
基于卷积神经网络的高分遥感影像耕地提取研究
2022-11-08 02:20陈玲玲廖凯涛宋月君张红梅
农业机械学报 2022年9期
陈玲玲 施 政 廖凯涛 宋月君 张红梅
(1.江西省水利科学院, 南昌 330029; 2.江西省土壤侵蚀与防治重点实验室, 南昌 330029; 3.南昌工程学院水利与生态工程学院, 南昌 330099)
0 引言
高分辨率遥感影像降低了中低分辨率影像的混合像元问题,能够较为清晰、准确地表达地物边界、形状、纹理信息、内部几何结构和空间关系[1-2],当前高分遥感地物提取传统方法主要有最大似然法(Maximum likelihood,ML)[3]、支持向量机法(Support vector machine, SVM)[4-5]、随机森林法(Random forest, RF)[6-7]、面向对象分类法[8-9]等,并取得了较好的研究成果。然而传统方法大多是先由专业技术人员人工设定规则或划分样本,再根据自身算法或结合其他算法来实现分类提取[10],受经验限制和人主观影响强,且高分影像中丰富的细节信息和复杂的规律往往无法被很好地描述,对特征差异大、信息复杂的遥感影像提取效果有限,容易导致椒盐噪声[11]。随着遥感大数据时代的来临,特别是米级、亚米级高分遥感影像的出现,其拥有更清晰、更加丰富的地物影像信息[12]。采用SVM方法将消耗大量的时间和计算资源,对计算机的性能要求高。虽然将大影像裁剪为若干小块来处理是一种解决办法,但这些提取方法需人工选取样本和设定参数,每一小块都要重新操作,繁琐耗时,还存在前后结果不一致的风险。目前,图斑精细化解译的实际过程依然以人工目视解译为主,遥感传统模型为辅的方式进行。
近年来,伴随着大数据、云计算和服务器的发展,给深度学习(Deep learning, DL)技术带来了巨大的机遇[13-15],卷积神经网络(Convolutional neural network, CNN)在遥感影像分类领域表现突出[16],CNN完全基于数据驱动,是一种无需专家知识来人工选择参数和设计特征,便可从数据中挖掘所需要的特征信息。具有智能化、自动化以及对海量遥感数据适应力强等特点。但CNN一般主要用作图像级的分类,归一化后输出结果为整个输入图像的一个数值描述(概率分布式),只能标识整幅图像的类别,不能对标识图像中的每个像素点进行识别[17]。因此,LONG等[18]提出了全卷积神经网络(Fully convolution network, FCN),首次实现了端到端对图像进行像素级分类的功能,做到了像素对像素的映射。FCN是目前许多语义分割方法的基础,相关学者基于FCN语义分割模型也开展耕地提取方面的研究工作[19-21],基于FCN的模型算法,一旦训练出模型参数,即可实现复用推广,不必多次人工选定参数,大大节省了人工判读时间,实现了耕地的自动化提取,且最大限度地降低了人主观因素影响。然而,目前应用于遥感领域的FCN模型大多注重精度而忽略了资源投入以及时间成本,在硬件资源和计算能力有限的情形下,可能会导致模型训练困难,耗时长,甚至无法实现等问题。
为解决上述问题,在以低资源消耗和高计算效率的轻量级卷积网络的基础上,通过对比SqueezeNet[22]、Xception[23]、ShuffleNet[24-25]和 MobileNet[26-27]等优秀轻量级CNN模型,引入参数少、计算量小、精度高的深度可分离卷积、压缩-激励块和反残差块,并将这些块组合生成一个新模块(Inv-Bottleneck)。并借鉴语义分割模型实现端到端的高效框架[28],引入U-Net 网络结构的编码-解码框架[29]。最后,以Inv-Bottleneck模块为核心,以编码-解码骨架为基础框架联合建立基于FCN的轻量级耕地图斑提取模型(Lightweight Inv-Bottleneck net,LWIBNet),应用数学形态学算法作为后处理手段,研究基于深度学习的高分遥感影像耕地图斑提取技术,以期为土地利用变化以及生态环境效益评价提供数据和技术支撑。
1 研究方法
本文采用LWIBNet模型进行耕地图斑提取,LWIBNet的整体架构见图1。编码-解码结构是LWIBNet的基本框架,其中编码部分由11个Inv-Bottleneck、2个标准卷积和1个最大池化组成,并分为5个模块,将向解码部分输出5个不同尺度信息的特征图谱 (FP),编码部分用于学习输入耕地图像的上下文语义信息并进行特征提取;解码部分由4个Inv-Bottleneck、4个标准卷积和5个上采样层组成,同样分为5个模块,将依次融合编码部分输出的5个FP,形成更为丰富的特征信息。解码部分用于加强编码部分的特征提取结果,并恢复特征图的的空间信息和分辨率,图1中,E-FP、D-FP分别表示编码、解码部分的特征图谱,各5层。
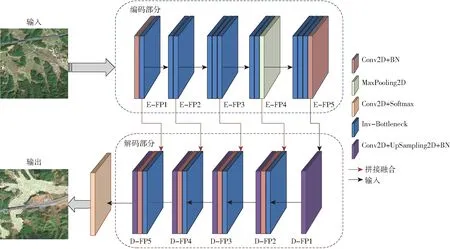
图1 LWIBNet轻量级耕地图斑提取模型结构图Fig.1 Structure diagram of LWIBNet lightweight cultivated land spot extraction model
解码部分的输出紧接带Softmax分类器的卷积层,此层能归纳出输入图像中具有相同语义的像素点,并输出一幅和输入图像大小相同的已分类标记好的图像,形成耕地图斑信息图。
1.1 Inv-Bottleneck模块
Inv-Bottleneck模块是本文模型的核心模块,由反残差块、压缩-激励块、深度可分离卷积和标准卷积构成,其能高效利用深层特征,在确保网络拥有一定准确率的同时降低参数量和计算量,节约计算资源并提高效率,其结构图如图2a所示。NL表示激活函数,即ReLU6和H_swish。
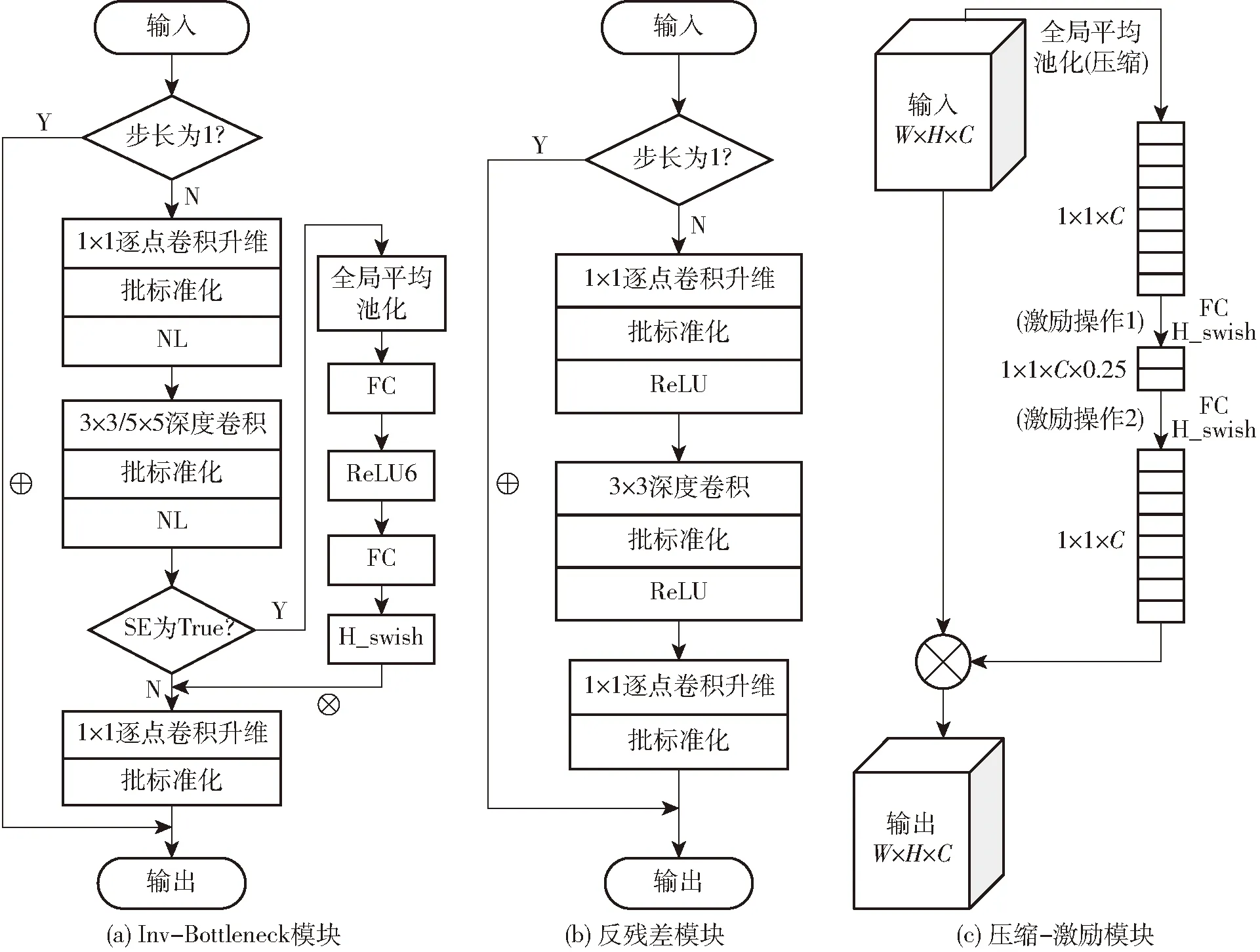
图2 模型组件结构图Fig.2 Structure diagrams of model components
1.1.1深度可分离卷积
深度可分离卷积是轻量级神经网络模型的核心工具,可显著降低计算量和计算成本,同时实现与标准卷积类似(或稍好)的性能,其将一个标准卷积拆分为两个独立的操作:深度卷积(DW)操作和逐点卷积(PW)操作[30]。
深度卷积中,一个卷积核负责一个通道,一个通道只被一个卷积核所卷积,且只改变FP的大小,不改变通道数,相同卷积核的深度卷积比标准卷积需要更少的参数;逐点卷积等价于核大小为1×1的标准卷积,操作时只改变通道数,不改变FP,它常被用来关联特征图各通道之间的信息,进行信息交流。
使用DW和PW参数量和计算量将显著减少,深度可分离卷积与标准卷积参数量、计算量比值分别为
(1)
(2)
式中Dk——卷积核尺寸
Wo、Ho——特征图宽度和高度
M——输入通道数N——输出通道数
若卷积核尺寸采用3×3,深度可分离卷积的参数量和计算量将减小为标准卷积的1/9~1/8。在Inv-Bottleneck中混合使用5×5和3×3的DW,能使参数量不过多增加的同时有更好的效果,并且为了降低过拟合的风险,每步DW和PW之后都将使用批标准化(BN)。
1.1.2反残差模块
反残差模块是以ResNet[31]的残差块为基础,并结合深度可分离卷积优化而来的,与ResNet残差块中维度先缩减后扩增相反,它先使用1×1 PW将输入的低维FP升维,然后在中间层利用轻量级的DW来提取特征并引入非线性,再使用一个线性的1×1 PW将其映射回低维空间中,如果步长为1,残差传播会被激活,此时特征图将与输入图谱相加,不仅能加深网络层数,缓解训练时网络深度增加而出现的梯度消失问题,还能减少参数量和计算量,提高模型的效率和性能。具体结构见图2b。
本文Inv-Bottleneck的骨架采用反残差结构,并引入了H_swish激活函数[32]。计算式为
(3)
因H_swish在更深层才能体现它的优势,在编码部分Inv-Bottleneck模块将在较后层才应用H_swish函数,其他则继续使用ReLU6。
1.1.3压缩-激励模块
压缩-激励模块(SE)是能够让网络模型对特征进行校准的机制,通过学习来自动获取每个特征通道的重要程度,然后依照这一结果去提升有用的特征并抑制对当前任务用处小的特征[33]。SE能提升模型的质量,但也会增加网络的总参数量和总计算量,因此引入了改进的SE块,其结构见图2c,包含1个压缩(Squeeze)和2个激励(Excitation)操作,与未改进前相比,第1个激励中增加了0.25的缩放参数,可减少通道个数从而降低计算量,两个激励中的激活函数都替换为计算量少的H_swish。图中的FC表示全连接层,可以看作1×1的卷积层,有利于实现通道间的融合;W、H和C分别表示特征图的宽、高和通道数。改进的SE模块被运用在Inv-Bottleneck模块的最后一层,先进行SE操作再进行PW操作。实现压缩-激励块能在不破坏特征的情况下,提升整个模型的运算性能。
1.2 编-解码结构
LWIBNet的编码、解码部分具体结构和参数如表1、2所示。
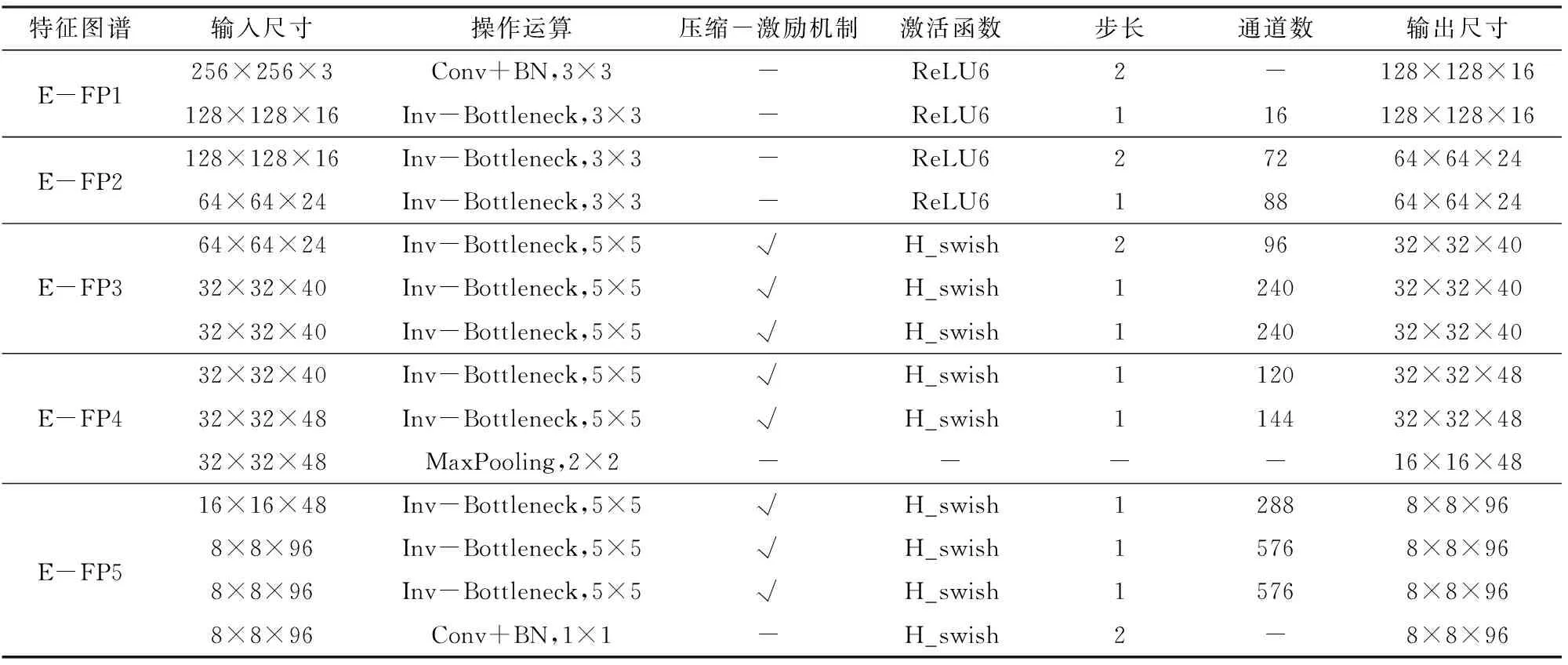
表1 编码部分具体结构和参数Tab.1 Specific structure and parameters of encoding part

表2 解码部分具体结构和参数Tab.2 Specific structure and parameters of decoding part
2 实验与结果分析
2.1 实验数据
本文收集了江西省奉新县、上高县、新余市渝水区、靖安县、崇仁县和宜丰县等6个县级行政区的高分1号以及高分6号遥感影像,并经过大气校正、几何校正以及多波段影像融合处理后的分辨率为2 m的栅格影像以及经人工目视解译的耕地矢量数据作为实验数据,其中奉新县、上高县、新余市渝水区、靖安县和崇仁县的部分影像被截取作为训练影像,相应的耕地矢量数据作为标签数据,训练影像以及对应标签共同构成训练数据。为满足 GPU 显存需求和提升训练效率,利用滑窗裁剪和随机裁剪,将训练数据裁剪为若干256像素×256像素的子图,并按比例4∶1分为训练集和验证集。另外,为避免训练集影像过少引起的欠拟合或过拟合等问题,还对训练集和验证集进行了水平翻转、垂直翻转、对角翻转等数据增广操作,并将其打乱使得样本分布更合理。最后生成了77 969幅256像素×256像素图像的训练集,19 492幅256像素×256像素图像的验证集。宜丰县的遥感影像作为测试影像,测试LWIBNet模型提取耕地图斑的精确度。高分遥感影像相关信息如表3所示。

表3 高分遥感影像的相关信息Tab.3 Related information of high-resolution remote sensing images
2.2 实验方案与设置
选取RF、SVM和ML与LWIBNet模型的提取结果进行对比分析。其中,SVM的每个类最大示例数设为500;RF的树设置为最大数量100,最大深度30;LWIBNet模型的训练参数设置为:损失函数均采用交叉熵函数,优化器采用更优的Nadam优化算法[34],分类器采用Softmax激活函数,初始学习率均采用1×10-4,批尺寸为36,验证集的损失率连续10轮没有下降,则停止训练。LWIBNet与传统模型对比实验软硬件环境为:CPU为lntel(R)Xeon(R)CPU E5-2687W;GPU为NVIDIA GeForce GTX 1070;操作系统为Windows 10;开发工具为Tensorflow2.3+Python3.8。
选取基于FCN的U-Net模型、Deeplabv3+模型(主干网络为Resnet50)与LWIBNet的模型对轻量性和提取精确度进行了对比,实验环境为:CPU为lntel (R) Core i7-10875H;GPU为NVIDIA GeForce RTX 2070;操作系统为Windows 10;开发工具为Tensorflow2.3+Python3.8。
为了避免传统模型以及基于FCN的模型产生细小图斑的影响,引入数学形态学方法,对传统分类模型和LWIBNet模型的提取结果进行后处理,传统模型先通过聚类处理将临近的类似分类区域聚类并进行合并,再用聚类之后的图像做过滤处理滤除小图斑。测试时增强算法具有提升精度的效果,所以LWIBNet模型的后处理为先使用增强算法来增强提取结果,再利用数学形态学的闭运算来优化图斑内部空洞,最后利用阈值法滤除杂波。
2.3 实验结果
使用优化后的耕地提取模型得到江西省宜丰县耕地图斑空间信息,如图3所示。
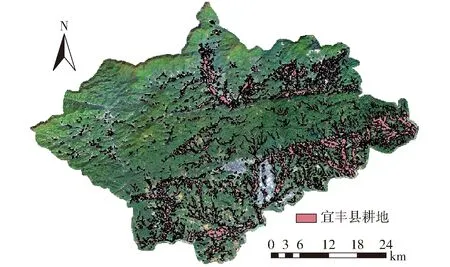
图3 LWIBNet模型提取的宜丰县耕地图斑空间分布信息图Fig.3 Spatial distribution information map of cultivated land spots in Yifeng County extracted by LWIBNet
2.4 精度评价与分析
为验证LWIBNet模型提取耕地图斑的精度,选取宜丰县一块7 107像素×5 052像素的区域作为测试影像,并将测试结果与相应区域人工标注的耕地信息图进行定性和定量比较。
2.4.1传统模型与LWIBNet模型定性对比
图4为各模型从测试影像提取耕地图斑的整体对比,有助于全局性对各模型提取结果进行对比。图5为各模型从测试影像提取耕地图斑的细节对比,能更具体地辨别出正确分类和错误分类的地物。

图4 各模型从测试影像提取耕地图斑的整体对比Fig.4 Overall comparisons of cultivated land patches extracted from test images by various models

图5 各模型从测试影像提取耕地图斑的细节对比Fig.5 Comparisons of details of cultivated land patches extracted from test images by different models
由图4可知,从整体来看,除了ML将较多耕地错误识别为非耕地而导致整体分类情况和标签图相差较大外,其他模型的提取结果都与标签图在整体趋势上有较高吻合度。但与LWIBNet相比,没有经过后处理的传统分类模型都受到了严重的椒盐噪声干扰,从图4d、4f、4h可以看到后处理后的传统模型缓解了噪声对影像质量的影响,各图斑之间的界限也更明晰,但它们依然存在诸多错分漏分情况。而LWIBNet仅受少量杂波影响,其在未后处理的制图整洁度和美观度远优于经后处理的传统模型。在各模型中的后处理主要针对被错识别为耕地的像素,后处理的效果在LWIBNet模型中的表现最为突出,错识别像素明显减少。根据图中错识别和漏识别像素数量和分布情况来看,ML的表现最差,正确识别的像元数最少,RF和SVM不管是后处理前还是后处理后分类表现相差不大,且这3个模型提取的图斑都存在破碎度大和像元混合的问题,将本是成片的耕地识别成了破碎不连续的零散图斑,破坏了耕地信息的空间完整性。而LWIBNet模型结果不仅错分像素最少,提取的成片耕地大部分都具有连续性,后处理后的制图成果更加整洁,图4k中也可以看出,LWIBNet模型提取的耕地区域与实际耕地的分布位置具有较好的一致性,从耕地图斑提取整体效果来看,LWIBNet模型表现最优。
由图5可知,从细节分析上看,传统模型提取的图斑破碎大和像元混合看的更清晰,出现这些问题可能是因为耕地的光谱信息类内差异大,这与种植方式、土壤属性和作物类型等的不同有关。而LWIBNet模型能充分利用上下文语义信息,可减轻这种类内差异大带来的影响,故提取的图斑连续性好。传统模型还易将枯水期的河湖库塘、植被覆盖较低的其他林地裸土地等错误识别为耕地,这可能是受高分影像“同物异谱”和“异物同谱”影响。而LWIBNet模型完全趋于数据驱动,能反复多次地学习图像的底层和高层特征,这个优点可减轻上述现象的影响,故LWIBNet模型错识别为耕地的像素更少。从细节图能明显地看出后处理后的结果比处理前更加整洁和准确,但后处理也会带来一定的负面影响,容易滤除一些正确识别的孤岛小图斑,从而造成漏识别,但总体效果较好。通过与标签图像对比,ML表现最差,SVM略优于RF,而LWIBNet表现最优。
2.4.2传统模型与LWIBNet模型定量对比
表4为LWIBNet模型与传统模型的定量评价结果。从表4可看出,所有模型后处理后的各项指标都高于处理前,ML、RF、SVM的Kappa系数比处理前分别提升了7.7%、9.6%和10.3%,而LWIBNet模型后处理后的提升较少,也提升了0.008。在3个传统模型中ML的评分最低,而SVM略高于RF。LWIBNet模型的各项评分显著优于传统模型,比表现最好的传统模型F1值提高11.6%,OA提高5.2%,MloU提高12.2%,Kappa系数提高12.0%。
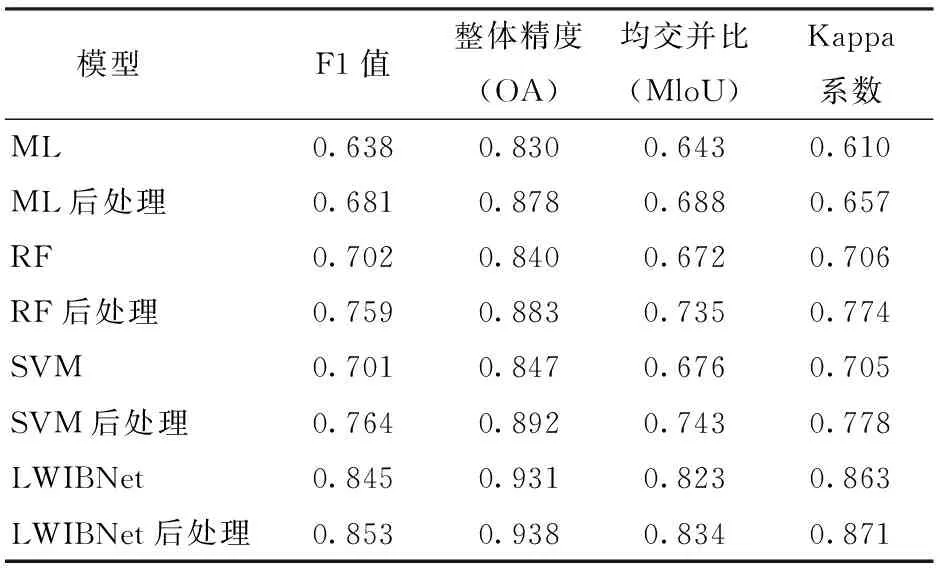
表4 LWIBNet与传统模型的定量评价指标对比Tab.4 Comparison of quantitative evaluation indexes between LWIBNet and traditional model
通过对比LWIBNet提取的宜丰县耕地总面积与人工解译的总面积发现,LWIBNet提取的宜丰县耕地图斑面积为278.30 hm2,人工解译的宜丰县耕地矢量数据中耕地面积为300.59 hm2。绝对误差为22.29 hm2,相对误差为7.42%,模型提取的耕地图斑大体上和人工识别的一致,但一些林间耕地,窄小耕地等样本量少或复杂的耕地类型,容易被漏提取,但总体上表现较好,表明利用LWIBNet模型提取耕地图斑有较大的可行性。
2.4.3经典FCN模型与LWIBNet模型的对比
实验主要包括模型轻量性和模型提取精确度对比。轻量性实验中包括模型的参数量、浮点运算数和训练耗时,这3个指标分别用于衡量模型复杂度、模型计算复杂度以及模型运行速度(表5)。对于模型提取精确度,主要开展了定性和定量的分析。此对比实验训练集和验证集是从大数据集中随机抽取7 500幅图像,每个模型都训练40个周期(由于计算资源和时间限制,这里未进行充分训练,能对比本文模型与经典模型的轻量度、精确度的差异即可)。从表5可看出,在参数量上,LWIBNet为1.07 MB,U-Net的参数量是它的29倍,Deeplabv3+ 约为LWIBNet的11倍。在浮点运算数上,LWIBNet为14.14 GB,U-Net是LWIBNet的7.7倍,Deeplabv3+约为LWIBNet的3.7倍。在训练耗时上,U-Net的耗时最多,是Deeplabv3+ 的2.3倍,是LWIBNet的4.6倍,LWIBNet的耗时最少,每步耗时139 ms。
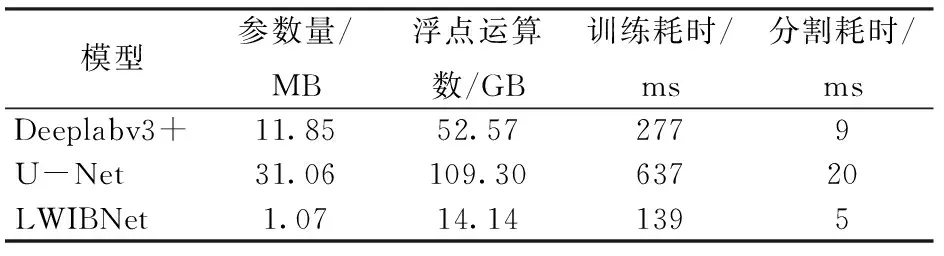
表5 LWIBNet与经典FCN模型的计算资源、时间消耗指标对比(轻量度对比)Tab.5 Comparison of computing resources and time consumption between LWIBNet and classical FCN model
在分割耗时上,U-Net的每步耗时最多,LWIBNet的耗时最少。LWIBNet 无论是参数量、计算量还是训练耗时都低于经典语义分割模型,符合轻量级网络模型的特点。
图6为各深度学习模型从测试影像提取耕地图斑的整体对比。由图6可知,Deeplabv3+的红色像素比黄色像素更多,表明错识别的像素中错识别为非耕地的更多,U-Net的红色像素比黄色像素略多一点,两种错识别概率相近,LWIBNet主要是黄色像素比红色像素多,也就是错识别为耕地的更多一点;3个模型对比来看,LWIBNet模型的黄色像素最多,也错识别为耕地的更多,但是它红色像素最少,正确提取的灰色像素也比其他模型多一点,Deeplabv3+红色像素最多,黄色最少,U-Net的黄色和红色像素数量居于中间。定量对比如表6所示。从表6可看出,U-Net与LWIBNet在各项指标上只有0.001~0.005的差异,LWIBNet与Deeplabv3+也仅有0.005~0.028的差异,且LWIBNet的大部分指标更优于Deeplabv3+。综合定性和定量结果,LWIBNet与经典FCN模型有着相似的分割精度,且该模型具有一定轻量性,它的计算资源和时间消耗更低。

图6 各深度学习模型从测试影像提取耕地图斑的整体对比Fig.6 Each deep learning model extracted whole contrast of cultivated land patches from test images
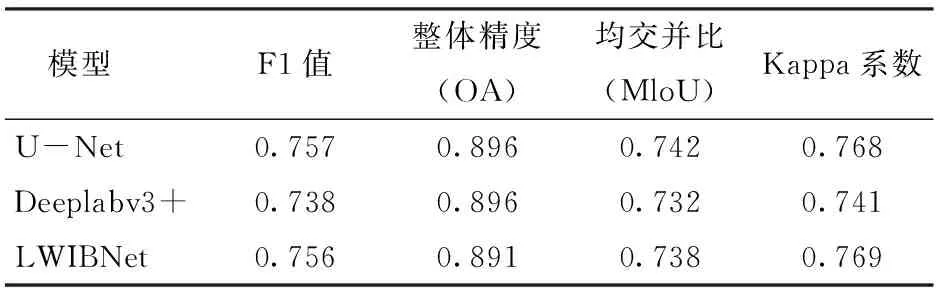
表6 LWIBNet与经典FCN模型的提取结果定量对比Tab.6 Quantitative comparison of extraction results between LWIBNet and classical FCN model
3 结论
(1)综合轻量级卷积神经网络和U-Net的优点,以Inv-Bottleneck模块(由深度可分离卷积、压缩-激励块和反残差块组成)为核心,联合高效的编码-解码结构为框架,建立了基于FCN的轻量级耕地图斑提取模型(LWIBNet模型)。
(2)LWIBNet模型有效改善了传统模型提取结果破碎的问题,并减轻了椒盐噪声影响,其F1值、整体精度(OA)、均交并比(MloU)和Kappa系数等各项指标均比表现最好的传统模型(经后处理的SVM)分别提高了11.6%、5.2%、12.2%和12.0%;且LWIBNet模型训练得到模型参数具有更好的普适性,降低了人为主观因素的干扰,自动化水平更高。
(3)在相同的实验环境和设置下,LWIBNet模型的参数量、计算量和训练耗时都低于经典的FCN模型Deeplabv3+和U-Net,其中,Deeplabv3+的参数量是LWIBNet模型的11倍,U-Net的计算量是LWIBNet模型的7.7倍,U-Net的训练耗时是LWIBNet模型的4.6倍,LWIBNet无论是参数量、计算量还是训练耗时和分割耗时都低于经典的FCN模型Deeplabv3+和U-Net,且提取结果的精度与经典FCN模型相似,表明LWIBNet能以更少的计算资源和时间消耗实现与经典FCN模型相似的分割精度。
猜你喜欢
北京测绘(2022年9期)2022-10-11
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
汽车实用技术(2022年15期)2022-08-19
计算技术与自动化(2022年1期)2022-04-15
资源导刊(2020年9期)2020-10-15
新农业(2020年8期)2020-08-26
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电力与能源系统学报·上旬刊(2019年4期)2019-09-10
企业导报(2015年16期)2015-12-14
