
基于多尺度注意力机制和知识蒸馏的茶叶嫩芽分级方法
2022-11-08 02:21黄海松陈星燃韩正功范青松朱云伟胡鹏飞
农业机械学报 2022年9期
黄海松 陈星燃 韩正功 范青松 朱云伟 胡鹏飞
(1.贵州大学现代制造技术教育部重点实验室, 贵阳 550025; 2.贵州装备制造职业学院科研处, 贵阳 551400; 3.清镇红枫山韵茶场有限公司, 贵阳 551400)
0 引言
在茶叶生产过程中,茶叶嫩芽的分级从根本上决定了产品品质,目前主要借助人工感官评审法完成,所得结果易受人为主观性及环境因素影响[1-2]。如今,计算机视觉技术虽不断与农业工程学科交叉[3-4],但针对茶叶嫩芽分级问题,国内外学者所开展的研究仍十分有限。许高建等[5]将采用VGG-16进行特征提取的Faster R-CNN模型在COCO数据集上进行预训练后用于四等级茶叶嫩芽的分级问题,陈妙婷[6]考虑茶叶采摘时遮挡情况的干扰添加相应的图像样本,利用YOLO算法处理改进PSO-SVM提取的特征信息实现茶叶嫩芽分级,两者虽均能在较短时间内实现茶叶分级,但准确率不高且所处理的数据需事先利用图像工具进行标注,时间和人工成本较大。高震宇等[7]为实现茶叶嫩芽分级,基于多层卷积神经网络搭建识别模型,并借助局部连接的训练方式极大加快了收敛速度,但因较为简单的网络结构使其处理复杂特征的能力匮乏,在实际应用中性能难以保证。毛腾跃等[8]融合SVM与特殊角点检测两种方法对四等级茶叶嫩芽进行分级,分级准确率为94.24%,但多分类器会产生大量计算冗余,加剧设备计算负担。吴正敏等[9]基于茶叶动态下落过程中所采集到的图像数据,结合随机森林算法和分类算法,利用前者预先选出具有强可分性的复杂特征,经分类算法处理后实现茶叶嫩芽的准确分级,但模型参数量庞大,将加剧设备的计算负担。QIAN等[10]将预训练后的Inception-V3模型的权重矩阵迁移至自建茶叶嫩芽数据集之上,并利用仿射变换对数据进行增强,最终对三等级茶叶的分级准确率达到了98%,但模型较大,不利于投入实际应用。XU等[11]提出了一种联合电子鼻和计算机视觉技术的茶叶品质鉴定方法,采用KNN、SVM等完成识别模型的建模,并通过融合策略对两者信号进行分析,综合两维度的信息实现精准分级,但使用成本较高且环境要求较为严苛。在实际应用中茶叶嫩芽图像采集面临着诸多困难,而上述分级方法普遍存在冗余参数多和模型规格大的缺点,在小规模数据集上易出现模型过拟合现象,严重影响分类性能,且对设备储存和计算能力要求高,难以部署到生产现场中。
综上,本文基于采摘自贵州红枫山韵茶场的茶叶嫩芽自建图像数据集,构建以多尺度注意力单元为核心的分级模型,聚焦强分级特征并从感知野和网络纵深两个层面充分提取茶叶嫩芽图像中的多尺度特征信息;提出一种结合双迁移学习和知识蒸馏的分级方法,在保证模型轻量高效的前提下,提升抵抗过拟合的能力和分级性能。
1 迁移学习和知识蒸馏
为解决现有方法在小规模茶叶嫩芽数据集上因模型过拟合现象严重影响分级性能,及模型所占内存空间大难以应用到实际生产中的问题,本文在构建一种轻量型分级网络的基础上,提出结合双迁移学习(Transfer learning, TL)和知识蒸馏(Knowledge distillation, KD)的分级方法,进一步提升模型稳健性和分级性能。本文中TL从两个源域数据中提取知识并将该部分知识应用于解决茶叶嫩芽分级任务之中。与多任务学习不同,TL会更加倾向于关注目标任务,而不是同时关注源任务和目标任务[12]。如图1所示,TL可以在目标任务中高质量训练数据较少的情况下,避免从头开始学习每一项任务,充分利用预训练时的源域信息,将从以往任务中习得的知识迁移至该目标任务之中。KD则是由多伦多大学的HINTON等[13]提出的一种知识迁移技术,借助混合损失函数的反向传播将教师模型(Teacher module)所习得的先验知识传授给学生模型(Student module),以达到压缩教师模型和增强学生模型性能的目的。
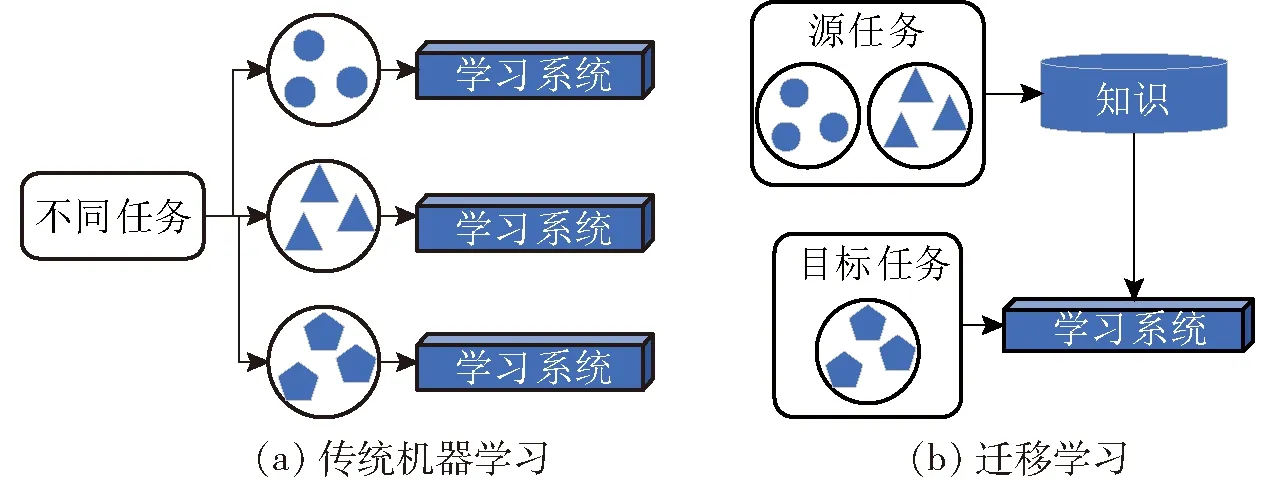
图1 学习过程示意图Fig.1 Learning process diagrams
2 基于多尺度注意力机制和知识蒸馏的方法
2.1 卷积块注意力模块
卷积块注意力模块(Convolutional block attention module, CBAM)由WOO等[14]于2018年提出,其借助通道注意力模块(Channel attention module, CAM)和空间注意力模块(Spatial attention module, SAM)推理注意力特征图并与输入特征图相乘,使模型提取出更具区分性的特征,并抑制无关特征,达到自适应优化特征和提高模型性能的目的。CBAM凭借轻量的特性,可以嵌入到任何卷积神经网络(CNN)结构。
2.1.1通道注意力模块
CAM主要关注特征矩阵中有价值的信息,提取分辨性较强的特征。通过对输入特征进行最大池化(MaxPool)和平均池化(AvgPool)操作压缩空间维度上的特征信息,生成两种不同空间上的特征图,经多层感知器(MLP)处理后逐元素相加,最后通过Sigmoid激活函数进行非线性转换,其结构如图2所示。
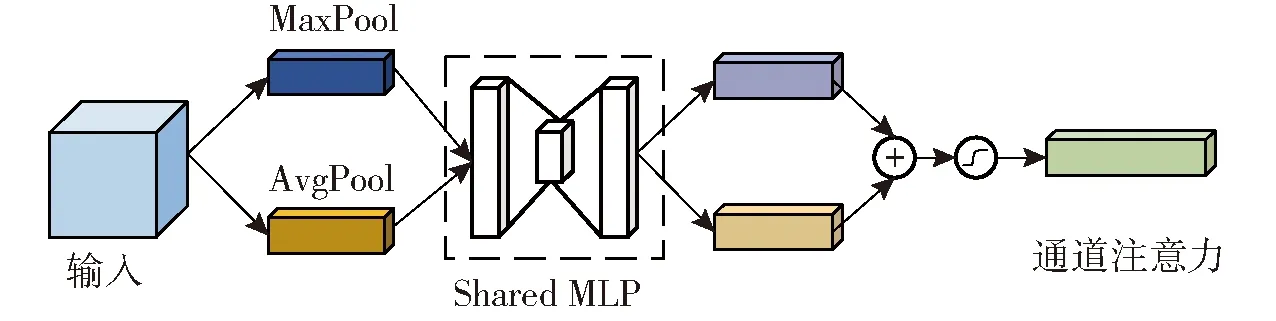
图2 通道注意力模块Fig.2 Convolutional block attention module
2.1.2空间注意力模块
SAM主要关注输入特征矩阵映射的位置信息,是对CAM的一种补充。输入特征图在经过沿空间维度的平均池化和最大池化操作后被拼接为一个通道数为2的三维空间特征图,后经卷积操作及Sigmoid激活函数处理生成空间注意力特征图,其结构如图3所示。
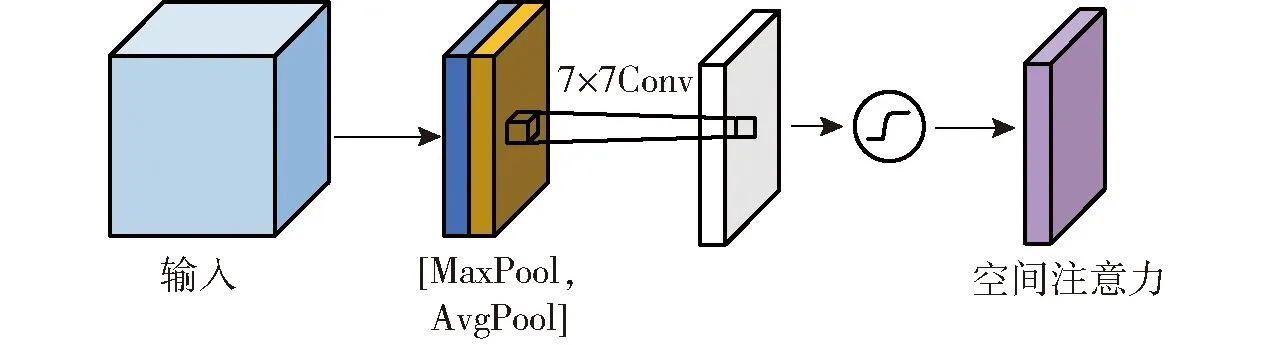
图3 空间注意力模块Fig.3 Spatial attention module
2.2 多尺度卷积块注意力模块
为使模型更加关注茶叶嫩芽图像的感兴趣区域,聚焦有利于分级的重要特征信息并抑制无关特征,本文引入注意力机制对茶叶嫩芽图像中的强分级特征信息进行提取与处理。由于茶叶嫩芽图像采集较为困难,为在有限的数据集上尽可能地挖掘特征信息,本文提出了一种多尺度空间注意力模块(Multiscale spatial attention module, MSAM),并通过与CAM结合构建了多尺度卷积块注意力模块(Multiscale convolutional block attention module,MCBAM),其结构如图4所示。在MSAM中用卷积核尺寸为5×5和9×9所构成的多尺度特征提取卷积层替换原普通卷积层,对经池化操作后的特征进行处理,并利用1×1卷积层实现多尺度特征信息的整合,两种不同的感知野较原始固定大小的卷积层更有利于模型提取茶叶图像中的多尺度特征信息[15]。对MCBAM而言,输入特征经CAM处理得到加权结果后再经MSAM加权得到输出特征图。
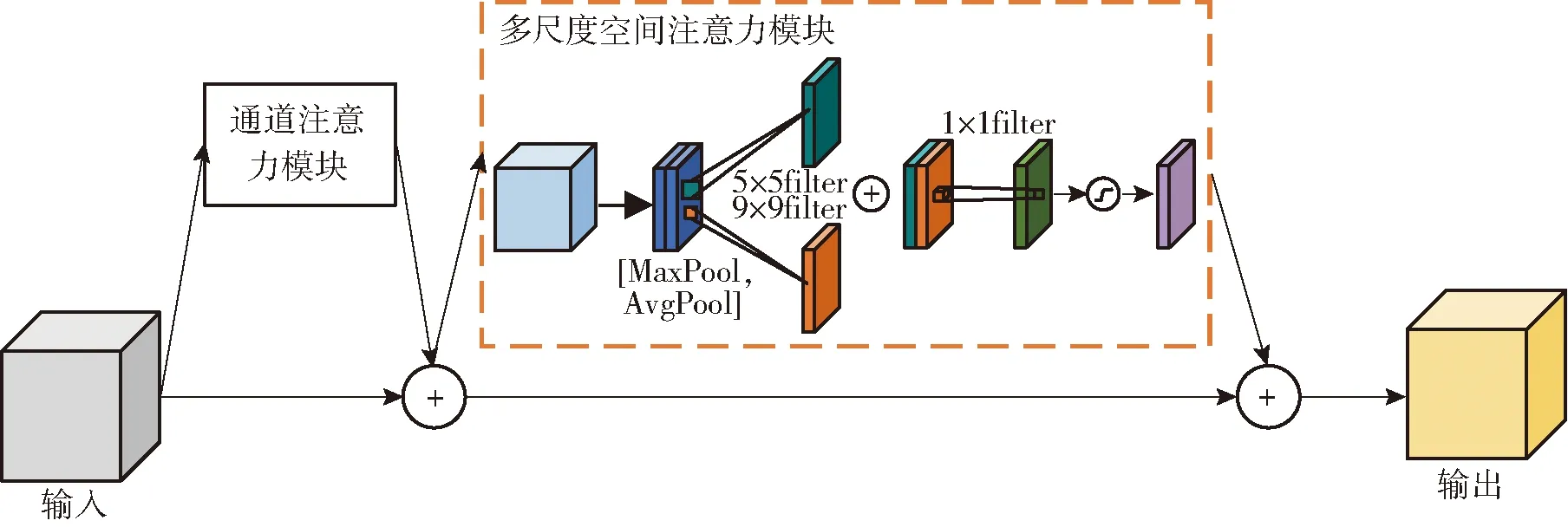
图4 MCBAM注意力模块Fig.4 MCBAM attention module
2.3 模型网络设计
ShuffleNet-V2网络为MA等于2018年提出的一种轻量型网络,引入了通道拆分(Channel split)、通道清洗(Channel shuffle)以及用保持通道数不变的分支拼接代替逐元素相加等操作,完全符合高效网络结构设计应该遵守的G1~G4准则,在计算复杂度和精度上有优异的综合表现。
结合ShuffleNet-V2 0.5x基本单元、MCBAM、多尺度深度捷径(Multiscale depth shortcut, MDS)构建Shuffle多尺度注意力单元(Shuffle multiscale attention unit, SMAU),如图5所示。在ShuffleNet-V2 0.5x基本单元的3组卷积层之后以串联的方式嵌入MCBAM,对经卷积层处理后的特征信息进行不同大小感知野下多尺度信息的提取及强分级复杂特征信息的增强。通过MDS(图5中①②③)将不同网络纵深下的特征信息进行融合,避免信息流传递过程中有效特征信息的损失,提高分级性能。且MDS可充当梯度反向流动的高速通道,使梯度不受阻碍的流动,缓解模型退化的问题,增强模型的稳健性[16],并在MCBAM、卷积层和整个SMAU之间构造成恒等映射,实现MCBAM与卷积层间的自适应组合[17],避免因引入MCBAM而引起精度下降。最终使模型聚焦茶叶嫩芽图像中有利于分级的特征,并从感知野大小和网络纵深两个层面提取多尺度特征信息用于分级,充分利用有限的数据,强化模型处理小规模数据集的能力。基于ShuffleNet-V2 0.5x的网络结构,以SMAU为核心构建一种融合多尺度注意力机制的轻量型茶叶分级模型ShuffleNet-V2 0.5x-SMAU,结构见表1。
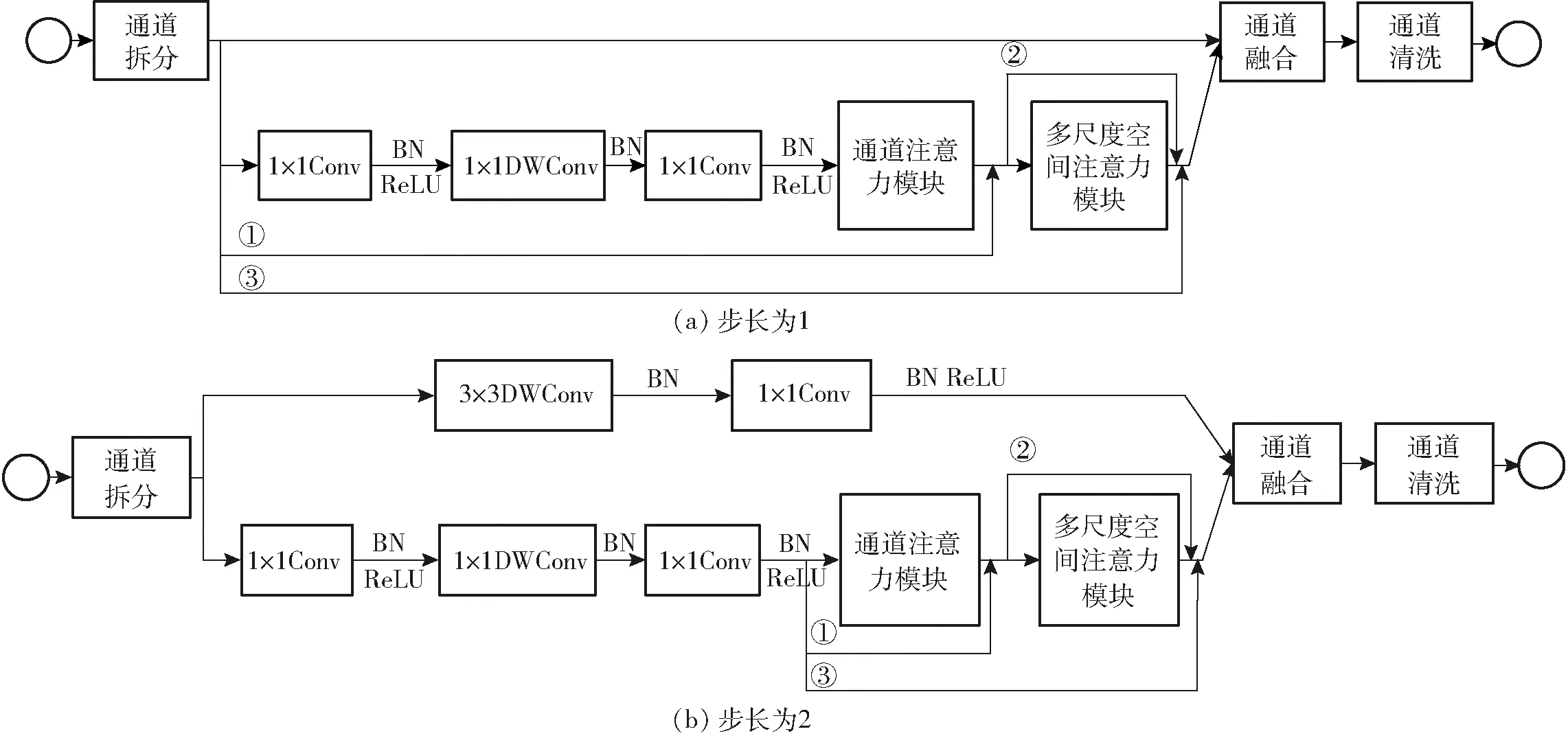
图5 多尺度注意力单元Fig.5 Shuffle multi-scale attention unit
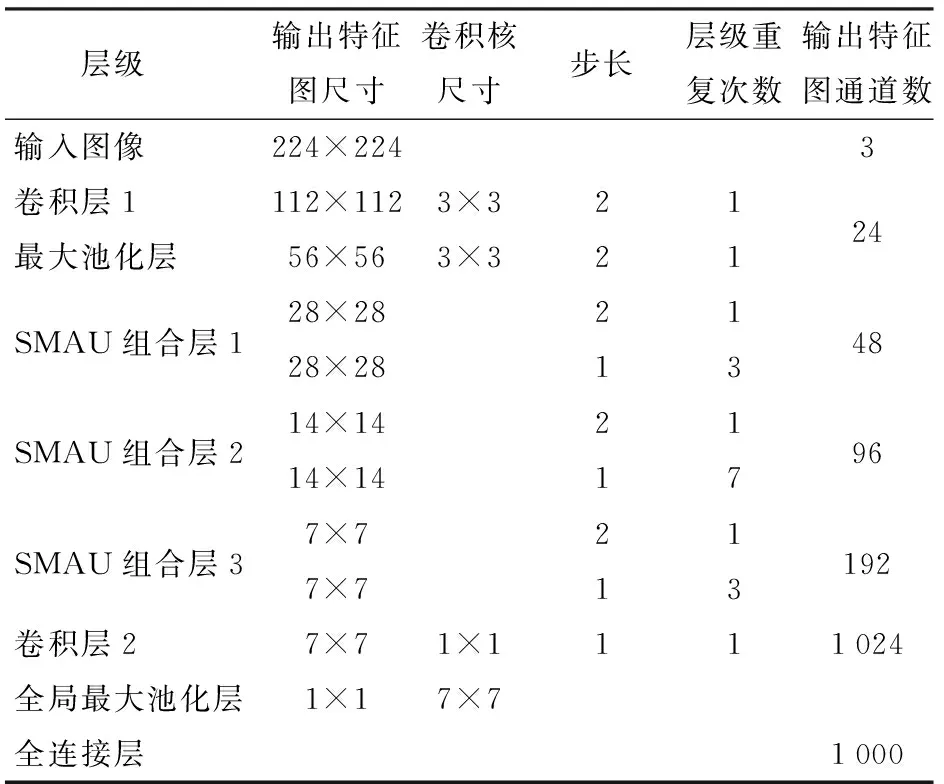
表1 ShuffleNet-V2 0.5x-SMAU网络结构Tab.1 Structure of ShuffleNet-V2 0.5x-SMAU
2.4 结合双迁移学习和知识蒸馏的茶叶嫩芽分级方法
本文引入迁移学习以充分利用源域的丰富特征信息,ShuffleNet-V2 0.5x-SMAU通过在大规模数据集上的预训练可以增强其在茶叶嫩芽数据集上抵抗模型过拟合的能力,并提高分类性能。结合知识蒸馏技术,提出一种结合双迁移学习和知识蒸馏的茶叶嫩芽分级方法,将预训练后的教师模型所习得的暗知识蒸馏到网络结构更简单、参数量更少的ShuffleNet-V2 0.5x-SMAU中,以增强其分类性能和处理小规模数据集的能力。
在茶叶嫩芽分级领域,由于目前尚无公共数据集,故常将Oxford-17 flower和Oxford-102 flower数据集应用于模型的预训练[10],但综合考虑计算量和时间成本等因素,基于Oxford-102 flower数据集中的50种花卉图像数据建立flower-50数据集。在flower-50上通过引入Focal Loss损失函数对学生模型进行预训练,可减少易分类样本的权重,使模型更关注难分类的样本[18]。
结合双迁移学习和知识蒸馏的茶叶嫩芽分级方法,训练出能实现不同等级新鲜茶叶嫩芽划分的模型。将在ImageNet上预训练后的Resnet32以及在flower-50上预训练后的ShuffleNet-V2 0.5x-SMAU的模型参数矩阵迁移至HF-G3数据集上,以解决茶叶嫩芽分级问题,在利用该方法训练模型时依次以二者构造教师模型及学生模型。利用该方法进行训练的流程如图6所示,设置温度T为10,比例系数α为0.8。利用结合双迁移学习和知识蒸馏的茶叶嫩芽分级方法进行模型训练的步骤为:
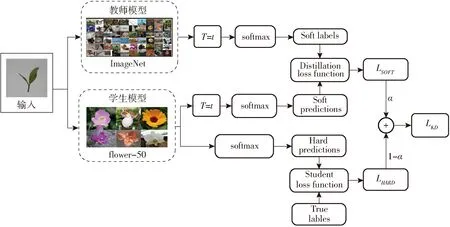
图6 基于双迁移学习和知识蒸馏的茶叶嫩芽分级方法结构图Fig.6 Structure diagram of tea bud grading method based on dual transfer learning and knowledge distillation
(1)以像素矩阵的形式将茶叶嫩芽图像信息输入到教师模型中得到对应各等级茶叶的概率分布,并通过逐次除以温度T进行平滑处理,后经softmax函数得到教师模型的软标签(Soft labels)qSLi,计算公式为
(1)
式中xTi——教师模型最后一层输出的特征图
n——特征图像通道数
(2)将茶叶嫩芽图像信息输入学生模型,并按步骤(1)中温度进行平滑处理,经softmax函数得到学生模型的软预测(Soft predictions)qSPi, 计算公式为
(2)
式中xSi——学生模型最后一层输出的特征图
(3) 将茶叶嫩芽图像信息输入学生模型,所获概率分布直接由softmax函数处理获取学生模型的硬预测(Hard predictions)qHPi,计算公式为
(3)
(4)由相对熵损失函数(Kullback-Leibler Divergence)对步骤(1)中获得的软标签和步骤(2)中获得的软预测进行计算得到软损失函数值LSOFT,计算公式为
(4)
式中B——批处理图像数量
C——茶叶嫩芽等级数
qSPj——学生模型软预测
(5)由交叉熵损失函数(Cross entropy)对步骤(3)中获得的硬预测和真实标签(True lables)进行计算得到硬损失函数LHARD,计算公式为
(5)
式中yTRUE——真实标签
qHPj——学生模型硬预测
(6)最后通过比例系数α调整两损失值的比例后得到混合损失函数LKD,计算公式为
LKD=(1-α)LHARD+αT2LSOFT
(6)
其中,LKD的反向传播是教师模型将暗知识授予学生模型并大幅提高学生模型分类性能的关键。
3 实验结果与分析
3.1 数据处理与实验设置
本文所用茶叶嫩芽图像采集平台由中科微创ZW-C3600型工业相机、变焦镜头及LED环形补光灯等组成,如图7所示。所拍摄茶叶均采摘于贵州省清镇市红枫山韵茶场,由茶场工人将原始茶叶嫩芽图像样本分为单芽、一芽一叶、一芽两叶共3个等级,如图8所示。选用翻转、平移、旋转及添加随机噪声4种数据增强方式对茶叶图像进行扩容处理,如图9所示。最终获得茶叶嫩芽图像数据共计2 136幅,其中对应3种不同等级的茶叶嫩芽各712幅,并按照比例3∶1将所得数据划分为训练集与测试集,作为本文实验采用的HF-G3图像数据集。

图7 茶叶嫩芽图像采集平台Fig.7 Tea bud image collection platform1.中科微创ZW-C3600型工业相机 2.变焦镜头 3.LED环形补光灯

图8 HF-G3数据集中3种不同等级茶叶的原始图像Fig.8 Three original images of tea at different levels in HF-G3 dataset

图9 经数据增强后的茶叶图像Fig.9 Tea image after data enhancement
本文设置了消融实验和对比实验。在消融实验中,以准确率变化曲线、茶叶嫩芽分级混淆矩阵等指标对多尺度注意力机制、结合双迁移学习和知识蒸馏的分级方法的合理性与有效性进行验证。在对比实验中,则是面向其他现有技术,从模型抗过拟合能力、分级能力、分级均衡性及模型规格4个角度对本文方法在综合性能上的优越性进行论证。
3.2 消融实验结果与分析
为验证本文方法的有效性,依次设置采用本文茶叶分级方法的实验组A(ShuffleNet-V2 0.5x-SMAU+TL+KD)、基于传统CBAM注意力模块的实验组B(ShuffleNet-V2 0.5x-CBAM+TL+KD)、学生模型未在flower-50上进行预训练的实验组C(ShuffleNet-V2 0.5x-SMAU+KD)以及未采用知识蒸馏的实验组D(ShuffleNet-V2 0.5x-SMAU+TL)。在HF-G3测试集数据上验证4个实验组的分级性能,通过Origin2019b绘制各实验组对应的准确率变化曲线,如图10所示。为进一步分析针对不同等级茶叶嫩芽进行分级时性能的差异,绘制各实验组对应的混淆矩阵,如图11所示。各级茶叶分级准确率及平均准确率如表2所示。
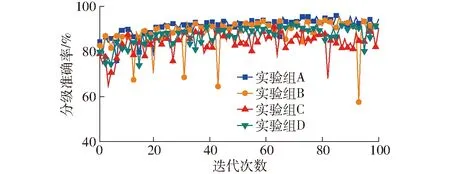
图10 各消融实验组在测试集上的准确率变化曲线Fig.10 Accuracy rate change curves of each ablation experimental group on test set
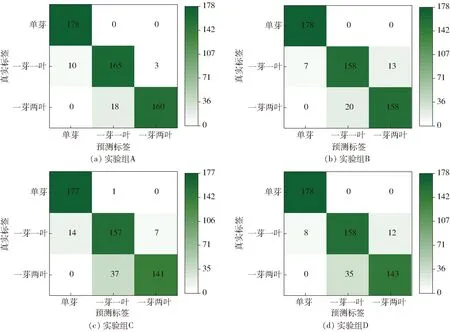
图11 各消融实验组在测试集上的混淆矩阵Fig.11 Confusion matrices of each ablation experiment group on test set
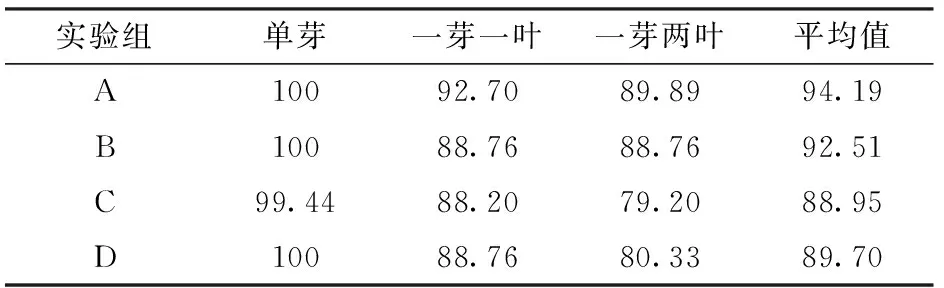
表2 各消融实验组在测试集上的分级准确率Tab.2 Classification accuracy of each ablation experiment group on test set %
从图10可知,实验组A与实验组B准确率分别为95.88%、95.13%,表现出了近似的分类性能,但后者对应的变化曲线震荡严重,说明SMAU相较于传统CBAM注意力模块,可以向模型提供更丰富的多尺度特征,并借助MDS构建恒等映射,有效缓解模型过拟合现象。对比实验组A、C,实验组A的分类性能明显优于实验组C,且实验组C出现了明显的过拟合现象,说明实验组A中通过学生模型在flower-50上的预训练,能在提高模型分类性能的同时,增强模型抵抗过拟合的能力。对比实验组A、D,前者因以预训练后的Resnet32作为教师模型进行知识蒸馏,较实验组D的最高分级准确率提高了3.87个百分点,并借助教师模型所习得的庞大权重矩阵在一定程度上缓解了过拟合现象,该组对比验证了知识蒸馏的有效性。
由表2可知,由于一级茶叶(单芽)区分特征明显,各实验组对其进行划分的准确率都十分理想,而在对另外两等级茶叶(一芽一叶、一芽两叶)的划分中实验组A的准确率最高,分别为92.70%、89.89%。对比实验组A、B,实验组A在一芽一叶及一芽两叶分级中,准确率较实验组B分别提高了3.94、1.13个百分点,说明SMAU更能使模型聚焦到利于分级的多尺度特征。对比实验组A、C、D,在对一芽两叶的识别准确率上,实验组A比另外两组高10.68、9.56个百分点,说明基于双迁移学习和知识蒸馏的茶叶等级分级方法能使模型处理茶叶复杂特征的能力得到显著提升。
在此部分所设置的消融实验中,本文方法对教师模型与学生模型均进行预训练,并将所获取到的权重参数矩阵迁移至茶叶嫩芽分级问题上,借助梯度反向传播将教师模型所习得暗知识向学生模型进行传授,结果表明该方法极大增强了学生模型获取和分析茶叶复杂特征的能力,使分类性能取得大幅提升。且通过相关实验的设置亦证明了SMAU较传统CBAM在茶叶等级划分问题上的优越性。
3.3 对比实验结果与分析
针对茶叶分级问题,为衡量本文ShuffleNet-V20.5x-SMAU+TL+KD与其他方法间性能的差异,本部分设置实验从抗过拟合能力、分级能力、分级均衡性、模型规格4方面依次对本文模型与FI-DenseNet[19]、Alter-Second Model[15]、ResNet18-Green tea[20]、AlexNet-Camelia[21]在HF-G3测试集上的表现进行对比。利用Origin2019b绘制各对比实验组的准确率与损失值变化曲线,如图12所示。基于图13所示的混淆矩阵,计算不同等级茶叶嫩芽的分级准确率及平均准确率,并绘制分级准确率柱状图,如图14所示。为从模型规格的角度深度探究对比模型间差异,以计算量、参数量、模型规格为指标制定如图15所示的模型比较柱状图。
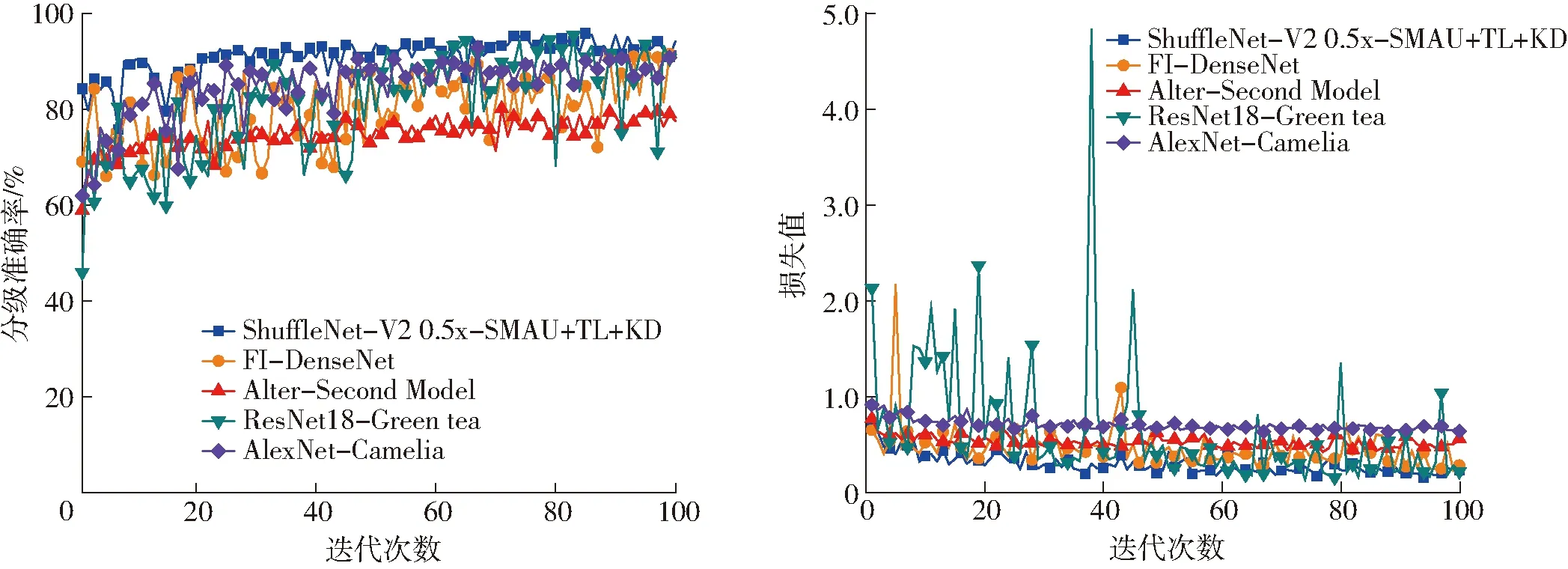
图12 各对比模型在测试集上的准确率及损失值变化曲线Fig.12 Accuracy and loss curves of each comparison model on test set
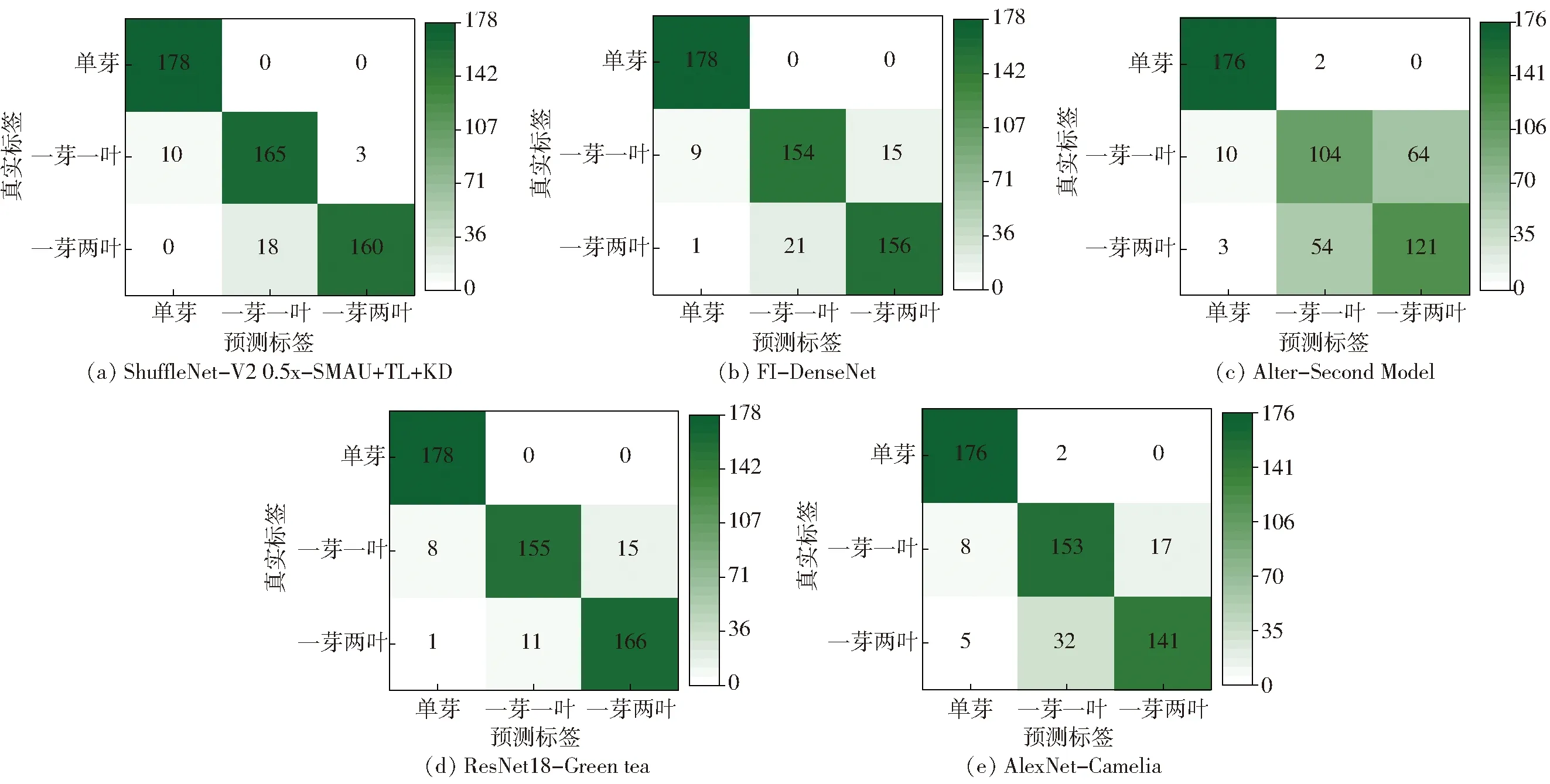
图13 各对比模型在测试集上的混淆矩阵Fig.13 Confusion matrices of each comparison model on test set
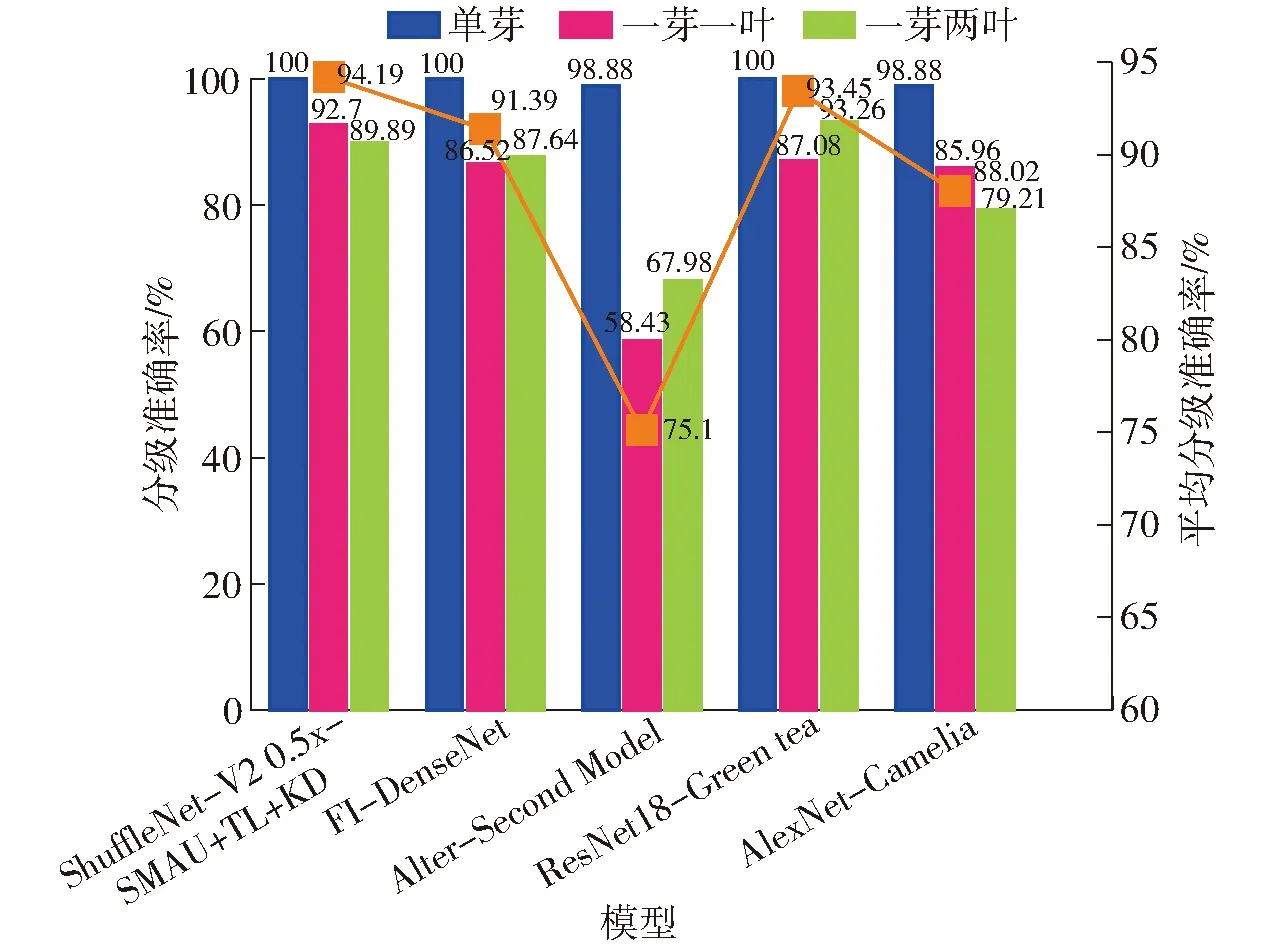
图14 各对比模型在测试集上的分级准确率Fig.14 Classification accuracy of each comparison model on test set
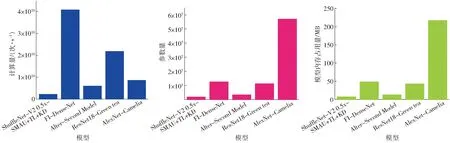
图15 各对比模型比较Fig.15 Comparison charts of each comparison model
从茶叶嫩芽分级准确率及损失值变化曲线看,本文的初始准确率最高。与FI-DenseNet及ResNet18-Green tea进行比较,两者分别基于DenseNet169及ResNet18搭建,最高分级准确率分别为91.57%、95.51%,与本文模型最高准确率94.94%具有相似的分类性能,但进一步观察变化曲线,可看出后两者震荡剧烈,出现了所有模型中最为严重的过拟合现象,说明基于复杂网络模型的方法并不适用于解决小规模茶叶等级划分问题。与Alter-Second Model对比,本文模型中的SMAU使模型不只限于感知野下的多尺度特征,还能挖掘不同深度下的多尺度特征,同时在注意力机制作用下,对有利于分级的特征进行增强,在同样拥有极强抵抗过拟合能力的条件下最高准确率较Alter-Second Model上升了14.34个百分点,收敛时损失值自0.415 1下降至0.150 7。AlexNet-Camelia采用了迁移学习的方法,表现出了一定的抵抗模型过拟合的能力,损失值曲线收敛迅速,震荡微弱,但准确率曲线仍存在一定幅度的震荡,本文模型不同于AlexNet-Camelia只是简单的结合AlexNet和迁移学习技术进行特征提取和分析,本文模型是将预训练后的ShuffleNet-V2 0.5x-SMAU和ResNet32模型参数迁移至茶叶分级中,并依次作为知识蒸馏中的学生和教师模型,这种方式不但使学生模型的稳健性得到大幅提升,也通过暗知识的传授,使分级性能得到很大程度的增强,使其最高准确率较AlexNet-Camelia上升了2.06个百分点,收敛时损失值自0.626 7下降至0.150 7。
从对不同等级茶叶嫩芽的分级准确率及平均准确率看,本文凭借MCBAM与MDS,从不同感知野和网络深度聚焦多尺度特征信息,且通过结合迁移学习与知识蒸馏,充分利用在源域中所得的权重矩阵,在避免模型过拟合的情况下兼具了优异的茶叶分级能力,对一芽一叶的划分准确率达到了92.70%,较其他方法分别提高了6.18、34.27、5.62、6.74个百分点。在一芽两叶分级问题上,ResNet18-Green tea虽凭借其复杂的网络结构表现出了最高的分类准确率,但本文模型的分级精度较其余对比实验组仍上升显著,且在平均准确率上本文模型的准确率为94.19%,优于其余模型的分级均衡性。
从模型规格看, 除Alter-Second Model以外,本文模型无论是在计算量、参数量还是模型内存占用量上都较其余模型小一个量级,表现出了最高的效率和最佳的轻量性。进一步观察,Alter-Second Model利用深度可分离卷积在很大程度上减小了模型的规格,使其计算量和参数量在与本文模型保持在同一量级。AlexNet-Camelia虽然拥有较少的计算量,但因采用微调的迁移学习方式冻结了大量的权重,使模型仍有庞大的参数量和计算冗余。本文模型与ResNet18-Green tea比较,计算量、参数量及内存占用量3项指标仅为后者的10.17%、16.4%、16.73%,由此得知本文模型在轻量化上远优于ResNet18-Green tea。
综上所述,本文提出的茶叶嫩芽分级方法,能在确保模型轻量化的前提下从感知野和网络深度两个层面对茶叶图像的多尺度特征信息进行聚焦,并借助结合双迁移学习和知识蒸馏的方法,使模型在处理小规模茶叶嫩芽数据集时,不仅拥有极强的抗过拟合能力和分类性能,还同时拥有所有对比模型中最少的计算冗余参数和最小的模型规格,对设备要求最低,更易部署到茶叶嫩芽分级实际场景中,展现出了所有对比模型中最佳的综合能力。
4 结束语
本文将MCBAM嵌入ShuffleNet-V2 0.5x网络的基本单元中,并通过引入MDS构建了一种轻量型茶叶嫩芽分级模型ShuffleNet-V2 0.5x-SMAU。在利用本文方法进行茶叶嫩芽分级时,将在两个大型数据集上预训练后的ResNet32、ShuffleNet-V2 0.5x-SMAU依次作为教师模型与学生模型。在自建茶叶嫩芽图像数据集HF-G3上设置了2组实验:在消融实验中,依次对SMAU、本文方法的合理性及优越性进行了充分论证;在与FI-DenseNet、Alter-Second Model、ResNet18-Green tea、AlexNet-Camelia对比实验中,本文方法对单芽、一芽一叶、一芽两叶的分级准确率为100%、92.70%、89.89%,平均准确率为94.19%,计算量为2.219 6×109,参数量为1.826 9×106,模型内存占用量为7.13 MB,在抗过拟合能力、分级能力、分级均衡性、模型规格上表现出了最优异的综合性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
红蜻蜓(2021年2期)2021-07-20
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
上海师范大学学报·自然科学版(2019年5期)2019-12-13
阅读(中年级)(2019年3期)2019-04-24
