新算法, 定义如下:
(1) Setup(SK,PP,DB,AttributeList)→VDB,PK,S: 其中SK 为数据持有者的私钥, 公共参数为PP, 所有文件构成的数据库DB, 以及数据使用者的属性列表AttributeList. 输出为一个构建好的可验证数据库VDB、公开密钥PK, 以及一些附加信息S.
(2) TrapGen(UA,w,KT)→Tpw: 当数据使用者想要在VDB 中搜索关键词为w的文件时, 将自己的属性UA, 目标关键词w, 以及索引密钥KT作为该算法的输入, 通过计算, 输出为对应的搜索陷门Tpw.
(3) Search(Tpw,UA,VDB,PK)→τ,D: 数据使用者将生成的陷门Tpw和自己的属性UA 发送给云存储服务, 云存储服务器将Tpw、UA 以及可验证数据库VDB、公开密钥PK 为输入. 先进行关键词搜索, 然后再对应属性权限索引表, 将该属性下对应的密文文件集DWwUA发送给数据使用者, 附上证明τ.
(4) Verify(τ,DWwUA)→result: 数据使用者收到云存储服务器返还的密文文件集DWwUA和证明τ后进行验证, 分别验证完整性和正确性. 如果通过验证, 算法输出result=0, 表示数据使用者接受搜索结果, 否则, 算法输出result=1, 表示云存储服务器的搜索结果不满足完整性或正确性,数据使用者拒绝云存储服务器的搜索结果.
(5) Update(Utype,w,UAtrribute,Fw,SI)→SI′: 在VDB-ABSE 方案中, 更新算法涉及关键词更新、文件更新以及属性更新. 输入为更新的种类参数Utype、关键词w、属性列表UAtrribute、文件Fw以及索引. 根据需要更新的类别, 更新索引, 最后将新的索引SI′作为输出.
在下面几个小节中将对这些算法进行详细说明, 并给出VDB-ABSE 方案的构造方法. 本文中使用的符号及其定义如表1 所示.
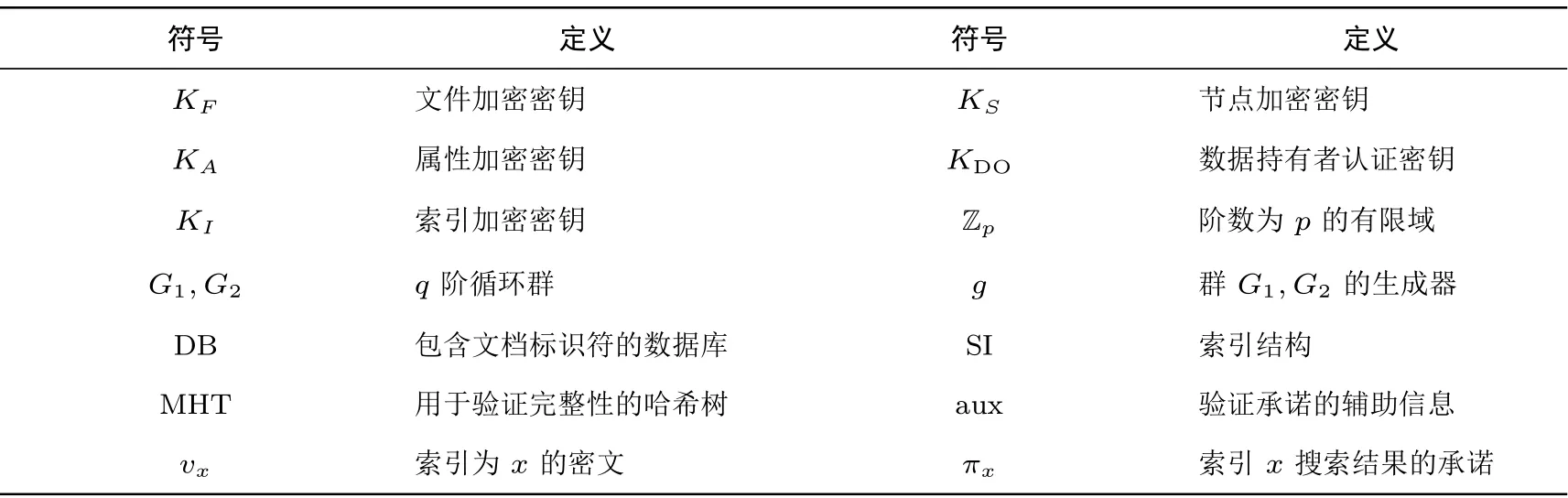
表1 本文中的符号及定义Table 1 Symbols and their definitions in this paper
2.2 初始化算法
密钥生成: 数据持有者DO 生成密钥集KF,KS,KA ∈{0,1}256、以及数据持有者DO 认证密钥KDO∈{0,1}λ; 选取大素数q.
参数选择: 选择抗强碰撞哈希函数H(*,K) :{0,1}λ×{0,1}*={0,1}τ, 其中K ∈{0,1}λ,τ为输出比特位. 伪随机函数F:{0,1}λ×{0,1}λ →{0,1}λ, 和两个能够使等式|G1| =|G2| =q成立的两个群,g是G1的生成器.e是一个双线性映射, hash 是G1中的安全哈希算法,P是[1,q] 范围内的排列.
明文文件集加密: 加密明文文件集合F={f1,f2,··· ,fn},n为明文文件数量. 加密采用AES 加密方式, 密钥使用KF. 加密得到密文集合C={c1,c2,··· ,cn}, 其中ci=AESenc(KF,fi).
关键词提取: 采用关键词提取技术, 根据明文文件集合F={f1,f2,··· ,fn}, 提取出关键词集合W={w1,w2,··· ,wm}.
属性权限划分: 数据持有者根据实际情况将数据使用者根据属性进行划分得到属性集合UAttribute.对每项属性进行权限划分, 计算UAi,wj条件下的可搜索的文件列表Fi,j, 即属性UAi可以搜索的关键词和关键词所对应的文件, 构成属性表AttributeList, 如式(1)所示:

构建可验证数据库: 数据持有者DO 将需要上传到云存储平台CSP 的文件先构建成可验证数据库VDB. 数据库DB 包含用户属性、文档标识符和关键词的对应关系, DBw表示关键词为w的所有文档标识符, DBUAw则表示DBw中属性为UA 可以搜索的所有文档标识符.
在初始化阶段的具体操作如下:
(1) 数据持有者随机选择q个元素zi ∈RZp, 计算hi=gzi,hi,j=gzizj, 其中1≤i/=j ≤q, 然后生成密钥y ∈RZp, 计算Y=gy. 公开参数为式(2):
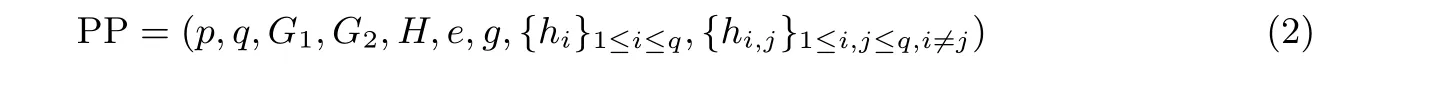
其中, 信息域为M=Zp.
(2) 构建索引结构, 明文字典树构建规则如下:
(a) 根节点为空节点, 不存储数据, 仅作为搜索入口.
(b) 深度为1 的节点存储属性, 用于在搜索时匹配用户属性.
(c) 深度大于1 的节点代表关键词中的字符, 从根节点到该子节点的路径代表该节点对应的关键词, 节点存储以下数据{μ,Np,DBs}. 其中,s代表该节点对应的字符串;μ代表s是否为关键词,μ= 1 时代表s是关键词; Np={np1,np2,··· ,npθ}代表该节点的子节点; DBs代表关键词s的属性权限索引表, 该表使用二维数组的结构存储属性与文档之间的访问权限, 1代表该属性有权限访问相关文档, 构建的二维数组结构如表2 所示.

表2 二位数组DBs 的结构图Table 2 Structure of two-dimensional array DBs
这个索引数组对于攻击者和云存储服务器没有任何意义, 为了提高安全性和索引的隐私安全, 可以在索引中添加一些假关键词和文档标识符, 进一步防止攻击者利用统计方法获取文档信息.
图2 给出了根据规则构建出的索引结构在明文状态下的示例. 在本方案中, 将对字典树加密生成搜索索引, 数据持有者通过密钥KS,KA,KI, 对字典树进行加密, 得到搜索索引SI, 并构建树MHT, 具体方法如下:

图2 索引结构在明文状态下的示例图Figure 2 Sample of index structure in plaintext
(a) 对于关键词w, 假设其每个字符为αi, 计算βi=F(KI,αi), 数据持有者对于每个属性下的关键词w ∈W进行式(3)计算, 该映射关系记作SI[UA,stagw]=eUAw.

(b) 数据持有者生成两个布隆过滤器BFw和BFUA, 把所有关键词标记stagw插入BFw, 以确保搜索的可验证性, 把所有的属性标记stagUA插入BFUA, 以保证用户属性的可验证性.
(c) 按照SI 的结构构建哈希树,根节点为φ,其他每个叶子节点中存储H(UA||w||m),其中w为SI 中相同路径所表示的关键词,m为属性UA 可搜索该关键词的文件标识符数量, 即DBUAw中1 的个数.

本方案公开密钥为PK=(PP,Y,CR,C0,BFw,BFUA,MHT,φ), 上传至云存储服务器的辅助信息为S=(PP,aux,DB,SI), 数据持有者和数据使用者保存的私钥为SK={y,KS,KI,KA,KF}.
2.3 陷门生成算法
数据使用者需要输入自己的属性UA, 以及需要搜索的关键词集Target ={t1,t2,···}. 生成陷门的具体操作如下:
(1) 首先生成属性陷门, 计算stagUA=F(KA,UA).
(2) 对于每个关键词wi=(α1,α2,··· ,αl) 中每个字母αi, 进行以下计算βi=F(KI,αi)
(3) 关键词的陷门为stagw=β1||β2||···, 关键词集的搜索陷门为式(5):
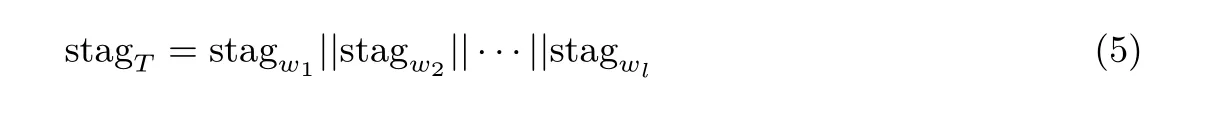
(4) 最后, 输出的搜索陷门是Tpw={stagUA,stagT}.
数据使用者将搜索陷门Tpw发送给云存储服务平台对目标文件进行请求搜索.
2.4 搜索算法
云存储平台在收到搜索请求后, 将搜索陷门Tpw解析为stagUA和stagT, 然后进行搜索, 详细的执行过程如下:
(1) 验证数据使用者的属性是否在可以搜索的权限范围内, 首先检查stagUA是否在BFUA内, 如果检查结果是存在的则再进行下面的步骤, 若不在属性范围内, 则结束此次搜索请求.
(2) 服务器收到搜索令牌后, 解析出来每个关键词的搜索陷门stagw, 通过SI 执行搜索, 得到结果R= SI[UA,stagw]. 云存储服务器将R和对应的所有加密文件一起发送给数据使用者. 数据使用者在接收到R之后, 计算Ke=F(KS,w), 解密DEC(Ke,R)=UA||DBUAw, 得到对应关键词所对应的文件标识符.
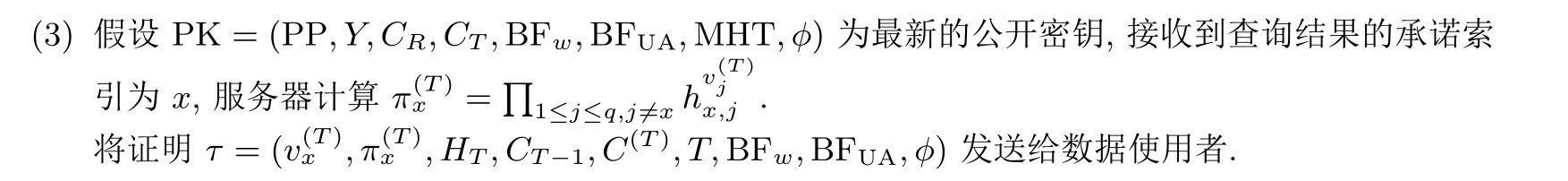
2.5 验证算法
验证阶段的工作主要分为三部分,先是验证搜索属性的正确性,接着验证搜索结果的完整性,即DBUAw的完整性, 再解析证明τ. 具体步骤如下:
(1) 当搜索结果为空时, 数据使用者检查BFw(stagw) = 1 是否成立, 如果不成立, 则接受搜索结果,过程终止.
(2) 当结果不为空时, 数据使用者首先计算DEC(Ke,R) = UA||DBUAw, 得到的属性标识符与自身属性标识符进行对比, 检验属性的正确性.
(3) 客户端通过使用MHT 的根来检查H(UA||w||m), 来验证完整性. 其中m是通过对接收到的密文文件e进行解密得到的, 也可以通过DBUAw中文件标识符的个数得到.
(4) 搜索结果的正确性可以通过向量承诺的特征得到. 数据使用者先对证明进行解析τ=(v(T)x ,π(T)x,HT,CT-1,C(T),T,BFw,BFUA,φ). 任何验证者都可以通过式(6)来检查证明τ的正确性:
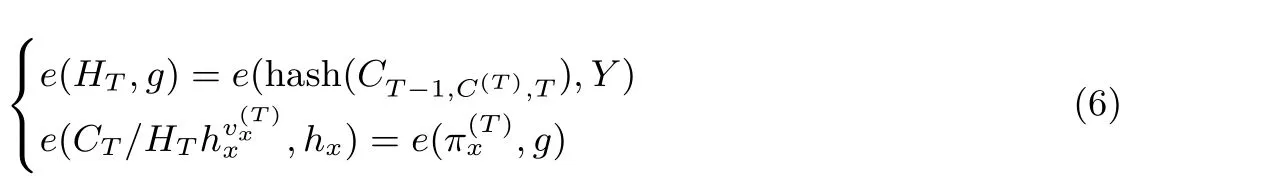

2.6 更新算法
在实际应用中, 对存储的数据进行动态更新十分重要, 本文提出的VDB-ABSE 方案支持对关键词、属性以及密文进行动态更新, 具体更新方法如下:
(1) VDB-ABSE 方案在对关键词进行更新时包括添加和删除两项操作. 数据拥有者首先要使用初始化算法中构建索引的方法为待操作关键词构建索引结构SI, 并更新公开密钥中的MHT, 将Utype 设定为对应的操作标识, 添加关键词时仅需将新关键词的stagw加入BFw中, 删除关键词时则需根据剩余关键词重新生成BFw, 将(SI,Utype,BFw) 发送到服务器. 服务器在数据拥有者通过身份验证后更新索引结构SI 及布隆过滤器BFw.
(2) VDB-ABSE 方案将数据使用者属性存储于索引结构中, 因此对属性的添加、删除操作与关键词的更新方法相似. 不同之处在于使用新属性的stagUA更新或重新生成BFUA, 将(SI, Utype,BFUA) 发送到服务器, 由服务器完成更新.
(3) 对于要更新的密文vx, 数据持有者首先获取相应的索引x, 服务器将最新的数据记录vx和相应的证明τ发送给数据持有者. 当Verify(PK,x,τ)=vx/=⊥时, 数据持有者在T上加1, 并计算出式(8):



2.7 方案运行流程
本节中VDB-ABSE 方案的运行流程为图3. 数据持有者对于可以对数据进行搜索的数据使用者进行管理属性, 能够掌握他们对文件搜索的不同权限, 在初始化阶段对文件进行加密, 并根据数据使用者的权限和属性生成相应的搜索索引, 再根据索引生成相应的哈希树, 构建可验证数据库, 并将可验证的数据库发送给云存储平台, 由云存储平台进行存储. 图3 中搜索阶段与动态更新阶段均可以进行重复操作. 在搜索阶段数据使用者先是根据自己的属性生成相应的搜索陷门, 向陷门发送给云存储平台, 云存储平台在接收到搜索陷门后执行搜索操作, 将搜索结果和证明返还给数据使用者, 数据使用者在接收到信息后先验证数据的完整性和真实性, 通过验证后对密文文件进行解密得到自己的目标文件. 当存储在云存储服务器端的可验证数据库需要进行更新时, 数据持有者将更新指令发送给云存储平台, 云存储平台按照指令进行更新并将新的数据库证明发送给数据持有者, 同时将公开密钥更新.

图3 VDB-ABSE 方案流程图Figure 3 VDB-ABSE scheme flow chart
3 方案分析
3.1 安全性分析
定理1 假设本方案中的F是安全的伪随机函数, 则本方案中使用的SI 实例Σ 是自适应安全的.
证明: 与文献[17] 类似, 本文通过设计一个模拟器S来提出安全性分析, 即证明RealΣA(λ) 和RealΣA,S(λ) 在计算上是不可区分的. RealΣA,S(λ) 实验实例化一个空的列表并且生成一个计数器, 对手A选择一个关键词集W, 实验生成索引SI 并发送给A, 再将生成的陷门stagw发送给A, 存储到列表中,并将最后列表发送给A. 如果存在模拟器对于所有的对手A都能安全地保护索引, 意味着模拟器S仅用泄露信息就可以精确地模拟整个协议, 从而完成证明, 则证明方案具备自适应安全.
模拟器算法S可按照以下方式进行:S将泄露信息LT= (|DBw|,N= ∑w∈W|DBw|) 和对手的查询T[q] 的所有记录作为输入. 初始化S(LT), 生成索引SI, 与索引生成算法相似, 不同的是S用相同长度的随机比特串填充数组的所有元素. 另外,S生成一个二维数组T[w,c] 来存储所有的条记录, 用来做A的响应. 然后,S发送SI 给A, 对于A的每一个查询q, 检索一个列表t= (T[q,1],··· ,T[q,|DBq|]). 如果元素F(stagw,c) 在赋值前被查询过, 则S终止.F是一个伪随机函数, stagw在RealΣA(λ) 中和被F范围内随机元素篡改后是无法区别的. 另一方面, 因为任何给定的T[w,c] 都是随机分配到SI 的, 所以A每个T[w,c] 的视图与真实游戏都是相同的. 即满足式(9):

因此, VDB-ABSE 方案中的索引SI 具备自适应安全.
定理2 提出来的VDB-ABSE 方案可以在Squ-CDH 假设下实现安全的关键词搜索.
证明: 与文献[18] 类似, 这里采用还原法提出安全证明. 假设所提出的VDB 方案在关键词搜索的情况下不能实现可验证的更新, 这意味着存在一个对手A, 可以以一个非常小的优势ϵ让数据使用者进行虚假开局, 因此可以建立一个高效的算法A′包含A来打破Squ-CDH 假设. 即在输入(g,ga) 时,A′可以输出ga2.
A′首先选择一个关键词w, 然后选择一个相关的索引i ∈RZq作为对索引i的猜想,A可以打破这个位置绑定.A′随机选择zj ∈RZp, 其中,j ∈[1,q] 和j/=i, 并且计算式(10):


假设(i*,π*) 为A返回的元组, 其中τ*= (v*,π*,ΣT). 如果A可以破解VDB-ABSE 方案的安全性, 即同时满足式(11):

A′成功的概率为ϵ/q, 几乎为0, 因此VDB-ABSE 方案在Squ-CDH 假设下能够实现安全的关键词搜索.
3.2 理论分析
在本小节中,将VDB-ABSE 方案与其他方案进行理论分析比较,表3 给出了本文提出的VDB-ABSE方案与文献[19,20] 提出方案的效率、安全性和功能对比. 其中M为在循环群G1(或G2) 中的乘法运算,E为在循环群G1中的幂运算,I为在循环群G1中的逆元运算,H为哈希运算,F为伪随机运算,P为双线性对运算,n为关键词个数.

表3 方案对比Table 3 Comparison among schemes
3.3 实验分析
本小节将对于VDB-ABSE 方案进行实验仿真, 并且与其他方案进行对比分析, 实验环境使用的CPU为Intel®CoreTMi5-7500 CPU@3.40 GHz, 16G 内存, 实验算法、参数的选择如表4 所示. 首先从公开数据库IMDB Reviews 中随机挑选3000 条评论数据, 并生成数据库, 在分词后选取400 个使用频率高的关键词, 设置数据使用者的属性个数为20.

表4 实验参数Table 4 Experiment parameters
图4 给出VDB-ABSE 方案与文献[19,20] 中方案的查询性能对比. 从图中可以看出, VDB-ABSE 方案的搜索用时较文献[19] 中的方案更长, 优于文献[20] 中的方案, 但文献[19] 中的方案是可验证数据库方案, 不支持可搜索加密, 而文献[20] 中的可搜索方案不支持基于属性加密. 另外, 文献[20] 中的方案使用的索引结构是在倒排索引结构的基础上进行升级, 搜索效率为O(n),n为关键词个数, VDB-ABSE 方案使用的是字典树结构, 搜索效率为O(1), 同时还需要进行属性搜索, 属性搜索的搜索效率为O(n),n为属性个数. 在现实场景中, 关键词通常远多于属性数量, 所以VDB-ABSE 方案的搜索效率比文献[20] 中的方案更好, 能够应对更加复杂的应用场景.

图4 VDB-ABSE 方案与其他方案的查询用时比较Figure 4 Comparison of query time between VDB-ABSE scheme and other schemes
图5 给出VDB-ABSE 方案与文献[19,20] 中方案的验证功能的性能对比. 图中三种方案的验证时间均与计算次数成线性关系, VDB-ABSE 方案与文献[20] 中方案需要更多的计算时间, 是因为两个方案都需要执行一个签名验证和复杂度为O(log2q) 的哈希运算以验证文档标识符的完整性. 此外, VDB-ABSE方案在这一基础上还要进行一次解密得到用户属性的验证结果, 所以VDB-ABSE 方案的验证所用时间会比其他两个方案更多一些, 但是从实验结果来看, 所耗时间还是在可以接受的范围内. 在验证性能差不多的情况下, VDB-ABSE 方案能够对数据使用者的属性进行区分, 具有更好的普适性.

图5 VDB-ABSE 方案与其他方案的验证用时比较Figure 5 Comparison of verify time between VDB-ABSE scheme and other schemes
图6 给出VDB-ABSE 方案与其他方案的更新功能所用时间对比. 三种方案均具有动态更新过程, 在更新过程中, VDB-ABSE 方案和文献[20] 中的方案在更新时除了要更新数据库, 还需要对索引中的信息进行更新, 由前文中对索引结构的分析可知, VDB-ABSE 方案在关键词个数更多的场景中的更新效率要略高于文献[20] 中的方案.
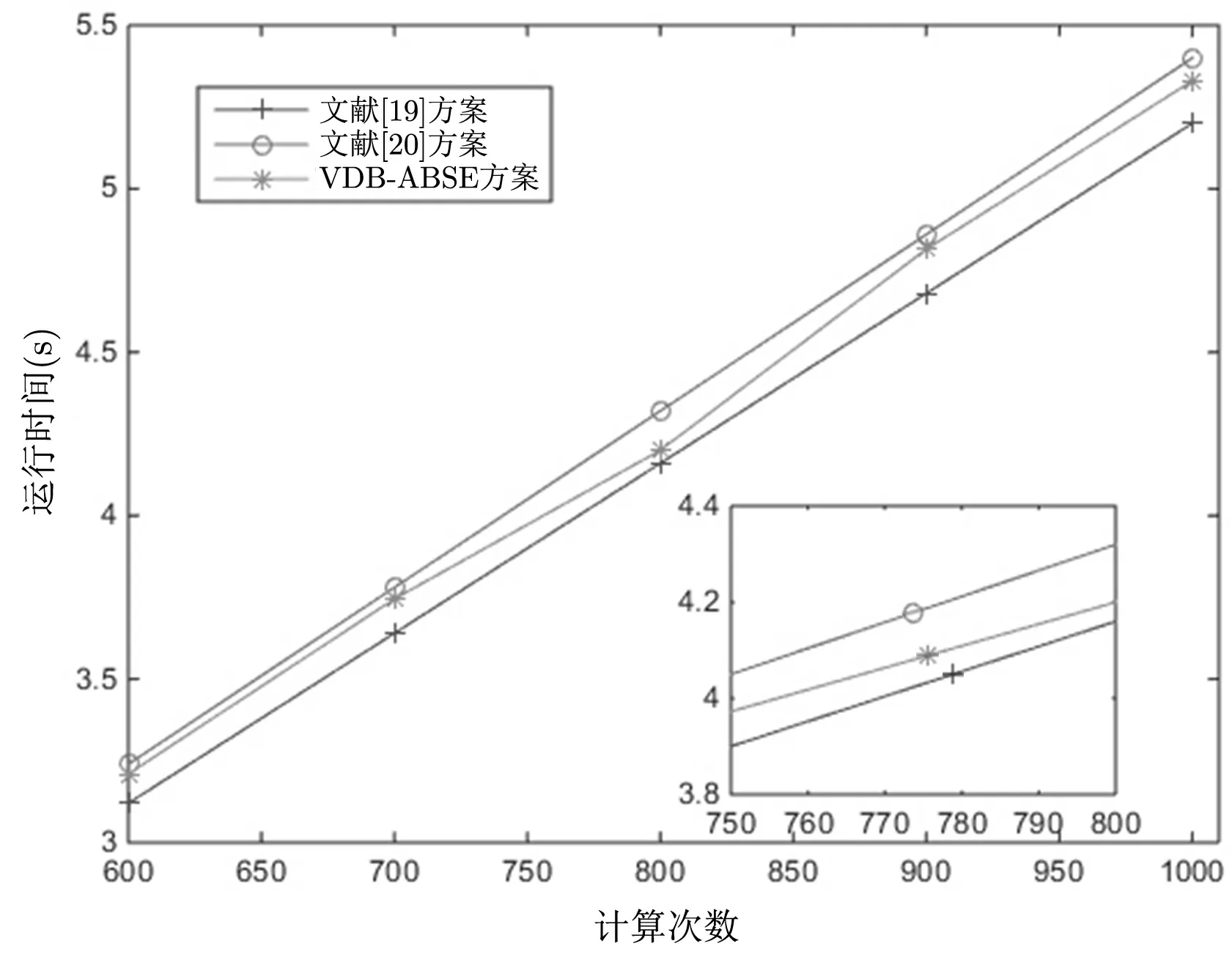
图6 VDB-ABSE 方案与其他方案的更新用时比较Figure 6 Comparison of update time between VDB-ABSE scheme and other schemes
4 结束语
本文引入了可验证数据库的概念, 在属性可搜索加密技术的基础上加入了可验证功能. 现有可搜索加密方案普遍存在效率较低, 或是不能保障数据安全性的问题. 为此, 本文提出了一种基于可验证数据库的可搜索加密方案(VDB-ABSE), 给出了VDB-ABSE 方案的方案模型, 对方案中的具体算法和构造方式进行了详细说明, 并对VDB-ABSE 方案进行了安全性分析, 证明了VDB-ABSE 方案是自适应安全的,同时证明了可以在Squ-CDH 假设下实现安全的关键词搜索. 通过分析VDB-ABSE 方案的性能, 并与其它方案进行比较, 可以看出VDB-ABSE 方案在效率、安全性和功能上表现更加优异. 实验结果表明,VDB-ABSE 方案能够应用于现实生活中更加复杂的场景, 具备属性权限控制、动态更新以及可验证的功能, 弥补了当前属性可搜索加密方案的不足.
猜你喜欢
小火炬·阅读作文(2023年5期)2023-03-02 12:44:57
流程工业(2020年11期)2020-02-28 22:32:15
软件导刊(2018年5期)2018-06-21 11:46:28
好日子(2018年5期)2018-05-30 16:24:04
长春工程学院学报(自然科学版)(2018年1期)2018-04-20 06:58:26
中国新闻周刊(2016年33期)2016-10-27 17:58:47
新天地(2016年3期)2016-05-30 10:48:04
当代旅游(2015年8期)2016-03-07 18:14:38
时代金融(2015年28期)2015-10-16 01:58:21
学苑创造·A版(2009年10期)2009-12-09 07:24:46
