
基于区块链的河豚供应链可信溯源优化研究
2022-11-08 02:20邹一波
农业机械学报 2022年9期
陈 明 孙 浩 邹一波 葛 艳 陈 希
(1.上海海洋大学信息学院, 上海 201306; 2.农业农村部渔业信息重点实验室, 上海 201306)
0 引言
河豚是一种剧毒鱼类, 特别是肝脏、性腺和血液中含有大量的河豚毒素[1],不当处理或错误食用可能会导致中毒。然而由于它肉质美味细腻和营养丰富,自古以来深受食客喜爱[2]。国家相关部门严禁销售野生河豚、养殖河豚活鱼和未加工整鱼[3],但是近年来销售和食用河豚中毒人死亡等事件[4-6]仍时有发生。河豚不同于其他水产品,根据国家相关规定,河豚产品需拥有明确可溯源标识才可以在市场上流通。传统溯源模型通过数据库存储数据,数据库在上传或更新数据时存在信息篡改的风险。因为河豚溯源信息的分布式存储特性,溯源时需要依次查询供应链的数据库,所以溯源效率较低。这些问题导致传统溯源模型难以应用于河豚供应链,因此河豚行业急需建立一个可靠有效的溯源模型[7]。
农产品供应链溯源研究中,一些研究结合射频识别设备(Radio frequency identification,RFID)、二维码、同位素技术和移动无线监测等技术,提供了供应链全程溯源系统[8-11],建立了供应链食品质量安全溯源体系[12-14],实现了农产品可溯源性和食品质量安全性的需求。但传统的溯源技术还存在以下问题:供应链中各个厂商不同的底层平台导致的信息孤岛效应;溯源系统的防篡改能力不足。区块链技术由于其不可篡改和分布式的特点常应用于溯源系统中,其分布式特点可以打破部门壁垒,实现信息共享[15]。近些年来国内外学者将区块链技术应用到农产品溯源过程中[16-18],利用量子密钥分发技术提高数据安全性[19],结合危害分析及关键控制点(Hazard analysis and critical control points,HACCP)保障产品安全[20-21]等。
但是区块链技术牺牲了部分效率来保证数据安全性[22],这是因为区块链及其存储方式应用于溯源系统时,需要多次遍历区块链来获取数据,所以导致了溯源查询效率低[23],从而限制了区块链在河豚供应链溯源中的应用。针对区块链溯源效率低的问题,杨信廷等[24]通过区块链溯源模型外接本地数据库的方式存储区块号来实现快速溯源。但溯源的过程中采用本地数据库会削弱区块链的不可篡改性、去中心化、分布式的特点。
本文以提高基于区块链的河豚供应链溯源模型的查询效率为目的,将对河豚业务供应链信息进行分析,整理并提取供应链各业务环节主要信息;基于区块链技术建立河豚供应链溯源存储优化模型,设计多链快速查询模式并制定供应链信息溯源智能合约,构建河豚供应链信息溯源系统;以江苏省某河豚企业供应链信息为例,进行相应的性能对比测试,以期实现基于区块链河豚供应链模型的快速溯源。
1 相关技术基础
区块链是一种分布式的数字账本,可以通过区块记录多个交易信息,不依赖于单个节点进行安全维护,因此确保了信息的安全性[25]。区块链由连续的多个区块组成,区块由区块头和区块体组成,区块头中包含区块号、当前区块哈希值、前一区块哈希值、时间戳等数据,区块体中记录了交易详细信息,具体包括交易数量、交易标识码(Identification,ID)、交易双方地址等数据,交易数据通过Merkle树逐级将哈希值传递到根节点,保证了交易具有防篡改特点[26]。由于区块链计算能力和共识算法相应速度有限,当数据量增加时,其交易吞吐量会快速下降[27]。交易ID是由一串固定长度的随机Byte种子+证书中的身份信息部分组成的哈希字符串[28],交易ID具有唯一性并且具有对应的交易地址,并且采用交易地址可以更快速地查询到相应的交易。
智能合约是运行在区块链上的一段计算机程序,在预定条件满足时,能够自动强制地执行合同条款,实现“代码即法律”的目标[29]。在以太坊公链中,智能合约可同时运行在全网所有节点,任何机构和个人都无法将其强行停止。在联盟链中,因为节点数量的有限性,同时为了提高系统运行效率,节点之间不会竞争记账权,而依据智能合约生成的交易直接记录到区块链中。智能合约扩展了区块链的功能,丰富了区块链的上层应用,依照商业逻辑编写完智能合约代码后,需要将其发布到区块链网络节点上[23]。
2 河豚供应链业务信息分析
河豚供应链的特点是环节众多,厂商之间相互独立,并且监管部门对河豚的溯源要求较高,导致业务信息数据结构不统一,需要记录和传递的数据量大。本文针对河豚业务信息特点,对河豚供应链从溯源的角度分为养殖、加工、仓储、物流、销售5个阶段,最后进入末端消费者手中,如图1所示。将河豚供应链各环节业务信息分为溯源码信息和一般产品信息。溯源码信息可以实现一码一物相互对应,消费者通过溯源码即可查找到对应的产品信息。产品信息包括厂商信息、合格证明信息。以加工阶段为例,加工厂商对河豚加工环节信息进行记录,以加工批号作为加工阶段溯源码,通过加工溯源码对加工阶段的业务信息溯源。对河豚产品中河豚毒素残留影响最大的是加工阶段的解剖去毒环节,这个环节工艺水平将会直接影响后续河豚产品的食品安全。所以在加工阶段所需要记录的数据不仅有加工溯源码、厂商名称、加工时间、加工温度等,还要记录病原微生物、河豚毒素合格证明信息[30]。河豚供应链业务信息分析可以为后续建立河豚供应链溯源模型提供基础。
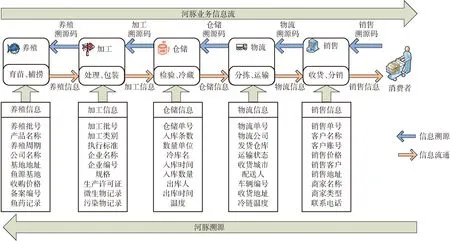
图1 河豚供应链溯源业务信息Fig.1 Tracing business information of pufferfish supply chain
3 多链河豚溯源优化模型构建
3.1 河豚供应链溯源优化模型架构
一般区块链溯源模型在利用单链结构上链时,不同环节的数据需要分开上链,各环节上链数据不会连续地存在区块上,导致查询时需要顺序遍历整条链才能查找到全部溯源数据,随着数据量的增加,顺序遍历的速度会线性增加,从而使得查询速度变慢[31]。本文针对河豚供应链特点,结合实际溯源的需求,基于区块链和智能合约技术,搭建河豚供应链信息溯源模型,如图2所示。信息溯源模型统一管理供应链所有生产环节的信息,将映射关系根节点信息存储到主链中,叶子节点信息存储到子链中,来实现快速溯源查询。模型在去中心化的环境中存储了所有生产环节厂商的数据以及关联信息,这样既保障了溯源数据的防篡改性、可信性、安全性,同时保证了溯源查询的高效性。
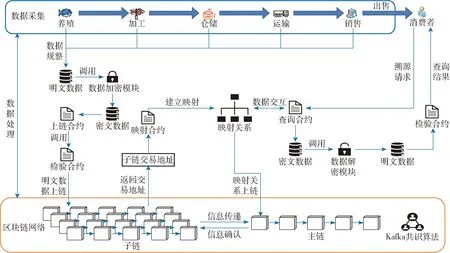
图2 模型总体架构Fig.2 Overall model architecture
整个模型可分为3个模块:供应链数据采集、数据处理、区块链网络。供应链数据采集由各环节厂商通过传感器收集数据后经过规整成为最初的原始数据。数据处理模块由数据上链、数据映射、数据查询、数据验证4部分组成,数据上链部分由各环节厂商节点进行同步上链操作,调用上链合约各个环节的数据上链到相应的子链,危害信息还需要调用校验合约校验显著危害是否符合要求,限值信息是否超过限值,如果全部合格则正常上链,否则返回相应不合格报错。数据查询部分由消费者通过客户端节点来进行查询,通过主链查询到映射关系,通过映射关系中的子链交易地址在各条子链中快速定位到交易数据,数据验证部分对交易中的数据进行验证,将所有的数据拼接成为完整的河豚溯源数据,校验数据完整性。区块链网络模块由子链和主链区块文件、共识算法等组成,维护数据存储和数据查询。
数据上链时,厂商在采集信息之后将溯源信息通过上链合约调用数据加密模块将明文数据转换为密文数据,之后提交上链请求将密文数据传输给各自的子链,在子链存储密文数据可以防止上下游数据泄露。子链在收到请求后将密文数据生成交易,然后将交易存储在当前区块中。子链上链合约会将交易哈希地址和河豚溯源码返回给该环节节点,节点调用映射合约将溯源码和各交易建立映射关系,最后将该河豚映射关系存储到主链中。至此溯源信息上链阶段完成。
数据溯源时消费者需要先将河豚包装上的溯源码输入到客户端节点,客户端节点验证溯源码格式之后,传输至区块链底层网络。通过调用映射合约对主链进行查询,获取到映射关系并返回节点,通过映射关系得到各子链的交易哈希地址,节点分别对各子链通过交易地址索引查询,通过交易地址可以直接定位到某个区块的交易信息。获取到各条子链的密文数据后,调用数据解密模块将密文数据解密为明文数据,最后拼接成完整的河豚溯源信息并在客户端展示。
3.2 多链存储模式设计
根据图1河豚业务流程分析设计出映射关系数据结构,如图3所示,数据映射是本模型提高溯源查询效率的关键,映射关系是一种类似于树的数据结构,反映了产品溯源码与交易地址之间的一对多关系。溯源时通过映射关系进行索引,查询速度会较快。通过根节点记录了产品溯源码、各阶段批号或单号和交易地址,通过交易地址寻址到叶子节点,子链中的交易ID具有唯一性,防止数据被篡改。叶子节点将厂商信息、产品信息、合格证明等信息分类存储,图3中省略号表示各阶段的叶子节点。通过这一流程来实现市场监管和质量安全的需求,在河豚数据上链的过程中通过区块链的时间戳实现了防篡改功能。
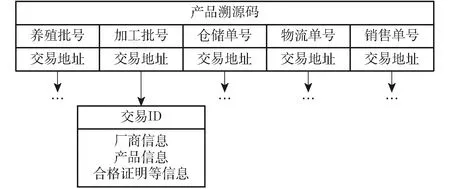
图3 映射关系数据结构Fig.3 Mapping data structure
例如某河豚水产品具体信息映射关系根节点数据如表1所示,写入区块链的溯源码包括养殖批号、加工批号、仓储单号、物流单号、销售单号。养殖批号同时作为河豚的产品溯源码,溯源码与子链存储溯源信息的交易地址形成映射关系,溯源码作为索引和唯一标识。

表1 主链映射关系根节点数据Tab.1 Root node data of main chain mapping relationship
3.3 多链快速查询流程
在区块链查询过程中随着数据量的增加查询时间会线性增加,如何保证数据安全的同时提升溯源的查询效率是研究重点。本文提出了一种多链快速查询流程,主链仅存储少量的映射关系数据,主要供应链信息存储在子链中,并建立与子链交易之间的映射关系,避免大数据量的遍历查询。
如图4所示,本河豚溯源模型的具体操作如下:建立区块链网络;客户端节点注册;河豚水产品溯源数据采集;编写智能合约;河豚水产品溯源数据上链;河豚水产品溯源数据查询。具体数据存储如图5所示,在上链操作前,通过智能合约将本环节数据标准化。上链时,任何环节出现显著危害信息无合格证明或危害信息超限值都会报错并及时终止生产。上链后需要对映射关系进行更新操作来维护映射关系的实时性。主链中会存储映射关系,在子链传来交易信息后主链会先查找是否已存在该溯源码的映射关系。如果主链不存在记录就新建该溯源码的映射关系,将产品溯源码和子链中的交易哈希地址建立起一对多映射关系。进行查询操作时,首先在主链节点进行顺序查找,找到一个批次号所在的交易地址,然后递归地在交易地址所指向的子链节点进行查找。直到查找到所有子链节点,然后在子链节点上进行交易数据查找,找出交易地址所对应的交易数据。消费者通过调用智能合约获取该河豚全部溯源信息。

图4 多链快速查询流程图Fig.4 Multi-chain quick query process

图5 多链溯源查询信息流Fig.5 Multi-chain traceability query information flow
链溯源查询信息流如图5所示, 供应链的各个阶段将本阶段的信息上链至相应子链,子链将信息存储到交易中,当主链发送溯源查询请求后,通过映射关系快速查询到各阶段信息后拼接成完整的全供应链溯源信息,传递给主链,主链通过智能合约将查询结果传递给客户端展示给消费者。
3.4 智能合约设计
数据上链通过上链合约实现,上链合约主要实现了河豚安全性判断功能。通过对河豚显著危害数据是否在限值内进行判断,严格管控河豚的食用安全。以河豚供应链仓储阶段为例,各环节厂商以JavaScript对象简谱( JavaScript object notation,JSON)格式将不同溯源信息调用相应的上链合约上传至区块链账本中,返回交易哈希地址,仓储信息上链具体上链算法为
输入:河豚溯源码 BatchCode,冷藏库温度 Temperature,金属碎片大小 MetalSize
输出:成功交易哈希地址 TxID,失败返回错误原因
1. message= Stub.GetState(BatchCode) ∥查子链中是否存在 BatchCode 记录
2. If (MetalSize大于金属碎片大小限值)
3. return “金属碎片过大”∥上链失败,返回失败原因
4. If (Temperature大于冷藏库温度限值)
5. return “生物的致病菌生长过度” ∥上链失败,返回失败原因
6. message. encryption();∥调用加密模块加密
7. Stub.PutState (message) ∥将密文数据上链
8. return TxID ∥上链成功,返回交易哈希地址
映射关系通过映射合约建立并写入主链,当该河豚产品尚未建立映射关系时,新建映射关系,当河豚产品已经存在映射关系则更新其映射关系。具体算法如下:各环节节点通过调用智能合约进行上链,智能合约首先将本环节的所有数据都上传到相应的子链,然后将其中的溯源码和子链交易哈希地址建立映射关系,映射关系中如果已有该溯源码的数据,则更新相应的交易哈希地址,具体映射合约算法为
输入:河豚溯源码 BatchCode,交易哈希地址 TxID,更新各环节 Breed Procees Pransport Storge Sales
输出:返回映射关系 Index
1. BatchCodeAsBytes:=stub.GetState(BatchCode)∥查询主链中是否有映射关系
2. Index:= &Index{}∥没有则新建映射关系
3. func UpdateIndex (args []string)∥有则更新映射关系
4. if updateItem == "Breed" {∥更新各环节交易哈希地址
5. Index.BreedTxId = TXID
6. }else if updateItem == "Process"{
7. Index.ProcessTxId = TXID
8. }else if updateItem == "Transport"{
9. Index.TransportTxId = TXID
10. }else if updateItem == "Storage"{
11. Index.StorageTxId = TXID
12. } else if updateItem == " Sales "{
13. Index. SalesTxId = TXID
14. }
15. stub.PutState(BatchCode, Index)∥将映射关系写入主链
16. return Index
随着全球经济与科技飞速发展,科学的力量也愈加强大。因此,要想把移动学习与高职英语教学相融合,就一定要以科学的方法作为支持力量进行推动。
当用户对河豚溯源查询时,通过查询合约输入溯源码查询到子链上的信息,具体的查询合约算法为
输入:河豚溯源码 BatchCode
输出:返回子链溯源信息Ciphertext
1. Stub.GetState( BatchCode) ∥查询主链中是否存在 BatchCode 记录
2. (BreedTxId,ProcessTxId,StorageTxId,TransportTxId, SalesTxId)=GetMapping (BatchCode)∥存在映射关系,获取映射关系中的交易哈希地址
3. Ciphertext.Breed=BreedChain.GetState(BreedTxId)∥根据交易哈希地址,请求养殖子链交易信息
5. Ciphertext.Storage=StorageChain.GetState(StorageTxId)∥请求仓储子链交易信息
6. Ciphertext.Transport=TransportChain.GetState(TransportTxId) ∥请求物流子链交易信息
7. Ciphertext.Sales=SalesChain.Getstate(TransportTxId) ∥请求销售子链交易信息
8. Ciphertext.Decrypt();∥调用解密模块解密
9. return Ciphertext ∥返回溯源信息
4 河豚全供应链溯源系统实现
4.1 系统架构
基于河豚供应链的溯源优化模型,设计了河豚供应链信息溯源系统架构。该系统架构如图6所示,分为Web应用层、接口层、智能合约层、存储层、网络层、业务层6层。
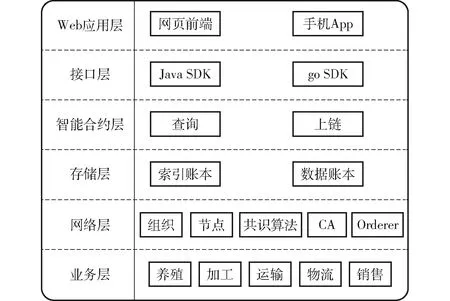
图6 系统分层架构Fig.6 System layered architecture
应用层主要是将系统以可视化的界面展示在消费者面前,消费者可以通过前端输入溯源码进行河豚的溯源。接口层主要连接Web应用层和智能合约层,各环节的厂商通过程序接口调用智能合约的相关函数实行数据上链。智能合约层编写数据查询和数据上链函数,并被安装到多链模型中,智能合约实现索引账本和数据账本的更新。存储层存有多链模型的数据结构,主要包括索引账本和数据账本两部分。网络层包括Hyperledger Fabric区块链的相关网络节点、组织、共识算法、证书授权机构(Certification authority,CA)、Orderer节点等。业务层就是连接各环节原本供应商的信息系统,各环节厂商将溯源信息进行上链。
4.2 案例分析
在上述模型的基础上,实现了基于区块链的河豚供应链溯源系统,本系统基于江苏省某河豚企业的河豚数据,在本数据的基础上编写相应的智能合约、接口及前端应用。本文研究成功应用于江苏省某河豚产品供应链厂商,该厂商包括完整的河豚养殖、加工、仓储、物流、销售环节,相关环节的溯源记录比较完整、清晰。如图7所示,Web前端界面包括可信溯源、区块链浏览器、交易查询、节点监控等,与传统的河豚溯源系统相比,区块链技术保证数据的去中心化存储,同时应用了本文提出的区块链溯源优化模型和多链快速查询模式,在应用后,溯源流程的溯源效率大大提升,且安全性得到保证,溯源信息的防篡改能力得到有效保障。

图7 系统工作界面Fig.7 System working interface
5 性能比较分析
目前的区块链溯源方法主要是单链存储模型,性能分析时分别对单链存储模型和本文提出的多链存储模型建立实验环境进行测试并对比结果。实验硬件运行内存为32 GB,硬盘容量为1 TB,带宽为100 Mb/s;环境基础采用Ubuntu 16.04,Docker 19.03;区块链架构使用Hyperledger Fabric 1.4.2。每次实验的数据采用测试10次的平均值。设置区块大小为10 MB,交易大小为512 KB,每10个交易打包生成一个区块,出块时间为2 s。共识算法采用Kafka,批处理信息阈值为16 KB,发送消息最大值为1 MB,等待请求响应的最长时间为30 s。本文采用性能测试工具Caliper v0.2.0对溯源系统进行性能测试。
如图8所示,本文提供的查询方法由主链查询时间和子链查询时间两部分组成。当数据量增加到1 000条时,总查询时间为0.161 s,主链查询时间为0.08 s,子链查询时间为0.081 s,当数据量增加到10 000条时查询时间逐渐增加至0.196 s,其中主链查询时间为0.086 s,占43.9%,子链查询时间为0.11 s,占56.1%。
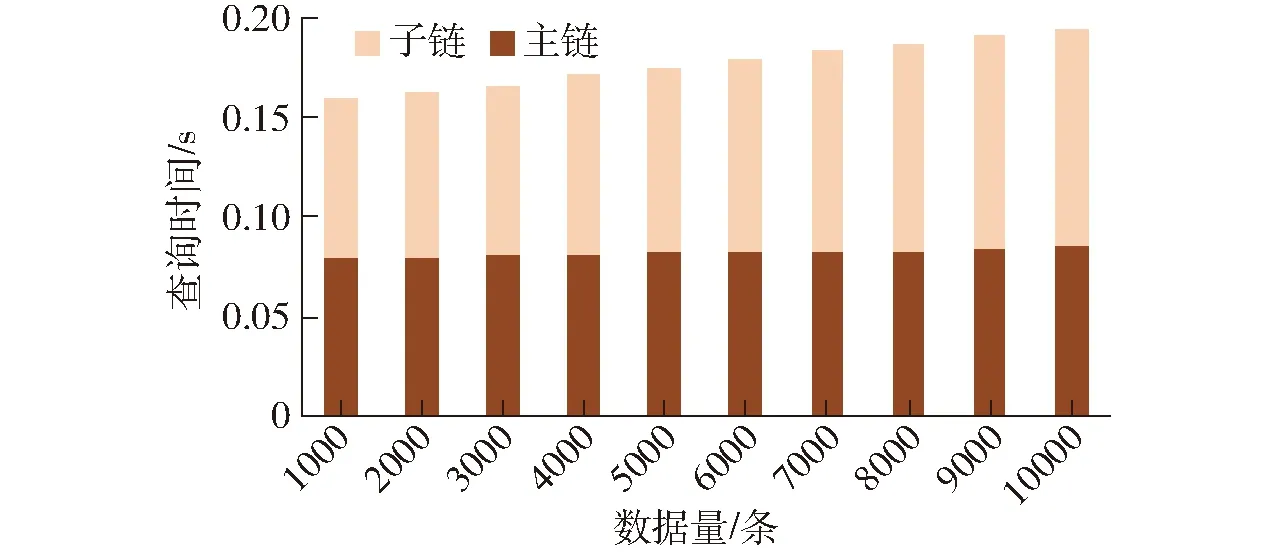
图8 主链和子链查询两阶段时间占比Fig.8 Proportion of time in two stages of main chain sub-chain query
若查询某河豚溯源码,在单链查询中,针对5个追溯企业上传的数据,需对整条链按溯源码对内容遍历查询5次。在多链查询中,整个过程分为主链查询和子链查询两阶段:主链查询阶段首先根据溯源码到主链遍历查询映射关系,然后从映射关系得到子链交易哈希地址;子链查询阶段通过得到的交易哈希地址快速定位到子链的交易记录。多链查询速度快的原因有两点:主链查询阶段采用遍历查询,但是主链仅存储映射关系,区块长度较短,单链模型中将所有溯源信息存储到一条链上,区块长度较长,所以主链的遍历查询比单链遍历查询要快很多;子链查询阶段是按映射关系中的交易哈希地址查询,速度会远快于单链中按内容遍历查询。
如图9a所示,当数据量增加到1 000条时,多链查询时间为0.161 s,单链查询时间为0.372 s;当数据量增加到10 000条时,多链查询时间逐渐增加至0.196 s,单链查询时间为2.769 s。在上链数据量达到10 000条时查询效率可以提升约92.9%。

图9 两种查询方法对比Fig.9 Comparisons of two query methods
节点架构如图10所示,单链查询中,所有节点都是处于一个组织中,只维护同一条链。多链查询中,将节点分为主链组织和子链组织,分别包含主链节点和子链节点,主链组织维护主链,子链组织同时维护5条子链。针对不同节点可能影响实验结果,本文实验对单链查询和多链查询分别设置2、4、6、8个节点进行实验,多链查询中节点分配情况如下: 2节点,主链组织1个节点,子链组织1个节点;4节点,主链组织2个节点,子链组织2个节点;6节点,主链组织3个节点,子链组织3个节点;8节点,主链组织4个节点,子链组织4个节点。
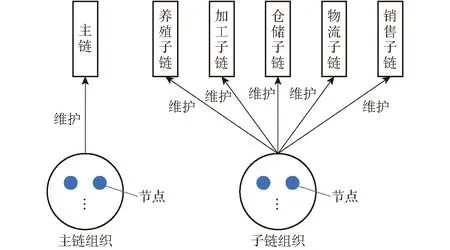
图10 节点架构Fig.10 Node architecture
多节点测试采用网络负载均衡的方式选择不同的区块链节点同步查询。节点查询吞吐量指直接从区块链节点发起交易查询、执行智能合约、收到节点查询结果这一过程的吞吐量,这一过程仅在节点执行,所以吞吐量较大。客户端查询吞吐量指从客户端浏览器发起交易到远程的区块链节点中查询的吞吐量,需要将交易提交到节点,整个过程需要网络传输信息,所以吞吐量较小。如图9b所示,随着节点数的增加,节点查询吞吐量会逐渐增加,节点数分别为2、4、6、8时,单链节点查询吞吐量分别为697、972、1 427、1 819 TPS(Transactions per second,每秒交易数);多链节点查询吞吐量分别为623、1 019、1 486、1 735 TPS,两者差距不大。如图9c所示,随着节点数的增加,客户端查询吞吐量都会逐渐增加。节点数分别为2、4、6、8时,单链客户端查询吞吐量分别为61、104、125、141 TPS;多链客户端查询吞吐量分别为58、99、120、134 TPS。在客户端查询吞吐量方面,单链查询比多链查询稍高一些。
如图9d~9f所示,针对2、4、6、8个节点的不同情况,分别在链上存储1 000、2 000、3 000条数据。然后测试同时发起10次查询,取单次查询时间平均值。实验显示随着节点数的增加,两种方式查询时间都会缩短,并且多链查询时间都会小于单链查询时间。
从测试结果可以看出,与传统的单链存储模型相比,在数据量较多时,多链存储模型可以大大提升查询效率,并且对吞吐量影响较小。
6 结论
(1)提出的多链溯源模型相比较以往的区块链单链溯源模型,在数据记录条数大于1 000条时,该模型查询效率将高于传统单链模型,在10 000条数据记录上链后,较传统单链模型查询效率提高约92.9%。该模型可以实现完全的链上数据存储,使得溯源数据的安全性得到保证,河豚供应链各环节和溯源模型的联系更加紧密,减少了供应链各环节的孤岛效应,各环节可以方便地进行数据上链,保证消费者可以查询到完整、真实、全面的河豚溯源信息。
(2)基于Hyperledger Fabric框架结合河豚溯源案例实现了河豚溯源模型的应用,通过该应用验证了本文提出的模型的可靠性和适用性,为河豚行业提供了一个安全的溯源模型,对消费者来说保证了河豚溯源信息的真实性,为监管者提供了一个方便有效的监管模型。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
小学生作文·小学低年级适用(2022年4期)2022-04-27
现代电子技术(2022年4期)2022-02-21
智能计算机与应用(2021年4期)2021-06-05
红楼梦学刊(2020年3期)2020-02-06
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
故事作文·高年级(2019年5期)2019-05-21
好孩子画报(2018年7期)2018-10-11
金桥(2018年7期)2018-09-25
当代贵州(2018年21期)2018-08-29
