
油气管道监理项目资源数据挖掘技术研究
2022-11-08 07:18赵国深赵嘉玲刘思妤夏荣蓓代炳涛
化工装备技术 2022年5期
赵国深* 赵嘉玲 刘思妤 王 星 夏荣蓓 代炳涛
(河北省智慧管道技术创新中心廊 廊坊中油朗威工程项目管理有限公司)
0 引言
在人工智能、大数据、云计算、5G 网络等技术广泛应用的时代,信息技术的快速发展使传统管理模式和生产方式产生了新的变革,并加快了传统人工模式向自动化、人工智能化方向的转变进程。传统管道建设主要依靠人工执行现场质量安全制度和监管实施情况以及不符合项隐患辨识工作。由于管道施工作业面广、区域跨度大、地理环境复杂,质量安全监督工作战线长、效率低,同时,人工检查存在视程短、主观性强、工作不连续、反应慢、取证难等问题,对于一些安全隐患无法及时进行查处和现场取证。利用信息技术来完成数据采集、数据分类和数据整合已经成为解决这些问题的主要途径。大数据技术(即大数据应用技术)包含各大数据平台,拥有海量的数据,其功能是可以在各大数据平台搜集各方数据,进行整合、分类、提取并得到有用信息,形成合适的问题解决方法,使得人员布设、机械设备、物资分配等方面得到全面优化,有效降低项目成本,保证施工技术方案可行,施工质量可靠。
为了更有效地解决油气管道监理项目中的问题,需要建立项目资源数据库。该数据库需要立足打造油气储运行业项目资源池,结合行业标准以及历史项目经验,实现项目信息、承包商信息、费用信息、质量信息、进度信息等内容的收集与共享,为储运行业建设及运营提供数据支撑。本文主要通过介绍数据库各部分的构成来为管道监理数据库的建设提供依据。
1 功能需求
数据系统功能主要包括:基础信息管理功能、主题查询检索功能、数据报表功能、计费管理功能及移动端功能。其数据系统功能构成如图1 所示。
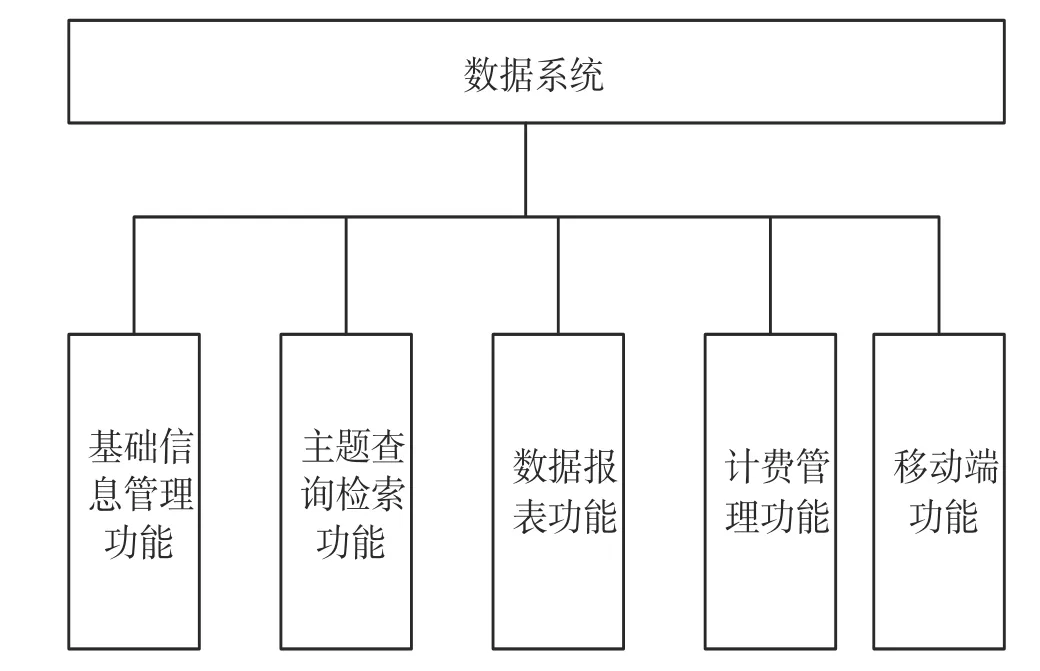
图1 数据系统功能构成
基础信息管理功能主要包含项目信息、承包商信息、造价信息、设备信息、资源投入信息、采办供应商信息等数据的录入功能;主题查询功能主要包含查询项目、查询进度、查询费用、查询延期、综合查询、高级查询、生成报告等功能;数据报表功能主要包括核心大数据智能分析展示;计费管理功能提供产品化对外提供服务的功能,支持首页、VIP 管理、积分管理、费用管理、组织架构管理、用户管理等;移动功能主要体现在实现移动应用App。
2 数据挖掘技术应用研究
2.1 技术架构
本课题研究过程中完成了1 套大数据分析云平台的部署,构建了以Hadoop 集群为基础的云平台,包括1 个主节点,3 个从节点。整个数据分析平台主要由数据的接入层、存储层、计算层、分析层及应用层五部分构成,其技术架构如图2 所示。
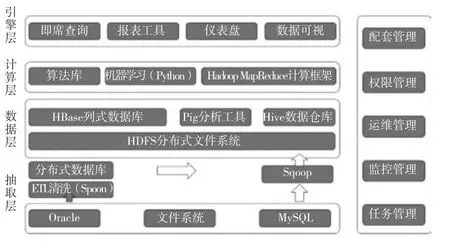
图2 数据挖掘技术架构
2.2 机器学习
在大数据学习研究过程中,按照数据获取、单因子探索分析及数据可视化、多因子关联分析、数据预处理、特征转换、模型学习及模型评估的完整流程开展,其流程如图3 所示。
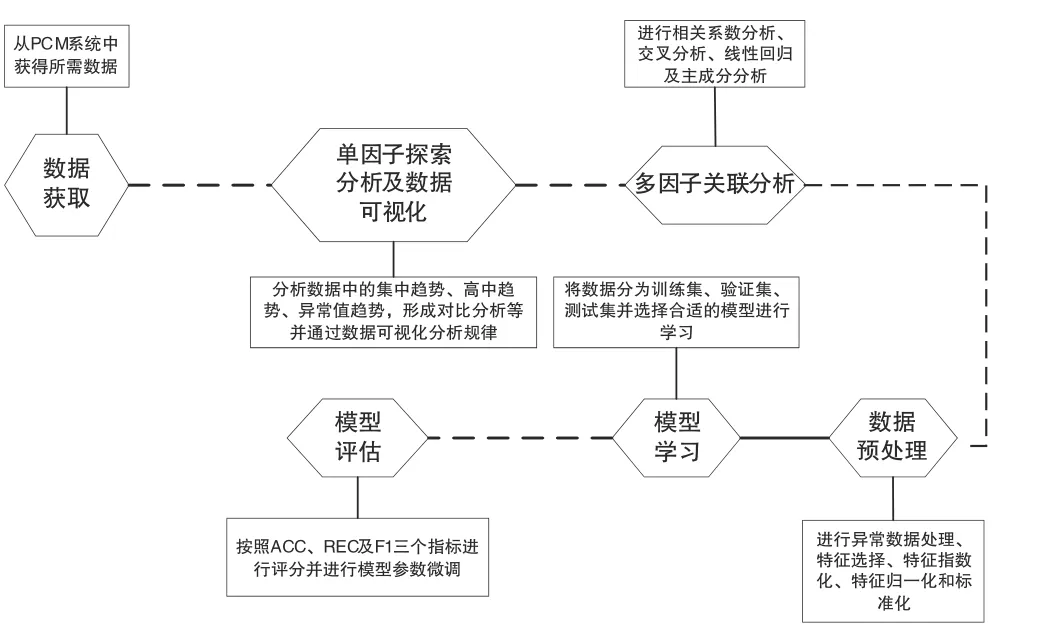
图3 机器学习流程
2.3 关键算法
随着计算机技术迅速发展,智能算法研究也进展飞速,其中集成学习算法是将几种机器学习技术组合成一个预测模型的算法,也是综合性能较高的一种智能算法。集成学习算法可以分为三类bagging(用于减少方差)、boosting(减少偏差)、stacking(提升预测结果)。这三类集成算法都用于体现参数对缺陷性质的影响程度。文中主要采用随机森林算法和XGBOOST 算法,这两种算法是分类分析算法中比较常用的算法。
2.3.1 随机森林算法基本原理
随机森林算法结构如图4 所示。
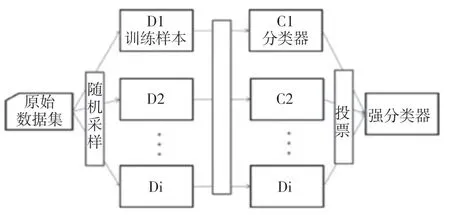
图4 Bagging结构
步骤1:选择样本。假如有N个样本,随机选择N个样本,每取完一个样本放回后继续取下一个样本,保证样本总量一直为N。将这些选好的样本作为决策树的根节点出的样本用来训练决策树。
步骤2:选择属性。选择完样本后需要考虑样本属性,假设每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m<<M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1 个属性作为该节点的分裂属性。
步骤3:确定分枝。决策树形成过程中每个节点都要按照步骤2 来分裂(如果下一次该节点选择的属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了,这样确保了树的高度≤M)。重复步骤2 直到不能再分裂为止,注意整个决策树形成过程中没有进行剪枝。
按照步骤1~3 建立大量的决策树,这样就构成了随机森林。
从以上步骤可以看出,随机森林的随机性体现在每颗树的训练样本都是随机的,树中每个节点的分类属性也是随机选择的。因此随机森林不会产生过拟合现象,最终结果由投票选举得出。
随机森林算法得出的结果表明参数对于缺陷影响的重要程度。
随机森林算法是基于Bagging 算法,装袋法。其应用流程如下所示。
样本选择:Bagging 随机有放回的取样。
样本权重:Bagging 采取的是均匀取样,且每个样本的权重相同。
预测函数: Bagging 的预测函数权值相同。
并行计算:Bagging 的各预测函数可以并行生成。
2.3.2 模型学习过程
使用随机森林进行机器学习。将数据集按照6:2:2的比例随机切分为训练集、验证集和测试集。随机森林使用10 棵基尼决策树,以全部特征为学习特征。
2.3.3 评估学习效果
以切分数据集为基础,以ACC(accuracy_score,在所有预测出来的正例中的真值)、REC(Recall score 所有正例的发现值)和F1(精确率和召回率的调和均值)三种指标对机器学习算法模型的预测结果进行评分。其评分效果如表1 所示。
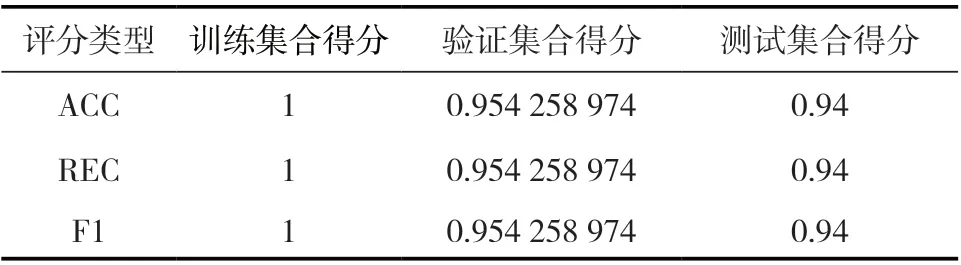
表1 评分学习效果
根据随机森林算法得出的分析结果可以通过三个维度(进度、成本、质量)来判定最优项目及较差项目,同时可以提供多维数据查询功能。查询费用情况如图5 所示,查询项目进度情况如图6 所示。
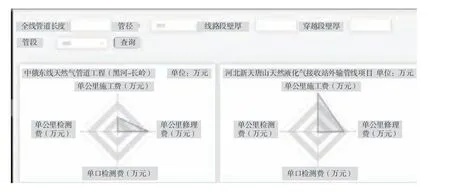
图5 查询费用情况
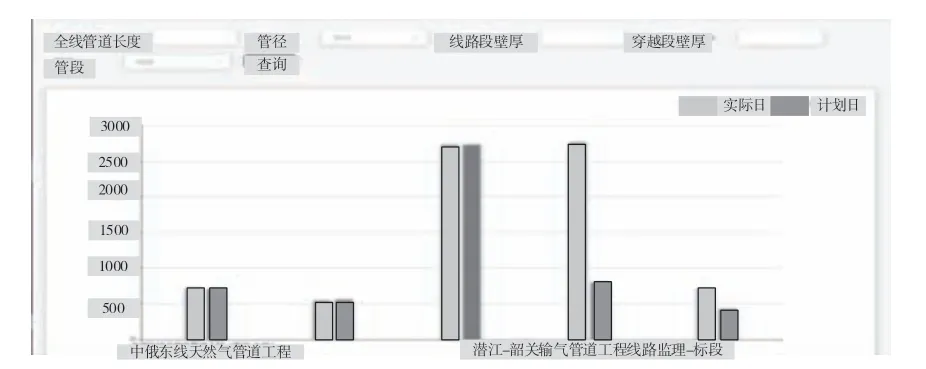
图6 查询进度情况
3 结语
遵循J2EE 开发标准,采用Java 语言开发技术方案,引入微服务的架构和场景化的理念,为快速搭建业务系统,提供持续、敏捷的应用方式,提高数据等信息化服务的开发能力。另外开发专业软件以满足展示层数据分析、二三维展示以及身份认证的需求为目的,包括数据整合分析工具、三维模型综合展示平台基础软件、文件格式转化工具等软件。整个开发平台的设计理念是采用“PaaS(平台即服务)平台”整体架构模式,引入微服务的架构和场景化的理念,以及API 技术和生态圈理念,推动“互联网+”在油气管道领域的应用。平台将对外提供多数据源接入功能,能够将来自物联设备的数据、中国石油其他平台数据,以及相关的异构数据接入平台,使得数据整合和SOA 化。接入平台的数据被封装为Web 服务,并利用SOA 架构对外提供服务,持续提高集成和部署、自动化构建代码和自动化部署能力。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
时代人物(2019年27期)2019-10-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
计算机测量与控制(2017年6期)2017-07-01
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
