
属性网络中结合用户偏好的社区搜索和离群点检测
2022-11-09 07:13李青青马慧芳李志欣姜彦斌
电子学报 2022年9期
李青青,马慧芳,2,李 举,李志欣,姜彦斌
(1.西北师范大学计算机科学与工程学院,甘肃兰州 730070;2.桂林电子科技大学广西可信软件重点实验室,广西桂林 541004;3.广西师范大学广西多源信息挖掘与安全重点实验室,广西桂林 541004)
1 引言
作为分析复杂系统本质和功能的有力表示,图可以建模各种复杂系统单元之间的交互关系.其中节点表示复杂系统单元,边表示节点间潜在结构和交互规则.此外,节点往往可以与大量属性相关联,描述节点的特定特征并提供与网络拓扑正交的有价值的信息[1,2].作为网络分析中的一个基本问题,社区搜索旨在挖掘与用户给定查询节点相关联的局部社区[3].与社区检测[4]不同,社区搜索将个性化需求整合到社区搜索过程中在特定用户挖掘[5]、蛋白分析网络[6]等任务中具有广泛的应用前景.
传统的社区搜索方法主要集中于普通图(无属性)[7~9].随着现实世界属性信息的激增,属性可作为辅助信息潜在的提高社区搜索的准确性.早期的属性社区搜索方法将属性视为同等重要,旨在通过属性相似性找到包含查询节点的局部内聚社区.如Leman等人[10]提出的基于属性图的无参数化方法,即PICS(Parameter-free Identification of Cohesive Subgroups),将所有属性视为节点来挖掘局部社区.Shang等人[11]设计了既能反映网络拓扑结构关系也能包含属性相似性的TA-graph来检测局部社区.但高维的属性信息使得这类方法的存储开销加剧.因此,有研究人员指出查询节点所携带的核心属性足以指导算法挖掘出融合用户偏好的个性化局部社区[12].在不影响精确性的前提下,可以使用核心属性进行个性化属性社区搜索.如Huang等人[13]研究了满足结构内聚性k-core和关键字内聚性的属性社区.VAC(Vertex-centric Attributed Community)[14]旨在挖掘包含查询节点且具有最大属性得分的连通k-truss.Ye等人[15]通过引入统计学方法来搜索具有指定属性的查询节点所在社区.同时,目标社区发现方法也因其能捕获个性化需求而被广泛研究.如Perozzi等人[16]提出了面向用户的属性图挖掘方法,利用焦点属性以提取目标社区与离群点.TSCM(Target Subspace and Communities Mining)[17]通过属性子空间来定位和挖掘目标社区.尽管以上方法缓解了存储开销,但大多数方法均仅能定位查询节点所在社区,未整合用户偏好到社区搜索过程以挖掘融合用户偏好的多社区且精准定位与社区中成员紧密连接但属性偏离其社区成员的节点.此外,尽管部分方法考虑了整合用户偏好到社区搜索过程中,但仍需用户提供足够多的查询节点来帮助算法捕获用户偏好,具有灵活性不足且不切合实际的局限性.
针对以上问题,提出了属性网络中结合用户偏好的社区搜索和离群点检测方法(Incorporating user Preference for Community Search and Outlier detection in attributed network,IPCSO).具体地,通过编码查询节点邻域网络中节点属性和结构间关系来捕获潜在社区成员.其次,定义平均划分相似度来挖掘属性子空间,并将其作为用户偏好来指导社区搜索过程.最后,将属性子空间蕴含的重要信息融入到网络中,并采用结构凝聚力约束k-core和属性内聚性约束fractional-core来搜索网络中的多社区并检测离群点.多种真实网络和人工网络上的广泛实验证明了本文方法的有效性和效率.
2 准备知识
2.1 符号说明与问题定义
给定无向加权属性图G=(V,E,T,W),其中V={vi}i=1,…,n表示图中节点集且|V|=n;E⊆V×V表示边集且|E|=m.属性集为T={ti}i=1,…,d,|T|=d.设节点属性矩阵为F∈Rn×d,fTi表示节点vi的属性向量.权重矩阵记为W∈Rn×n,其中wij=cos(fi,fj)表示边(vi,vj)的权重.设用户给定的查询节点集为Q={qi}i=1,…,s,Q⊆V.属性约束fractional-core的阈值为w,结构约束k-core的阈值为k.IPCSO的目标是找到目标社区集C={Ci}i=1,…,l和离群点集O={Oi}i=1,…,b,满足:(1)社区内紧密连接;(2)在属性上与用户偏好(属性子空间)一致;(3)找到偏离属性约束的社区内成员(离群点).具体地,本文方法的问题定义如下:(1)输入:属性图G=(V,E,T,W),用户提供的查询节点集合Q,属性约束阈值w以及结构约束阈值k.(2)输出:融合用户偏好的社区集C与离群点集O.
2.2 结合用户偏好的社区搜索和离群点检测基本框架
本文提出的方法框架如图1所示:在给定属性网络G=(V,E,T,W),查询节点集Q,结构约束阈值k和属性约束阈值w的情况下,采用编码可以显式建模邻居之间的交互以突出局部结构内的公共属性,有助于算法挖掘潜在社区成员.通过平均划分相似度获取每个属性的重要性权重,以此表示用户偏好.通过属性子空间的指导对网络重加权,并设定结构约束及属性约束检测多社区以及社区中的离群点.接下来将详细介绍该算法.

图1 结合用户偏好的社区搜索和离群点检测的基本框架
定义1(节点vi的邻域网络)给定节点vi,其邻域网络被定义为N(vi)=(VN(vi),EN(vi),TN(vi),WN(vi)),其中节点集为VN(vi)={vw|(vi,vw)∈E}∪{vi},EN(vi)={(vu,vw)|vu∈VN(vi)^vw∈VN(vi)^(vu,vw)∈E}为 边 集,TN(vi)表 示VN(vi)的 属 性 集,TN(vi)⊆T.WN(vi)∈R|VN(νi)|×|VN(νi)|为EN(vi)的权重矩阵.
3 结合用户偏好的社区搜索和离群点检测
3.1 编码节点属性和结构
较少的查询节点(例如,一个查询节点)包含的信息有限,无法准确计算属性子空间.此外,查询节点间可能没有相互作用关系,无法保证推断出的子空间与内聚连接相关联.针对此,受CDE模型[18]的启发,设计了建模查询节点与其邻居间相互作用及属性相关性的方法.该方法可有效地挖掘查询节点所在社区的潜在成员,将较少的查询节点扩展为一组候选查询节点.具体地,编码节点结构和属性信息以增强节点的表示能力,从而避免丢失与查询节点相似的潜在社区成员信息.因此,尽管给定少量查询节点,查询节点的特征信息仍可保留用以查找与其相似的候选节点.
接下来将详细介绍该策略.首先,编码节点结构和属性相似性mij的公式被定义为:

具体地,首先提取节点vi的邻域网络.然后,利用式(1)对每个候选查询节点及其邻居节点的结构和属性关系进行编码.最后,将mij值最大的节点vj加入候选节点集中.上述过程持续进行到候选节点的数量大于扩展深度h为止.图2显示了编码节点属性和结构的过程,其中边的粗度表示端点节点的属性相似度.设h=5,v2为用户提供的查询节点,首先初始化候选查询节点集Q1={v2}并提取v2的邻域网络.其次,通过式(1)对查询节点与其邻居节点间的相似度进行编码,选择具有最大m2j的节点vj添加到候选查询节点集中,得Q1={v2,v3}.重复上述步骤,分别提取v2和v3的邻域网络,计算v2与其邻居vj∈VN(v2)间的相似强度m2j,v3与其邻居va∈VN(v3)间的相似强度m3a,选择节点v8加入到候选查询节点集中.上述过程在候选查询节点个数大于5时停止,最后得候选查询节点集为Q1={v1,v2,v3,v4,v8}.

图2 编码节点属性和结构策略的示例
3.2 基于平均划分相似度挖掘属性子空间
本节设计了一种属性子空间推断方法,该方法适用于衡量真实社区中属性的重要性.首先通过扩展后的查询节点集来提取用户所关注的核心属性,随后根据核心属性集挖掘用户所聚焦的属性子空间,以此来指导算法挖掘融合用户偏好的社区.特别地,基于距离属性划分方法[19,20]的潜在含义,同一社区中的属性应产生相似的划分,存在一些由属性定义的划分与实际节点所属社区一致.首先根据候选查询节点集将其中节点所携带的属性提取为核心属性集Tcore,Tcore⊆T.对于∀ti∈Tcore,由属性ti划分的节点集V表示为V/ti={Ci,Γi},Ci表示包含属性ti的节点集,Γi表示不包含属性ti的节点集,且Ci∪Γi=V.
定义2(划分熵)给定属性ti∈Tcore,设属性ti的划分为V/ti={Ci,Γi}.P(Ci)表示包含属性ti的节点集合的概率,则属性ti的划分熵E(ti)定义为:

定义3(划分条件熵)给定核心属性ti,tj∈Tcore,设属性ti和tj的划分分别为V/ti={Ci,Γi},V/tj={Cj,Γj}.则核心属性tj关于属性ti的划分条件熵CEti(tj)定义为:
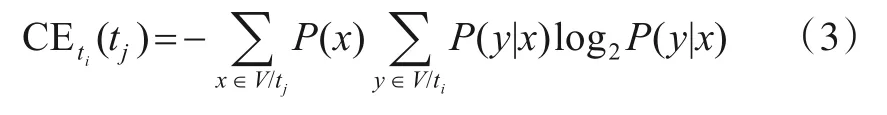
定义4(划分联合熵)给定核心属性ti,tj∈Tcore,核心属性ti和tj的划分联合熵E(ti,tj)定义为:

定义5(属性划分距离)划分V/ti和V/tj的属性划分距离d(V/ti,V/tj)为:

定义6(归一化属性划分相似度)为了便于度量属性划分的相似性,对属性划分距离进行归一化并将其转化为属性划分相似度:
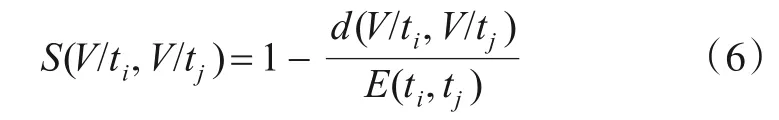
值得注意的是,式(6)的分母不能为零,所以不会出现未定义的情况.此外,由于式(6)的分母总是大于分子,因此不会因为分母过大而放小比值.
由上可知,平均划分相似度可形式化为:
定义7(平均划分相似度)给定属性ti,tj∈Tcore,属性ti的平均划分相似度定义为:

APS衡量划分相似度差异性,可表示选用某一属性ti进行划分与其他属性进行划分的相异程度.属性ti的APS值越大,则表明选用属性ti划分所得的社区与其他属性划分所得社区的相似程度越高.用向量τ来表示属性子空间,其元素值计算如下:

元素τi表示对应属性ti在属性子空间中的重要性或与查询节点的相关性,若属性ti∈Tcore,则属性子空间中元素设为APS(ti),否则,将其在属性子空间下的重要性设为0.
3.3 编码节点属性和结构
3.3.1 网络重加权
属性子空间可帮助用户探索在核心属性上内聚的社区,通过重加权网络将属性子空间对属性的关注程度融入到整个网络中.首先定义在属性子空间的指导下重加权后的权重矩阵Wτ,Wτ中元素表示节点vi和vj在属性子空间下的相似度.具体计算公式如下:
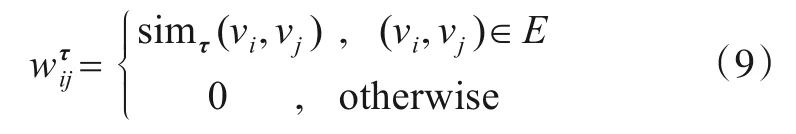
3.3.2 社区搜索与离群点检测
现有方法常使用k-core[21],k-truss[22]和k-clique[23]等结构约束来度量社区结构的内聚性.k-core考虑了图中节点的结构内聚性,fractional-core[24]不仅考虑了图中节点的度,而且也考虑节点间的连接强度.因此,选用前者来度量社区的结构凝聚力,后者度量属性子空间下端点节点属性的凝聚性.具体定义如下:
定义8(k-core[21])给定一个正整数k(k≥0),图G的k-core表示为Hk,其是图G的最大子图,使得∀ν∈Hk,degHk(ν)≥k,其中degHK(ν)=|VN(ν)-ν|.
值得注意的是Hk可能不是一个连通子图,设k-core的连通分量为
定义9(fractional-core[24])给定一个有理数w,fractional-core是图G的最大子图Hw,Hw中节点的度都不小于w,即∀νi∈Hw,di≥w,其中
IPCSO方法旨在通过属性子空间的指导搜索出满足fractional-core和k-core约束的多社区,同时识别出社区中的离群点,且所挖掘到的社区都是最大的.也就是说,不存在另一个满足结构和属性内聚性约束的社区C⊂C'.具体地,首先提取满足结构约束k-core的所有密集连通子图作为候选社区.其次,在这些密集连通子图上设置属性约束以满足属性内聚性.最后,返回满足结构和属性约束的社区,其中不满足属性约束的节点为离群点.
4 实验结果与分析
本节将通过实验验证IPCSO方法的有效性和效率,旨在回答以下三个研究问题.问题1:参数的变化对于IPCSO方法影响如何?问题2:IPCSO方法相比其他基准方法的性能表现如何?以及问题3:IPCSO方法在实际应用中表现如何?
4.1 数据集描述
4.1.1 人工数据集
为研究IPCSO方法的性能,基于LFR[25]生成了节点数为n、属性数为d的具有真实基准的人工网络.其中人工网络中节点的平均度数由davg来控制,最大度通过dmax来设定.此外,μ控制社区内边数与社区间边数的比值.社区的大小分别通过参数cmax和cmin来控制.给定社区中所需节点数,邻接矩阵对角线上定义的块以0.35的概率随机为块中的每个元素分配一条边.对于非对角线上的块,以0.01的概率随机分配边.更进一步地,按照均值为[0,1]以及方差控制在0.001范围内的高斯分布来分配属性值.较小的方差便于社区中的节点包含有核心属性.其余属性可从方差较大的正态分布中提取.离群点可从每个社区中随机选择一个节点,将其属性替换为与该社区属性差异较大的属性.经过多次测试,人工网络参数设置为:davg=20,dmax=80,cmin=2,cmax=80.具体设置如表1所示.

表1 人工数据集统计信息
4.1.2 真实数据集
选取了5个真实属性网络.4Area是计算机科学领域的合著网络,其中节点表示作者,边表示作者间的合著关系,属性表征作者在数据库、信息检索和机器学习等方面发表的会议.YouTube是一个社交网络的视频分享网站,节点表示用户,边表示友谊关系,属性描述用户的身份信息.而Disney数据集是共同购买网络,其中节点为影片,边表示共同购买关系,每部电影有28个属性.由联邦能源管理委员会发布的Enron中,节点表示电子邮件地址,电子邮件之间的传输关系记为边.节点上携带18个属性,用于描述邮件的平均内容长度、平均收件人数量等信息.此外,IMDB(Internet Movie Date-Base)数据集中节点表示电影,边表示电影中演员的共同参演关系.具体统计数据如表2所示.

表2 真实数据集统计信息
4.2 实验设置
4.2.1 评价指标
为评估IPCSO方法在属性图上的有效性,采用Precision和CAS(Community Attribute Similarity)[14]来度量社区的质量.设算法搜索到的社区为C,基准社区为C',则Precision=|C'∩C|||C,其他评价指标定义如下:
定义10(CAS)CAS度量社区C中的属性凝聚力,形式上:

其中T(vi)为节点vi所携带的属性集合.CAS值越高,属性内聚性越强.
4.2.2 对比方法
为度量IPCSO方法的性能,选取了以下三类方法进行对比.第一,比较本文方法与目标社区发现方法的性能,选取了FocusCO(Focused Clustering and Outlier)和TSCM.FocusCO为经典的目标社区发现算法之一,TSCM与IPCSO均采用了扩展查询节点的策略来挖掘社区.第二,为研究IPCSO与其他基于结构度量的属性社区搜索方法的性能,选择了ACQ(Attributed Community Query)和VAC-Etruss(Vertex-centric Attributed Community-Etruss).其中ACQ是具有奠基性的社区搜索方法之一,而VAC-Ecore(Vertex-centric Attributed Community-Ecore)是以节点为中心的属性社区搜索方法的变体.第三,为了探索IPCSO方法挖掘融合用户偏好社区的有效性,选取了LOCLU(LOcal CLustering Unimodality)方法.
4.3 参数分析(问题1)
本节将从三方面研究不同参数设置对于IPCSO的影响.探索查询节点个数对于IPCSO的性能影响.研究编码查询节点结构和属性策略中超参数a的选定以及扩展深度h的选择对于IPCSO的影响.观察k和w的变化对于IPCSO性能的影响.
对于查询节点个数s,从每个真实数据集中任意选取6个查询节点,在s取值不同的情况下运行方法50次并取其平均值返回结果.如图3所示.不同数据集上查询节点个数的变化对于本文方法的影响均较小.原因在于IPCSO方法使用较少的查询节点就可以有效的编码节点信息以找到潜在社区成员,有助于增强用户偏好以达到较为精确地搜索结果.此外,由于所查找社区的属性内聚性通过用户指定的属性约束来控制,故查询节点个数的变化对于CAS的影响较小.

图3 不同数据集上s取值对应的Precision和CAS
图4展示了编码查询节点结构和属性策略中的超参数a和扩展深度h取值的影响.从图4(a)和图4(b)均可观察到,a和h的增加首先会带来较大的性能提升,但随着其取值不断增大会使得IPCSO的性能下降.a=2时所有数据集上的性能表现较好,当a=6时部分数据集上的性能下降.这说明当a设定为2时编码节点属性和结构策略足以帮助IPCSO找到候选查询节点集以提取用户偏好.当h=6时,较小的数据集上的性能达到了最优.在较大数据集中,h=8时性能表现最好,之后则出现了性能下降.究其原因在于扩展过深会使得将不属于查询节点所在社区的节点纳入.

图4 不同数据集上a和h取值对应的Precision
图5给出了结构约束阈值k和属性约束阈值w分别从8以4的步长变化到20,0.2以0.2的步长变化到0.8的结果.图5(a)中可观察到,k值的增加会使得算法所找到社区的结构凝聚性增强,其精度也会随之增加.k的大小与返回社区的大小密切相关.图5(b)可观察到随着w的增加,算法的精度随之降低,源于较小的属性阈值将会使得所返回社区的属性内聚性更强,精度更高.但如果将w设置过小,算法将会返回一个空社区.本文设置k=8,w=0.7.

图5 不同数据集上k和w取值对应的Precision
4.4 性能比较(问题2)
本节将评价IPCSO方法的有效性,观察IPCSO方法与基准方法的性能差异.
表3给出了在不同数据集上取4个查询节点,运行100次的平均结果.从实验结果可得,TSCM在所有数据集上的表现都优于FocusCO.因为较少的查询节点不足以精确地捕获到用户偏好,进而使得算法不能准确定位与查询节点相似的社区成员.TSCM性能表现虽好,但不足以与IPCSO方法竞争,这是由于IPCSO对社区内聚性的要求更高.由于结构内聚性的要求,ACQ和VAC-Ecore在所有数据集上的表现均优于目标社区发现方法,且ACQ的CAS高于VAC-Ecore但却低于IPCSO,原因在于ACQ需要用户将查询节点所携带的属性作为输入并返回覆盖该属性的社区,而VAC-Ecore只需要找到属性得分最小的查询节点所在社区.对于IPCSO,其返回的社区均在属性子空间的指导下,社区内节点与查询节点具有较大的相似性.LOCLU可与IPCSO方法相媲美,其在所有数据集上的表现均优于目标社区发现方法和基于结构度量的方法,但该方法容易将其他社区节点囊括在内.整体而言,IPCSO始终优于所有方法.
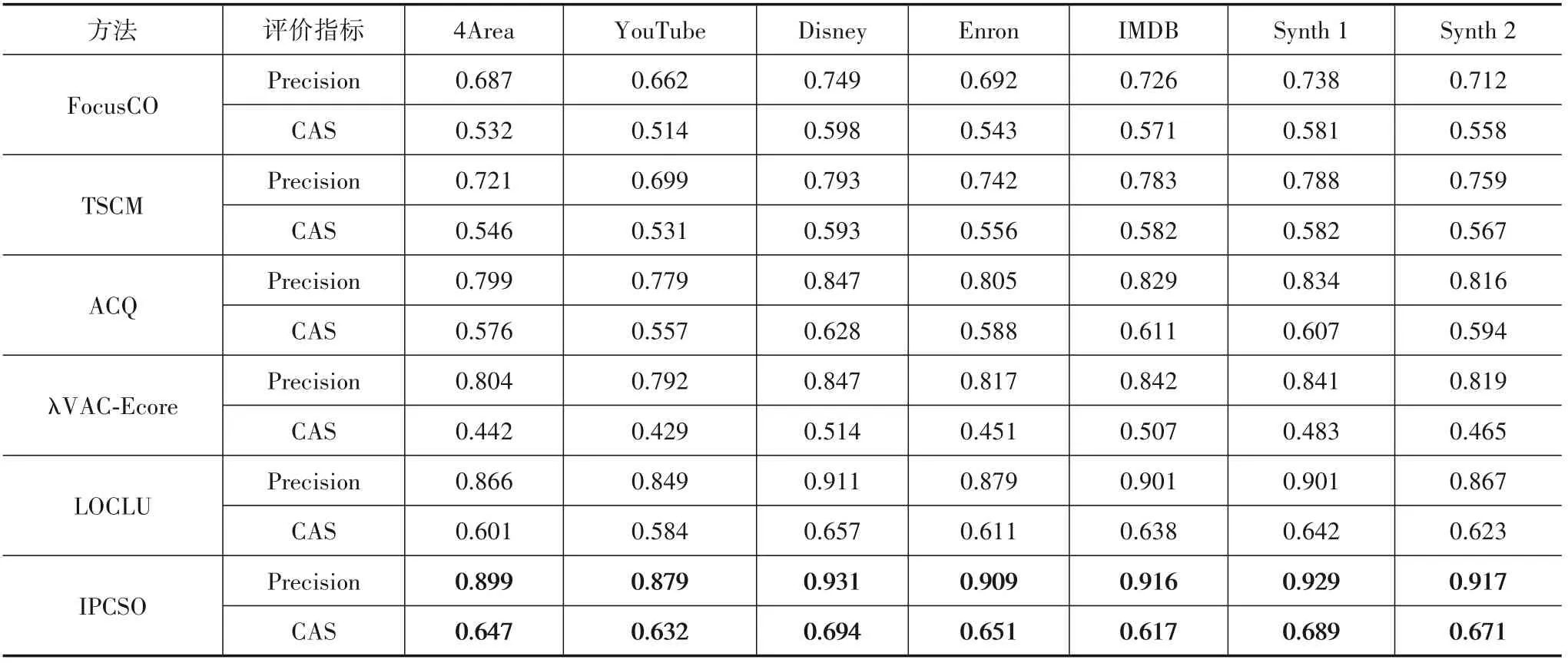
表3 IPCSO与基线方法的整体性能比较
4.5 案例分析(问题3)
本节将对比IPCSO和FocusCO在Disney上的运行结果,深入挖掘实验现象的原因.图6给出了Disney数据集上两种方法的运行结果:

图6 IPCSO与FocusCO在Dinsey上的结果对比
以影片ID是52和24的节点为查询节点,使用IPCSO与FocusCO方法分别搜索与ν52和ν24具有相似评分和价格的其他节点.结果如图6所示.其中红色节点ν52和ν24表示用户给定的查询节点,绿色节点表示离群点,算法找到与查询节点相似的节点用蓝色标识.从图中可观察到,FocusCO检测到三个目标社区,而IPCSO找到了四个社区.IPCSO发现的每个社区都与用户偏好密切相关,并且精准的定位到了离群点,而FocusCO由于较少的查询节点使得算法错误的判别了离群点.此外,FocusCO发现的社区的内部连接比IPCSO所发现的社区连接松散.这是因为较少的查询节点对于FocusCO方法而言具有较大的局限性,而本文方法对于查询节点的个数不敏感,可通过较少的查询节点准确的捕获到用户偏好,从而使得社区搜索结果更精确.
5 结论
在属性网络中结合用户偏好的社区搜索和离群点检测任务中,基于现有大多数方法仅利用拓扑结构信息且只定位查询节点所在社区,未整合用户偏好到社区搜索过程中的局限性,设计了面向属性网络的融合用户偏好的多社区和离群点检测方法.具体地,通过编码节点属性和结构得到候选查询节点集,利用候选查询节点集所携带的属性为核心属性设计了平均划分相似度来挖掘符合用户偏好的属性子空间方法,并设置结构和属性约束以搜索内聚社区.真实数据集和人工数据集上的实验证明了本文方法的有效性.
猜你喜欢
幼儿教育·父母孩子版(2022年4期)2022-05-08
计算技术与自动化(2022年1期)2022-04-15
华人时刊(2020年13期)2020-09-25
VOGUE服饰与美容(2020年9期)2020-09-02
意林(2019年11期)2019-06-30
诗选刊(2018年7期)2018-07-09
小天使·五年级语数英综合(2017年3期)2017-04-25
读写算·小学低年级(2017年1期)2017-02-06
阅读(中年级)(2016年4期)2016-11-19
海外英语(2006年11期)2006-11-30
