
基于深度学习的无人机遥感小麦倒伏面积提取方法
2022-11-08 02:20申华磊苏歆琪赵巧丽臧贺藏
农业机械学报 2022年9期
申华磊 苏歆琪,2 赵巧丽 周 萌 刘 栋,4 臧贺藏
(1.河南师范大学计算机与信息工程学院, 新乡 453007; 2.河南省农业科学院农业经济与信息研究所, 郑州 450002; 3.农业农村部黄淮海智慧农业技术重点实验室, 郑州 450002; 4.河南省教育人工智能与个性化学习重点实验室, 新乡 453007)
0 引言
小麦作为河南省主要粮食作物,连续5年播种面积稳定在5.67×107hm2以上,占全国小麦种植总面积近1/4,总产3.75×1010kg[1-2],肩负着我国粮食安全重任。倒伏是制约小麦品种产量的主要因素[3],近年来由于台风天气偏多,暴风雨时有发生,对小麦产量影响极大,严重时减产达50%[4]。及时准确地提取小麦倒伏面积,可为灾后确定受灾面积及评估损失提供技术支撑[5]。
目前,小麦倒伏面积的获取主要包括低通量的人工测量和高通量的遥感测量[6-8]。人工测量法存在主观性强、随机性强、缺乏统一的标准,导致效率低下且费时费力,不能高效快速地提取倒伏面积。而遥感测量法是基于遥感影像中不同纹理[9]、光谱反射率[10]、颜色特征[11]等进行特征融合,采用最大似然法对图像进行监督分类提取倒伏面积。随着深度学习在语义分割中的快速发展,国内外专家采用语义分割方法检测作物倒伏面积取得了突破性进展[12-16]。这些研究主要采用遥感测量法进行特征分类,分割方法较为单一,未对不同特征筛选与分类方法进行组合优选,而深度学习方法存在无人机飞行高度较高的情况,只能实现粗略的倒伏区域分割。
深度学习的优势在于通过多层神经网络自动提取有效特征,这些特征不仅包括图像的局部细节特征,而且包括图像的高级语义特征。但由于计算量大、资源消耗的限制,特别是遥感高分辨率图像,内存约束要求必须对其进行下采样,或将其分割成多个块分别进行处理。然而,前一种方法会使图像失真,而后者则会由于缺乏全局信息造成误判。因此,本文移植并改进一种基于注意力机制的深层显著性网络U2-Net[17],对其进行轻量化,以对小麦倒伏面积进行信息提取和自动分割。同时,通过无人机拍摄图像并自建数据集,对该模型性能进行评价。
1 研究区概况与数据
1.1 研究区概况
研究区位于河南省农业科学院河南现代农业研究开发基地的小麦区域试验试验地,地处35°0′44″ N,113°41′44″ E,如图1所示。气候类型属暖温带大陆性季风气候,年平均气温为14.4℃,多年平均降雨量为549.9 mm,全年日照时数2 300~2 600 h,冬小麦—夏玉米轮作为该地区的主要种植模式。
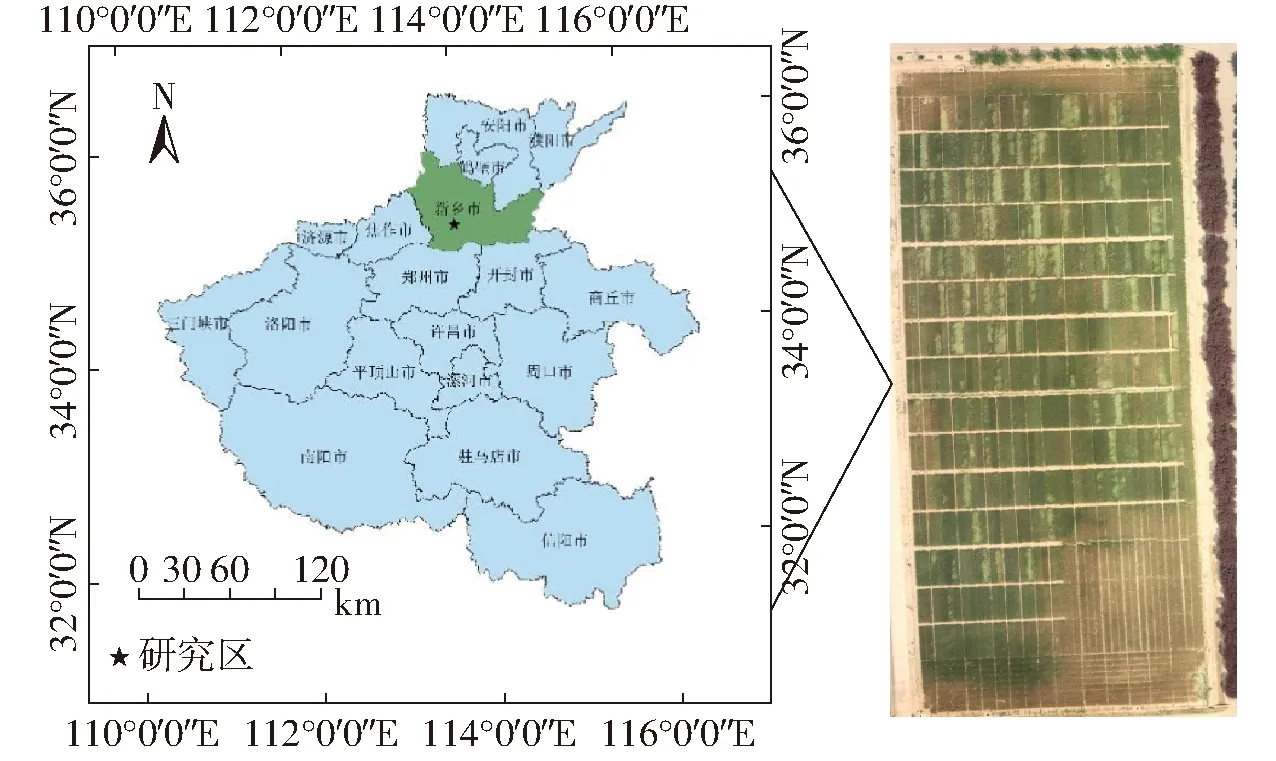
图1 研究区位置Fig.1 Geographical location of study area
1.2 数据采集与预处理
根据国内外专家经验[12-14,18]结合本研究实际情况,实验采用大疆精灵4 Pro型无人机,轴距350 mm,相机像素为2 000万像素,影像传感器为1英寸CMOS,镜头参数为FOV 84°,8.8 mm/24 mm(35 mm格式等效),光圈f/2.8~f/11。搭载GPS/GLONASS双模定位,拍摄图像分辨率为5 472像素×3 078像素,宽高比为16∶9。时间为2020年5月14日,此时研究区内小麦处于灌浆期。影像采集时间为 10:00,天气晴朗无云,垂直拍摄,飞行速度3 m/s,飞行时长25 min,航向重叠度为80%,旁向重叠度为80%,相机拍照模式为等时间隔拍照,最终采集700幅原始图像。飞行采用大疆无人机自动规划的航线,共规划5条航线,航拍完成后采用自动返航的方式降落,如图2所示。
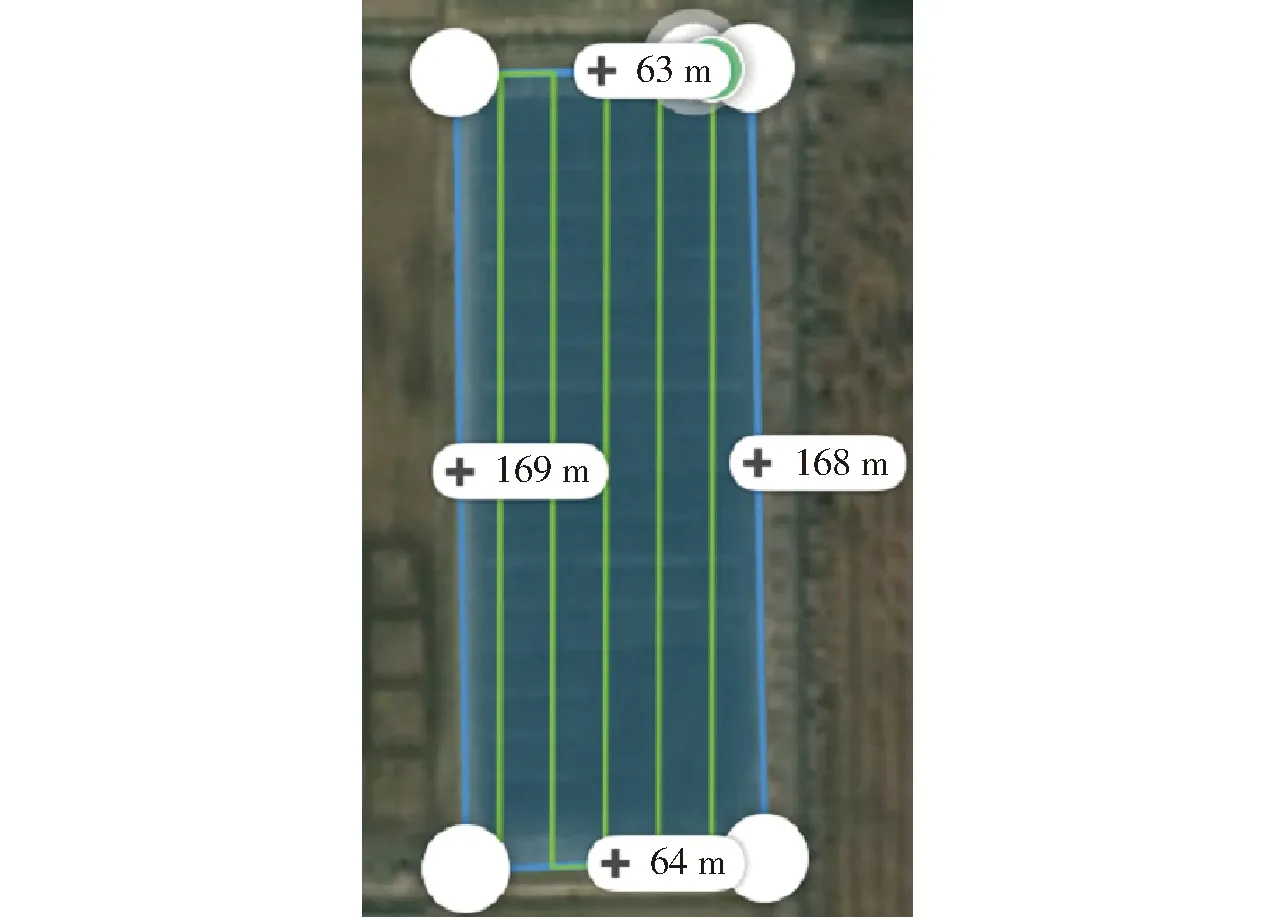
图2 无人机自动规划航线图Fig.2 UAV automatic planning route map
为实现小麦倒伏区域细粒度分割,使倒伏区域更加精确,本实验设置飞行高度为30 m。低于30 m,无人机可能与建筑碰撞,而高于30 m,则无法获得较高分辨率图像。无论无人机飞行高度和天气条件等变量如何变化,只要在可控操作的环境下,通过合适的训练及参数调整,本模型技术均具有一定的有效性和准确性。图3为小麦倒伏图像2种分割策略,裁剪方法注重局部特征,下采样方法注重全局特征。

图3 小麦倒伏图像分割策略Fig.3 Different methods for wheat lodging image segmentation
1.3 数据集构建和标注
实验使用原数据集700幅图像,通过对测试集进行去重,训练集进行优选,最终筛选出250幅原始数据图像。深度学习通常需要大量数据,本实验采用的高通量数据分辨率为5 472像素×3 078像素,深度学习通常使用数据分辨率仅为512像素×512像素。如果使用滑动窗口进行裁剪,单幅图像可裁剪出64幅完全无重复图像,经过随机位置裁剪,单幅图像可得到100幅以上有效图像。250幅原始图像经过数据处理后可得25 000幅有效图像,满足了深度学习的数据量要求。无人机飞行过程中,由于无人机拍摄角度和光影不同,不同航道拍摄相同位置图像会有差异,因此同样存在训练价值。为了均衡数据,选取第1、2、3号航线图像作为训练集,5号航线图像作为测试集。本研究分下采样组和裁剪组,具体步骤为:
(1)筛选出无人机姿态平稳、拍摄清晰无遮挡数据,用于深度学习训练。
(2)人工标注:使用Labelme插件[19]将小麦中度、重度倒伏区域标注为前景,其余区域标注为背景,并转换成二值图像作为训练集和测试集的标签。
(3)下采样组和裁剪组:下采样组将所有训练样本和测试样本等比例下采样至342像素×342像素,之后通过背景填充将图像扩充至512像素×512像素。裁剪组将测试样本裁剪为固定比例、边缘重叠和图像分辨率为512像素×512像素,同时记录重叠区域的长和宽。
(4)数据增强:对下采样组训练样本进行无损变换,即水平或竖直随机旋转,以提高模型的鲁棒性。对裁剪组训练样本进行随机剪裁,剪裁区域尺寸为512像素×512像素,以在每轮训练中生成不同的训练样本。
(5)图像拼接和恢复:将裁剪组掩膜图按记录的重叠区域长和宽进行合并,最终拼接成5 472像素×3078像素的分割结果图。将下采样组掩膜图裁剪为342像素×342像素,并等比例放大复原。
(6)精度验证:对比分割结果(Mask)图和标注(Ground truth)图,计算模型指标。同时,通过地物关系与遥感图像映射,计算标注面积与分割面积,从而求出有效面积与准确率。
2 研究方法
2.1 U2-Net模型
显著性目标检测[20-21]主要用于人脸检测领域,通常旨在仅检测并分割场景中最显著的部分。中、重度小麦倒伏区域特征明显,U2-Net是一种2层嵌套的U形结构的深度神经网络,用于显著性目标检测。该网络能够捕捉更多的上下文信息,并融合不同尺度的感受野特征,增加了网络深度,但没有显著提高计算代价。
具体而言,U2-Net是一个2层嵌套的U型网络架构,其外层是由11个基本模块组成的U型结构,由6级编码器、5级解码器和显著图融合模块组成,其中每个模块由一个基于残差的U-Net块填充。因此,嵌套的U型网络结构可以更有效提取每个模块内的多尺度特征和聚集阶段的多层次特征。
虽然原始的U2-Net已经具备优异的性能,但是为了对高通量小麦倒伏面积的特征特异性进行提取,对U2-Net做出进一步改进:引入通道注意力机制和一种Non-local注意力机制,构建一种新的小麦倒伏面积分割模型——Attention_U2-Net。该模型在进一步挖掘现有语义特征的同时,优化了网络结构。
2.2 基于注意力机制的Attention_U2-Net语义分割模型
如图4所示,Attention_U2-Net由2层嵌套的U型结构组成。本文改进了U2-Net中的RSU(ReSidual U-blocks)块,使用了基于通道注意力机制的级联代替了U2-Net本身的级联,在每个Block层使用Non-local[22]机制代替U2-Net中的空洞卷积[23],并使用改进的Multi focal loss缓解训练样本难易程度不均和类别不平衡问题。
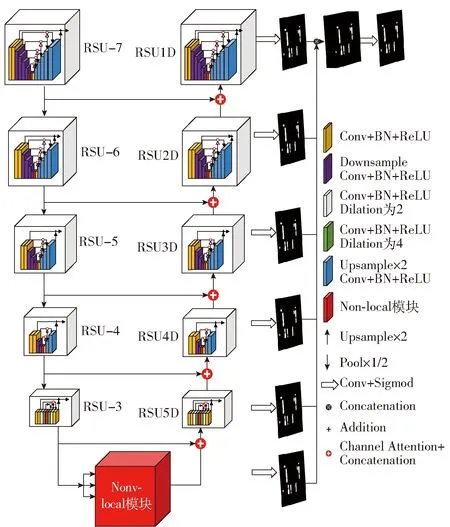
图4 Attention_U2-Net网络结构图Fig.4 Attention_U2-Net architecture
U2-Net使用了大量的空洞卷积,在尽量不损失特征信息的前提下,增加感受野。对于显著性目标需要大感受野,而裁剪后数据语义混乱且倒伏面积随机。由于空洞卷积的卷积核不连续,导致特征空间上下文信息可能丢失;频繁使用大步长空洞卷积可能增加小麦倒伏区域边缘识别难度。同时,空洞卷积使得卷积结果之间缺乏相关性,从而产生局部信息丢失。
Non-local机制(图5a)是一种Self-attention[24]机制,原理式为
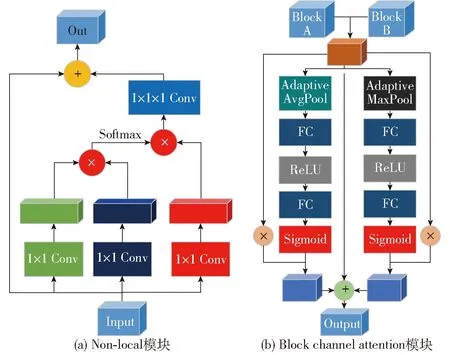
图5 分支结构图Fig.5 Branch structure diagrams
(1)式中x——输入特征图yi——特征图i对应位置的值i——输出位置的响应j——全局位置的响应f()——计算特征图在i和j位置的相似度g()——计算特征图在j位置的表示C()——归一化函数,保证变换前后信息不变
Non-local可以通过计算任意2个位置之间的交互直接捕捉远程依赖,而不用局限于相邻点,相当于构造了一个和特征图谱尺寸一样大的卷积核,从而保留更多信息。Attention_U2-Net在每个RSU块里保留了少量扩张率低的空洞卷积用于提取上下文信息特征,广泛使用Non-local模块替换了扩张率大的空洞卷积,同时Non-local模块也替代了整个U2-Net网络底层,增强了网络模型的特征提取能力,同时减少了计算量。U2-Net采用级联的方式将上采样Block和下采样Block结合,产生多个通道,通过Block channel attention(图5b)使神经网络能够自动为融合后多个Block自动分配合适的权重。本文采用了全局平均池化和最大池化2种方式,分别获取Block不同的语义特征,并设计一个残差结构进行信息融合。经过随机裁剪的样本,可能存在样本难易度和类别分配不均衡问题,从训练组数据每个航道随机抽取144幅裁剪后图像用于类别统计,如表1所示。单幅图像倒伏面积大于30%样本约占总体样本的24%,以致于大部分裁剪图像中无倒伏面积,正负样本比例失衡,样本难易度同样存在比例不均衡问题。由表2可以看出,将倒伏面积小于10%的样本以及边缘特征不明显的样本定义为高难度样本,其它倒伏样本定义为低难度样本。虽然高难度样本总占比约为9.31%,但倒伏样本中高难度样本占比高达27.56%,这并不意味着能够抛弃高难度样本而专注于提升低难度样本的分割准确率。本实验基于U2-Net的Multi bce loss和Focal loss[25]提出了一种适用于小麦倒伏面积分割的损失函数:Multi focal loss,计算式为

表1 随机抽样正负样本分布Tab.1 Distribution of randomly selected positive and negative samples
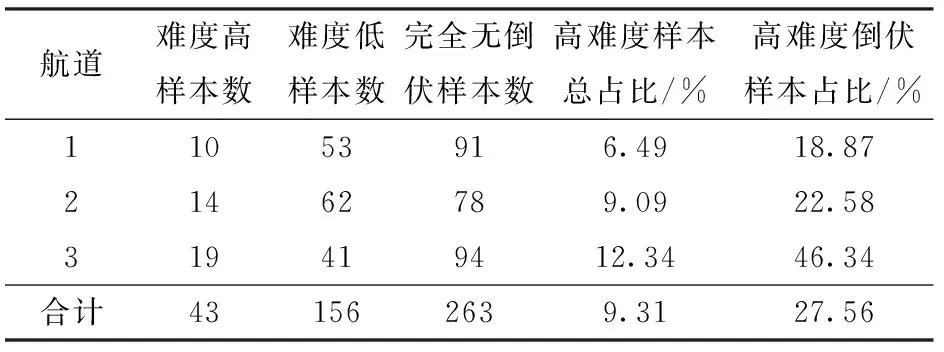
表2 随机抽样样本难易度分布Tab.2 Statistics on difficulty of randomly selected samples

使用Focal loss可以通过设置不同权重以抑制简单样本并解决正负样本比例严重失衡问题。Multi focal loss降低了大量简单负样本在训练中所占权重,极大程度上抑制了裁剪带来的噪声;该损失函数控制了难易分类样本权重,并将每层掩膜图叠加,从而提高了模型鲁棒性,使其更适合用于小麦倒伏面积提取。
模型的输入图像分辨率为512像素×512像素,输出为单通道掩膜图像。Attention_U2-Net沿用了U2-Net的编、解码结构,由6层编码器、5层解码器和掩膜图融合模块组成。在前5个编码阶段,Attention_U2-Net同U2-Net将其分别标记为RSU-7、RSU-6、RSU-5、RSU-4和RSU-3;其中“7”、“6”、“5”、“4”和“3”表示RSU块的高度(H),对于高度和宽度较大的特征图,上层使用较大的H来捕获更大尺度的信息。RSU-4和RSU-3中的特征图的分辨率相对较小,进一步降低这些特征图的采样会导致裁剪区域上下文信息丢失。底层使用Non-local结构替换U2-Net大步长串联空洞卷积,降低了模型深度的同时,使其拥有更大的感受野能更好地识别边缘信息。在后5个解码阶段,Attention_U2-Net使用线性插值进行上采样,解码模块同编码器结构保持一致,但对输入特征向量进行了处理,通过级联上一层特征与同一层相同分辨率特征,经过改进的通道注意力机制进行特征融合后输入上采样块,可以更有效地保证语义信息的完整性。
通过替换空洞卷积为Non-local结构,可以提升分割精度,但同样带来了巨大的参数量。Attention_U2-Net只对大步长的空洞卷积进行了替换,在每个RSU块中,Attention_U2-Net使用Non-local结构替换了大步长的空洞卷积,从而权衡模型速度和精度。掩膜图融合阶段,生成掩膜图概率映射,通过3×3卷积和线性插值生成每一阶段相同分辨率的掩膜图。将6个阶段的掩膜图并在一起,之后通过1×1卷积层和Sigmoid函数输出最终的掩膜图。
2.3 模型训练
实验选用Intel(R) Core(TM) i7-10600 CPU,主频2.90 GHz,GPU选择NVIDIA GeForce RTX3090,显存24 GB,使用PyTorch作为深度学习框架。
实验将训练集和测试集分为多个批次,遍历所有批次后完成一次迭代。优化器选择Adam,设置初始学习率为0.001,随着迭代次数提升降低学习率至0.000 1。
2.4 评价指标
采用查准率(Precision)、召回率(Recall)、F1值(F1-Score)和IoU(Intersection over Union)指数评估模型性能,使用准确率量化倒伏面积提取能力。其中查准率指预测为倒伏面积占实际倒伏面积的比例;召回率表示预测倒伏面积占实际倒伏面积的比例。F1值为查准率和召回率二者的调和均值;IoU指数为倒伏面积预测面积和实际倒伏面积的重叠率;准确率指识别有效面积与提取总面积的比值。以上指标取值在0~1之间,值越大,表明评估效果越好。本文定义了一种用于量化倒伏面积准确率的公式
(4)
式中Lt——正确识别为倒伏小麦面积
Nt——正确识别非倒伏小麦面积
Lf——误把倒伏小麦识别为非倒伏小麦面积
Nf——未正确识别出倒伏小麦面积
Ps——倒伏面积预测准确率
3 结果与分析
3.1 不同分割模型训练结果
基于测试样本数据,对比了Attention_U2-Net、U2-Net和主流模型FastFCN[26](预训练网络ResNet[27])、U-Net[28]、FCN[29](预训练网络VGG[30])、SegNet[31]、DeepLabv3[32]的分割性能,图6为训练图像可视化进行了指数平滑。采用下采样所得样本训练神经网络收敛速度快、准确率高,而采用裁剪所得训练样本的训练收敛速度慢。由于正负样本不均衡导致裁剪后训练难度增大,部分模型的决策边界偏向数量多的负样本,使得准确率波动不明显并偏高。
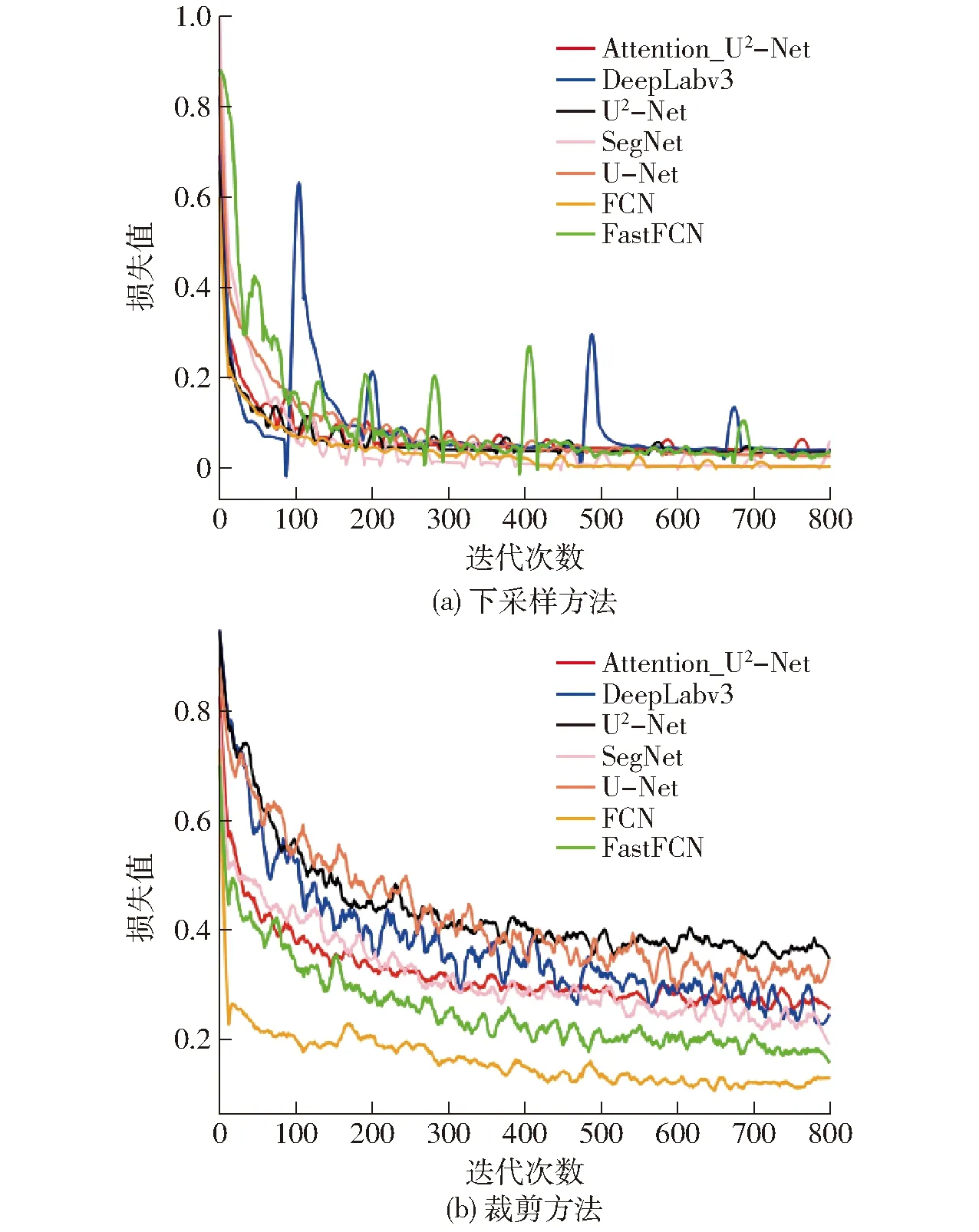
图6 训练损失Fig.6 Train loss
3.2 不同分割模型性能对比分析
由表3可以看出,Attention_U2-Net的分割效果最佳。U-Net、FCN、FastFCN、SegNet等在下采样方法上性能相差较小,但在裁剪方法上多尺度适应性优势未能体现,识别准确率较低。U-Net、SegNet等浅层网络对于裁剪出的512像素×512像素掩膜图误检率较高,而DeepLabv3的整体分割效果较好。说明深层网络在下采样图像上的性能和浅层网络相似,浅层网络模型对解决许多简单并有良好约束的问题非常有效。深层网络训练速度慢,内存占用大,因此可以携带更多的数据,能够实现更复杂的数据关系映射。由图7可以看出,对比下采样方法和裁剪方法,严重倒伏区域有显著的纹理和颜色特征,易于分割;小范围或轻微倒伏区域的纹理和颜色特征不明显,采用下采样后的分割效果较差。通过裁剪得到的边缘特征较为明显,能够识别难度较高样本,但模型收敛速度慢,算力需求高。
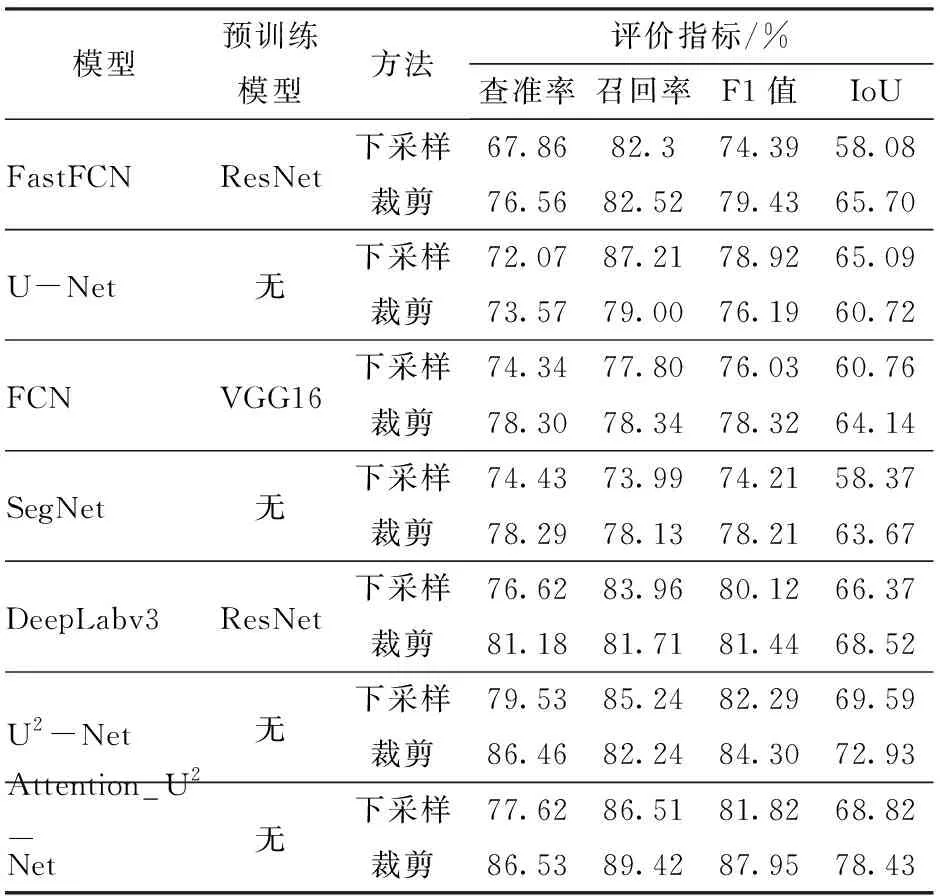
表3 不同分割模型在提取小麦倒伏面积时的评价指标Tab.3 Evaluation indexes of wheat lodging area extraction by different segmentation models

图7 下采样和裁剪方法对小范围倒伏区域分割效果Fig.7 Segmentation of down sampling method and cropping method on small-scale lodging area
采用裁剪方法处理纹理细节时,深层网络能获取更充分的上下文信息,而浅层网络采用裁剪方法时,分割结果较差。采用下采样方法分辨率损失严重,甚至无法辨别轻、中度小麦倒伏面积。由于数据集中严重倒伏面积的占比较大,轻微倒伏面积占比较少,从而导致基于下采样方法的评价指标偏高。由于人工标注误差,整体准确率偏低。移植后U2-Net的整体性能略高于DeepLabv3,同时处理裁剪图像时的性能较其它模型有较大提升。由于Attention_U2-Net基于裁剪方式进行改进,从而更关心局部特征,使用下采样方法处理数据不能很好地提取全局特征导致模型效能较差。使用裁剪方法时Attention_U2-Net的计算成本略高于原U2-Net,但极大地增强了特征提取能力和泛化能力,F1值提高3.65个百分点,识别效能有效提高。
3.3 不同模型面积提取效能分析
为了通过掩膜图像计算实际区域倒伏面积,以实地测量方式测得一个小区面积为8 m×1.5 m,对应区域遥感图像像素数为356 400个。通过计算可得29 700个像素对应实际面积为1 m2,从而求出标注面积与提取面积。
如表4与表5(结果保留两位小数)所示,为了对模型实际性能进行评估,对标记数据进行地物关系映射,测得标注倒伏面积为0.40 hm2,非倒伏面积为3.0 hm2。非倒伏区域面积大、识别难度低、误检率低;倒伏区域面积小,但部分倒伏区域识别难度大、误检率高。大部分模型使用裁剪方法提取倒伏面积效能较下采样方法有所提升。其中使用裁剪方法时Attention_U2-Net检测倒伏面积为0.42 hm2,准确面积为0.37 hm2;检测非倒伏面积为2.98 hm2,其中准确面积为 2.94 hm2,Ps为97.25%。Attention_U2-Net提取倒伏区域有效面积最接近标注面积,拥有最高的Ps值,且误检面积较其它方法最低,能够检测出其它模型无法检测出的异常样本,体现出在复杂大田环境下准确判断倒伏区域的有效性,具有更高的实用价值。
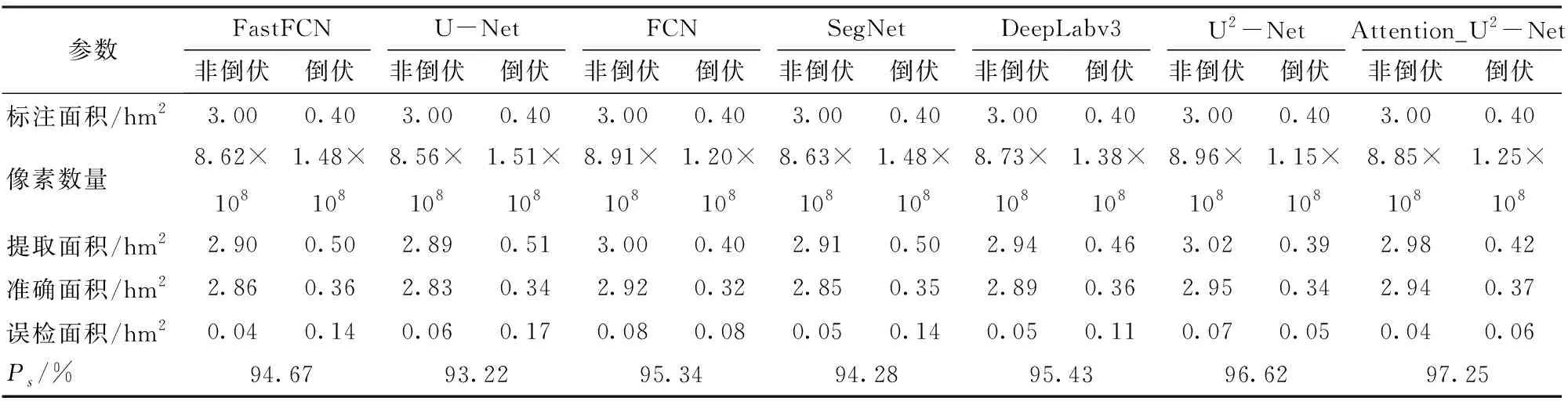
表4 裁剪方法各模型提取面积准确率对比Tab.4 Comparison of area extraction accuracy of each model of cropping method
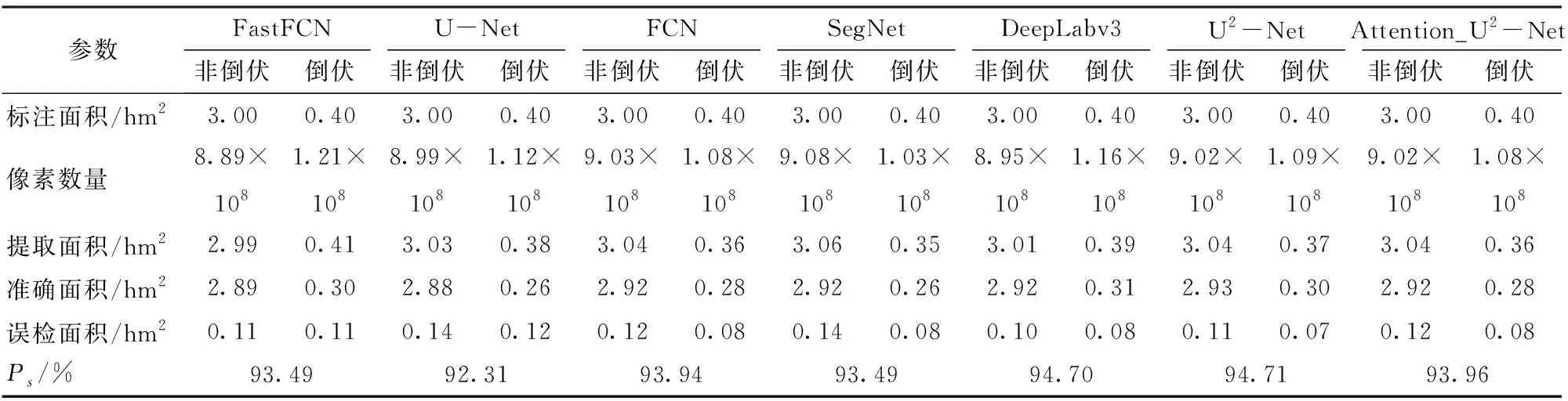
表5 下采样方法各模型提取面积准确率对比Tab.5 Comparison of area extraction accuracy of each model of down sampling method
3.4 不同分割模型定性比较
如图8和图9所示,预测图中白色区域为判断倒伏小麦的高权重区域,黑色为低权重区域。从图8可看出,U2-Net和Attention_U2-Net可以更好地实现裁剪后小麦倒伏面积提取,其中Attention_U2-Net的验证结果更接近标注图,U-Net和SegNet的验证结果较差;Attention_U2-Net、U2-Net和浅层网络训练结果差距不大,但算力消耗较大。综合图8、9分割结果,采用下采样方法进行小麦倒伏面积分割结果较裁剪方法的误差大;而使用裁剪方法的训练难度高。

图8 下采样方法实验结果定性比较Fig.8 Qualitative comparison of crop experimental results of down sampling method

图9 裁剪方法实验结果定性比较Fig.9 Qualitative comparison of crop experimental results of cropping method
4 结论
(1)采用下采样和裁剪两种策略对无人机遥感小麦倒伏区域进行了分割。为了提高困难样本的检测率,提出了一种深层神经网络Attention_U2-Net。首先移植了U2-Net网络并使用改进注意力机制优化了级联模式,并使用Non-local替代了大步长的空洞卷积,使模型能从深层和浅层捕获更多的局部细节信息和全局语义信息;然后融合所有中间层的Focal损失,能在每层上更好地梳理样本分配不均和难易不平衡问题,进一步提高网络分割精度。
(2)基于无人机高通量倒伏区域识别方法精度高,能识别细微倒伏区域,移植后的网络通过采用裁剪方式,对小麦倒伏数据集的语义分割F1值为84.30%。改进后的Attention_U2-Net分割小麦倒伏区域,其F1值可达87.95%。为了对模型实际性能进行评估,本实验对倒伏区域进行人工标注并进行地物关系映射,测得标注倒伏面积为0.40 hm2,非倒伏面积为3.0 hm2。Attention_U2-Net检测倒伏面积为0.42 hm2,其中准确面积为0.37 hm2;检测非倒伏面积为2.98 hm2,其中准确面积为2.94 hm2,Ps为97.25%。通过与FastFCN、U-Net、FCN、SegNet、DeepLabv3主流神经网络模型对比,Attention_U2-Net具有最高的准确率及F1值,表明本文模型在小麦倒伏区域检测应用中的准确性和有效性。
(3)实验结果表明,采用裁剪方法处理小麦倒伏数据,可能导致小麦倒伏区域的语义信息丢失,且训练难度大;采用下采样方法通过浅层网络可以兼顾训练速度和训练效果,但只能适用于区域大、倒伏程度严重的情况,准确率较裁剪方法整体偏低。本文提出的Attention_U2-Net采用裁剪方法可以完成高难度训练任务且不显著占用计算资源,能够准确提取出小麦倒伏面积,可以满足麦田环境下的高通量作业需求,为后续确定受灾面积及评估损失提供技术支撑。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
小哥白尼(军事科学)(2022年2期)2022-05-25
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
红领巾·萌芽(2019年8期)2019-08-27
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
CHIP新电脑(2016年3期)2016-03-10
计算技术与自动化(2014年1期)2014-12-12
